 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GI-PIP: Do We Require Impractical Auxiliary Dataset for Gradient Inversion Attacks?
Jan 23, 2024
Deep gradient inversion attacks expose a serious threat to Federated Learning (FL) by accurately recovering private data from shared gradients. However, the state-of-the-art heavily relies on impractical assumptions to access excessive auxiliary data, which violates the basic data partitioning principle of FL. In this paper, a novel method, Gradient Inversion Attack using Practical Image Prior (GI-PIP), is proposed under a revised threat model. GI-PIP exploits anomaly detection models to capture the underlying distribution from fewer data, while GAN-based methods consume significant more data to synthesize images. The extracted distribution is then leveraged to regulate the attack process as Anomaly Score loss. Experimental results show that GI-PIP achieves a 16.12 dB PSNR recovery using only 3.8% data of ImageNet, while GAN-based methods necessitate over 70%. Moreover, GI-PIP exhibits superior capability on distribution generalization compared to GAN-based methods. Our approach significantly alleviates the auxiliary data requirement on both amount and distribution in gradient inversion attacks, hence posing more substantial threat to real-world FL.
IRIS: Inverse Rendering of Indoor Scenes from Low Dynamic Range Images
Jan 23, 2024While numerous 3D reconstruction and novel-view synthesis methods allow for photorealistic rendering of a scene from multi-view images easily captured with consumer cameras, they bake illumination in their representations and fall short of supporting advanced applications like material editing, relighting, and virtual object insertion. The reconstruction of physically based material properties and lighting via inverse rendering promises to enable such applications. However, most inverse rendering techniques require high dynamic range (HDR) images as input, a setting that is inaccessible to most users. We present a method that recovers the physically based material properties and spatially-varying HDR lighting of a scene from multi-view, low-dynamic-range (LDR) images. We model the LDR image formation process in our inverse rendering pipeline and propose a novel optimization strategy for material, lighting, and a camera response model. We evaluate our approach with synthetic and real scenes compared to the state-of-the-art inverse rendering methods that take either LDR or HDR input. Our method outperforms existing methods taking LDR images as input, and allows for highly realistic relighting and object insertion.
Design and Implementation of Hardware Accelerators for Neural Processing Applications
Jan 25, 2024Primary motivation for this work was the need to implement hardware accelerators for a newly proposed ANN structure called Auto Resonance Network (ARN) for robotic motion planning. ARN is an approximating feed-forward hierarchical and explainable network. It can be used in various AI applications but the application base was small. Therefore, the objective of the research was twofold: to develop a new application using ARN and to implement a hardware accelerator for ARN. As per the suggestions given by the Doctoral Committee, an image recognition system using ARN has been implemented. An accuracy of around 94% was achieved with only 2 layers of ARN. The network also required a small training data set of about 500 images. Publicly available MNIST dataset was used for this experiment. All the coding was done in Python. Massive parallelism seen in ANNs presents several challenges to CPU design. For a given functionality, e.g., multiplication, several copies of serial modules can be realized within the same area as a parallel module. Advantage of using serial modules compared to parallel modules under area constraints has been discussed. One of the module often useful in ANNs is a multi-operand addition. One problem in its implementation is that the estimation of carry bits when the number of operands changes. A theorem to calculate exact number of carry bits required for a multi-operand addition has been presented in the thesis which alleviates this problem. The main advantage of the modular approach to multi-operand addition is the possibility of pipelined addition with low reconfiguration overhead. This results in overall increase in throughput for large number of additions, typically seen in several DNN configurations.
Improving Fairness of Automated Chest X-ray Diagnosis by Contrastive Learning
Jan 25, 2024Purpose: Limited studies exploring concrete methods or approaches to tackle and enhance model fairness in the radiology domain. Our proposed AI model utilizes supervised contrastive learning to minimize bias in CXR diagnosis. Materials and Methods: In this retrospective study, we evaluated our proposed method on two datasets: the Medical Imaging and Data Resource Center (MIDRC) dataset with 77,887 CXR images from 27,796 patients collected as of April 20, 2023 for COVID-19 diagnosis, and the NIH Chest X-ray (NIH-CXR) dataset with 112,120 CXR images from 30,805 patients collected between 1992 and 2015. In the NIH-CXR dataset, thoracic abnormalities include atelectasis, cardiomegaly, effusion, infiltration, mass, nodule, pneumonia, pneumothorax, consolidation, edema, emphysema, fibrosis, pleural thickening, or hernia. Our proposed method utilizes supervised contrastive learning with carefully selected positive and negative samples to generate fair image embeddings, which are fine-tuned for subsequent tasks to reduce bias in chest X-ray (CXR) diagnosis. We evaluated the methods using the marginal AUC difference ($\delta$ mAUC). Results: The proposed model showed a significant decrease in bias across all subgroups when compared to the baseline models, as evidenced by a paired T-test (p<0.0001). The $\delta$ mAUC obtained by our method were 0.0116 (95\% CI, 0.0110-0.0123), 0.2102 (95% CI, 0.2087-0.2118), and 0.1000 (95\% CI, 0.0988-0.1011) for sex, race, and age on MIDRC, and 0.0090 (95\% CI, 0.0082-0.0097) for sex and 0.0512 (95% CI, 0.0512-0.0532) for age on NIH-CXR, respectively. Conclusion: Employing supervised contrastive learning can mitigate bias in CXR diagnosis, addressing concerns of fairness and reliability in deep learning-based diagnostic methods.
Residual Learning for Image Point Descriptors
Dec 24, 2023Local image feature descriptors have had a tremendous impact on the development and application of computer vision methods. It is therefore unsurprising that significant efforts are being made for learning-based image point descriptors. However, the advantage of learned methods over handcrafted methods in real applications is subtle and more nuanced than expected. Moreover, handcrafted descriptors such as SIFT and SURF still perform better point localization in Structure-from-Motion (SfM) compared to many learned counterparts. In this paper, we propose a very simple and effective approach to learning local image descriptors by using a hand-crafted detector and descriptor. Specifically, we choose to learn only the descriptors, supported by handcrafted descriptors while discarding the point localization head. We optimize the final descriptor by leveraging the knowledge already present in the handcrafted descriptor. Such an approach of optimization allows us to discard learning knowledge already present in non-differentiable functions such as the hand-crafted descriptors and only learn the residual knowledge in the main network branch. This offers 50X convergence speed compared to the standard baseline architecture of SuperPoint while at inference the combined descriptor provides superior performance over the learned and hand-crafted descriptors. This is done with minor increase in the computations over the baseline learned descriptor. Our approach has potential applications in ensemble learning and learning with non-differentiable functions. We perform experiments in matching, camera localization and Structure-from-Motion in order to showcase the advantages of our approach.
Guided Image Restoration via Simultaneous Feature and Image Guided Fusion
Dec 14, 2023
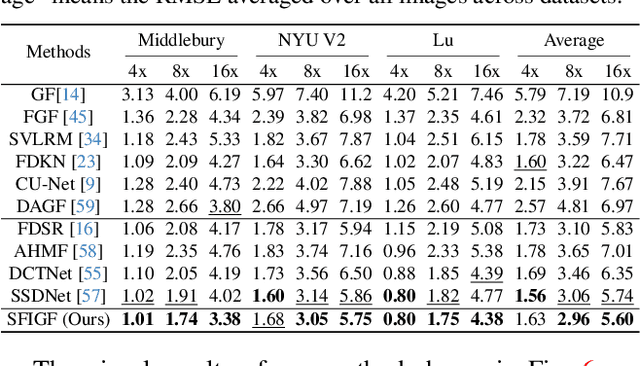
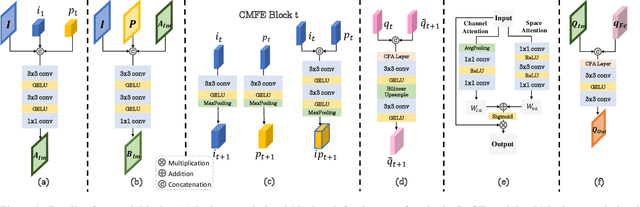
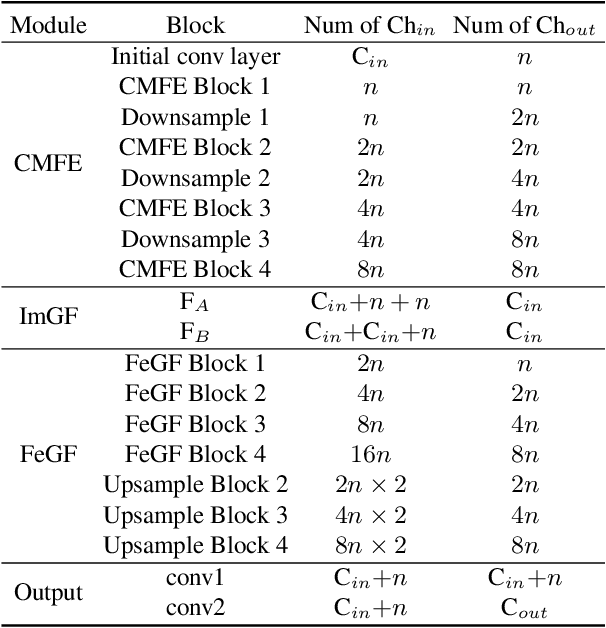
Guided image restoration (GIR), such as guided depth map super-resolution and pan-sharpening, aims to enhance a target image using guidance information from another image of the same scene. Currently, joint image filtering-inspired deep learning-based methods represent the state-of-the-art for GIR tasks. Those methods either deal with GIR in an end-to-end way by elaborately designing filtering-oriented deep neural network (DNN) modules, focusing on the feature-level fusion of inputs; or explicitly making use of the traditional joint filtering mechanism by parameterizing filtering coefficients with DNNs, working on image-level fusion. The former ones are good at recovering contextual information but tend to lose fine-grained details, while the latter ones can better retain textual information but might lead to content distortions. In this work, to inherit the advantages of both methodologies while mitigating their limitations, we proposed a Simultaneous Feature and Image Guided Fusion (SFIGF) network, that simultaneously considers feature and image-level guided fusion following the guided filter (GF) mechanism. In the feature domain, we connect the cross-attention (CA) with GF, and propose a GF-inspired CA module for better feature-level fusion; in the image domain, we fully explore the GF mechanism and design GF-like structure for better image-level fusion. Since guided fusion is implemented in both feature and image domains, the proposed SFIGF is expected to faithfully reconstruct both contextual and textual information from sources and thus lead to better GIR results. We apply SFIGF to 4 typical GIR tasks, and experimental results on these tasks demonstrate its effectiveness and general availability.
Concealed Object Segmentation with Hierarchical Coherence Modeling
Jan 22, 2024Concealed object segmentation (COS) is a challenging task that involves localizing and segmenting those concealed objects that are visually blended with their surrounding environments. Despite achieving remarkable success, existing COS segmenters still struggle to achieve complete segmentation results in extremely concealed scenarios. In this paper, we propose a Hierarchical Coherence Modeling (HCM) segmenter for COS, aiming to address this incomplete segmentation limitation. In specific, HCM promotes feature coherence by leveraging the intra-stage coherence and cross-stage coherence modules, exploring feature correlations at both the single-stage and contextual levels. Additionally, we introduce the reversible re-calibration decoder to detect previously undetected parts in low-confidence regions, resulting in further enhancing segmentation performance. Extensive experiments conducted on three COS tasks, including camouflaged object detection, polyp image segmentation, and transparent object detection, demonstrate the promising results achieved by the proposed HCM segmenter.
PanGu-Draw: Advancing Resource-Efficient Text-to-Image Synthesis with Time-Decoupled Training and Reusable Coop-Diffusion
Dec 29, 2023Current large-scale diffusion models represent a giant leap forward in conditional image synthesis, capable of interpreting diverse cues like text, human poses, and edges. However, their reliance on substantial computational resources and extensive data collection remains a bottleneck. On the other hand, the integration of existing diffusion models, each specialized for different controls and operating in unique latent spaces, poses a challenge due to incompatible image resolutions and latent space embedding structures, hindering their joint use. Addressing these constraints, we present "PanGu-Draw", a novel latent diffusion model designed for resource-efficient text-to-image synthesis that adeptly accommodates multiple control signals. We first propose a resource-efficient Time-Decoupling Training Strategy, which splits the monolithic text-to-image model into structure and texture generators. Each generator is trained using a regimen that maximizes data utilization and computational efficiency, cutting data preparation by 48% and reducing training resources by 51%. Secondly, we introduce "Coop-Diffusion", an algorithm that enables the cooperative use of various pre-trained diffusion models with different latent spaces and predefined resolutions within a unified denoising process. This allows for multi-control image synthesis at arbitrary resolutions without the necessity for additional data or retraining. Empirical validations of Pangu-Draw show its exceptional prowess in text-to-image and multi-control image generation, suggesting a promising direction for future model training efficiencies and generation versatility. The largest 5B T2I PanGu-Draw model is released on the Ascend platform. Project page: $\href{https://pangu-draw.github.io}{this~https~URL}$
Decoupled Textual Embeddings for Customized Image Generation
Dec 19, 2023Customized text-to-image generation, which aims to learn user-specified concepts with a few images, has drawn significant attention recently. However, existing methods usually suffer from overfitting issues and entangle the subject-unrelated information (e.g., background and pose) with the learned concept, limiting the potential to compose concept into new scenes. To address these issues, we propose the DETEX, a novel approach that learns the disentangled concept embedding for flexible customized text-to-image generation. Unlike conventional methods that learn a single concept embedding from the given images, our DETEX represents each image using multiple word embeddings during training, i.e., a learnable image-shared subject embedding and several image-specific subject-unrelated embeddings. To decouple irrelevant attributes (i.e., background and pose) from the subject embedding, we further present several attribute mappers that encode each image as several image-specific subject-unrelated embeddings. To encourage these unrelated embeddings to capture the irrelevant information, we incorporate them with corresponding attribute words and propose a joint training strategy to facilitate the disentanglement. During inference, we only use the subject embedding for image generation, while selectively using image-specific embeddings to retain image-specified attributes. Extensive experiments demonstrate that the subject embedding obtained by our method can faithfully represent the target concept, while showing superior editability compared to the state-of-the-art methods. Our code will be made published available.
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
Jan 24, 2024Autonomous agents capable of planning, reasoning, and executing actions on the web offer a promising avenue for automating computer tasks. However, the majority of existing benchmarks primarily focus on text-based agents, neglecting many natural tasks that require visual information to effectively solve. Given that most computer interfaces cater to human perception, visual information often augments textual data in ways that text-only models struggle to harness effectively. To bridge this gap, we introduce VisualWebArena, a benchmark designed to assess the performance of multimodal web agents on realistic \textit{visually grounded tasks}. VisualWebArena comprises of a set of diverse and complex web-based tasks that evaluate various capabilities of autonomous multimodal agents. To perform on this benchmark, agents need to accurately process image-text inputs, interpret natural language instructions, and execute actions on websites to accomplish user-defined objectives. We conduct an extensive evaluation of state-of-the-art LLM-based autonomous agents, including several multimodal models. Through extensive quantitative and qualitative analysis, we identify several limitations of text-only LLM agents, and reveal gaps in the capabilities of state-of-the-art multimodal language agents. VisualWebArena provides a framework for evaluating multimodal autonomous language agents, and offers insights towards building stronger autonomous agents for the web. Our code, baseline models, and data is publicly available at https://jykoh.com/vwa.