 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A New Split for Evaluating True Zero-Shot Action Recognition
Jul 27, 2021
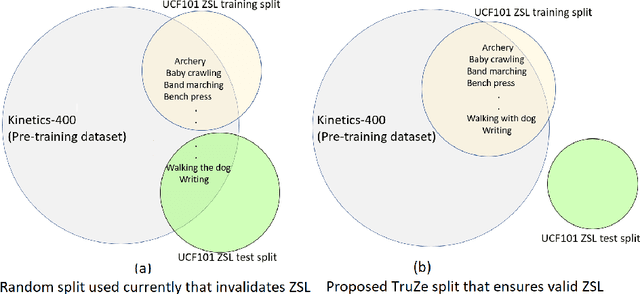
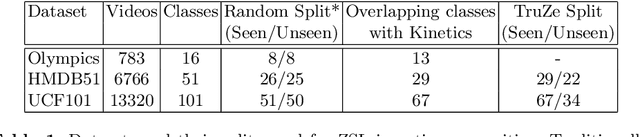
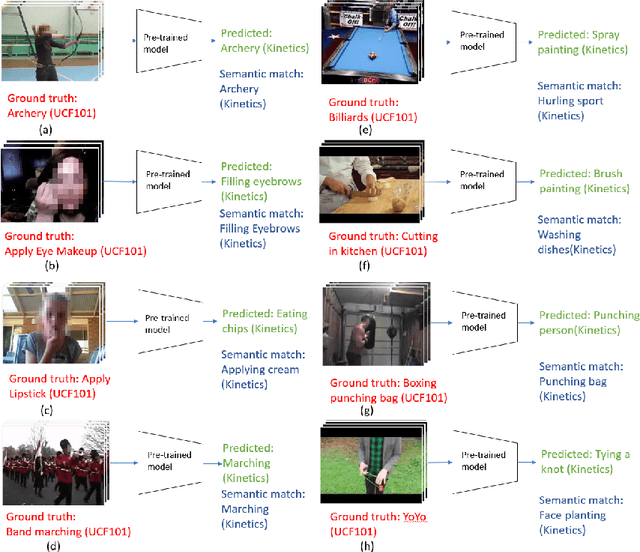
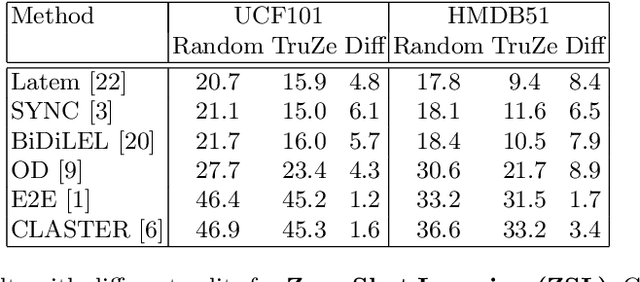
Zero-shot action recognition is the task of classifying action categories that are not available in the training set. In this setting, the standard evaluation protocol is to use existing action recognition datasets (e.g. UCF101) and randomly split the classes into seen and unseen. However, most recent work builds on representations pre-trained on the Kinetics dataset, where classes largely overlap with classes in the zero-shot evaluation datasets. As a result, classes which are supposed to be unseen, are present during supervised pre-training, invalidating the condition of the zero-shot setting. A similar concern was previously noted several years ago for image based zero-shot recognition, but has not been considered by the zero-shot action recognition community. In this paper, we propose a new split for true zero-shot action recognition with no overlap between unseen test classes and training or pre-training classes. We benchmark several recent approaches on the proposed True Zero-Shot (TruZe) Split for UCF101 and HMDB51, with zero-shot and generalized zero-shot evaluation. In our extensive analysis we find that our TruZe splits are significantly harder than comparable random splits as nothing is leaking from pre-training, i.e. unseen performance is consistently lower, up to 9.4% for zero-shot action recognition. In an additional evaluation we also find that similar issues exist in the splits used in few-shot action recognition, here we see differences of up to 14.1%. We publish our splits and hope that our benchmark analysis will change how the field is evaluating zero- and few-shot action recognition moving forward.
Automatic 4D Facial Expression Recognition via Collaborative Cross-domain Dynamic Image Network
May 07, 2019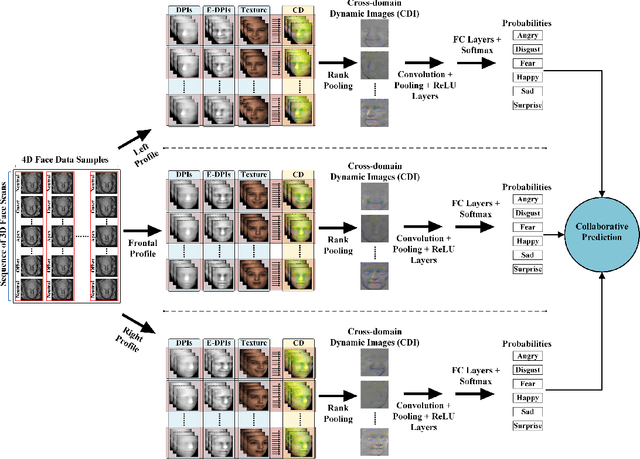
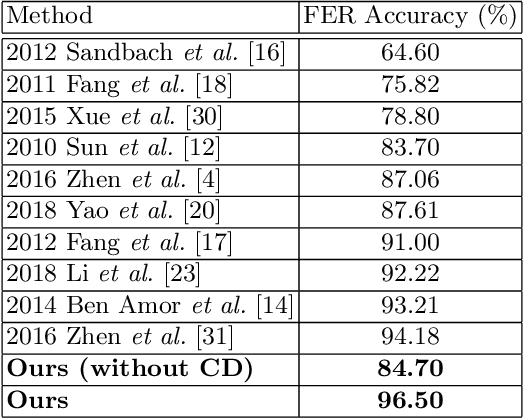
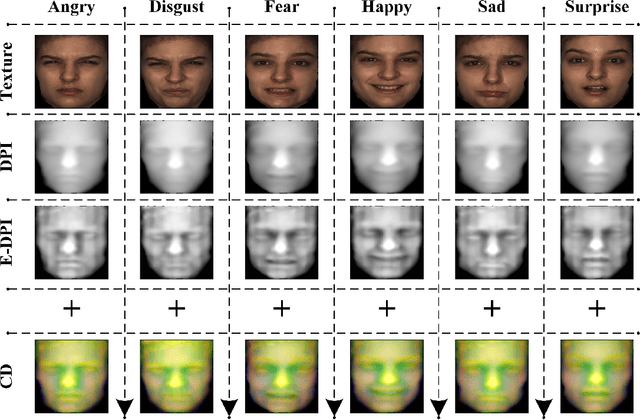

This paper proposes a novel 4D Facial Expression Recognition (FER) method using Collaborative Cross-domain Dynamic Image Network (CCDN). Given a 4D data of face scans, we first compute its geometrical images, and then combine their correlated information in the proposed cross-domain image representations. The acquired set is then used to generate cross-domain dynamic images (CDI) via rank pooling that encapsulates facial deformations over time in terms of a single image. For the training phase, these CDIs are fed into an end-to-end deep learning model, and the resultant predictions collaborate over multi-views for performance gain in expression classification. Furthermore, we propose a 4D augmentation scheme that not only expands the training data scale but also introduces significant facial muscle movement patterns to improve the FER performance. Results from extensive experiments on the commonly used BU-4DFE dataset under widely adopted settings show that our proposed method outperforms the state-of-the-art 4D FER methods by achieving an accuracy of 96.5% indicating its effectiveness.
HOME: Heatmap Output for future Motion Estimation
May 23, 2021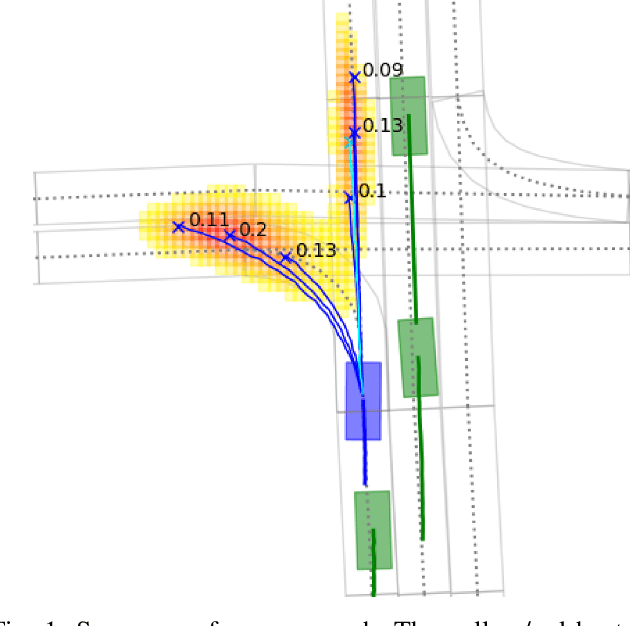
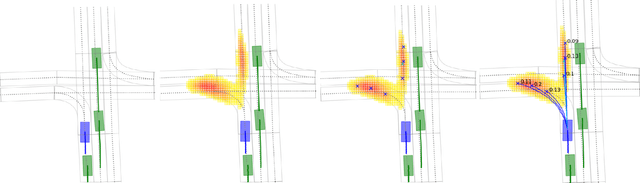
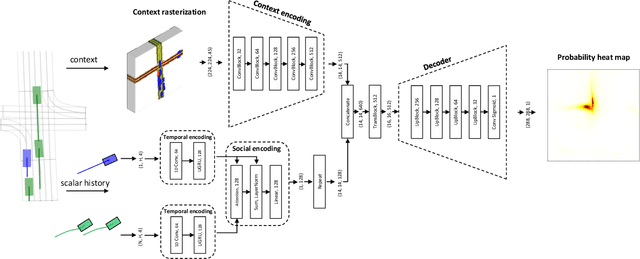
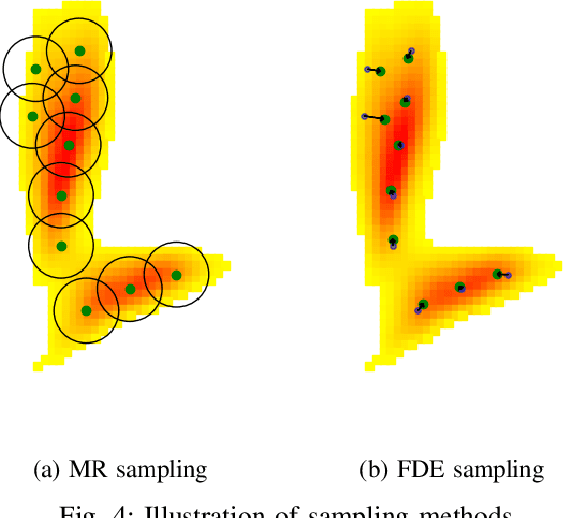
In this paper, we propose HOME, a framework tackling the motion forecasting problem with an image output representing the probability distribution of the agent's future location. This method allows for a simple architecture with classic convolution networks coupled with attention mechanism for agent interactions, and outputs an unconstrained 2D top-view representation of the agent's possible future. Based on this output, we design two methods to sample a finite set of agent's future locations. These methods allow us to control the optimization trade-off between miss rate and final displacement error for multiple modalities without having to retrain any part of the model. We apply our method to the Argoverse Motion Forecasting Benchmark and achieve 1st place on the online leaderboard.
Deepfake Forensics via An Adversarial Game
Mar 25, 2021
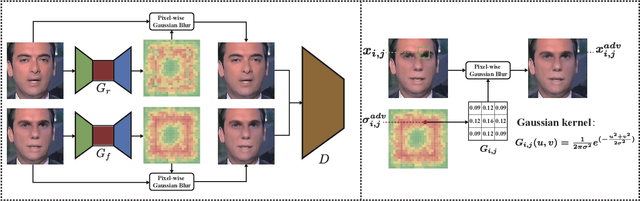

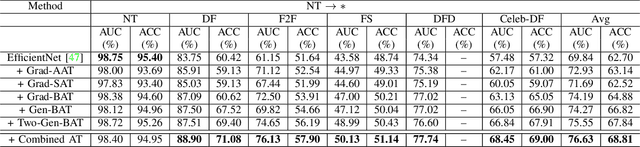
With the progress in AI-based facial forgery (i.e., deepfake), people are increasingly concerned about its abuse. Albeit effort has been made for training classification (also known as deepfake detection) models to recognize such forgeries, existing models suffer from poor generalization to unseen forgery technologies and high sensitivity to changes in image/video quality. In this paper, we advocate adversarial training for improving the generalization ability to both unseen facial forgeries and unseen image/video qualities. We believe training with samples that are adversarially crafted to attack the classification models improves the generalization ability considerably. Considering that AI-based face manipulation often leads to high-frequency artifacts that can be easily spotted by models yet difficult to generalize, we further propose a new adversarial training method that attempts to blur out these specific artifacts, by introducing pixel-wise Gaussian blurring models. With adversarial training, the classification models are forced to learn more discriminative and generalizable features, and the effectiveness of our method can be verified by plenty of empirical evidence. Our code will be made publicly available.
Joint Optimization of Hadamard Sensing and Reconstruction in Compressed Sensing Fluorescence Microscopy
May 17, 2021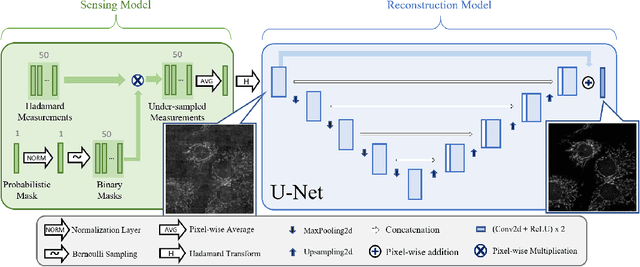
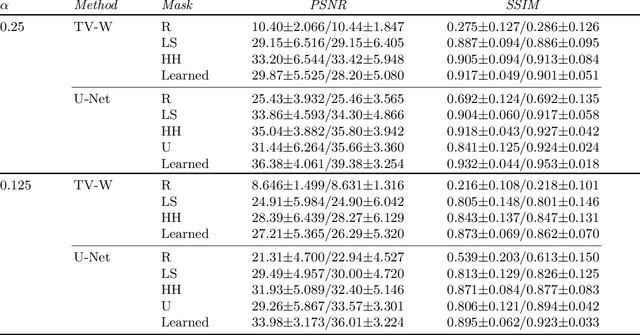

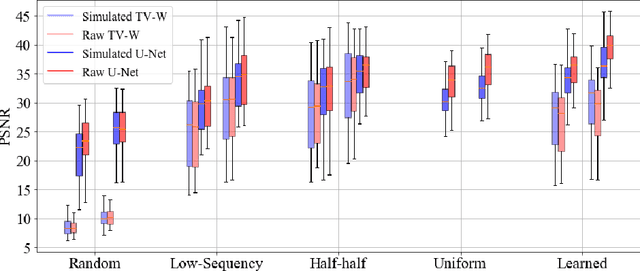
Compressed sensing fluorescence microscopy (CS-FM) proposes a scheme whereby less measurements are collected during sensing and reconstruction is performed to recover the image. Much work has gone into optimizing the sensing and reconstruction portions separately. We propose a method of jointly optimizing both sensing and reconstruction end-to-end under a total measurement constraint, enabling learning of the optimal sensing scheme concurrently with the parameters of a neural network-based reconstruction network. We train our model on a rich dataset of confocal, two-photon, and wide-field microscopy images comprising of a variety of biological samples. We show that our method outperforms several baseline sensing schemes and a regularized regression reconstruction algorithm.
Characterizing Social Imaginaries and Self-Disclosures of Dissonance in Online Conspiracy Discussion Communities
Jul 21, 2021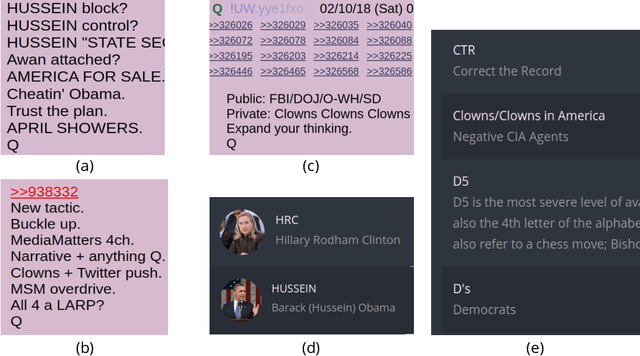

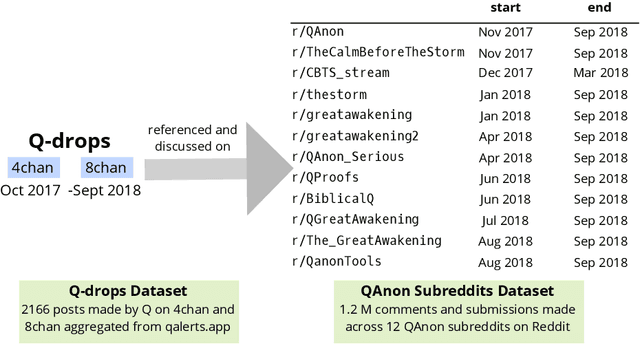
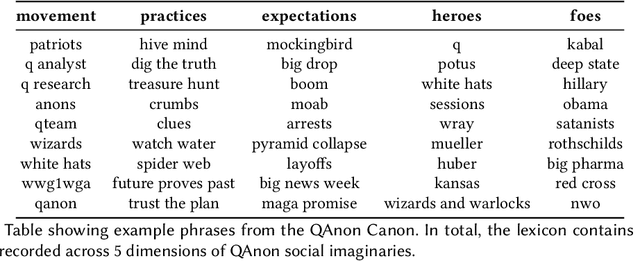
Online discussion platforms offer a forum to strengthen and propagate belief in misinformed conspiracy theories. Yet, they also offer avenues for conspiracy theorists to express their doubts and experiences of cognitive dissonance. Such expressions of dissonance may shed light on who abandons misguided beliefs and under which circumstances. This paper characterizes self-disclosures of dissonance about QAnon, a conspiracy theory initiated by a mysterious leader Q and popularized by their followers, anons in conspiracy theory subreddits. To understand what dissonance and disbelief mean within conspiracy communities, we first characterize their social imaginaries, a broad understanding of how people collectively imagine their social existence. Focusing on 2K posts from two image boards, 4chan and 8chan, and 1.2 M comments and posts from 12 subreddits dedicated to QAnon, we adopt a mixed methods approach to uncover the symbolic language representing the movement, expectations, practices, heroes and foes of the QAnon community. We use these social imaginaries to create a computational framework for distinguishing belief and dissonance from general discussion about QAnon. Further, analyzing user engagement with QAnon conspiracy subreddits, we find that self-disclosures of dissonance correlate with a significant decrease in user contributions and ultimately with their departure from the community. We contribute a computational framework for identifying dissonance self-disclosures and measuring the changes in user engagement surrounding dissonance. Our work can provide insights into designing dissonance-based interventions that can potentially dissuade conspiracists from online conspiracy discussion communities.
Unsupervised Pixel-level Road Defect Detection via Adversarial Image-to-Frequency Transform
Feb 03, 2020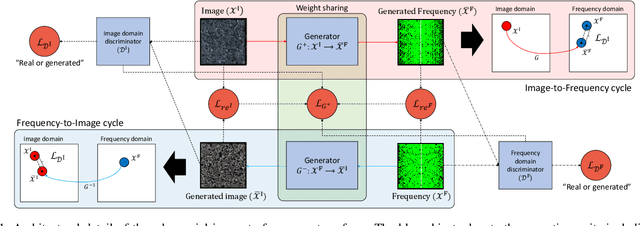
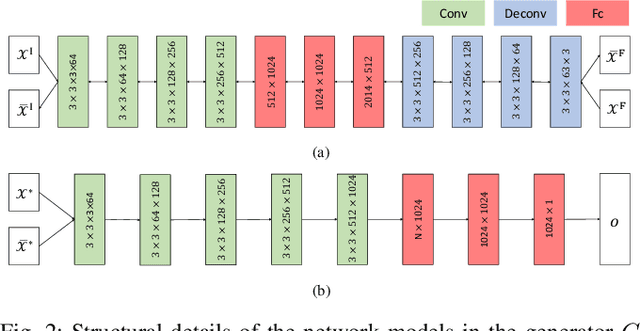
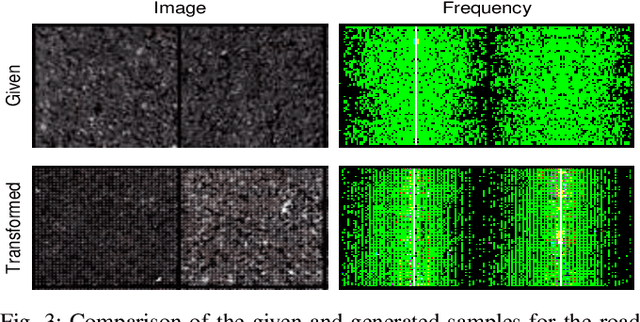
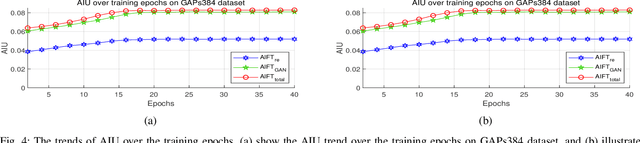
In the past few years, the performance of road defect detection has been remarkably improved thanks to advancements on various studies on computer vision and deep learning. Although a large-scale and well-annotated datasets enhance the performance of detecting road pavement defects to some extent, it is still challengeable to derive a model which can perform reliably for various road conditions in practice, because it is intractable to construct a dataset considering diverse road conditions and defect patterns. To end this, we propose an unsupervised approach to detecting road defects, using Adversarial Image-to-Frequency Transform (AIFT). AIFT adopts the unsupervised manner and adversarial learning in deriving the defect detection model, so AIFT does not need annotations for road pavement defects. We evaluate the efficiency of AIFT using GAPs384 dataset, Cracktree200 dataset, CRACK500 dataset, and CFD dataset. The experimental results demonstrate that the proposed approach detects various road detects, and it outperforms existing state-of-the-art approaches.
Sparsity-based Convolutional Kernel Network for Unsupervised Medical Image Analysis
Jul 27, 2018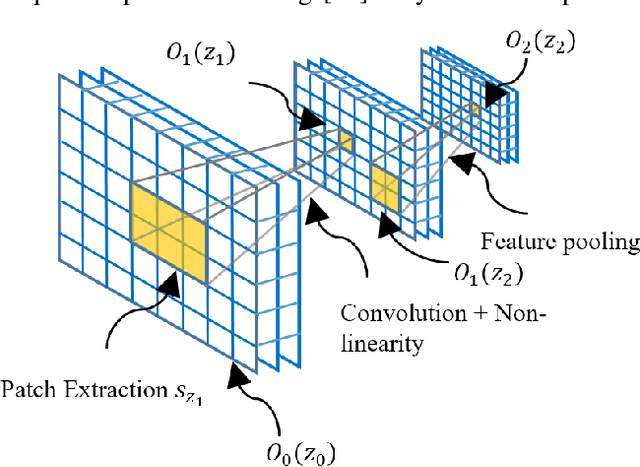
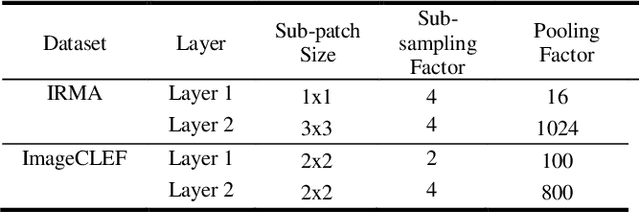
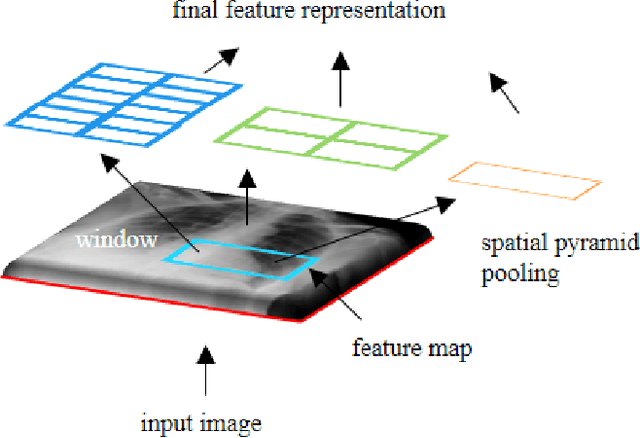
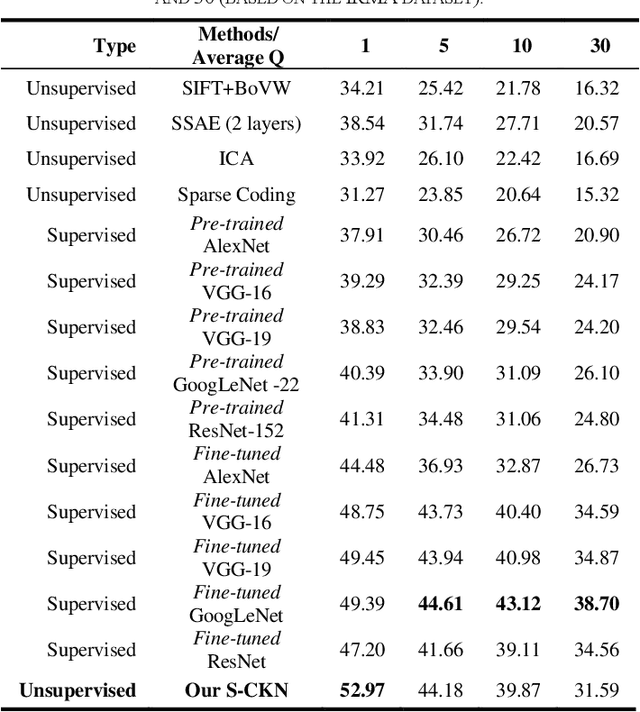
The availability of large-scale annotated image datasets coupled with recent advances in supervised deep learning methods are enabling the derivation of representative image features that can potentially impact different image analysis problems. However, such supervised approaches are not feasible in the medical domain where it is challenging to obtain a large volume of labelled data due to the complexity of manual annotation and inter- and intra-observer variability in label assignment. Algorithms designed to work on small annotated datasets are useful but have limited applications. In an effort to address the lack of annotated data in the medical image analysis domain, we propose an algorithm for hierarchical unsupervised feature learning. Our algorithm introduces three new contributions: (i) we use kernel learning to identify and represent invariant characteristics across image sub-patches in an unsupervised manner; (ii) we leverage the sparsity inherent to medical image data and propose a new sparse convolutional kernel network (S-CKN) that can be pre-trained in a layer-wise fashion, thereby providing initial discriminative features for medical data; and (iii) we propose a spatial pyramid pooling framework to capture subtle geometric differences in medical image data. Our experiments evaluate our algorithm in two common application areas of medical image retrieval and classification using two public datasets. Our results demonstrate that the medical image feature representations extracted with our algorithm enable a higher accuracy in both application areas compared to features extracted from other conventional unsupervised methods. Furthermore, our approach achieves an accuracy that is competitive with state-of-the-art supervised CNNs.
Self-Paced Uncertainty Estimation for One-shot Person Re-Identification
Apr 19, 2021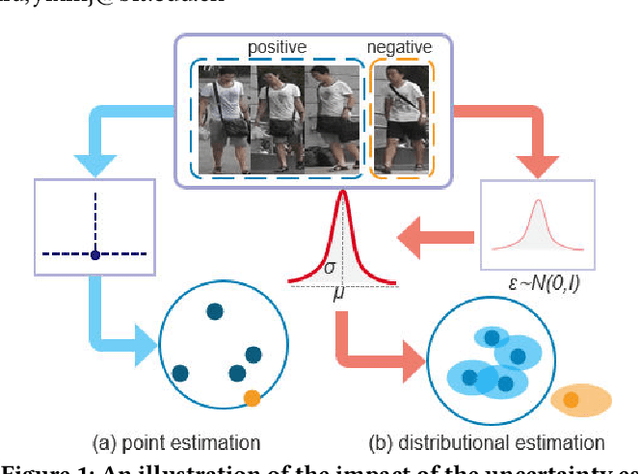
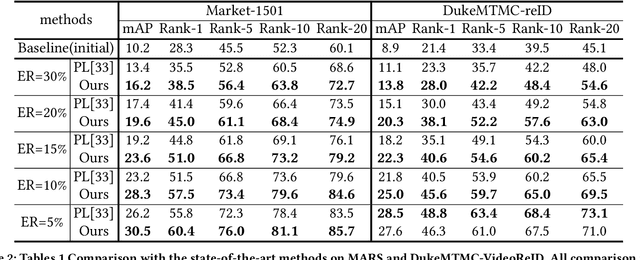
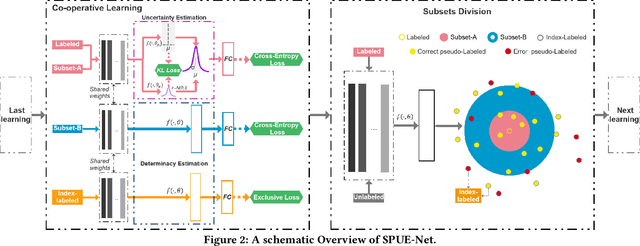
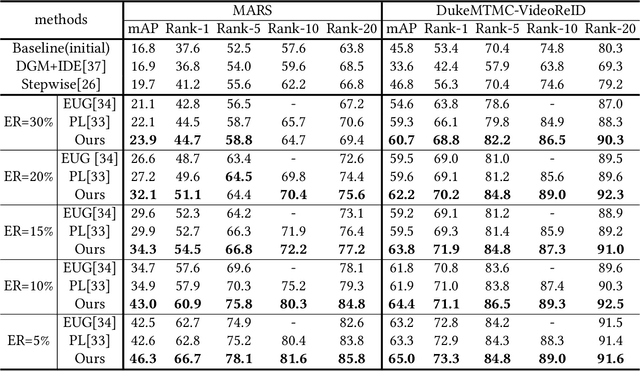
The one-shot Person Re-ID scenario faces two kinds of uncertainties when constructing the prediction model from $X$ to $Y$. The first is model uncertainty, which captures the noise of the parameters in DNNs due to a lack of training data. The second is data uncertainty, which can be divided into two sub-types: one is image noise, where severe occlusion and the complex background contain irrelevant information about the identity; the other is label noise, where mislabeled affects visual appearance learning. In this paper, to tackle these issues, we propose a novel Self-Paced Uncertainty Estimation Network (SPUE-Net) for one-shot Person Re-ID. By introducing a self-paced sampling strategy, our method can estimate the pseudo-labels of unlabeled samples iteratively to expand the labeled samples gradually and remove model uncertainty without extra supervision. We divide the pseudo-label samples into two subsets to make the use of training samples more reasonable and effective. In addition, we apply a Co-operative learning method of local uncertainty estimation combined with determinacy estimation to achieve better hidden space feature mining and to improve the precision of selected pseudo-labeled samples, which reduces data uncertainty. Extensive comparative evaluation experiments on video-based and image-based datasets show that SPUE-Net has significant advantages over the state-of-the-art methods.
Confidence-Aware Learning for Camouflaged Object Detection
Jun 22, 2021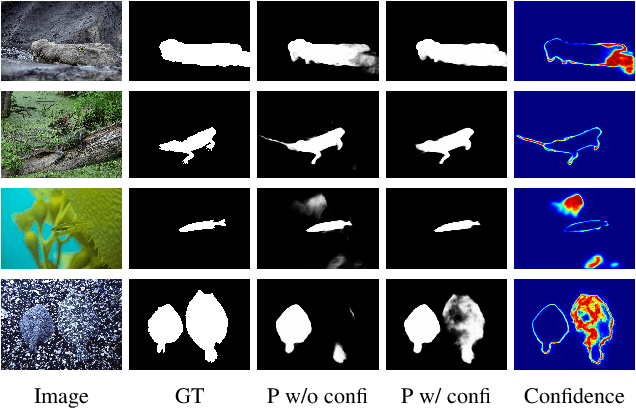
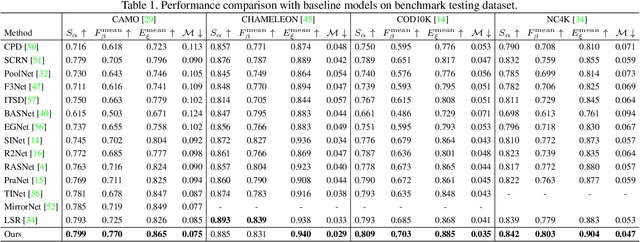
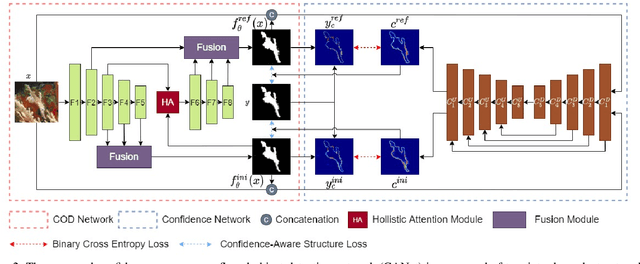
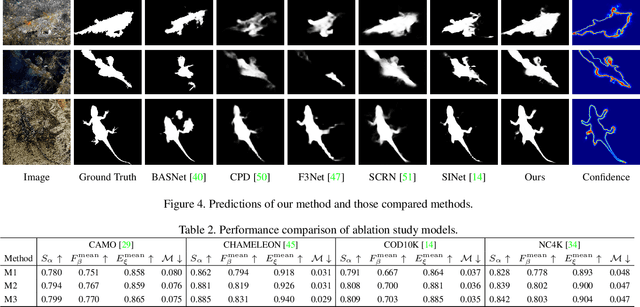
Confidence-aware learning is proven as an effective solution to prevent networks becoming overconfident. We present a confidence-aware camouflaged object detection framework using dynamic supervision to produce both accurate camouflage map and meaningful "confidence" representing model awareness about the current prediction. A camouflaged object detection network is designed to produce our camouflage prediction. Then, we concatenate it with the input image and feed it to the confidence estimation network to produce an one channel confidence map.We generate dynamic supervision for the confidence estimation network, representing the agreement of camouflage prediction with the ground truth camouflage map. With the produced confidence map, we introduce confidence-aware learning with the confidence map as guidance to pay more attention to the hard/low-confidence pixels in the loss function. We claim that, once trained, our confidence estimation network can evaluate pixel-wise accuracy of the prediction without relying on the ground truth camouflage map. Extensive results on four camouflaged object detection testing datasets illustrate the superior performance of the proposed model in explaining the camouflage prediction.