 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CHASE: Robust Visual Tracking via Cell-Level Differentiable Neural Architecture Search
Jul 02, 2021
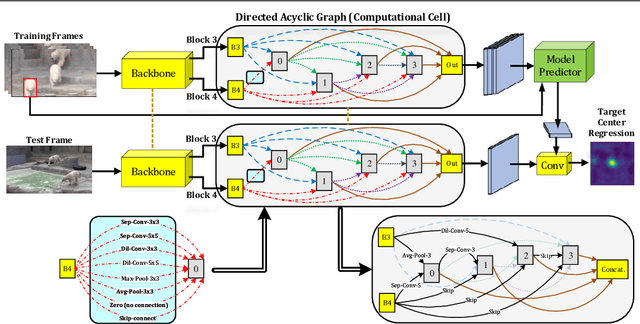

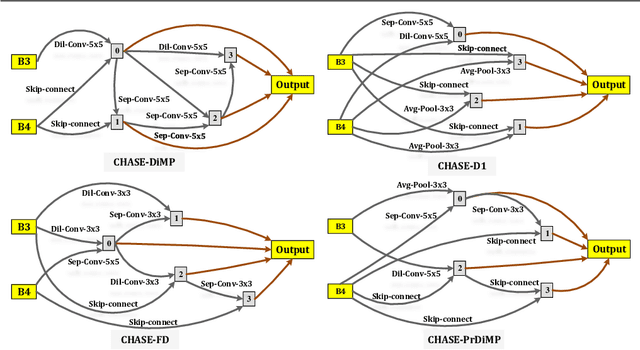
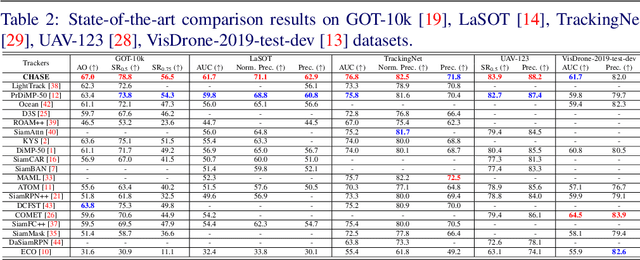
A strong visual object tracker nowadays relies on its well-crafted modules, which typically consist of manually-designed network architectures to deliver high-quality tracking results. Not surprisingly, the manual design process becomes a particularly challenging barrier, as it demands sufficient prior experience, enormous effort, intuition and perhaps some good luck. Meanwhile, neural architecture search has gaining grounds in practical applications such as image segmentation, as a promising method in tackling the issue of automated search of feasible network structures. In this work, we propose a novel cell-level differentiable architecture search mechanism to automate the network design of the tracking module, aiming to adapt backbone features to the objective of a tracking network during offline training. The proposed approach is simple, efficient, and with no need to stack a series of modules to construct a network. Our approach is easy to be incorporated into existing trackers, which is empirically validated using different differentiable architecture search-based methods and tracking objectives. Extensive experimental evaluations demonstrate the superior performance of our approach over five commonly-used benchmarks. Meanwhile, our automated searching process takes 41 (18) hours for the second (first) order DARTS method on the TrackingNet dataset.
Pick-and-Learn: Automatic Quality Evaluation for Noisy-Labeled Image Segmentation
Jul 27, 2019
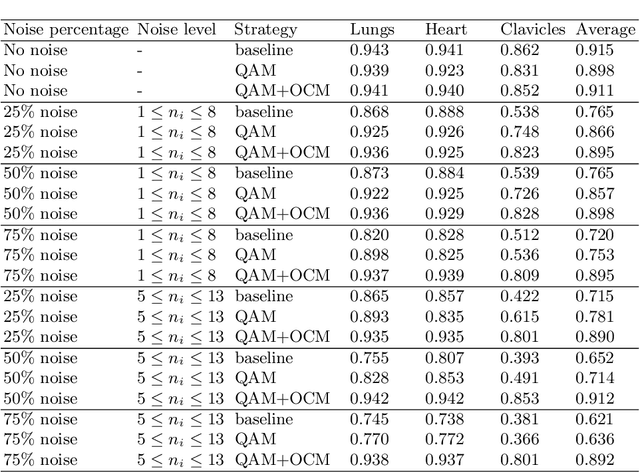
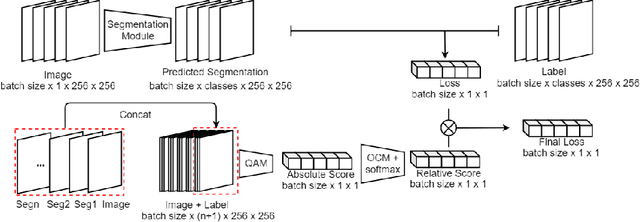
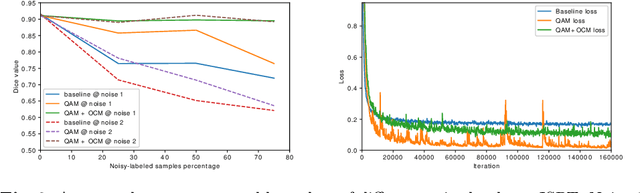
Deep learning methods have achieved promising performance in many areas, but they are still struggling with noisy-labeled images during the training process. Considering that the annotation quality indispensably relies on great expertise, the problem is even more crucial in the medical image domain. How to eliminate the disturbance from noisy labels for segmentation tasks without further annotations is still a significant challenge. In this paper, we introduce our label quality evaluation strategy for deep neural networks automatically assessing the quality of each label, which is not explicitly provided, and training on clean-annotated ones. We propose a solution for network automatically evaluating the relative quality of the labels in the training set and using good ones to tune the network parameters. We also design an overfitting control module to let the network maximally learn from the precise annotations during the training process. Experiments on the public biomedical image segmentation dataset have proved the method outperforms baseline methods and retains both high accuracy and good generalization at different noise levels.
Learning Long-Term Style-Preserving Blind Video Temporal Consistency
Mar 12, 2021
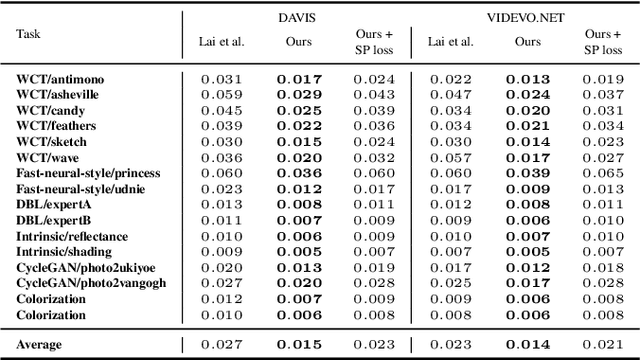

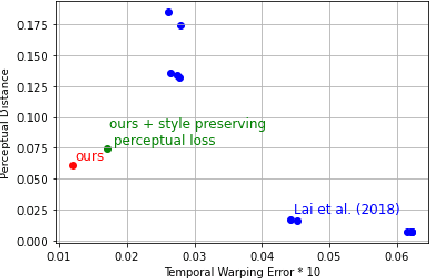
When trying to independently apply image-trained algorithms to successive frames in videos, noxious flickering tends to appear. State-of-the-art post-processing techniques that aim at fostering temporal consistency, generate other temporal artifacts and visually alter the style of videos. We propose a postprocessing model, agnostic to the transformation applied to videos (e.g. style transfer, image manipulation using GANs, etc.), in the form of a recurrent neural network. Our model is trained using a Ping Pong procedure and its corresponding loss, recently introduced for GAN video generation, as well as a novel style preserving perceptual loss. The former improves long-term temporal consistency learning, while the latter fosters style preservation. We evaluate our model on the DAVIS and videvo.net datasets and show that our approach offers state-of-the-art results concerning flicker removal, and better keeps the overall style of the videos than previous approaches.
TeLCoS: OnDevice Text Localization with Clustering of Script
Apr 21, 2021
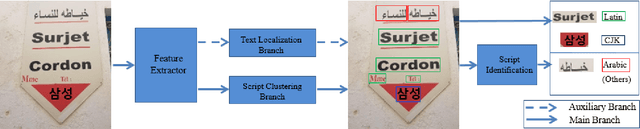

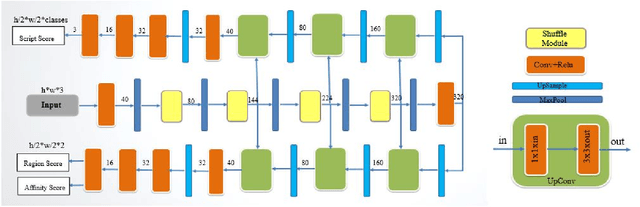
Recent research in the field of text localization in a resource constrained environment has made extensive use of deep neural networks. Scene text localization and recognition on low-memory mobile devices have a wide range of applications including content extraction, image categorization and keyword based image search. For text recognition of multi-lingual localized text, the OCR systems require prior knowledge of the script of each text instance. This leads to word script identification being an essential step for text recognition. Most existing methods treat text localization, script identification and text recognition as three separate tasks. This makes script identification an overhead in the recognition pipeline. To reduce this overhead, we propose TeLCoS: OnDevice Text Localization with Clustering of Script, a multi-task dual branch lightweight CNN network that performs real-time on device Text Localization and High-level Script Clustering simultaneously. The network drastically reduces the number of calls to a separate script identification module, by grouping and identifying some majorly used scripts through a single feed-forward pass over the localization network. We also introduce a novel structural similarity based channel pruning mechanism to build an efficient network with only 1.15M parameters. Experiments on benchmark datasets suggest that our method achieves state-of-the-art performance, with execution latency of 60 ms for the entire pipeline on the Exynos 990 chipset device.
Opportunistic Screening of Osteoporosis Using Plain Film Chest X-ray
Apr 05, 2021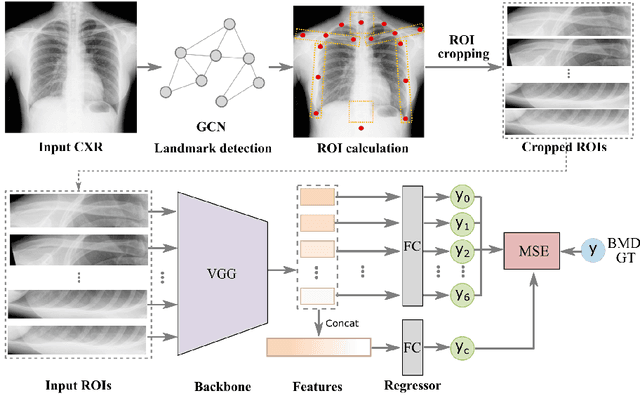
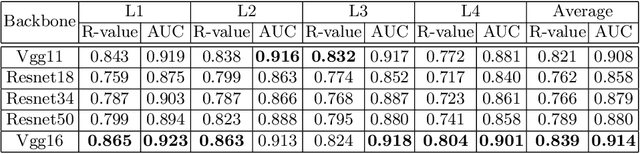
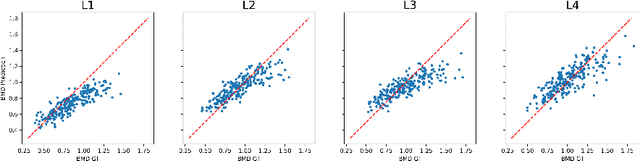
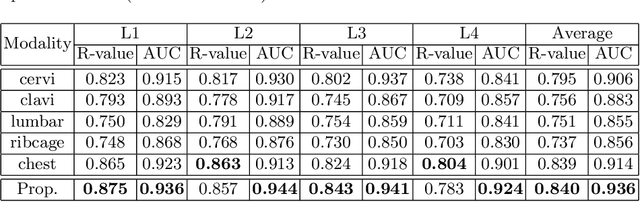
Osteoporosis is a common chronic metabolic bone disease that is often under-diagnosed and under-treated due to the limited access to bone mineral density (BMD) examinations, Dual-energy X-ray Absorptiometry (DXA). In this paper, we propose a method to predict BMD from Chest X-ray (CXR), one of the most common, accessible, and low-cost medical image examinations. Our method first automatically detects Regions of Interest (ROIs) of local and global bone structures from the CXR. Then a multi-ROI model is developed to exploit both local and global information in the chest X-ray image for accurate BMD estimation. Our method is evaluated on 329 CXR cases with ground truth BMD measured by DXA. The model predicted BMD has a strong correlation with the gold standard DXA BMD (Pearson correlation coefficient 0.840). When applied for osteoporosis screening, it achieves a high classification performance (AUC 0.936). As the first effort in the field to use CXR scans to predict the spine BMD, the proposed algorithm holds strong potential in enabling early osteoporosis screening through routine chest X-rays and contributing to the enhancement of public health.
Dynamic imaging using a deep generative SToRM (Gen-SToRM) model
Feb 11, 2021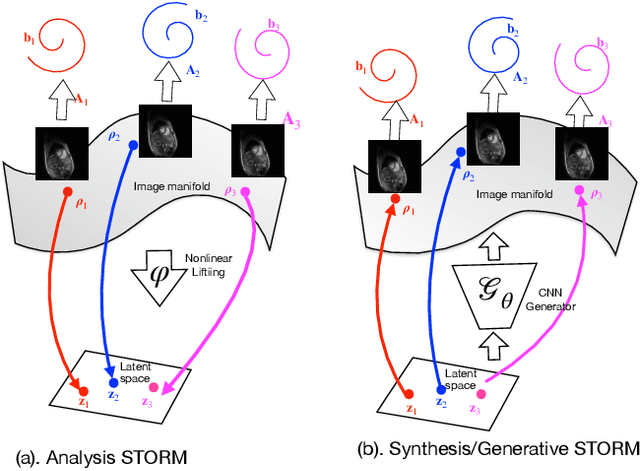
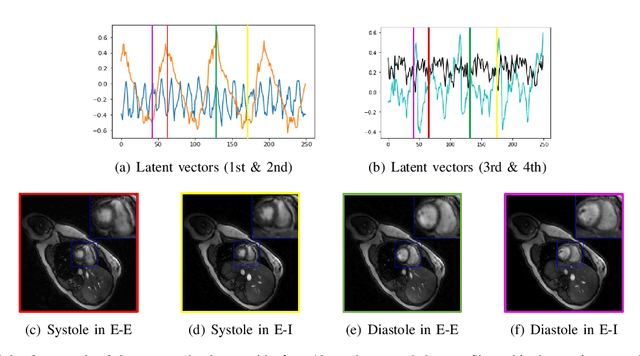
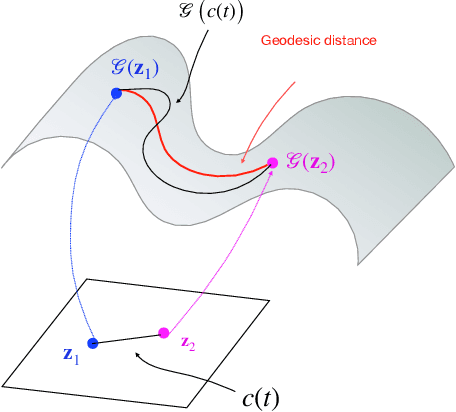
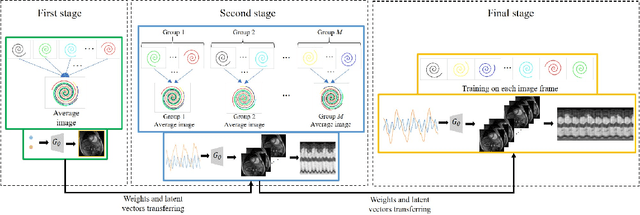
We introduce a generative smoothness regularization on manifolds (SToRM) model for the recovery of dynamic image data from highly undersampled measurements. The model assumes that the images in the dataset are non-linear mappings of low-dimensional latent vectors. We use the deep convolutional neural network (CNN) to represent the non-linear transformation. The parameters of the generator as well as the low-dimensional latent vectors are jointly estimated only from the undersampled measurements. This approach is different from traditional CNN approaches that require extensive fully sampled training data. We penalize the norm of the gradients of the non-linear mapping to constrain the manifold to be smooth, while temporal gradients of the latent vectors are penalized to obtain a smoothly varying time-series. The proposed scheme brings in the spatial regularization provided by the convolutional network. The main benefit of the proposed scheme is the improvement in image quality and the orders-of-magnitude reduction in memory demand compared to traditional manifold models. To minimize the computational complexity of the algorithm, we introduce an efficient progressive training-in-time approach and an approximate cost function. These approaches speed up the image reconstructions and offers better reconstruction performance.
Learning Stable Classifiers by Transferring Unstable Features
Jun 15, 2021

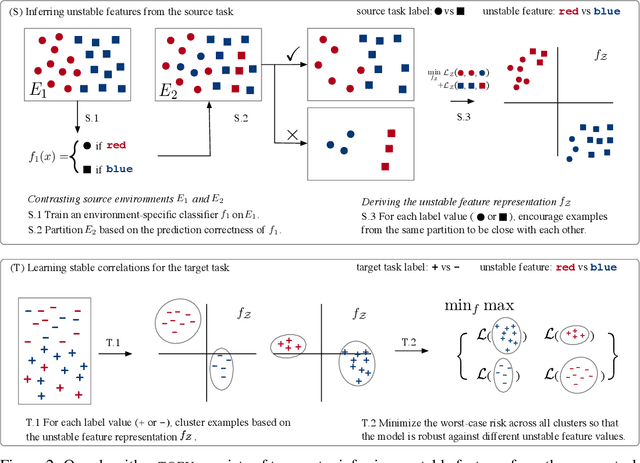
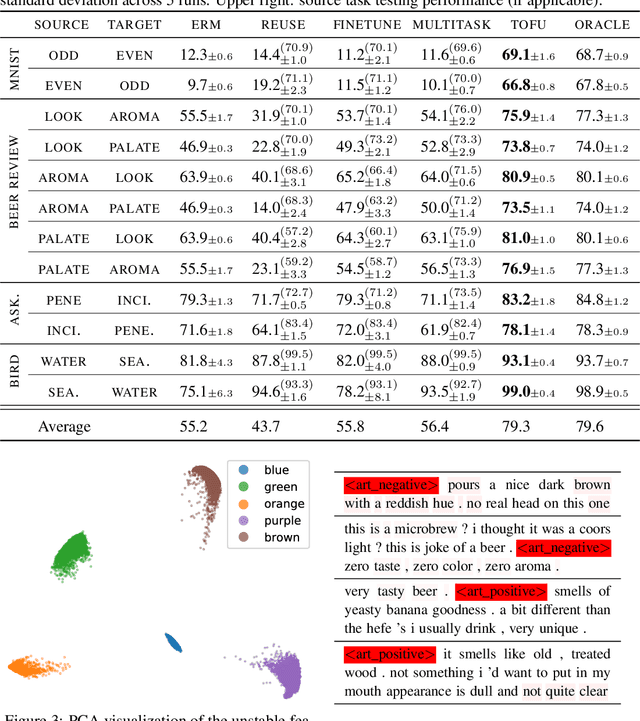
We study transfer learning in the presence of spurious correlations. We experimentally demonstrate that directly transferring the stable feature extractor learned on the source task may not eliminate these biases for the target task. However, we hypothesize that the unstable features in the source task and those in the target task are directly related. By explicitly informing the target classifier of the source task's unstable features, we can regularize the biases in the target task. Specifically, we derive a representation that encodes the unstable features by contrasting different data environments in the source task. On the target task, we cluster data from this representation, and achieve robustness by minimizing the worst-case risk across all clusters. We evaluate our method on both text and image classifications. Empirical results demonstrate that our algorithm is able to maintain robustness on the target task, outperforming the best baseline by 22.9% in absolute accuracy across 12 transfer settings. Our code is available at https://github.com/YujiaBao/Tofu.
Learning Depth via Leveraging Semantics: Self-supervised Monocular Depth Estimation with Both Implicit and Explicit Semantic Guidance
Feb 11, 2021
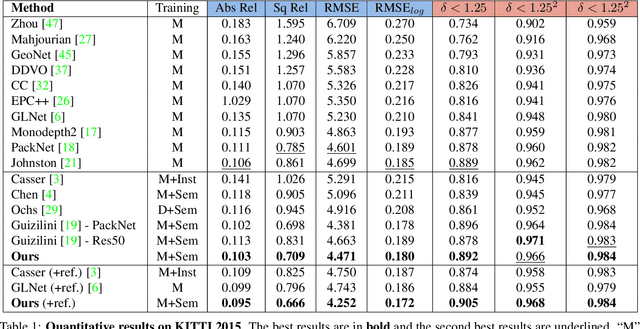
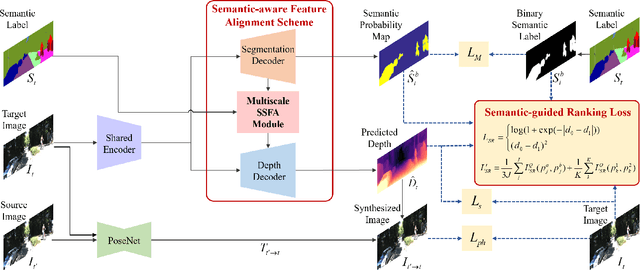

Self-supervised depth estimation has made a great success in learning depth from unlabeled image sequences. While the mappings between image and pixel-wise depth are well-studied in current methods, the correlation between image, depth and scene semantics, however, is less considered. This hinders the network to better understand the real geometry of the scene, since the contextual clues, contribute not only the latent representations of scene depth, but also the straight constraints for depth map. In this paper, we leverage the two benefits by proposing the implicit and explicit semantic guidance for accurate self-supervised depth estimation. We propose a Semantic-aware Spatial Feature Alignment (SSFA) scheme to effectively align implicit semantic features with depth features for scene-aware depth estimation. We also propose a semantic-guided ranking loss to explicitly constrain the estimated depth maps to be consistent with real scene contextual properties. Both semantic label noise and prediction uncertainty is considered to yield reliable depth supervisions. Extensive experimental results show that our method produces high quality depth maps which are consistently superior either on complex scenes or diverse semantic categories, and outperforms the state-of-the-art methods by a significant margin.
Task-driven Self-supervised Bi-channel Networks Learning for Diagnosis of Breast Cancers with Mammography
Jan 15, 2021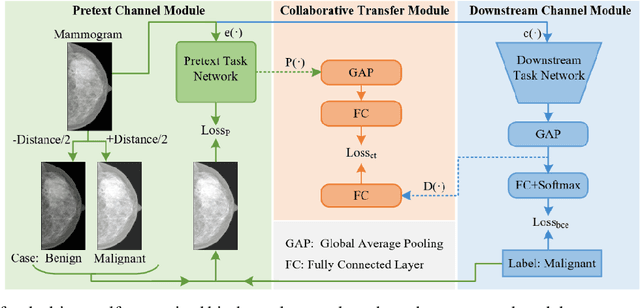

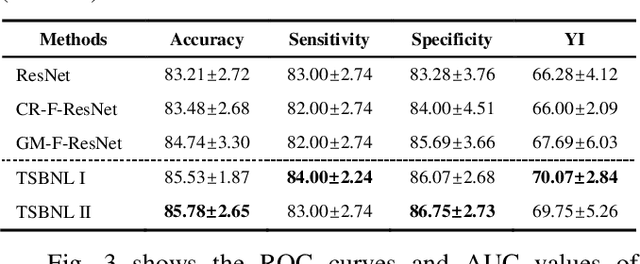
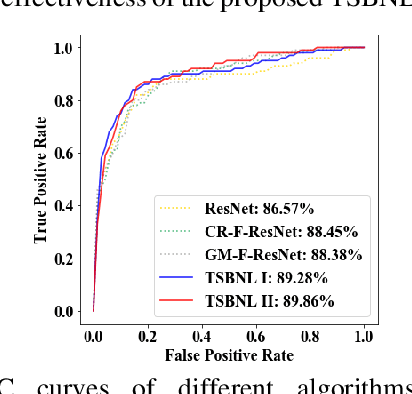
Deep learning can promote the mammography-based computer-aided diagnosis (CAD) for breast cancers, but it generally suffers from the small size sample problem. In this work, a task-driven self-supervised bi-channel networks (TSBNL) framework is proposed to improve the performance of classification network with limited mammograms. In particular, a new gray-scale image mapping (GSIM) task for image restoration is designed as the pretext task to improve discriminate feature representation with label information of mammograms. The TSBNL then innovatively integrates this image restoration network and the downstream classification network into a unified SSL framework, and transfers the knowledge from the pretext network to the classification network with improved diagnostic accuracy. The proposed algorithm is evaluated on a public INbreast mammogram dataset. The experimental results indicate that it outperforms the conventional SSL algorithms for diagnosis of breast cancers with limited samples.
Deep Embedding Convolutional Neural Network for Synthesizing CT Image from T1-Weighted MR Image
Nov 09, 2017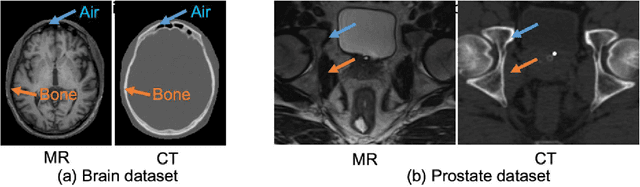

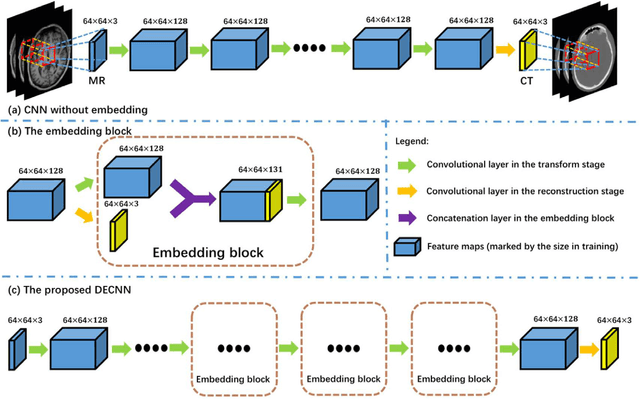

Recently, more and more attention is drawn to the field of medical image synthesis across modalities. Among them, the synthesis of computed tomography (CT) image from T1-weighted magnetic resonance (MR) image is of great importance, although the mapping between them is highly complex due to large gaps of appearances of the two modalities. In this work, we aim to tackle this MR-to-CT synthesis by a novel deep embedding convolutional neural network (DECNN). Specifically, we generate the feature maps from MR images, and then transform these feature maps forward through convolutional layers in the network. We can further compute a tentative CT synthesis from the midway of the flow of feature maps, and then embed this tentative CT synthesis back to the feature maps. This embedding operation results in better feature maps, which are further transformed forward in DECNN. After repeat-ing this embedding procedure for several times in the network, we can eventually synthesize a final CT image in the end of the DECNN. We have validated our proposed method on both brain and prostate datasets, by also compar-ing with the state-of-the-art methods. Experimental results suggest that our DECNN (with repeated embedding op-erations) demonstrates its superior performances, in terms of both the perceptive quality of the synthesized CT image and the run-time cost for synthesizing a CT image.