 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Do Better ImageNet Models Transfer Better... for Image Recommendation?
Sep 25, 2018
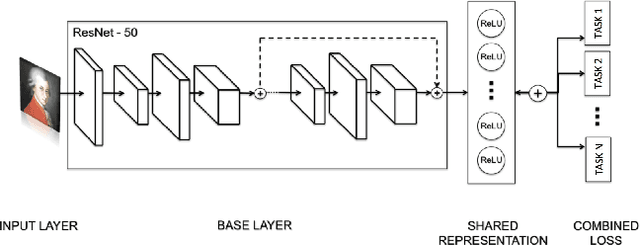
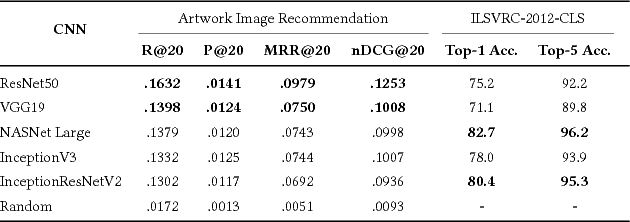
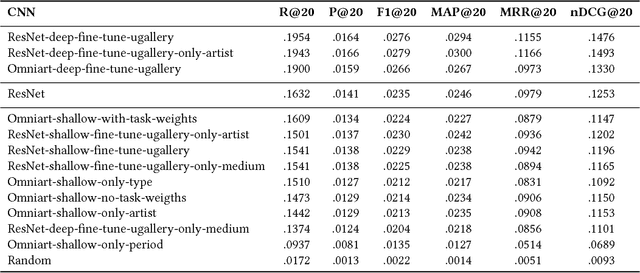
Visual embeddings from Convolutional Neural Networks (CNN) trained on the ImageNet dataset for the ILSVRC challenge have shown consistently good performance for transfer learning and are widely used in several tasks, including image recommendation. However, some important questions have not yet been answered in order to use these embeddings for a larger scope of recommendation domains: a) Do CNNs that perform better in ImageNet are also better for transfer learning in content-based image recommendation?, b) Does fine-tuning help to improve performance? and c) Which is the best way to perform the fine-tuning? In this paper we compare several CNN models pre-trained with ImageNet to evaluate their transfer learning performance to an artwork image recommendation task. Our results indicate that models with better performance in the ImageNet challenge do not always imply better transfer learning for recommendation tasks (e.g. NASNet vs. ResNet). Our results also show that fine-tuning can be helpful even with a small dataset, but not every fine-tuning works. Our results can inform other researchers and practitioners on how to train their CNNs for better transfer learning towards image recommendation systems.
Multiscale Invertible Generative Networks for High-Dimensional Bayesian Inference
May 12, 2021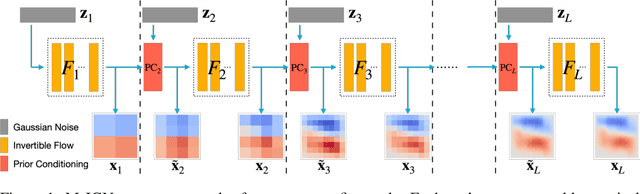
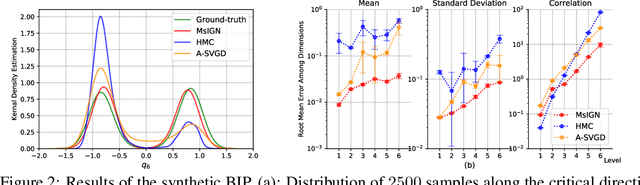
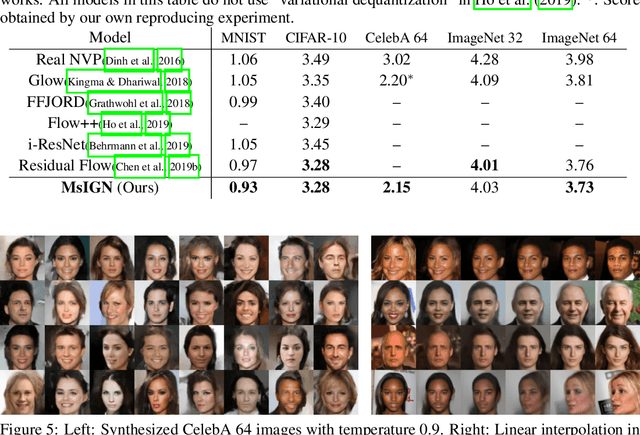
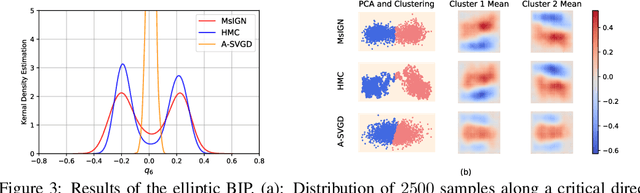
We propose a Multiscale Invertible Generative Network (MsIGN) and associated training algorithm that leverages multiscale structure to solve high-dimensional Bayesian inference. To address the curse of dimensionality, MsIGN exploits the low-dimensional nature of the posterior, and generates samples from coarse to fine scale (low to high dimension) by iteratively upsampling and refining samples. MsIGN is trained in a multi-stage manner to minimize the Jeffreys divergence, which avoids mode dropping in high-dimensional cases. On two high-dimensional Bayesian inverse problems, we show superior performance of MsIGN over previous approaches in posterior approximation and multiple mode capture. On the natural image synthesis task, MsIGN achieves superior performance in bits-per-dimension over baseline models and yields great interpret-ability of its neurons in intermediate layers.
Video Synthesis from a Single Image and Motion Stroke
Dec 05, 2018
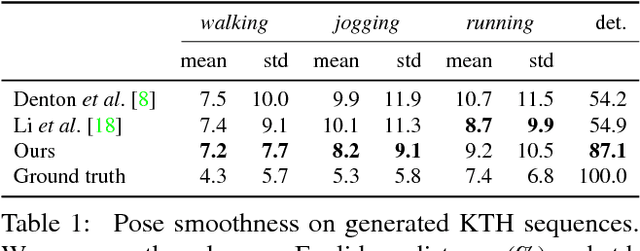
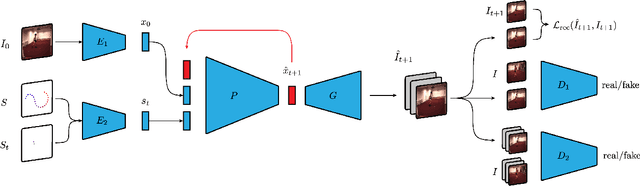

In this paper, we propose a new method to automatically generate a video sequence from a single image and a user provided motion stroke. Generating a video sequence based on a single input image has many applications in visual content creation, but it is tedious and time-consuming to produce even for experienced artists. Automatic methods have been proposed to address this issue, but most existing video prediction approaches require multiple input frames. In addition, generated sequences have limited variety since the output is mostly determined by the input frames, without allowing the user to provide additional constraints on the result. In our technique, users can control the generated animation using a sketch stroke on a single input image. We train our system such that the trajectory of the animated object follows the stroke, which makes it both more flexible and more controllable. From a single image, users can generate a variety of video sequences corresponding to different sketch inputs. Our method is the first system that, given a single frame and a motion stroke, can generate animations by recurrently generating videos frame by frame. An important benefit of the recurrent nature of our architecture is that it facilitates the synthesis of an arbitrary number of generated frames. Our architecture uses an autoencoder and a generative adversarial network (GAN) to generate sharp texture images, and we use another GAN to guarantee that transitions between frames are realistic and smooth. We demonstrate the effectiveness of our approach on the MNIST, KTH, and Human 3.6M datasets.
An Improved Real-Time Face Recognition System at Low Resolution Based on Local Binary Pattern Histogram Algorithm and CLAHE
Apr 15, 2021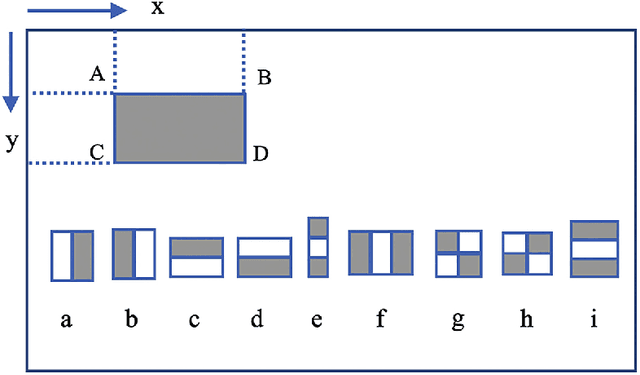

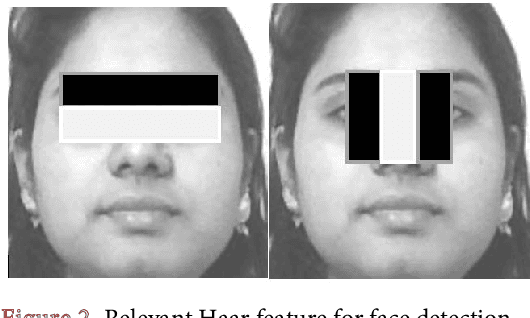
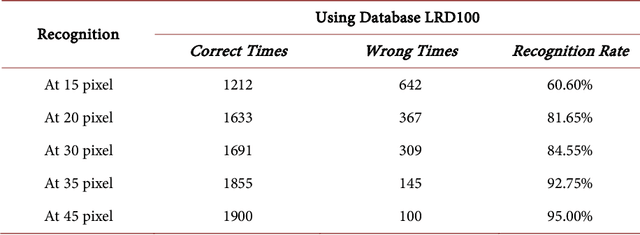
This research presents an improved real-time face recognition system at a low resolution of 15 pixels with pose and emotion and resolution variations. We have designed our datasets named LRD200 and LRD100, which have been used for training and classification. The face detection part uses the Viola-Jones algorithm, and the face recognition part receives the face image from the face detection part to process it using the Local Binary Pattern Histogram (LBPH) algorithm with preprocessing using contrast limited adaptive histogram equalization (CLAHE) and face alignment. The face database in this system can be updated via our custom-built standalone android app and automatic restarting of the training and recognition process with an updated database. Using our proposed algorithm, a real-time face recognition accuracy of 78.40% at 15 px and 98.05% at 45 px have been achieved using the LRD200 database containing 200 images per person. With 100 images per person in the database (LRD100) the achieved accuracies are 60.60% at 15 px and 95% at 45 px respectively. A facial deflection of about 30 degrees on either side from the front face showed an average face recognition precision of 72.25% - 81.85%. This face recognition system can be employed for law enforcement purposes, where the surveillance camera captures a low-resolution image because of the distance of a person from the camera. It can also be used as a surveillance system in airports, bus stations, etc., to reduce the risk of possible criminal threats.
* Journal, Optics and Photonics Journal
Properties on n-dimensional convolution for image deconvolution
Nov 30, 2017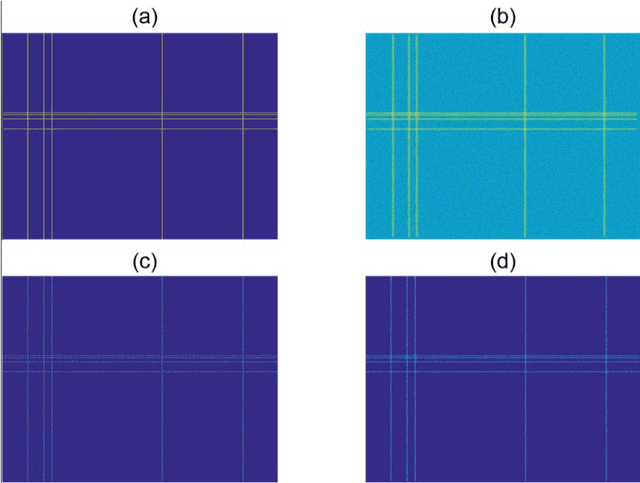

Convolution system is linear and time invariant, and can describe the optical imaging process. Based on convolution system, many deconvolution techniques have been developed for optical image analysis, such as boosting the space resolution of optical images, image denoising, image enhancement and so on. Here, we gave properties on N-dimensional convolution. By using these properties, we proposed image deconvolution method. This method uses a series of convolution operations to deconvolute image. We demonstrated that the method has the similar deconvolution results to the state-of-art method. The core calculation of the proposed method is image convolution, and thus our method can easily be integrated into GPU mode for large-scale image deconvolution.
CycleSegNet: Object Co-segmentation with Cycle Refinement and Region Correspondence
Jan 05, 2021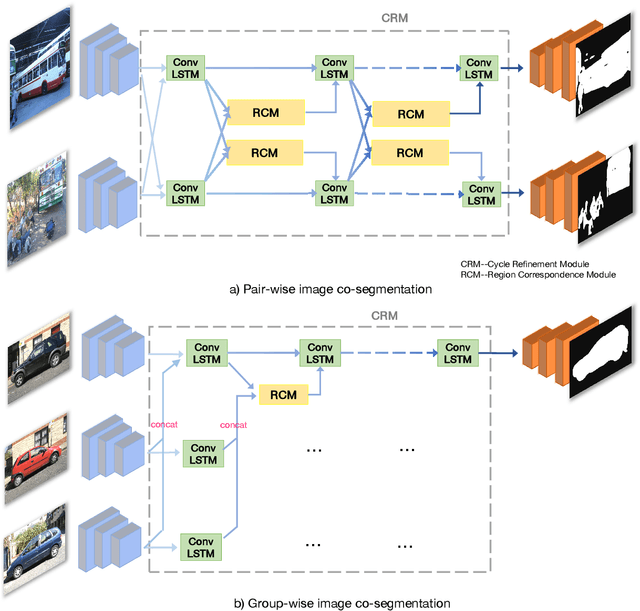
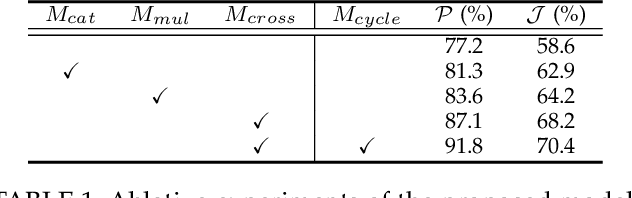
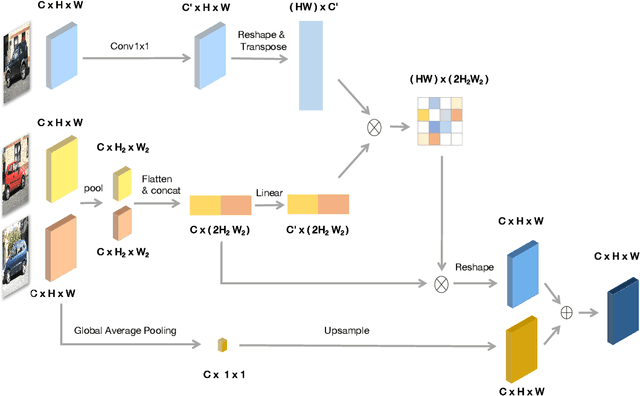
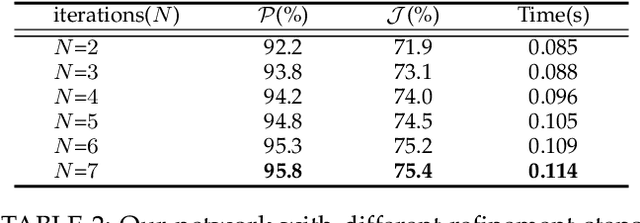
Image co-segmentation is an active computer vision task which aims to segment the common objects in a set of images. Recently, researchers design various learning-based algorithms to handle the co-segmentation task. The main difficulty in this task is how to effectively transfer information between images to infer the common object regions. In this paper, we present CycleSegNet, a novel framework for the co-segmentation task. Our network design has two key components: a region correspondence module which is the basic operation for exchanging information between local image regions, and a cycle refinement module which utilizes ConvLSTMs to progressively update image embeddings and exchange information in a cycle manner. Experiment results on four popular benchmark datasets -- PASCAL VOC dataset, MSRC dataset, Internet dataset and iCoseg dataset demonstrate that our proposed method significantly outperforms the existing networks and achieves new state-of-the-art performance.
Low-rank Characteristic Tensor Density Estimation Part II: Compression and Latent Density Estimation
Jun 20, 2021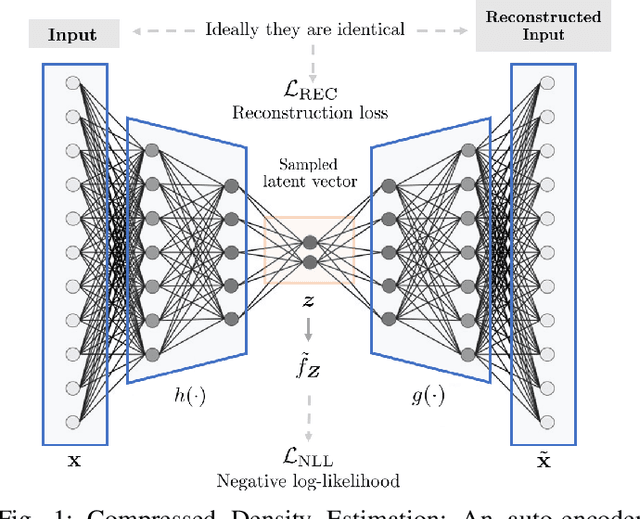
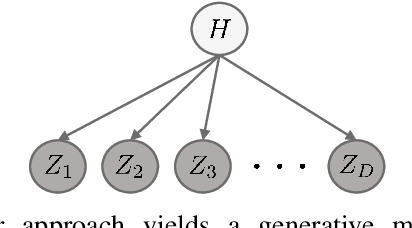
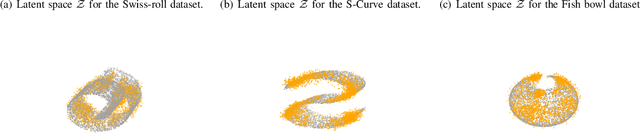
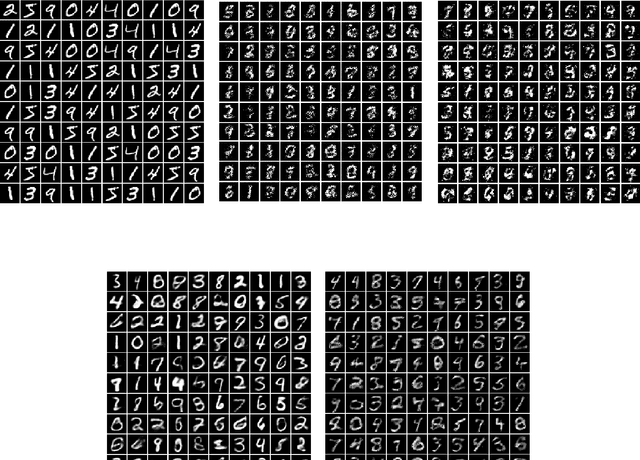
Learning generative probabilistic models is a core problem in machine learning, which presents significant challenges due to the curse of dimensionality. This paper proposes a joint dimensionality reduction and non-parametric density estimation framework, using a novel estimator that can explicitly capture the underlying distribution of appropriate reduced-dimension representations of the input data. The idea is to jointly design a nonlinear dimensionality reducing auto-encoder to model the training data in terms of a parsimonious set of latent random variables, and learn a canonical low-rank tensor model of the joint distribution of the latent variables in the Fourier domain. The proposed latent density model is non-parametric and universal, as opposed to the predefined prior that is assumed in variational auto-encoders. Joint optimization of the auto-encoder and the latent density estimator is pursued via a formulation which learns both by minimizing a combination of the negative log-likelihood in the latent domain and the auto-encoder reconstruction loss. We demonstrate that the proposed model achieves very promising results on toy, tabular, and image datasets on regression tasks, sampling, and anomaly detection.
B-spline Parameterized Joint Optimization of Reconstruction and K-space Trajectories (BJORK) for Accelerated 2D MRI
Jan 27, 2021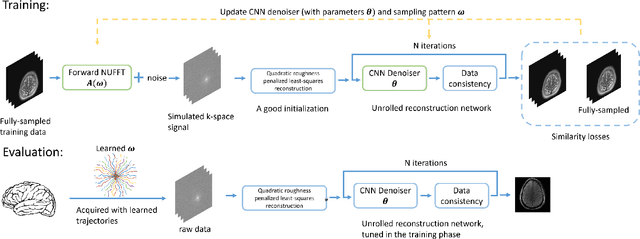
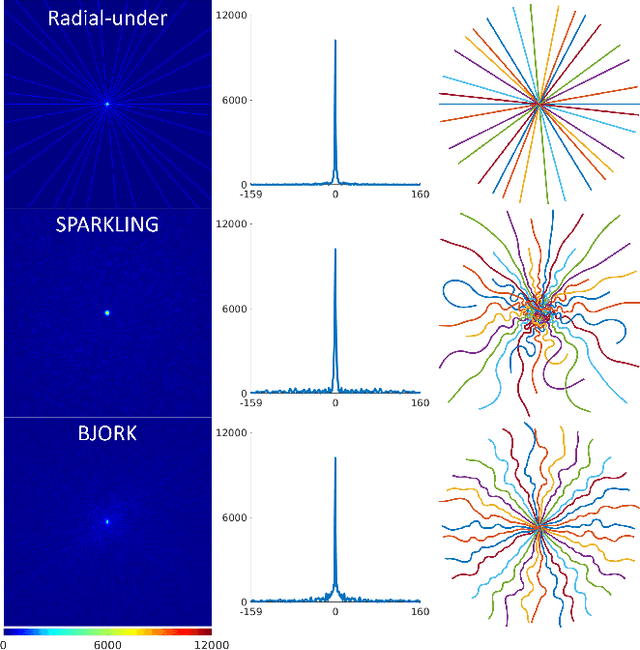


Optimizing k-space sampling trajectories is a challenging topic for fast magnetic resonance imaging (MRI). This work proposes to optimize a reconstruction algorithm and sampling trajectories jointly concerning image reconstruction quality. We parameterize trajectories with quadratic B-spline kernels to reduce the number of parameters and enable multi-scale optimization, which may help to avoid sub-optimal local minima. The algorithm includes an efficient non-Cartesian unrolled neural network-based reconstruction and an accurate approximation for backpropagation through the non-uniform fast Fourier transform (NUFFT) operator to accurately reconstruct and back-propagate multi-coil non-Cartesian data. Penalties on slew rate and gradient amplitude enforce hardware constraints. Sampling and reconstruction are trained jointly using large public datasets. To correct the potential eddy-current effect introduced by the curved trajectory, we use a pencil-beam trajectory mapping technique. In both simulations and in-vivo experiments, the learned trajectory demonstrates significantly improved image quality compared to previous model-based and learning-based trajectory optimization methods for 20x acceleration factors. Though trained with neural network-based reconstruction, the proposed trajectory also leads to improved image quality with compressed sensing-based reconstruction.
Learning without Forgetting for 3D Point Cloud Objects
Jun 27, 2021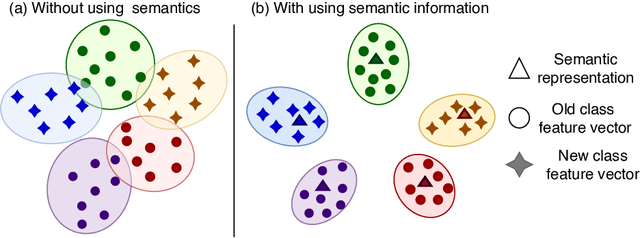

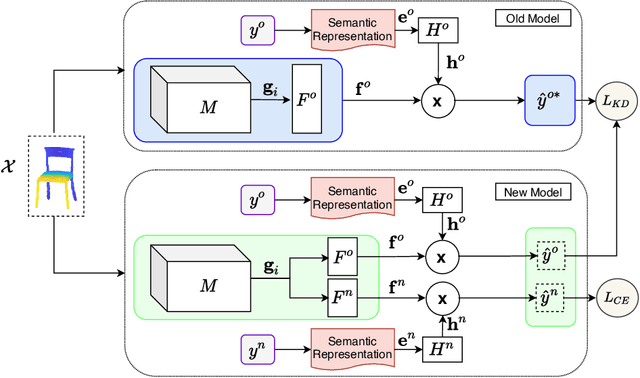

When we fine-tune a well-trained deep learning model for a new set of classes, the network learns new concepts but gradually forgets the knowledge of old training. In some real-life applications, we may be interested in learning new classes without forgetting the capability of previous experience. Such learning without forgetting problem is often investigated using 2D image recognition tasks. In this paper, considering the growth of depth camera technology, we address the same problem for the 3D point cloud object data. This problem becomes more challenging in the 3D domain than 2D because of the unavailability of large datasets and powerful pretrained backbone models. We investigate knowledge distillation techniques on 3D data to reduce catastrophic forgetting of the previous training. Moreover, we improve the distillation process by using semantic word vectors of object classes. We observe that exploring the interrelation of old and new knowledge during training helps to learn new concepts without forgetting old ones. Experimenting on three 3D point cloud recognition backbones (PointNet, DGCNN, and PointConv) and synthetic (ModelNet40, ModelNet10) and real scanned (ScanObjectNN) datasets, we establish new baseline results on learning without forgetting for 3D data. This research will instigate many future works in this area.
Paying Attention to Activation Maps in Camera Pose Regression
Mar 21, 2021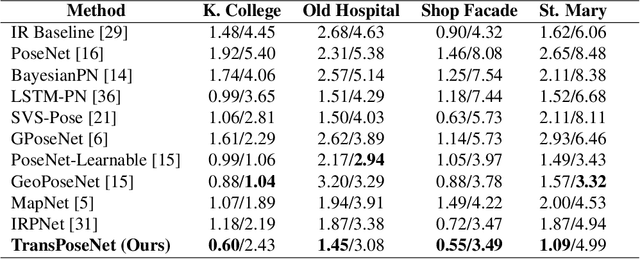
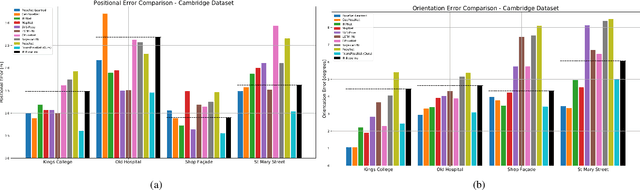
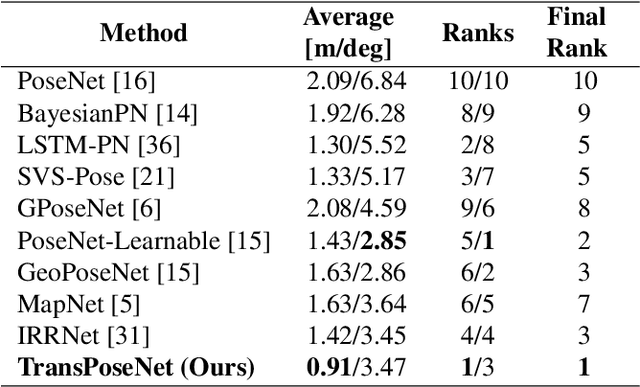
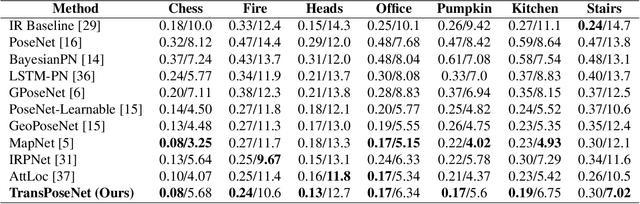
Camera pose regression methods apply a single forward pass to the query image to estimate the camera pose. As such, they offer a fast and light-weight alternative to traditional localization schemes based on image retrieval. Pose regression approaches simultaneously learn two regression tasks, aiming to jointly estimate the camera position and orientation using a single embedding vector computed by a convolutional backbone. We propose an attention-based approach for pose regression, where the convolutional activation maps are used as sequential inputs. Transformers are applied to encode the sequential activation maps as latent vectors, used for camera pose regression. This allows us to pay attention to spatially-varying deep features. Using two Transformer heads, we separately focus on the features for camera position and orientation, based on how informative they are per task. Our proposed approach is shown to compare favorably to contemporary pose regressors schemes and achieves state-of-the-art accuracy across multiple outdoor and indoor benchmarks. In particular, to the best of our knowledge, our approach is the only method to attain sub-meter average accuracy across outdoor scenes. We make our code publicly available from here.