 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Probabilistic Bitwise Genetic Algorithm for B-Spline based Image Deformation Estimation
Mar 26, 2019
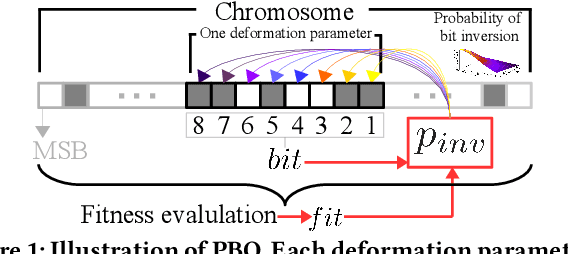
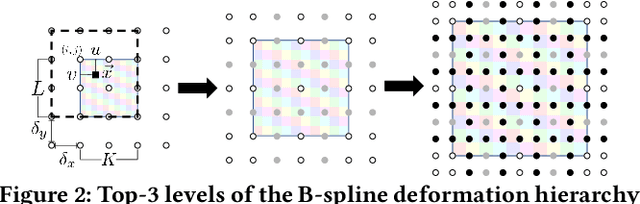
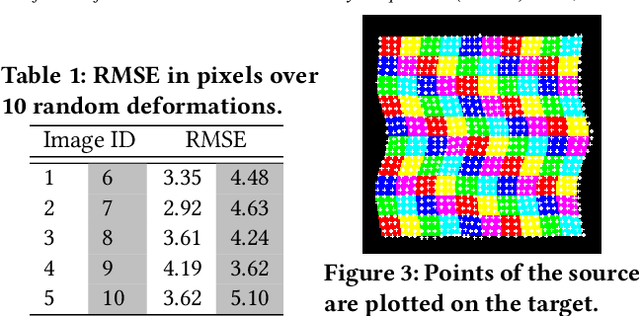
We propose a novel genetic algorithm to solve the image deformation estimation problem by preserving the genetic diversity. As a classical problem, there is always a trade-off between the complexity of deformation models and the difficulty of parameters search in image deformation. 2D cubic B-spline surface is a highly free-form deformation model and is able to handle complex deformations such as fluid image distortions. However, it is challenging to estimate an apposite global solution. To tackle this problem, we develop a genetic operation named probabilistic bitwise operation (PBO) to replace the crossover and mutation operations, which can preserve the diversity during generation iteration and achieve better coverage ratio of the solution space. Furthermore, a selection strategy named annealing selection is proposed to control the convergence. Qualitative and quantitative results on synthetic data show the effectiveness of our method.
Salvage of Supervision in Weakly Supervised Detection
Jun 08, 2021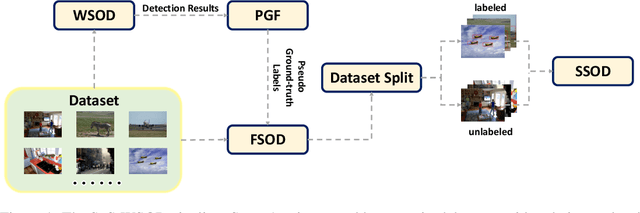
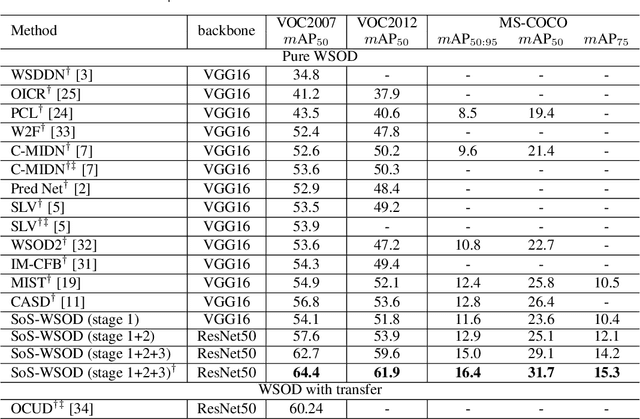


Weakly supervised object detection (WSOD) has recently attracted much attention. However, the method, performance and speed gaps between WSOD and fully supervised detection prevent WSOD from being applied in real-world tasks. To bridge the gaps, this paper proposes a new framework, Salvage of Supervision (SoS), with the key idea being to harness every potentially useful supervisory signal in WSOD: the weak image-level labels, the pseudo-labels, and the power of semi-supervised object detection. This paper shows that each type of supervisory signal brings in notable improvements, outperforms existing WSOD methods (which mainly use only the weak labels) by large margins. The proposed SoS-WSOD method achieves 64.4 $m\text{AP}_{50}$ on VOC2007, 61.9 $m\text{AP}_{50}$ on VOC2012 and 16.4 $m\text{AP}_{50:95}$ on MS-COCO, and also has fast inference speed. Ablations and visualization further verify the effectiveness of SoS.
Mutual Information Maximization on Disentangled Representations for Differential Morph Detection
Dec 02, 2020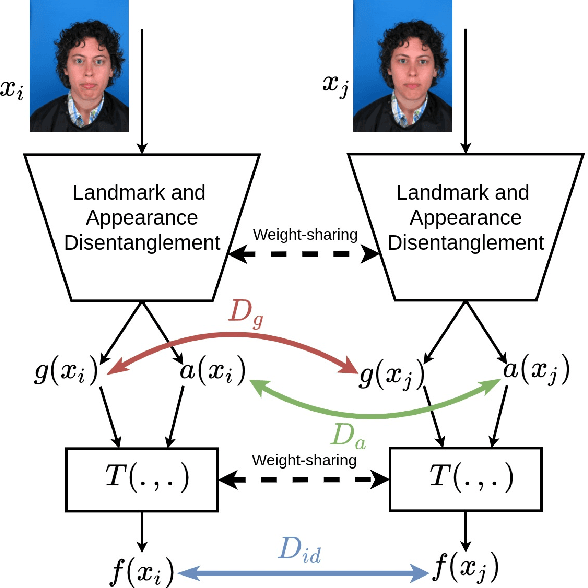
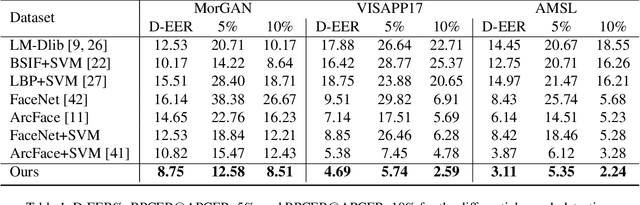
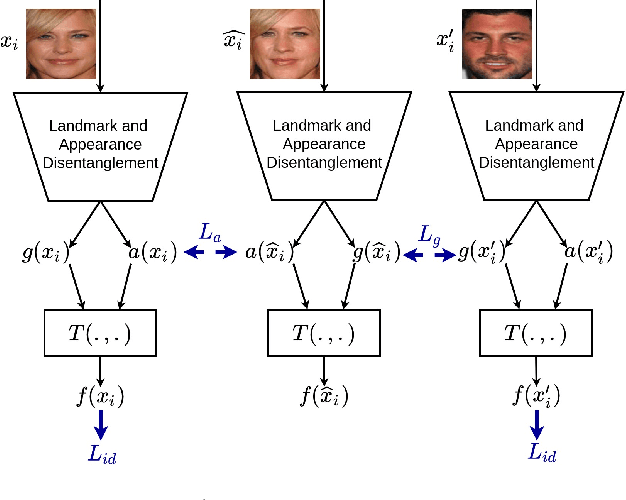
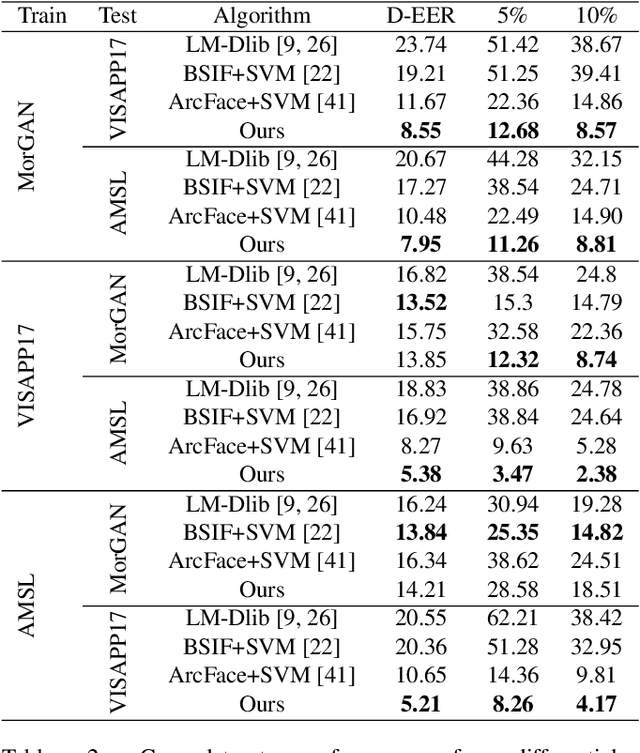
In this paper, we present a novel differential morph detection framework, utilizing landmark and appearance disentanglement. In our framework, the face image is represented in the embedding domain using two disentangled but complementary representations. The network is trained by triplets of face images, in which the intermediate image inherits the landmarks from one image and the appearance from the other image. This initially trained network is further trained for each dataset using contrastive representations. We demonstrate that, by employing appearance and landmark disentanglement, the proposed framework can provide state-of-the-art differential morph detection performance. This functionality is achieved by the using distances in landmark, appearance, and ID domains. The performance of the proposed framework is evaluated using three morph datasets generated with different methodologies.
Towards Imperceptible Adversarial Image Patches Based on Network Explanations
Dec 10, 2020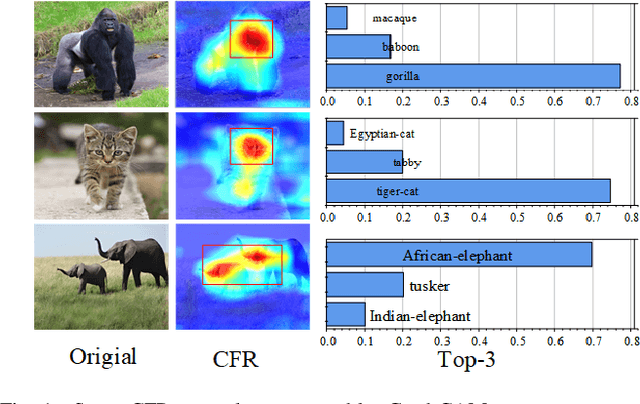
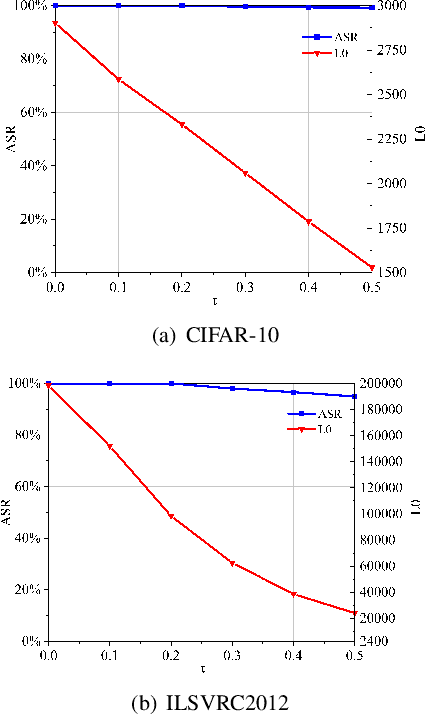

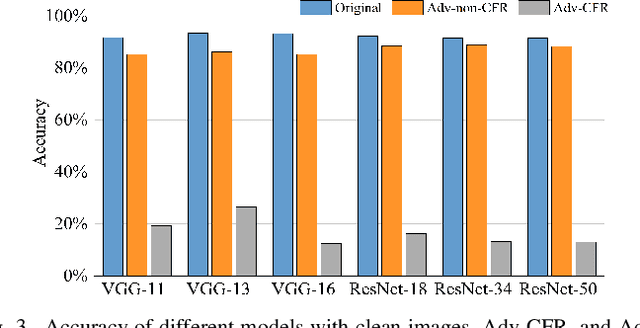
The vulnerability of deep neural networks (DNNs) for adversarial examples have attracted more attention. Many algorithms are proposed to craft powerful adversarial examples. However, these algorithms modifying the global or local region of pixels without taking into account network explanations. Hence, the perturbations are redundancy and easily detected by human eyes. In this paper, we propose a novel method to generate local region perturbations. The main idea is to find the contributing feature regions (CFRs) of images based on network explanations for perturbations. Due to the network explanations, the perturbations added to the CFRs are more effective than other regions. In our method, a soft mask matrix is designed to represent the CFRs for finely characterizing the contributions of each pixel. Based on this soft mask, we develop a new objective function with inverse temperature to search for optimal perturbations in CFRs. Extensive experiments are conducted on CIFAR-10 and ILSVRC2012, which demonstrate the effectiveness, including attack success rate, imperceptibility,and transferability.
Ensemble Augmentation for Deep Neural Networks Using 1-D Time Series Vibration Data
Aug 06, 2021
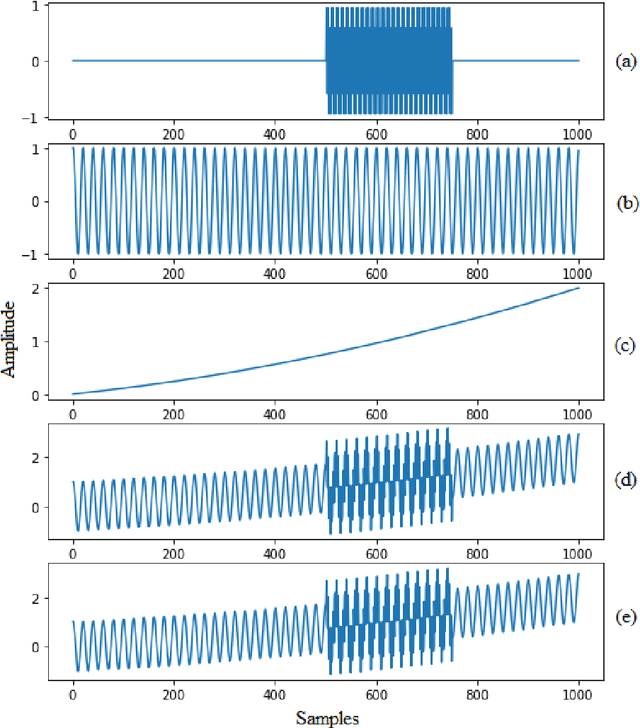
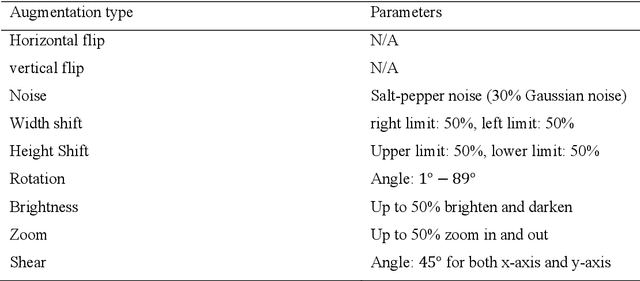
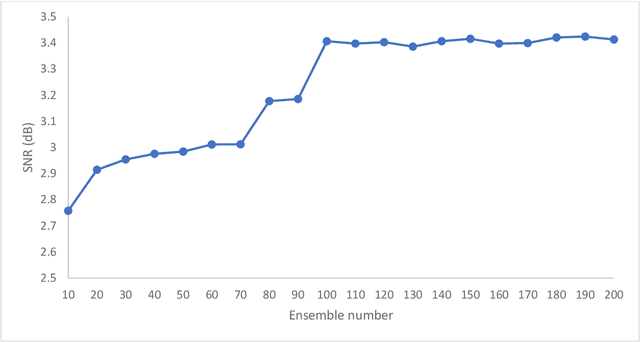
Time-series data are one of the fundamental types of raw data representation used in data-driven techniques. In machine condition monitoring, time-series vibration data are overly used in data mining for deep neural networks. Typically, vibration data is converted into images for classification using Deep Neural Networks (DNNs), and scalograms are the most effective form of image representation. However, the DNN classifiers require huge labeled training samples to reach their optimum performance. So, many forms of data augmentation techniques are applied to the classifiers to compensate for the lack of training samples. However, the scalograms are graphical representations where the existing augmentation techniques suffer because they either change the graphical meaning or have too much noise in the samples that change the physical meaning. In this study, a data augmentation technique named ensemble augmentation is proposed to overcome this limitation. This augmentation method uses the power of white noise added in ensembles to the original samples to generate real-like samples. After averaging the signal with ensembles, a new signal is obtained that contains the characteristics of the original signal. The parameters for the ensemble augmentation are validated using a simulated signal. The proposed method is evaluated using 10 class bearing vibration data using three state-of-the-art Transfer Learning (TL) models, namely, Inception-V3, MobileNet-V2, and ResNet50. Augmented samples are generated in two increments: the first increment generates the same number of fake samples as the training samples, and in the second increment, the number of samples is increased gradually. The outputs from the proposed method are compared with no augmentation, augmentations using deep convolution generative adversarial network (DCGAN), and several geometric transformation-based augmentations...
On instabilities of deep learning in image reconstruction - Does AI come at a cost?
Feb 14, 2019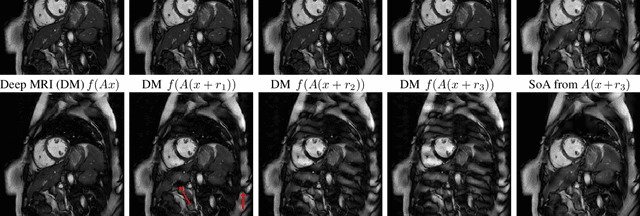
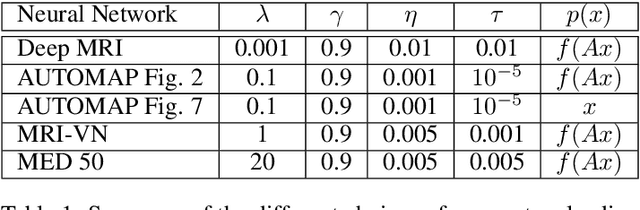
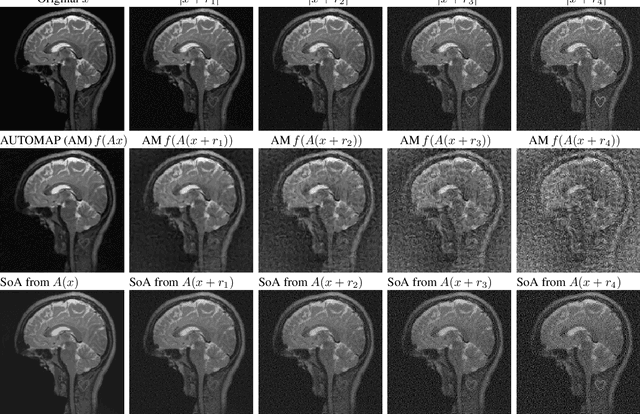
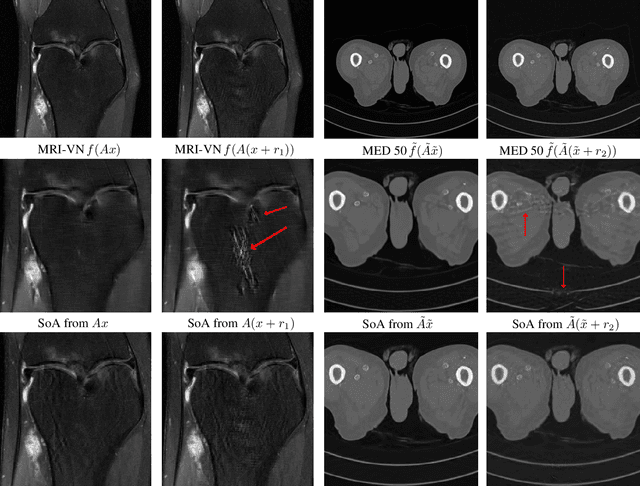
Deep learning, due to its unprecedented success in tasks such as image classification, has emerged as a new tool in image reconstruction with potential to change the field. In this paper we demonstrate a crucial phenomenon: deep learning typically yields unstablemethods for image reconstruction. The instabilities usually occur in several forms: (1) tiny, almost undetectable perturbations, both in the image and sampling domain, may result in severe artefacts in the reconstruction, (2) a small structural change, for example a tumour, may not be captured in the reconstructed image and (3) (a counterintuitive type of instability) more samples may yield poorer performance. Our new stability test with algorithms and easy to use software detects the instability phenomena. The test is aimed at researchers to test their networks for instabilities and for government agencies, such as the Food and Drug Administration (FDA), to secure safe use of deep learning methods.
A comparative study of various Deep Learning techniques for spatio-temporal Super-Resolution reconstruction of Forced Isotropic Turbulent flows
Jul 07, 2021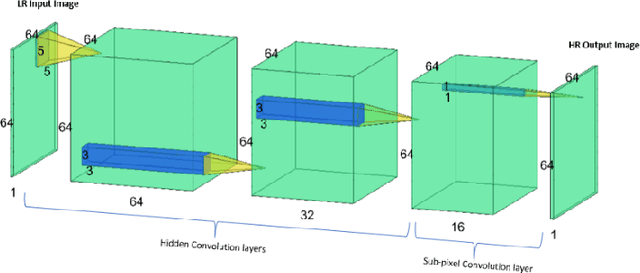
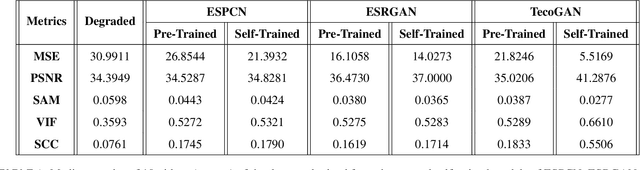
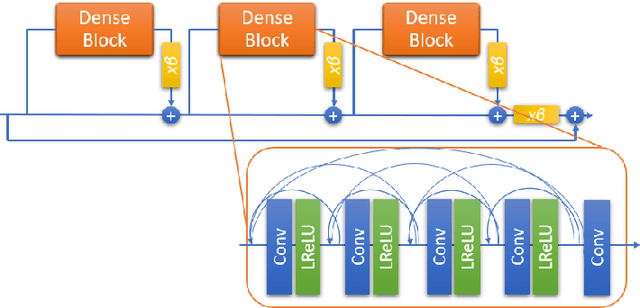
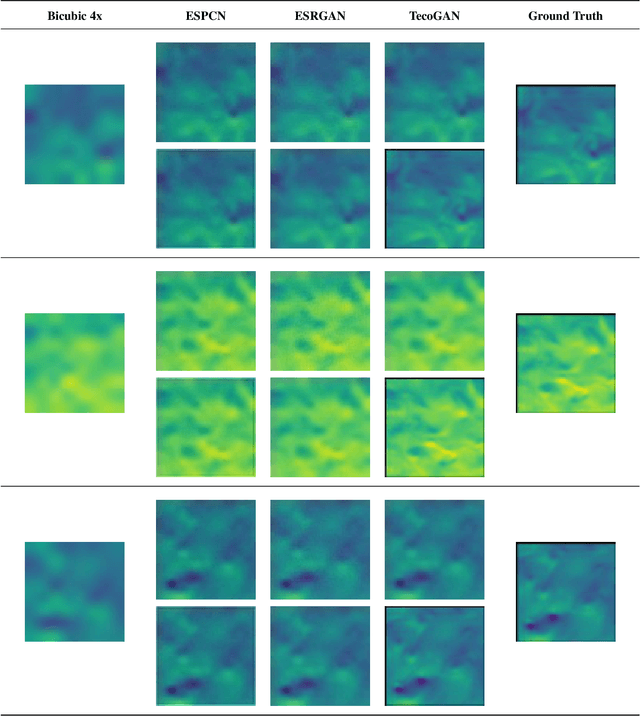
Super-resolution is an innovative technique that upscales the resolution of an image or a video and thus enables us to reconstruct high-fidelity images from low-resolution data. This study performs super-resolution analysis on turbulent flow fields spatially and temporally using various state-of-the-art machine learning techniques like ESPCN, ESRGAN and TecoGAN to reconstruct high-resolution flow fields from low-resolution flow field data, especially keeping in mind the need for low resource consumption and rapid results production/verification. The dataset used for this study is extracted from the 'isotropic 1024 coarse' dataset which is a part of Johns Hopkins Turbulence Databases (JHTDB). We have utilized pre-trained models and fine tuned them to our needs, so as to minimize the computational resources and the time required for the implementation of the super-resolution models. The advantages presented by this method far exceed the expectations and the outcomes of regular single structure models. The results obtained through these models are then compared using MSE, PSNR, SAM, VIF and SCC metrics in order to evaluate the upscaled results, find the balance between computational power and output quality, and then identify the most accurate and efficient model for spatial and temporal super-resolution of turbulent flow fields.
Explainable Deep Few-shot Anomaly Detection with Deviation Networks
Aug 01, 2021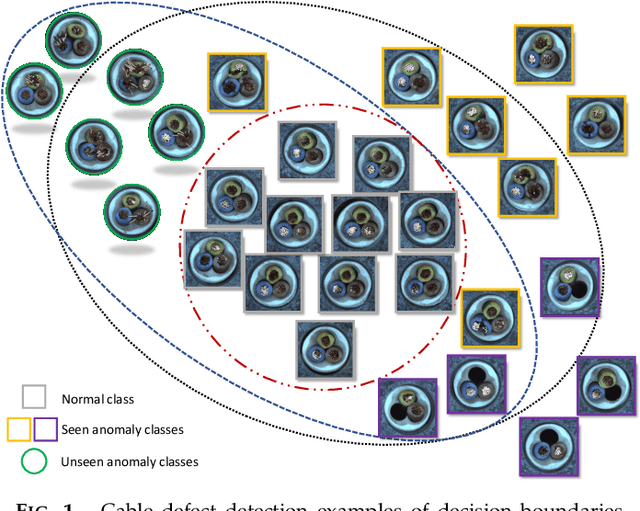
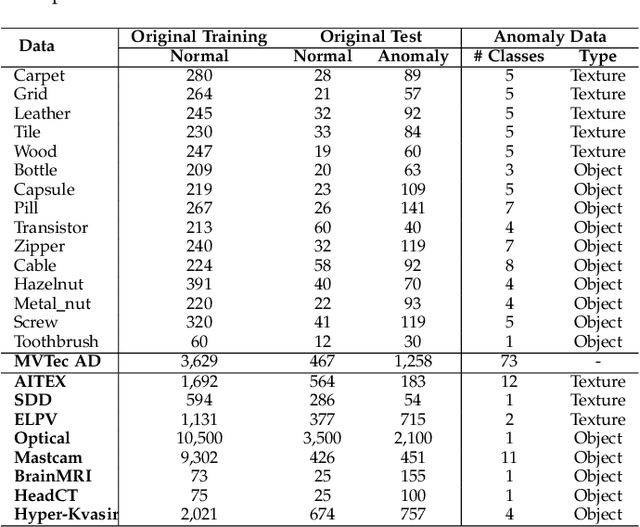
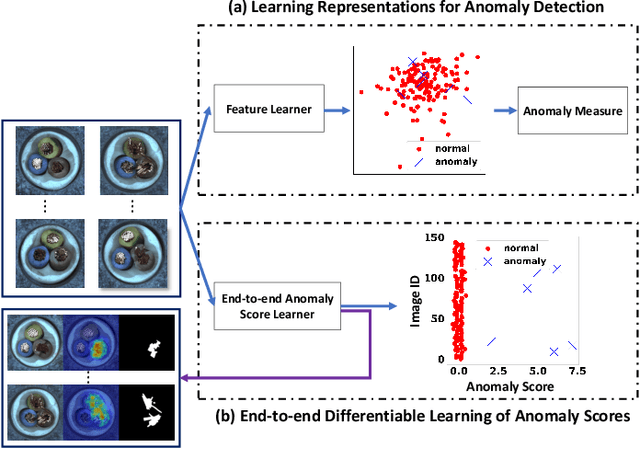
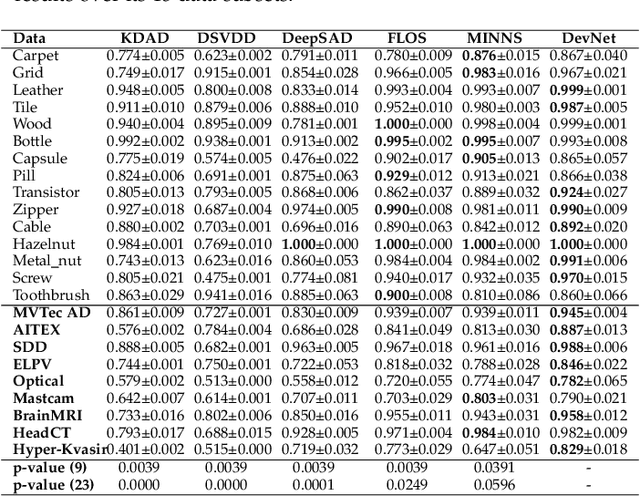
Existing anomaly detection paradigms overwhelmingly focus on training detection models using exclusively normal data or unlabeled data (mostly normal samples). One notorious issue with these approaches is that they are weak in discriminating anomalies from normal samples due to the lack of the knowledge about the anomalies. Here, we study the problem of few-shot anomaly detection, in which we aim at using a few labeled anomaly examples to train sample-efficient discriminative detection models. To address this problem, we introduce a novel weakly-supervised anomaly detection framework to train detection models without assuming the examples illustrating all possible classes of anomaly. Specifically, the proposed approach learns discriminative normality (regularity) by leveraging the labeled anomalies and a prior probability to enforce expressive representations of normality and unbounded deviated representations of abnormality. This is achieved by an end-to-end optimization of anomaly scores with a neural deviation learning, in which the anomaly scores of normal samples are imposed to approximate scalar scores drawn from the prior while that of anomaly examples is enforced to have statistically significant deviations from these sampled scores in the upper tail. Furthermore, our model is optimized to learn fine-grained normality and abnormality by top-K multiple-instance-learning-based feature subspace deviation learning, allowing more generalized representations. Comprehensive experiments on nine real-world image anomaly detection benchmarks show that our model is substantially more sample-efficient and robust, and performs significantly better than state-of-the-art competing methods in both closed-set and open-set settings. Our model can also offer explanation capability as a result of its prior-driven anomaly score learning. Code and datasets are available at: https://git.io/DevNet.
A Hierarchical Approach for Visual Storytelling Using Image Description
Sep 26, 2019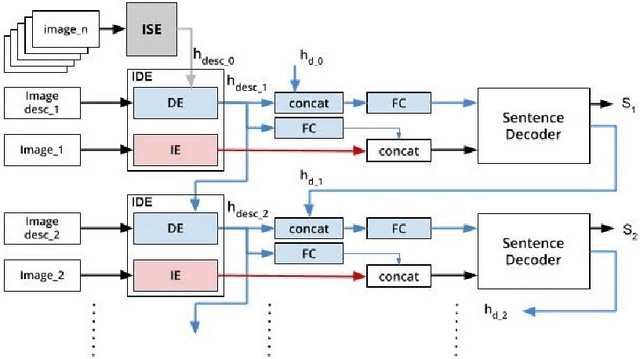
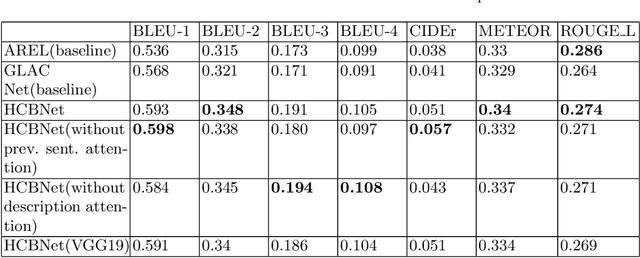
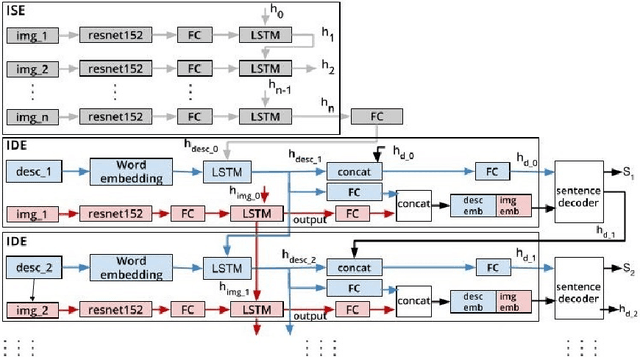
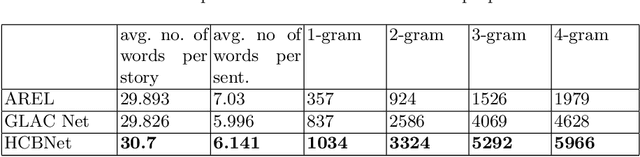
One of the primary challenges of visual storytelling is developing techniques that can maintain the context of the story over long event sequences to generate human-like stories. In this paper, we propose a hierarchical deep learning architecture based on encoder-decoder networks to address this problem. To better help our network maintain this context while also generating long and diverse sentences, we incorporate natural language image descriptions along with the images themselves to generate each story sentence. We evaluate our system on the Visual Storytelling (VIST) dataset and show that our method outperforms state-of-the-art techniques on a suite of different automatic evaluation metrics. The empirical results from this evaluation demonstrate the necessities of different components of our proposed architecture and shows the effectiveness of the architecture for visual storytelling.
Language Guided Fashion Image Manipulation with Feature-wise Transformations
Aug 12, 2018

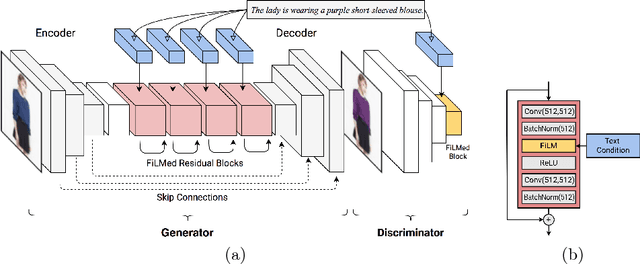

Developing techniques for editing an outfit image through natural sentences and accordingly generating new outfits has promising applications for art, fashion and design. However, it is considered as a certainly challenging task since image manipulation should be carried out only on the relevant parts of the image while keeping the remaining sections untouched. Moreover, this manipulation process should generate an image that is as realistic as possible. In this work, we propose FiLMedGAN, which leverages feature-wise linear modulation (FiLM) to relate and transform visual features with natural language representations without using extra spatial information. Our experiments demonstrate that this approach, when combined with skip connections and total variation regularization, produces more plausible results than the baseline work, and has a better localization capability when generating new outfits consistent with the target description.