 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents
May 28, 2020
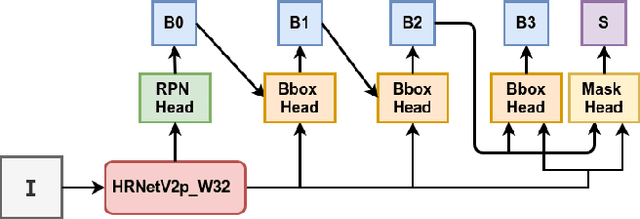
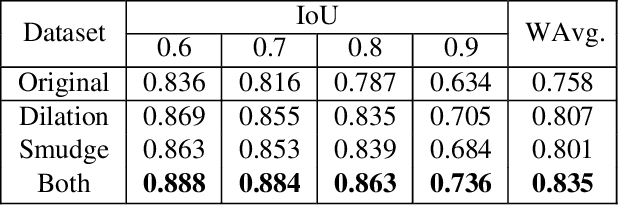
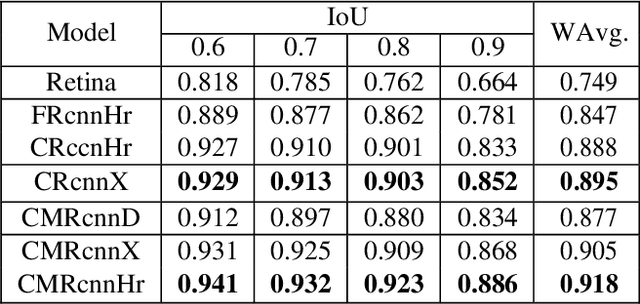
An automatic table recognition method for interpretation of tabular data in document images majorly involves solving two problems of table detection and table structure recognition. The prior work involved solving both problems independently using two separate approaches. More recent works signify the use of deep learning-based solutions while also attempting to design an end to end solution. In this paper, we present an improved deep learning-based end to end approach for solving both problems of table detection and structure recognition using a single Convolution Neural Network (CNN) model. We propose CascadeTabNet: a Cascade mask Region-based CNN High-Resolution Network (Cascade mask R-CNN HRNet) based model that detects the regions of tables and recognizes the structural body cells from the detected tables at the same time. We evaluate our results on ICDAR 2013, ICDAR 2019 and TableBank public datasets. We achieved 3rd rank in ICDAR 2019 post-competition results for table detection while attaining the best accuracy results for the ICDAR 2013 and TableBank dataset. We also attain the highest accuracy results on the ICDAR 2019 table structure recognition dataset. Additionally, we demonstrate effective transfer learning and image augmentation techniques that enable CNNs to achieve very accurate table detection results. Code and dataset has been made available at: https://github.com/DevashishPrasad/CascadeTabNet
Learning Nonparametric Human Mesh Reconstruction from a Single Image without Ground Truth Meshes
Feb 28, 2020
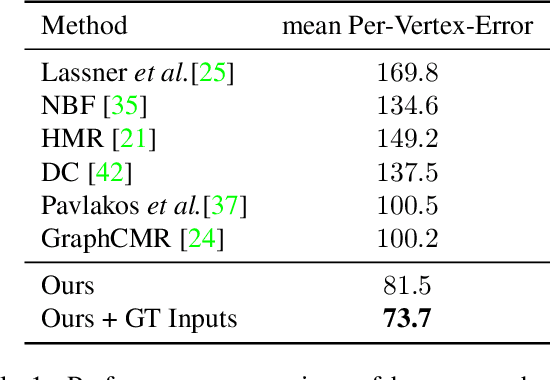
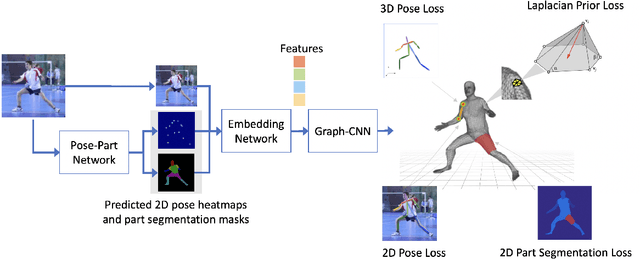

Nonparametric approaches have shown promising results on reconstructing 3D human mesh from a single monocular image. Unlike previous approaches that use a parametric human model like skinned multi-person linear model (SMPL), and attempt to regress the model parameters, nonparametric approaches relax the heavy reliance on the parametric space. However, existing nonparametric methods require ground truth meshes as their regression target for each vertex, and obtaining ground truth mesh labels is very expensive. In this paper, we propose a novel approach to learn human mesh reconstruction without any ground truth meshes. This is made possible by introducing two new terms into the loss function of a graph convolutional neural network (Graph CNN). The first term is the Laplacian prior that acts as a regularizer on the reconstructed mesh. The second term is the part segmentation loss that forces the projected region of the reconstructed mesh to match the part segmentation. Experimental results on multiple public datasets show that without using 3D ground truth meshes, the proposed approach outperforms the previous state-of-the-art approaches that require ground truth meshes for training.
Learning Camera Localization via Dense Scene Matching
Mar 31, 2021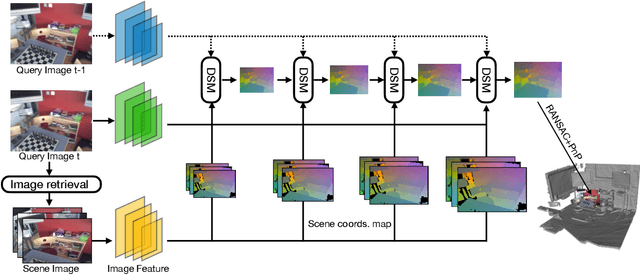
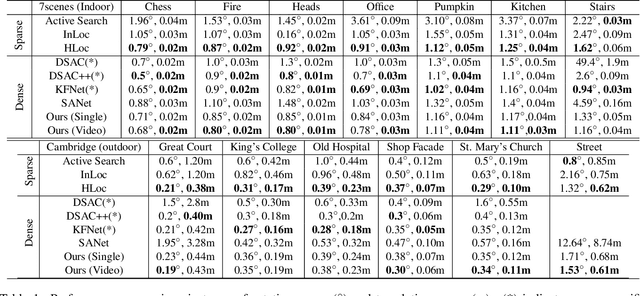
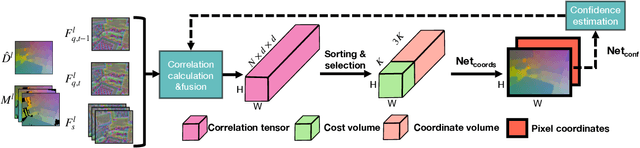
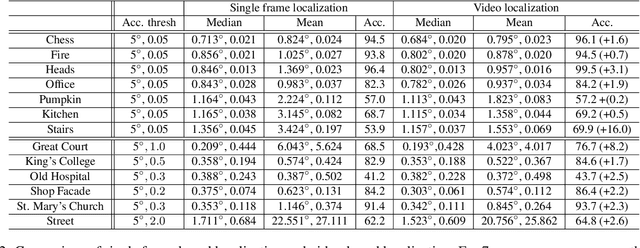
Camera localization aims to estimate 6 DoF camera poses from RGB images. Traditional methods detect and match interest points between a query image and a pre-built 3D model. Recent learning-based approaches encode scene structures into a specific convolutional neural network (CNN) and thus are able to predict dense coordinates from RGB images. However, most of them require re-training or re-adaption for a new scene and have difficulties in handling large-scale scenes due to limited network capacity. We present a new method for scene agnostic camera localization using dense scene matching (DSM), where a cost volume is constructed between a query image and a scene. The cost volume and the corresponding coordinates are processed by a CNN to predict dense coordinates. Camera poses can then be solved by PnP algorithms. In addition, our method can be extended to temporal domain, which leads to extra performance boost during testing time. Our scene-agnostic approach achieves comparable accuracy as the existing scene-specific approaches, such as KFNet, on the 7scenes and Cambridge benchmark. This approach also remarkably outperforms state-of-the-art scene-agnostic dense coordinate regression network SANet. The Code is available at https://github.com/Tangshitao/Dense-Scene-Matching.
Bridge the Gap Between Model-based and Model-free Human Reconstruction
Jun 11, 2021
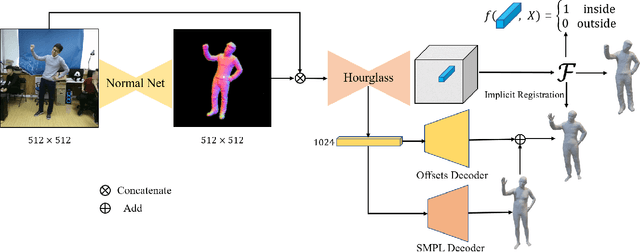

It is challenging to directly estimate the geometry of human from a single image due to the high diversity and complexity of body shapes with the various clothing styles. Most of model-based approaches are limited to predict the shape and pose of a minimally clothed body with over-smoothing surface. Although capturing the fine detailed geometries, the model-free methods are lack of the fixed mesh topology. To address these issues, we propose a novel topology-preserved human reconstruction approach by bridging the gap between model-based and model-free human reconstruction. We present an end-to-end neural network that simultaneously predicts the pixel-aligned implicit surface and the explicit mesh model built by graph convolutional neural network. Moreover, an extra graph convolutional neural network is employed to estimate the vertex offsets between the implicit surface and parametric mesh model. Finally, we suggest an efficient implicit registration method to refine the neural network output in implicit space. Experiments on DeepHuman dataset showed that our approach is effective.
Hand Gesture Recognition Based on a Nonconvex Regularization
Apr 30, 2021
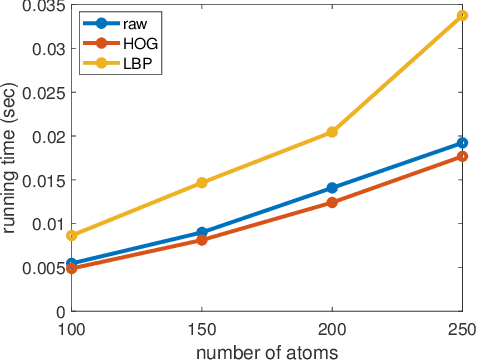


Recognition of hand gestures is one of the most fundamental tasks in human-robot interaction. Sparse representation based methods have been widely used due to their efficiency and low requirements on the training data. Recently, nonconvex regularization techniques including the $\ell_{1-2}$ regularization have been proposed in the image processing community to promote sparsity while achieving efficient performance. In this paper, we propose a vision-based hand gesture recognition model based on the $\ell_{1-2}$ regularization, which is solved by the alternating direction method of multipliers (ADMM). Numerical experiments on binary and gray-scale data sets have shown the effectiveness of this method in identifying hand gestures.
AppealNet: An Efficient and Highly-Accurate Edge/Cloud Collaborative Architecture for DNN Inference
May 12, 2021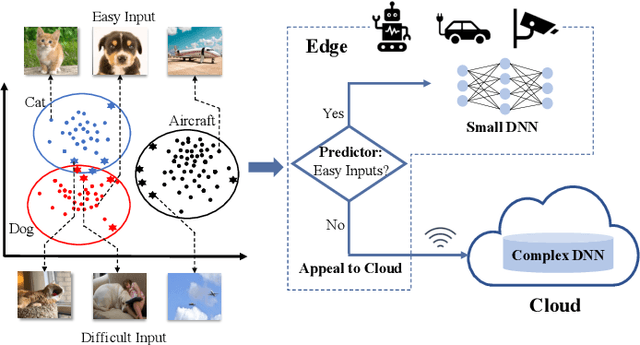
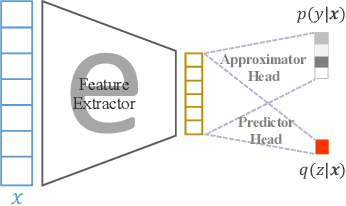
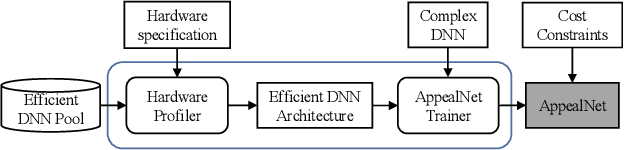
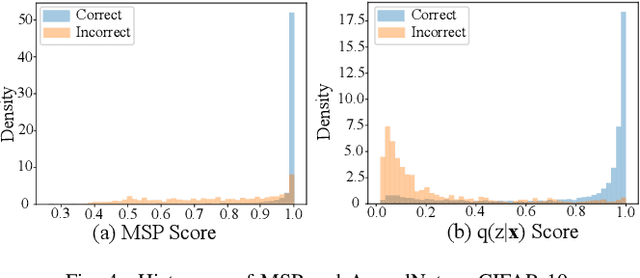
This paper presents AppealNet, a novel edge/cloud collaborative architecture that runs deep learning (DL) tasks more efficiently than state-of-the-art solutions. For a given input, AppealNet accurately predicts on-the-fly whether it can be successfully processed by the DL model deployed on the resource-constrained edge device, and if not, appeals to the more powerful DL model deployed at the cloud. This is achieved by employing a two-head neural network architecture that explicitly takes inference difficulty into consideration and optimizes the tradeoff between accuracy and computation/communication cost of the edge/cloud collaborative architecture. Experimental results on several image classification datasets show up to more than 40% energy savings compared to existing techniques without sacrificing accuracy.
Pose2Drone: A Skeleton-Pose-based Framework for Human-Drone Interaction
May 28, 2021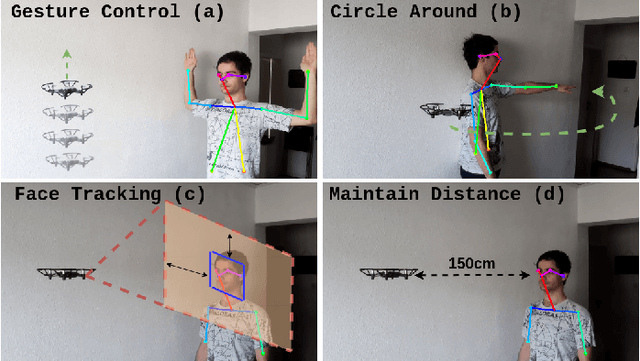


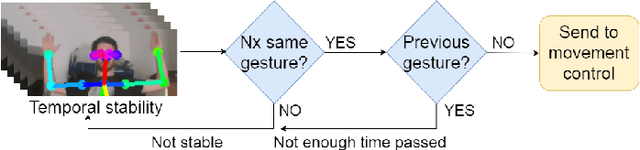
Drones have become a common tool, which is utilized in many tasks such as aerial photography, surveillance, and delivery. However, operating a drone requires more and more interaction with the user. A natural and safe method for Human-Drone Interaction (HDI) is using gestures. In this paper, we introduce an HDI framework building upon skeleton-based pose estimation. Our framework provides the functionality to control the movement of the drone with simple arm gestures and to follow the user while keeping a safe distance. We also propose a monocular distance estimation method, which is entirely based on image features and does not require any additional depth sensors. To perform comprehensive experiments and quantitative analysis, we create a customized testing dataset. The experiments indicate that our HDI framework can achieve an average of 93.5\% accuracy in the recognition of 11 common gestures. The code is available at: https://github.com/Zrrr1997/Pose2Drone
DepthwiseGANs: Fast Training Generative Adversarial Networks for Realistic Image Synthesis
Mar 06, 2019
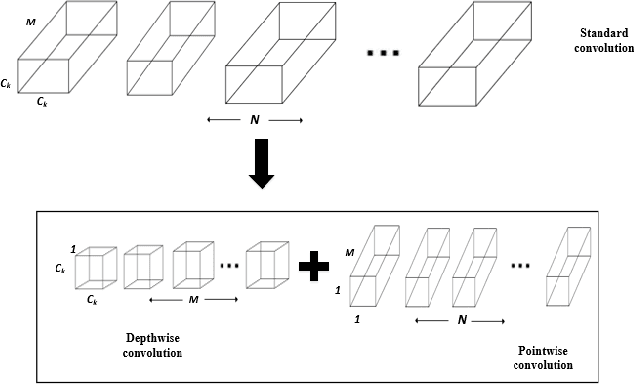
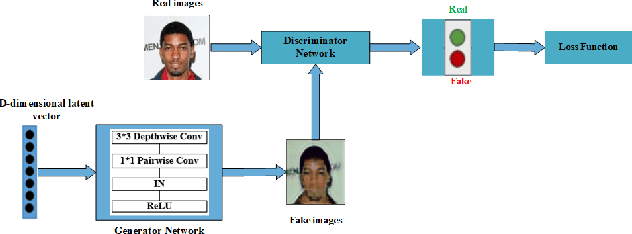
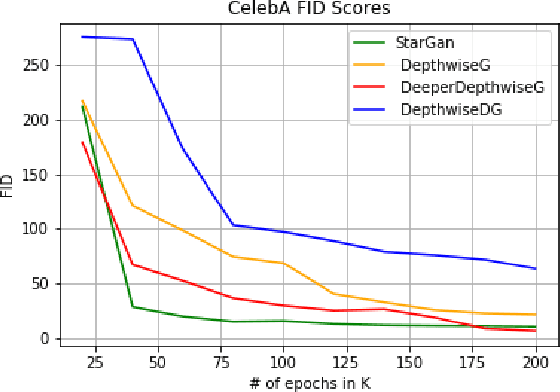
Recent work has shown significant progress in the direction of synthetic data generation using Generative Adversarial Networks (GANs). GANs have been applied in many fields of computer vision including text-to-image conversion, domain transfer, super-resolution, and image-to-video applications. In computer vision, traditional GANs are based on deep convolutional neural networks. However, deep convolutional neural networks can require extensive computational resources because they are based on multiple operations performed by convolutional layers, which can consist of millions of trainable parameters. Training a GAN model can be difficult and it takes a significant amount of time to reach an equilibrium point. In this paper, we investigate the use of depthwise separable convolutions to reduce training time while maintaining data generation performance. Our results show that a DepthwiseGAN architecture can generate realistic images in shorter training periods when compared to a StarGan architecture, but that model capacity still plays a significant role in generative modelling. In addition, we show that depthwise separable convolutions perform best when only applied to the generator. For quality evaluation of generated images, we use the Fr\'echet Inception Distance (FID), which compares the similarity between the generated image distribution and that of the training dataset.
Multiscale Invertible Generative Networks for High-Dimensional Bayesian Inference
May 12, 2021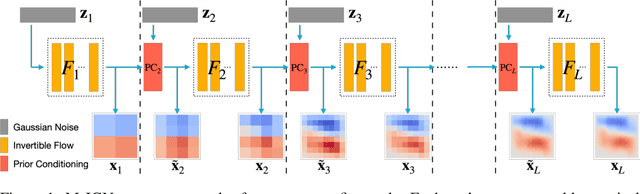
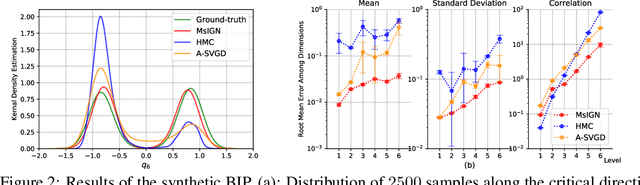
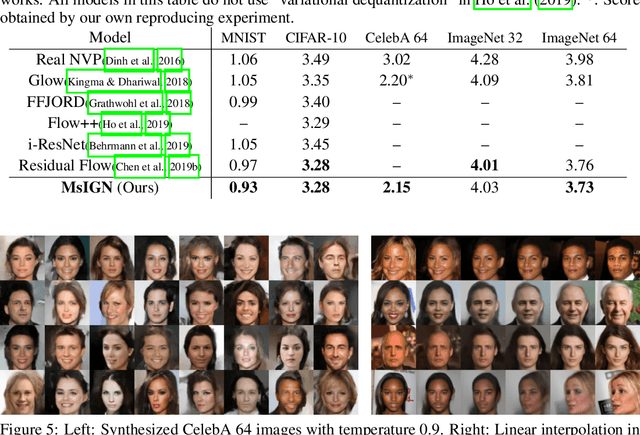
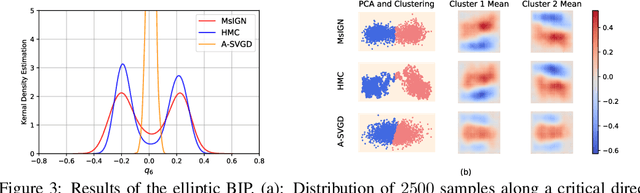
We propose a Multiscale Invertible Generative Network (MsIGN) and associated training algorithm that leverages multiscale structure to solve high-dimensional Bayesian inference. To address the curse of dimensionality, MsIGN exploits the low-dimensional nature of the posterior, and generates samples from coarse to fine scale (low to high dimension) by iteratively upsampling and refining samples. MsIGN is trained in a multi-stage manner to minimize the Jeffreys divergence, which avoids mode dropping in high-dimensional cases. On two high-dimensional Bayesian inverse problems, we show superior performance of MsIGN over previous approaches in posterior approximation and multiple mode capture. On the natural image synthesis task, MsIGN achieves superior performance in bits-per-dimension over baseline models and yields great interpret-ability of its neurons in intermediate layers.
Learning Uncertainty For Safety-Oriented Semantic Segmentation In Autonomous Driving
May 28, 2021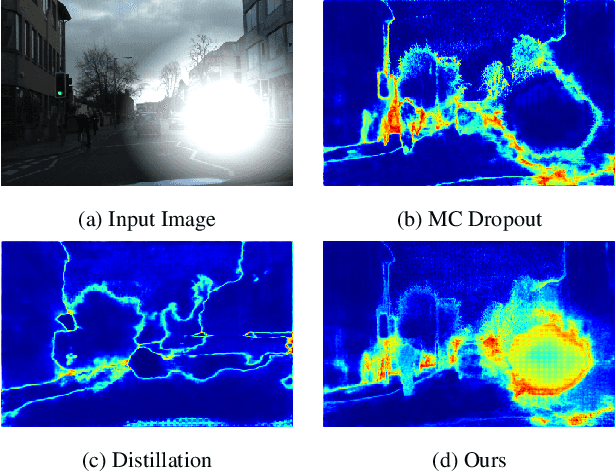
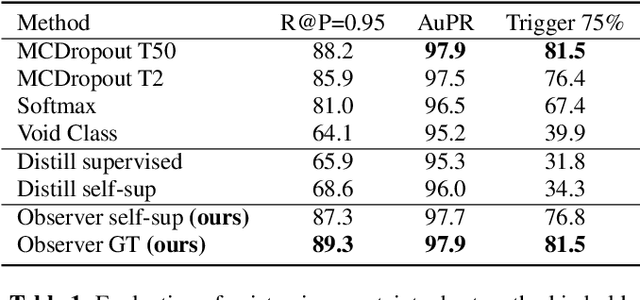
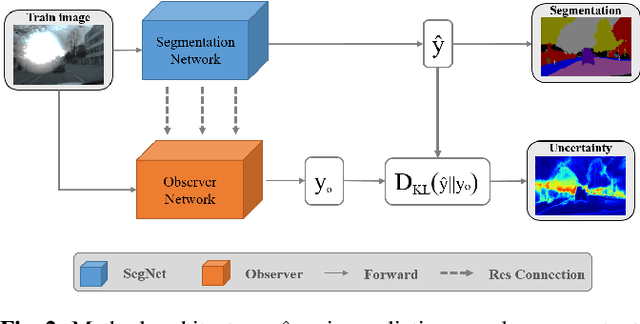
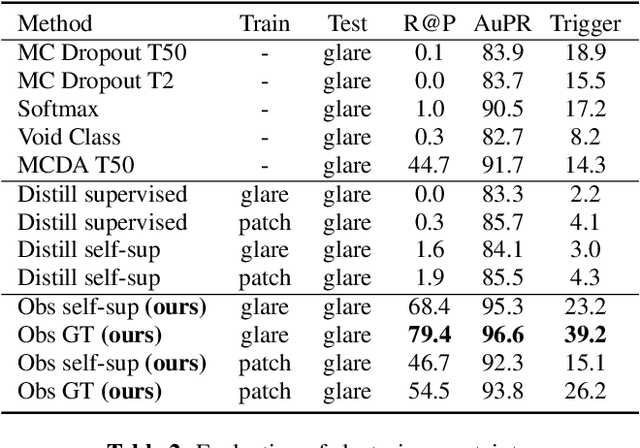
In this paper, we show how uncertainty estimation can be leveraged to enable safety critical image segmentation in autonomous driving, by triggering a fallback behavior if a target accuracy cannot be guaranteed. We introduce a new uncertainty measure based on disagreeing predictions as measured by a dissimilarity function. We propose to estimate this dissimilarity by training a deep neural architecture in parallel to the task-specific network. It allows this observer to be dedicated to the uncertainty estimation, and let the task-specific network make predictions. We propose to use self-supervision to train the observer, which implies that our method does not require additional training data. We show experimentally that our proposed approach is much less computationally intensive at inference time than competing methods (e.g. MCDropout), while delivering better results on safety-oriented evaluation metrics on the CamVid dataset, especially in the case of glare artifacts.