 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Large Margin Multi-modal Multi-task Feature Extraction for Image Classification
Apr 08, 2019
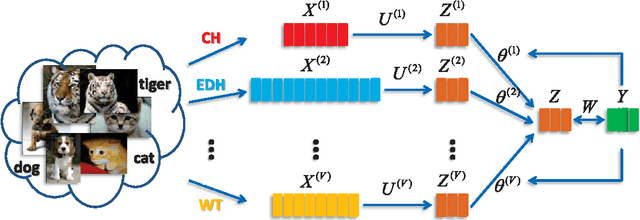
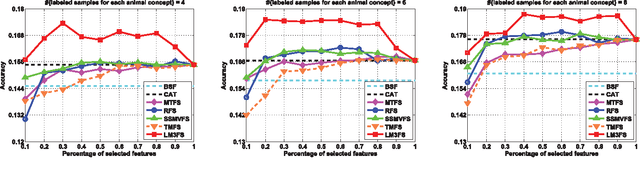
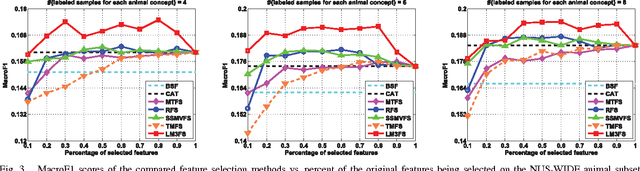
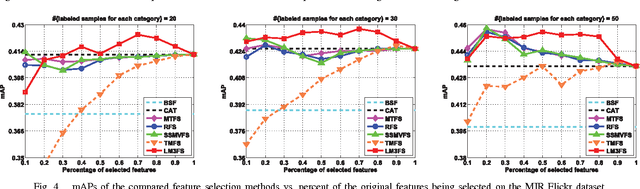
The features used in many image analysis-based applications are frequently of very high dimension. Feature extraction offers several advantages in high-dimensional cases, and many recent studies have used multi-task feature extraction approaches, which often outperform single-task feature extraction approaches. However, most of these methods are limited in that they only consider data represented by a single type of feature, even though features usually represent images from multiple modalities. We therefore propose a novel large margin multi-modal multi-task feature extraction (LM3FE) framework for handling multi-modal features for image classification. In particular, LM3FE simultaneously learns the feature extraction matrix for each modality and the modality combination coefficients. In this way, LM3FE not only handles correlated and noisy features, but also utilizes the complementarity of different modalities to further help reduce feature redundancy in each modality. The large margin principle employed also helps to extract strongly predictive features so that they are more suitable for prediction (e.g., classification). An alternating algorithm is developed for problem optimization and each sub-problem can be efficiently solved. Experiments on two challenging real-world image datasets demonstrate the effectiveness and superiority of the proposed method.
Graph-based non-linear least squares optimization for visual place recognition in changing environments
Dec 29, 2020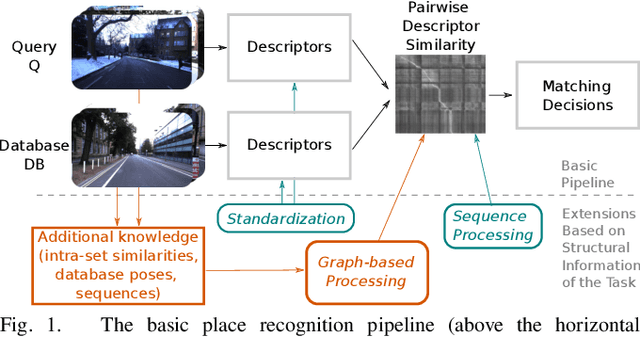
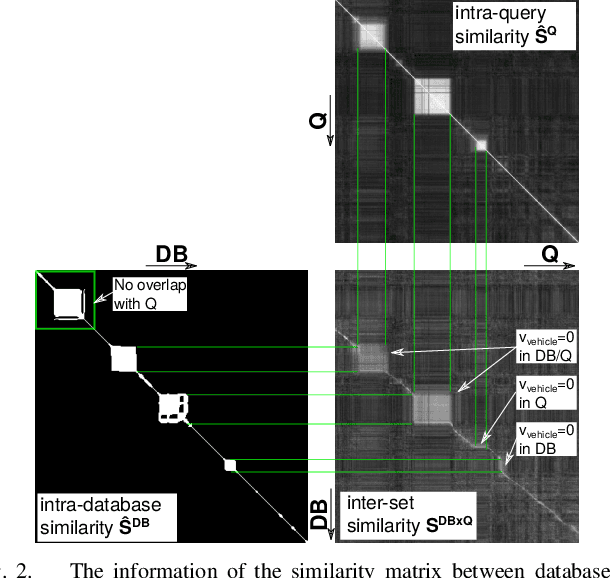
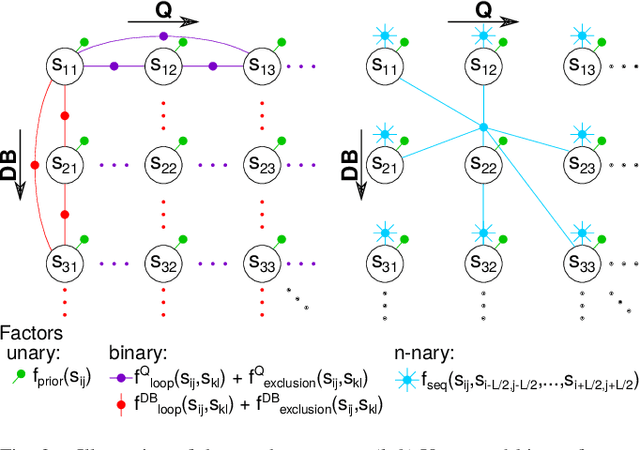
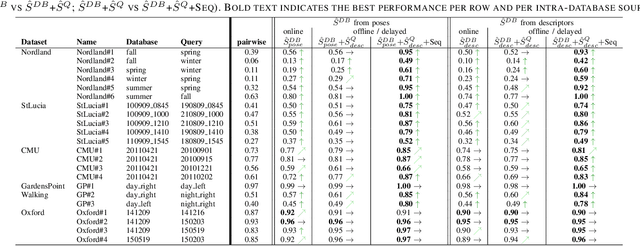
Visual place recognition is an important subproblem of mobile robot localization. Since it is a special case of image retrieval, the basic source of information is the pairwise similarity of image descriptors. However, the embedding of the image retrieval problem in this robotic task provides additional structure that can be exploited, e.g. spatio-temporal consistency. Several algorithms exist to exploit this structure, e.g., sequence processing approaches or descriptor standardization approaches for changing environments. In this paper, we propose a graph-based framework to systematically exploit different types of additional structure and information. The graphical model is used to formulate a non-linear least squares problem that can be optimized with standard tools. Beyond sequences and standardization, we propose the usage of intra-set similarities within the database and/or the query image set as additional source of information. If available, our approach also allows to seamlessly integrate additional knowledge about poses of database images. We evaluate the system on a variety of standard place recognition datasets and demonstrate performance improvements for a large number of different configurations including different sources of information, different types of constraints, and online or offline place recognition setups.
TransBTS: Multimodal Brain Tumor Segmentation Using Transformer
Mar 07, 2021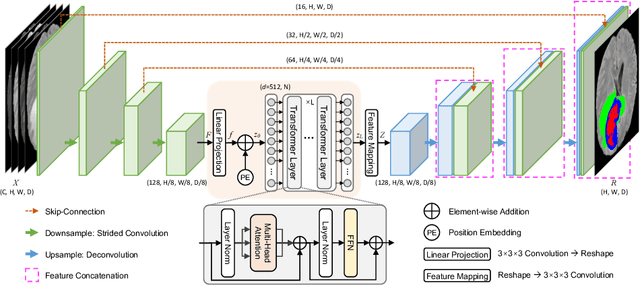
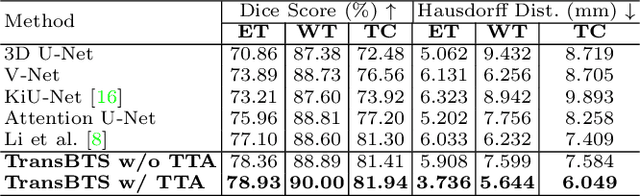
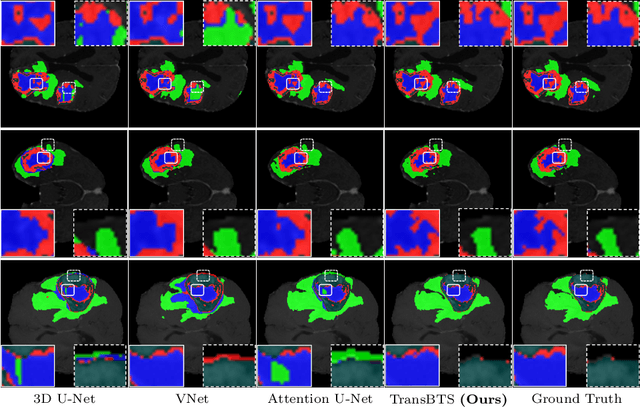
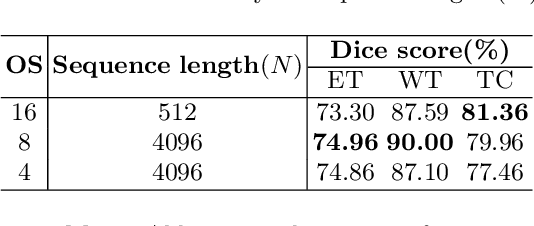
Transformer, which can benefit from global (long-range) information modeling using self-attention mechanisms, has been successful in natural language processing and 2D image classification recently. However, both local and global features are crucial for dense prediction tasks, especially for 3D medical image segmentation. In this paper, we for the first time exploit Transformer in 3D CNN for MRI Brain Tumor Segmentation and propose a novel network named TransBTS based on the encoder-decoder structure. To capture the local 3D context information, the encoder first utilizes 3D CNN to extract the volumetric spatial feature maps. Meanwhile, the feature maps are reformed elaborately for tokens that are fed into Transformer for global feature modeling. The decoder leverages the features embedded by Transformer and performs progressive upsampling to predict the detailed segmentation map. Experimental results on the BraTS 2019 dataset show that TransBTS outperforms state-of-the-art methods for brain tumor segmentation on 3D MRI scans. Code is available at https://github.com/Wenxuan-1119/TransBTS
Automatically eliminating seam lines with Poisson editing in complex relative radiometric normalization mosaicking scenarios
Jun 14, 2021Relative radiometric normalization (RRN) mosaicking among multiple remote sensing images is crucial for the downstream tasks, including map-making, image recognition, semantic segmentation, and change detection. However, there are often seam lines on the mosaic boundary and radiometric contrast left, especially in complex scenarios, making the appearance of mosaic images unsightly and reducing the accuracy of the latter classification/recognition algorithms. This paper renders a novel automatical approach to eliminate seam lines in complex RRN mosaicking scenarios. It utilizes the histogram matching on the overlap area to alleviate radiometric contrast, Poisson editing to remove the seam lines, and merging procedure to determine the normalization transfer order. Our method can handle the mosaicking seam lines with arbitrary shapes and images with extreme topological relationships (with a small intersection area). These conditions make the main feathering or blending methods, e.g., linear weighted blending and Laplacian pyramid blending, unavailable. In the experiment, our approach visually surpasses the automatic methods without Poisson editing and the manual blurring and feathering method using GIMP software.
CRASH: Raw Audio Score-based Generative Modeling for Controllable High-resolution Drum Sound Synthesis
Jun 14, 2021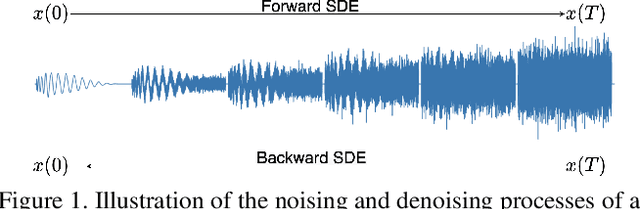
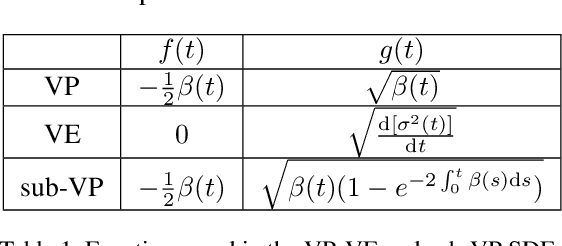
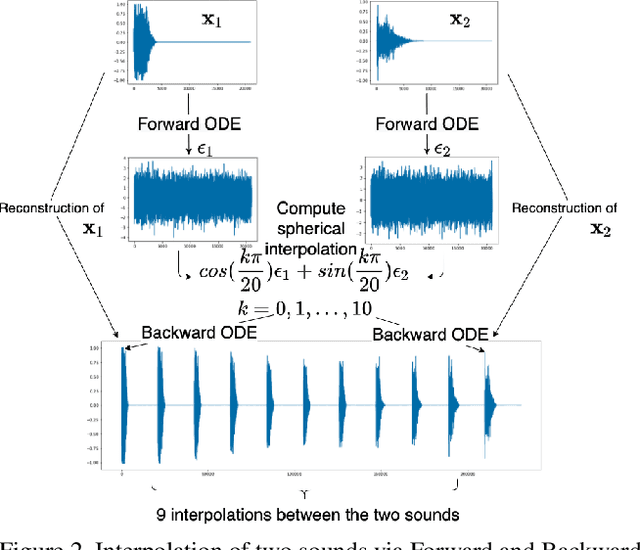

In this paper, we propose a novel score-base generative model for unconditional raw audio synthesis. Our proposal builds upon the latest developments on diffusion process modeling with stochastic differential equations, which already demonstrated promising results on image generation. We motivate novel heuristics for the choice of the diffusion processes better suited for audio generation, and consider the use of a conditional U-Net to approximate the score function. While previous approaches on diffusion models on audio were mainly designed as speech vocoders in medium resolution, our method termed CRASH (Controllable Raw Audio Synthesis with High-resolution) allows us to generate short percussive sounds in 44.1kHz in a controllable way. Through extensive experiments, we showcase on a drum sound generation task the numerous sampling schemes offered by our method (unconditional generation, deterministic generation, inpainting, interpolation, variations, class-conditional sampling) and propose the class-mixing sampling, a novel way to generate "hybrid" sounds. Our proposed method closes the gap with GAN-based methods on raw audio, while offering more flexible generation capabilities with lighter and easier-to-train models.
Deep learning with photosensor timing information as a background rejection method for the Cherenkov Telescope Array
Mar 10, 2021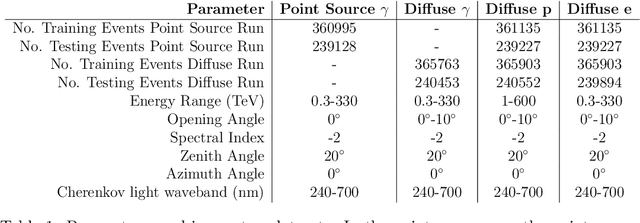
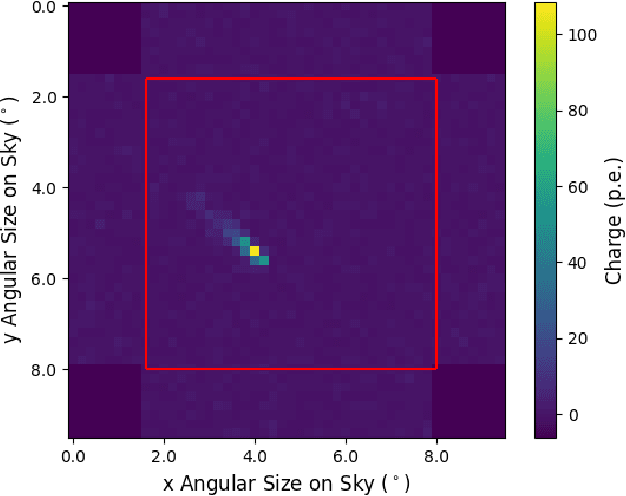
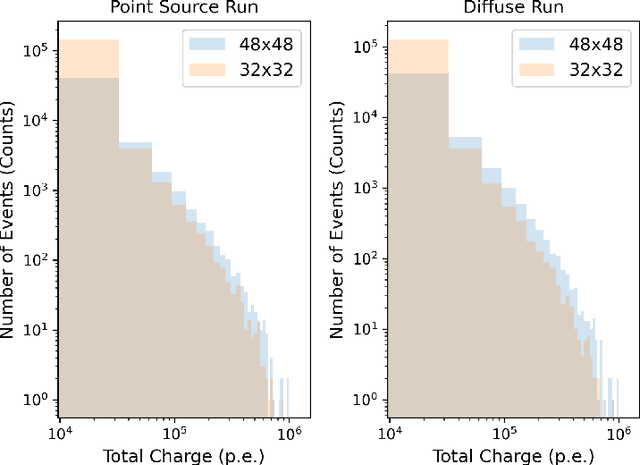

New deep learning techniques present promising new analysis methods for Imaging Atmospheric Cherenkov Telescopes (IACTs) such as the upcoming Cherenkov Telescope Array (CTA). In particular, the use of Convolutional Neural Networks (CNNs) could provide a direct event classification method that uses the entire information contained within the Cherenkov shower image, bypassing the need to Hillas parameterise the image and allowing fast processing of the data. Existing work in this field has utilised images of the integrated charge from IACT camera photomultipliers, however the majority of current and upcoming generation IACT cameras have the capacity to read out the entire photosensor waveform following a trigger. As the arrival times of Cherenkov photons from Extensive Air Showers (EAS) at the camera plane are dependent upon the altitude of their emission and the impact distance from the telescope, these waveforms contain information potentially useful for IACT event classification. In this test-of-concept simulation study, we investigate the potential for using these camera pixel waveforms with new deep learning techniques as a background rejection method, against both proton and electron induced EAS. We find that a means of utilising their information is to create a set of seven additional 2-dimensional pixel maps of waveform parameters, to be fed into the machine learning algorithm along with the integrated charge image. Whilst we ultimately find that the only classification power against electrons is based upon event direction, methods based upon timing information appear to out-perform similar charge based methods for gamma/hadron separation. We also review existing methods of event classifications using a combination of deep learning and timing information in other astroparticle physics experiments.
Soft Rasterizer: A Differentiable Renderer for Image-based 3D Reasoning
Apr 03, 2019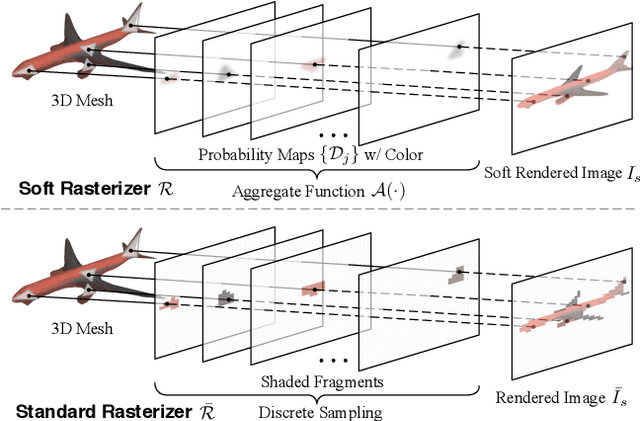



Rendering bridges the gap between 2D vision and 3D scenes by simulating the physical process of image formation. By inverting such renderer, one can think of a learning approach to infer 3D information from 2D images. However, standard graphics renderers involve a fundamental discretization step called rasterization, which prevents the rendering process to be differentiable, hence able to be learned. Unlike the state-of-the-art differentiable renderers, which only approximate the rendering gradient in the back propagation, we propose a truly differentiable rendering framework that is able to (1) directly render colorized mesh using differentiable functions and (2) back-propagate efficient supervision signals to mesh vertices and their attributes from various forms of image representations, including silhouette, shading and color images. The key to our framework is a novel formulation that views rendering as an aggregation function that fuses the probabilistic contributions of all mesh triangles with respect to the rendered pixels. Such formulation enables our framework to flow gradients to the occluded and far-range vertices, which cannot be achieved by the previous state-of-the-arts. We show that by using the proposed renderer, one can achieve significant improvement in 3D unsupervised single-view reconstruction both qualitatively and quantitatively. Experiments also demonstrate that our approach is able to handle the challenging tasks in image-based shape fitting, which remain nontrivial to existing differentiable renderers.
Ultra-low bitrate video conferencing using deep image animation
Dec 01, 2020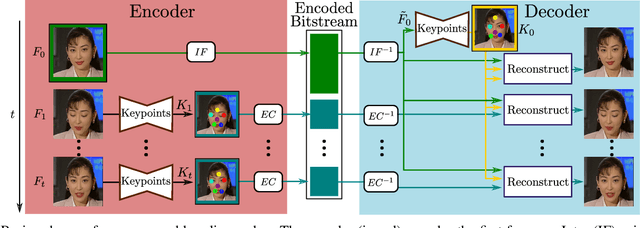
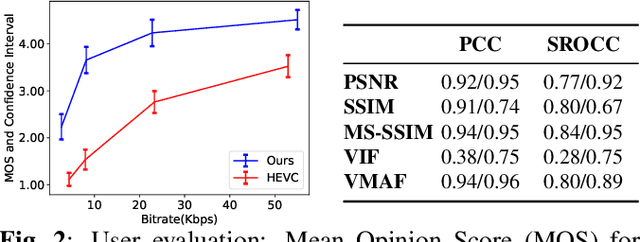
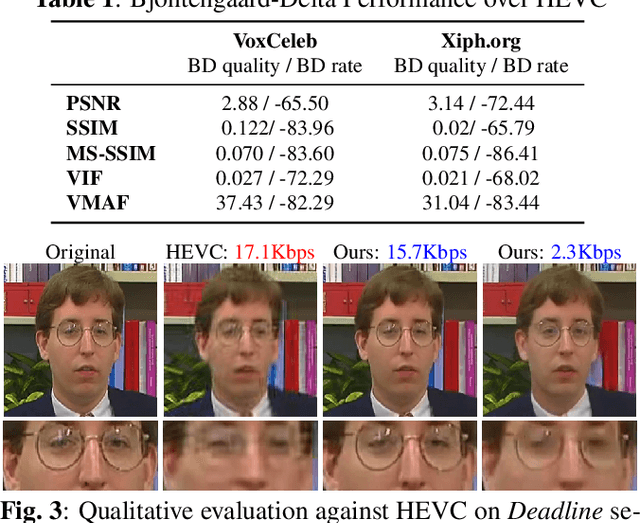
In this work we propose a novel deep learning approach for ultra-low bitrate video compression for video conferencing applications. To address the shortcomings of current video compression paradigms when the available bandwidth is extremely limited, we adopt a model-based approach that employs deep neural networks to encode motion information as keypoint displacement and reconstruct the video signal at the decoder side. The overall system is trained in an end-to-end fashion minimizing a reconstruction error on the encoder output. Objective and subjective quality evaluation experiments demonstrate that the proposed approach provides an average bitrate reduction for the same visual quality of more than 80% compared to HEVC.
Palmprint image registration using convolutional neural networks and Hough transform
Apr 03, 2019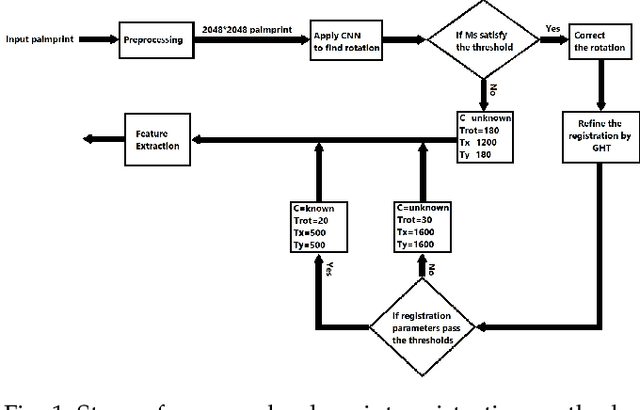

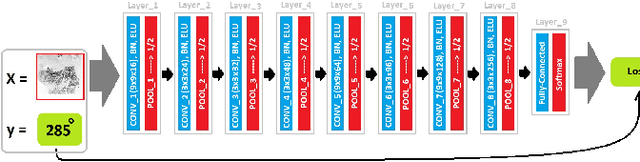
Minutia-based palmprint recognition systems has got lots of interest in last two decades. Due to the large number of minutiae in a palmprint, approximately 1000 minutiae, the matching process is time consuming which makes it unpractical for real time applications. One way to address this issue is aligning all palmprint images to a reference image and bringing them to a same coordinate system. Bringing all palmprint images to a same coordinate system, results in fewer computations during minutia matching. In this paper, using convolutional neural network (CNN) and generalized Hough transform (GHT), we propose a new method to register palmprint images accurately. This method, finds the corresponding rotation and displacement (in both x and y direction) between the palmprint and a reference image. Exact palmprint registration can enhance the speed and the accuracy of matching process. Proposed method is capable of distinguishing between left and right palmprint automatically which helps to speed up the matching process. Furthermore, designed structure of CNN in registration stage, gives us the segmented palmprint image from background which is a pre-processing step for minutia extraction. The proposed registration method followed by minutia-cylinder code (MCC) matching algorithm has been evaluated on the THUPALMLAB database, and the results show the superiority of our algorithm over most of the state-of-the-art algorithms.
Anomaly Detection of Test-Time Evasion Attacks using Class-conditional Generative Adversarial Networks
May 21, 2021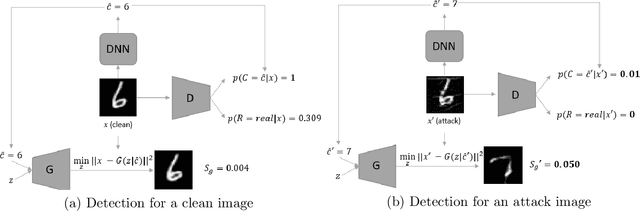
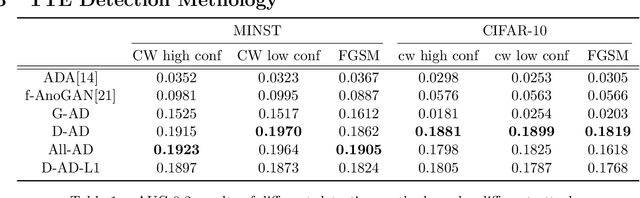
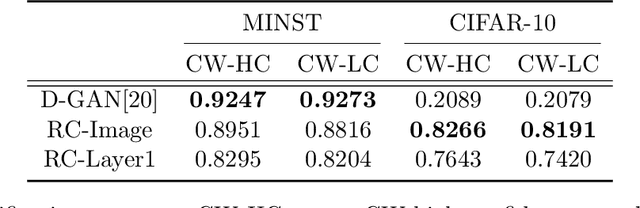
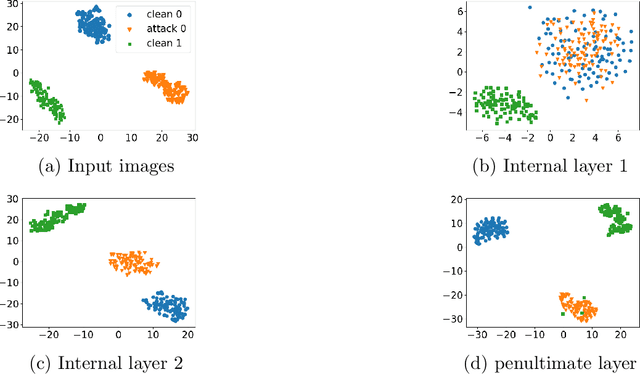
Deep Neural Networks (DNNs) have been shown vulnerable to adversarial (Test-Time Evasion (TTE)) attacks which, by making small changes to the input, alter the DNN's decision. We propose an attack detector based on class-conditional Generative Adversarial Networks (GANs). We model the distribution of clean data conditioned on the predicted class label by an Auxiliary Classifier GAN (ACGAN). Given a test sample and its predicted class, three detection statistics are calculated using the ACGAN Generator and Discriminator. Experiments on image classification datasets under different TTE attack methods show that our method outperforms state-of-the-art detection methods. We also investigate the effectiveness of anomaly detection using different DNN layers (input features or internal-layer features) and demonstrate that anomalies are harder to detect using features closer to the DNN's output layer.