 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Interpretability-Driven Sample Selection Using Self Supervised Learning For Disease Classification And Segmentation
Apr 13, 2021
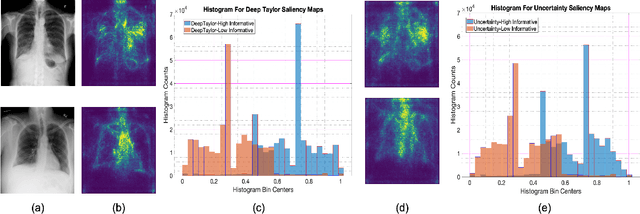
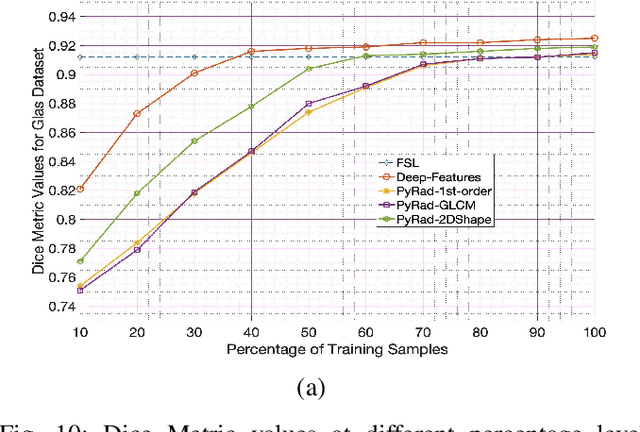
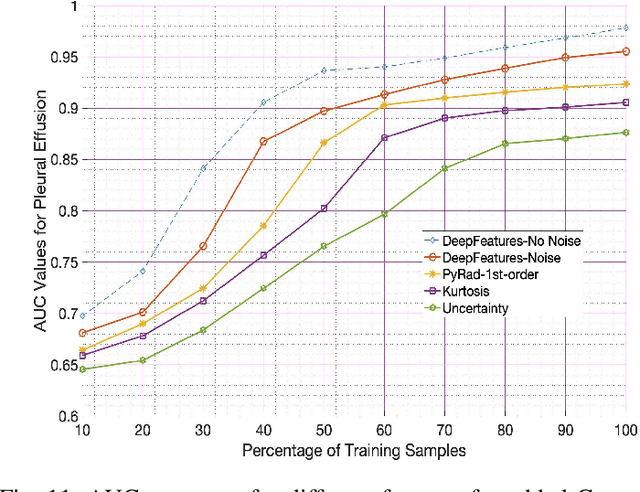
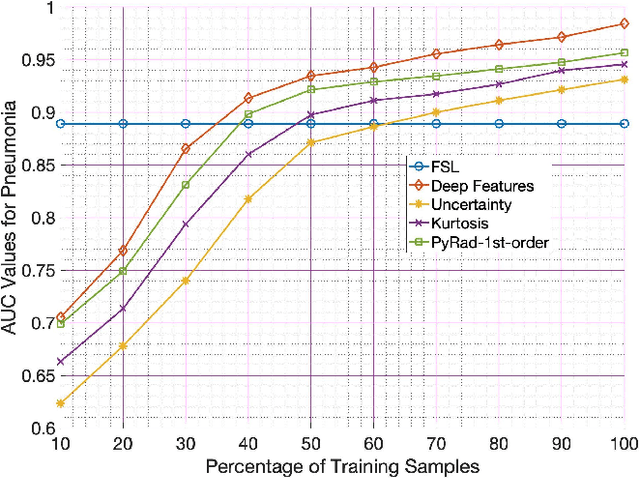
In supervised learning for medical image analysis, sample selection methodologies are fundamental to attain optimum system performance promptly and with minimal expert interactions (e.g. label querying in an active learning setup). In this paper we propose a novel sample selection methodology based on deep features leveraging information contained in interpretability saliency maps. In the absence of ground truth labels for informative samples, we use a novel self supervised learning based approach for training a classifier that learns to identify the most informative sample in a given batch of images. We demonstrate the benefits of the proposed approach, termed Interpretability-Driven Sample Selection (IDEAL), in an active learning setup aimed at lung disease classification and histopathology image segmentation. We analyze three different approaches to determine sample informativeness from interpretability saliency maps: (i) an observational model stemming from findings on previous uncertainty-based sample selection approaches, (ii) a radiomics-based model, and (iii) a novel data-driven self-supervised approach. We compare IDEAL to other baselines using the publicly available NIH chest X-ray dataset for lung disease classification, and a public histopathology segmentation dataset (GLaS), demonstrating the potential of using interpretability information for sample selection in active learning systems. Results show our proposed self supervised approach outperforms other approaches in selecting informative samples leading to state of the art performance with fewer samples.
Recursive Training for Zero-Shot Semantic Segmentation
Feb 26, 2021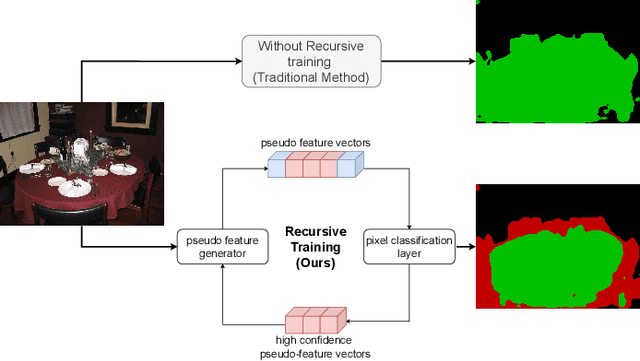
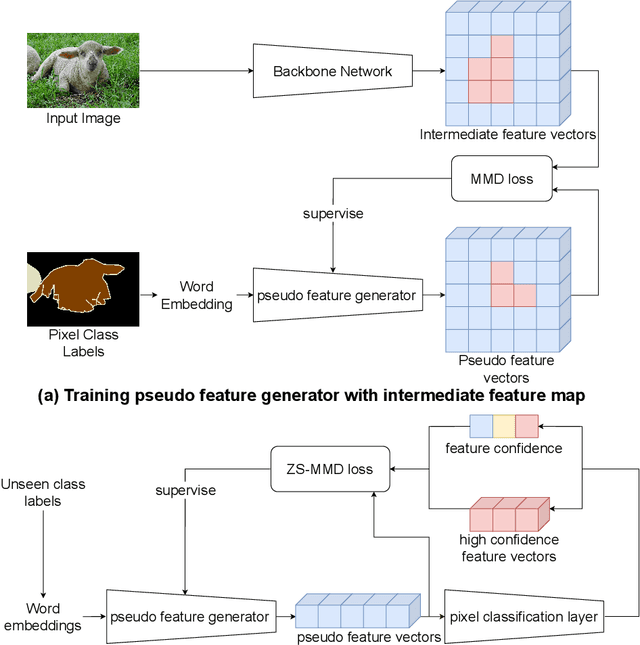

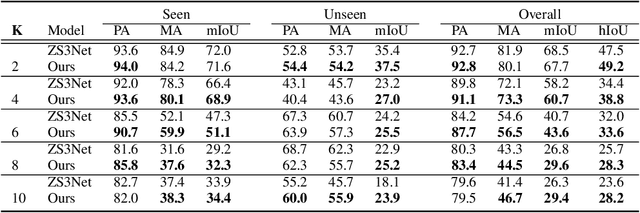
General purpose semantic segmentation relies on a backbone CNN network to extract discriminative features that help classify each image pixel into a 'seen' object class (ie., the object classes available during training) or a background class. Zero-shot semantic segmentation is a challenging task that requires a computer vision model to identify image pixels belonging to an object class which it has never seen before. Equipping a general purpose semantic segmentation model to separate image pixels of 'unseen' classes from the background remains an open challenge. Some recent models have approached this problem by fine-tuning the final pixel classification layer of a semantic segmentation model for a Zero-Shot setting, but struggle to learn discriminative features due to the lack of supervision. We propose a recursive training scheme to supervise the retraining of a semantic segmentation model for a zero-shot setting using a pseudo-feature representation. To this end, we propose a Zero-Shot Maximum Mean Discrepancy (ZS-MMD) loss that weighs high confidence outputs of the pixel classification layer as a pseudo-feature representation, and feeds it back to the generator. By closing-the-loop on the generator end, we provide supervision during retraining that in turn helps the model learn a more discriminative feature representation for 'unseen' classes. We show that using our recursive training and ZS-MMD loss, our proposed model achieves state-of-the-art performance on the Pascal-VOC 2012 dataset and Pascal-Context dataset.
BM3D vs 2-Layer ONN
Mar 04, 2021

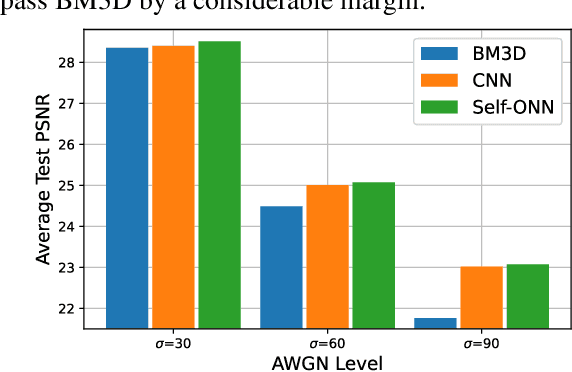

Despite their recent success on image denoising, the need for deep and complex architectures still hinders the practical usage of CNNs. Older but computationally more efficient methods such as BM3D remain a popular choice, especially in resource-constrained scenarios. In this study, we aim to find out whether compact neural networks can learn to produce competitive results as compared to BM3D for AWGN image denoising. To this end, we configure networks with only two hidden layers and employ different neuron models and layer widths for comparing the performance with BM3D across different AWGN noise levels. Our results conclusively show that the recently proposed self-organized variant of operational neural networks based on a generative neuron model (Self-ONNs) is not only a better choice as compared to CNNs, but also provide competitive results as compared to BM3D and even significantly surpass it for high noise levels.
Medical Image Segmentation Based on Multi-Modal Convolutional Neural Network: Study on Image Fusion Schemes
Nov 02, 2017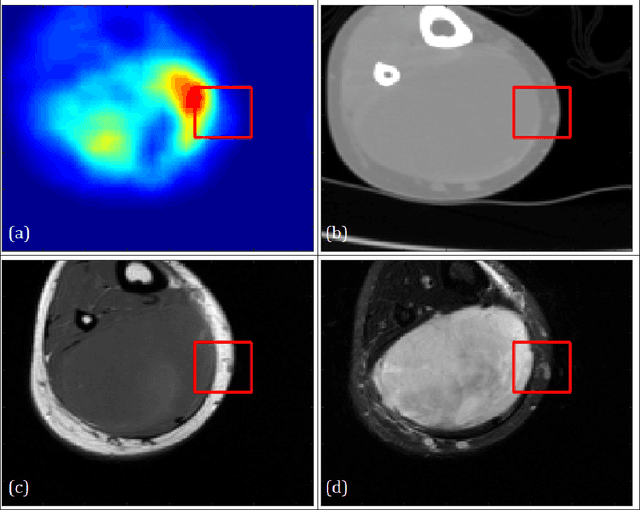
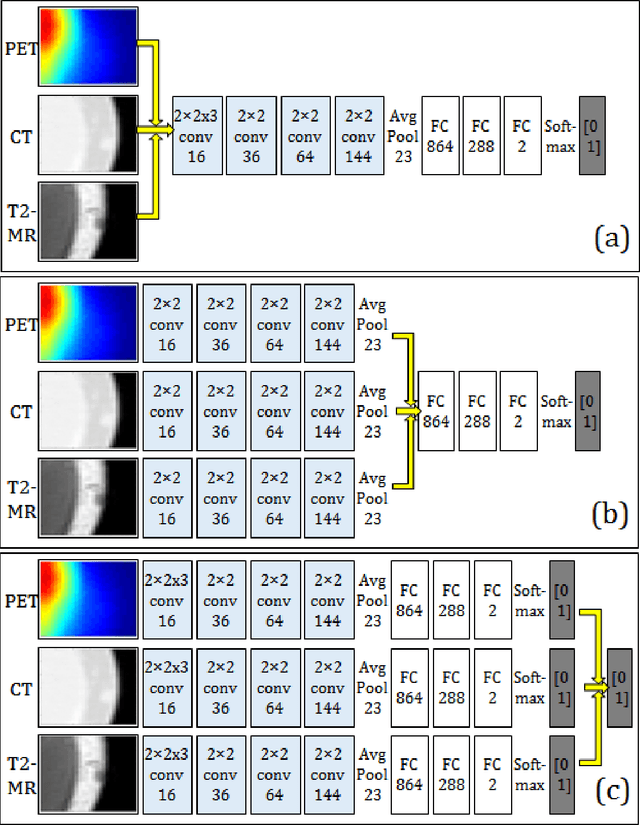
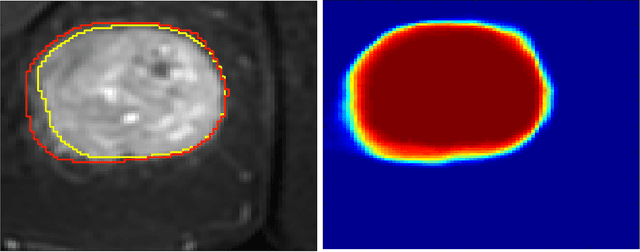
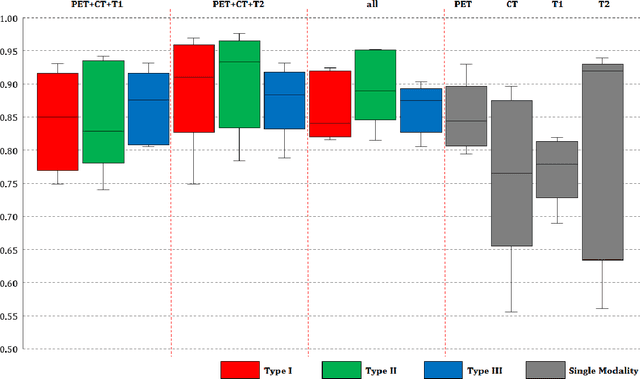
Image analysis using more than one modality (i.e. multi-modal) has been increasingly applied in the field of biomedical imaging. One of the challenges in performing the multimodal analysis is that there exist multiple schemes for fusing the information from different modalities, where such schemes are application-dependent and lack a unified framework to guide their designs. In this work we firstly propose a conceptual architecture for the image fusion schemes in supervised biomedical image analysis: fusing at the feature level, fusing at the classifier level, and fusing at the decision-making level. Further, motivated by the recent success in applying deep learning for natural image analysis, we implement the three image fusion schemes above based on the Convolutional Neural Network (CNN) with varied structures, and combined into a single framework. The proposed image segmentation framework is capable of analyzing the multi-modality images using different fusing schemes simultaneously. The framework is applied to detect the presence of soft tissue sarcoma from the combination of Magnetic Resonance Imaging (MRI), Computed Tomography (CT) and Positron Emission Tomography (PET) images. It is found from the results that while all the fusion schemes outperform the single-modality schemes, fusing at the feature level can generally achieve the best performance in terms of both accuracy and computational cost, but also suffers from the decreased robustness in the presence of large errors in any image modalities.
* Zhe Guo and Xiang Li contribute equally to this work
Pixel-wise Anomaly Detection in Complex Driving Scenes
Mar 09, 2021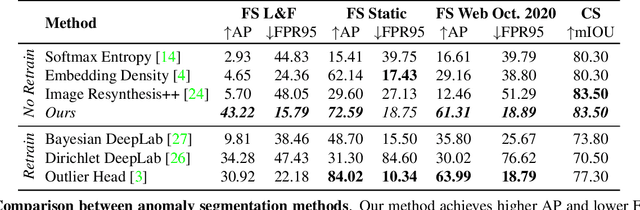
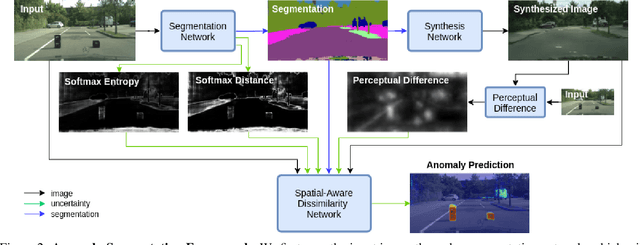
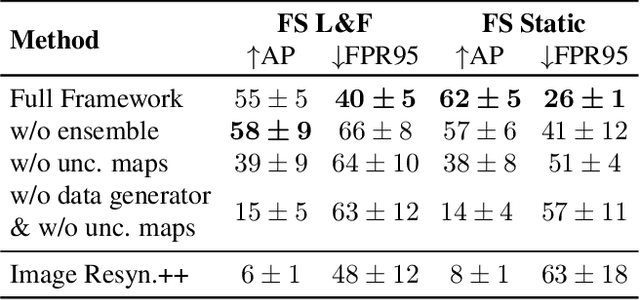
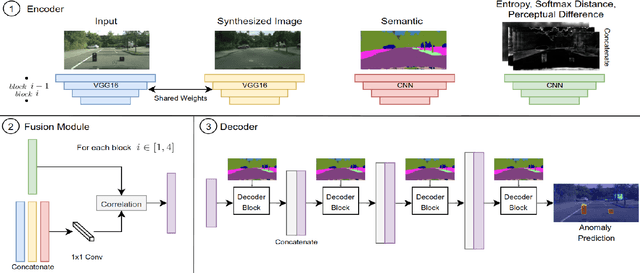
The inability of state-of-the-art semantic segmentation methods to detect anomaly instances hinders them from being deployed in safety-critical and complex applications, such as autonomous driving. Recent approaches have focused on either leveraging segmentation uncertainty to identify anomalous areas or re-synthesizing the image from the semantic label map to find dissimilarities with the input image. In this work, we demonstrate that these two methodologies contain complementary information and can be combined to produce robust predictions for anomaly segmentation. We present a pixel-wise anomaly detection framework that uses uncertainty maps to improve over existing re-synthesis methods in finding dissimilarities between the input and generated images. Our approach works as a general framework around already trained segmentation networks, which ensures anomaly detection without compromising segmentation accuracy, while significantly outperforming all similar methods. Top-2 performance across a range of different anomaly datasets shows the robustness of our approach to handling different anomaly instances.
Learning Transferable Visual Models From Natural Language Supervision
Feb 26, 2021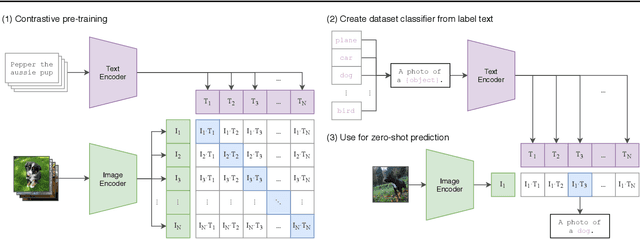
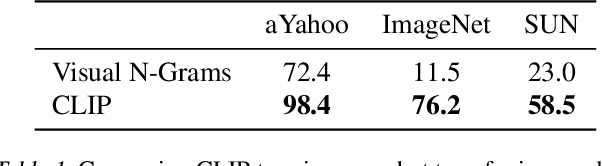
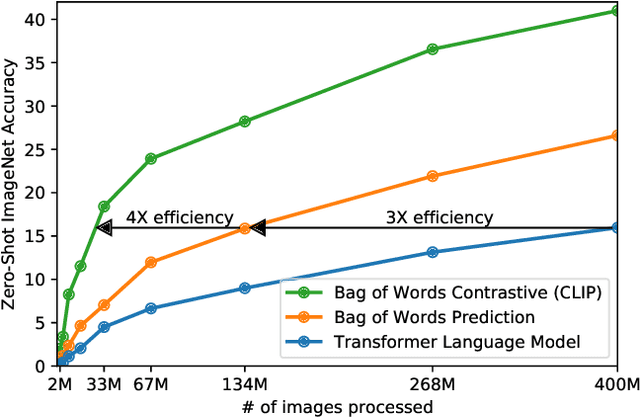
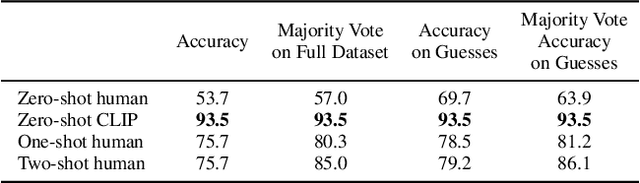
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual concept. Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision. We demonstrate that the simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks. We study the performance of this approach by benchmarking on over 30 different existing computer vision datasets, spanning tasks such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification. The model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need for any dataset specific training. For instance, we match the accuracy of the original ResNet-50 on ImageNet zero-shot without needing to use any of the 1.28 million training examples it was trained on. We release our code and pre-trained model weights at https://github.com/OpenAI/CLIP.
Argmax Flows and Multinomial Diffusion: Towards Non-Autoregressive Language Models
Feb 10, 2021


The field of language modelling has been largely dominated by autoregressive models, for which sampling is inherently difficult to parallelize. This paper introduces two new classes of generative models for categorical data such as language or image segmentation: Argmax Flows and Multinomial Diffusion. Argmax Flows are defined by a composition of a continuous distribution (such as a normalizing flow), and an argmax function. To optimize this model, we learn a probabilistic inverse for the argmax that lifts the categorical data to a continuous space. Multinomial Diffusion gradually adds categorical noise in a diffusion process, for which the generative denoising process is learned. We demonstrate that our models perform competitively on language modelling and modelling of image segmentation maps.
Mixed supervision for surface-defect detection: from weakly to fully supervised learning
Apr 20, 2021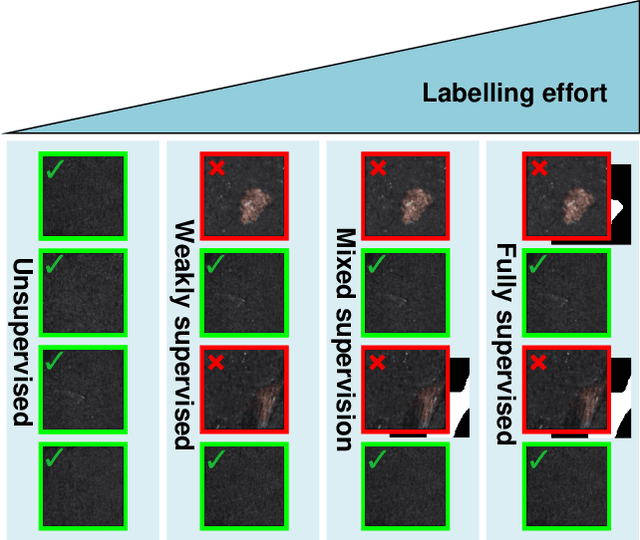
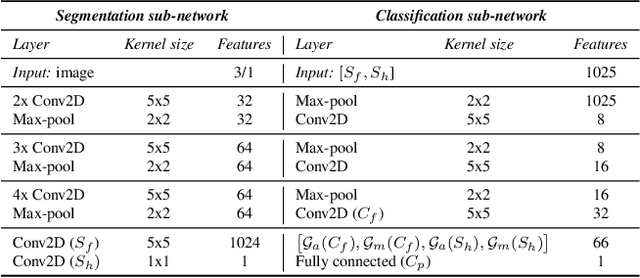
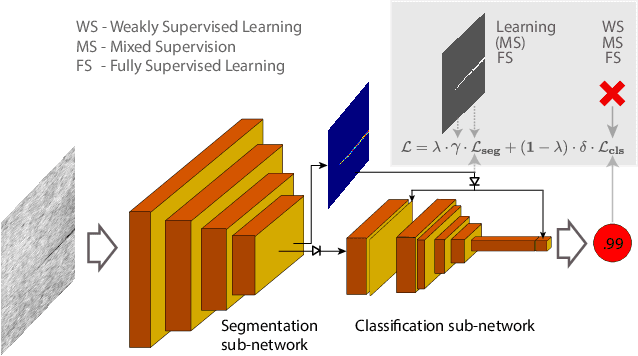
Deep-learning methods have recently started being employed for addressing surface-defect detection problems in industrial quality control. However, with a large amount of data needed for learning, often requiring high-precision labels, many industrial problems cannot be easily solved, or the cost of the solutions would significantly increase due to the annotation requirements. In this work, we relax heavy requirements of fully supervised learning methods and reduce the need for highly detailed annotations. By proposing a deep-learning architecture, we explore the use of annotations of different details ranging from weak (image-level) labels through mixed supervision to full (pixel-level) annotations on the task of surface-defect detection. The proposed end-to-end architecture is composed of two sub-networks yielding defect segmentation and classification results. The proposed method is evaluated on several datasets for industrial quality inspection: KolektorSDD, DAGM and Severstal Steel Defect. We also present a new dataset termed KolektorSDD2 with over 3000 images containing several types of defects, obtained while addressing a real-world industrial problem. We demonstrate state-of-the-art results on all four datasets. The proposed method outperforms all related approaches in fully supervised settings and also outperforms weakly-supervised methods when only image-level labels are available. We also show that mixed supervision with only a handful of fully annotated samples added to weakly labelled training images can result in performance comparable to the fully supervised model's performance but at a significantly lower annotation cost.
Assessment of Subjective and Objective Quality of Live Streaming Sports Videos
Jun 15, 2021
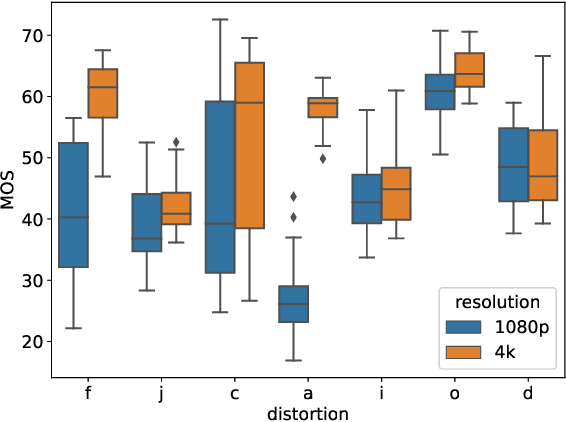
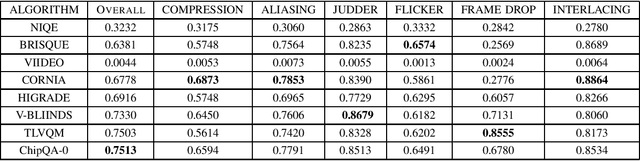
Video live streaming is gaining prevalence among video streaming services, especially for the delivery of popular sporting events. Many objective Video Quality Assessment (VQA) models have been developed to predict the perceptual quality of videos. Appropriate databases that exemplify the distortions encountered in live streaming videos are important to designing and learning objective VQA models. Towards making progress in this direction, we built a video quality database specifically designed for live streaming VQA research. The new video database is called the Laboratory for Image and Video Engineering (LIVE) Live stream Database. The LIVE Livestream Database includes 315 videos of 45 contents impaired by 6 types of distortions. We also performed a subjective quality study using the new database, whereby more than 12,000 human opinions were gathered from 40 subjects. We demonstrate the usefulness of the new resource by performing a holistic evaluation of the performance of current state-of-the-art (SOTA) VQA models. The LIVE Livestream database is being made publicly available for these purposes at https://live.ece.utexas.edu/research/LIVE_APV_Study/apv_index.html.
KonIQ-10k: An ecologically valid database for deep learning of blind image quality assessment
Oct 14, 2019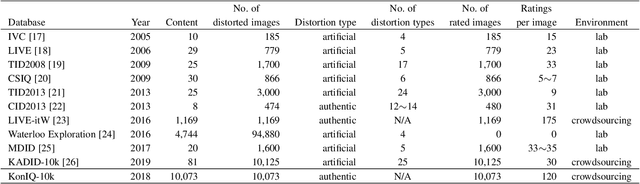
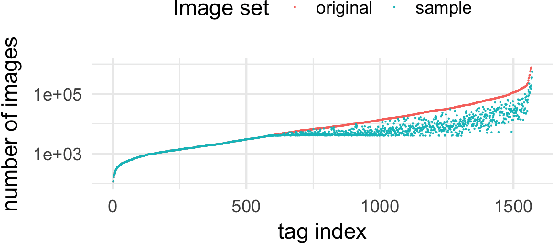

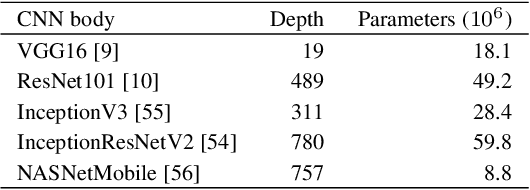
Deep learning methods for image quality assessment (IQA) are limited due to the small size of existing datasets. Extensive datasets require substantial resources both for generating publishable content, and annotating it accurately. We present a systematic and scalable approach to create KonIQ-10k, the largest IQA dataset to date consisting of 10,073 quality scored images. This is the first in-the-wild database aiming for ecological validity, with regard to the authenticity of distortions, the diversity of content, and quality-related indicators. Through the use of crowdsourcing, we obtained 1.2 million reliable quality ratings from 1,459 crowd workers, paving the way for more general IQA models. We propose a novel, deep learning model (KonCept512), to show an excellent generalization beyond the test set (0.921 SROCC), to the current state-of-the-art database LIVE-in-the-Wild (0.825 SROCC). The model derives its core performance from the InceptionResNet architecture, being trained at a higher resolution than previous models (512x384). A correlation analysis shows that KonCept512 performs similar to having 9 subjective scores for each test image.