 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Domain Adaptation for Semantic Segmentation by Content Transfer
Dec 23, 2020
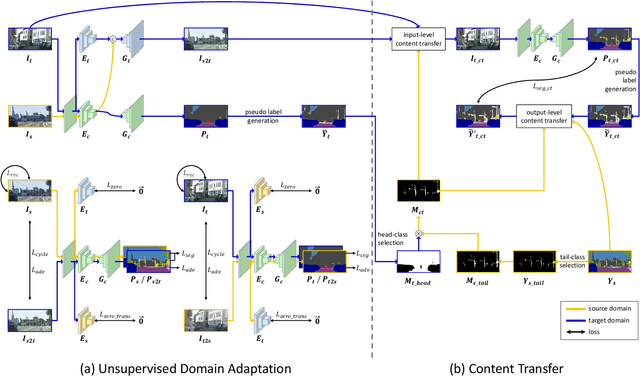
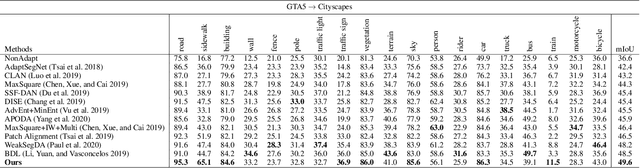
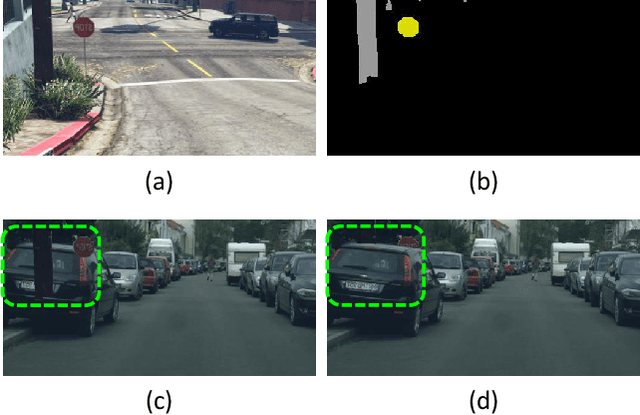
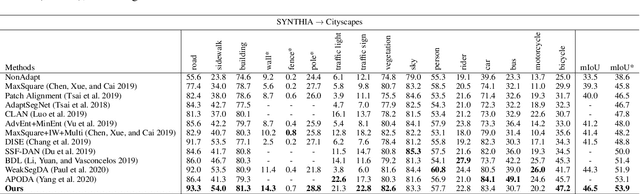
In this paper, we tackle the unsupervised domain adaptation (UDA) for semantic segmentation, which aims to segment the unlabeled real data using labeled synthetic data. The main problem of UDA for semantic segmentation relies on reducing the domain gap between the real image and synthetic image. To solve this problem, we focused on separating information in an image into content and style. Here, only the content has cues for semantic segmentation, and the style makes the domain gap. Thus, precise separation of content and style in an image leads to effect as supervision of real data even when learning with synthetic data. To make the best of this effect, we propose a zero-style loss. Even though we perfectly extract content for semantic segmentation in the real domain, another main challenge, the class imbalance problem, still exists in UDA for semantic segmentation. We address this problem by transferring the contents of tail classes from synthetic to real domain. Experimental results show that the proposed method achieves the state-of-the-art performance in semantic segmentation on the major two UDA settings.
Incorporating Orientations into End-to-end Driving Model for Steering Control
Mar 10, 2021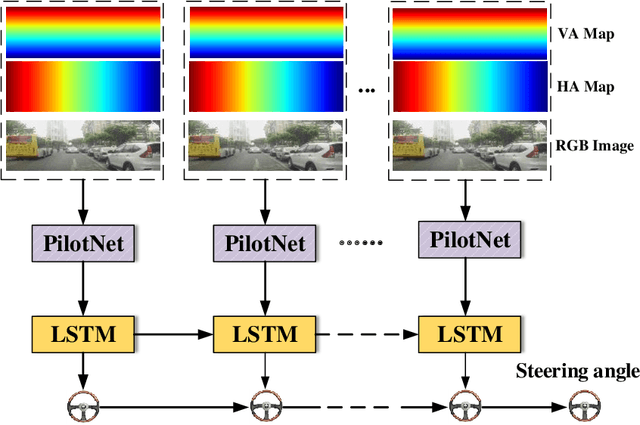
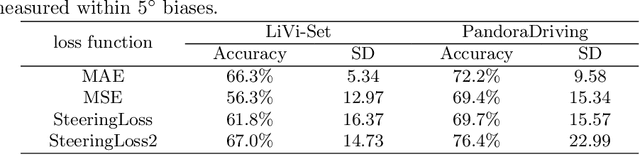
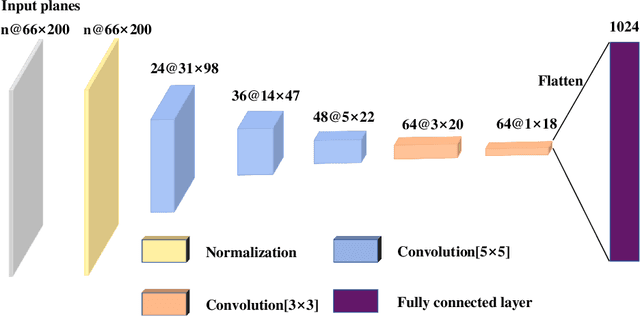

In this paper, we present a novel end-to-end deep neural network model for autonomous driving that takes monocular image sequence as input, and directly generates the steering control angle. Firstly, we model the end-to-end driving problem as a local path planning process. Inspired by the environmental representation in the classical planning algorithms(i.e. the beam curvature method), pixel-wise orientations are fed into the network to learn direction-aware features. Next, to handle the imbalanced distribution of steering values in training datasets, we propose an improvement on a cost-sensitive loss function named SteeringLoss2. Besides, we also present a new end-to-end driving dataset, which provides corresponding LiDAR and image sequences, as well as standard driving behaviors. Our dataset includes multiple driving scenarios, such as urban, country, and off-road. Numerous experiments are conducted on both public available LiVi-Set and our own dataset, and the results show that the model using our proposed methods can predict steering angle accurately.
A Generative Map for Image-based Camera Localization
Apr 16, 2019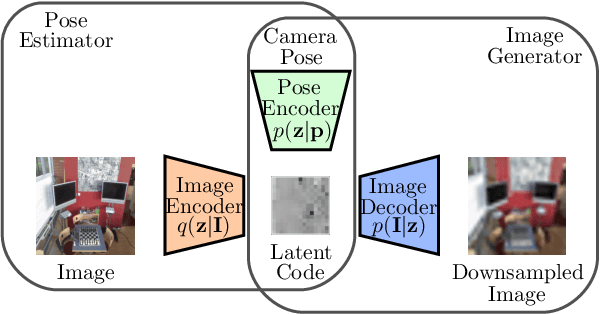
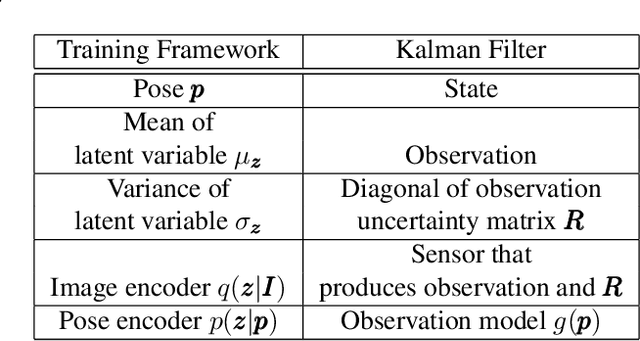
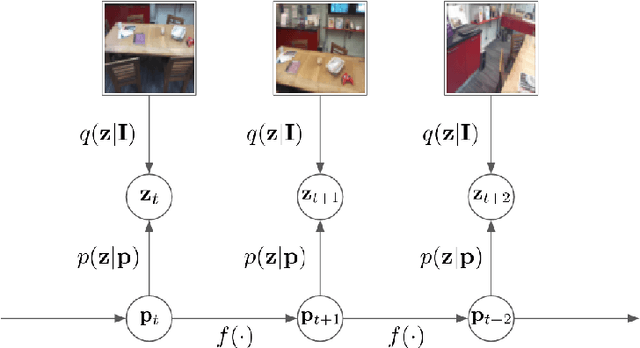
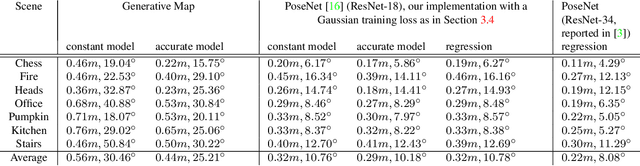
In image-based camera localization systems, information about the environment is usually stored in some representation, which can be referred to as a map. Conventionally, most maps are built upon hand-crafted features. Recently, neural networks have attracted attention as a data-driven map representation, and have shown promising results in visual localization. However, these neural network maps are generally hard to interpret by human. A readable map is not only accessible to humans, but also provides a way to be verified when the ground truth pose is unavailable. To tackle this problem, we propose Generative Map, a new framework for learning human-readable neural network maps, by combining a generative model with the Kalman filter, which also allows it to incorporate additional sensor information such as stereo visual odometry. For evaluation, we use real world images from the 7-Scenes and Oxford RobotCar datasets. We demonstrate that our Generative Map can be queried with a pose of interest from the test sequence to predict an image, which closely resembles the true scene. For localization, we show that Generative Map achieves comparable performance with current regression models. Moreover, our framework is trained completely from scratch, unlike regression models which rely on large ImageNet pretrained networks.
Spectrum Congruency of Multiscale Local Patches for Edge Detection
Mar 10, 2021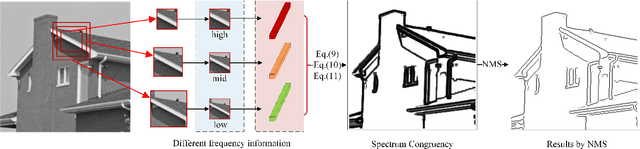

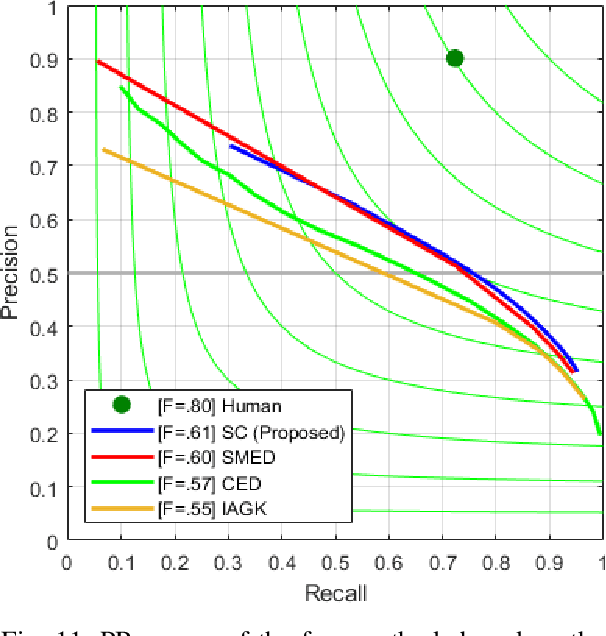
This paper proposes a novel feature called spectrum congruency for describing edges in images. The spectrum congruency is a generalization of the phase congruency, which depicts how much each Fourier components of the image are congruent in phase. Instead of using fixed bases in phase congruency, the spectrum congruency measures the congruency of the energy distribution of multiscale patches in a data-driven transform domain, which is more adaptable to the input images. Multiscale image patches are used to acquire different frequency components for modeling the local energy and amplitude. The spectrum congruency coincides nicely with human visions of perceiving features and provides a more reliable way of detecting edges. Unlike most existing differential-based multiscale edge detectors which simply combine the multiscale information, our method focuses on exploiting the correlation of the multiscale patches based on their local energy. We test our proposed method on synthetic and real images, and the results demonstrate that our approach is practical and highly robust to noise.
Discovering Relationships between Object Categories via Universal Canonical Maps
Jun 17, 2021



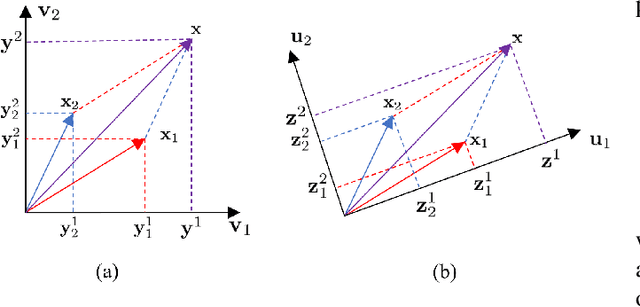
We tackle the problem of learning the geometry of multiple categories of deformable objects jointly. Recent work has shown that it is possible to learn a unified dense pose predictor for several categories of related objects. However, training such models requires to initialize inter-category correspondences by hand. This is suboptimal and the resulting models fail to maintain correct correspondences as individual categories are learned. In this paper, we show that improved correspondences can be learned automatically as a natural byproduct of learning category-specific dense pose predictors. To do this, we express correspondences between different categories and between images and categories using a unified embedding. Then, we use the latter to enforce two constraints: symmetric inter-category cycle consistency and a new asymmetric image-to-category cycle consistency. Without any manual annotations for the inter-category correspondences, we obtain state-of-the-art alignment results, outperforming dedicated methods for matching 3D shapes. Moreover, the new model is also better at the task of dense pose prediction than prior work.
OIAD: One-for-all Image Anomaly Detection with Disentanglement Learning
Jan 18, 2020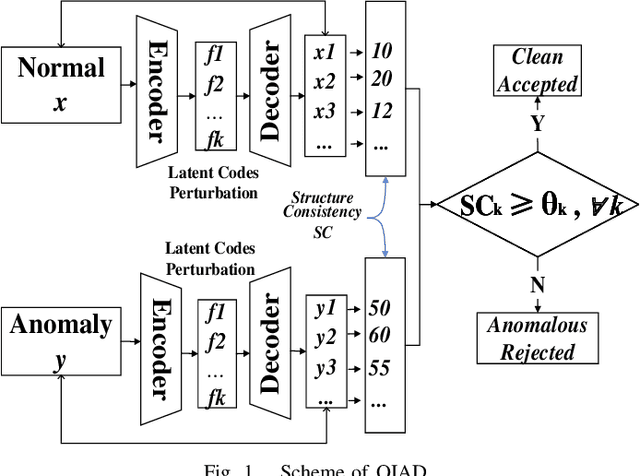
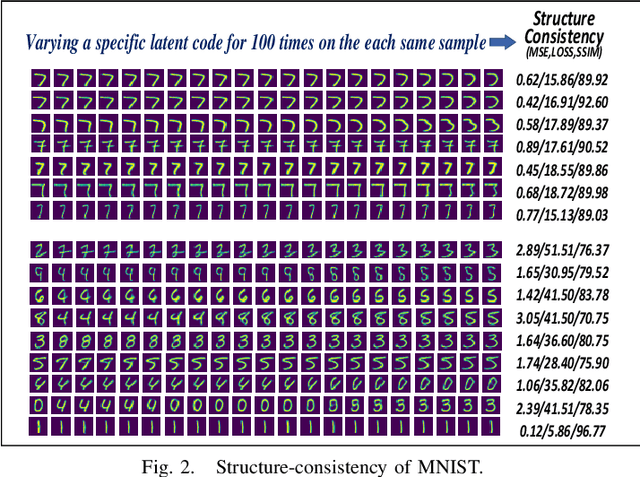
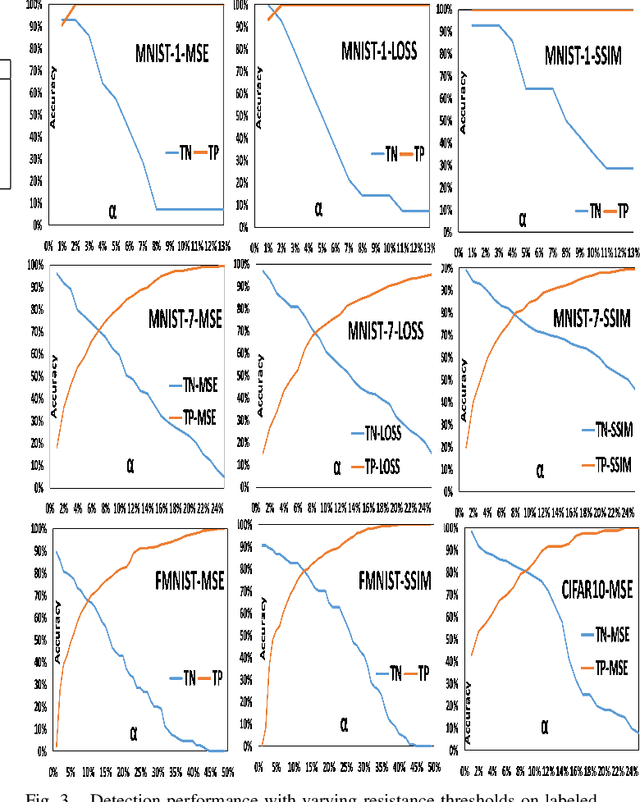
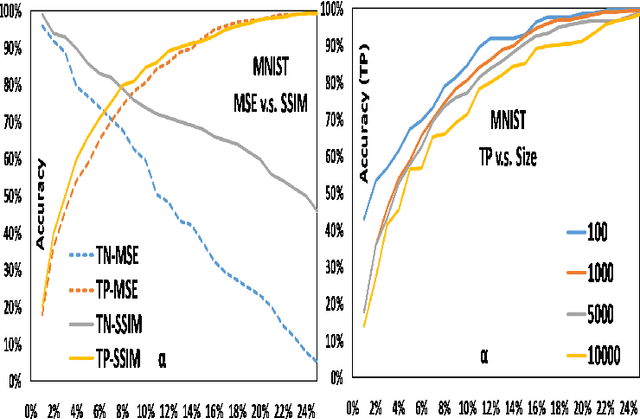
Anomaly detection aims to recognize samples with anomalous and unusual patterns with respect to a set of normal data, which is significant for numerous domain applications, e.g. in industrial inspection, medical imaging, and security enforcement. There are two key research challenges associated with existing anomaly detention approaches: (1) many of them perform well on low-dimensional problems however the performance on high-dimensional instances is limited, such as images; (2) many of them depend on often still rely on traditional supervised approaches and manual engineering of features, while the topic has not been fully explored yet using modern deep learning approaches, even when the well-label samples are limited. In this paper, we propose a One-for-all Image Anomaly Detection system (OIAD) based on disentangled learning using only clean samples. Our key insight is that the impact of small perturbation on the latent representation can be bounded for normal samples while anomaly images are usually outside such bounded intervals, called structure consistency. We implement this idea and evaluate its performance for anomaly detention. Our experiments with three datasets show that OIAD can detect over $90\%$ of anomalies while maintaining a high low false alarm rate. It can also detect suspicious samples from samples labeled as clean, coincided with what humans would deem unusual.
SECANT: Self-Expert Cloning for Zero-Shot Generalization of Visual Policies
Jun 17, 2021
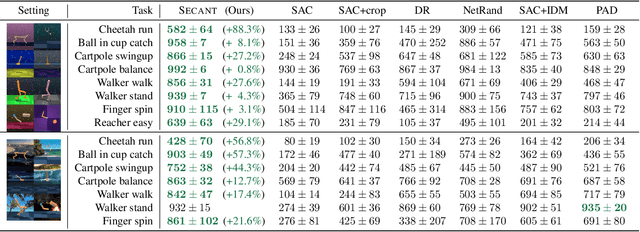
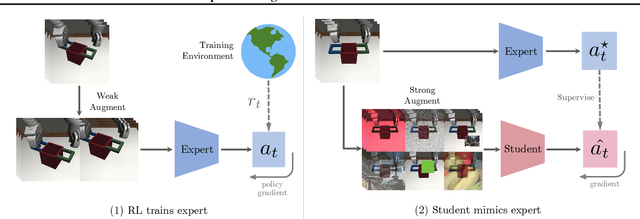
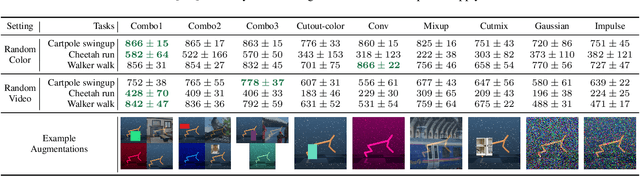
Generalization has been a long-standing challenge for reinforcement learning (RL). Visual RL, in particular, can be easily distracted by irrelevant factors in high-dimensional observation space. In this work, we consider robust policy learning which targets zero-shot generalization to unseen visual environments with large distributional shift. We propose SECANT, a novel self-expert cloning technique that leverages image augmentation in two stages to decouple robust representation learning from policy optimization. Specifically, an expert policy is first trained by RL from scratch with weak augmentations. A student network then learns to mimic the expert policy by supervised learning with strong augmentations, making its representation more robust against visual variations compared to the expert. Extensive experiments demonstrate that SECANT significantly advances the state of the art in zero-shot generalization across 4 challenging domains. Our average reward improvements over prior SOTAs are: DeepMind Control (+26.5%), robotic manipulation (+337.8%), vision-based autonomous driving (+47.7%), and indoor object navigation (+15.8%). Code release and video are available at https://linxifan.github.io/secant-site/.
Automatic Segmentation of the Prostate on 3D Trans-rectal Ultrasound Images using Statistical Shape Models and Convolutional Neural Networks
Jun 17, 2021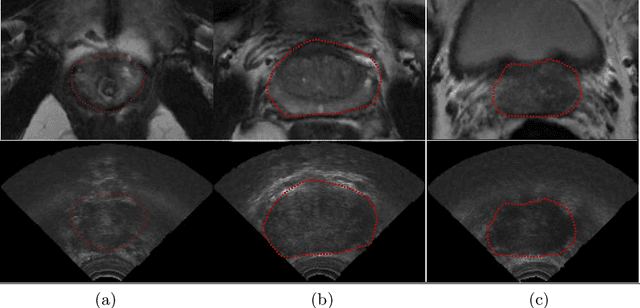
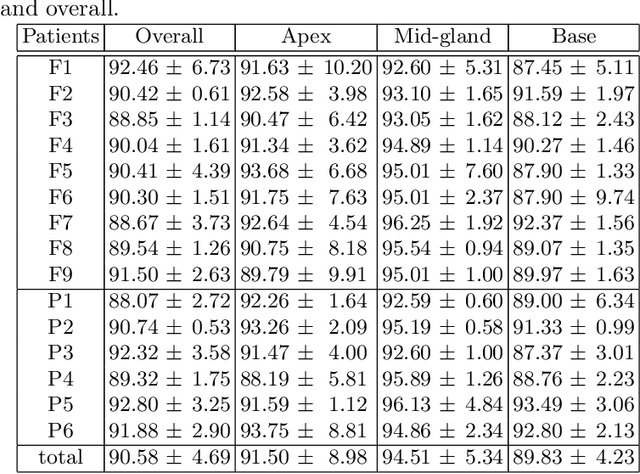
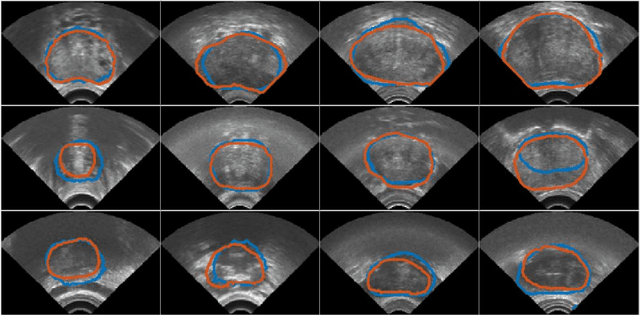
In this work we propose to segment the prostate on a challenging dataset of trans-rectal ultrasound (TRUS) images using convolutional neural networks (CNNs) and statistical shape models (SSMs). TRUS is commonly used for a number of image-guided interventions on the prostate. Fast and accurate segmentation on the organ in these images is crucial to planning and fusion with other modalities such as magnetic resonance images (MRIs) . However, TRUS has limited soft tissue contrast and signal to noise ratio which makes the task of segmenting the prostate challenging and subject to inter-observer and intra-observer variability. This is especially problematic at the base and apex where the gland boundary is hard to define. In this paper, we aim to tackle this problem by taking advantage of shape priors learnt on an MR dataset which has higher soft tissue contrast allowing the prostate to be contoured more accurately. We use this shape prior in combination with a prostate tissue probability map computed by a CNN for segmentation.
A Unified Conditional Disentanglement Framework for Multimodal Brain MR Image Translation
Jan 14, 2021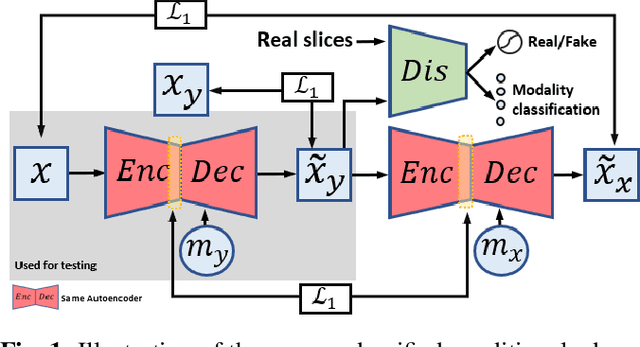
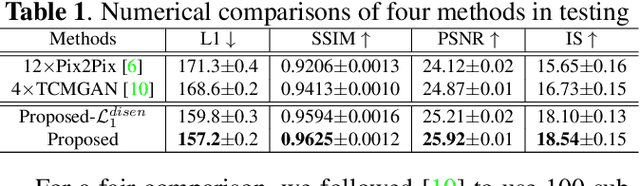
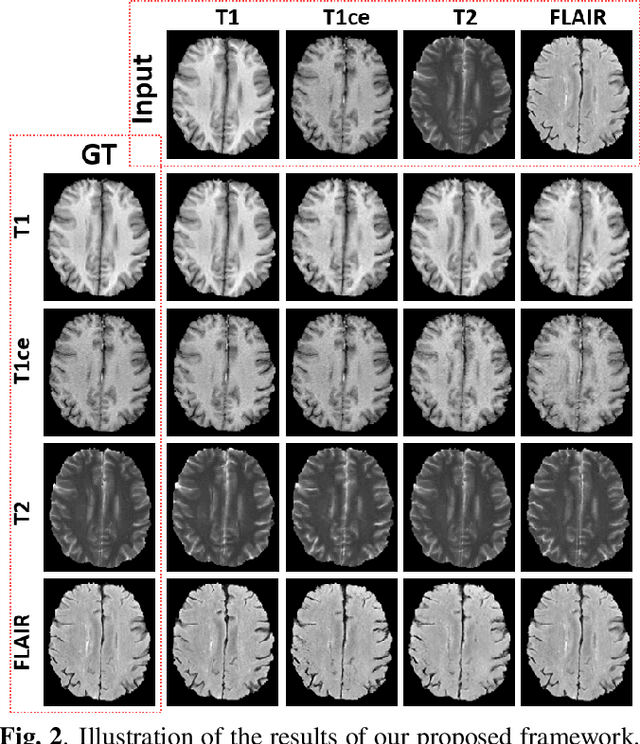
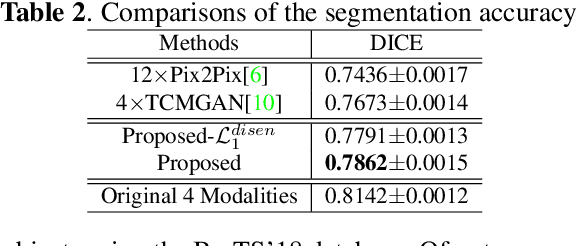
Multimodal MRI provides complementary and clinically relevant information to probe tissue condition and to characterize various diseases. However, it is often difficult to acquire sufficiently many modalities from the same subject due to limitations in study plans, while quantitative analysis is still demanded. In this work, we propose a unified conditional disentanglement framework to synthesize any arbitrary modality from an input modality. Our framework hinges on a cycle-constrained conditional adversarial training approach, where it can extract a modality-invariant anatomical feature with a modality-agnostic encoder and generate a target modality with a conditioned decoder. We validate our framework on four MRI modalities, including T1-weighted, T1 contrast enhanced, T2-weighted, and FLAIR MRI, from the BraTS'18 database, showing superior performance on synthesis quality over the comparison methods. In addition, we report results from experiments on a tumor segmentation task carried out with synthesized data.
Argmax Flows and Multinomial Diffusion: Towards Non-Autoregressive Language Models
Feb 10, 2021


The field of language modelling has been largely dominated by autoregressive models, for which sampling is inherently difficult to parallelize. This paper introduces two new classes of generative models for categorical data such as language or image segmentation: Argmax Flows and Multinomial Diffusion. Argmax Flows are defined by a composition of a continuous distribution (such as a normalizing flow), and an argmax function. To optimize this model, we learn a probabilistic inverse for the argmax that lifts the categorical data to a continuous space. Multinomial Diffusion gradually adds categorical noise in a diffusion process, for which the generative denoising process is learned. We demonstrate that our models perform competitively on language modelling and modelling of image segmentation maps.