 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Shifts: A Dataset of Real Distributional Shift Across Multiple Large-Scale Tasks
Jul 23, 2021
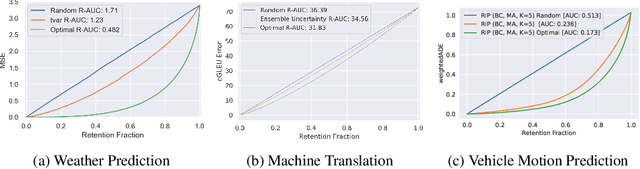
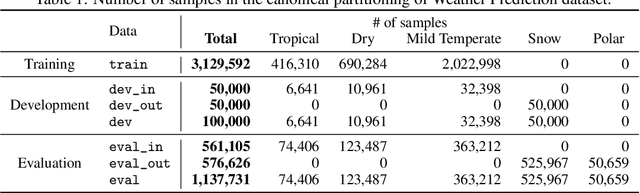
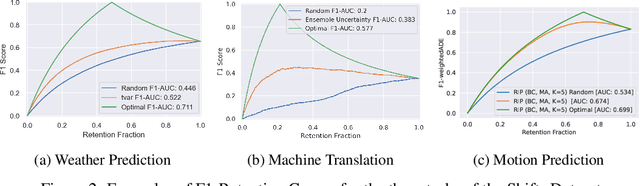
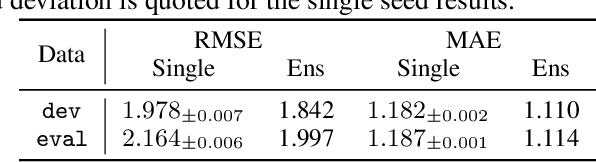
There has been significant research done on developing methods for improving robustness to distributional shift and uncertainty estimation. In contrast, only limited work has examined developing standard datasets and benchmarks for assessing these approaches. Additionally, most work on uncertainty estimation and robustness has developed new techniques based on small-scale regression or image classification tasks. However, many tasks of practical interest have different modalities, such as tabular data, audio, text, or sensor data, which offer significant challenges involving regression and discrete or continuous structured prediction. Thus, given the current state of the field, a standardized large-scale dataset of tasks across a range of modalities affected by distributional shifts is necessary. This will enable researchers to meaningfully evaluate the plethora of recently developed uncertainty quantification methods, as well as assessment criteria and state-of-the-art baselines. In this work, we propose the \emph{Shifts Dataset} for evaluation of uncertainty estimates and robustness to distributional shift. The dataset, which has been collected from industrial sources and services, is composed of three tasks, with each corresponding to a particular data modality: tabular weather prediction, machine translation, and self-driving car (SDC) vehicle motion prediction. All of these data modalities and tasks are affected by real, `in-the-wild' distributional shifts and pose interesting challenges with respect to uncertainty estimation. In this work we provide a description of the dataset and baseline results for all tasks.
Advancing biological super-resolution microscopy through deep learning: a brief review
Jun 24, 2021
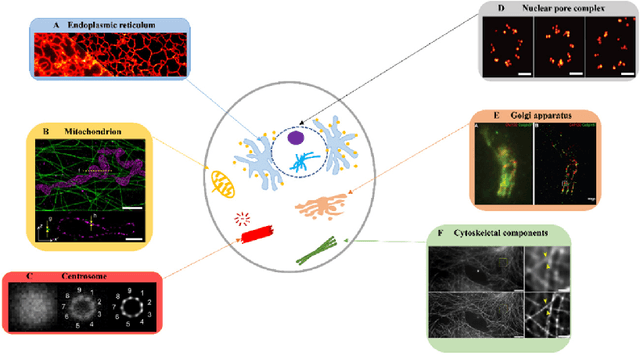
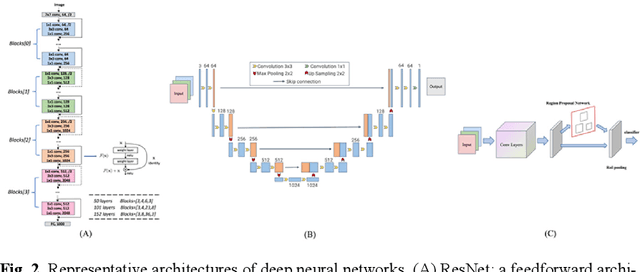
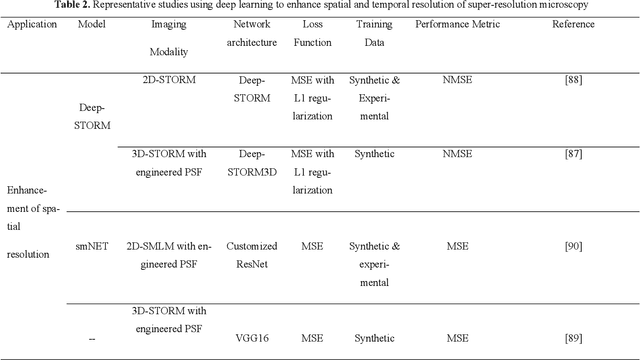
Super-resolution microscopy overcomes the diffraction limit of conventional light microscopy in spatial resolution. By providing novel spatial or spatio-temporal information on biological processes at nanometer resolution with molecular specificity, it plays an increasingly important role in life sciences. However, its technical limitations require trade-offs to balance its spatial resolution, temporal resolution, and light exposure of samples. Recently, deep learning has achieved breakthrough performance in many image processing and computer vision tasks. It has also shown great promise in pushing the performance envelope of super-resolution microscopy. In this brief Review, we survey recent advances in using deep learning to enhance performance of super-resolution microscopy. We focus primarily on how deep learning ad-vances reconstruction of super-resolution images. Related key technical challenges are discussed. Despite the challenges, deep learning is set to play an indispensable and transformative role in the development of super-resolution microscopy. We conclude with an outlook on how deep learning could shape the future of this new generation of light microscopy technology.
Practical Fast Gradient Sign Attack against Mammographic Image Classifier
Jan 27, 2020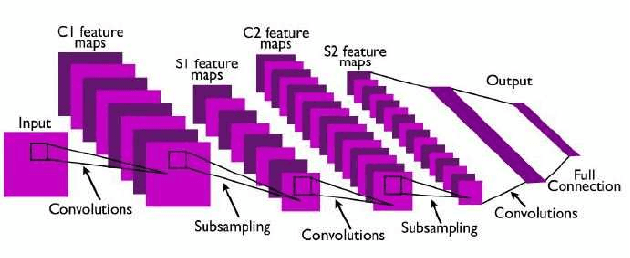
Artificial intelligence (AI) has been a topic of major research for many years. Especially, with the emergence of deep neural network (DNN), these studies have been tremendously successful. Today machines are capable of making faster, more accurate decision than human. Thanks to the great development of machine learning (ML) techniques, ML have been used many different fields such as education, medicine, malware detection, autonomous car etc. In spite of having this degree of interest and much successful research, ML models are still vulnerable to adversarial attacks. Attackers can manipulate clean data in order to fool the ML classifiers to achieve their desire target. For instance; a benign sample can be modified as a malicious sample or a malicious one can be altered as benign while this modification can not be recognized by human observer. This can lead to many financial losses, or serious injuries, even deaths. The motivation behind this paper is that we emphasize this issue and want to raise awareness. Therefore, the security gap of mammographic image classifier against adversarial attack is demonstrated. We use mamographic images to train our model then evaluate our model performance in terms of accuracy. Later on, we poison original dataset and generate adversarial samples that missclassified by the model. We then using structural similarity index (SSIM) analyze similarity between clean images and adversarial images. Finally, we show how successful we are to misuse by using different poisoning factors.
DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort
Apr 13, 2021
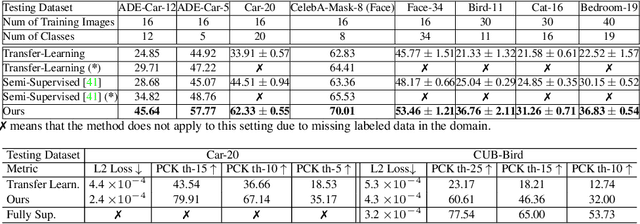
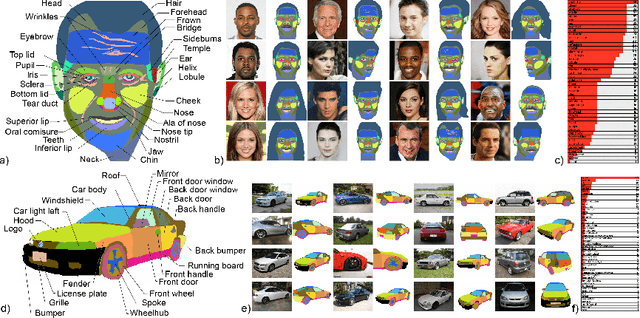
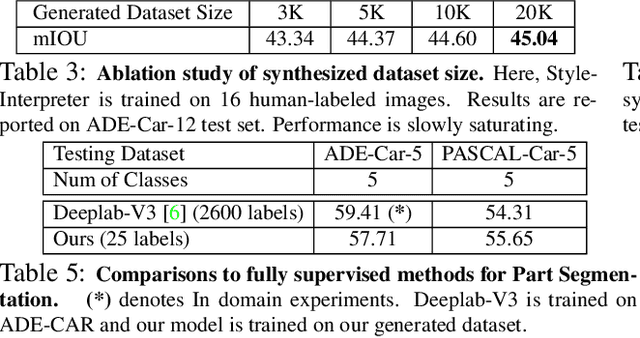
We introduce DatasetGAN: an automatic procedure to generate massive datasets of high-quality semantically segmented images requiring minimal human effort. Current deep networks are extremely data-hungry, benefiting from training on large-scale datasets, which are time consuming to annotate. Our method relies on the power of recent GANs to generate realistic images. We show how the GAN latent code can be decoded to produce a semantic segmentation of the image. Training the decoder only needs a few labeled examples to generalize to the rest of the latent space, resulting in an infinite annotated dataset generator! These generated datasets can then be used for training any computer vision architecture just as real datasets are. As only a few images need to be manually segmented, it becomes possible to annotate images in extreme detail and generate datasets with rich object and part segmentations. To showcase the power of our approach, we generated datasets for 7 image segmentation tasks which include pixel-level labels for 34 human face parts, and 32 car parts. Our approach outperforms all semi-supervised baselines significantly and is on par with fully supervised methods, which in some cases require as much as 100x more annotated data as our method.
On Complex Conjugate Pair Sums and Complex Conjugate Subspaces
Jun 05, 2021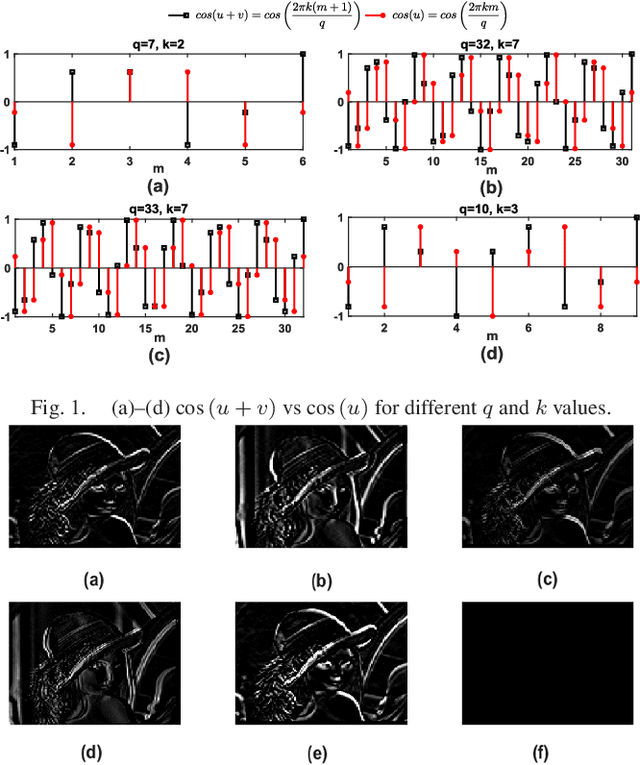

In this letter, we study a few properties of Complex Conjugate Pair Sums (CCPSs) and Complex Conjugate Subspaces (CCSs). Initially, we consider an LTI system whose impulse response is one period data of CCPS. For a given input x(n), we prove that the output of this system is equivalent to computing the first order derivative of x(n). Further, with some constraints on the impulse response, the system output is also equivalent to the second order derivative. With this, we show that a fine edge detection in an image can be achieved using CCPSs as impulse response over Ramanujan Sums (RSs). Later computation of projection for CCS is studied. Here the projection matrix has a circulant structure, which makes the computation of projections easier. Finally, we prove that CCS is shift-invariant and closed under the operation of circular cross-correlation.
* 4 pages, 2 figures
Discriminative Region Suppression for Weakly-Supervised Semantic Segmentation
Apr 05, 2021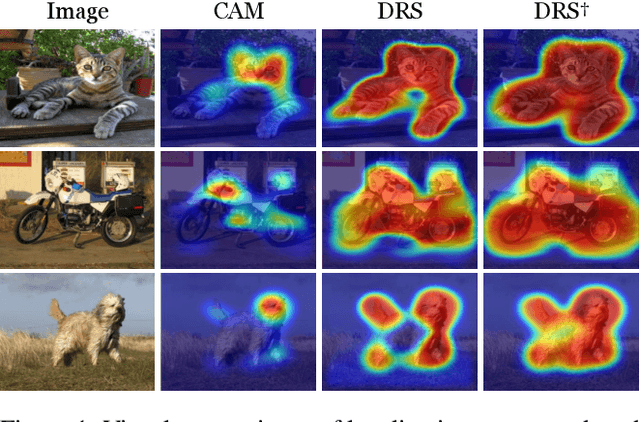
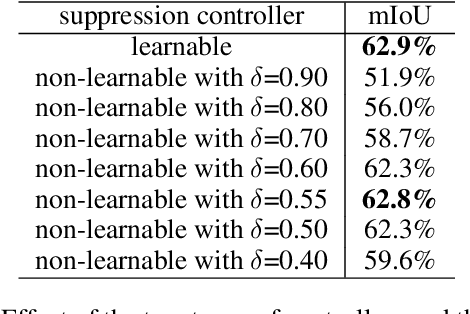
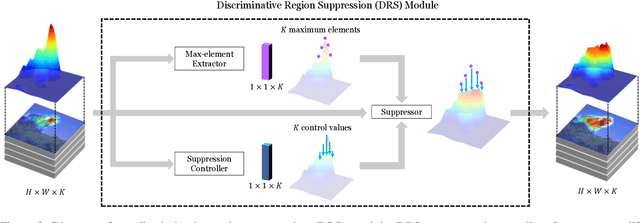

Weakly-supervised semantic segmentation (WSSS) using image-level labels has recently attracted much attention for reducing annotation costs. Existing WSSS methods utilize localization maps from the classification network to generate pseudo segmentation labels. However, since localization maps obtained from the classifier focus only on sparse discriminative object regions, it is difficult to generate high-quality segmentation labels. To address this issue, we introduce discriminative region suppression (DRS) module that is a simple yet effective method to expand object activation regions. DRS suppresses the attention on discriminative regions and spreads it to adjacent non-discriminative regions, generating dense localization maps. DRS requires few or no additional parameters and can be plugged into any network. Furthermore, we introduce an additional learning strategy to give a self-enhancement of localization maps, named localization map refinement learning. Benefiting from this refinement learning, localization maps are refined and enhanced by recovering some missing parts or removing noise itself. Due to its simplicity and effectiveness, our approach achieves mIoU 71.4% on the PASCAL VOC 2012 segmentation benchmark using only image-level labels. Extensive experiments demonstrate the effectiveness of our approach. The code is available at https://github.com/qjadud1994/DRS.
Similarity-Aware Fusion Network for 3D Semantic Segmentation
Jul 17, 2021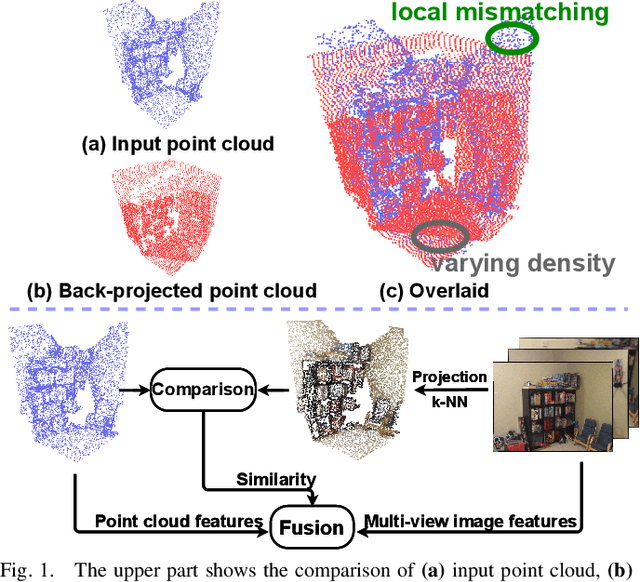
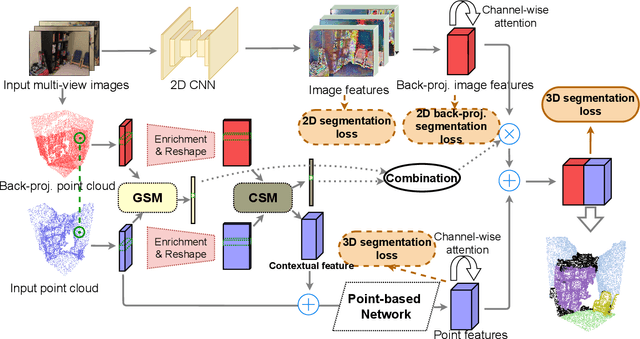
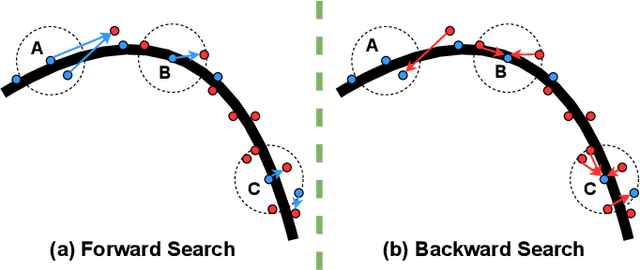
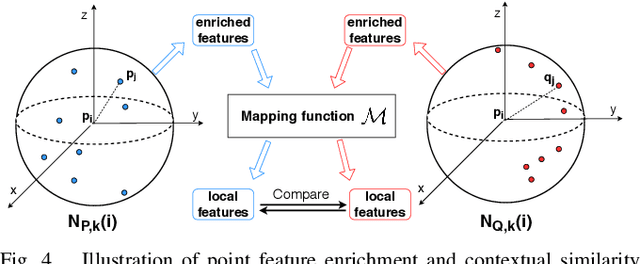
In this paper, we propose a similarity-aware fusion network (SAFNet) to adaptively fuse 2D images and 3D point clouds for 3D semantic segmentation. Existing fusion-based methods achieve remarkable performances by integrating information from multiple modalities. However, they heavily rely on the correspondence between 2D pixels and 3D points by projection and can only perform the information fusion in a fixed manner, and thus their performances cannot be easily migrated to a more realistic scenario where the collected data often lack strict pair-wise features for prediction. To address this, we employ a late fusion strategy where we first learn the geometric and contextual similarities between the input and back-projected (from 2D pixels) point clouds and utilize them to guide the fusion of two modalities to further exploit complementary information. Specifically, we employ a geometric similarity module (GSM) to directly compare the spatial coordinate distributions of pair-wise 3D neighborhoods, and a contextual similarity module (CSM) to aggregate and compare spatial contextual information of corresponding central points. The two proposed modules can effectively measure how much image features can help predictions, enabling the network to adaptively adjust the contributions of two modalities to the final prediction of each point. Experimental results on the ScanNetV2 benchmark demonstrate that SAFNet significantly outperforms existing state-of-the-art fusion-based approaches across various data integrity.
Video Rescaling Networks with Joint Optimization Strategies for Downscaling and Upscaling
Mar 27, 2021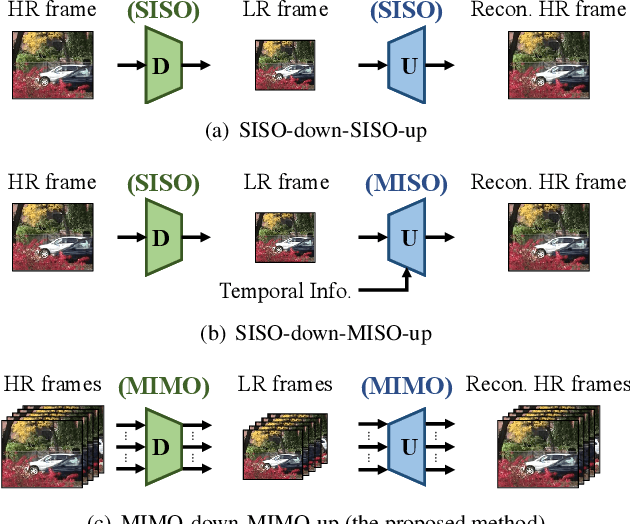
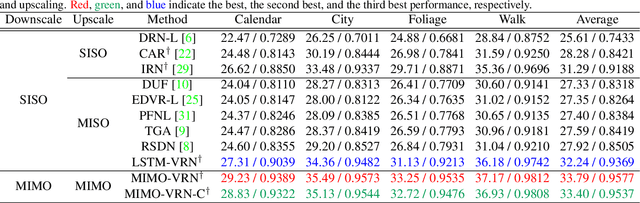
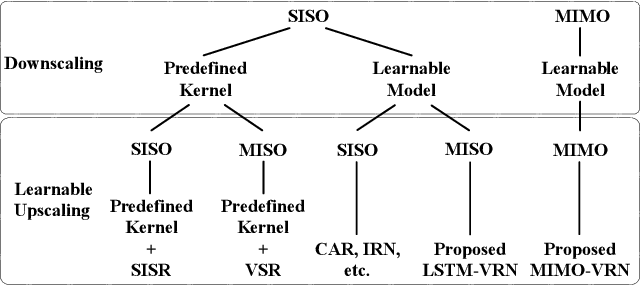
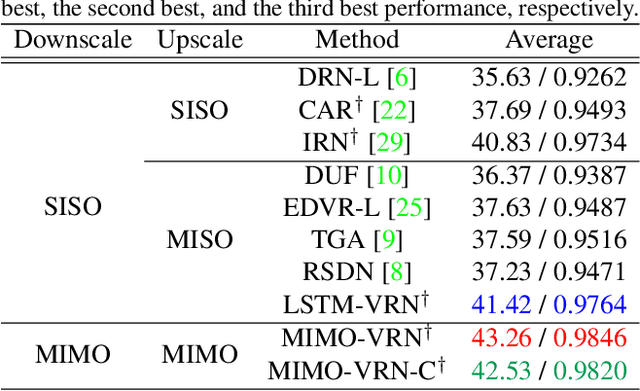
This paper addresses the video rescaling task, which arises from the needs of adapting the video spatial resolution to suit individual viewing devices. We aim to jointly optimize video downscaling and upscaling as a combined task. Most recent studies focus on image-based solutions, which do not consider temporal information. We present two joint optimization approaches based on invertible neural networks with coupling layers. Our Long Short-Term Memory Video Rescaling Network (LSTM-VRN) leverages temporal information in the low-resolution video to form an explicit prediction of the missing high-frequency information for upscaling. Our Multi-input Multi-output Video Rescaling Network (MIMO-VRN) proposes a new strategy for downscaling and upscaling a group of video frames simultaneously. Not only do they outperform the image-based invertible model in terms of quantitative and qualitative results, but also show much improved upscaling quality than the video rescaling methods without joint optimization. To our best knowledge, this work is the first attempt at the joint optimization of video downscaling and upscaling.
MLFcGAN: Multi-level Feature Fusion based Conditional GAN for Underwater Image Color Correction
Feb 13, 2020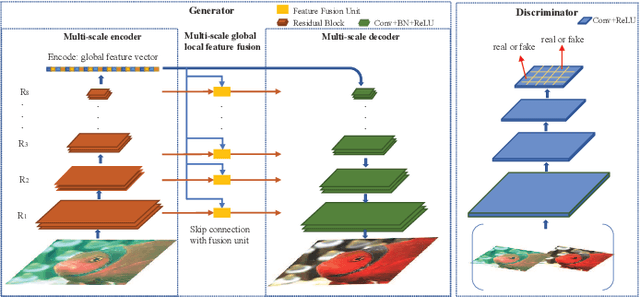



Color correction for underwater images has received increasing interests, due to its critical role in facilitating available mature vision algorithms for underwater scenarios. Inspired by the stunning success of deep convolutional neural networks (DCNNs) techniques in many vision tasks, especially the strength in extracting features in multiple scales, we propose a deep multi-scale feature fusion net based on the conditional generative adversarial network (GAN) for underwater image color correction. In our network, multi-scale features are extracted first, followed by augmenting local features on each scale with global features. This design was verified to facilitate more effective and faster network learning, resulting in better performance in both color correction and detail preservation. We conducted extensive experiments and compared with the state-of-the-art approaches quantitatively and qualitatively, showing that our method achieves significant improvements.
On the Duality Between Retinex and Image Dehazing
Apr 06, 2018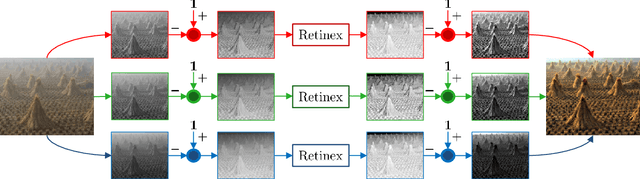
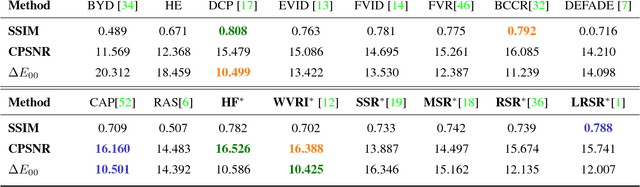

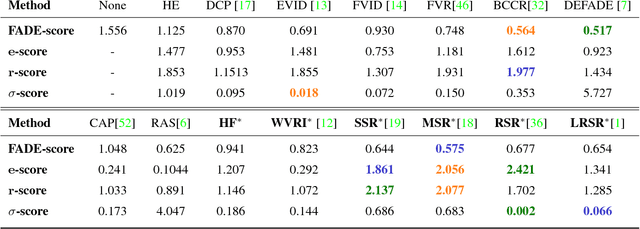
Image dehazing deals with the removal of undesired loss of visibility in outdoor images due to the presence of fog. Retinex is a color vision model mimicking the ability of the Human Visual System to robustly discount varying illuminations when observing a scene under different spectral lighting conditions. Retinex has been widely explored in the computer vision literature for image enhancement and other related tasks. While these two problems are apparently unrelated, the goal of this work is to show that they can be connected by a simple linear relationship. Specifically, most Retinex-based algorithms have the characteristic feature of always increasing image brightness, which turns them into ideal candidates for effective image dehazing by directly applying Retinex to a hazy image whose intensities have been inverted. In this paper, we give theoretical proof that Retinex on inverted intensities is a solution to the image dehazing problem. Comprehensive qualitative and quantitative results indicate that several classical and modern implementations of Retinex can be transformed into competing image dehazing algorithms performing on pair with more complex fog removal methods, and can overcome some of the main challenges associated with this problem.