 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-supervised Change Detection in Multi-view Remote Sensing Images
Mar 10, 2021
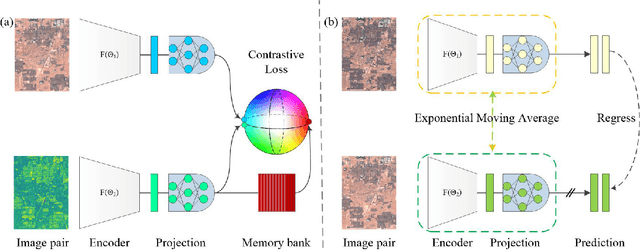
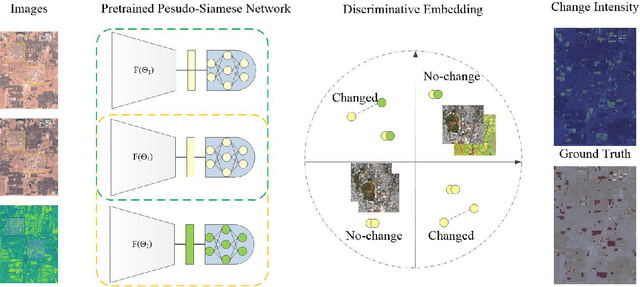
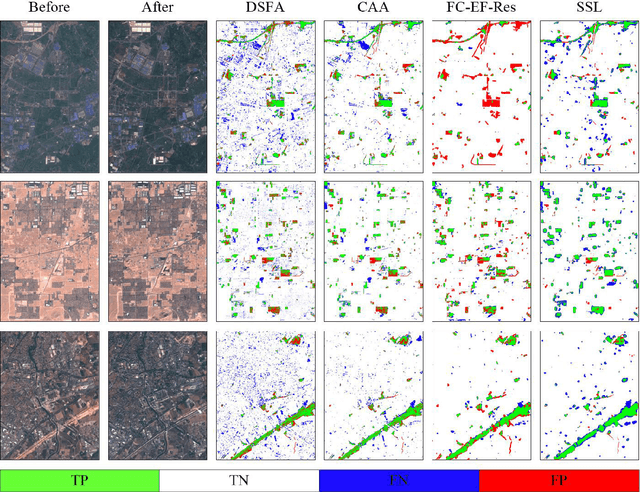
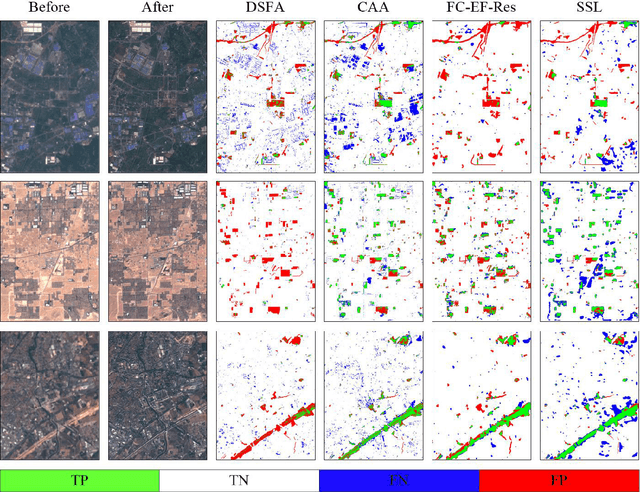
The vast amount of unlabeled multi-temporal and multi-sensor remote sensing data acquired by the many Earth Observation satellites present a challenge for change detection. Recently, many generative model-based methods have been proposed for remote sensing image change detection on such unlabeled data. However, the high diversities in the learned features weaken the discrimination of the relevant change indicators in unsupervised change detection tasks. Moreover, these methods lack research on massive archived images. In this work, a self-supervised change detection approach based on an unlabeled multi-view setting is proposed to overcome this limitation. This is achieved by the use of a multi-view contrastive loss and an implicit contrastive strategy in the feature alignment between multi-view images. In this approach, a pseudo-Siamese network is trained to regress the output between its two branches pre-trained in a contrastive way on a large dataset of multi-temporal homogeneous or heterogeneous image patches. Finally, the feature distance between the outputs of the two branches is used to define a change measure, which can be analyzed by thresholding to get the final binary change map. Experiments are carried out on five homogeneous and heterogeneous remote sensing image datasets. The proposed SSL approach is compared with other supervised and unsupervised state-of-the-art change detection methods. Results demonstrate both improvements over state-of-the-art unsupervised methods and that the proposed SSL approach narrows the gap between unsupervised and supervised change detection.
Warp Consistency for Unsupervised Learning of Dense Correspondences
Apr 08, 2021
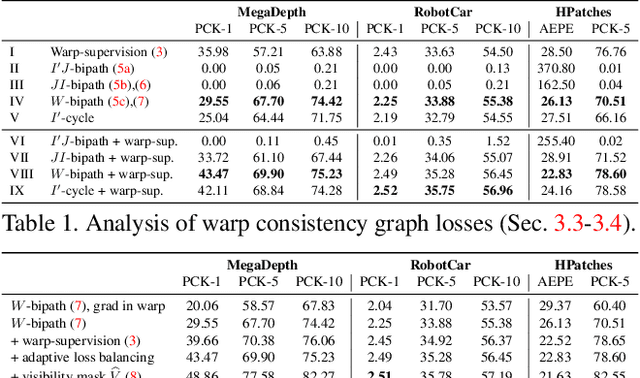

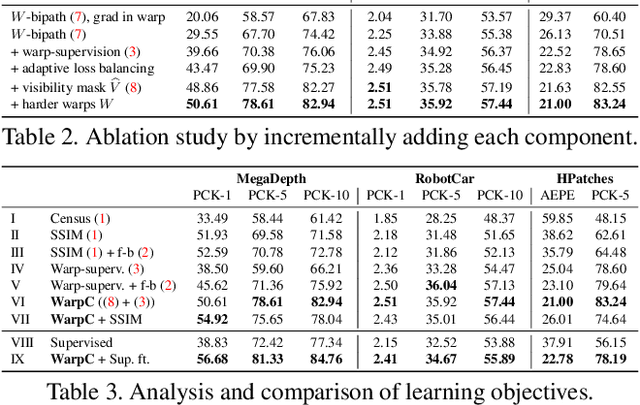
The key challenge in learning dense correspondences lies in the lack of ground-truth matches for real image pairs. While photometric consistency losses provide unsupervised alternatives, they struggle with large appearance changes, which are ubiquitous in geometric and semantic matching tasks. Moreover, methods relying on synthetic training pairs often suffer from poor generalisation to real data. We propose Warp Consistency, an unsupervised learning objective for dense correspondence regression. Our objective is effective even in settings with large appearance and view-point changes. Given a pair of real images, we first construct an image triplet by applying a randomly sampled warp to one of the original images. We derive and analyze all flow-consistency constraints arising between the triplet. From our observations and empirical results, we design a general unsupervised objective employing two of the derived constraints. We validate our warp consistency loss by training three recent dense correspondence networks for the geometric and semantic matching tasks. Our approach sets a new state-of-the-art on several challenging benchmarks, including MegaDepth, RobotCar and TSS. Code and models will be released at https://github.com/PruneTruong/DenseMatching.
HPRNet: Hierarchical Point Regression for Whole-Body Human Pose Estimation
Jun 08, 2021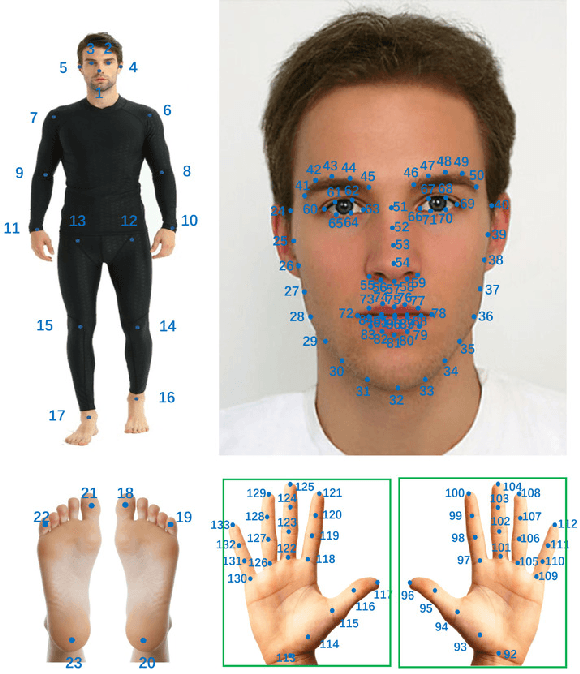

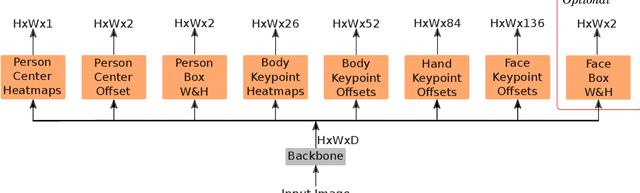

In this paper, we present a new bottom-up one-stage method for whole-body pose estimation, which we name "hierarchical point regression," or HPRNet for short, referring to the network that implements this method. To handle the scale variance among different body parts, we build a hierarchical point representation of body parts and jointly regress them. Unlike the existing two-stage methods, our method predicts whole-body pose in a constant time independent of the number of people in an image. On the COCO WholeBody dataset, HPRNet significantly outperforms all previous bottom-up methods on the keypoint detection of all whole-body parts (i.e. body, foot, face and hand); it also achieves state-of-the-art results in the face (75.4 AP) and hand (50.4 AP) keypoint detection. Code and models are available at https://github.com/nerminsamet/HPRNet.git.
Atrous Residual Interconnected Encoder to Attention Decoder Framework for Vertebrae Segmentation via 3D Volumetric CT Images
Apr 08, 2021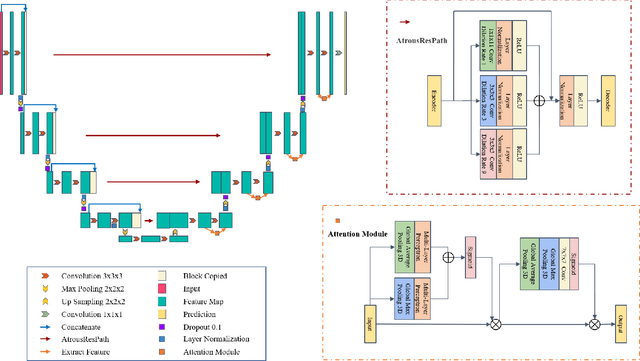

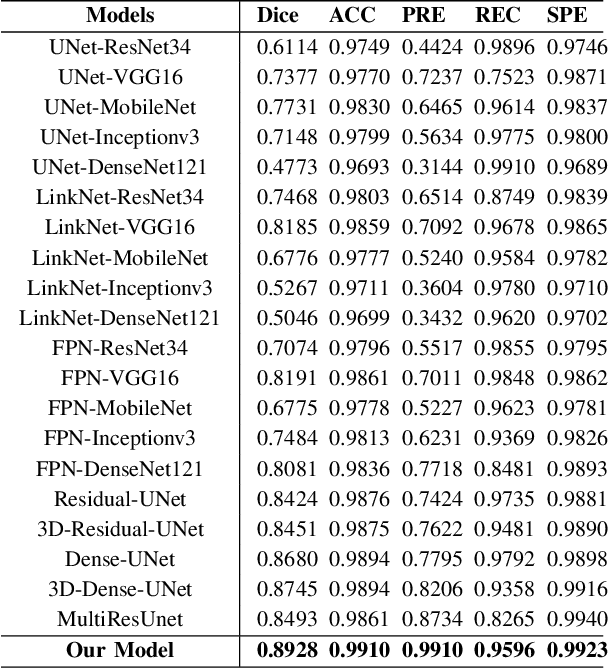
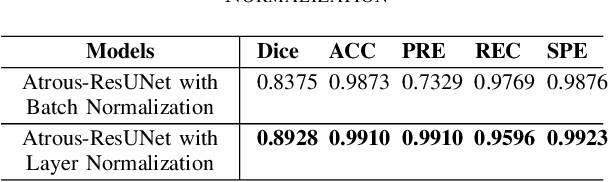
Automatic medical image segmentation based on Computed Tomography (CT) has been widely applied for computer-aided surgery as a prerequisite. With the development of deep learning technologies, deep convolutional neural networks (DCNNs) have shown robust performance in automated semantic segmentation of medical images. However, semantic segmentation algorithms based on DCNNs still meet the challenges of feature loss between encoder and decoder, multi-scale object, restricted field of view of filters, and lack of medical image data. This paper proposes a novel algorithm for automated vertebrae segmentation via 3D volumetric spine CT images. The proposed model is based on the structure of encoder to decoder, using layer normalization to optimize mini-batch training performance. To address the concern of the information loss between encoder and decoder, we designed an Atrous Residual Path to pass more features from encoder to decoder instead of an easy shortcut connection. The proposed model also applied the attention module in the decoder part to extract features from variant scales. The proposed model is evaluated on a publicly available dataset by a variety of metrics. The experimental results show that our model achieves competitive performance compared with other state-of-the-art medical semantic segmentation methods.
Integrating Novelty Detection Capabilities with MSL Mastcam Operations to Enhance Data Analysis
Mar 23, 2021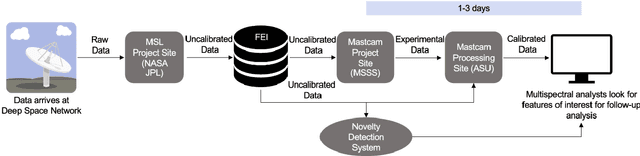



While innovations in scientific instrumentation have pushed the boundaries of Mars rover mission capabilities, the increase in data complexity has pressured Mars Science Laboratory (MSL) and future Mars rover operations staff to quickly analyze complex data sets to meet progressively shorter tactical and strategic planning timelines. MSLWEB is an internal data tracking tool used by operations staff to perform first pass analysis on MSL image sequences, a series of products taken by the Mast camera, Mastcam. Mastcam's multiband multispectral image sequences require more complex analysis compared to standard 3-band RGB images. Typically, these are analyzed using traditional methods to identify unique features within the sequence. Given the short time frame of tactical planning in which downlinked images might need to be analyzed (within 5-10 hours before the next uplink), there exists a need to triage analysis time to focus on the most important sequences and parts of a sequence. We address this need by creating products for MSLWEB that use novelty detection to help operations staff identify unusual data that might be diagnostic of new or atypical compositions or mineralogies detected within an imaging scene. This was achieved in two ways: 1) by creating products for each sequence to identify novel regions in the image, and 2) by assigning multispectral sequences a sortable novelty score. These new products provide colorized heat maps of inferred novelty that operations staff can use to rapidly review downlinked data and focus their efforts on analyzing potentially new kinds of diagnostic multispectral signatures. This approach has the potential to guide scientists to new discoveries by quickly drawing their attention to often subtle variations not detectable with simple color composites.
Mixed-Resolution Image Representation and Compression with Convolutional Neural Networks
Aug 01, 2018
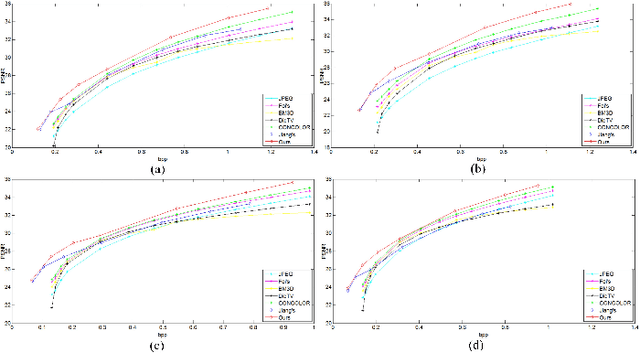
In this paper, we propose an end-to-end mixed-resolution image compression framework with convolutional neural networks. Firstly, given one input image, feature description neural network (FDNN) is used to generate a new representation of this image, so that this image representation can be more efficiently compressed by standard codec, as compared to the input image. Furthermore, we use post-processing neural network (PPNN) to remove the coding artifacts caused by quantization of codec. Secondly, low-resolution image representation is adopted for high efficiency compression in terms of most of bit spent by image's structures under low bit-rate. However, more bits should be assigned to image details in the high-resolution, when most of structures have been kept after compression at the high bit-rate. This comes from a fact that the low-resolution image representation can't burden more information than high-resolution representation beyond a certain bit-rate. Finally, to resolve the problem of error back-propagation from the PPNN network to the FDNN network, we introduce to learn a virtual codec neural network to imitate two continuous procedures of standard compression and post-processing. The objective experimental results have demonstrated the proposed method has a large margin improvement, when comparing with several state-of-the-art approaches.
Fine tuning U-Net for ultrasound image segmentation: which layers?
Feb 19, 2020


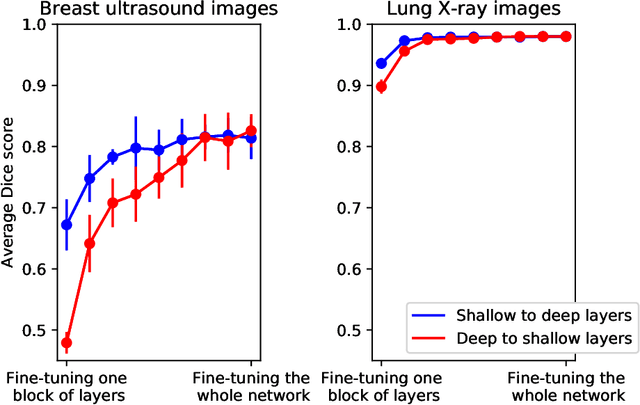
Fine-tuning a network which has been trained on a large dataset is an alternative to full training in order to overcome the problem of scarce and expensive data in medical applications. While the shallow layers of the network are usually kept unchanged, deeper layers are modified according to the new dataset. This approach may not work for ultrasound images due to their drastically different appearance. In this study, we investigated the effect of fine-tuning different layers of a U-Net which was trained on segmentation of natural images in breast ultrasound image segmentation. Tuning the contracting part and fixing the expanding part resulted in substantially better results compared to fixing the contracting part and tuning the expanding part. Furthermore, we showed that starting to fine-tune the U-Net from the shallow layers and gradually including more layers will lead to a better performance compared to fine-tuning the network from the deep layers moving back to shallow layers. We did not observe the same results on segmentation of X-ray images, which have different salient features compared to ultrasound, it may therefore be more appropriate to fine-tune the shallow layers rather than deep layers. Shallow layers learn lower level features (including speckle pattern, and probably the noise and artifact properties) which are critical in automatic segmentation in this modality.
DMSANet: Dual Multi Scale Attention Network
Jun 13, 2021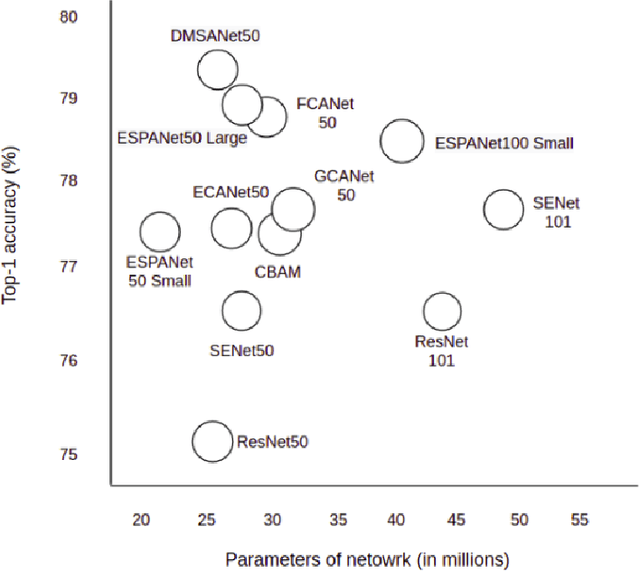
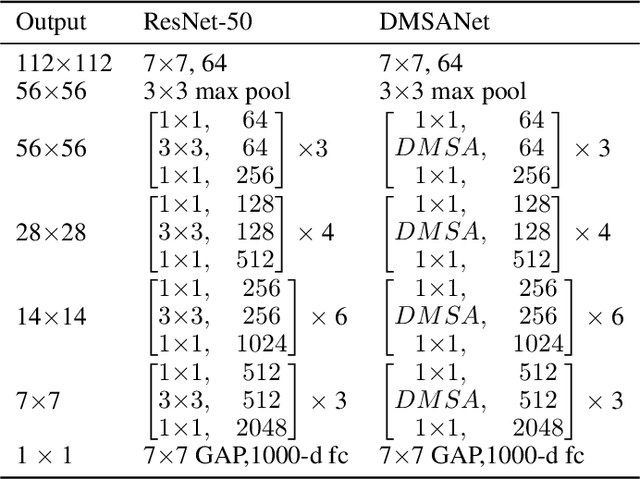
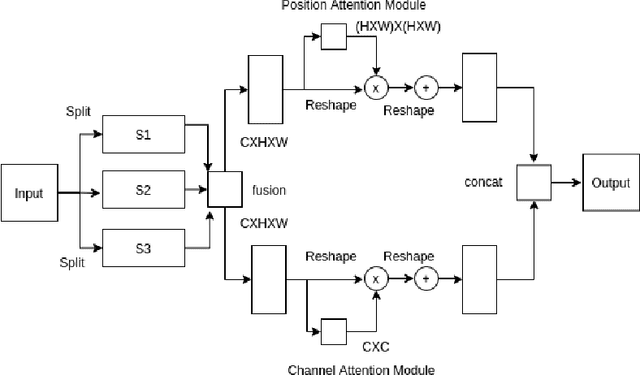
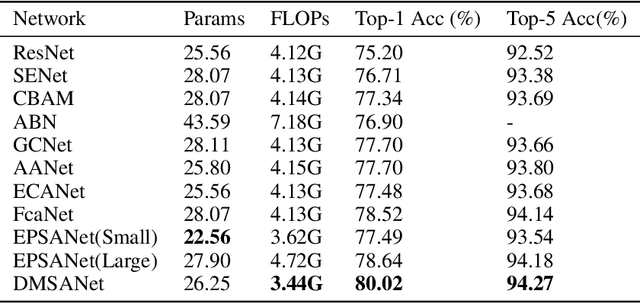
Attention mechanism of late has been quite popular in the computer vision community. A lot of work has been done to improve the performance of the network, although almost always it results in increased computational complexity. In this paper, we propose a new attention module that not only achieves the best performance but also has lesser parameters compared to most existing models. Our attention module can easily be integrated with other convolutional neural networks because of its lightweight nature. The proposed network named Dual Multi Scale Attention Network (DMSANet) is comprised of two parts: the first part is used to extract features at various scales and aggregate them, the second part uses spatial and channel attention modules in parallel to adaptively integrate local features with their global dependencies. We benchmark our network performance for Image Classification on ImageNet dataset, Object Detection and Instance Segmentation both on MS COCO dataset.
The Randomness of Input Data Spaces is an A Priori Predictor for Generalization
Jun 08, 2021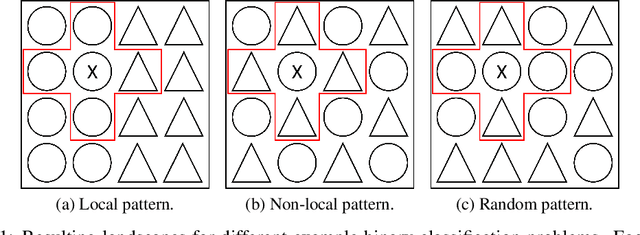
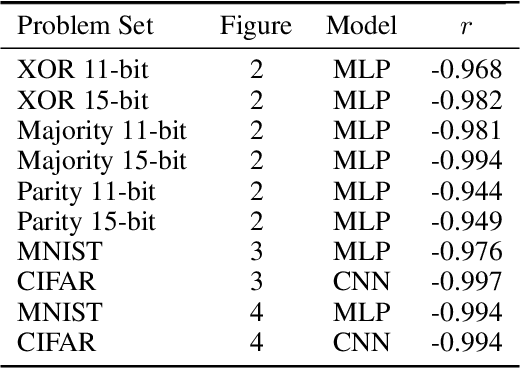
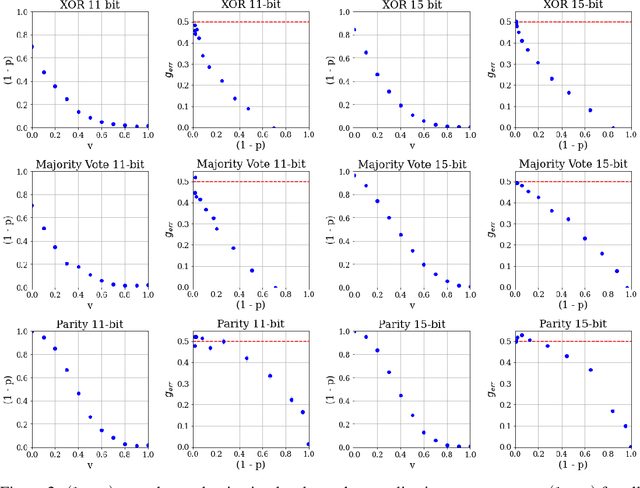
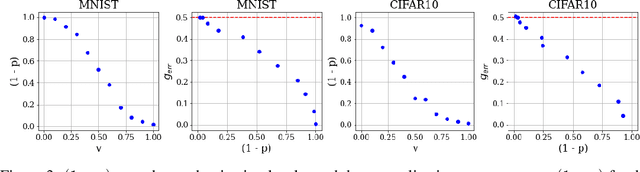
Over-parameterized models can perfectly learn various types of data distributions, however, generalization error is usually lower for real data in comparison to artificial data. This suggests that the properties of data distributions have an impact on generalization capability. This work focuses on the search space defined by the input data and assumes that the correlation between labels of neighboring input values influences generalization. If correlation is low, the randomness of the input data space is high leading to high generalization error. We suggest to measure the randomness of an input data space using Maurer's universal. Results for synthetic classification tasks and common image classification benchmarks (MNIST, CIFAR10, and Microsoft's cats vs. dogs data set) find a high correlation between the randomness of input data spaces and the generalization error of deep neural networks for binary classification problems.
Improving Image Classification Robustness through Selective CNN-Filters Fine-Tuning
Apr 08, 2019

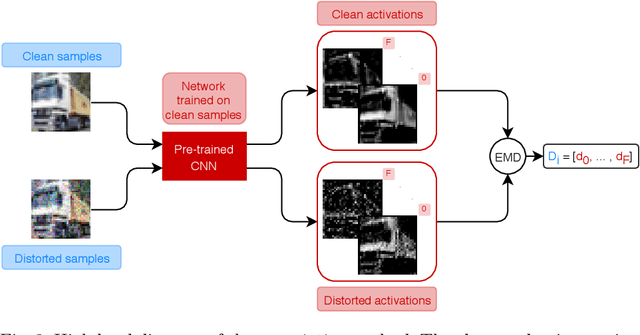
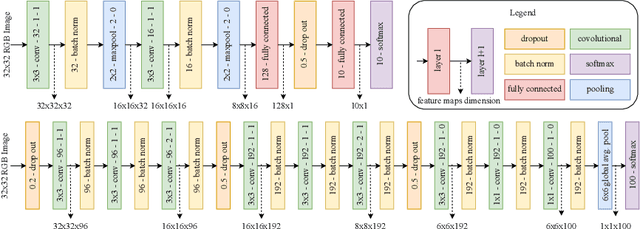
Image quality plays a big role in CNN-based image classification performance. Fine-tuning the network with distorted samples may be too costly for large networks. To solve this issue, we propose a transfer learning approach optimized to keep into account that in each layer of a CNN some filters are more susceptible to image distortion than others. Our method identifies the most susceptible filters and applies retraining only to the filters that show the highest activation maps distance between clean and distorted images. Filters are ranked using the Borda count election method and then only the most affected filters are fine-tuned. This significantly reduces the number of parameters to retrain. We evaluate this approach on the CIFAR-10 and CIFAR-100 datasets, testing it on two different models and two different types of distortion. Results show that the proposed transfer learning technique recovers most of the lost performance due to input data distortion, at a considerably faster pace with respect to existing methods, thanks to the reduced number of parameters to fine-tune. When few noisy samples are provided for training, our filter-level fine tuning performs particularly well, also outperforming state of the art layer-level transfer learning approaches.