 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Research on Fast Text Recognition Method for Financial Ticket Image
Jan 05, 2021
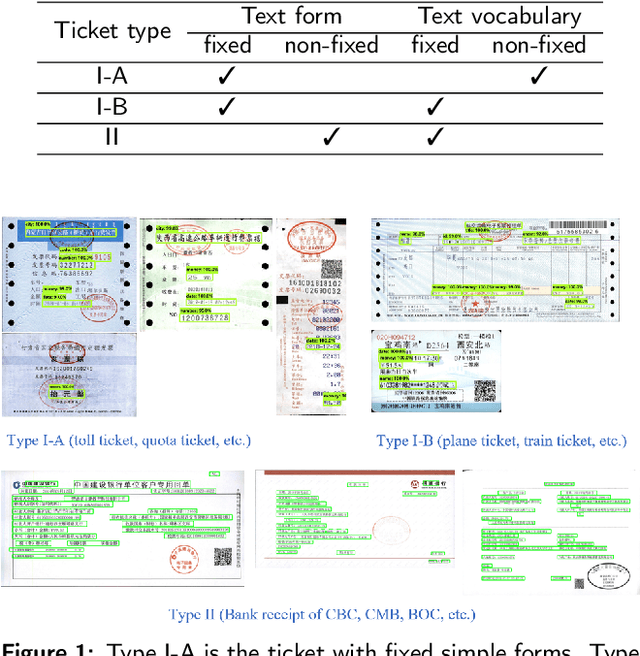
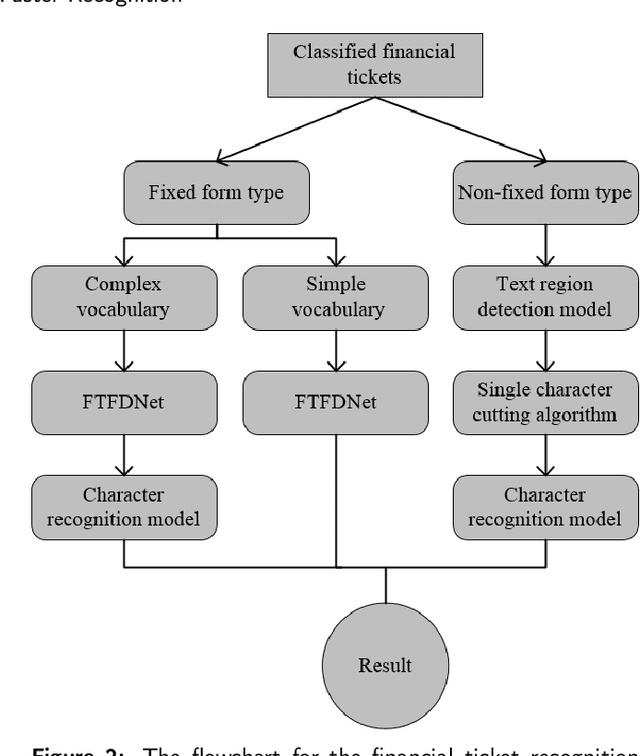

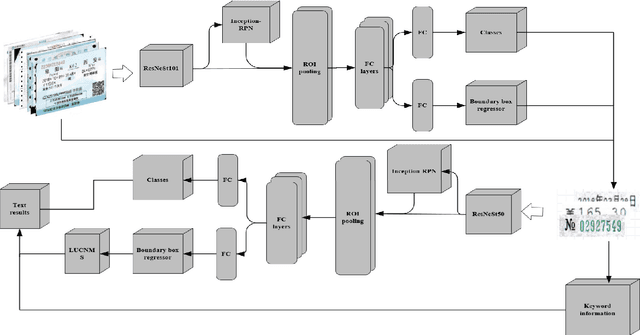
Currently, deep learning methods have been widely applied in and thus promoted the development of different fields. In the financial accounting field, the rapid increase in the number of financial tickets dramatically increases labor costs; hence, using a deep learning method to relieve the pressure on accounting is necessary. At present, a few works have applied deep learning methods to financial ticket recognition. However, first, their approaches only cover a few types of tickets. In addition, the precision and speed of their recognition models cannot meet the requirements of practical financial accounting systems. Moreover, none of the methods provides a detailed analysis of both the types and content of tickets. Therefore, this paper first analyzes the different features of 482 kinds of financial tickets, divides all kinds of financial tickets into three categories and proposes different recognition patterns for each category. These recognition patterns can meet almost all types of financial ticket recognition needs. Second, regarding the fixed format types of financial tickets (accounting for 68.27\% of the total types of tickets), we propose a simple yet efficient network named the Financial Ticket Faster Detection network (FTFDNet) based on a Faster RCNN. Furthermore, according to the characteristics of the financial ticket text, in order to obtain higher recognition accuracy, the loss function, Region Proposal Network (RPN), and Non-Maximum Suppression (NMS) are improved to make FTFDNet focus more on text. Finally, we perform a comparison with the best ticket recognition model from the ICDAR2019 invoice competition. The experimental results illustrate that FTFDNet increases the processing speed by 50\% while maintaining similar precision.
An Investigation of Feature-based Nonrigid Image Registration using Gaussian Process
Jan 12, 2020
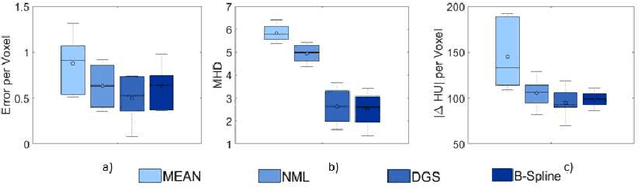
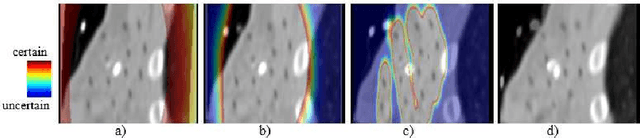
For a wide range of clinical applications, such as adaptive treatment planning or intraoperative image update, feature-based deformable registration (FDR) approaches are widely employed because of their simplicity and low computational complexity. FDR algorithms estimate a dense displacement field by interpolating a sparse field, which is given by the established correspondence between selected features. In this paper, we consider the deformation field as a Gaussian Process (GP), whereas the selected features are regarded as prior information on the valid deformations. Using GP, we are able to estimate the both dense displacement field and a corresponding uncertainty map at once. Furthermore, we evaluated the performance of different hyperparameter settings for squared exponential kernels with synthetic, phantom and clinical data respectively. The quantitative comparison shows, GP-based interpolation has performance on par with state-of-the-art B-spline interpolation. The greatest clinical benefit of GP-based interpolation is that it gives a reliable estimate of the mathematical uncertainty of the calculated dense displacement map.
Learning Category-Specific Mesh Reconstruction from Image Collections
Jul 30, 2018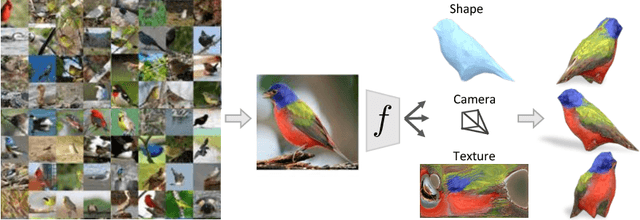
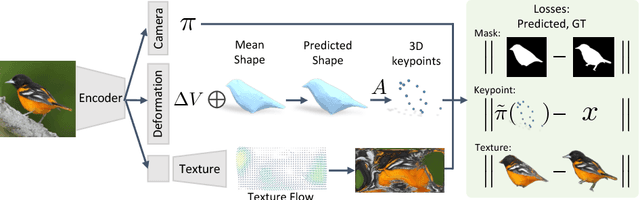
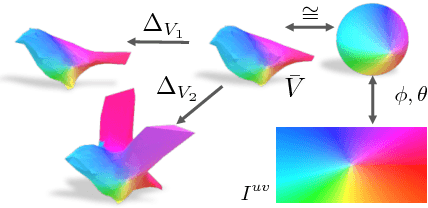

We present a learning framework for recovering the 3D shape, camera, and texture of an object from a single image. The shape is represented as a deformable 3D mesh model of an object category where a shape is parameterized by a learned mean shape and per-instance predicted deformation. Our approach allows leveraging an annotated image collection for training, where the deformable model and the 3D prediction mechanism are learned without relying on ground-truth 3D or multi-view supervision. Our representation enables us to go beyond existing 3D prediction approaches by incorporating texture inference as prediction of an image in a canonical appearance space. Additionally, we show that semantic keypoints can be easily associated with the predicted shapes. We present qualitative and quantitative results of our approach on CUB and PASCAL3D datasets and show that we can learn to predict diverse shapes and textures across objects using only annotated image collections. The project website can be found at https://akanazawa.github.io/cmr/.
Inferring Dynamic Representations of Facial Actions from a Still Image
Apr 04, 2019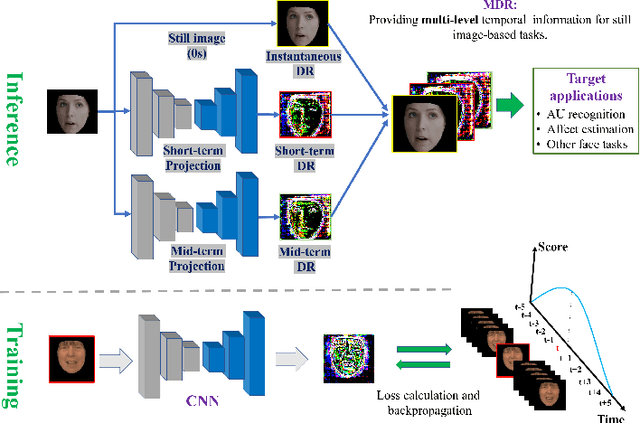
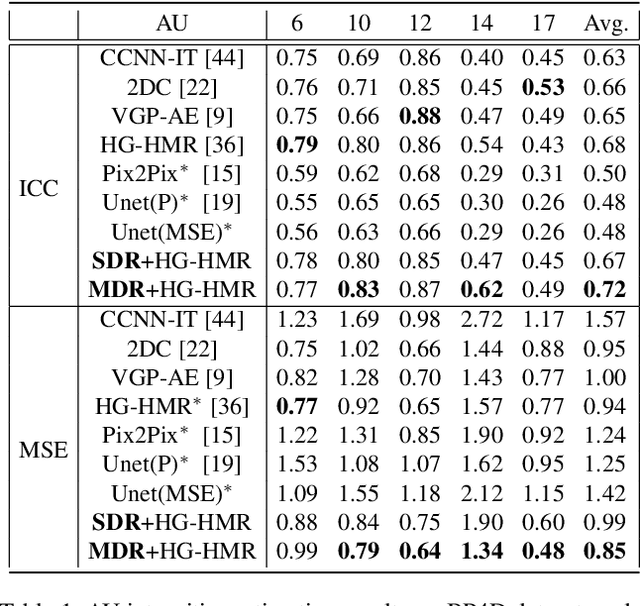
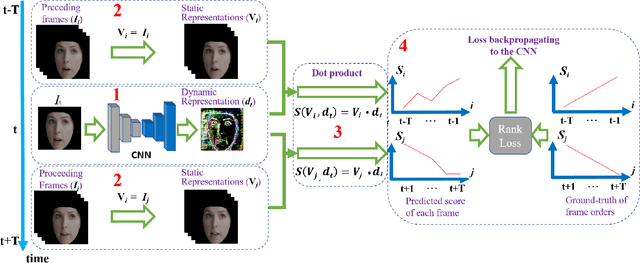
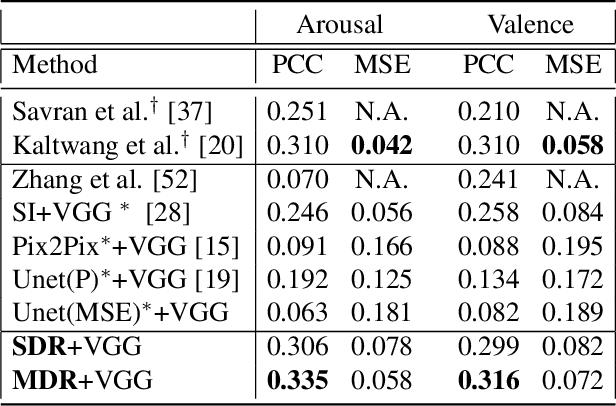
Facial actions are spatio-temporal signals by nature, and therefore their modeling is crucially dependent on the availability of temporal information. In this paper, we focus on inferring such temporal dynamics of facial actions when no explicit temporal information is available, i.e. from still images. We present a novel approach to capture multiple scales of such temporal dynamics, with an application to facial Action Unit (AU) intensity estimation and dimensional affect estimation. In particular, 1) we propose a framework that infers a dynamic representation (DR) from a still image, which captures the bi-directional flow of time within a short time-window centered at the input image; 2) we show that we can train our method without the need of explicitly generating target representations, allowing the network to represent dynamics more broadly; and 3) we propose to apply a multiple temporal scale approach that infers DRs for different window lengths (MDR) from a still image. We empirically validate the value of our approach on the task of frame ranking, and show how our proposed MDR attains state of the art results on BP4D for AU intensity estimation and on SEMAINE for dimensional affect estimation, using only still images at test time.
Convolutional Dictionary Pair Learning Network for Image Representation Learning
Jan 15, 2020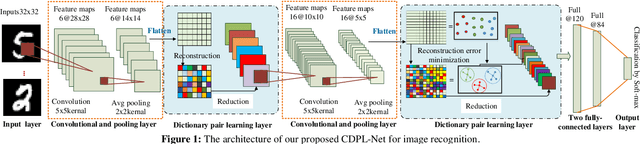
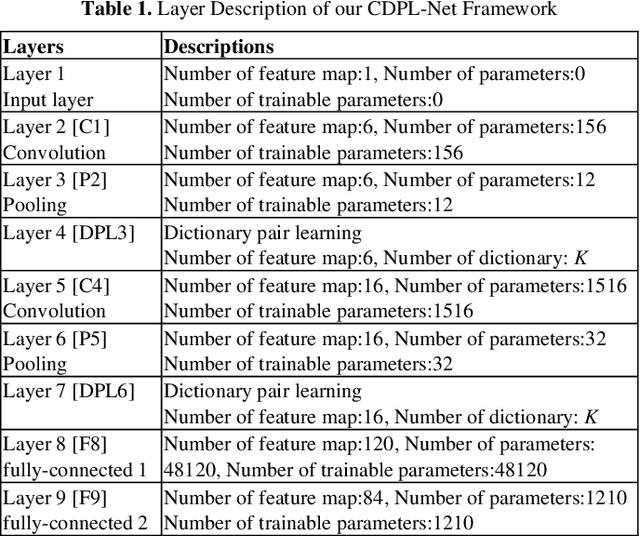
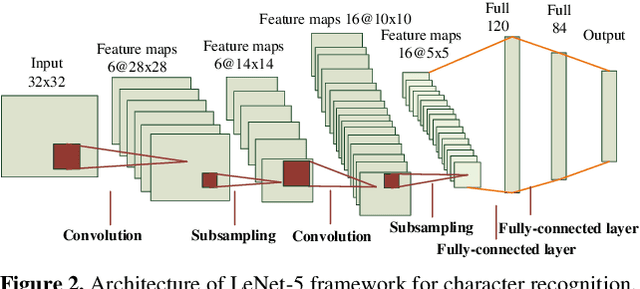
Both the Dictionary Learning (DL) and Convolutional Neural Networks (CNN) are powerful image representation learning systems based on different mechanisms and principles, however whether we can seamlessly integrate them to improve the per-formance is noteworthy exploring. To address this issue, we propose a novel generalized end-to-end representation learning architecture, dubbed Convolutional Dictionary Pair Learning Network (CDPL-Net) in this paper, which integrates the learning schemes of the CNN and dictionary pair learning into a unified framework. Generally, the architecture of CDPL-Net includes two convolutional/pooling layers and two dictionary pair learn-ing (DPL) layers in the representation learning module. Besides, it uses two fully-connected layers as the multi-layer perception layer in the nonlinear classification module. In particular, the DPL layer can jointly formulate the discriminative synthesis and analysis representations driven by minimizing the batch based reconstruction error over the flatted feature maps from the convolution/pooling layer. Moreover, DPL layer uses l1-norm on the analysis dictionary so that sparse representation can be delivered, and the embedding process will also be robust to noise. To speed up the training process of DPL layer, the efficient stochastic gradient descent is used. Extensive simulations on real databases show that our CDPL-Net can deliver enhanced performance over other state-of-the-art methods.
CAPE: Encoding Relative Positions with Continuous Augmented Positional Embeddings
Jun 06, 2021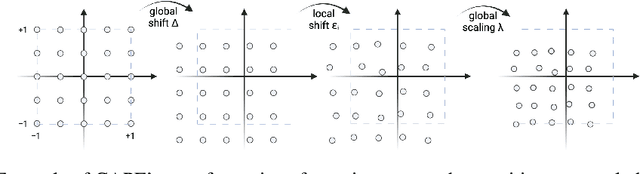
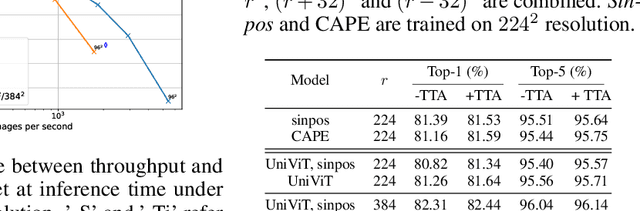
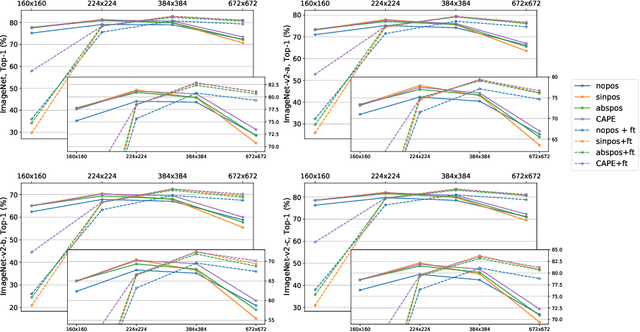
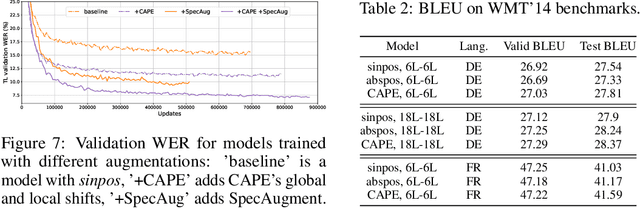
Without positional information, attention-based transformer neural networks are permutation-invariant. Absolute or relative positional embeddings are the most popular ways to feed transformer models positional information. Absolute positional embeddings are simple to implement, but suffer from generalization issues when evaluating on sequences of different length than those seen at training time. Relative positions are more robust to length change, but are more complex to implement and yield inferior model throughput. In this paper, we propose an augmentation-based approach (CAPE) for absolute positional embeddings, which keeps the advantages of both absolute (simplicity and speed) and relative position embeddings (better generalization). In addition, our empirical evaluation on state-of-the-art models in machine translation, image and speech recognition demonstrates that CAPE leads to better generalization performance as well as increased stability with respect to training hyper-parameters.
Graph Pattern Loss based Diversified Attention Network for Cross-Modal Retrieval
Jun 25, 2021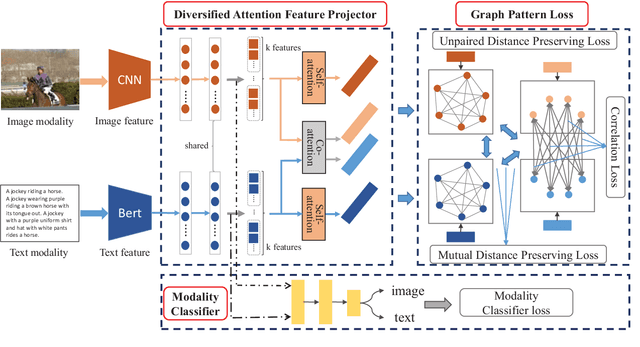
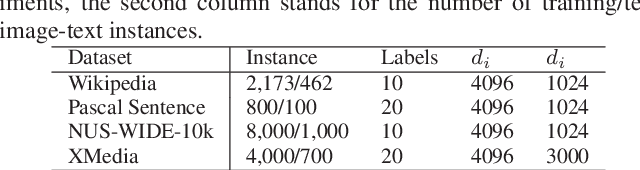
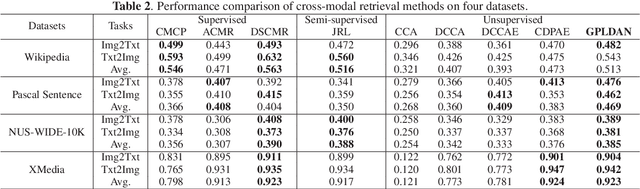
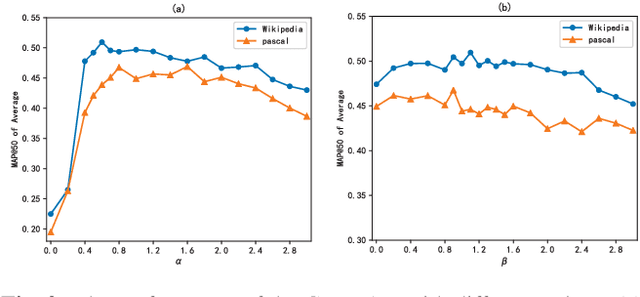
Cross-modal retrieval aims to enable flexible retrieval experience by combining multimedia data such as image, video, text, and audio. One core of unsupervised approaches is to dig the correlations among different object representations to complete satisfied retrieval performance without requiring expensive labels. In this paper, we propose a Graph Pattern Loss based Diversified Attention Network(GPLDAN) for unsupervised cross-modal retrieval to deeply analyze correlations among representations. First, we propose a diversified attention feature projector by considering the interaction between different representations to generate multiple representations of an instance. Then, we design a novel graph pattern loss to explore the correlations among different representations, in this graph all possible distances between different representations are considered. In addition, a modality classifier is added to explicitly declare the corresponding modalities of features before fusion and guide the network to enhance discrimination ability. We test GPLDAN on four public datasets. Compared with the state-of-the-art cross-modal retrieval methods, the experimental results demonstrate the performance and competitiveness of GPLDAN.
* 5 pages, 3 figures
Keyframe-Focused Visual Imitation Learning
Jun 11, 2021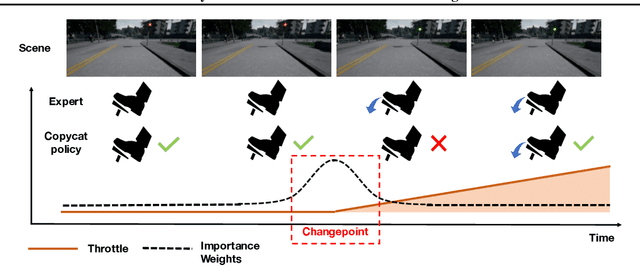
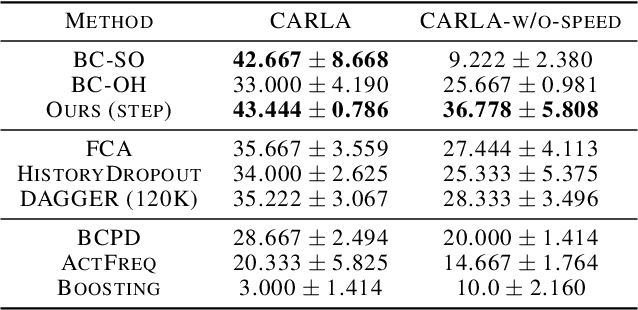
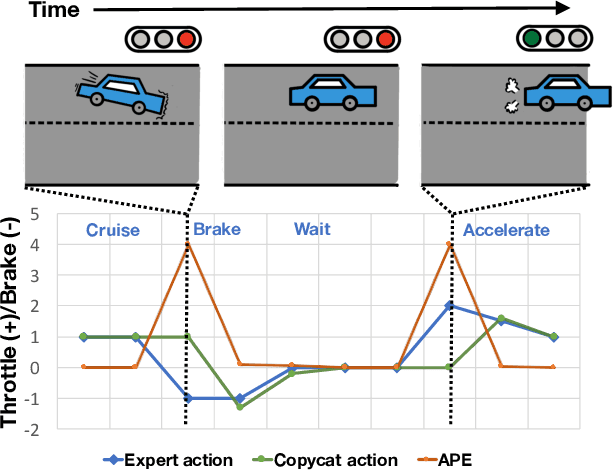

Imitation learning trains control policies by mimicking pre-recorded expert demonstrations. In partially observable settings, imitation policies must rely on observation histories, but many seemingly paradoxical results show better performance for policies that only access the most recent observation. Recent solutions ranging from causal graph learning to deep information bottlenecks have shown promising results, but failed to scale to realistic settings such as visual imitation. We propose a solution that outperforms these prior approaches by upweighting demonstration keyframes corresponding to expert action changepoints. This simple approach easily scales to complex visual imitation settings. Our experimental results demonstrate consistent performance improvements over all baselines on image-based Gym MuJoCo continuous control tasks. Finally, on the CARLA photorealistic vision-based urban driving simulator, we resolve a long-standing issue in behavioral cloning for driving by demonstrating effective imitation from observation histories. Supplementary materials and code at: \url{https://tinyurl.com/imitation-keyframes}.
Making EfficientNet More Efficient: Exploring Batch-Independent Normalization, Group Convolutions and Reduced Resolution Training
Jun 11, 2021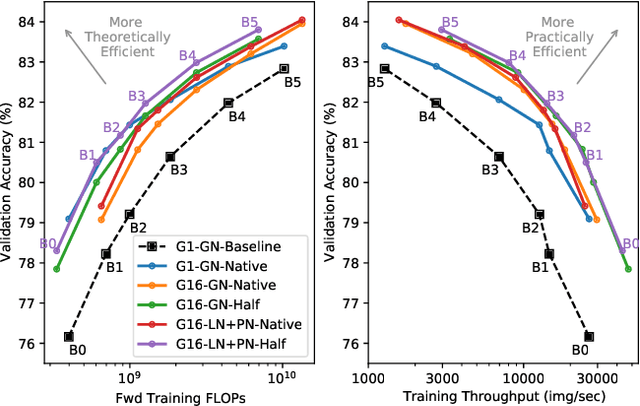

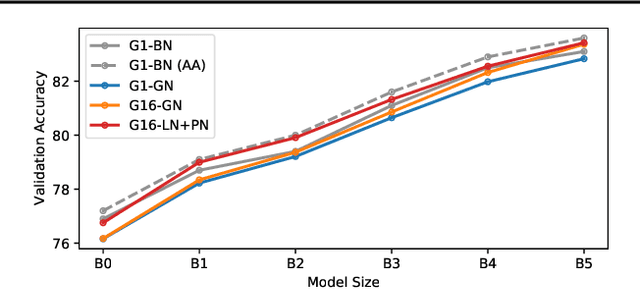
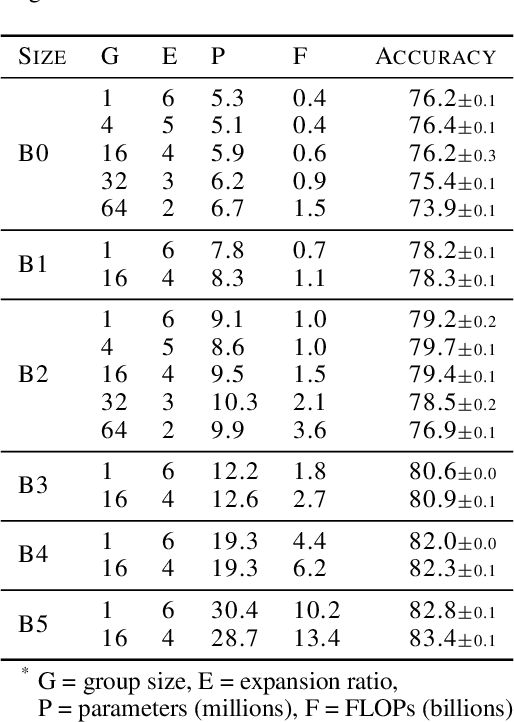
Much recent research has been dedicated to improving the efficiency of training and inference for image classification. This effort has commonly focused on explicitly improving theoretical efficiency, often measured as ImageNet validation accuracy per FLOP. These theoretical savings have, however, proven challenging to achieve in practice, particularly on high-performance training accelerators. In this work, we focus on improving the practical efficiency of the state-of-the-art EfficientNet models on a new class of accelerator, the Graphcore IPU. We do this by extending this family of models in the following ways: (i) generalising depthwise convolutions to group convolutions; (ii) adding proxy-normalized activations to match batch normalization performance with batch-independent statistics; (iii) reducing compute by lowering the training resolution and inexpensively fine-tuning at higher resolution. We find that these three methods improve the practical efficiency for both training and inference. Our code will be made available online.
Pyramid U-Net for Retinal Vessel Segmentation
Apr 06, 2021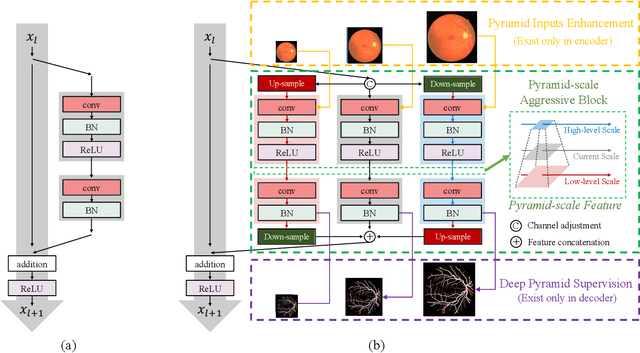
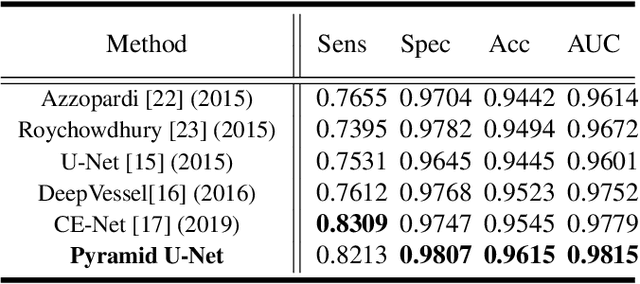
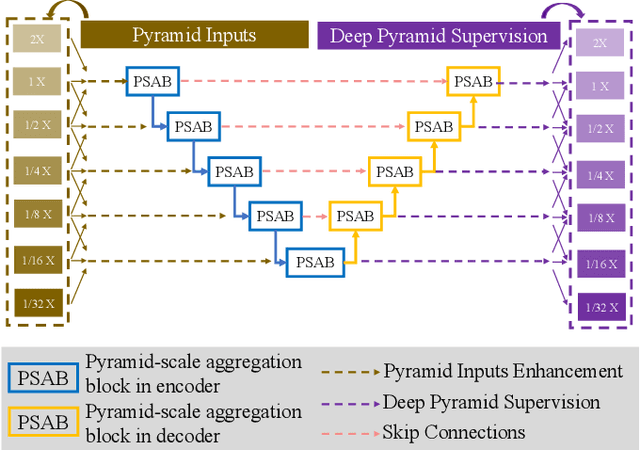

Retinal blood vessel can assist doctors in diagnosis of eye-related diseases such as diabetes and hypertension, and its segmentation is particularly important for automatic retinal image analysis. However, it is challenging to segment these vessels structures, especially the thin capillaries from the color retinal image due to low contrast and ambiguousness. In this paper, we propose pyramid U-Net for accurate retinal vessel segmentation. In pyramid U-Net, the proposed pyramid-scale aggregation blocks (PSABs) are employed in both the encoder and decoder to aggregate features at higher, current and lower levels. In this way, coarse-to-fine context information is shared and aggregated in each block thus to improve the location of capillaries. To further improve performance, two optimizations including pyramid inputs enhancement and deep pyramid supervision are applied to PSABs in the encoder and decoder, respectively. For PSABs in the encoder, scaled input images are added as extra inputs. While for PSABs in the decoder, scaled intermediate outputs are supervised by the scaled segmentation labels. Extensive evaluations show that our pyramid U-Net outperforms the current state-of-the-art methods on the public DRIVE and CHASE-DB1 datasets.