 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AI for Calcium Scoring
May 24, 2021
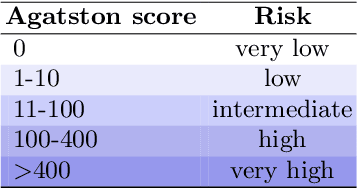
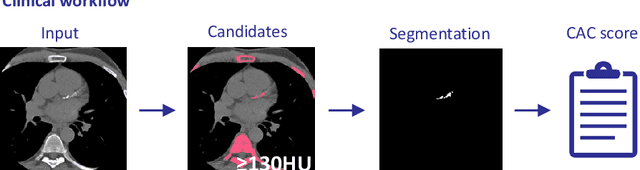
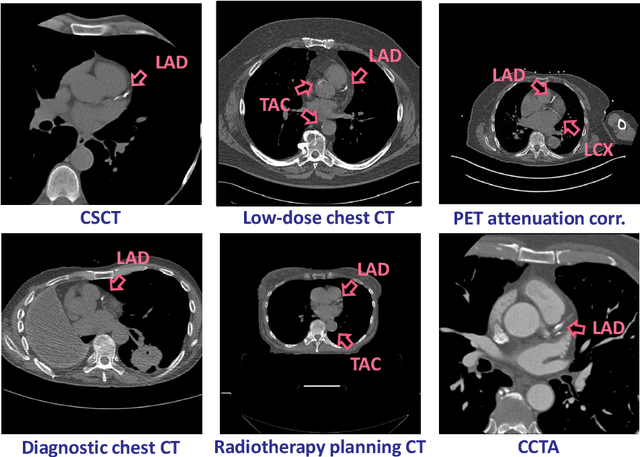
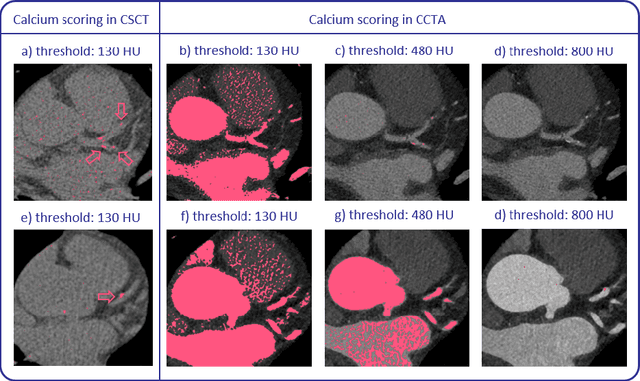
Calcium scoring, a process in which arterial calcifications are detected and quantified in CT, is valuable in estimating the risk of cardiovascular disease events. Especially when used to quantify the extent of calcification in the coronary arteries, it is a strong and independent predictor of coronary heart disease events. Advances in artificial intelligence (AI)-based image analysis have produced a multitude of automatic calcium scoring methods. While most early methods closely follow standard calcium scoring accepted in clinic, recent approaches extend this procedure to enable faster or more reproducible calcium scoring. This chapter provides an introduction to AI for calcium scoring, and an overview of the developed methods and their applications. We conclude with a discussion on AI methods in calcium scoring and propose potential directions for future research.
RL-DARTS: Differentiable Architecture Search for Reinforcement Learning
Jun 04, 2021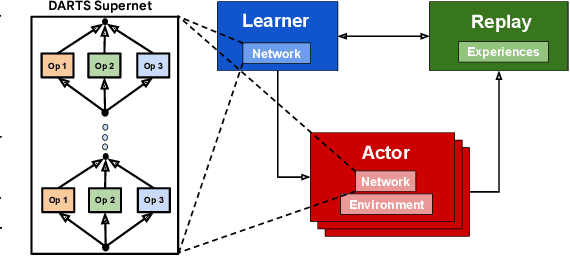
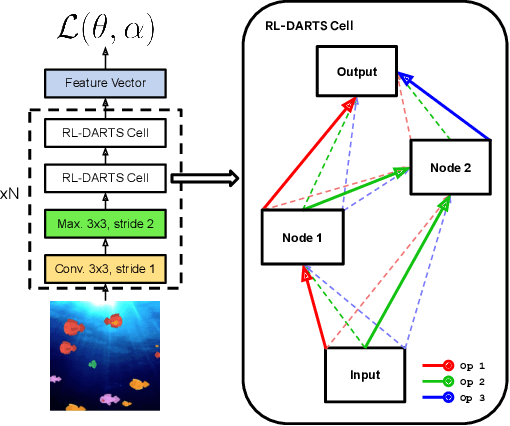
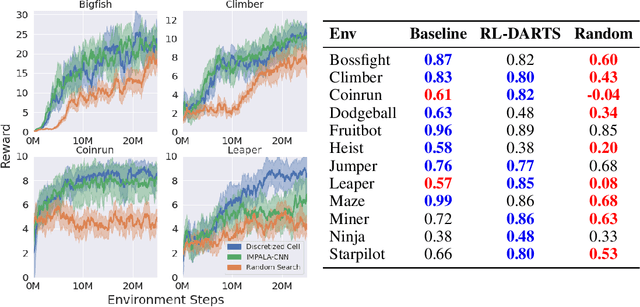
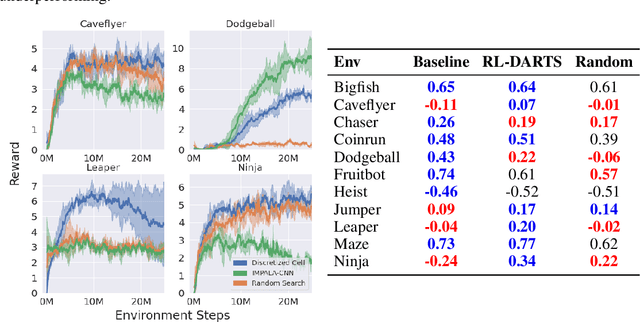
We introduce RL-DARTS, one of the first applications of Differentiable Architecture Search (DARTS) in reinforcement learning (RL) to search for convolutional cells, applied to the Procgen benchmark. We outline the initial difficulties of applying neural architecture search techniques in RL, and demonstrate that by simply replacing the image encoder with a DARTS supernet, our search method is sample-efficient, requires minimal extra compute resources, and is also compatible with off-policy and on-policy RL algorithms, needing only minor changes in preexisting code. Surprisingly, we find that the supernet can be used as an actor for inference to generate replay data in standard RL training loops, and thus train end-to-end. Throughout this training process, we show that the supernet gradually learns better cells, leading to alternative architectures which can be highly competitive against manually designed policies, but also verify previous design choices for RL policies.
Explainable AI for medical imaging: Explaining pneumothorax diagnoses with Bayesian Teaching
Jun 08, 2021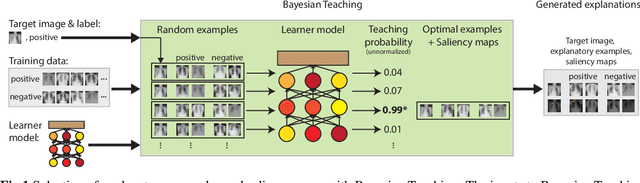
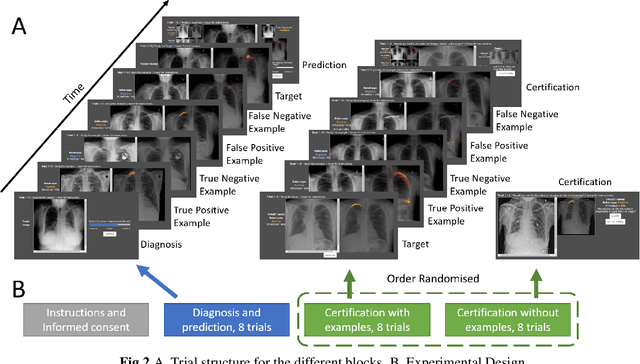
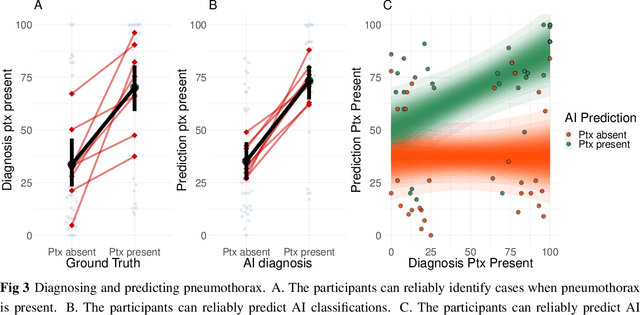
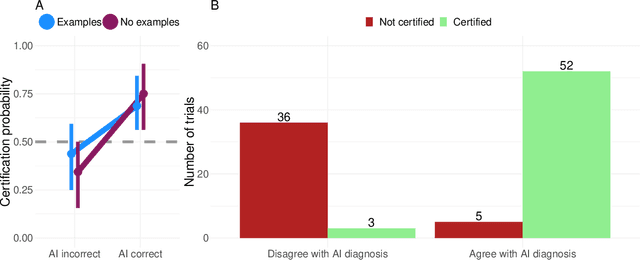
Limited expert time is a key bottleneck in medical imaging. Due to advances in image classification, AI can now serve as decision-support for medical experts, with the potential for great gains in radiologist productivity and, by extension, public health. However, these gains are contingent on building and maintaining experts' trust in the AI agents. Explainable AI may build such trust by helping medical experts to understand the AI decision processes behind diagnostic judgements. Here we introduce and evaluate explanations based on Bayesian Teaching, a formal account of explanation rooted in the cognitive science of human learning. We find that medical experts exposed to explanations generated by Bayesian Teaching successfully predict the AI's diagnostic decisions and are more likely to certify the AI for cases when the AI is correct than when it is wrong, indicating appropriate trust. These results show that Explainable AI can be used to support human-AI collaboration in medical imaging.
Sparsity-based Convolutional Kernel Network for Unsupervised Medical Image Analysis
Jul 27, 2018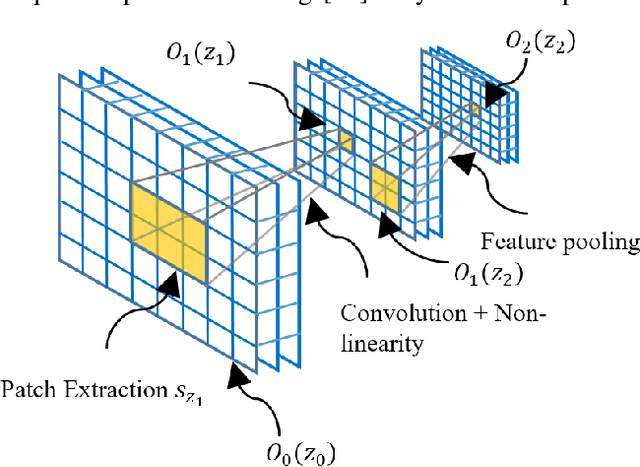
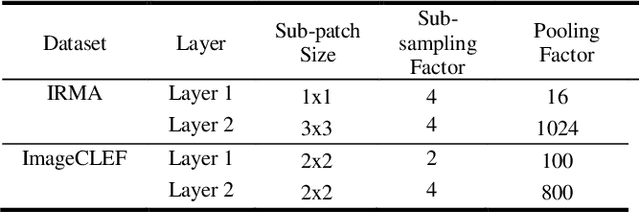
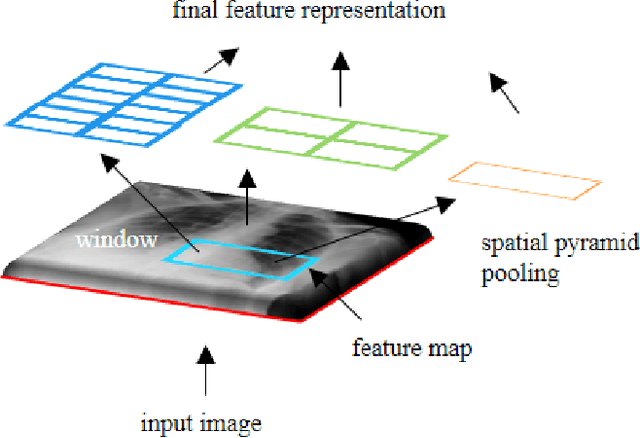
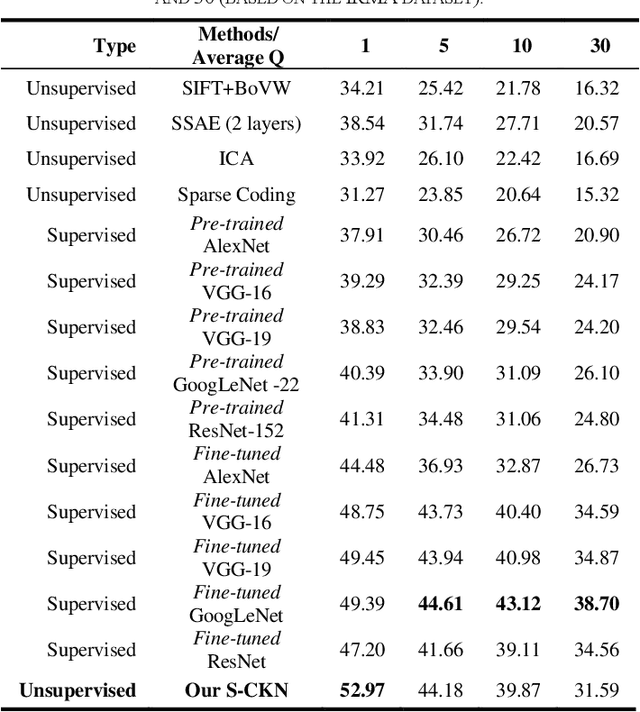
The availability of large-scale annotated image datasets coupled with recent advances in supervised deep learning methods are enabling the derivation of representative image features that can potentially impact different image analysis problems. However, such supervised approaches are not feasible in the medical domain where it is challenging to obtain a large volume of labelled data due to the complexity of manual annotation and inter- and intra-observer variability in label assignment. Algorithms designed to work on small annotated datasets are useful but have limited applications. In an effort to address the lack of annotated data in the medical image analysis domain, we propose an algorithm for hierarchical unsupervised feature learning. Our algorithm introduces three new contributions: (i) we use kernel learning to identify and represent invariant characteristics across image sub-patches in an unsupervised manner; (ii) we leverage the sparsity inherent to medical image data and propose a new sparse convolutional kernel network (S-CKN) that can be pre-trained in a layer-wise fashion, thereby providing initial discriminative features for medical data; and (iii) we propose a spatial pyramid pooling framework to capture subtle geometric differences in medical image data. Our experiments evaluate our algorithm in two common application areas of medical image retrieval and classification using two public datasets. Our results demonstrate that the medical image feature representations extracted with our algorithm enable a higher accuracy in both application areas compared to features extracted from other conventional unsupervised methods. Furthermore, our approach achieves an accuracy that is competitive with state-of-the-art supervised CNNs.
Discovering Relationships between Object Categories via Universal Canonical Maps
Jun 17, 2021



We tackle the problem of learning the geometry of multiple categories of deformable objects jointly. Recent work has shown that it is possible to learn a unified dense pose predictor for several categories of related objects. However, training such models requires to initialize inter-category correspondences by hand. This is suboptimal and the resulting models fail to maintain correct correspondences as individual categories are learned. In this paper, we show that improved correspondences can be learned automatically as a natural byproduct of learning category-specific dense pose predictors. To do this, we express correspondences between different categories and between images and categories using a unified embedding. Then, we use the latter to enforce two constraints: symmetric inter-category cycle consistency and a new asymmetric image-to-category cycle consistency. Without any manual annotations for the inter-category correspondences, we obtain state-of-the-art alignment results, outperforming dedicated methods for matching 3D shapes. Moreover, the new model is also better at the task of dense pose prediction than prior work.
Generator Surgery for Compressed Sensing
Mar 01, 2021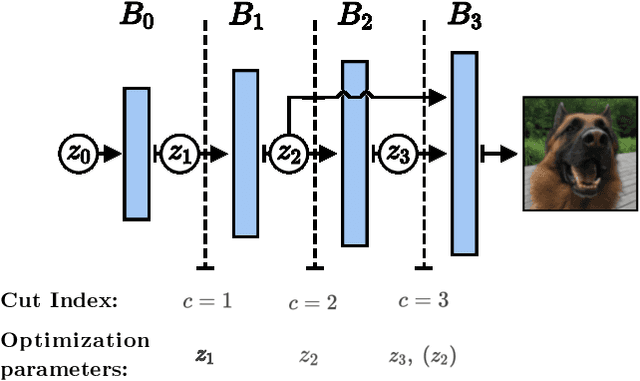
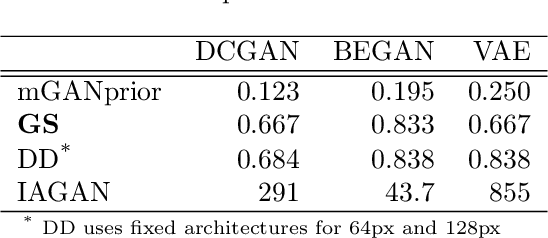
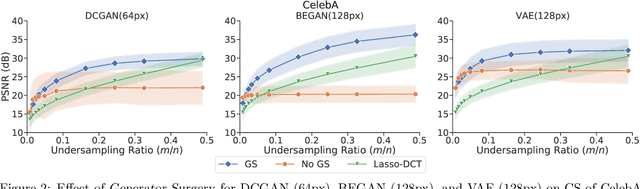
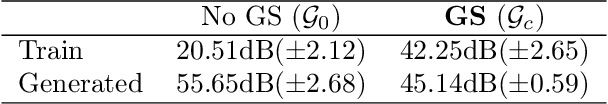
Image recovery from compressive measurements requires a signal prior for the images being reconstructed. Recent work has explored the use of deep generative models with low latent dimension as signal priors for such problems. However, their recovery performance is limited by high representation error. We introduce a method for achieving low representation error using generators as signal priors. Using a pre-trained generator, we remove one or more initial blocks at test time and optimize over the new, higher-dimensional latent space to recover a target image. Experiments demonstrate significantly improved reconstruction quality for a variety of network architectures. This approach also works well for out-of-training-distribution images and is competitive with other state-of-the-art methods. Our experiments show that test-time architectural modifications can greatly improve the recovery quality of generator signal priors for compressed sensing.
Boosting Image Recognition with Non-differentiable Constraints
Oct 02, 2019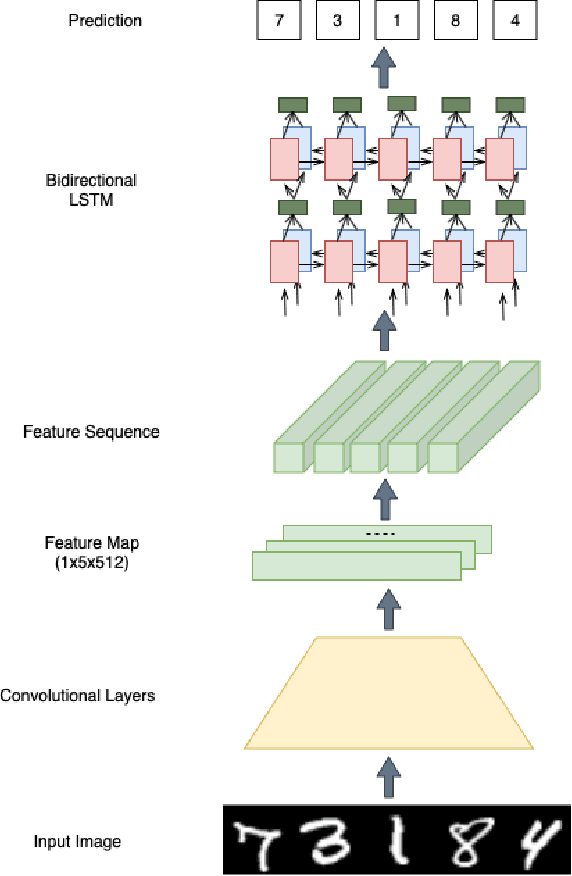
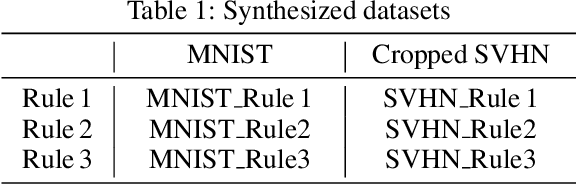

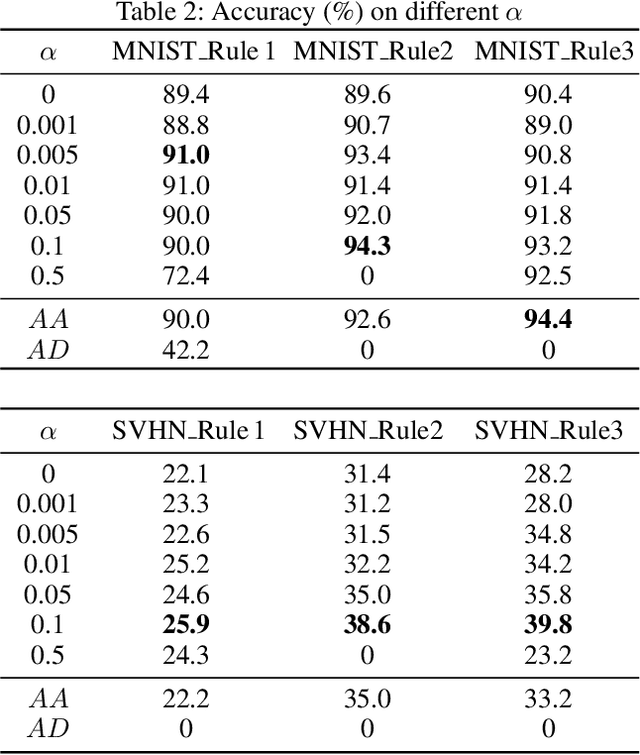
In this paper, we study the problem of image recognition with non-differentiable constraints. A lot of real-life recognition applications require a rich output structure with deterministic constraints that are discrete or modeled by a non-differentiable function. A prime example is recognizing digit sequences, which are restricted by such rules (e.g., \textit{container code detection}, \textit{social insurance number recognition}, etc.). We investigate the usefulness of adding non-differentiable constraints in learning for the task of digit sequence recognition. Toward this goal, we synthesize six different datasets from MNIST and Cropped SVHN, with three discrete rules inspired by real-life protocols. To deal with the non-differentiability of these rules, we propose a reinforcement learning approach based on the policy gradient method. We find that incorporating this rule-based reinforcement can effectively increase the accuracy for all datasets and provide a good inductive bias which improves the model even with limited data. On one of the datasets, MNIST\_Rule2, models trained with rule-based reinforcement increase the accuracy by 4.7\% for 2000 samples and 23.6\% for 500 samples. We further test our model against synthesized adversarial examples, e.g., blocking out digits, and observe that adding our rule-based reinforcement increases the model robustness with a relatively smaller performance drop.
SECANT: Self-Expert Cloning for Zero-Shot Generalization of Visual Policies
Jun 17, 2021
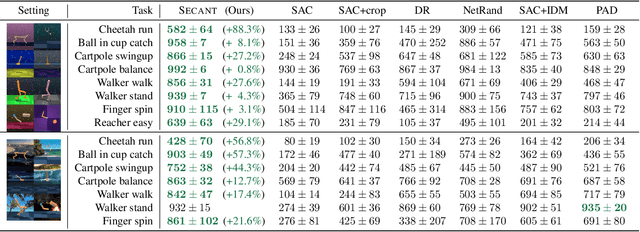
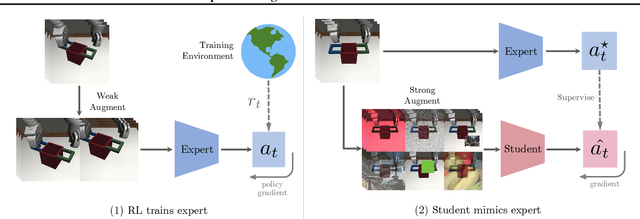
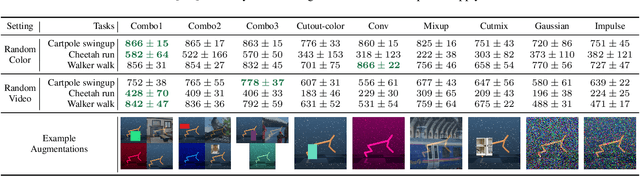
Generalization has been a long-standing challenge for reinforcement learning (RL). Visual RL, in particular, can be easily distracted by irrelevant factors in high-dimensional observation space. In this work, we consider robust policy learning which targets zero-shot generalization to unseen visual environments with large distributional shift. We propose SECANT, a novel self-expert cloning technique that leverages image augmentation in two stages to decouple robust representation learning from policy optimization. Specifically, an expert policy is first trained by RL from scratch with weak augmentations. A student network then learns to mimic the expert policy by supervised learning with strong augmentations, making its representation more robust against visual variations compared to the expert. Extensive experiments demonstrate that SECANT significantly advances the state of the art in zero-shot generalization across 4 challenging domains. Our average reward improvements over prior SOTAs are: DeepMind Control (+26.5%), robotic manipulation (+337.8%), vision-based autonomous driving (+47.7%), and indoor object navigation (+15.8%). Code release and video are available at https://linxifan.github.io/secant-site/.
Understanding Image Quality and Trust in Peer-to-Peer Marketplaces
Nov 26, 2018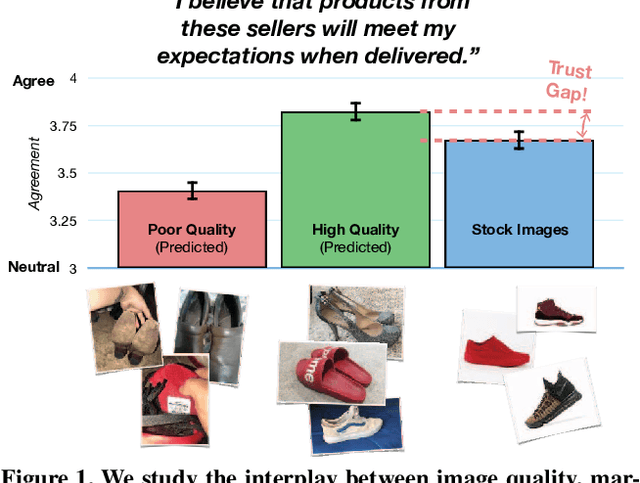

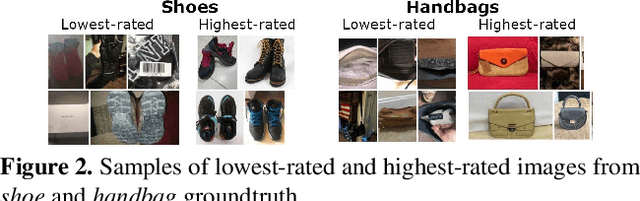
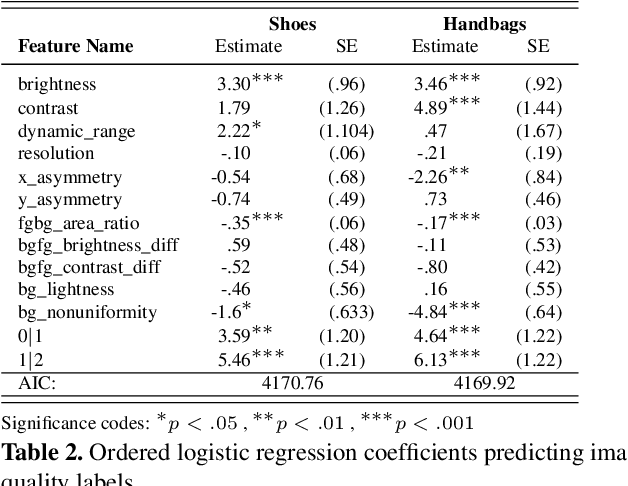
As any savvy online shopper knows, second-hand peer-to-peer marketplaces are filled with images of mixed quality. How does image quality impact marketplace outcomes, and can quality be automatically predicted? In this work, we conducted a large-scale study on the quality of user-generated images in peer-to-peer marketplaces. By gathering a dataset of common second-hand products (~75,000 images) and annotating a subset with human-labeled quality judgments, we were able to model and predict image quality with decent accuracy (~87%). We then conducted two studies focused on understanding the relationship between these image quality scores and two marketplace outcomes: sales and perceived trustworthiness. We show that image quality is associated with higher likelihood that an item will be sold, though other factors such as view count were better predictors of sales. Nonetheless, we show that high quality user-generated images selected by our models outperform stock imagery in eliciting perceptions of trust from users. Our findings can inform the design of future marketplaces and guide potential sellers to take better product images.
Survey of the Detection and Classification of Pulmonary Lesions via CT and X-Ray
Dec 31, 2020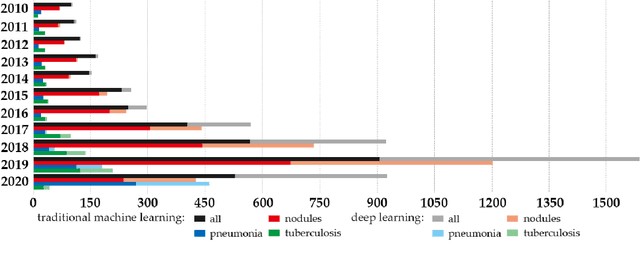
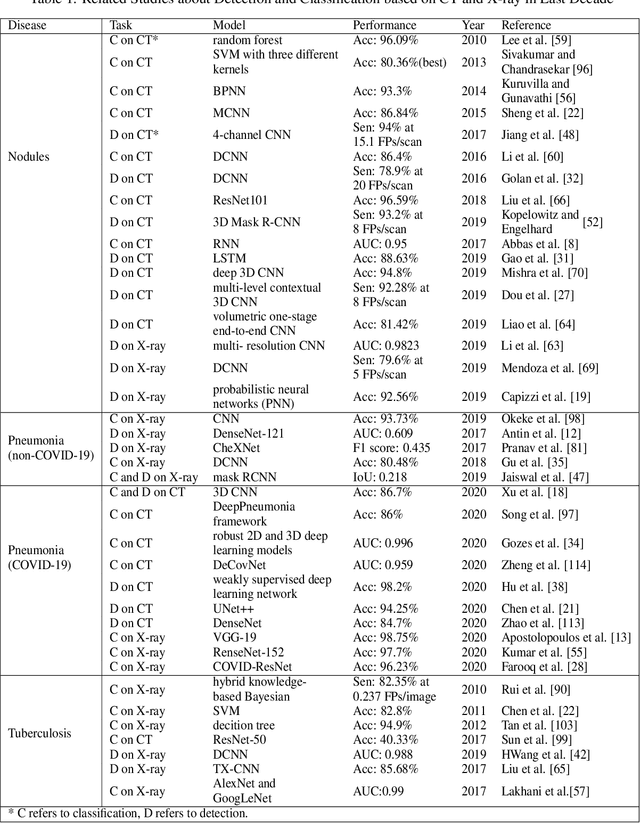
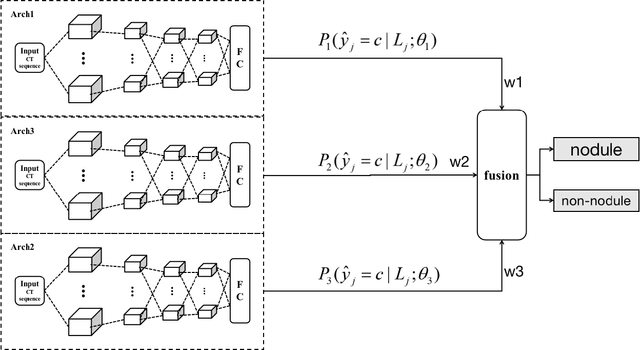
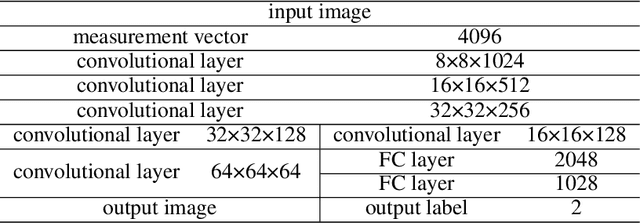
In recent years, the prevalence of several pulmonary diseases, especially the coronavirus disease 2019 (COVID-19) pandemic, has attracted worldwide attention. These diseases can be effectively diagnosed and treated with the help of lung imaging. With the development of deep learning technology and the emergence of many public medical image datasets, the diagnosis of lung diseases via medical imaging has been further improved. This article reviews pulmonary CT and X-ray image detection and classification in the last decade. It also provides an overview of the detection of lung nodules, pneumonia, and other common lung lesions based on the imaging characteristics of various lesions. Furthermore, this review introduces 26 commonly used public medical image datasets, summarizes the latest technology, and discusses current challenges and future research directions.