 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Task-driven Self-supervised Bi-channel Networks Learning for Diagnosis of Breast Cancers with Mammography
Jan 15, 2021
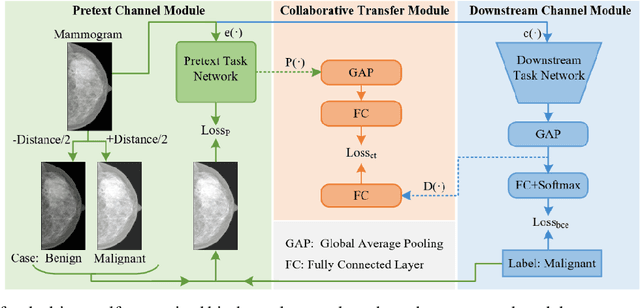

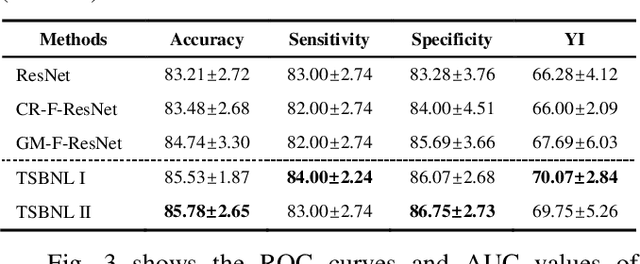
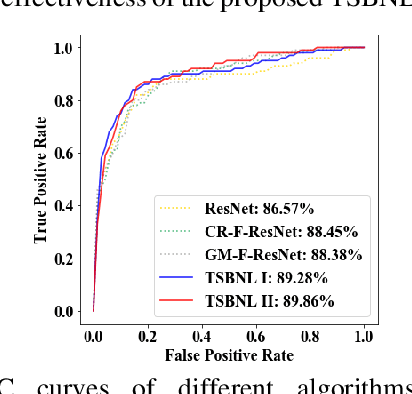
Deep learning can promote the mammography-based computer-aided diagnosis (CAD) for breast cancers, but it generally suffers from the small size sample problem. In this work, a task-driven self-supervised bi-channel networks (TSBNL) framework is proposed to improve the performance of classification network with limited mammograms. In particular, a new gray-scale image mapping (GSIM) task for image restoration is designed as the pretext task to improve discriminate feature representation with label information of mammograms. The TSBNL then innovatively integrates this image restoration network and the downstream classification network into a unified SSL framework, and transfers the knowledge from the pretext network to the classification network with improved diagnostic accuracy. The proposed algorithm is evaluated on a public INbreast mammogram dataset. The experimental results indicate that it outperforms the conventional SSL algorithms for diagnosis of breast cancers with limited samples.
DFM: A Performance Baseline for Deep Feature Matching
Jun 14, 2021
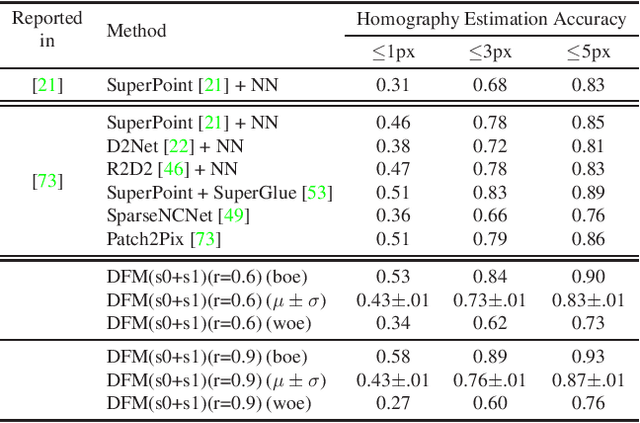
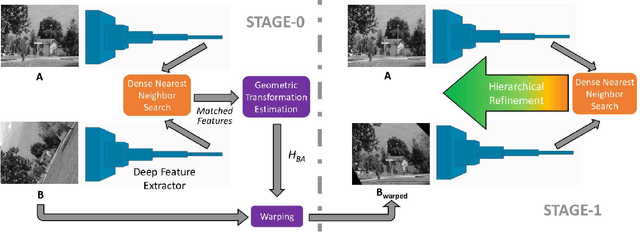

A novel image matching method is proposed that utilizes learned features extracted by an off-the-shelf deep neural network to obtain a promising performance. The proposed method uses pre-trained VGG architecture as a feature extractor and does not require any additional training specific to improve matching. Inspired by well-established concepts in the psychology area, such as the Mental Rotation paradigm, an initial warping is performed as a result of a preliminary geometric transformation estimate. These estimates are simply based on dense matching of nearest neighbors at the terminal layer of VGG network outputs of the images to be matched. After this initial alignment, the same approach is repeated again between reference and aligned images in a hierarchical manner to reach a good localization and matching performance. Our algorithm achieves 0.57 and 0.80 overall scores in terms of Mean Matching Accuracy (MMA) for 1 pixel and 2 pixels thresholds respectively on Hpatches dataset, which indicates a better performance than the state-of-the-art.
Learning Cascaded Detection Tasks with Weakly-Supervised Domain Adaptation
Jul 09, 2021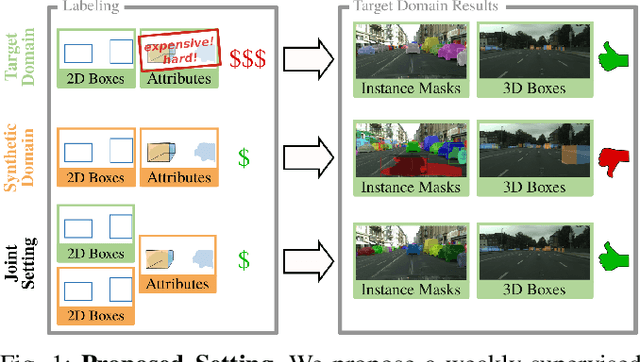
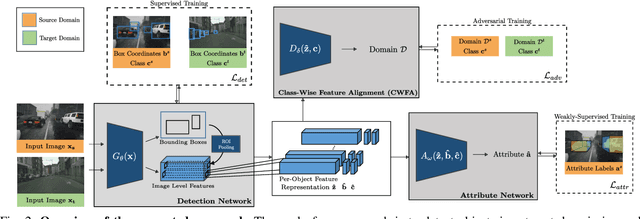


In order to handle the challenges of autonomous driving, deep learning has proven to be crucial in tackling increasingly complex tasks, such as 3D detection or instance segmentation. State-of-the-art approaches for image-based detection tasks tackle this complexity by operating in a cascaded fashion: they first extract a 2D bounding box based on which additional attributes, e.g. instance masks, are inferred. While these methods perform well, a key challenge remains the lack of accurate and cheap annotations for the growing variety of tasks. Synthetic data presents a promising solution but, despite the effort in domain adaptation research, the gap between synthetic and real data remains an open problem. In this work, we propose a weakly supervised domain adaptation setting which exploits the structure of cascaded detection tasks. In particular, we learn to infer the attributes solely from the source domain while leveraging 2D bounding boxes as weak labels in both domains to explain the domain shift. We further encourage domain-invariant features through class-wise feature alignment using ground-truth class information, which is not available in the unsupervised setting. As our experiments demonstrate, the approach is competitive with fully supervised settings while outperforming unsupervised adaptation approaches by a large margin.
Voice2Mesh: Cross-Modal 3D Face Model Generation from Voices
Apr 21, 2021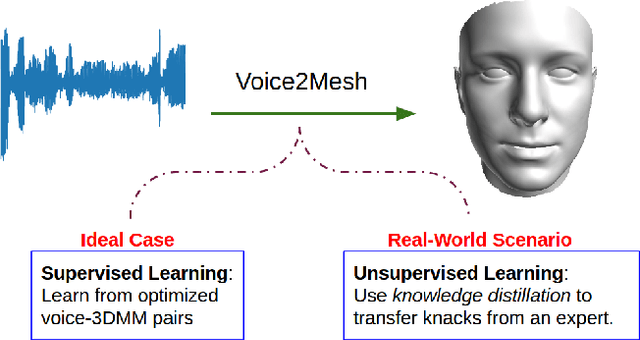
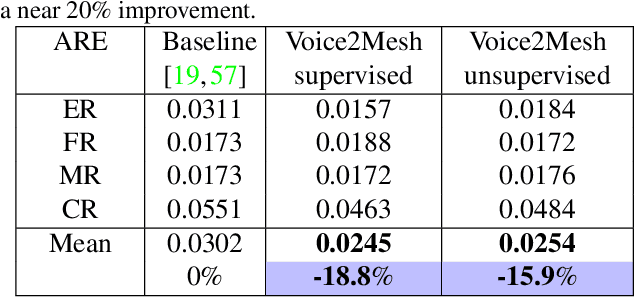
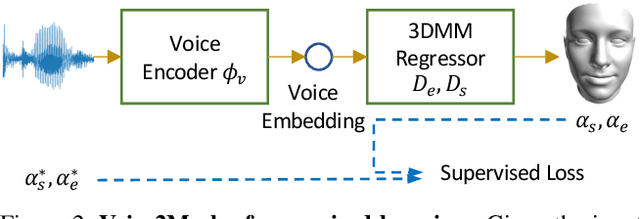

This work focuses on the analysis that whether 3D face models can be learned from only the speech inputs of speakers. Previous works for cross-modal face synthesis study image generation from voices. However, image synthesis includes variations such as hairstyles, backgrounds, and facial textures, that are arguably irrelevant to voice or without direct studies to show correlations. We instead investigate the ability to reconstruct 3D faces to concentrate on only geometry, which is more physiologically grounded. We propose both the supervised learning and unsupervised learning frameworks. Especially we demonstrate how unsupervised learning is possible in the absence of a direct voice-to-3D-face dataset under limited availability of 3D face scans when the model is equipped with knowledge distillation. To evaluate the performance, we also propose several metrics to measure the geometric fitness of two 3D faces based on points, lines, and regions. We find that 3D face shapes can be reconstructed from voices. Experimental results suggest that 3D faces can be reconstructed from voices, and our method can improve the performance over the baseline. The best performance gains (15% - 20%) on ear-to-ear distance ratio metric (ER) coincides with the intuition that one can roughly envision whether a speaker's face is overall wider or thinner only from a person's voice. See our project page for codes and data.
Memory Efficient 3D U-Net with Reversible Mobile Inverted Bottlenecks for Brain Tumor Segmentation
Apr 21, 2021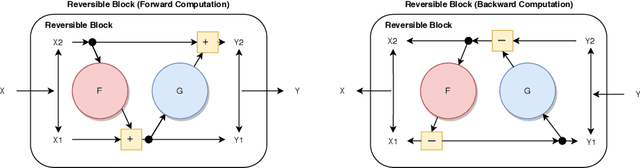

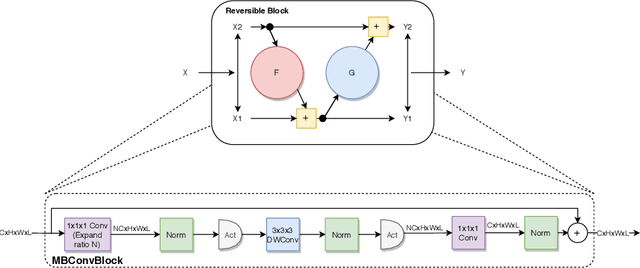
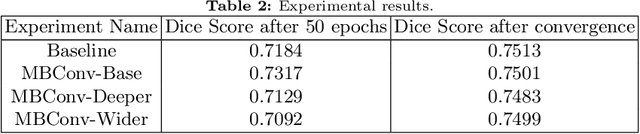
We propose combining memory saving techniques with traditional U-Net architectures to increase the complexity of the models on the Brain Tumor Segmentation (BraTS) challenge. The BraTS challenge consists of a 3D segmentation of a 240x240x155x4 input image into a set of tumor classes. Because of the large volume and need for 3D convolutional layers, this task is very memory intensive. To address this, prior approaches use smaller cropped images while constraining the model's depth and width. Our 3D U-Net uses a reversible version of the mobile inverted bottleneck block defined in MobileNetV2, MnasNet and the more recent EfficientNet architectures to save activation memory during training. Using reversible layers enables the model to recompute input activations given the outputs of that layer, saving memory by eliminating the need to store activations during the forward pass. The inverted residual bottleneck block uses lightweight depthwise separable convolutions to reduce computation by decomposing convolutions into a pointwise convolution and a depthwise convolution. Further, this block inverts traditional bottleneck blocks by placing an intermediate expansion layer between the input and output linear 1x1 convolution, reducing the total number of channels. Given a fixed memory budget, with these memory saving techniques, we are able to train image volumes up to 3x larger, models with 25% more depth, or models with up to 2x the number of channels than a corresponding non-reversible network.
* 11 pages, 5 figures, Published at MICCAI Brainles 2020
UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
Dec 31, 2020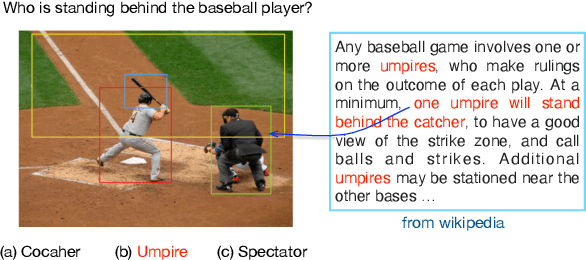

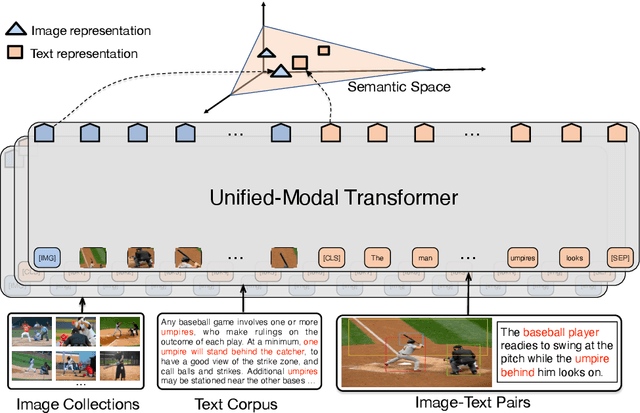
Existed pre-training methods either focus on single-modal tasks or multi-modal tasks, and cannot effectively adapt to each other. They can only utilize single-modal data (i.e. text or image) or limited multi-modal data (i.e. image-text pairs). In this work, we propose a unified-modal pre-training architecture, namely UNIMO, which can effectively adapt to both single-modal and multi-modal understanding and generation tasks. Large scale of free text corpus and image collections can be utilized to improve the capability of visual and textual understanding, and cross-modal contrastive learning (CMCL) is leveraged to align the textual and visual information into a unified semantic space over a corpus of image-text pairs. As the non-paired single-modal data is very rich, our model can utilize much larger scale of data to learn more generalizable representations. Moreover, the textual knowledge and visual knowledge can enhance each other in the unified semantic space. The experimental results show that UNIMO significantly improves the performance of several single-modal and multi-modal downstream tasks.
Single-pixel diffuser camera
May 06, 2021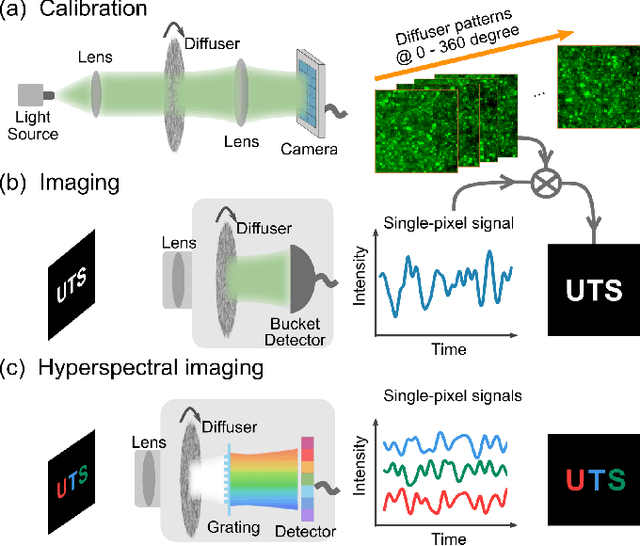
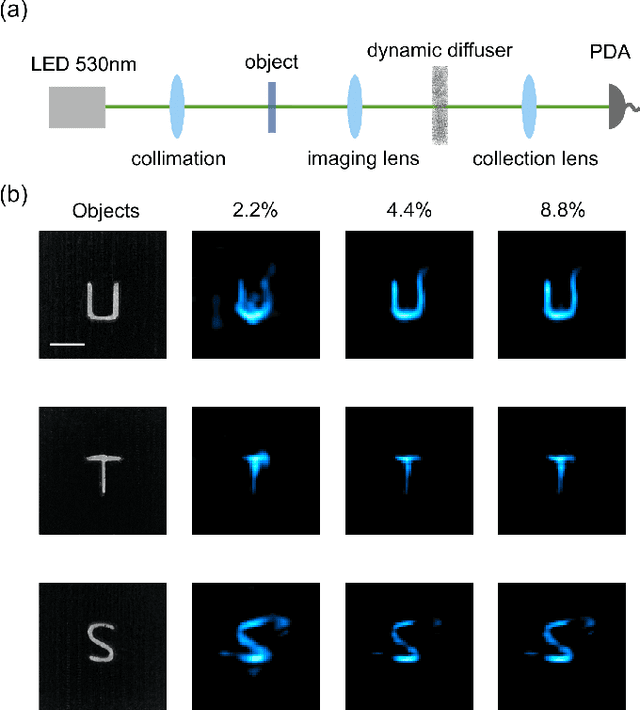
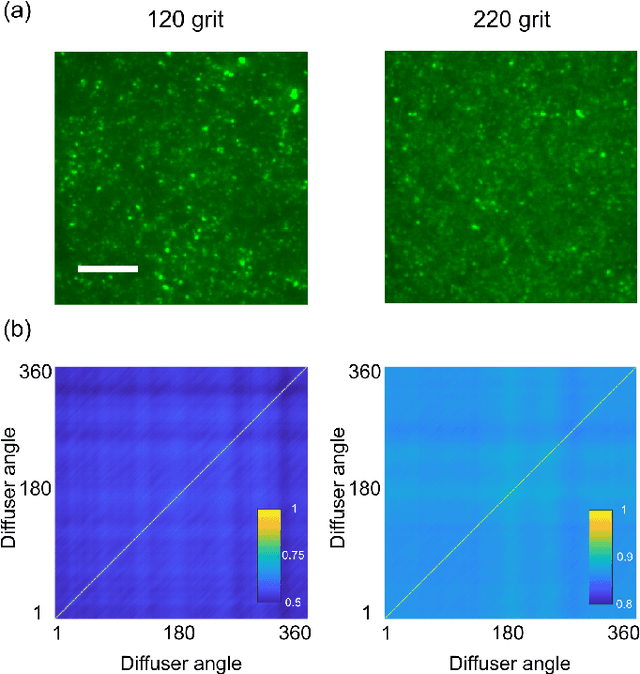
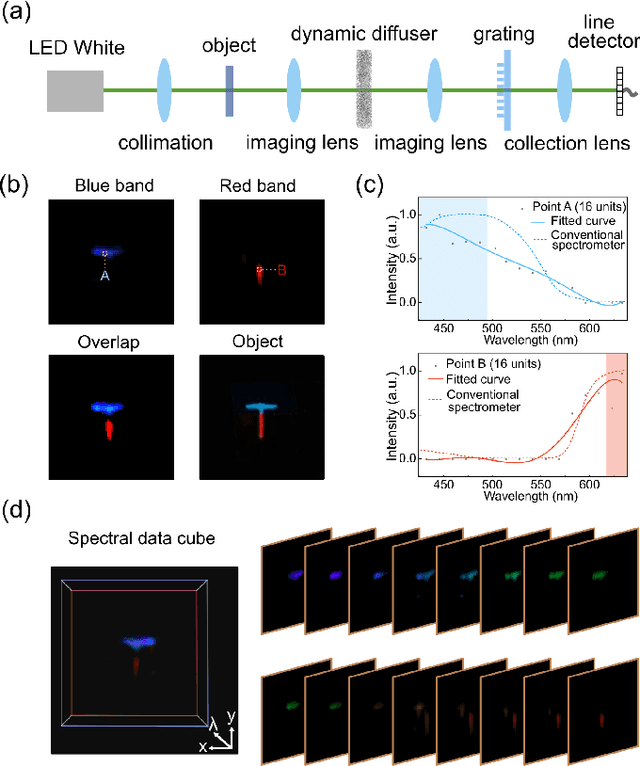
We present a compact, diffuser-assisted, single-pixel computational camera. A rotating ground glass diffuser is adopted, in preference to a commonly used digital micro-mirror device (DMD), to encode a two-dimensional (2D) image into single-pixel signals. We retrieve images with an 8.8% sampling ratio after the calibration of the pseudo-random pattern of the diffuser under incoherent illumination. Furthermore, we demonstrate hyperspectral imaging with line array detection by adding a diffraction grating. The implementation results in a cost-effective single-pixel camera for high-dimensional imaging, with potential for imaging in non-visible wavebands.
Medical Transformer: Universal Brain Encoder for 3D MRI Analysis
Apr 28, 2021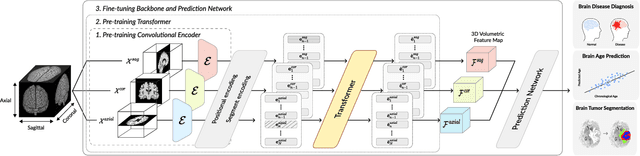
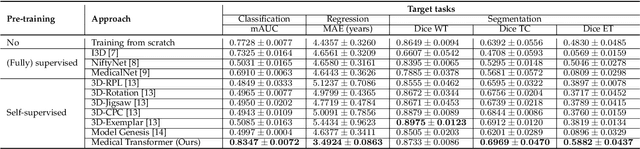
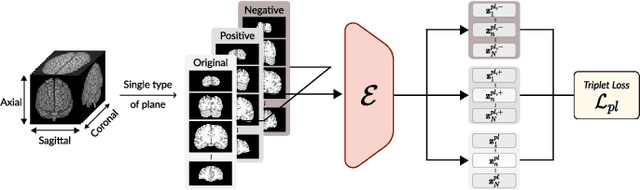
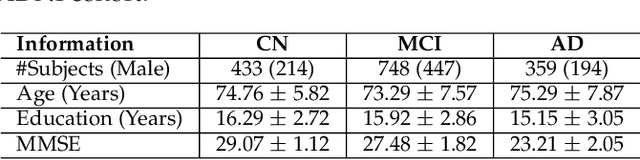
Transfer learning has gained attention in medical image analysis due to limited annotated 3D medical datasets for training data-driven deep learning models in the real world. Existing 3D-based methods have transferred the pre-trained models to downstream tasks, which achieved promising results with only a small number of training samples. However, they demand a massive amount of parameters to train the model for 3D medical imaging. In this work, we propose a novel transfer learning framework, called Medical Transformer, that effectively models 3D volumetric images in the form of a sequence of 2D image slices. To make a high-level representation in 3D-form empowering spatial relations better, we take a multi-view approach that leverages plenty of information from the three planes of 3D volume, while providing parameter-efficient training. For building a source model generally applicable to various tasks, we pre-train the model in a self-supervised learning manner for masked encoding vector prediction as a proxy task, using a large-scale normal, healthy brain magnetic resonance imaging (MRI) dataset. Our pre-trained model is evaluated on three downstream tasks: (i) brain disease diagnosis, (ii) brain age prediction, and (iii) brain tumor segmentation, which are actively studied in brain MRI research. The experimental results show that our Medical Transformer outperforms the state-of-the-art transfer learning methods, efficiently reducing the number of parameters up to about 92% for classification and
RECON: Rapid Exploration for Open-World Navigation with Latent Goal Models
Apr 12, 2021
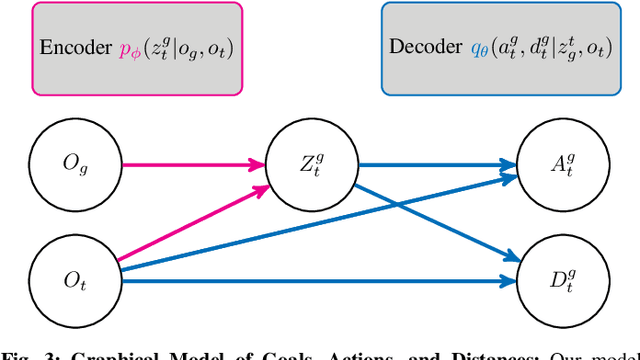
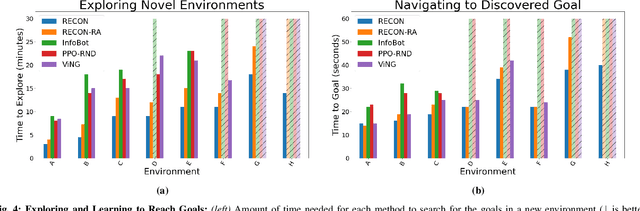
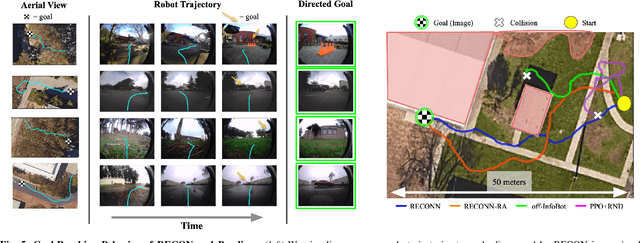
We describe a robotic learning system for autonomous navigation in diverse environments. At the core of our method are two components: (i) a non-parametric map that reflects the connectivity of the environment but does not require geometric reconstruction or localization, and (ii) a latent variable model of distances and actions that enables efficiently constructing and traversing this map. The model is trained on a large dataset of prior experience to predict the expected amount of time and next action needed to transit between the current image and a goal image. Training the model in this way enables it to develop a representation of goals robust to distracting information in the input images, which aids in deploying the system to quickly explore new environments. We demonstrate our method on a mobile ground robot in a range of outdoor navigation scenarios. Our method can learn to reach new goals, specified as images, in a radius of up to 80 meters in just 20 minutes, and reliably revisit these goals in changing environments. We also demonstrate our method's robustness to previously-unseen obstacles and variable weather conditions. We encourage the reader to visit the project website for videos of our experiments and demonstrations https://sites.google.com/view/recon-robot
RoI Tanh-polar Transformer Network for Face Parsing in the Wild
Feb 04, 2021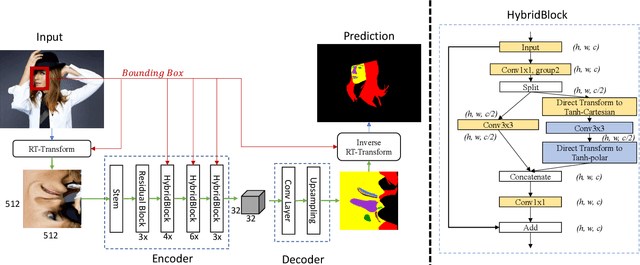


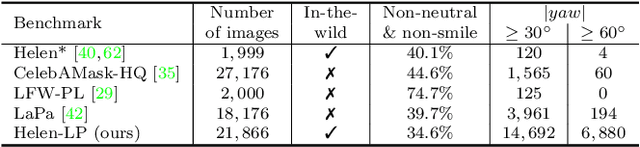
Face parsing aims to predict pixel-wise labels for facial components of a target face in an image. Existing approaches usually crop the target face from the input image with respect to a bounding box calculated during pre-processing, and thus can only parse inner facial Regions of Interest (RoIs). Peripheral regions like hair are ignored and nearby faces that are partially included in the bounding box can cause distractions. Moreover, these methods are only trained and evaluated on near-frontal portrait images and thus their performance for in-the-wild cases were unexplored. To address these issues, this paper makes three contributions. First, we introduce iBugMask dataset for face parsing in the wild containing 1,000 manually annotated images with large variations in sizes, poses, expressions and background, and Helen-LP, a large-pose training set containing 21,866 images generated using head pose augmentation. Second, we propose RoI Tanh-polar transform that warps the whole image to a Tanh-polar representation with a fixed ratio between the face area and the context, guided by the target bounding box. The new representation contains all information in the original image, and allows for rotation equivariance in the convolutional neural networks (CNNs). Third, we propose a hybrid residual representation learning block, coined HybridBlock, that contains convolutional layers in both the Tanh-polar space and the Tanh-Cartesian space, allowing for receptive fields of different shapes in CNNs. Through extensive experiments, we show that the proposed method significantly improves the state-of-the-art for face parsing in the wild.