 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Demographic Fairness in Face Identification: The Watchlist Imbalance Effect
Jun 16, 2021

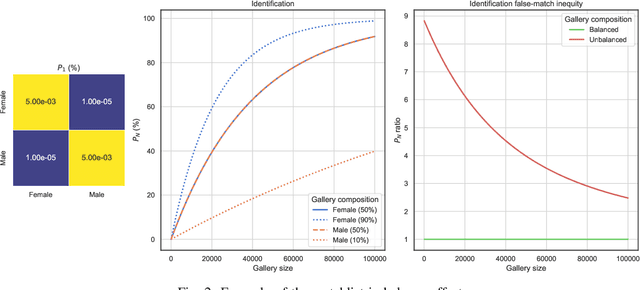

Recently, different researchers have found that the gallery composition of a face database can induce performance differentials to facial identification systems in which a probe image is compared against up to all stored reference images to reach a biometric decision. This negative effect is referred to as "watchlist imbalance effect". In this work, we present a method to theoretically estimate said effect for a biometric identification system given its verification performance across demographic groups and the composition of the used gallery. Further, we report results for identification experiments on differently composed demographic subsets, i.e. females and males, of the public academic MORPH database using the open-source ArcFace face recognition system. It is shown that the database composition has a huge impact on performance differentials in biometric identification systems, even if performance differentials are less pronounced in the verification scenario. This study represents the first detailed analysis of the watchlist imbalance effect which is expected to be of high interest for future research in the field of facial recognition.
Repurposing GANs for One-shot Semantic Part Segmentation
Mar 09, 2021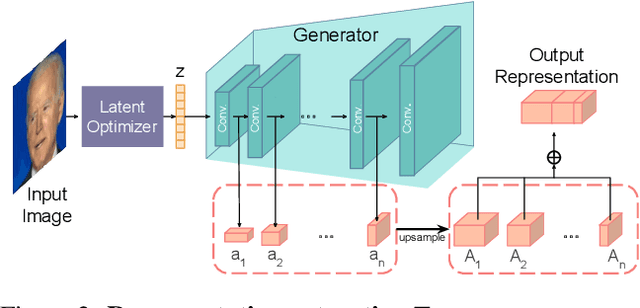
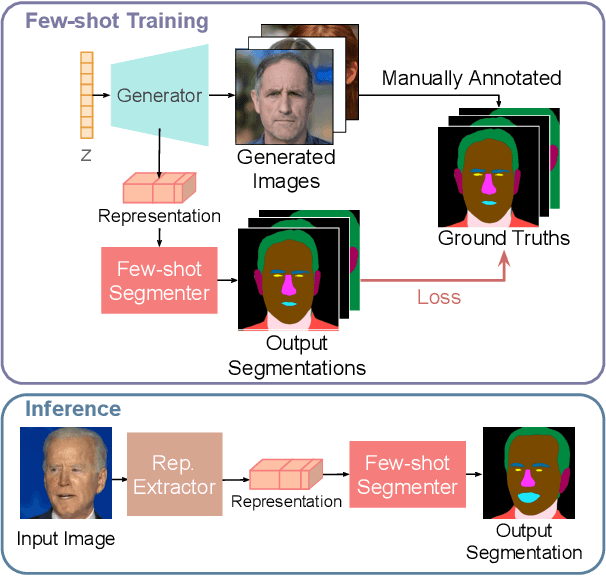

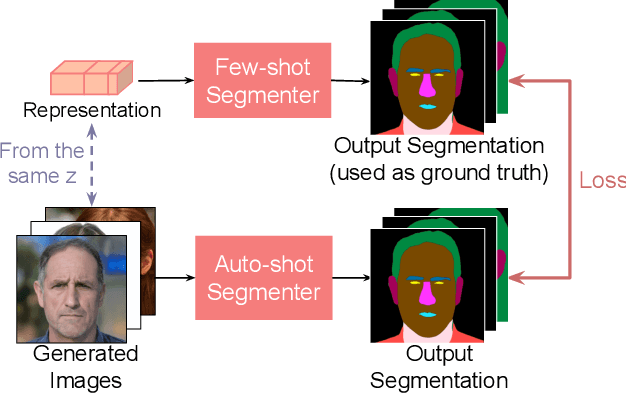
While GANs have shown success in realistic image generation, the idea of using GANs for other tasks unrelated to synthesis is underexplored. Do GANs learn meaningful structural parts of objects during their attempt to reproduce those objects? In this work, we test this hypothesis and propose a simple and effective approach based on GANs for semantic part segmentation that requires as few as one label example along with an unlabeled dataset. Our key idea is to leverage a trained GAN to extract pixel-wise representation from the input image and use it as feature vectors for a segmentation network. Our experiments demonstrate that GANs representation is "readily discriminative" and produces surprisingly good results that are comparable to those from supervised baselines trained with significantly more labels. We believe this novel repurposing of GANs underlies a new class of unsupervised representation learning that is applicable to many other tasks. More results are available at https://repurposegans.github.io/.
An Introduction to Image Synthesis with Generative Adversarial Nets
Mar 12, 2018There has been a drastic growth of research in Generative Adversarial Nets (GANs) in the past few years. Proposed in 2014, GAN has been applied to various applications such as computer vision and natural language processing, and achieves impressive performance. Among the many applications of GAN, image synthesis is the most well-studied one, and research in this area has already demonstrated the great potential of using GAN in image synthesis. In this paper, we provide a taxonomy of methods used in image synthesis, review different models for text-to-image synthesis and image-to-image translation, and discuss some evaluation metrics as well as possible future research directions in image synthesis with GAN.
Deep Image Clustering with Tensor Kernels and Unsupervised Companion Objectives
Jan 20, 2020
In this paper we develop a new model for deep image clustering, using convolutional neural networks and tensor kernels. The proposed Deep Tensor Kernel Clustering (DTKC) consists of a convolutional neural network (CNN), which is trained to reflect a common cluster structure at the output of its intermediate layers. Encouraging a consistent cluster structure throughout the network has the potential to guide it towards meaningful clusters, even though these clusters might appear to be nonlinear in the input space. The cluster structure is enforced through the idea of unsupervised companion objectives, where separate loss functions are attached to layers in the network. These unsupervised companion objectives are constructed based on a proposed generalization of the Cauchy-Schwarz (CS) divergence, from vectors to tensors of arbitrary rank. Generalizing the CS divergence to tensor-valued data is a crucial step, due to the tensorial nature of the intermediate representations in the CNN. Several experiments are conducted to thoroughly assess the performance of the proposed DTKC model. The results indicate that the model outperforms, or performs comparable to, a wide range of baseline algorithms. We also empirically demonstrate that our model does not suffer from objective function mismatch, which can be a problematic artifact in autoencoder-based clustering models.
Class agnostic moving target detection by color and location prediction of moving area
Jun 24, 2021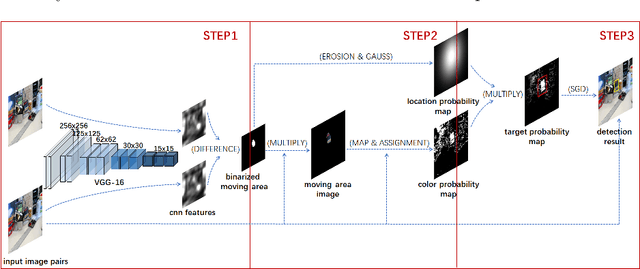
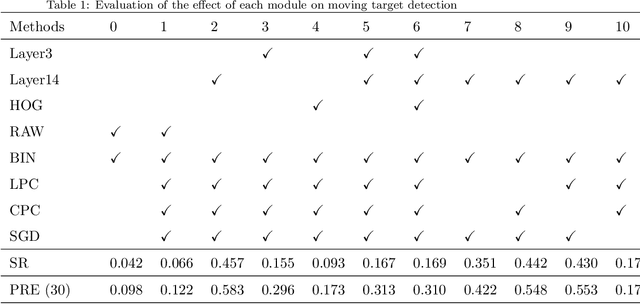


Moving target detection plays an important role in computer vision. However, traditional algorithms such as frame difference and optical flow usually suffer from low accuracy or heavy computation. Recent algorithms such as deep learning-based convolutional neural networks have achieved high accuracy and real-time performance, but they usually need to know the classes of targets in advance, which limits the practical applications. Therefore, we proposed a model free moving target detection algorithm. This algorithm extracts the moving area through the difference of image features. Then, the color and location probability map of the moving area will be calculated through maximum a posteriori probability. And the target probability map can be obtained through the dot multiply between the two maps. Finally, the optimal moving target area can be solved by stochastic gradient descent on the target probability map. Results show that the proposed algorithm achieves the highest accuracy compared with state-of-the-art algorithms, without needing to know the classes of targets. Furthermore, as the existing datasets are not suitable for moving target detection, we proposed a method for producing evaluation dataset. Besides, we also proved the proposed algorithm can be used to assist target tracking.
Mixed supervision for surface-defect detection: from weakly to fully supervised learning
Apr 20, 2021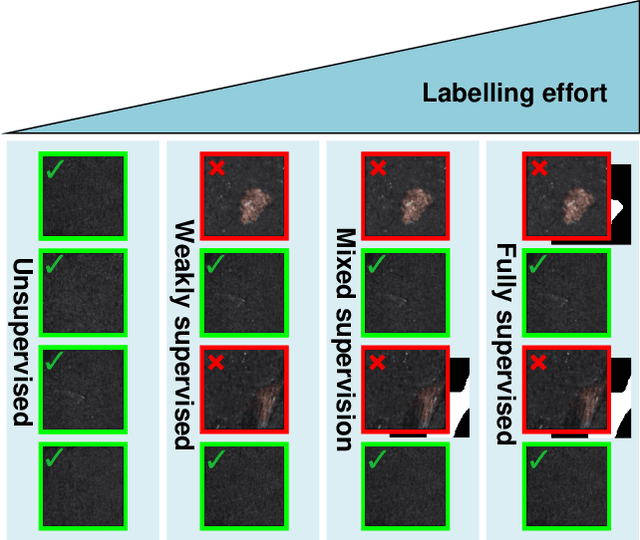
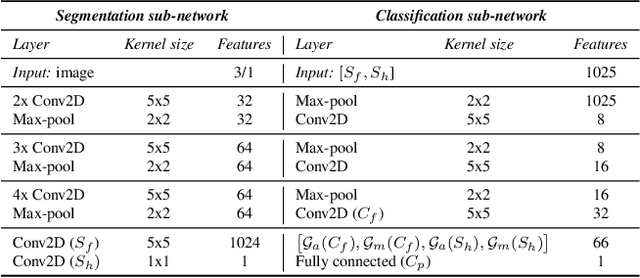
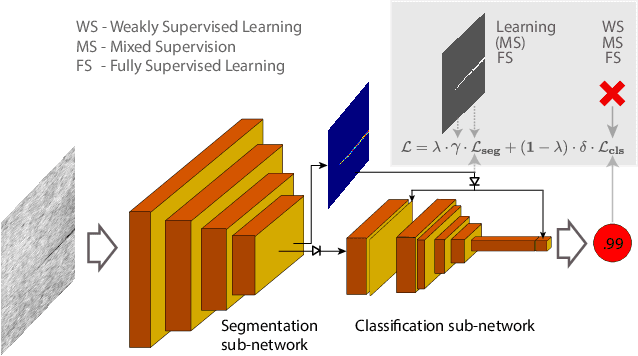
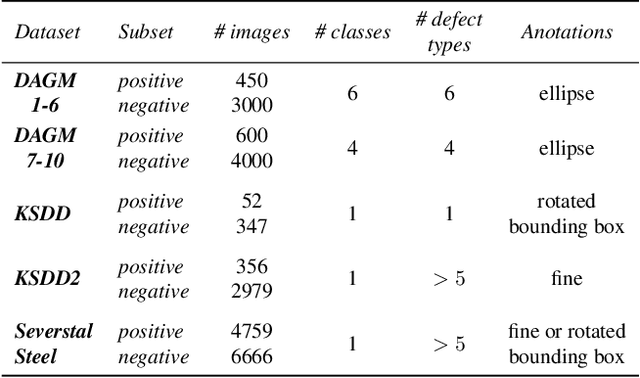
Deep-learning methods have recently started being employed for addressing surface-defect detection problems in industrial quality control. However, with a large amount of data needed for learning, often requiring high-precision labels, many industrial problems cannot be easily solved, or the cost of the solutions would significantly increase due to the annotation requirements. In this work, we relax heavy requirements of fully supervised learning methods and reduce the need for highly detailed annotations. By proposing a deep-learning architecture, we explore the use of annotations of different details ranging from weak (image-level) labels through mixed supervision to full (pixel-level) annotations on the task of surface-defect detection. The proposed end-to-end architecture is composed of two sub-networks yielding defect segmentation and classification results. The proposed method is evaluated on several datasets for industrial quality inspection: KolektorSDD, DAGM and Severstal Steel Defect. We also present a new dataset termed KolektorSDD2 with over 3000 images containing several types of defects, obtained while addressing a real-world industrial problem. We demonstrate state-of-the-art results on all four datasets. The proposed method outperforms all related approaches in fully supervised settings and also outperforms weakly-supervised methods when only image-level labels are available. We also show that mixed supervision with only a handful of fully annotated samples added to weakly labelled training images can result in performance comparable to the fully supervised model's performance but at a significantly lower annotation cost.
Accurate 3D Face Reconstruction with Weakly-Supervised Learning: From Single Image to Image Set
Mar 20, 2019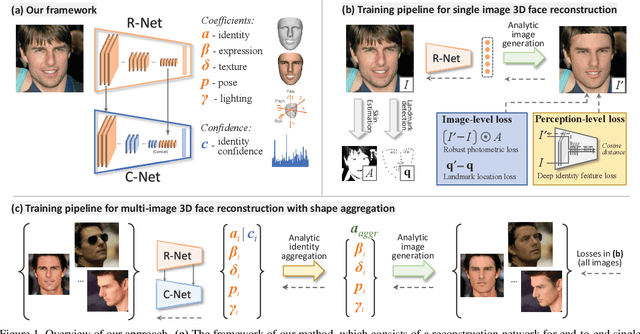


Recently, deep learning based 3D face reconstruction methods have shown promising results in both quality and efficiency.However, training deep neural networks typically requires a large volume of data, whereas face images with ground-truth 3D face shapes are scarce. In this paper, we propose a novel deep 3D face reconstruction approach that 1) leverages a robust, hybrid loss function for weakly-supervised learning which takes into account both low-level and perception-level information for supervision, and 2) performs multi-image face reconstruction by exploiting complementary information from different images for shape aggregation. Our method is fast, accurate, and robust to occlusion and large pose. We provide comprehensive experiments on three datasets, systematically comparing our method with fifteen recent methods and demonstrating its state-of-the-art performance.
SelfDoc: Self-Supervised Document Representation Learning
Jun 07, 2021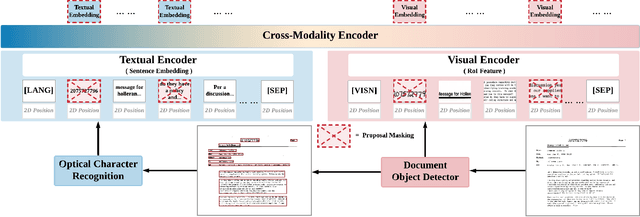
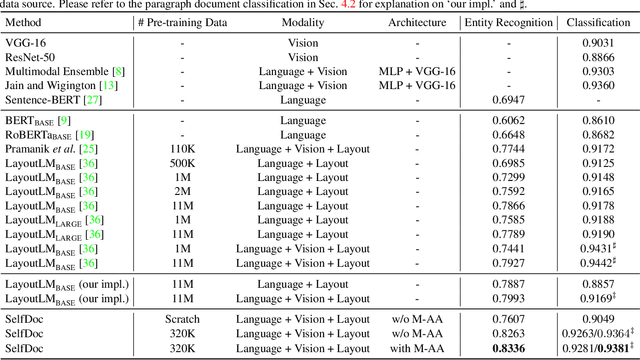
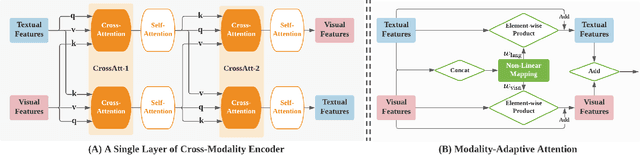

We propose SelfDoc, a task-agnostic pre-training framework for document image understanding. Because documents are multimodal and are intended for sequential reading, our framework exploits the positional, textual, and visual information of every semantically meaningful component in a document, and it models the contextualization between each block of content. Unlike existing document pre-training models, our model is coarse-grained instead of treating individual words as input, therefore avoiding an overly fine-grained with excessive contextualization. Beyond that, we introduce cross-modal learning in the model pre-training phase to fully leverage multimodal information from unlabeled documents. For downstream usage, we propose a novel modality-adaptive attention mechanism for multimodal feature fusion by adaptively emphasizing language and vision signals. Our framework benefits from self-supervised pre-training on documents without requiring annotations by a feature masking training strategy. It achieves superior performance on multiple downstream tasks with significantly fewer document images used in the pre-training stage compared to previous works.
A Bayesian Multiscale Deep Learning Framework for Flows in Random Media
Mar 08, 2021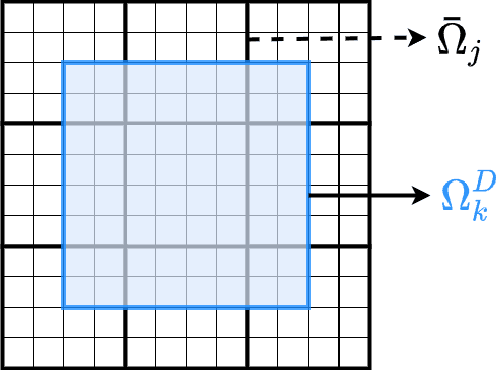

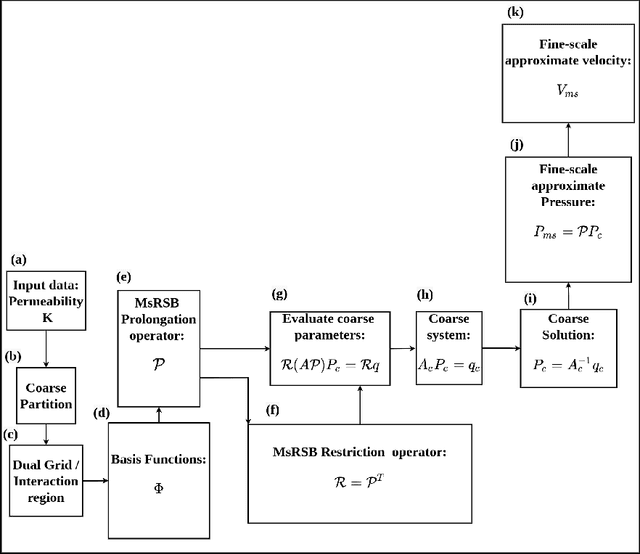
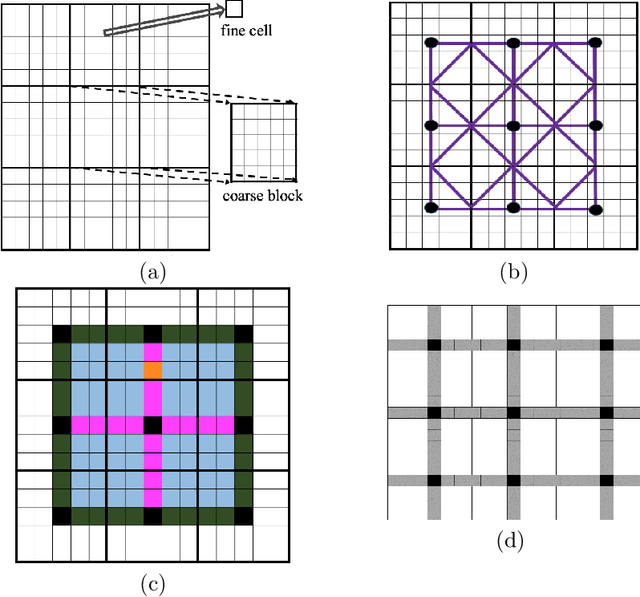
Fine-scale simulation of complex systems governed by multiscale partial differential equations (PDEs) is computationally expensive and various multiscale methods have been developed for addressing such problems. In addition, it is challenging to develop accurate surrogate and uncertainty quantification models for high-dimensional problems governed by stochastic multiscale PDEs using limited training data. In this work to address these challenges, we introduce a novel hybrid deep-learning and multiscale approach for stochastic multiscale PDEs with limited training data. For demonstration purposes, we focus on a porous media flow problem. We use an image-to-image supervised deep learning model to learn the mapping between the input permeability field and the multiscale basis functions. We introduce a Bayesian approach to this hybrid framework to allow us to perform uncertainty quantification and propagation tasks. The performance of this hybrid approach is evaluated with varying intrinsic dimensionality of the permeability field. Numerical results indicate that the hybrid network can efficiently predict well for high-dimensional inputs.
Point of Care Image Analysis for COVID-19
Nov 10, 2020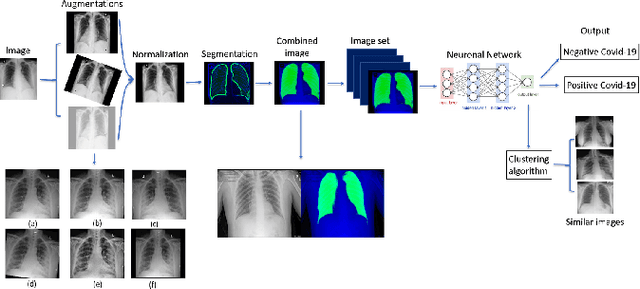
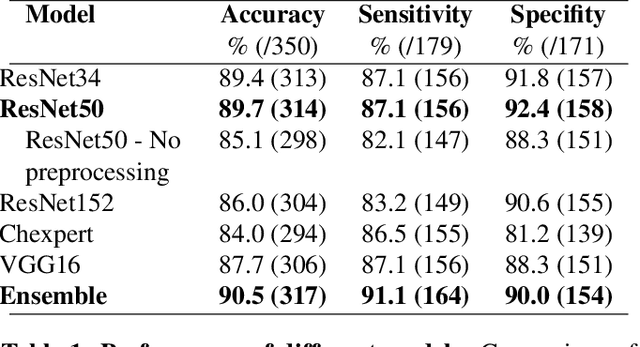
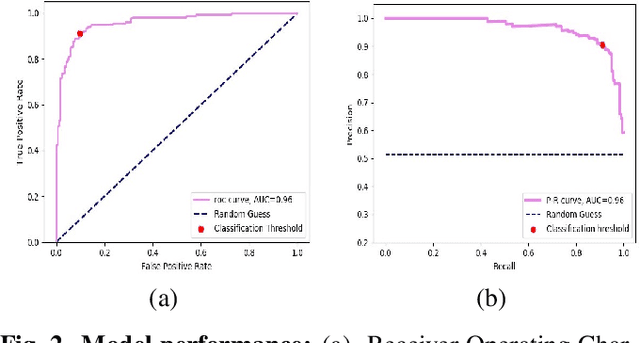
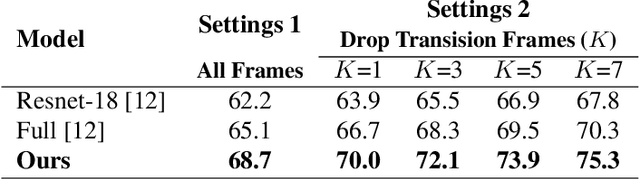
Early detection of COVID-19 is key in containing the pandemic. Disease detection and evaluation based on imaging is fast and cheap and therefore plays an important role in COVID-19 handling. COVID-19 is easier to detect in chest CT, however, it is expensive, non-portable, and difficult to disinfect, making it unfit as a point-of-care (POC) modality. On the other hand, chest X-ray (CXR) and lung ultrasound (LUS) are widely used, yet, COVID-19 findings in these modalities are not always very clear. Here we train deep neural networks to significantly enhance the capability to detect, grade and monitor COVID-19 patients using CXRs and LUS. Collaborating with several hospitals in Israel we collect a large dataset of CXRs and use this dataset to train a neural network obtaining above 90% detection rate for COVID-19. In addition, in collaboration with ULTRa (Ultrasound Laboratory Trento, Italy) and hospitals in Italy we obtained POC ultrasound data with annotations of the severity of disease and trained a deep network for automatic severity grading.