 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
QFCNN: Quantum Fourier Convolutional Neural Network
Jun 19, 2021
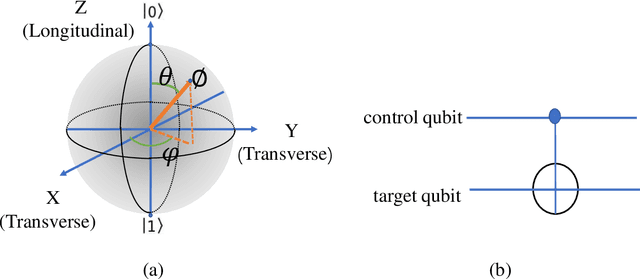
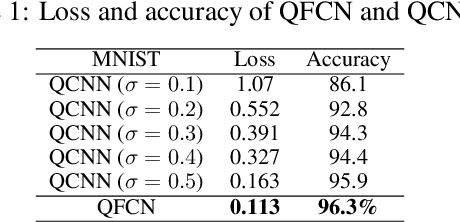
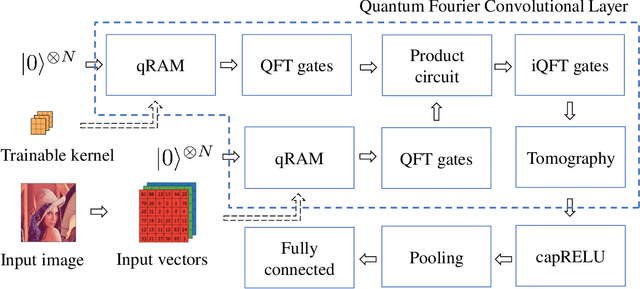
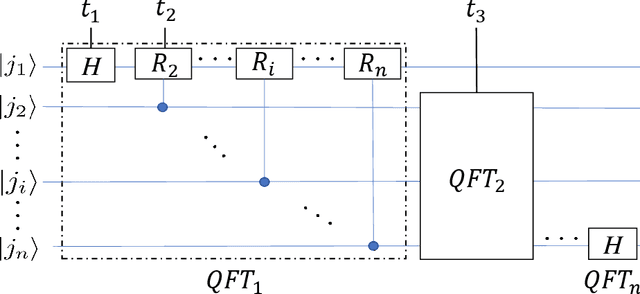
The neural network and quantum computing are both significant and appealing fields, with their interactive disciplines promising for large-scale computing tasks that are untackled by conventional computers. However, both developments are restricted by the scope of the hardware development. Nevertheless, many neural network algorithms had been proposed before GPUs become powerful enough for running very deep models. Similarly, quantum algorithms can also be proposed as knowledge reserves before real quantum computers are easily accessible. Specifically, taking advantage of both the neural networks and quantum computation and designing quantum deep neural networks (QDNNs) for acceleration on Noisy Intermediate-Scale Quantum (NISQ) processors is also an important research problem. As one of the most widely used neural network architectures, convolutional neural network (CNN) remains to be accelerated by quantum mechanisms, with only a few attempts have been demonstrated. In this paper, we propose a new hybrid quantum-classical circuit, namely Quantum Fourier Convolutional Network (QFCN). Our model achieves exponential speed-up compared with classical CNN theoretically and improves over the existing best result of quantum CNN. We demonstrate the potential of this architecture by applying it to different deep learning tasks, including traffic prediction and image classification.
Towards an Interpretable Latent Space in Structured Models for Video Prediction
Jul 16, 2021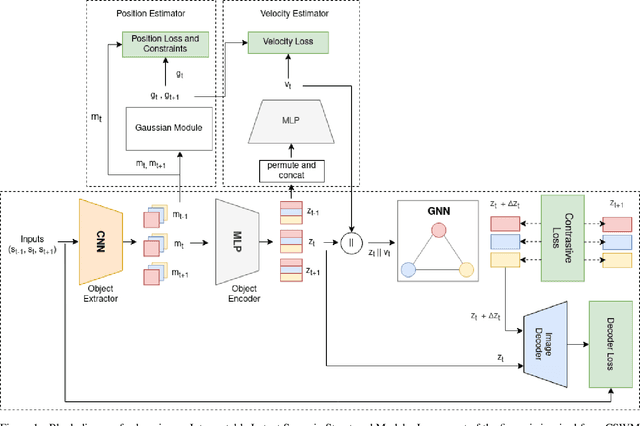
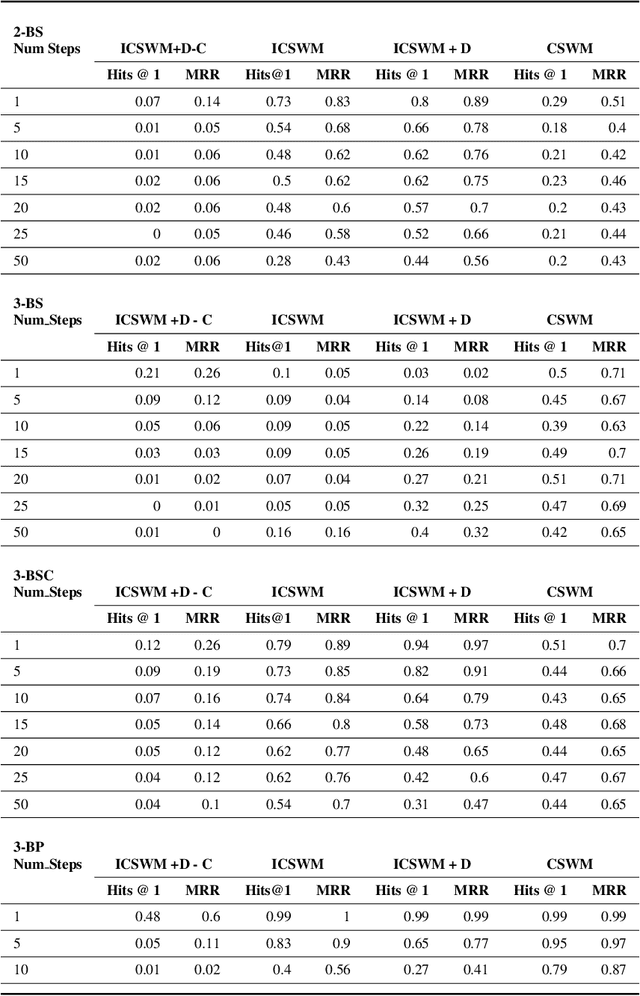
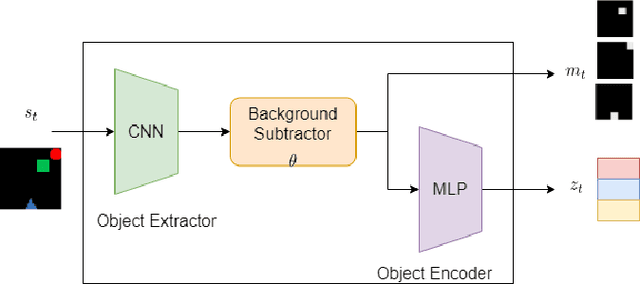
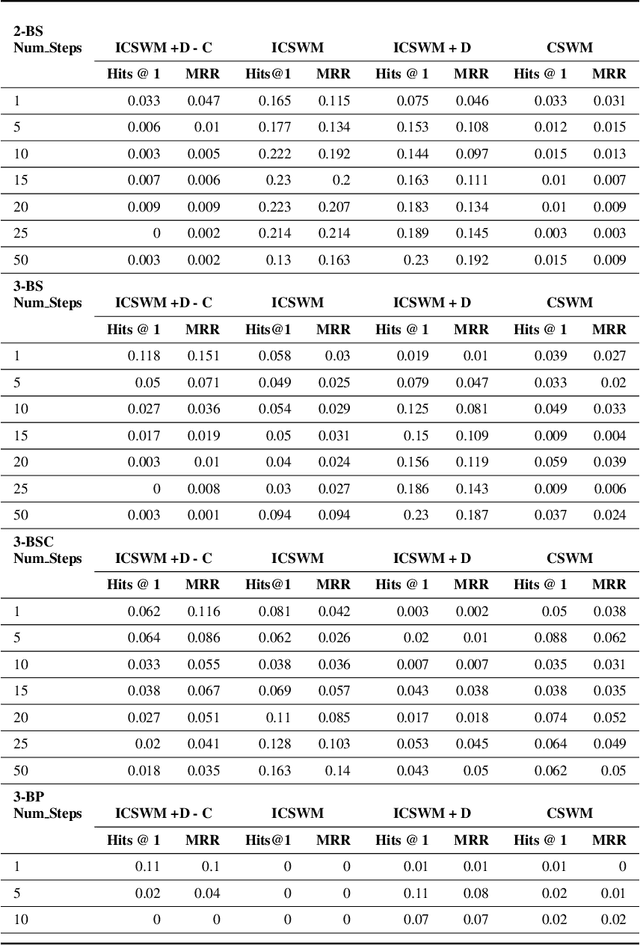
We focus on the task of future frame prediction in video governed by underlying physical dynamics. We work with models which are object-centric, i.e., explicitly work with object representations, and propagate a loss in the latent space. Specifically, our research builds on recent work by Kipf et al. \cite{kipf&al20}, which predicts the next state via contrastive learning of object interactions in a latent space using a Graph Neural Network. We argue that injecting explicit inductive bias in the model, in form of general physical laws, can help not only make the model more interpretable, but also improve the overall prediction of model. As a natural by-product, our model can learn feature maps which closely resemble actual object positions in the image, without having any explicit supervision about the object positions at the training time. In comparison with earlier works \cite{jaques&al20}, which assume a complete knowledge of the dynamics governing the motion in the form of a physics engine, we rely only on the knowledge of general physical laws, such as, world consists of objects, which have position and velocity. We propose an additional decoder based loss in the pixel space, imposed in a curriculum manner, to further refine the latent space predictions. Experiments in multiple different settings demonstrate that while Kipf et al. model is effective at capturing object interactions, our model can be significantly more effective at localising objects, resulting in improved performance in 3 out of 4 domains that we experiment with. Additionally, our model can learn highly intrepretable feature maps, resembling actual object positions.
Multimodal Continuous Visual Attention Mechanisms
Apr 07, 2021
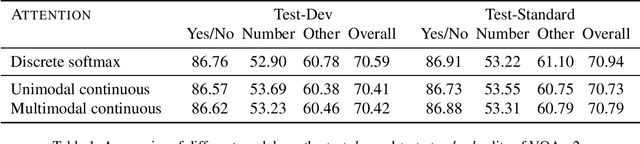


Visual attention mechanisms are a key component of neural network models for computer vision. By focusing on a discrete set of objects or image regions, these mechanisms identify the most relevant features and use them to build more powerful representations. Recently, continuous-domain alternatives to discrete attention models have been proposed, which exploit the continuity of images. These approaches model attention as simple unimodal densities (e.g. a Gaussian), making them less suitable to deal with images whose region of interest has a complex shape or is composed of multiple non-contiguous patches. In this paper, we introduce a new continuous attention mechanism that produces multimodal densities, in the form of mixtures of Gaussians. We use the EM algorithm to obtain a clustering of relevant regions in the image, and a description length penalty to select the number of components in the mixture. Our densities decompose as a linear combination of unimodal attention mechanisms, enabling closed-form Jacobians for the backpropagation step. Experiments on visual question answering in the VQA-v2 dataset show competitive accuracies and a selection of regions that mimics human attention more closely in VQA-HAT. We present several examples that suggest how multimodal attention maps are naturally more interpretable than their unimodal counterparts, showing the ability of our model to automatically segregate objects from ground in complex scenes.
Hand Gesture Recognition Based on a Nonconvex Regularization
Apr 29, 2021


Recognition of hand gestures is one of the most fundamental tasks in human-robot interaction. Sparse representation based methods have been widely used due to their efficiency and low requirements on the training data. Recently, nonconvex regularization techniques including the $\ell_{1-2}$ regularization have been proposed in the image processing community to promote sparsity while achieving efficient performance. In this paper, we propose a vision-based human arm gesture recognition model based on the $\ell_{1-2}$ regularization, which is solved by the alternating direction method of multipliers (ADMM). Numerical experiments on realistic data sets have shown the effectiveness of this method in identifying arm gestures.
Direct Image to Point Cloud Descriptors Matching for 6-DOF Camera Localization in Dense 3D Point Cloud
Jun 14, 2019
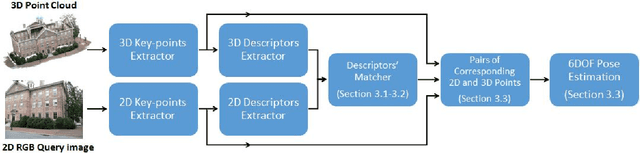
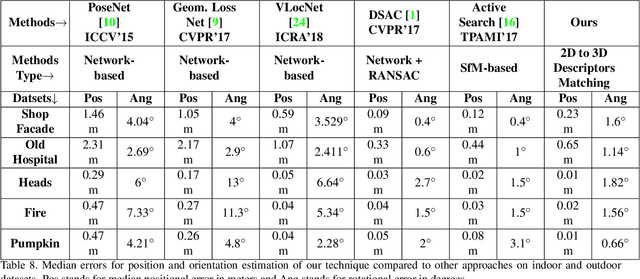
We propose a novel concept to directly match feature descriptors extracted from RGB images, with feature descriptors extracted from 3D point clouds. We use this concept to localize the position and orientation (pose) of the camera of a query image in dense point clouds. We generate a dataset of matching 2D and 3D descriptors, and use it to train a proposed Descriptor-Matcher algorithm. To localize a query image in a point cloud, we extract 2D keypoints and descriptors from the query image. Then the Descriptor-Matcher is used to find the corresponding pairs 2D and 3D keypoints by matching the 2D descriptors with the pre-extracted 3D descriptors of the point cloud. This information is used in a robust pose estimation algorithm to localize the query image in the 3D point cloud. Experiments demonstrate that directly matching 2D and 3D descriptors is not only a viable idea but also achieves competitive accuracy compared to other state-of-the-art approaches for camera pose localization.
Exact Backpropagation in Binary Weighted Networks with Group Weight Transformations
Jul 16, 2021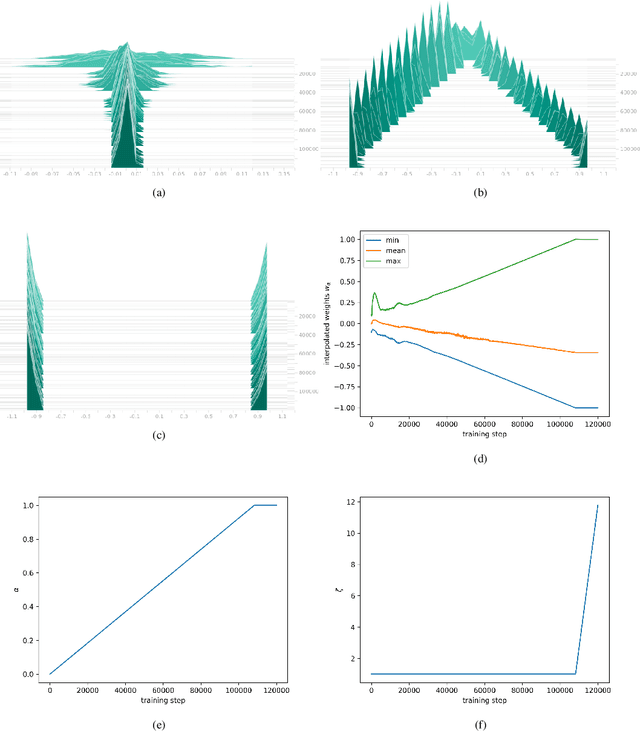

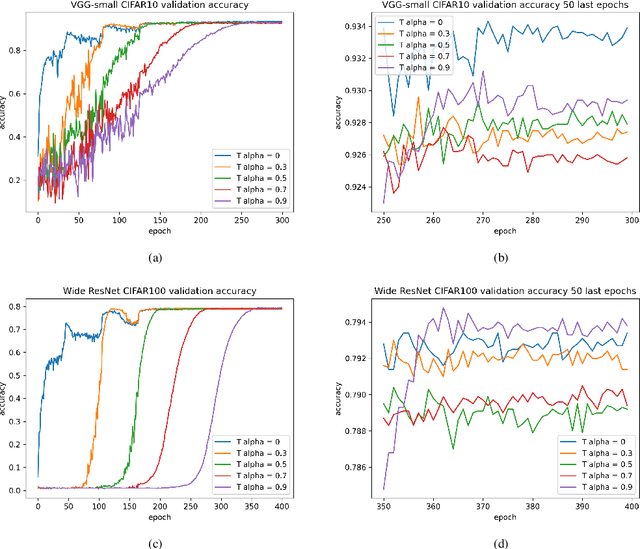
Quantization based model compression serves as high performing and fast approach for inference that yields models which are highly compressed when compared to their full-precision floating point counterparts. The most extreme quantization is a 1-bit representation of parameters such that they have only two possible values, typically -1(0) or +1, enabling efficient implementation of the ubiquitous dot product using only additions. The main contribution of this work is the introduction of a method to smooth the combinatorial problem of determining a binary vector of weights to minimize the expected loss for a given objective by means of empirical risk minimization with backpropagation. This is achieved by approximating a multivariate binary state over the weights utilizing a deterministic and differentiable transformation of real-valued, continuous parameters. The proposed method adds little overhead in training, can be readily applied without any substantial modifications to the original architecture, does not introduce additional saturating nonlinearities or auxiliary losses, and does not prohibit applying other methods for binarizing the activations. Contrary to common assertions made in the literature, it is demonstrated that binary weighted networks can train well with the same standard optimization techniques and similar hyperparameter settings as their full-precision counterparts, specifically momentum SGD with large learning rates and $L_2$ regularization. To conclude experiments demonstrate the method performs remarkably well across a number of inductive image classification tasks with various architectures compared to their full-precision counterparts. The source code is publicly available at https://bitbucket.org/YanivShu/binary_weighted_networks_public.
GuideMe: A Mobile Application based on Global Positioning System and Object Recognition Towards a Smart Tourist Guide
May 27, 2021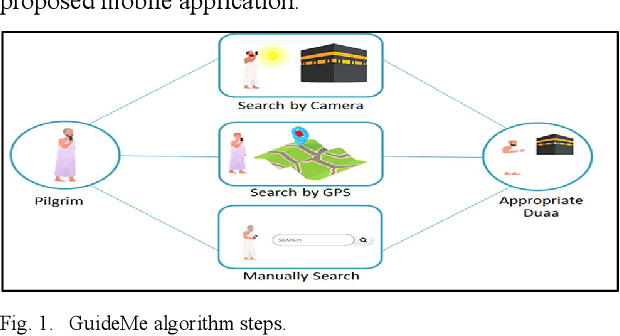



Finding information about tourist places to visit is a challenging problem that people face while visiting different countries. This problem is accentuated when people are coming from different countries, speak different languages, and are from all segments of society. In this context, visitors and pilgrims face important problems to find the appropriate doaas when visiting holy places. In this paper, we propose a mobile application that helps the user find the appropriate doaas for a given holy place in an easy and intuitive manner. Three different options are developed to achieve this goal: 1) manual search, 2) GPS location to identify the holy places and therefore their corresponding doaas, and 3) deep learning (DL) based method to determine the holy place by analyzing an image taken by the visitor. Experiments show good performance of the proposed mobile application in providing the appropriate doaas for visited holy places.
Verifying Quantized Neural Networks using SMT-Based Model Checking
Jun 10, 2021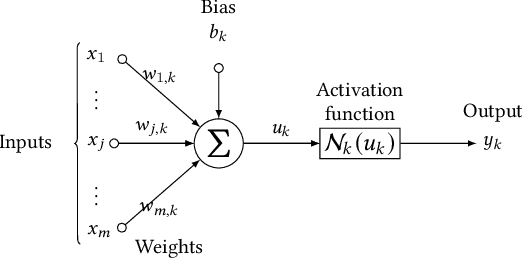
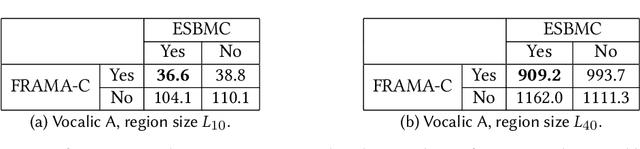
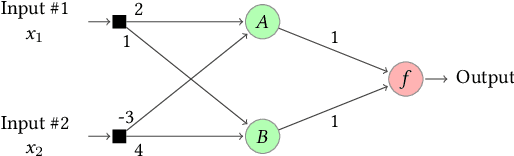
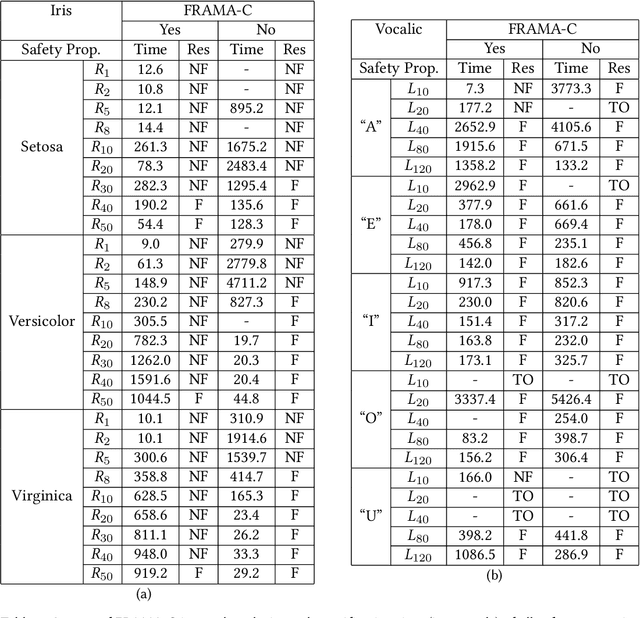
Artificial Neural Networks (ANNs) are being deployed on an increasing number of safety-critical applications, including autonomous cars and medical diagnosis. However, concerns about their reliability have been raised due to their black-box nature and apparent fragility to adversarial attacks. Here, we develop and evaluate a symbolic verification framework using incremental model checking (IMC) and satisfiability modulo theories (SMT) to check for vulnerabilities in ANNs. More specifically, we propose several ANN-related optimizations for IMC, including invariant inference via interval analysis and the discretization of non-linear activation functions. With this, we can provide guarantees on the safe behavior of ANNs implemented both in floating-point and fixed-point (quantized) arithmetic. In this regard, our verification approach was able to verify and produce adversarial examples for 52 test cases spanning image classification and general machine learning applications. For small- to medium-sized ANN, our approach completes most of its verification runs in minutes. Moreover, in contrast to most state-of-the-art methods, our approach is not restricted to specific choices of activation functions or non-quantized representations.
Deep Gaussian Scale Mixture Prior for Spectral Compressive Imaging
Mar 30, 2021
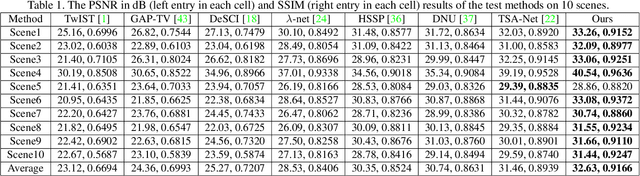
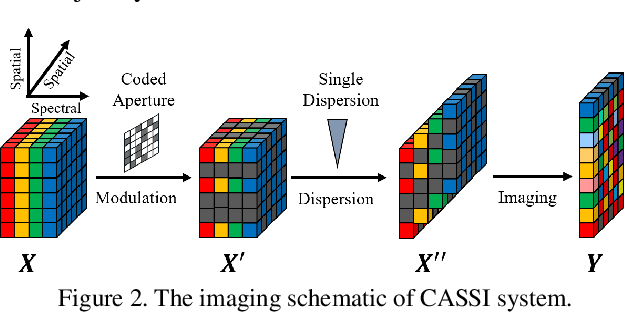
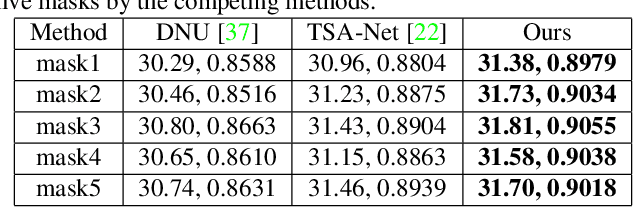
In coded aperture snapshot spectral imaging (CASSI) system, the real-world hyperspectral image (HSI) can be reconstructed from the captured compressive image in a snapshot. Model-based HSI reconstruction methods employed hand-crafted priors to solve the reconstruction problem, but most of which achieved limited success due to the poor representation capability of these hand-crafted priors. Deep learning based methods learning the mappings between the compressive images and the HSIs directly achieved much better results. Yet, it is nontrivial to design a powerful deep network heuristically for achieving satisfied results. In this paper, we propose a novel HSI reconstruction method based on the Maximum a Posterior (MAP) estimation framework using learned Gaussian Scale Mixture (GSM) prior. Different from existing GSM models using hand-crafted scale priors (e.g., the Jeffrey's prior), we propose to learn the scale prior through a deep convolutional neural network (DCNN). Furthermore, we also propose to estimate the local means of the GSM models by the DCNN. All the parameters of the MAP estimation algorithm and the DCNN parameters are jointly optimized through end-to-end training. Extensive experimental results on both synthetic and real datasets demonstrate that the proposed method outperforms existing state-of-the-art methods. The code is available at https://see.xidian.edu.cn/faculty/wsdong/Projects/DGSM-SCI.htm.
Gaze-based dual resolution deep imitation learning for high-precision dexterous robot manipulation
Mar 03, 2021
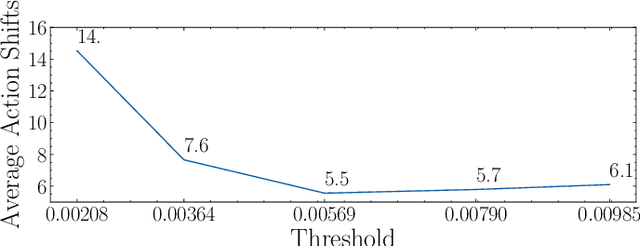

A high-precision manipulation task, such as needle threading, is challenging. Physiological studies have proposed connecting low-resolution peripheral vision and fast movement to transport the hand into the vicinity of an object, and using high-resolution foveated vision to achieve the accurate homing of the hand to the object. The results of this study demonstrate that a deep imitation learning based method, inspired by the gaze-based dual resolution visuomotor control system in humans, can solve the needle threading task. First, we recorded the gaze movements of a human operator who was teleoperating a robot. Then, we used only a high-resolution image around the gaze to precisely control the thread position when it was close to the target. We used a low-resolution peripheral image to reach the vicinity of the target. The experimental results obtained in this study demonstrate that the proposed method enables precise manipulation tasks using a general-purpose robot manipulator and improves computational efficiency.
* 8 pages. The supplementary video can be found at: https://www.youtube.com/watch?v=ytpChcFqD5g Published in IEEE Robotics and Automation Letters. Replaced to add video url in the manuscript