 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spectro-Temporal RF Identification using Deep Learning
Jul 11, 2021
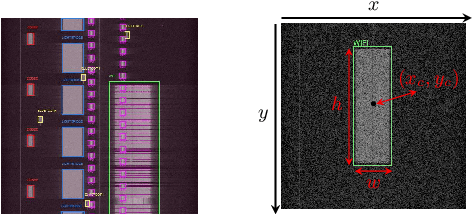
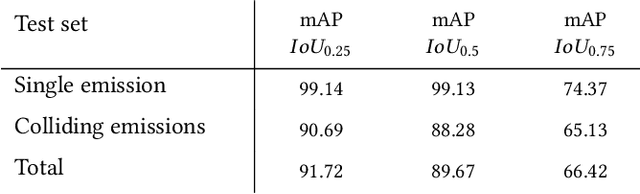


RF emissions detection, classification, and spectro-temporal localization are crucial not only for tasks relating to understanding, managing, and protecting the RF spectrum, but also for safety and security applications such as detecting intruding drones or jammers. Achieving this goal for wideband spectrum and in real-time performance is a challenging problem. We present WRIST, a Wideband, Real-time RF Identification system with Spectro-Temporal detection, framework and system. Our resulting deep learning model is capable to detect, classify, and precisely locate RF emissions in time and frequency using RF samples of 100 MHz spectrum in real-time (over 6Gbps incoming I&Q streams). Such capabilities are made feasible by leveraging a deep-learning based one-stage object detection framework, and transfer learning to a multi-channel image-based RF signals representation. We also introduce an iterative training approach which leverages synthesized and augmented RF data to efficiently build large labelled datasets of RF emissions (SPREAD). WRIST detector achieves 90 mean Average Precision even in extremely congested environment in the wild. WRIST model classifies five technologies (Bluetooth, Lightbridge, Wi-Fi, XPD, and ZigBee) and is easily extendable to others. We are making our curated and annotated dataset available to the whole community. It consists of nearly 1 million fully labelled RF emissions collected from various off-the-shelf wireless radios in a range of environments and spanning the five classes of emissions.
R-Drop: Regularized Dropout for Neural Networks
Jun 28, 2021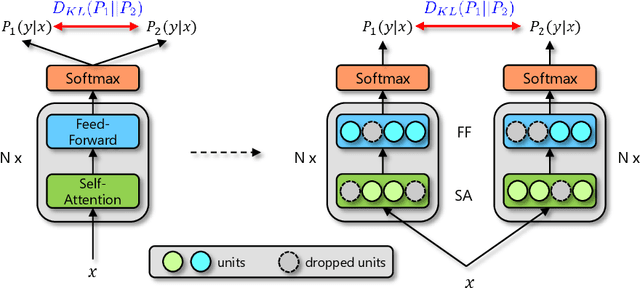

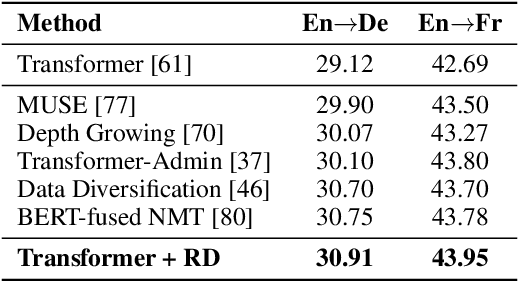
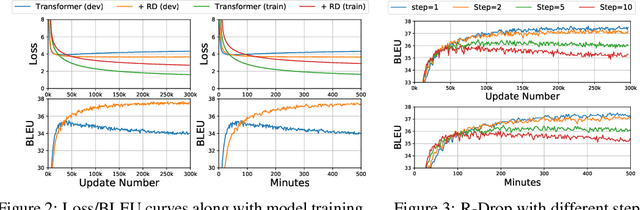
Dropout is a powerful and widely used technique to regularize the training of deep neural networks. In this paper, we introduce a simple regularization strategy upon dropout in model training, namely R-Drop, which forces the output distributions of different sub models generated by dropout to be consistent with each other. Specifically, for each training sample, R-Drop minimizes the bidirectional KL-divergence between the output distributions of two sub models sampled by dropout. Theoretical analysis reveals that R-Drop reduces the freedom of the model parameters and complements dropout. Experiments on $\bf{5}$ widely used deep learning tasks ($\bf{18}$ datasets in total), including neural machine translation, abstractive summarization, language understanding, language modeling, and image classification, show that R-Drop is universally effective. In particular, it yields substantial improvements when applied to fine-tune large-scale pre-trained models, e.g., ViT, RoBERTa-large, and BART, and achieves state-of-the-art (SOTA) performances with the vanilla Transformer model on WMT14 English$\to$German translation ($\bf{30.91}$ BLEU) and WMT14 English$\to$French translation ($\bf{43.95}$ BLEU), even surpassing models trained with extra large-scale data and expert-designed advanced variants of Transformer models. Our code is available at GitHub{\url{https://github.com/dropreg/R-Drop}}.
Watching You: Global-guided Reciprocal Learning for Video-based Person Re-identification
Apr 01, 2021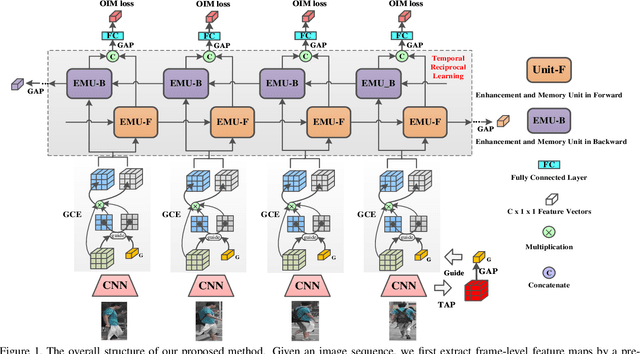
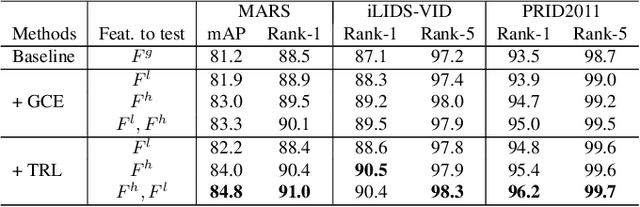
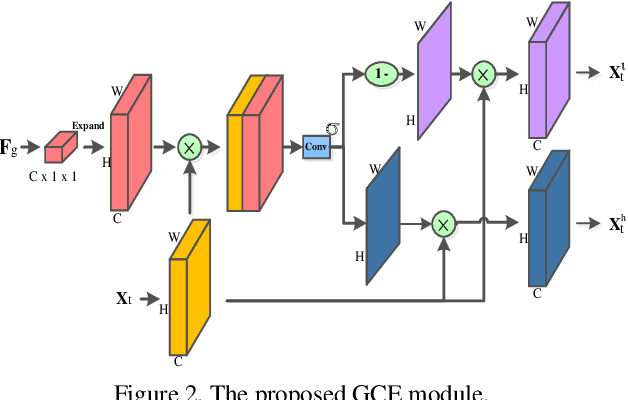
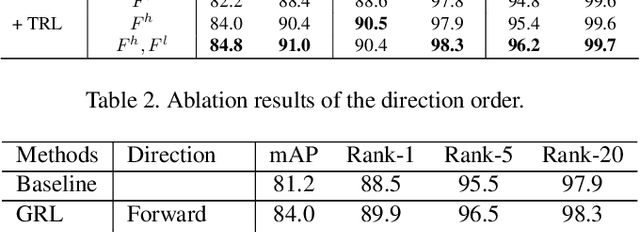
Video-based person re-identification (Re-ID) aims to automatically retrieve video sequences of the same person under non-overlapping cameras. To achieve this goal, it is the key to fully utilize abundant spatial and temporal cues in videos. Existing methods usually focus on the most conspicuous image regions, thus they may easily miss out fine-grained clues due to the person varieties in image sequences. To address above issues, in this paper, we propose a novel Global-guided Reciprocal Learning (GRL) framework for video-based person Re-ID. Specifically, we first propose a Global-guided Correlation Estimation (GCE) to generate feature correlation maps of local features and global features, which help to localize the high- and low-correlation regions for identifying the same person. After that, the discriminative features are disentangled into high-correlation features and low-correlation features under the guidance of the global representations. Moreover, a novel Temporal Reciprocal Learning (TRL) mechanism is designed to sequentially enhance the high-correlation semantic information and accumulate the low-correlation sub-critical clues. Extensive experiments are conducted on three public benchmarks. The experimental results indicate that our approach can achieve better performance than other state-of-the-art approaches. The code is released at https://github.com/flysnowtiger/GRL.
Ultrasound Classification of Breast Masses Using a Comprehensive Nakagami Imaging and Machine Learning Framework
Jun 20, 2021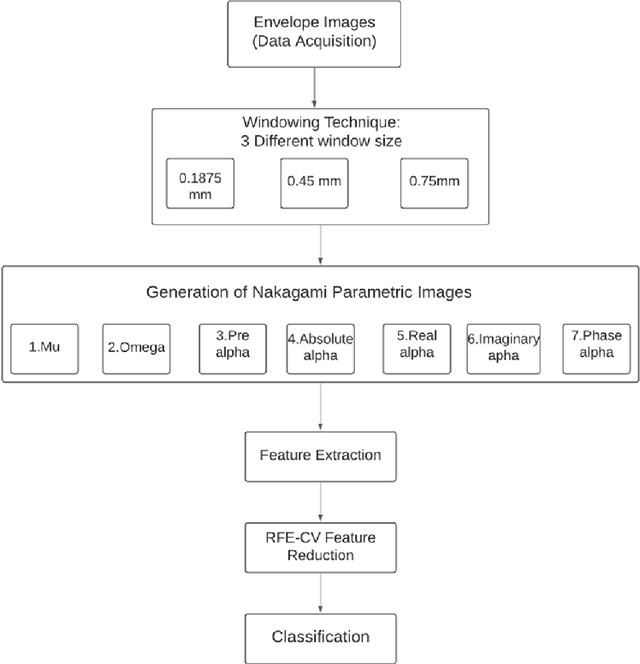
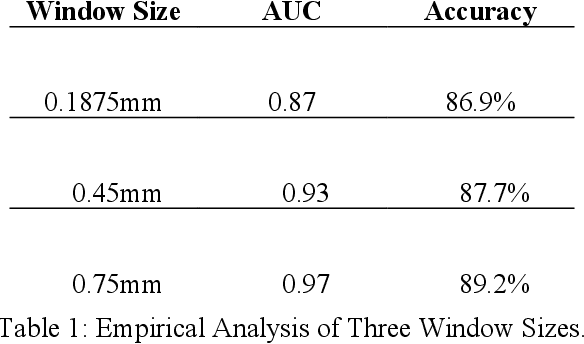

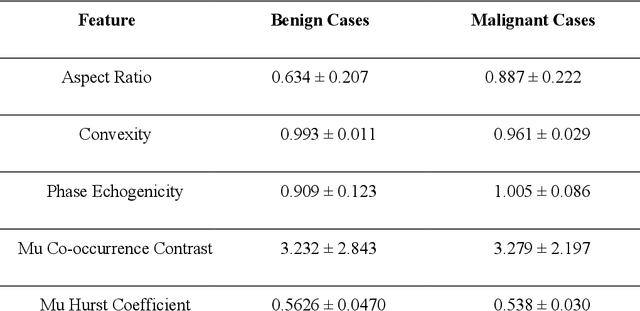
In this study we investigate the potential of parametric images formed from ultrasound B-mode scans using the Nakagami distribution for non-invasive classification of breast lesions. Through a sliding window technique, we generated seven types of parametric images from each patient scan in our dataset using basic and as well as derived parameters of the Nakagami distribution. To determine the most suitable window size for image generation, we conducted an empirical analysis using three windows, and selected the best one for our study. From the parametric images formed for each patient, we extracted a total of 72 features. Feature selection was performed to find the optimum subset of features for the best classification performance. Incorporating the selected subset of features with the Support Vector Machine (SVM) classifier, and by tuning the decision threshold, we obtained a maximum classification accuracy of 93.08%, an Area under the ROC Curve (AUC) of 0.9712, a False Negative Rate of 0%, and a very low False Positive Rate of 8.65%. Our results indicate that the high accuracy of such a procedure may assist in the diagnostic process associated with detection of breast cancer, as well as help to reduce false positive diagnosis.
PProCRC: Probabilistic Collaboration of Image Patches
Mar 21, 2019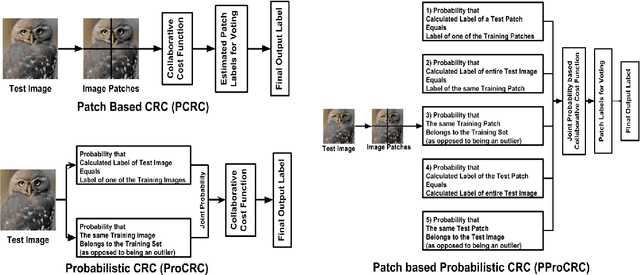
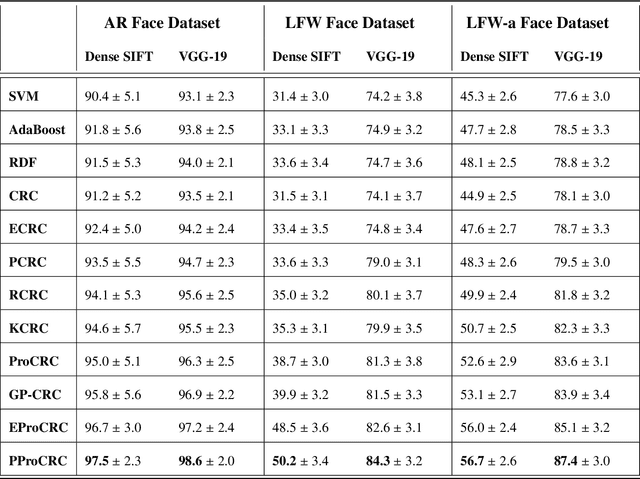

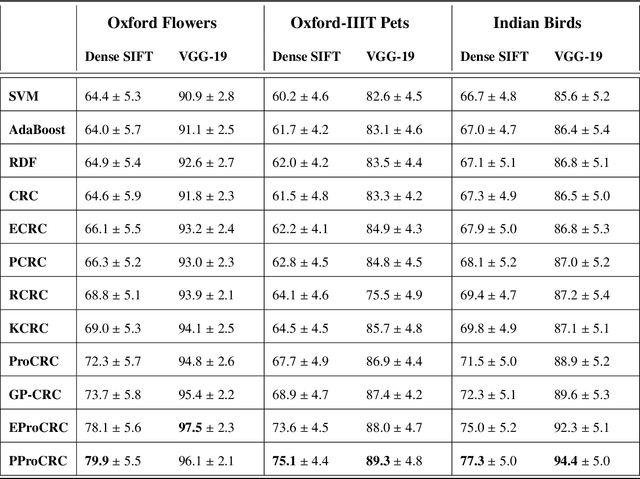
We present a conditional probabilistic framework for collaborative representation of image patches. It in-corporates background compensation and outlier patch suppression into the main formulation itself, thus doingaway with the need for pre-processing steps to handle the same. A closed form non-iterative solution of the costfunction is derived. The proposed method (PProCRC) outperforms earlier related patch based (PCRC, GP-CRC)as well as the state-of-the-art probabilistic (ProCRC and EProCRC) models on several fine-grained benchmarkimage datasets for face recognition (AR and LFW) and species recognition (Oxford Flowers and Pets) tasks.We also expand our recent endemic Indian birds (IndBirds) dataset and report results on it. The demo code andIndBirds dataset are available through lead author.
Generator Surgery for Compressed Sensing
Feb 22, 2021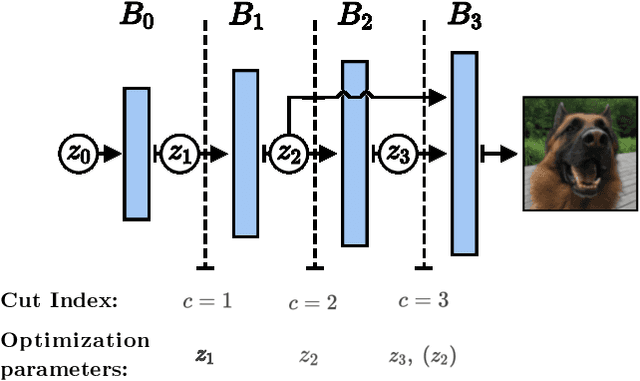
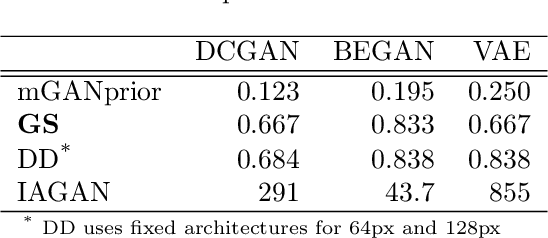
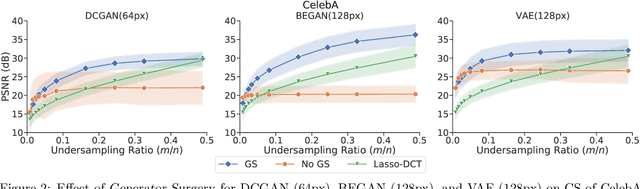
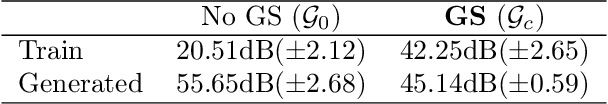
Image recovery from compressive measurements requires a signal prior for the images being reconstructed. Recent work has explored the use of deep generative models with low latent dimension as signal priors for such problems. However, their recovery performance is limited by high representation error. We introduce a method for achieving low representation error using generators as signal priors. Using a pre-trained generator, we remove one or more initial blocks at test time and optimize over the new, higher-dimensional latent space to recover a target image. Experiments demonstrate significantly improved reconstruction quality for a variety of network architectures. This approach also works well for out-of-training-distribution images and is competitive with other state-of-the-art methods. Our experiments show that test-time architectural modifications can greatly improve the recovery quality of generator signal priors for compressed sensing.
FPS-Net: A Convolutional Fusion Network for Large-Scale LiDAR Point Cloud Segmentation
Mar 01, 2021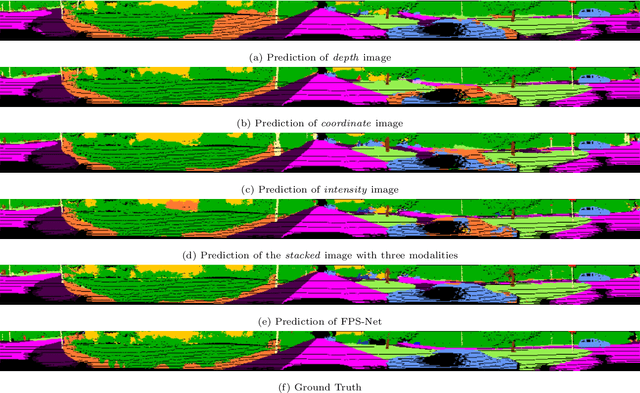
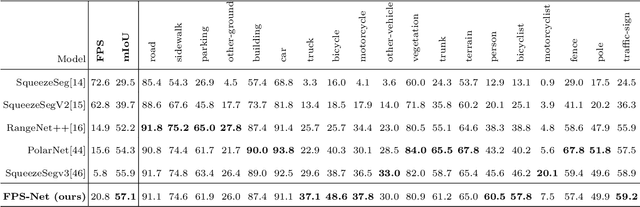
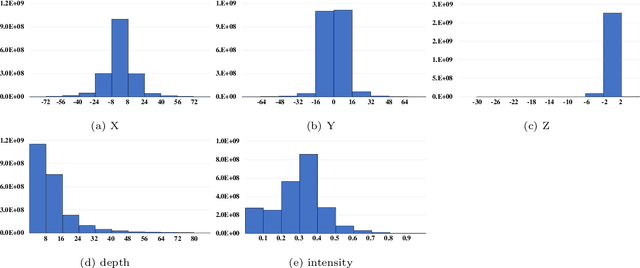
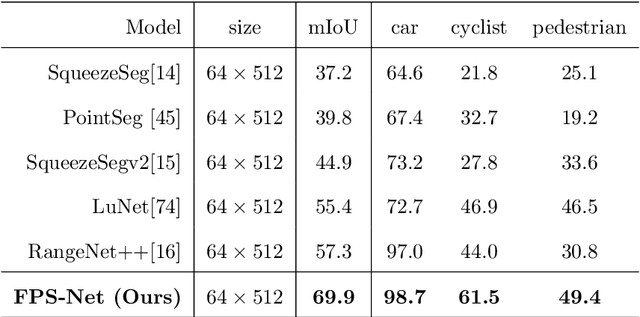
Scene understanding based on LiDAR point cloud is an essential task for autonomous cars to drive safely, which often employs spherical projection to map 3D point cloud into multi-channel 2D images for semantic segmentation. Most existing methods simply stack different point attributes/modalities (e.g. coordinates, intensity, depth, etc.) as image channels to increase information capacity, but ignore distinct characteristics of point attributes in different image channels. We design FPS-Net, a convolutional fusion network that exploits the uniqueness and discrepancy among the projected image channels for optimal point cloud segmentation. FPS-Net adopts an encoder-decoder structure. Instead of simply stacking multiple channel images as a single input, we group them into different modalities to first learn modality-specific features separately and then map the learned features into a common high-dimensional feature space for pixel-level fusion and learning. Specifically, we design a residual dense block with multiple receptive fields as a building block in the encoder which preserves detailed information in each modality and learns hierarchical modality-specific and fused features effectively. In the FPS-Net decoder, we use a recurrent convolution block likewise to hierarchically decode fused features into output space for pixel-level classification. Extensive experiments conducted on two widely adopted point cloud datasets show that FPS-Net achieves superior semantic segmentation as compared with state-of-the-art projection-based methods. In addition, the proposed modality fusion idea is compatible with typical projection-based methods and can be incorporated into them with consistent performance improvements.
Improved OOD Generalization via Adversarial Training and Pre-training
May 24, 2021
Recently, learning a model that generalizes well on out-of-distribution (OOD) data has attracted great attention in the machine learning community. In this paper, after defining OOD generalization via Wasserstein distance, we theoretically show that a model robust to input perturbation generalizes well on OOD data. Inspired by previous findings that adversarial training helps improve input-robustness, we theoretically show that adversarially trained models have converged excess risk on OOD data, and empirically verify it on both image classification and natural language understanding tasks. Besides, in the paradigm of first pre-training and then fine-tuning, we theoretically show that a pre-trained model that is more robust to input perturbation provides a better initialization for generalization on downstream OOD data. Empirically, after fine-tuning, this better-initialized model from adversarial pre-training also has better OOD generalization.
MC-GAN: Multi-conditional Generative Adversarial Network for Image Synthesis
Aug 15, 2018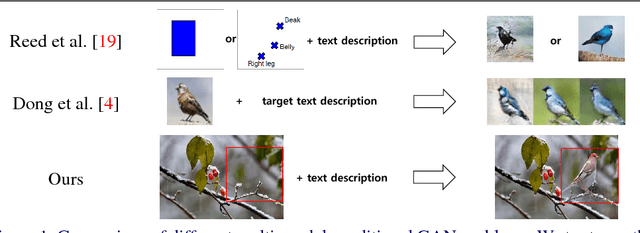

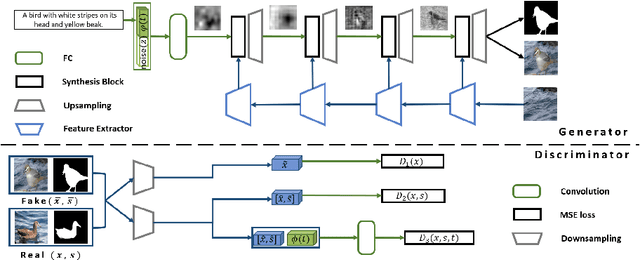
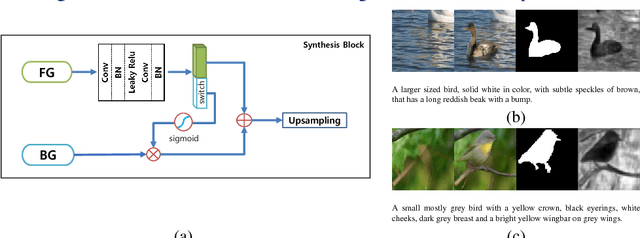
In this paper, we introduce a new method for generating an object image from text attributes on a desired location, when the base image is given. One step further to the existing studies on text-to-image generation mainly focusing on the object's appearance, the proposed method aims to generate an object image preserving the given background information, which is the first attempt in this field. To tackle the problem, we propose a multi-conditional GAN (MC-GAN) which controls both the object and background information jointly. As a core component of MC-GAN, we propose a synthesis block which disentangles the object and background information in the training stage. This block enables MC-GAN to generate a realistic object image with the desired background by controlling the amount of the background information from the given base image using the foreground information from the text attributes. From the experiments with Caltech-200 bird and Oxford-102 flower datasets, we show that our model is able to generate photo-realistic images with a resolution of 128 x 128. The source code of MC-GAN is released.
Feature-Based Image Clustering and Segmentation Using Wavelets
Jul 05, 2019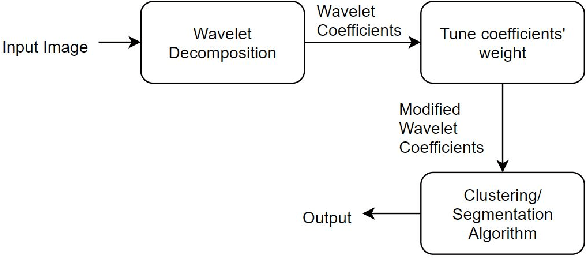
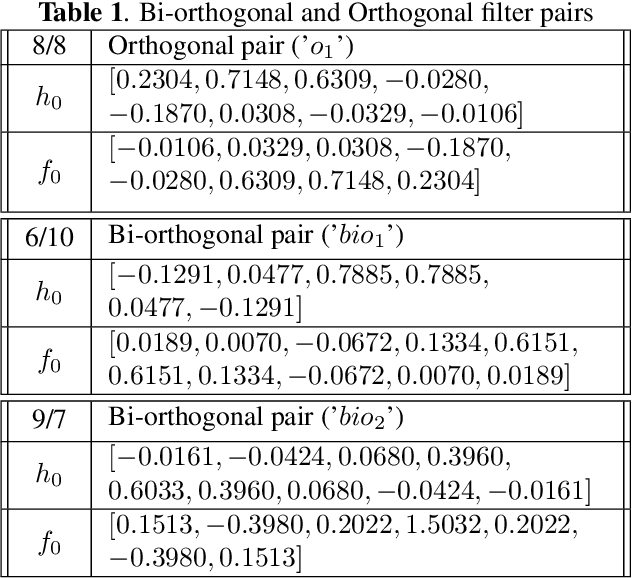
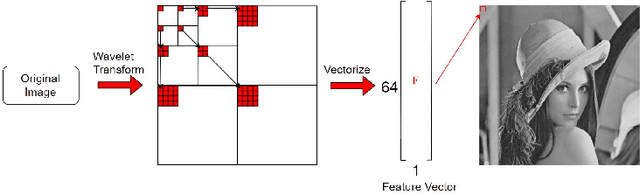
Pixel intensity is a widely used feature for clustering and segmentation algorithms, the resulting segmentation using only intensity values might suffer from noises and lack of spatial context information. Wavelet transform is often used for image denoising and classification. We proposed a novel method to incorporate Wavelet features in segmentation and clustering algorithms. The conventional K-means, Fuzzy c-means (FCM), and Active contour without edges (ACWE) algorithms were modified to adapt Wavelet features, leading to robust clustering/segmentation algorithms. A weighting parameter to control the weight of low-frequency sub-band information was also introduced. The new algorithms showed the capability to converge to different segmentation results based on the frequency information derived from the Wavelet sub-bands.