 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Shape-conditioned Image Generation by Learning Latent Appearance Representation from Unpaired Data
Nov 29, 2018

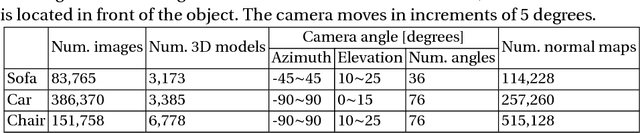
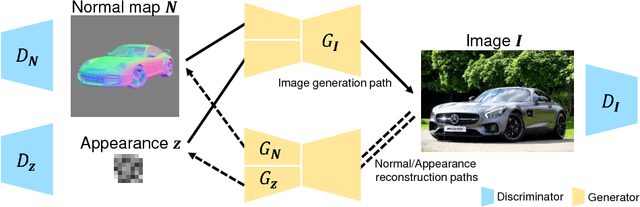
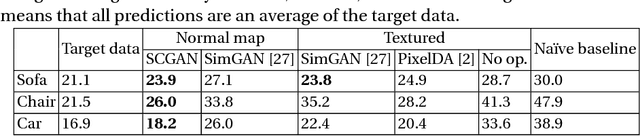
Conditional image generation is effective for diverse tasks including training data synthesis for learning-based computer vision. However, despite the recent advances in generative adversarial networks (GANs), it is still a challenging task to generate images with detailed conditioning on object shapes. Existing methods for conditional image generation use category labels and/or keypoints and are only give limited control over object categories. In this work, we present SCGAN, an architecture to generate images with a desired shape specified by an input normal map. The shape-conditioned image generation task is achieved by explicitly modeling the image appearance via a latent appearance vector. The network is trained using unpaired training samples of real images and rendered normal maps. This approach enables us to generate images of arbitrary object categories with the target shape and diverse image appearances. We show the effectiveness of our method through both qualitative and quantitative evaluation on training data generation tasks.
Image-to-Video Person Re-Identification by Reusing Cross-modal Embeddings
Oct 22, 2018
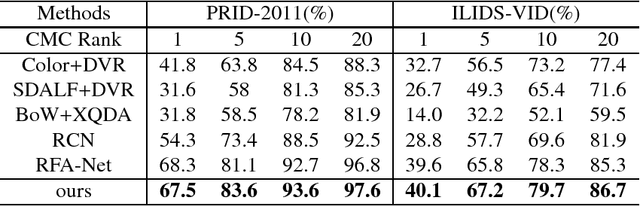
Image-to-video person re-identification identifies a target person by a probe image from quantities of pedestrian videos captured by non-overlapping cameras. Despite the great progress achieved,it's still challenging to match in the multimodal scenario,i.e. between image and video. Currently,state-of-the-art approaches mainly focus on the task-specific data,neglecting the extra information on the different but related tasks. In this paper,we propose an end-to-end neural network framework for image-to-video person reidentification by leveraging cross-modal embeddings learned from extra information.Concretely speaking,cross-modal embeddings from image captioning and video captioning models are reused to help learned features be projected into a coordinated space,where similarity can be directly computed. Besides,training steps from fixed model reuse approach are integrated into our framework,which can incorporate beneficial information and eventually make the target networks independent of existing models. Apart from that,our proposed framework resorts to CNNs and LSTMs for extracting visual and spatiotemporal features,and combines the strengths of identification and verification model to improve the discriminative ability of the learned feature. The experimental results demonstrate the effectiveness of our framework on narrowing down the gap between heterogeneous data and obtaining observable improvement in image-to-video person re-identification.
Assessing Reliability and Challenges of Uncertainty Estimations for Medical Image Segmentation
Jul 07, 2019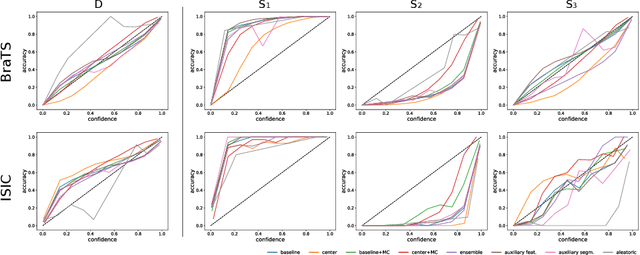
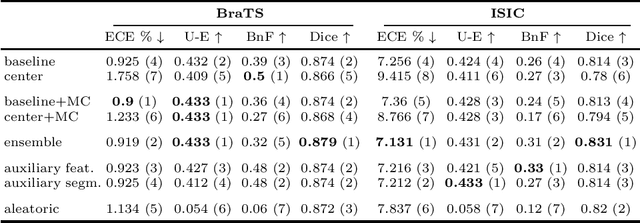
Despite the recent improvements in overall accuracy, deep learning systems still exhibit low levels of robustness. Detecting possible failures is critical for a successful clinical integration of these systems, where each data point corresponds to an individual patient. Uncertainty measures are a promising direction to improve failure detection since they provide a measure of a system's confidence. Although many uncertainty estimation methods have been proposed for deep learning, little is known on their benefits and current challenges for medical image segmentation. Therefore, we report results of evaluating common voxel-wise uncertainty measures with respect to their reliability, and limitations on two medical image segmentation datasets. Results show that current uncertainty methods perform similarly and although they are well-calibrated at the dataset level, they tend to be miscalibrated at subject-level. Therefore, the reliability of uncertainty estimates is compromised, highlighting the importance of developing subject-wise uncertainty estimations. Additionally, among the benchmarked methods, we found auxiliary networks to be a valid alternative to common uncertainty methods since they can be applied to any previously trained segmentation model.
Generative Image Inpainting with Contextual Attention
Mar 21, 2018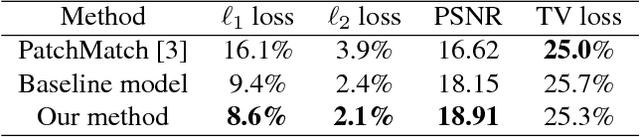

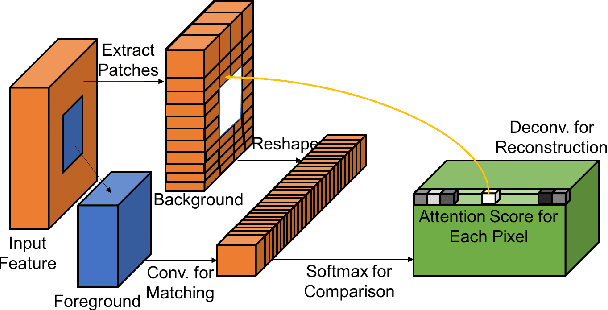
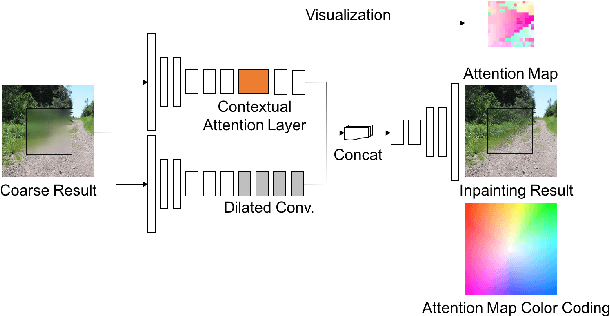
Recent deep learning based approaches have shown promising results for the challenging task of inpainting large missing regions in an image. These methods can generate visually plausible image structures and textures, but often create distorted structures or blurry textures inconsistent with surrounding areas. This is mainly due to ineffectiveness of convolutional neural networks in explicitly borrowing or copying information from distant spatial locations. On the other hand, traditional texture and patch synthesis approaches are particularly suitable when it needs to borrow textures from the surrounding regions. Motivated by these observations, we propose a new deep generative model-based approach which can not only synthesize novel image structures but also explicitly utilize surrounding image features as references during network training to make better predictions. The model is a feed-forward, fully convolutional neural network which can process images with multiple holes at arbitrary locations and with variable sizes during the test time. Experiments on multiple datasets including faces (CelebA, CelebA-HQ), textures (DTD) and natural images (ImageNet, Places2) demonstrate that our proposed approach generates higher-quality inpainting results than existing ones. Code, demo and models are available at: https://github.com/JiahuiYu/generative_inpainting.
A Tour of Unsupervised Deep Learning for Medical Image Analysis
Dec 19, 2018

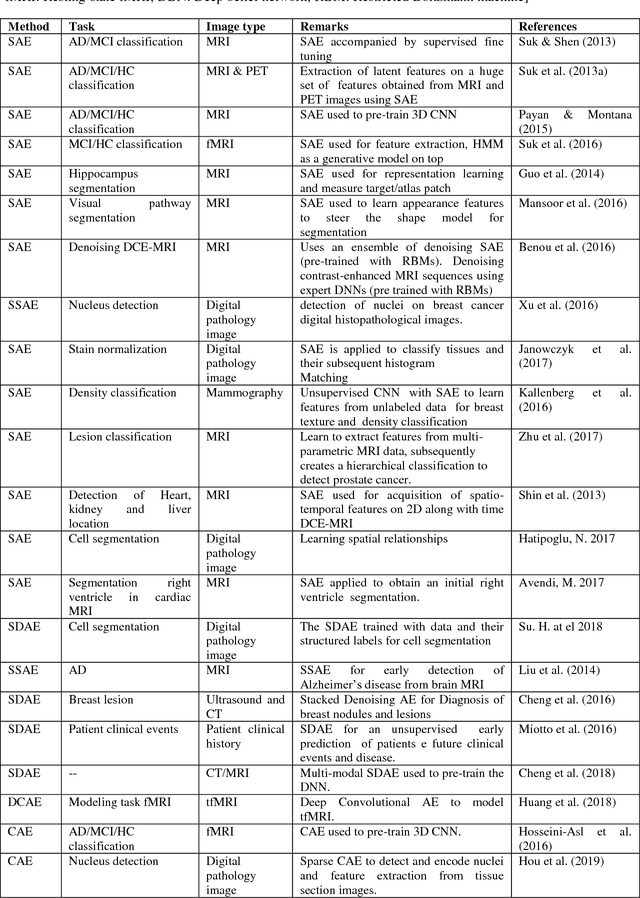
Interpretation of medical images for diagnosis and treatment of complex disease from high-dimensional and heterogeneous data remains a key challenge in transforming healthcare. In the last few years, both supervised and unsupervised deep learning achieved promising results in the area of medical imaging and image analysis. Unlike supervised learning which is biased towards how it is being supervised and manual efforts to create class label for the algorithm, unsupervised learning derive insights directly from the data itself, group the data and help to make data driven decisions without any external bias. This review systematically presents various unsupervised models applied to medical image analysis, including autoencoders and its several variants, Restricted Boltzmann machines, Deep belief networks, Deep Boltzmann machine and Generative adversarial network. Future research opportunities and challenges of unsupervised techniques for medical image analysis have also been discussed.
Visual Question Rewriting for Increasing Response Rate
Jun 04, 2021
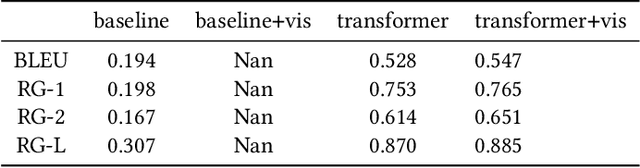
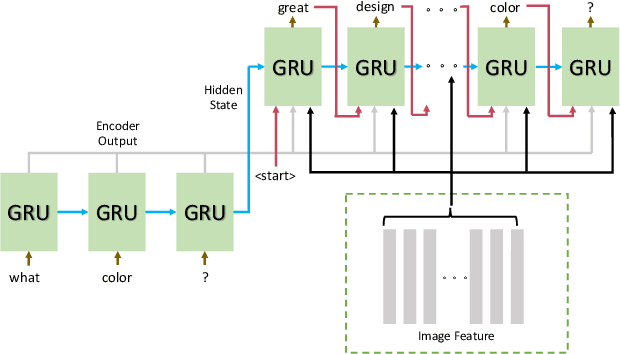
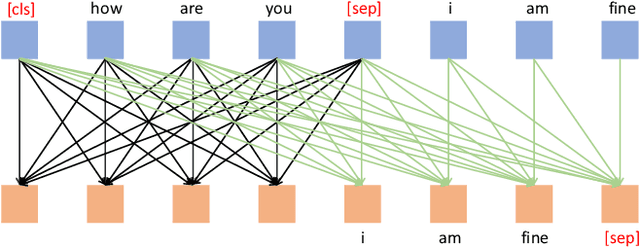
When a human asks questions online, or when a conversational virtual agent asks human questions, questions triggering emotions or with details might more likely to get responses or answers. we explore how to automatically rewrite natural language questions to improve the response rate from people. In particular, a new task of Visual Question Rewriting(VQR) task is introduced to explore how visual information can be used to improve the new questions. A data set containing around 4K bland questions, attractive questions and images triples is collected. We developed some baseline sequence to sequence models and more advanced transformer based models, which take a bland question and a related image as input and output a rewritten question that is expected to be more attractive. Offline experiments and mechanical Turk based evaluations show that it is possible to rewrite bland questions in a more detailed and attractive way to increase the response rate, and images can be helpful.
All-Day Object Tracking for Unmanned Aerial Vehicle
Jan 24, 2021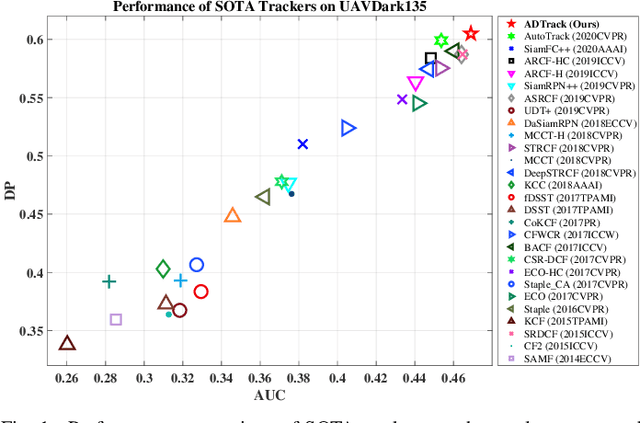
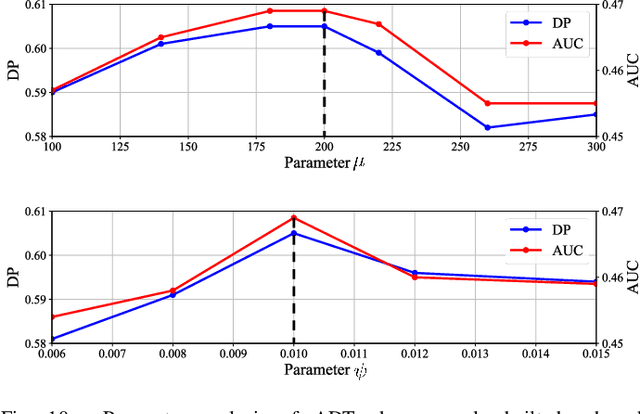

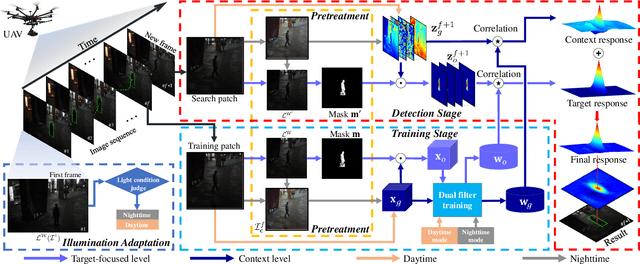
Visual object tracking, which is representing a major interest in image processing field, has facilitated numerous real world applications. Among them, equipping unmanned aerial vehicle (UAV) with real time robust visual trackers for all day aerial maneuver, is currently attracting incremental attention and has remarkably broadened the scope of applications of object tracking. However, prior tracking methods have merely focused on robust tracking in the well-illuminated scenes, while ignoring trackers' capabilities to be deployed in the dark. In darkness, the conditions can be more complex and harsh, easily posing inferior robust tracking or even tracking failure. To this end, this work proposed a novel discriminative correlation filter based tracker with illumination adaptive and anti dark capability, namely ADTrack. ADTrack firstly exploits image illuminance information to enable adaptability of the model to the given light condition. Then, by virtue of an efficient and effective image enhancer, ADTrack carries out image pretreatment, where a target aware mask is generated. Benefiting from the mask, ADTrack aims to solve a dual regression problem where dual filters, i.e., the context filter and target focused filter, are trained with mutual constraint. Thus ADTrack is able to maintain continuously favorable performance in all-day conditions. Besides, this work also constructed one UAV nighttime tracking benchmark UAVDark135, comprising of more than 125k manually annotated frames, which is also very first UAV nighttime tracking benchmark. Exhaustive experiments are extended on authoritative daytime benchmarks, i.e., UAV123 10fps, DTB70, and the newly built dark benchmark UAVDark135, which have validated the superiority of ADTrack in both bright and dark conditions on a single CPU.
LocalTrans: A Multiscale Local Transformer Network for Cross-Resolution Homography Estimation
Jun 13, 2021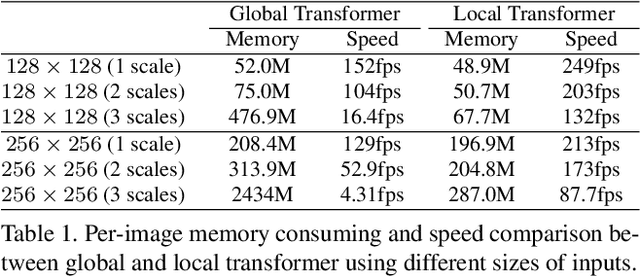
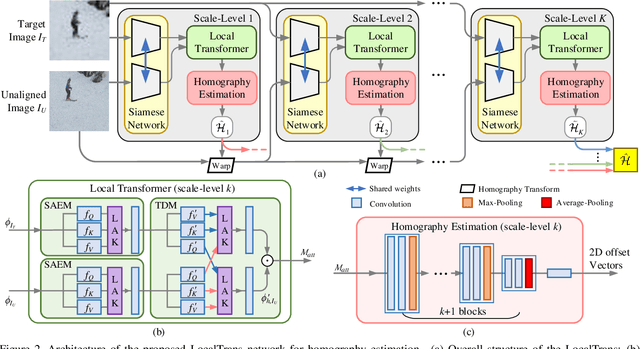
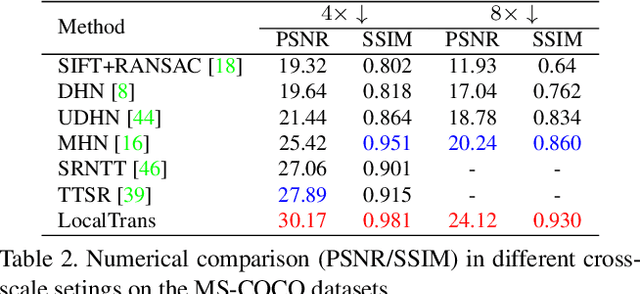
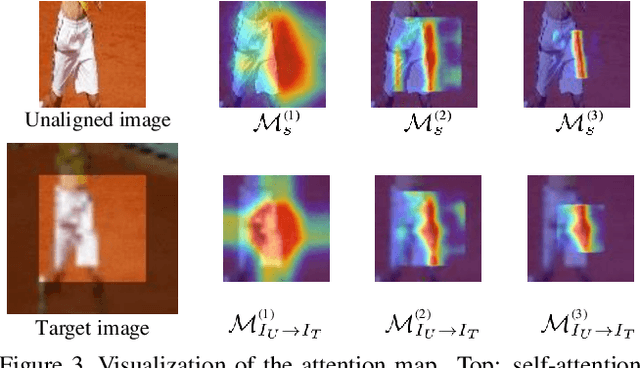
Cross-resolution image alignment is a key problem in multiscale gigapixel photography, which requires to estimate homography matrix using images with large resolution gap. Existing deep homography methods concatenate the input images or features, neglecting the explicit formulation of correspondences between them, which leads to degraded accuracy in cross-resolution challenges. In this paper, we consider the cross-resolution homography estimation as a multimodal problem, and propose a local transformer network embedded within a multiscale structure to explicitly learn correspondences between the multimodal inputs, namely, input images with different resolutions. The proposed local transformer adopts a local attention map specifically for each position in the feature. By combining the local transformer with the multiscale structure, the network is able to capture long-short range correspondences efficiently and accurately. Experiments on both the MS-COCO dataset and the real-captured cross-resolution dataset show that the proposed network outperforms existing state-of-the-art feature-based and deep-learning-based homography estimation methods, and is able to accurately align images under $10\times$ resolution gap.
Selective Replay Enhances Learning in Online Continual Analogical Reasoning
Mar 06, 2021
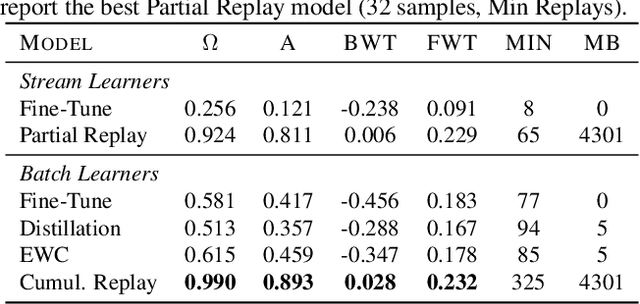

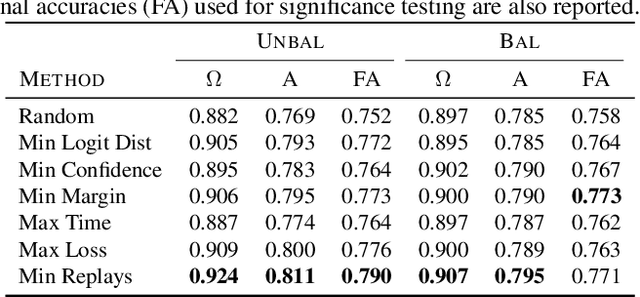
In continual learning, a system learns from non-stationary data streams or batches without catastrophic forgetting. While this problem has been heavily studied in supervised image classification and reinforcement learning, continual learning in neural networks designed for abstract reasoning has not yet been studied. Here, we study continual learning of analogical reasoning. Analogical reasoning tests such as Raven's Progressive Matrices (RPMs) are commonly used to measure non-verbal abstract reasoning in humans, and recently offline neural networks for the RPM problem have been proposed. In this paper, we establish experimental baselines, protocols, and forward and backward transfer metrics to evaluate continual learners on RPMs. We employ experience replay to mitigate catastrophic forgetting. Prior work using replay for image classification tasks has found that selectively choosing the samples to replay offers little, if any, benefit over random selection. In contrast, we find that selective replay can significantly outperform random selection for the RPM task.
An Interaction-based Convolutional Neural Network (ICNN) Towards Better Understanding of COVID-19 X-ray Images
Jun 13, 2021
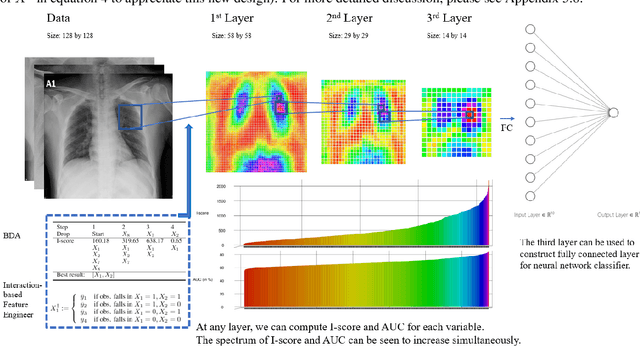

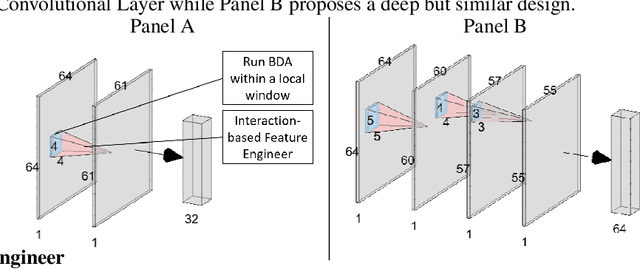
The field of Explainable Artificial Intelligence (XAI) aims to build explainable and interpretable machine learning (or deep learning) methods without sacrificing prediction performance. Convolutional Neural Networks (CNNs) have been successful in making predictions, especially in image classification. However, these famous deep learning models use tens of millions of parameters based on a large number of pre-trained filters which have been repurposed from previous data sets. We propose a novel Interaction-based Convolutional Neural Network (ICNN) that does not make assumptions about the relevance of local information. Instead, we use a model-free Influence Score (I-score) to directly extract the influential information from images to form important variable modules. We demonstrate that the proposed method produces state-of-the-art prediction performance of 99.8% on a real-world data set classifying COVID-19 Chest X-ray images without sacrificing the explanatory power of the model. This proposed design can efficiently screen COVID-19 patients before human diagnosis, and will be the benchmark for addressing future XAI problems in large-scale data sets.