 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pyramid U-Net for Retinal Vessel Segmentation
Apr 06, 2021
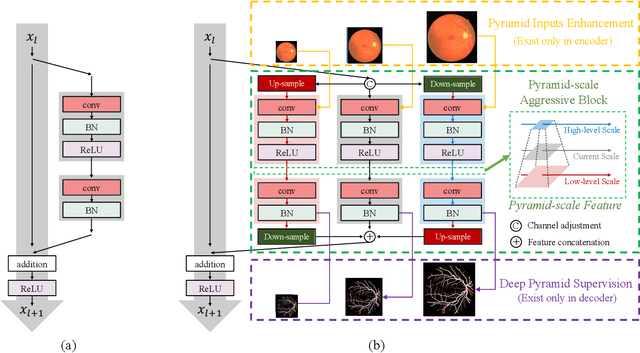
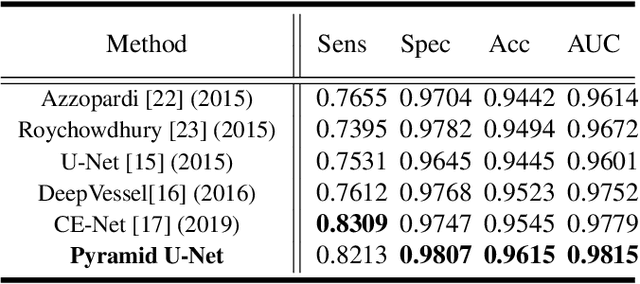
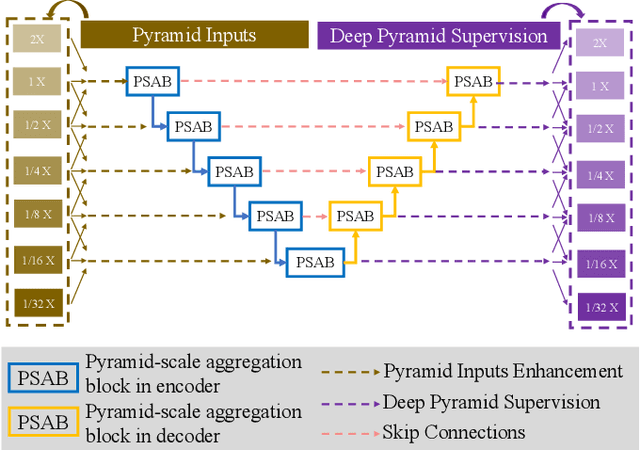

Retinal blood vessel can assist doctors in diagnosis of eye-related diseases such as diabetes and hypertension, and its segmentation is particularly important for automatic retinal image analysis. However, it is challenging to segment these vessels structures, especially the thin capillaries from the color retinal image due to low contrast and ambiguousness. In this paper, we propose pyramid U-Net for accurate retinal vessel segmentation. In pyramid U-Net, the proposed pyramid-scale aggregation blocks (PSABs) are employed in both the encoder and decoder to aggregate features at higher, current and lower levels. In this way, coarse-to-fine context information is shared and aggregated in each block thus to improve the location of capillaries. To further improve performance, two optimizations including pyramid inputs enhancement and deep pyramid supervision are applied to PSABs in the encoder and decoder, respectively. For PSABs in the encoder, scaled input images are added as extra inputs. While for PSABs in the decoder, scaled intermediate outputs are supervised by the scaled segmentation labels. Extensive evaluations show that our pyramid U-Net outperforms the current state-of-the-art methods on the public DRIVE and CHASE-DB1 datasets.
Making EfficientNet More Efficient: Exploring Batch-Independent Normalization, Group Convolutions and Reduced Resolution Training
Jun 11, 2021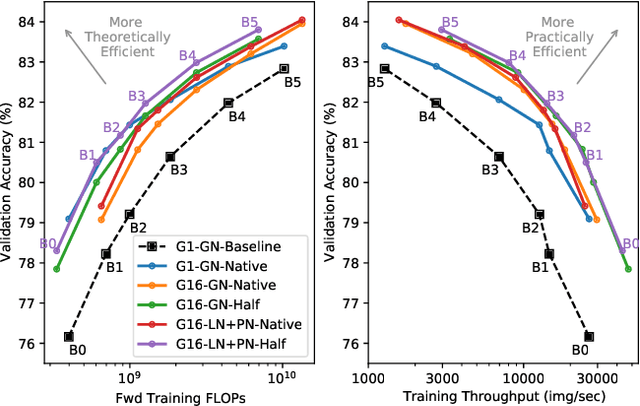

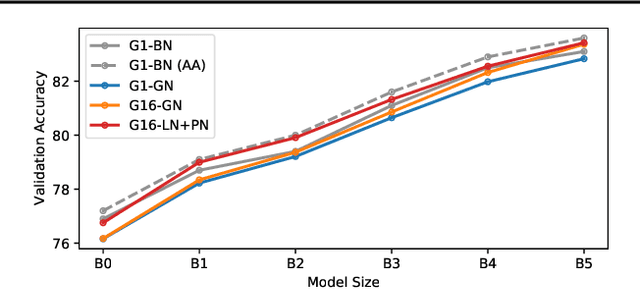
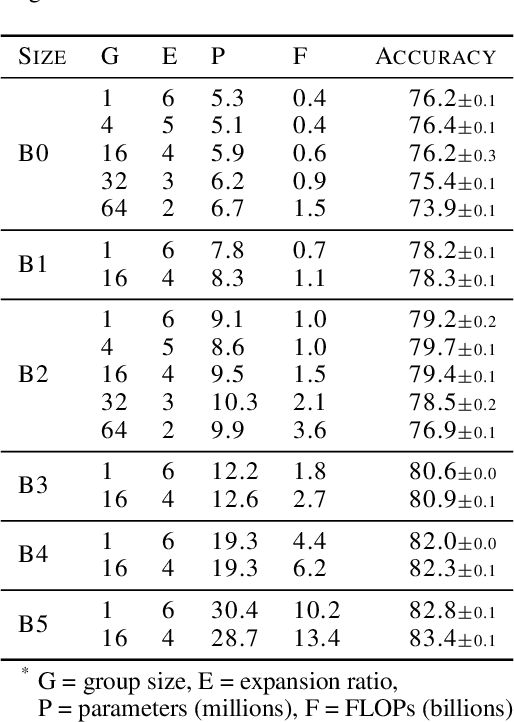
Much recent research has been dedicated to improving the efficiency of training and inference for image classification. This effort has commonly focused on explicitly improving theoretical efficiency, often measured as ImageNet validation accuracy per FLOP. These theoretical savings have, however, proven challenging to achieve in practice, particularly on high-performance training accelerators. In this work, we focus on improving the practical efficiency of the state-of-the-art EfficientNet models on a new class of accelerator, the Graphcore IPU. We do this by extending this family of models in the following ways: (i) generalising depthwise convolutions to group convolutions; (ii) adding proxy-normalized activations to match batch normalization performance with batch-independent statistics; (iii) reducing compute by lowering the training resolution and inexpensively fine-tuning at higher resolution. We find that these three methods improve the practical efficiency for both training and inference. Our code will be made available online.
SConE: Siamese Constellation Embedding Descriptor for Image Matching
Sep 28, 2018

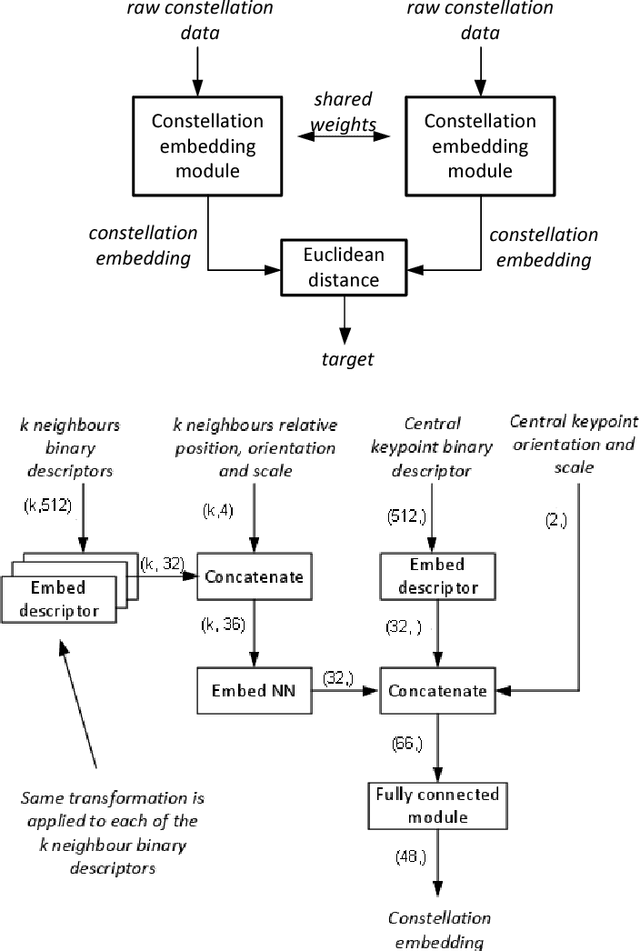
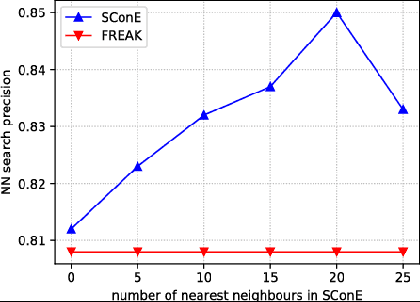
Numerous computer vision applications rely on local feature descriptors, such as SIFT, SURF or FREAK, for image matching. Although their local character makes image matching processes more robust to occlusions, it often leads to geometrically inconsistent keypoint matches that need to be filtered out, e.g. using RANSAC. In this paper we propose a novel, more discriminative, descriptor that includes not only local feature representation, but also information about the geometric layout of neighbouring keypoints. To that end, we use a Siamese architecture that learns a low-dimensional feature embedding of keypoint constellation by maximizing the distances between non-corresponding pairs of matched image patches, while minimizing it for correct matches. The 48-dimensional oating point descriptor that we train is built on top of the state-of-the-art FREAK descriptor achieves significant performance improvement over the competitors on a challenging TUM dataset.
Polarimetric image augmentation
May 22, 2020


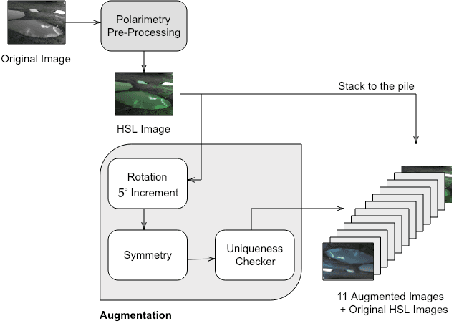
Robotics applications in urban environments are subject to obstacles that exhibit specular reflections hampering autonomous navigation. On the other hand, these reflections are highly polarized and this extra information can successfully be used to segment the specular areas. In nature, polarized light is obtained by reflection or scattering. Deep Convolutional Neural Networks (DCNNs) have shown excellent segmentation results, but require a significant amount of data to achieve best performances. The lack of data is usually overcomed by using augmentation methods. However, unlike RGB images, polarization images are not only scalar (intensity) images and standard augmentation techniques cannot be applied straightforwardly. We propose to enhance deep learning models through a regularized augmentation procedure applied to polarimetric data in order to characterize scenes more effectively under challenging conditions. We subsequently observe an average of 18.1% improvement in IoU between non augmented and regularized training procedures on real world data.
Coding Standards as Anchors for the CVPR CLIC video track
May 20, 2021
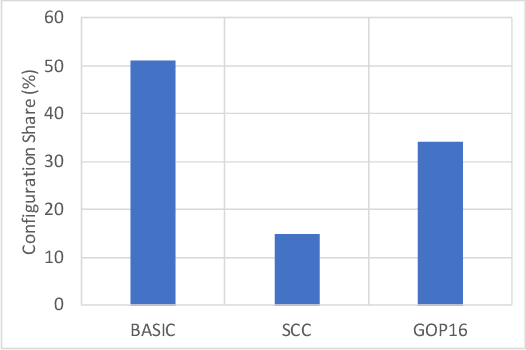
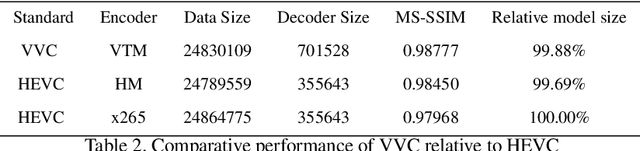
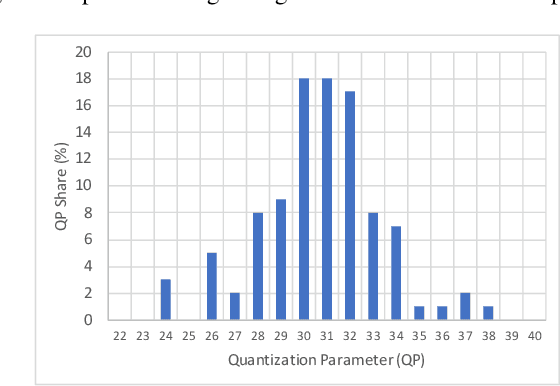
In 2021, a new track has been initiated in the Challenge for Learned Image Compression~: the video track. This category proposes to explore technologies for the compression of short video clips at 1 Mbit/s. This paper proposes to generate coded videos using the latest standardized video coders, especially Versatile Video Coding (VVC). The objective is not only to measure the progress made by learning techniques compared to the state of the art video coders, but also to quantify their progress from years to years. With this in mind, this paper documents how to generate the video sequences fulfilling the requirements of this challenge, in a reproducible way, targeting the maximum performance for VVC.
Understanding the Role of Scene Graphs in Visual Question Answering
Jan 17, 2021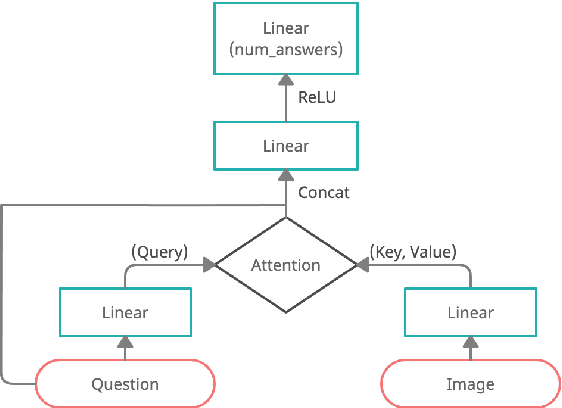
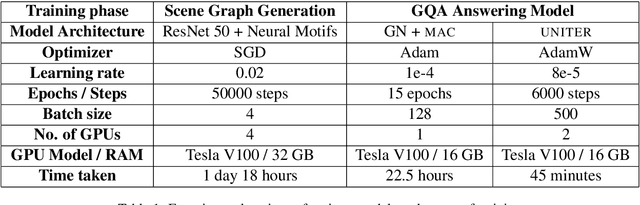
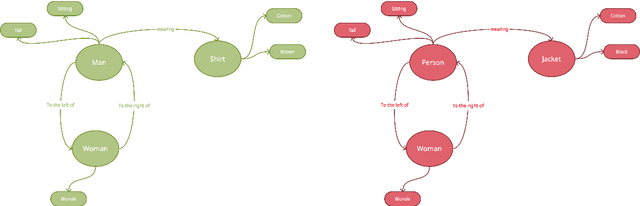
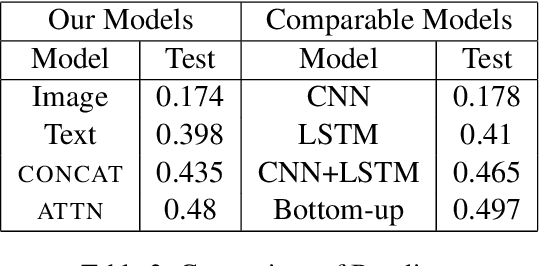
Visual Question Answering (VQA) is of tremendous interest to the research community with important applications such as aiding visually impaired users and image-based search. In this work, we explore the use of scene graphs for solving the VQA task. We conduct experiments on the GQA dataset which presents a challenging set of questions requiring counting, compositionality and advanced reasoning capability, and provides scene graphs for a large number of images. We adopt image + question architectures for use with scene graphs, evaluate various scene graph generation techniques for unseen images, propose a training curriculum to leverage human-annotated and auto-generated scene graphs, and build late fusion architectures to learn from multiple image representations. We present a multi-faceted study into the use of scene graphs for VQA, making this work the first of its kind.
Blind stain separation using model-aware generative learning and its applications on fluorescence microscopy images
Feb 12, 2021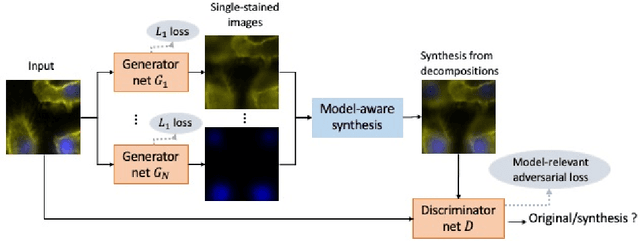

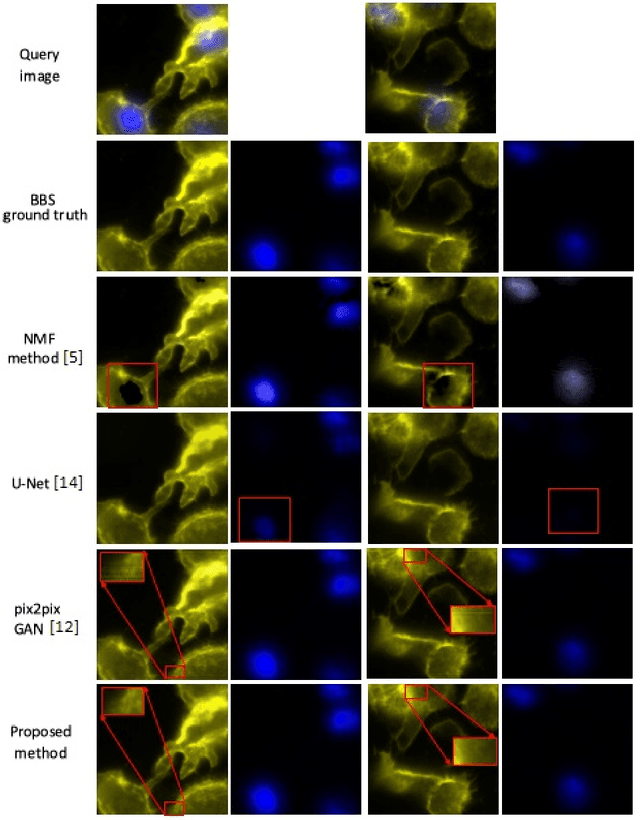
Multiple stains are usually used to highlight biological substances in biomedical image analysis. To decompose multiple stains for co-localization quantification, blind source separation is usually performed. Prior model-based stain separation methods usually rely on stains' spatial distributions over an image and may fail to solve the co-localization problem. With the advantage of machine learning, deep generative models are used for this purpose. Since prior knowledge of imaging models is ignored in purely data-driven solutions, these methods may be sub-optimal. In this study, a novel learning-based blind source separation framework is proposed, where the physical model of biomedical imaging is incorporated to regularize the learning process. The introduced model-relevant adversarial loss couples all generators in the framework and limits the capacities of the generative models. Further more, a training algorithm is innovated for the proposed framework to avoid inter-generator confusion during learning. This paper particularly takes fluorescence unmixing in fluorescence microscopy images as an application example of the proposed framework. Qualitative and quantitative experimentation on a public fluorescence microscopy image set demonstrates the superiority of the proposed method over both prior model-based approaches and learning-based methods.
Aligning Correlation Information for Domain Adaptation in Action Recognition
Jul 11, 2021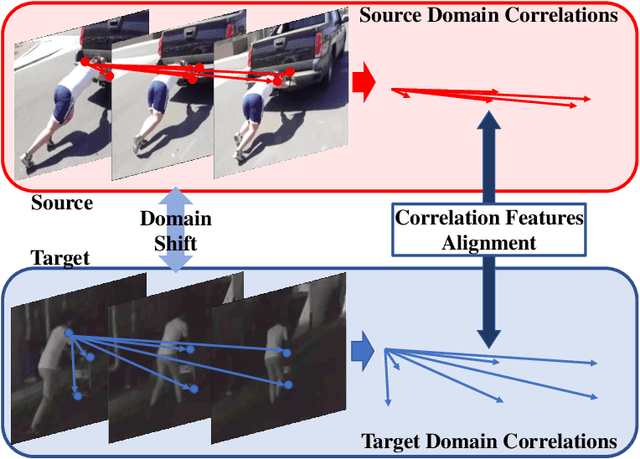
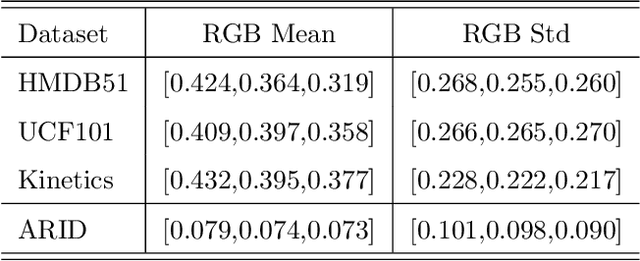
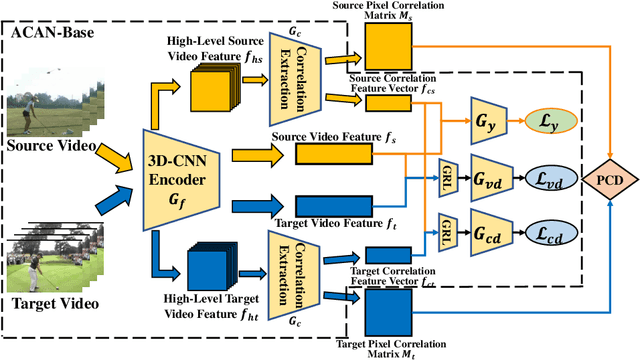

Domain adaptation (DA) approaches address domain shift and enable networks to be applied to different scenarios. Although various image DA approaches have been proposed in recent years, there is limited research towards video DA. This is partly due to the complexity in adapting the different modalities of features in videos, which includes the correlation features extracted as long-term dependencies of pixels across spatiotemporal dimensions. The correlation features are highly associated with action classes and proven their effectiveness in accurate video feature extraction through the supervised action recognition task. Yet correlation features of the same action would differ across domains due to domain shift. Therefore we propose a novel Adversarial Correlation Adaptation Network (ACAN) to align action videos by aligning pixel correlations. ACAN aims to minimize the distribution of correlation information, termed as Pixel Correlation Discrepancy (PCD). Additionally, video DA research is also limited by the lack of cross-domain video datasets with larger domain shifts. We, therefore, introduce a novel HMDB-ARID dataset with a larger domain shift caused by a larger statistical difference between domains. This dataset is built in an effort to leverage current datasets for dark video classification. Empirical results demonstrate the state-of-the-art performance of our proposed ACAN for both existing and the new video DA datasets.
Heterogeneous Face Frontalization via Domain Agnostic Learning
Jul 17, 2021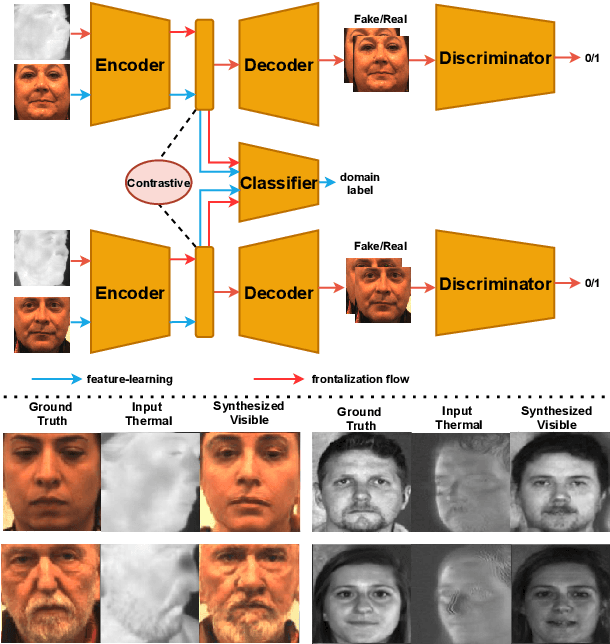
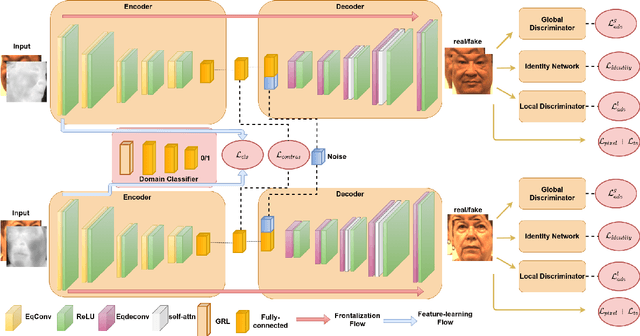
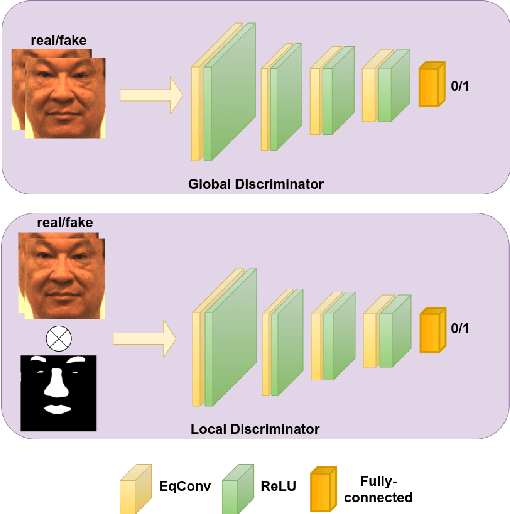
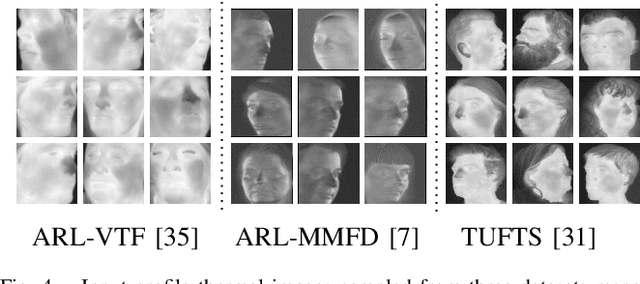
Recent advances in deep convolutional neural networks (DCNNs) have shown impressive performance improvements on thermal to visible face synthesis and matching problems. However, current DCNN-based synthesis models do not perform well on thermal faces with large pose variations. In order to deal with this problem, heterogeneous face frontalization methods are needed in which a model takes a thermal profile face image and generates a frontal visible face. This is an extremely difficult problem due to the large domain as well as large pose discrepancies between the two modalities. Despite its applications in biometrics and surveillance, this problem is relatively unexplored in the literature. We propose a domain agnostic learning-based generative adversarial network (DAL-GAN) which can synthesize frontal views in the visible domain from thermal faces with pose variations. DAL-GAN consists of a generator with an auxiliary classifier and two discriminators which capture both local and global texture discriminations for better synthesis. A contrastive constraint is enforced in the latent space of the generator with the help of a dual-path training strategy, which improves the feature vector discrimination. Finally, a multi-purpose loss function is utilized to guide the network in synthesizing identity preserving cross-domain frontalization. Extensive experimental results demonstrate that DAL-GAN can generate better quality frontal views compared to the other baseline methods.
Unsupervised Deep Features for Privacy Image Classification
Sep 24, 2019
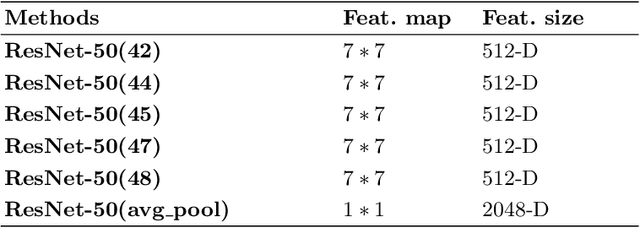
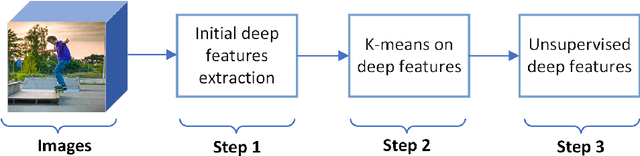

Sharing images online poses security threats to a wide range of users due to the unawareness of privacy information. Deep features have been demonstrated to be a powerful representation for images. However, deep features usually suffer from the issues of a large size and requiring a huge amount of data for fine-tuning. In contrast to normal images (e.g., scene images), privacy images are often limited because of sensitive information. In this paper, we propose a novel approach that can work on limited data and generate deep features of smaller size. For training images, we first extract the initial deep features from the pre-trained model and then employ the K-means clustering algorithm to learn the centroids of these initial deep features. We use the learned centroids from training features to extract the final features for each testing image and encode our final features with the triangle encoding. To improve the discriminability of the features, we further perform the fusion of two proposed unsupervised deep features obtained from different layers. Experimental results show that the proposed features outperform state-of-the-art deep features, in terms of both classification accuracy and testing time.