 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Day-to-day and seasonal regularity of network passenger delay for metro networks
Jul 07, 2021
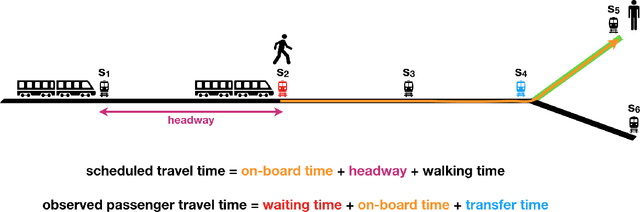
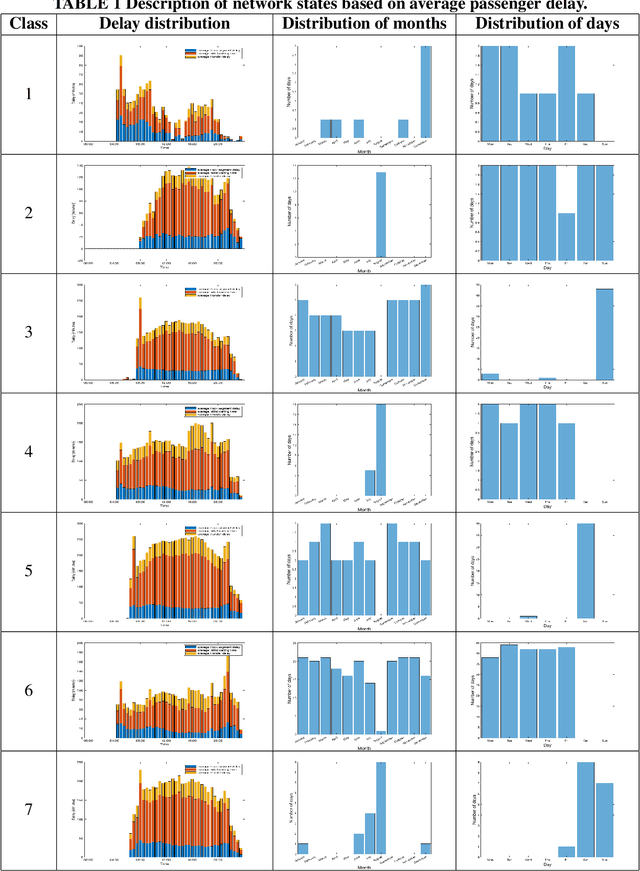
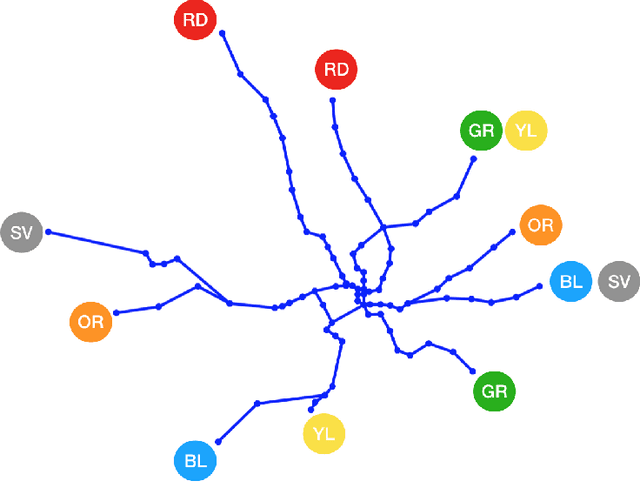
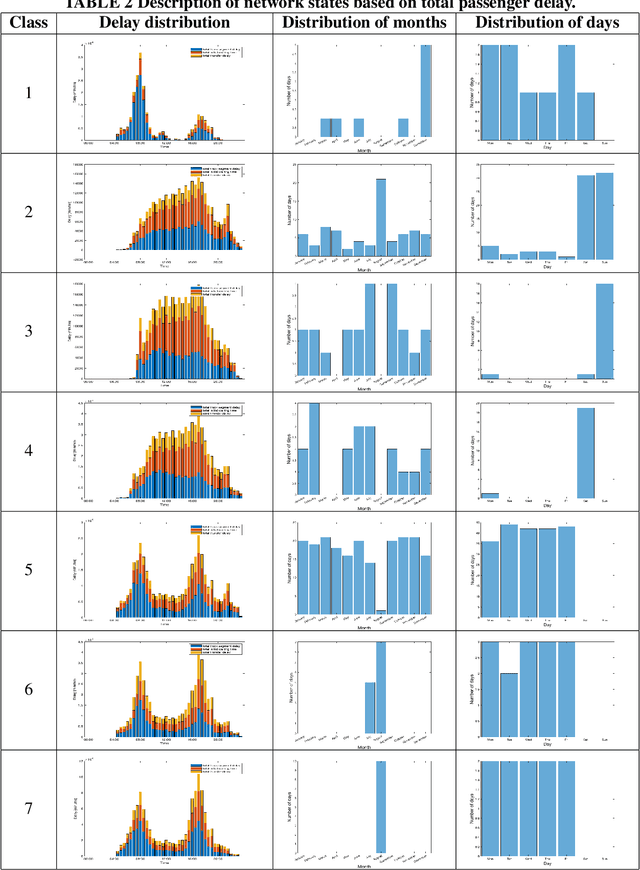
In an effort to improve user satisfaction and transit image, transit service providers worldwide offer delay compensations. Smart card data enables the estimation of passenger delays throughout the network and aid in monitoring service performance. Notwithstanding, in order to prioritize measures for improving service reliability and hence reducing passenger delays, it is paramount to identify the system components - stations and track segments - where most passenger delay occurs. To this end, we propose a novel method for estimating network passenger delay from individual trajectories. We decompose the delay along a passenger trajectory into its corresponding track segment delay, initial waiting time and transfer delay. We distinguish between two different types of passenger delay in relation to the public transit network: average passenger delay and total passenger delay. We employ temporal clustering on these two quantities to reveal daily and seasonal regularity in delay patterns of the transit network. The estimation and clustering methods are demonstrated on one year of data from Washington metro network. The data consists of schedule information and smart card data which includes passenger-train assignment of the metro network for the months of August 2017 to August 2018. Our findings show that the average passenger delay is relatively stable throughout the day. The temporal clustering reveals pronounced and recurrent and thus predictable daily and weekly patterns with distinct characteristics for certain months.
Aggregated Deep Local Features for Remote Sensing Image Retrieval
Mar 22, 2019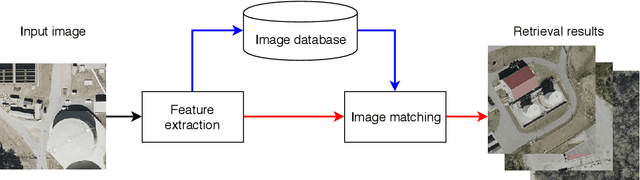


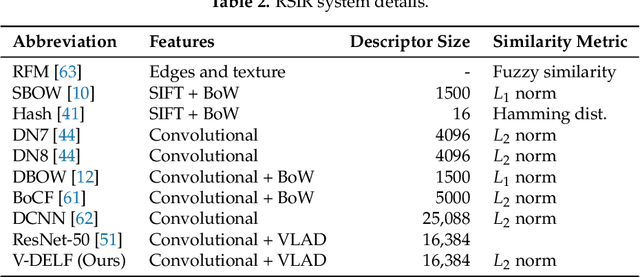
Remote Sensing Image Retrieval remains a challenging topic due to the special nature of Remote Sensing Imagery. Such images contain various different semantic objects, which clearly complicates the retrieval task. In this paper, we present an image retrieval pipeline that uses attentive, local convolutional features and aggregates them using the Vector of Locally Aggregated Descriptors (VLAD) to produce a global descriptor. We study various system parameters such as the multiplicative and additive attention mechanisms and descriptor dimensionality. We propose a query expansion method that requires no external inputs. Experiments demonstrate that even without training, the local convolutional features and global representation outperform other systems. After system tuning, we can achieve state-of-the-art or competitive results. Furthermore, we observe that our query expansion method increases overall system performance by about 3%, using only the top-three retrieved images. Finally, we show how dimensionality reduction produces compact descriptors with increased retrieval performance and fast retrieval computation times, e.g. 50% faster than the current systems.
* Published in Remote Sensing. The first two authors have equal contribution
A Practical Framework for ROI Detection in Medical Images -- a case study for hip detection in anteroposterior pelvic radiographs
Mar 02, 2021
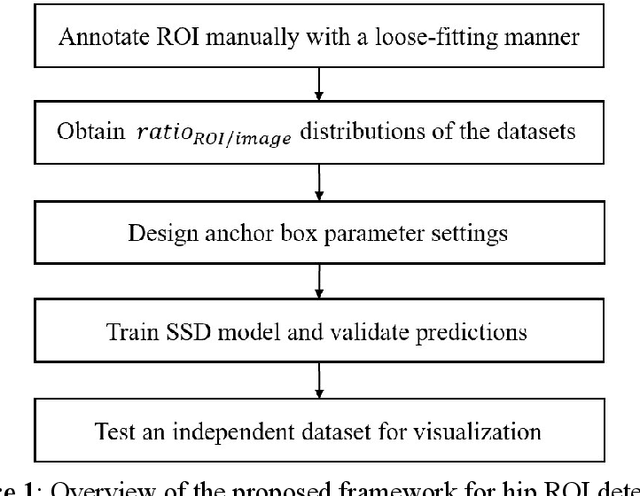
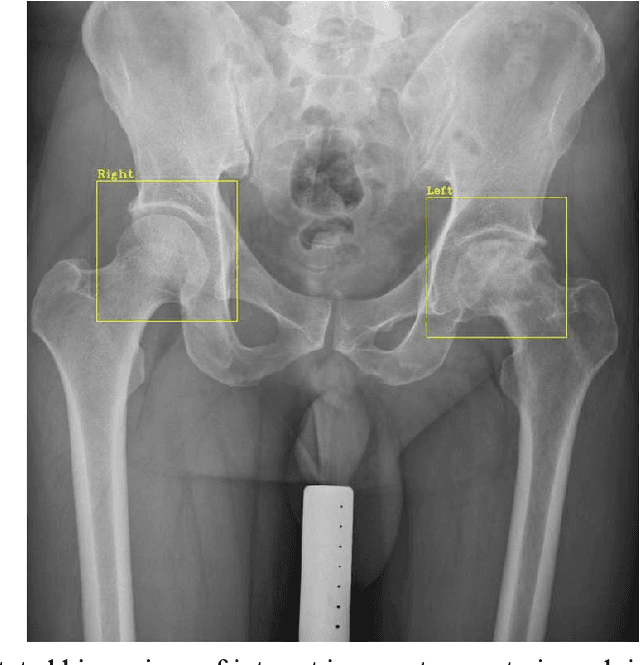
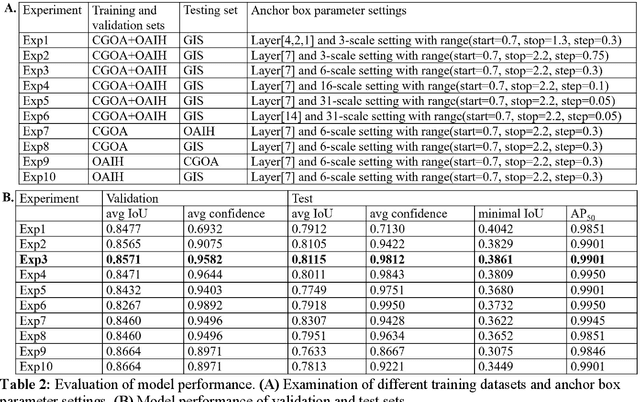
Purpose Automated detection of region of interest (ROI) is a critical step for many medical image applications such as heart ROIs detection in perfusion MRI images, lung boundary detection in chest X-rays, and femoral head detection in pelvic radiographs. Thus, we proposed a practical framework of ROIs detection in medical images, with a case study for hip detection in anteroposterior (AP) pelvic radiographs. Materials and Methods: We conducted a retrospective study which analyzed hip joints seen on 7,399 AP pelvic radiographs from three diverse sources, including 4,290 high resolution radiographs from Chang Gung Memorial Hospital Osteoarthritis, 3,008 low to medium resolution radiographs from Osteoarthritis Initiative, and 101 heterogeneous radiographs from Google image search engine. We presented a deep learning-based ROI detection framework utilizing single-shot multi-box detector (SSD) with ResNet-101 backbone and customized head structure based on the characteristics of the obtained datasets, whose ground truths were labeled by non-medical annotators in a simple graphical interface. Results: Our method achieved average intersection over union (IoU)=0.8115, average confidence=0.9812, and average precision with threshold IoU=0.5 (AP50)=0.9901 in the independent test set, suggesting that the detected hip regions have appropriately covered main features of the hip joints. Conclusion: The proposed approach featured on low-cost labeling, data-driven model design, and heterogeneous data testing. We have demonstrated the feasibility of training a robust hip region detector for AP pelvic radiographs. This practical framework has a promising potential for a wide range of medical image applications.
Adversarial Image Translation: Unrestricted Adversarial Examples in Face Recognition Systems
May 27, 2019

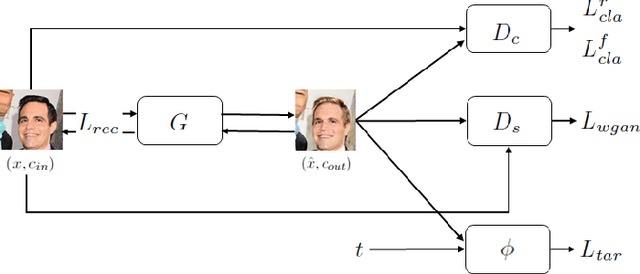

Thanks to recent advances in Deep Neural Networks (DNNs), face recognition systems have achieved high accuracy in classification of a large number of face images. However, recent works demonstrate that DNNs could be vulnerable to adversarial examples and raise concerns about robustness of face recognition systems. In particular adversarial examples that are not restricted to small perturbations could be more serious risks since conventional certified defenses might be ineffective against them. To shed light on the vulnerability to this type of adversarial examples, we propose a flexible and efficient method to generate unrestricted adversarial examples using image translation techniques. Our method enables us to translate a source image into any desired facial appearance with large perturbations so that target face recognition systems could be deceived. Through our experiments, we demonstrate that our method achieves about 90% and 30% attack success rates under a white- and black-box setting, respectively. We also illustrate that our translated images are perceptually realistic and maintain personal identity while the perturbations are large enough to bypass certified defenses.
Image Moment Models for Extended Object Tracking
Apr 09, 2018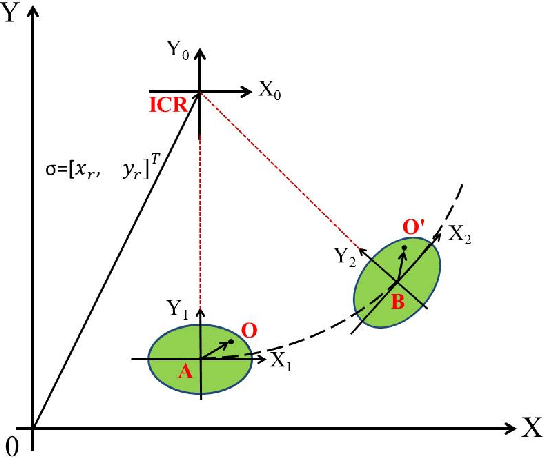

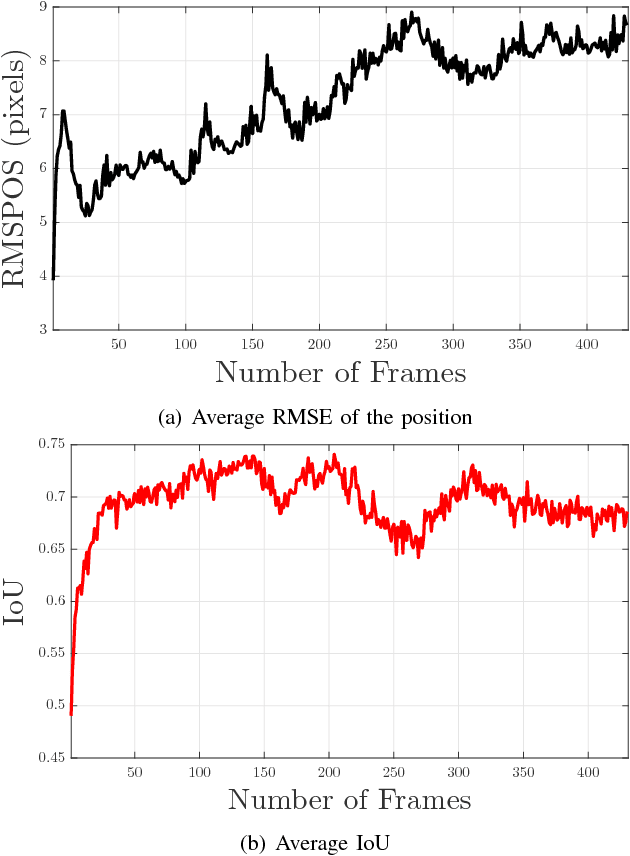
In this paper, a novel image moments based model for shape estimation and tracking of an object moving with a complex trajectory is presented. The camera is assumed to be stationary looking at a moving object. Point features inside the object are sampled as measurements. An ellipsoidal approximation of the shape is assumed as a primitive shape. The shape of an ellipse is estimated using a combination of image moments. Dynamic model of image moments when the object moves under the constant velocity or coordinated turn motion model is derived as a function for the shape estimation of the object. An Unscented Kalman Filter-Interacting Multiple Model (UKF-IMM) filter algorithm is applied to estimate the shape of the object (approximated as an ellipse) and track its position and velocity. A likelihood function based on average log-likelihood is derived for the IMM filter. Simulation results of the proposed UKF-IMM algorithm with the image moments based models are presented that show the estimations of the shape of the object moving in complex trajectories. Comparison results, using intersection over union (IOU), and position and velocity root mean square errors (RMSE) as metrics, with a benchmark algorithm from literature are presented. Results on real image data captured from the quadcopter are also presented.
A Variational Perspective on Diffusion-Based Generative Models and Score Matching
Jun 05, 2021


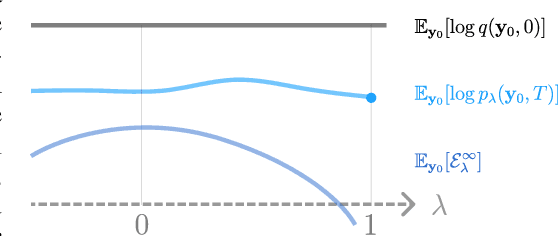
Discrete-time diffusion-based generative models and score matching methods have shown promising results in modeling high-dimensional image data. Recently, Song et al. (2021) show that diffusion processes that transform data into noise can be reversed via learning the score function, i.e. the gradient of the log-density of the perturbed data. They propose to plug the learned score function into an inverse formula to define a generative diffusion process. Despite the empirical success, a theoretical underpinning of this procedure is still lacking. In this work, we approach the (continuous-time) generative diffusion directly and derive a variational framework for likelihood estimation, which includes continuous-time normalizing flows as a special case, and can be seen as an infinitely deep variational autoencoder. Under this framework, we show that minimizing the score-matching loss is equivalent to maximizing a lower bound of the likelihood of the plug-in reverse SDE proposed by Song et al. (2021), bridging the theoretical gap.
ODDObjects: A Framework for Multiclass Unsupervised Anomaly Detection on Masked Objects
Apr 26, 2021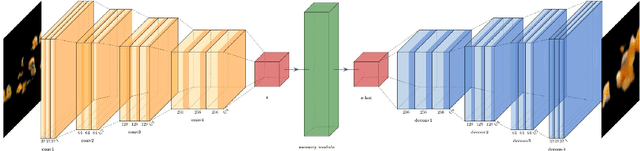



This paper presents a novel framework for unsupervised anomaly detection on masked objects called ODDObjects, which stands for Out-of-Distribution Detection on Objects. ODDObjects is designed to detect anomalies of various categories using unsupervised autoencoders trained on COCO-style datasets. The method utilizes autoencoder-based image reconstruction, where high reconstruction error indicates the possibility of an anomaly. The framework extends previous work on anomaly detection with autoencoders, comparing state-of-the-art models trained on object recognition datasets. Various model architectures were compared, and experimental results show that memory-augmented deep convolutional autoencoders perform the best at detecting out-of-distribution objects.
DepthwiseGANs: Fast Training Generative Adversarial Networks for Realistic Image Synthesis
Mar 06, 2019
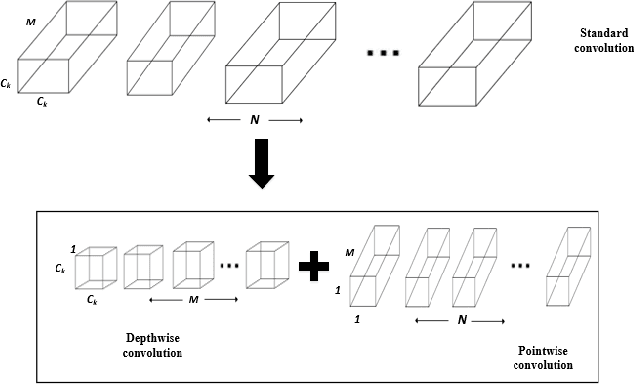
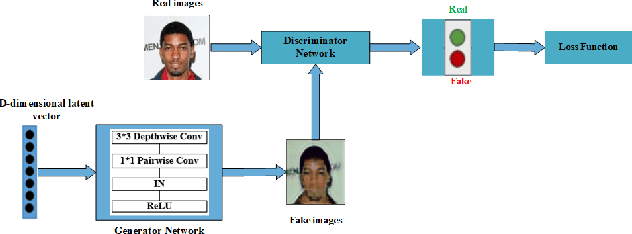
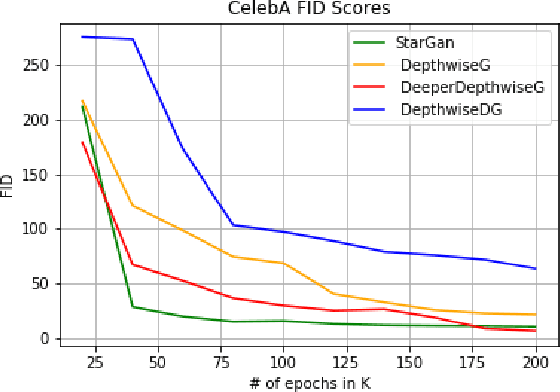
Recent work has shown significant progress in the direction of synthetic data generation using Generative Adversarial Networks (GANs). GANs have been applied in many fields of computer vision including text-to-image conversion, domain transfer, super-resolution, and image-to-video applications. In computer vision, traditional GANs are based on deep convolutional neural networks. However, deep convolutional neural networks can require extensive computational resources because they are based on multiple operations performed by convolutional layers, which can consist of millions of trainable parameters. Training a GAN model can be difficult and it takes a significant amount of time to reach an equilibrium point. In this paper, we investigate the use of depthwise separable convolutions to reduce training time while maintaining data generation performance. Our results show that a DepthwiseGAN architecture can generate realistic images in shorter training periods when compared to a StarGan architecture, but that model capacity still plays a significant role in generative modelling. In addition, we show that depthwise separable convolutions perform best when only applied to the generator. For quality evaluation of generated images, we use the Fr\'echet Inception Distance (FID), which compares the similarity between the generated image distribution and that of the training dataset.
A Neural Compositional Paradigm for Image Captioning
Oct 23, 2018
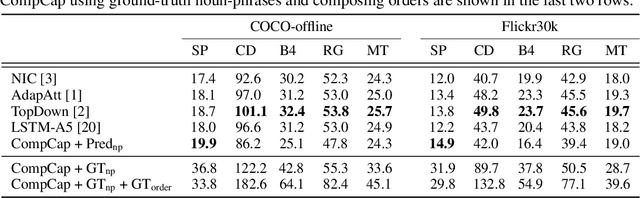
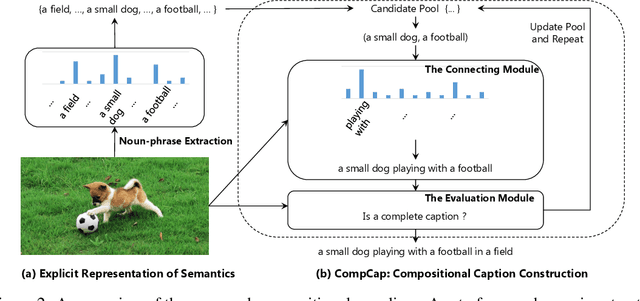
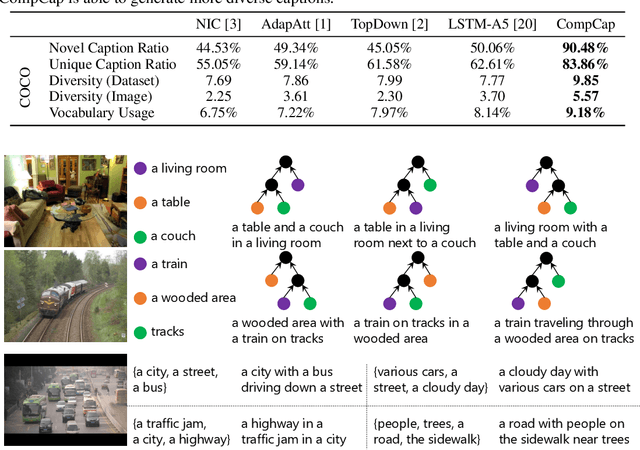
Mainstream captioning models often follow a sequential structure to generate captions, leading to issues such as introduction of irrelevant semantics, lack of diversity in the generated captions, and inadequate generalization performance. In this paper, we present an alternative paradigm for image captioning, which factorizes the captioning procedure into two stages: (1) extracting an explicit semantic representation from the given image; and (2) constructing the caption based on a recursive compositional procedure in a bottom-up manner. Compared to conventional ones, our paradigm better preserves the semantic content through an explicit factorization of semantics and syntax. By using the compositional generation procedure, caption construction follows a recursive structure, which naturally fits the properties of human language. Moreover, the proposed compositional procedure requires less data to train, generalizes better, and yields more diverse captions.
Data Efficient Unsupervised Domain Adaptation for Cross-Modality Image Segmentation
Jul 05, 2019
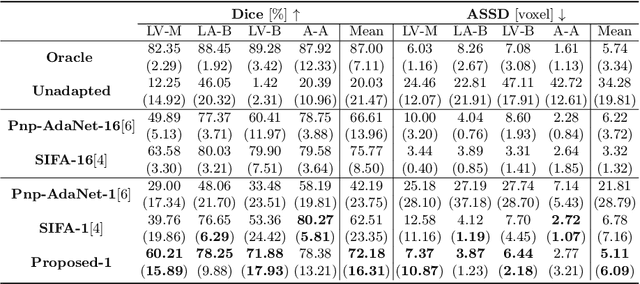
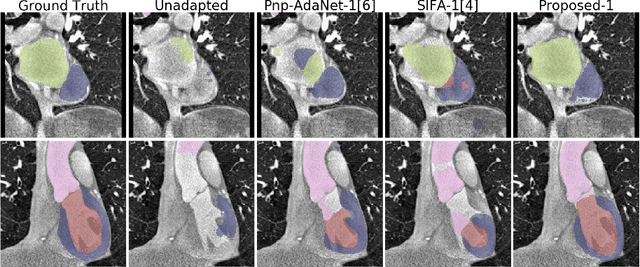
Deep learning models trained on medical images from a source domain (e.g. imaging modality) often fail when deployed on images from a different target domain, despite imaging common anatomical structures. Deep unsupervised domain adaptation (UDA) aims to improve the performance of a deep neural network model on a target domain, using solely unlabelled target domain data and labelled source domain data. However, current state-of-the-art methods exhibit reduced performance when target data is scarce. In this work, we introduce a new data efficient UDA method for multi-domain medical image segmentation. The proposed method combines a novel VAE-based feature prior matching, which is data-efficient, and domain adversarial training to learn a shared domain-invariant latent space which is exploited during segmentation. Our method is evaluated on a public multi-modality cardiac image segmentation dataset by adapting from the labelled source domain (3D MRI) to the unlabelled target domain (3D CT). We show that by using only one single unlabelled 3D CT scan, the proposed architecture outperforms the state-of-the-art in the same setting. Finally, we perform ablation studies on prior matching and domain adversarial training to shed light on the theoretical grounding of the proposed method.