 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Localizing dexterous surgical tools in X-ray for image-based navigation
Jan 20, 2019
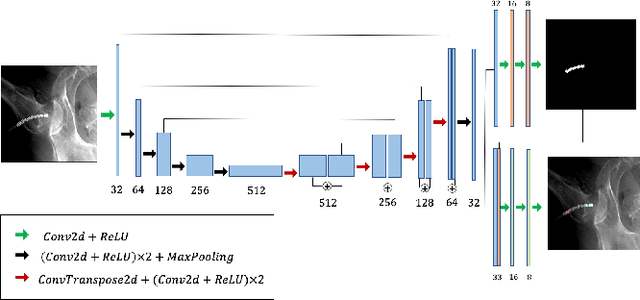
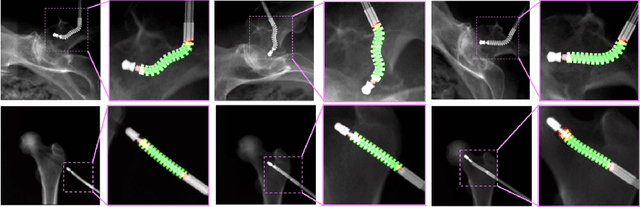
X-ray image based surgical tool navigation is fast and supplies accurate images of deep seated structures. Typically, recovering the 6 DOF rigid pose and deformation of tools with respect to the X-ray camera can be accurately achieved through intensity-based 2D/3D registration of 3D images or models to 2D X-rays. However, the capture range of image-based 2D/3D registration is inconveniently small suggesting that automatic and robust initialization strategies are of critical importance. This manuscript describes a first step towards leveraging semantic information of the imaged object to initialize 2D/3D registration within the capture range of image-based registration by performing concurrent segmentation and localization of dexterous surgical tools in X-ray images. We presented a learning-based strategy to simultaneously localize and segment dexterous surgical tools in X-ray images and demonstrate promising performance on synthetic and ex vivo data. We currently investigate methods to use semantic information extracted by the proposed network to reliably and robustly initialize image-based 2D/3D registration. While image-based 2D/3D registration has been an obvious focus of the CAI community, robust initialization thereof (albeit critical) has largely been neglected. This manuscript discusses learning-based retrieval of semantic information on imaged-objects as a stepping stone for such initialization and may therefore be of interest to the IPCAI community. Since results are still preliminary and only focus on localization, we target the Long Abstract category.
TED-net: Convolution-free T2T Vision Transformer-based Encoder-decoder Dilation network for Low-dose CT Denoising
Jun 08, 2021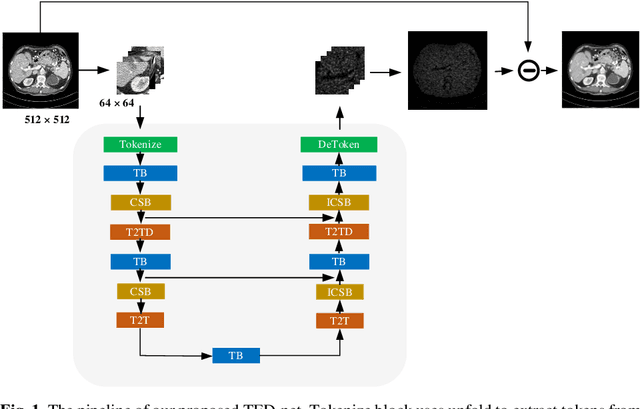
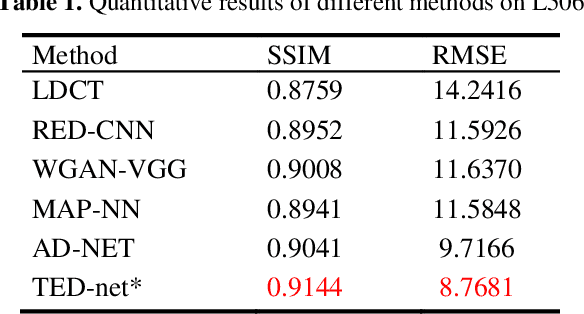
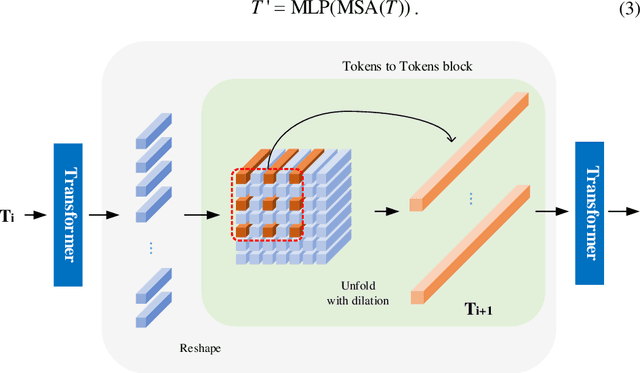
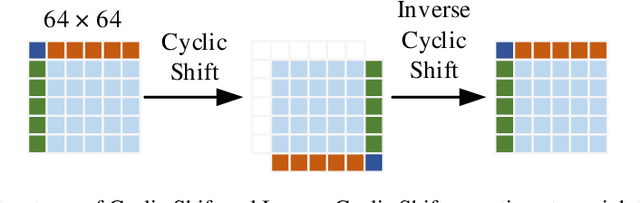
Low dose computed tomography is a mainstream for clinical applications. How-ever, compared to normal dose CT, in the low dose CT (LDCT) images, there are stronger noise and more artifacts which are obstacles for practical applications. In the last few years, convolution-based end-to-end deep learning methods have been widely used for LDCT image denoising. Recently, transformer has shown superior performance over convolution with more feature interactions. Yet its ap-plications in LDCT denoising have not been fully cultivated. Here, we propose a convolution-free T2T vision transformer-based Encoder-decoder Dilation net-work (TED-net) to enrich the family of LDCT denoising algorithms. The model is free of convolution blocks and consists of a symmetric encoder-decoder block with sole transformer. Our model is evaluated on the AAPM-Mayo clinic LDCT Grand Challenge dataset, and results show outperformance over the state-of-the-art denoising methods.
Detection of Alzheimer's Disease Using Graph-Regularized Convolutional Neural Network Based on Structural Similarity Learning of Brain Magnetic Resonance Images
Feb 25, 2021
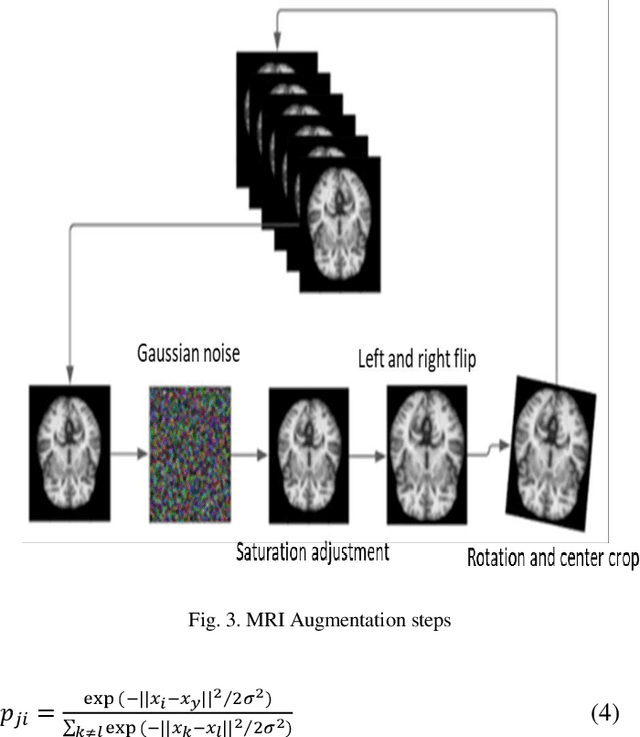
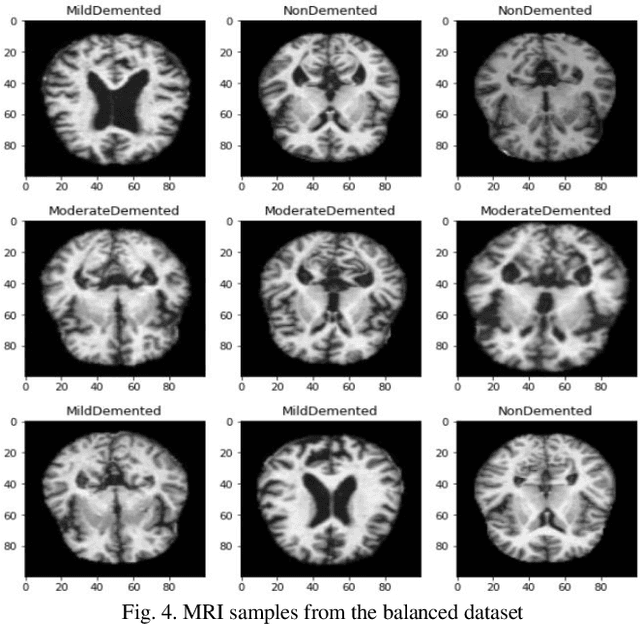
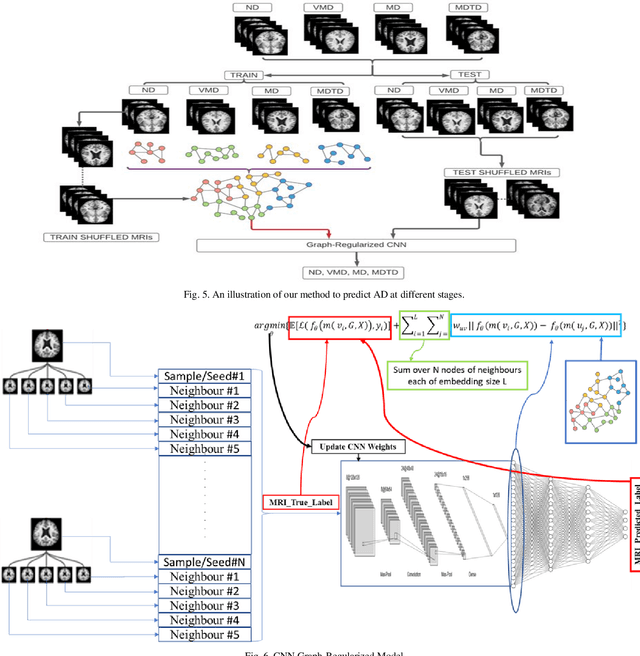
Objective: This paper presents an Alzheimer's disease (AD) detection method based on learning structural similarity between Magnetic Resonance Images (MRIs) and representing this similarity as a graph. Methods: We construct the similarity graph using embedded features of the input image (i.e., Non-Demented (ND), Very Mild Demented (VMD), Mild Demented (MD), and Moderated Demented (MDTD)). We experiment and compare different dimension-reduction and clustering algorithms to construct the best similarity graph to capture the similarity between the same class images using the cosine distance as a similarity measure. We utilize the similarity graph to present (sample) the training data to a convolutional neural network (CNN). We use the similarity graph as a regularizer in the loss function of a CNN model to minimize the distance between the input images and their k-nearest neighbours in the similarity graph while minimizing the categorical cross-entropy loss between the training image predictions and the actual image class labels. Results: We conduct extensive experiments with several pre-trained CNN models and compare the results to other recent methods. Conclusion: Our method achieves superior performance on the testing dataset (accuracy = 0.986, area under receiver operating characteristics curve = 0.998, F1 measure = 0.987). Significance: The classification results show an improvement in the prediction accuracy compared to the other methods. We release all the code used in our experiments to encourage reproducible research in this area
A New Split for Evaluating True Zero-Shot Action Recognition
Jul 27, 2021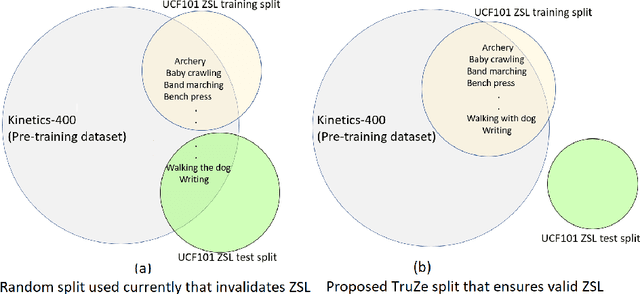
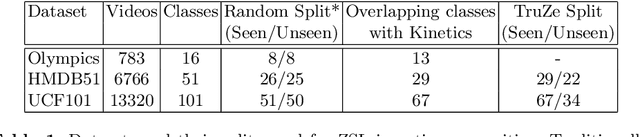
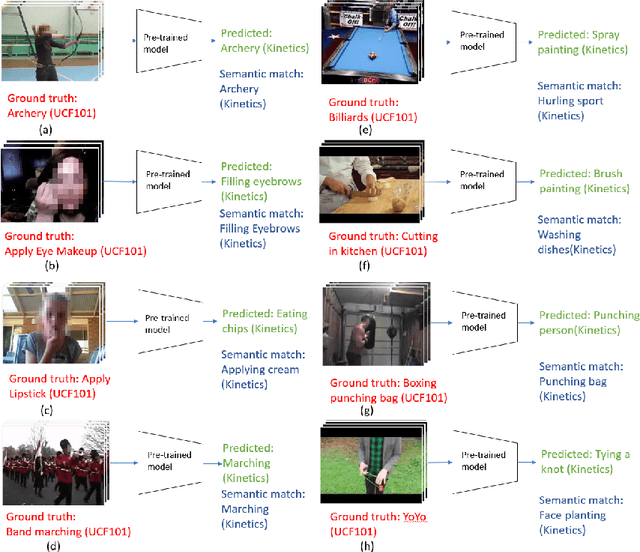
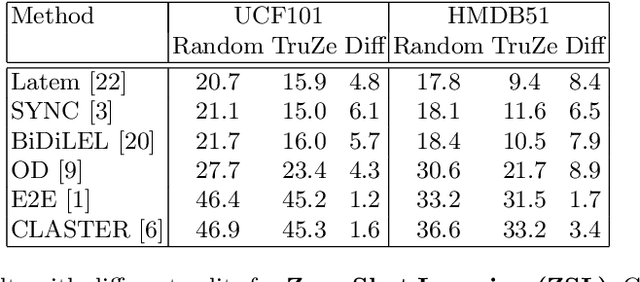
Zero-shot action recognition is the task of classifying action categories that are not available in the training set. In this setting, the standard evaluation protocol is to use existing action recognition datasets (e.g. UCF101) and randomly split the classes into seen and unseen. However, most recent work builds on representations pre-trained on the Kinetics dataset, where classes largely overlap with classes in the zero-shot evaluation datasets. As a result, classes which are supposed to be unseen, are present during supervised pre-training, invalidating the condition of the zero-shot setting. A similar concern was previously noted several years ago for image based zero-shot recognition, but has not been considered by the zero-shot action recognition community. In this paper, we propose a new split for true zero-shot action recognition with no overlap between unseen test classes and training or pre-training classes. We benchmark several recent approaches on the proposed True Zero-Shot (TruZe) Split for UCF101 and HMDB51, with zero-shot and generalized zero-shot evaluation. In our extensive analysis we find that our TruZe splits are significantly harder than comparable random splits as nothing is leaking from pre-training, i.e. unseen performance is consistently lower, up to 9.4% for zero-shot action recognition. In an additional evaluation we also find that similar issues exist in the splits used in few-shot action recognition, here we see differences of up to 14.1%. We publish our splits and hope that our benchmark analysis will change how the field is evaluating zero- and few-shot action recognition moving forward.
A Generalized Framework for Edge-preserving and Structure-preserving Image Smoothing
Jul 23, 2019
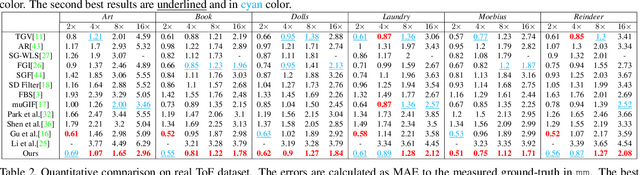
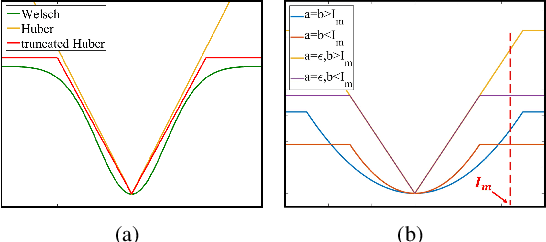

Image smoothing is a fundamental procedure in applications of both computer vision and graphics. The required smoothing properties can be different or even contradictive among different tasks. Nevertheless, the inherent smoothing nature of one smoothing operator is usually fixed and thus cannot meet the various requirements of different applications. In this paper, a non-convex non-smooth optimization framework is proposed to achieve diverse smoothing natures where even contradictive smoothing behaviors can be achieved. To this end, we first introduce the truncated Huber penalty function which has seldom been used in image smoothing. A robust framework is then proposed. When combined with the strong flexibility of the truncated Huber penalty function, our framework is capable of a range of applications and can outperform the state-of-the-art approaches in several tasks. In addition, an efficient numerical solution is provided and its convergence is theoretically guaranteed even the optimization framework is non-convex and non-smooth. The effectiveness and superior performance of our approach are validated through comprehensive experimental results in a range of applications.
Interactive Medical Image Segmentation using Deep Learning with Image-specific Fine-tuning
Oct 11, 2017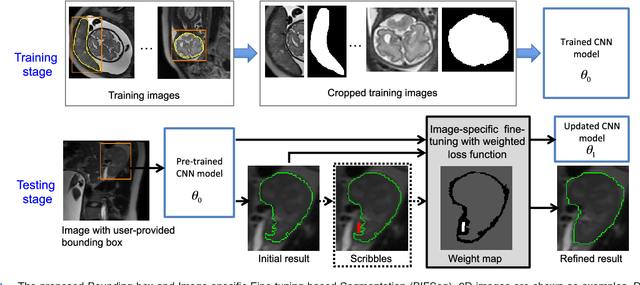
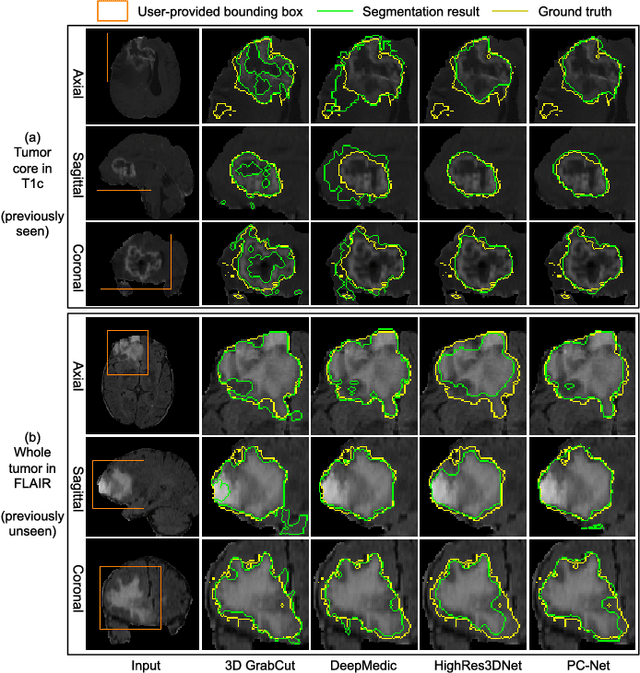
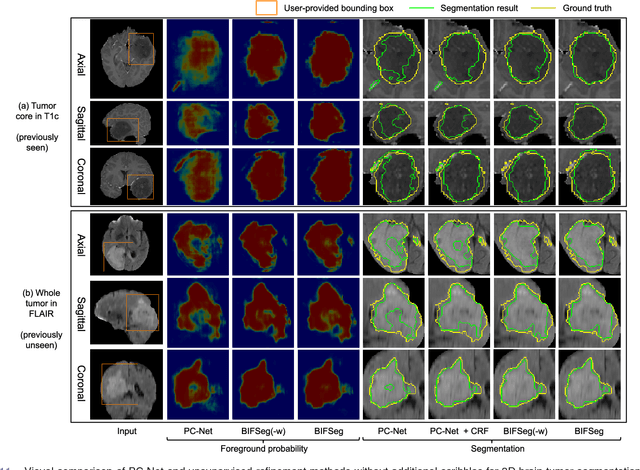
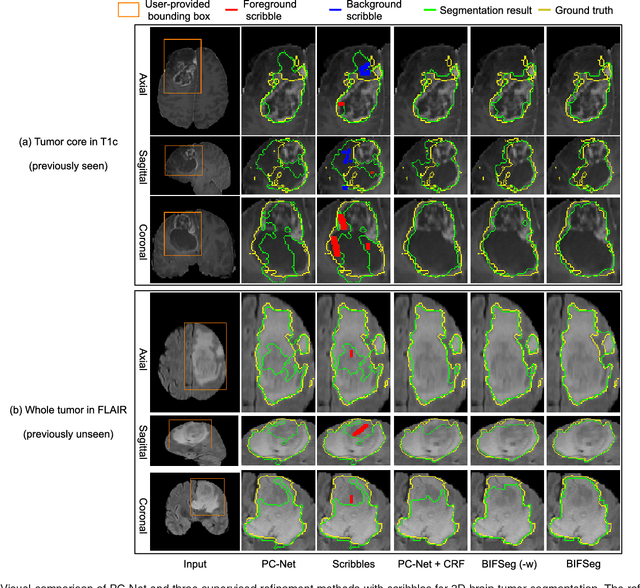
Convolutional neural networks (CNNs) have achieved state-of-the-art performance for automatic medical image segmentation. However, they have not demonstrated sufficiently accurate and robust results for clinical use. In addition, they are limited by the lack of image-specific adaptation and the lack of generalizability to previously unseen object classes. To address these problems, we propose a novel deep learning-based framework for interactive segmentation by incorporating CNNs into a bounding box and scribble-based segmentation pipeline. We propose image-specific fine-tuning to make a CNN model adaptive to a specific test image, which can be either unsupervised (without additional user interactions) or supervised (with additional scribbles). We also propose a weighted loss function considering network and interaction-based uncertainty for the fine-tuning. We applied this framework to two applications: 2D segmentation of multiple organs from fetal MR slices, where only two types of these organs were annotated for training; and 3D segmentation of brain tumor core (excluding edema) and whole brain tumor (including edema) from different MR sequences, where only tumor cores in one MR sequence were annotated for training. Experimental results show that 1) our model is more robust to segment previously unseen objects than state-of-the-art CNNs; 2) image-specific fine-tuning with the proposed weighted loss function significantly improves segmentation accuracy; and 3) our method leads to accurate results with fewer user interactions and less user time than traditional interactive segmentation methods.
A Survey of Modern Deep Learning based Object Detection Models
Apr 24, 2021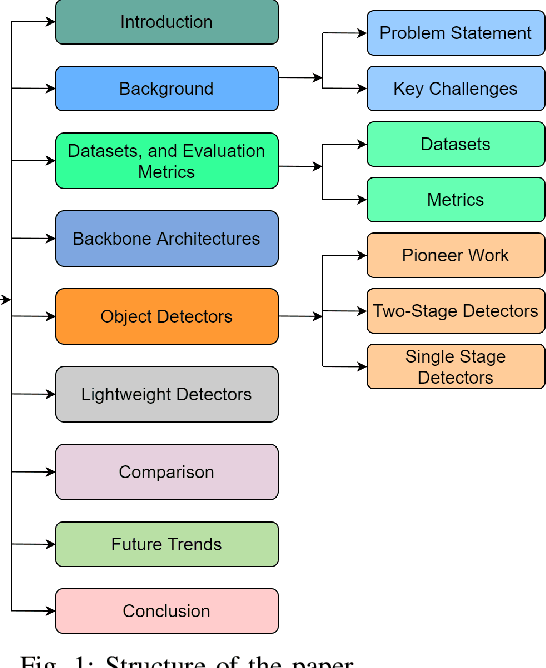


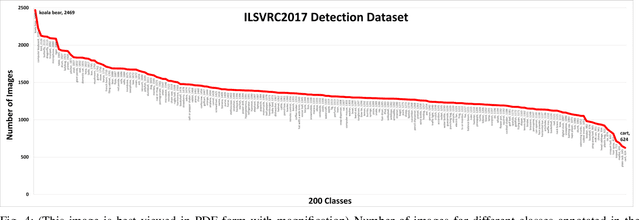
Object Detection is the task of classification and localization of objects in an image or video. It has gained prominence in recent years due to its widespread applications. This article surveys recent developments in deep learning based object detectors. Concise overview of benchmark datasets and evaluation metrics used in detection is also provided along with some of the prominent backbone architectures used in recognition tasks. It also covers contemporary lightweight classification models used on edge devices. Lastly, we compare the performances of these architectures on multiple metrics.
HOME: Heatmap Output for future Motion Estimation
May 23, 2021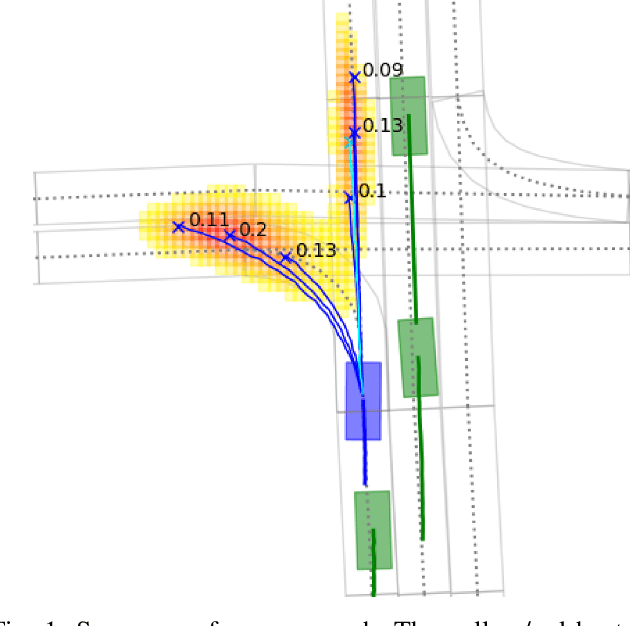
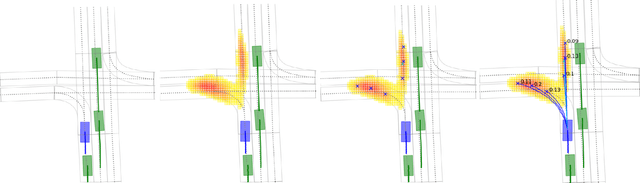
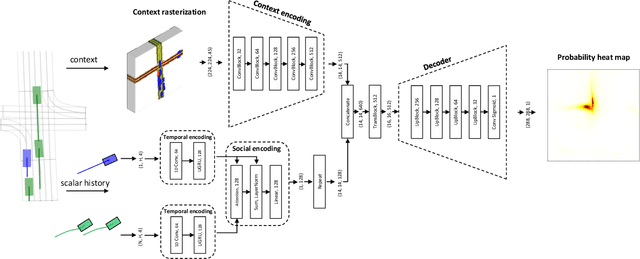
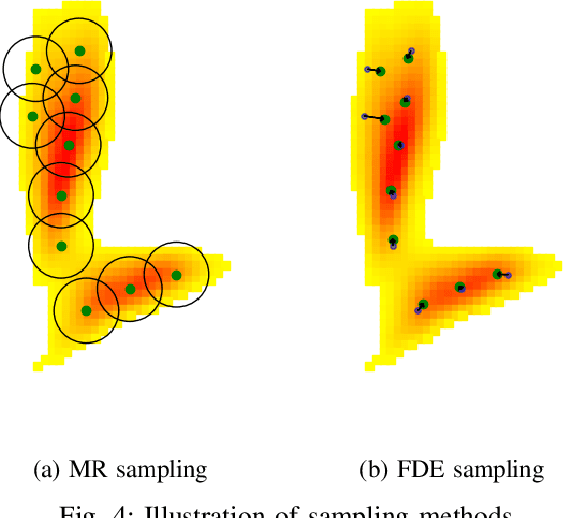
In this paper, we propose HOME, a framework tackling the motion forecasting problem with an image output representing the probability distribution of the agent's future location. This method allows for a simple architecture with classic convolution networks coupled with attention mechanism for agent interactions, and outputs an unconstrained 2D top-view representation of the agent's possible future. Based on this output, we design two methods to sample a finite set of agent's future locations. These methods allow us to control the optimization trade-off between miss rate and final displacement error for multiple modalities without having to retrain any part of the model. We apply our method to the Argoverse Motion Forecasting Benchmark and achieve 1st place on the online leaderboard.
Characterizing Social Imaginaries and Self-Disclosures of Dissonance in Online Conspiracy Discussion Communities
Jul 21, 2021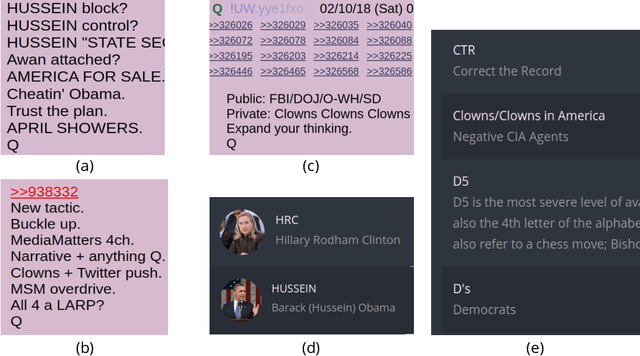

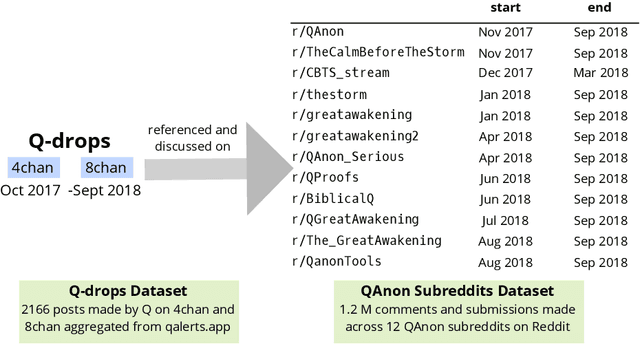
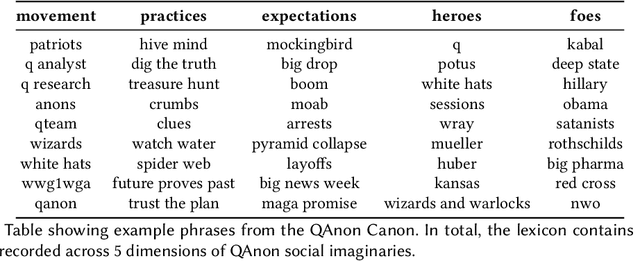
Online discussion platforms offer a forum to strengthen and propagate belief in misinformed conspiracy theories. Yet, they also offer avenues for conspiracy theorists to express their doubts and experiences of cognitive dissonance. Such expressions of dissonance may shed light on who abandons misguided beliefs and under which circumstances. This paper characterizes self-disclosures of dissonance about QAnon, a conspiracy theory initiated by a mysterious leader Q and popularized by their followers, anons in conspiracy theory subreddits. To understand what dissonance and disbelief mean within conspiracy communities, we first characterize their social imaginaries, a broad understanding of how people collectively imagine their social existence. Focusing on 2K posts from two image boards, 4chan and 8chan, and 1.2 M comments and posts from 12 subreddits dedicated to QAnon, we adopt a mixed methods approach to uncover the symbolic language representing the movement, expectations, practices, heroes and foes of the QAnon community. We use these social imaginaries to create a computational framework for distinguishing belief and dissonance from general discussion about QAnon. Further, analyzing user engagement with QAnon conspiracy subreddits, we find that self-disclosures of dissonance correlate with a significant decrease in user contributions and ultimately with their departure from the community. We contribute a computational framework for identifying dissonance self-disclosures and measuring the changes in user engagement surrounding dissonance. Our work can provide insights into designing dissonance-based interventions that can potentially dissuade conspiracists from online conspiracy discussion communities.
Image captioning with weakly-supervised attention penalty
Mar 06, 2019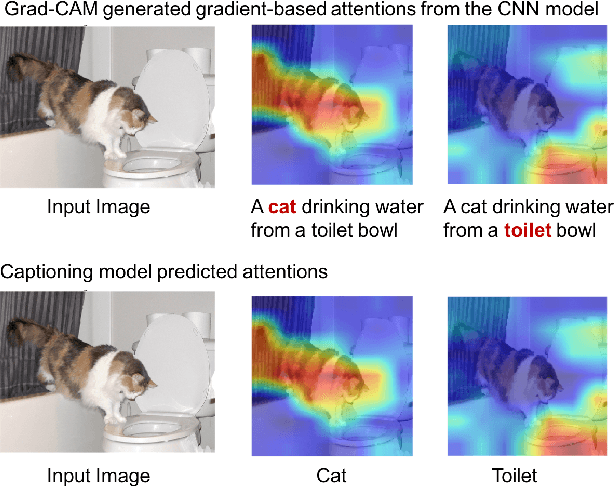
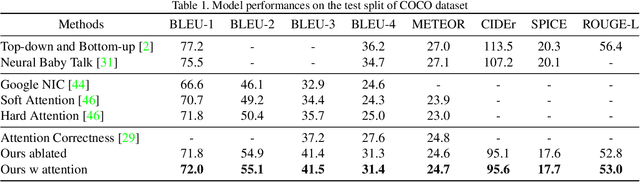
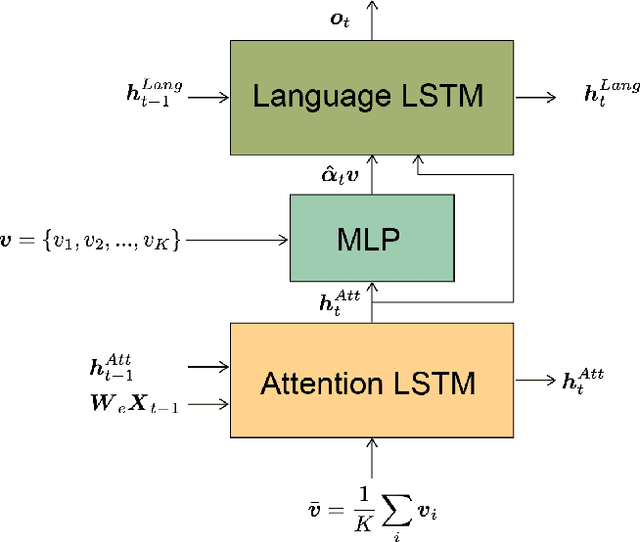

Stories are essential for genealogy research since they can help build emotional connections with people. A lot of family stories are reserved in historical photos and albums. Recent development on image captioning models makes it feasible to "tell stories" for photos automatically. The attention mechanism has been widely adopted in many state-of-the-art encoder-decoder based image captioning models, since it can bridge the gap between the visual part and the language part. Most existing captioning models implicitly trained attention modules with word-likelihood loss. Meanwhile, lots of studies have investigated intrinsic attentions for visual models using gradient-based approaches. Ideally, attention maps predicted by captioning models should be consistent with intrinsic attentions from visual models for any given visual concept. However, no work has been done to align implicitly learned attention maps with intrinsic visual attentions. In this paper, we proposed a novel model that measured consistency between captioning predicted attentions and intrinsic visual attentions. This alignment loss allows explicit attention correction without using any expensive bounding box annotations. We developed and evaluated our model on COCO dataset as well as a genealogical dataset from Ancestry.com Operations Inc., which contains billions of historical photos. The proposed model achieved better performances on all commonly used language evaluation metrics for both datasets.