 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Punny Captions: Witty Wordplay in Image Descriptions
May 31, 2018
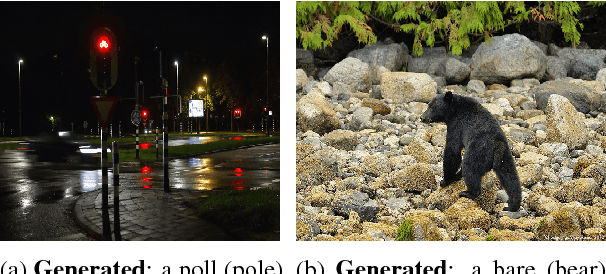
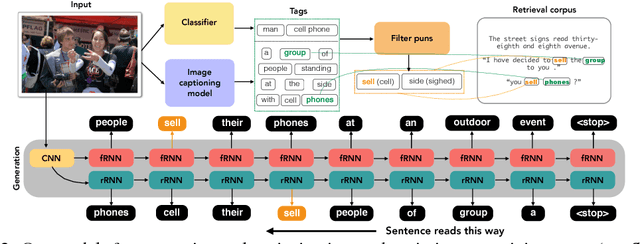
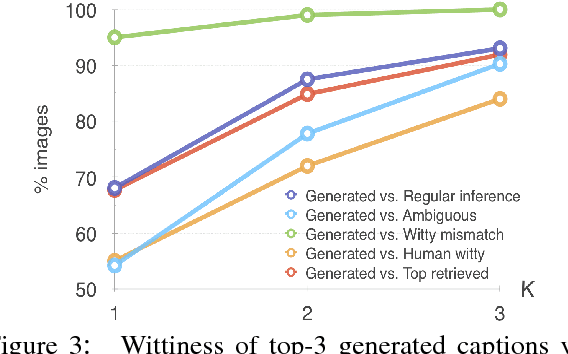

Wit is a form of rich interaction that is often grounded in a specific situation (e.g., a comment in response to an event). In this work, we attempt to build computational models that can produce witty descriptions for a given image. Inspired by a cognitive account of humor appreciation, we employ linguistic wordplay, specifically puns, in image descriptions. We develop two approaches which involve retrieving witty descriptions for a given image from a large corpus of sentences, or generating them via an encoder-decoder neural network architecture. We compare our approach against meaningful baseline approaches via human studies and show substantial improvements. We find that when a human is subject to similar constraints as the model regarding word usage and style, people vote the image descriptions generated by our model to be slightly wittier than human-written witty descriptions. Unsurprisingly, humans are almost always wittier than the model when they are free to choose the vocabulary, style, etc.
MicroNet: Towards Image Recognition with Extremely Low FLOPs
Nov 24, 2020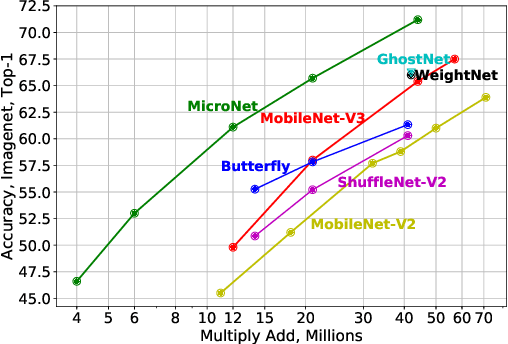
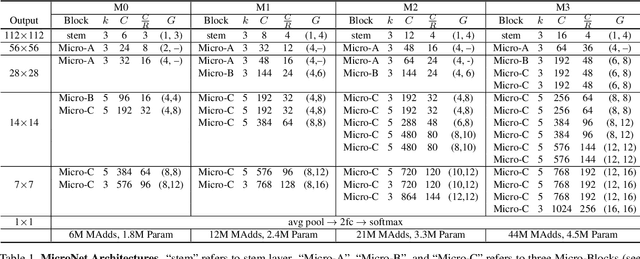
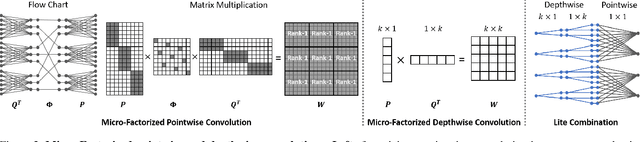
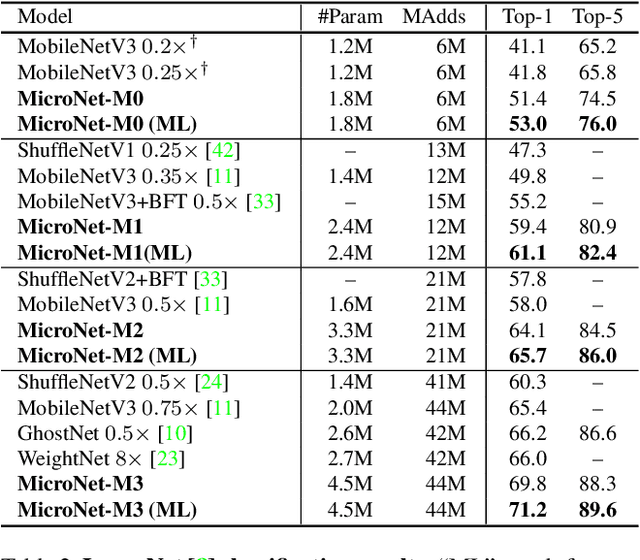
In this paper, we present MicroNet, which is an efficient convolutional neural network using extremely low computational cost (e.g. 6 MFLOPs on ImageNet classification). Such a low cost network is highly desired on edge devices, yet usually suffers from a significant performance degradation. We handle the extremely low FLOPs based upon two design principles: (a) avoiding the reduction of network width by lowering the node connectivity, and (b) compensating for the reduction of network depth by introducing more complex non-linearity per layer. Firstly, we propose Micro-Factorized convolution to factorize both pointwise and depthwise convolutions into low rank matrices for a good tradeoff between the number of channels and input/output connectivity. Secondly, we propose a new activation function, named Dynamic Shift-Max, to improve the non-linearity via maxing out multiple dynamic fusions between an input feature map and its circular channel shift. The fusions are dynamic as their parameters are adapted to the input. Building upon Micro-Factorized convolution and dynamic Shift-Max, a family of MicroNets achieve a significant performance gain over the state-of-the-art in the low FLOP regime. For instance, MicroNet-M1 achieves 61.1% top-1 accuracy on ImageNet classification with 12 MFLOPs, outperforming MobileNetV3 by 11.3%.
Contextually Guided Convolutional Neural Networks for Learning Most Transferable Representations
Mar 24, 2021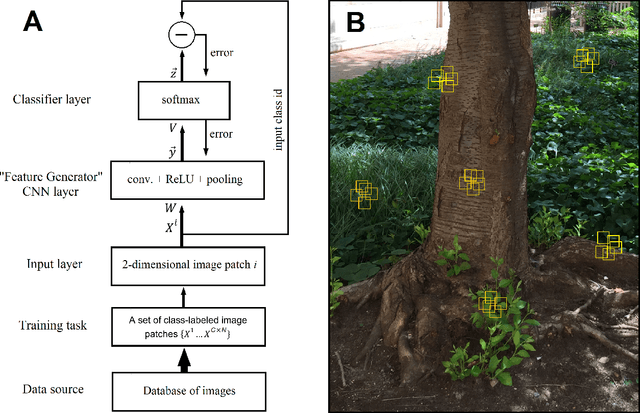
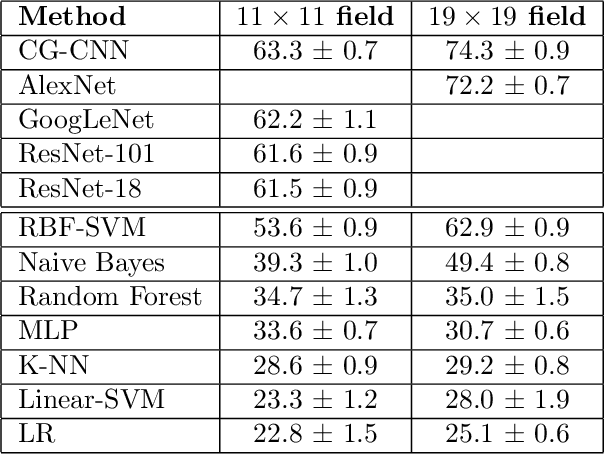
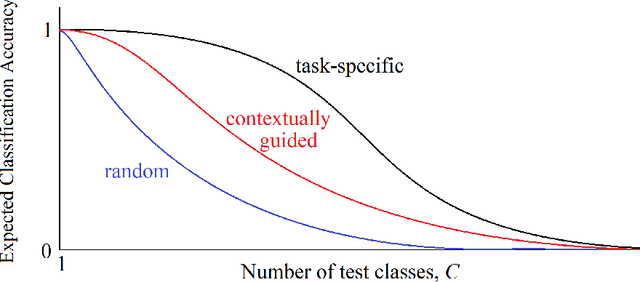

Deep Convolutional Neural Networks (CNNs), trained extensively on very large labeled datasets, learn to recognize inferentially powerful features in their input patterns and represent efficiently their objective content. Such objectivity of their internal representations enables deep CNNs to readily transfer and successfully apply these representations to new classification tasks. Deep CNNs develop their internal representations through a challenging process of error backpropagation-based supervised training. In contrast, deep neural networks of the cerebral cortex develop their even more powerful internal representations in an unsupervised process, apparently guided at a local level by contextual information. Implementing such local contextual guidance principles in a single-layer CNN architecture, we propose an efficient algorithm for developing broad-purpose representations (i.e., representations transferable to new tasks without additional training) in shallow CNNs trained on limited-size datasets. A contextually guided CNN (CG-CNN) is trained on groups of neighboring image patches picked at random image locations in the dataset. Such neighboring patches are likely to have a common context and therefore are treated for the purposes of training as belonging to the same class. Across multiple iterations of such training on different context-sharing groups of image patches, CNN features that are optimized in one iteration are then transferred to the next iteration for further optimization, etc. In this process, CNN features acquire higher pluripotency, or inferential utility for any arbitrary classification task, which we quantify as a transfer utility. In our application to natural images, we find that CG-CNN features show the same, if not higher, transfer utility and classification accuracy as comparable transferable features in the first CNN layer of the well-known deep networks.
A Hierarchical Dual Model of Environment- and Place-Specific Utility for Visual Place Recognition
Jul 06, 2021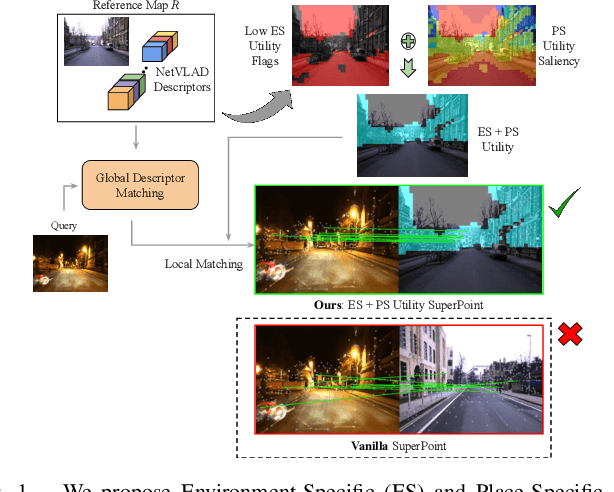
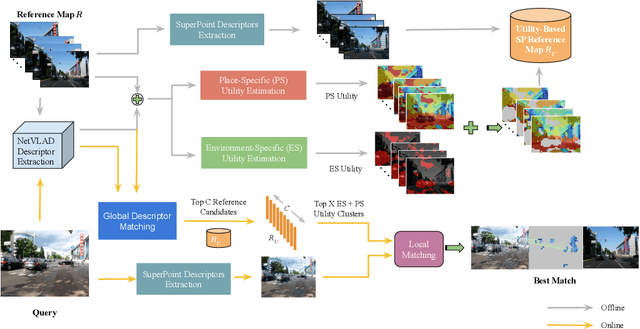
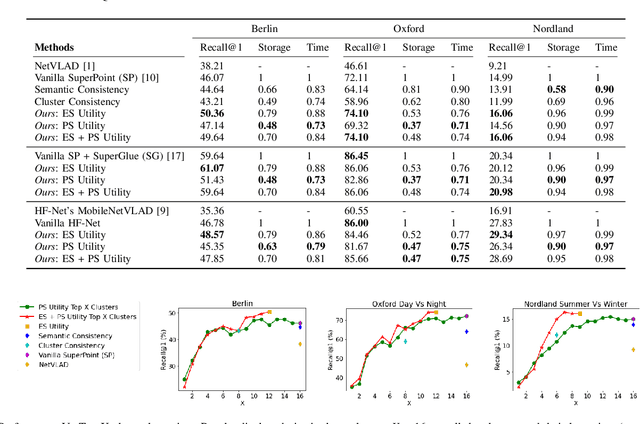
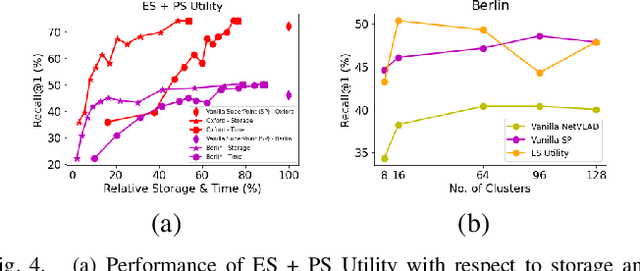
Visual Place Recognition (VPR) approaches have typically attempted to match places by identifying visual cues, image regions or landmarks that have high ``utility'' in identifying a specific place. But this concept of utility is not singular - rather it can take a range of forms. In this paper, we present a novel approach to deduce two key types of utility for VPR: the utility of visual cues `specific' to an environment, and to a particular place. We employ contrastive learning principles to estimate both the environment- and place-specific utility of Vector of Locally Aggregated Descriptors (VLAD) clusters in an unsupervised manner, which is then used to guide local feature matching through keypoint selection. By combining these two utility measures, our approach achieves state-of-the-art performance on three challenging benchmark datasets, while simultaneously reducing the required storage and compute time. We provide further analysis demonstrating that unsupervised cluster selection results in semantically meaningful results, that finer grained categorization often has higher utility for VPR than high level semantic categorization (e.g. building, road), and characterise how these two utility measures vary across different places and environments. Source code is made publicly available at https://github.com/Nik-V9/HEAPUtil.
A CNN-RNN Framework for Image Annotation from Visual Cues and Social Network Metadata
Oct 13, 2019
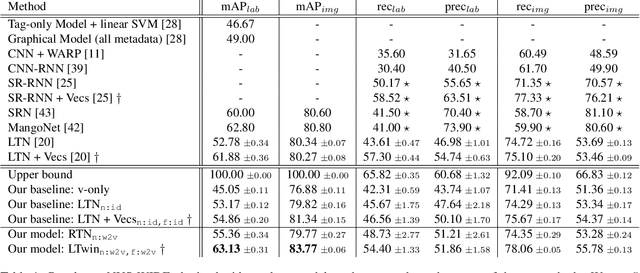
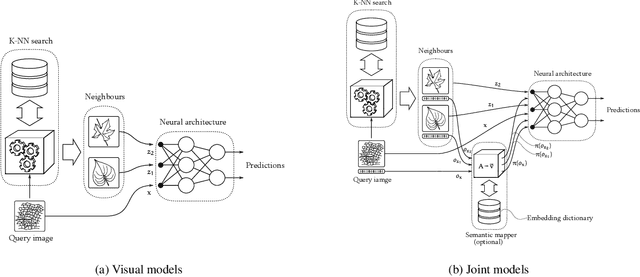
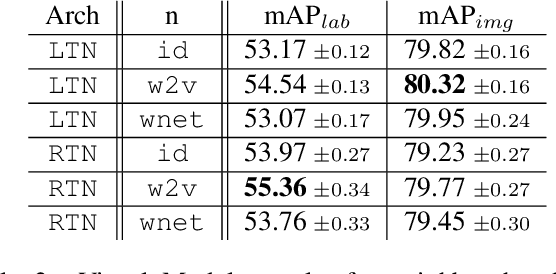
Images represent a commonly used form of visual communication among people. Nevertheless, image classification may be a challenging task when dealing with unclear or non-common images needing more context to be correctly annotated. Metadata accompanying images on social-media represent an ideal source of additional information for retrieving proper neighbourhoods easing image annotation task. To this end, we blend visual features extracted from neighbours and their metadata to jointly leverage context and visual cues. Our models use multiple semantic embeddings to properly map metadata to a meaningful semantic space decoupling the neural model from the low-level representation of metadata and achieve robustness to vocabulary changes between training and testing phases. Convolutional and recurrent neural networks (CNNs-RNNs) are jointly adopted to infer similarity among neighbours and query images. We perform comprehensive experiments on the NUS-WIDE dataset showing that our models outperform state-of-the-art architectures based on images and metadata, and decrease both sensory and semantic gaps to better annotate images.
Deep Neural Networks are Surprisingly Reversible: A Baseline for Zero-Shot Inversion
Jul 13, 2021



Understanding the behavior and vulnerability of pre-trained deep neural networks (DNNs) can help to improve them. Analysis can be performed via reversing the network's flow to generate inputs from internal representations. Most existing work relies on priors or data-intensive optimization to invert a model, yet struggles to scale to deep architectures and complex datasets. This paper presents a zero-shot direct model inversion framework that recovers the input to the trained model given only the internal representation. The crux of our method is to inverse the DNN in a divide-and-conquer manner while re-syncing the inverted layers via cycle-consistency guidance with the help of synthesized data. As a result, we obtain a single feed-forward model capable of inversion with a single forward pass without seeing any real data of the original task. With the proposed approach, we scale zero-shot direct inversion to deep architectures and complex datasets. We empirically show that modern classification models on ImageNet can, surprisingly, be inverted, allowing an approximate recovery of the original 224x224px images from a representation after more than 20 layers. Moreover, inversion of generators in GANs unveils latent code of a given synthesized face image at 128x128px, which can even, in turn, improve defective synthesized images from GANs.
ThumbNet: One Thumbnail Image Contains All You Need for Recognition
Apr 10, 2019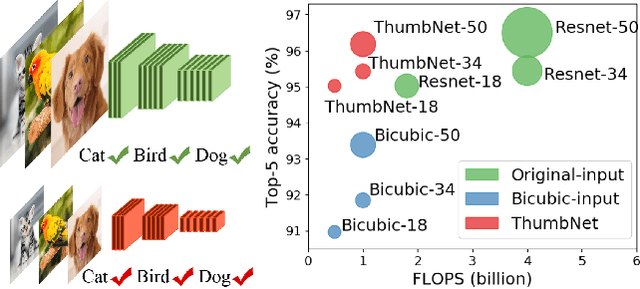

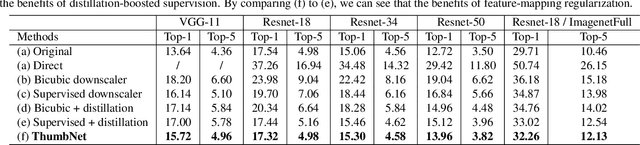
Although deep convolutional neural networks (CNNs) have achieved great success in the computer vision community, its real-world application is still impeded by its voracious demand of computational resources. Current works mostly seek to compress the network by reducing its parameters or parameter-incurred computation, neglecting the influence of the input image on the system complexity. Based on the fact that input images of a CNN contain much redundant spatial content, we propose in this paper an efficient and unified framework, dubbed as ThumbNet, to simultaneously accelerate and compress CNN models by enabling them to infer on one thumbnail image. We provide three effective strategies to train ThumbNet. In doing so, ThumbNet learns an inference network that performs equally well on small images as the original-input network on large images. With ThumbNet, not only do we obtain the thumbnail-input inference network that can drastically reduce computation and memory requirements, but also we obtain an image downscaler that can generate thumbnail images for generic classification tasks. Extensive experiments show the effectiveness of ThumbNet, and demonstrate that the thumbnail-input inference network learned by ThumbNet can adequately retain the accuracy of the original-input network even when the input images are downscaled 16 times.
Stacked Semantic-Guided Network for Zero-Shot Sketch-Based Image Retrieval
Apr 03, 2019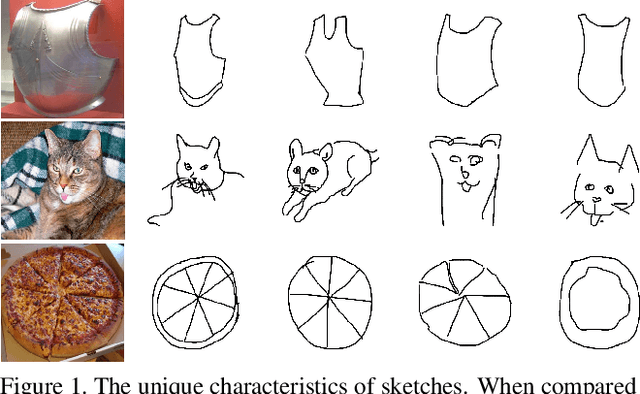
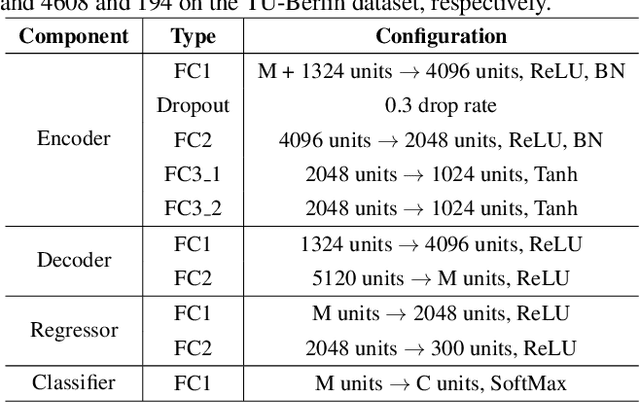
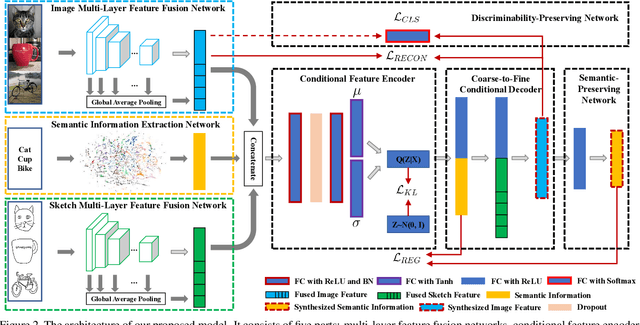
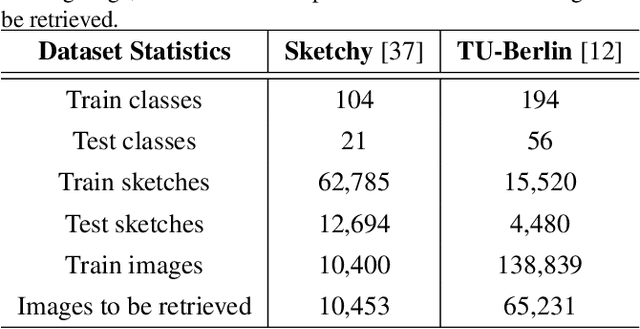
Zero-shot sketch-based image retrieval (ZS-SBIR) is a task of cross-domain image retrieval from a natural image gallery with free-hand sketch under a zero-shot scenario. Previous works mostly focus on a generative approach that takes a highly abstract and sparse sketch as input and then synthesizes the corresponding natural image. However, the intrinsic visual sparsity and large intra-class variance of the sketch make the learning of the conditional decoder more difficult and hence achieve unsatisfactory retrieval performance. In this paper, we propose a novel stacked semantic-guided network to address the unique characteristics of sketches in ZS-SBIR. Specifically, we devise multi-layer feature fusion networks that incorporate different intermediate feature representation information in a deep neural network to alleviate the intrinsic sparsity of sketches. In order to improve visual knowledge transfer from seen to unseen classes, we elaborate a coarse-to-fine conditional decoder that generates coarse-grained category-specific corresponding features first (taking auxiliary semantic information as conditional input) and then generates fine-grained instance-specific corresponding features (taking sketch representation as conditional input). Furthermore, regression loss and classification loss are utilized to preserve the semantic and discriminative information of the synthesized features respectively. Extensive experiments on the large-scale Sketchy dataset and TU-Berlin dataset demonstrate that our proposed approach outperforms state-of-the-art methods by more than 20\% in retrieval performance.
What classifiers know what they don't?
Jul 13, 2021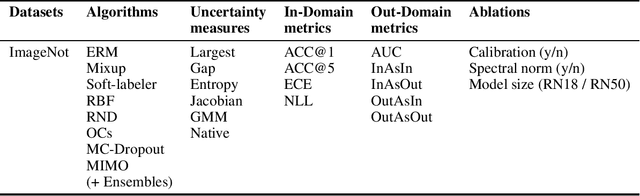
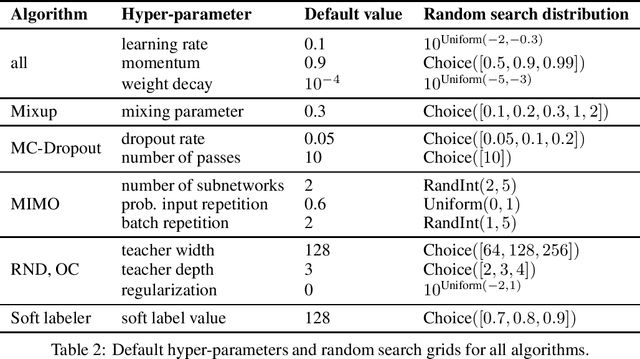
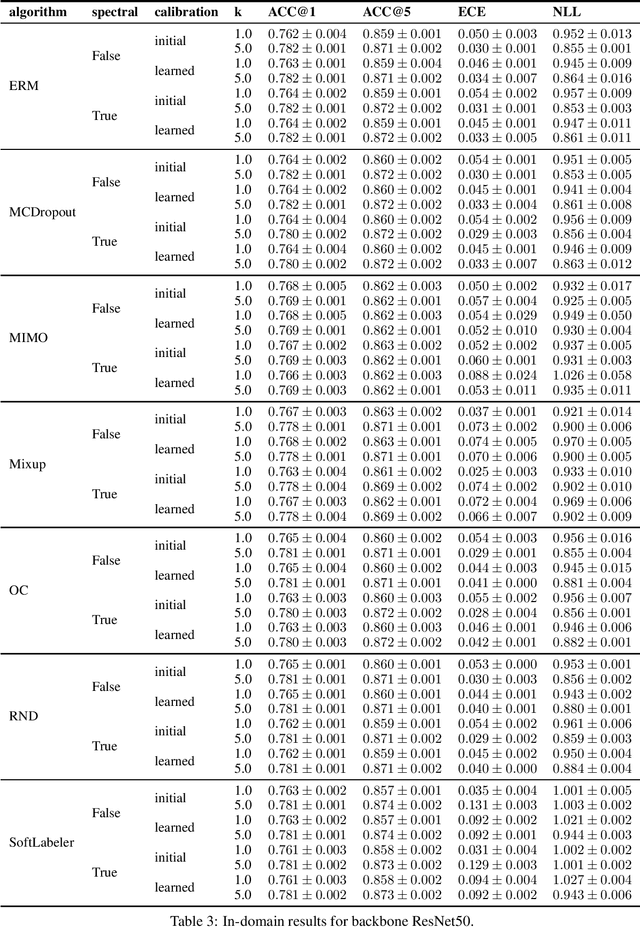
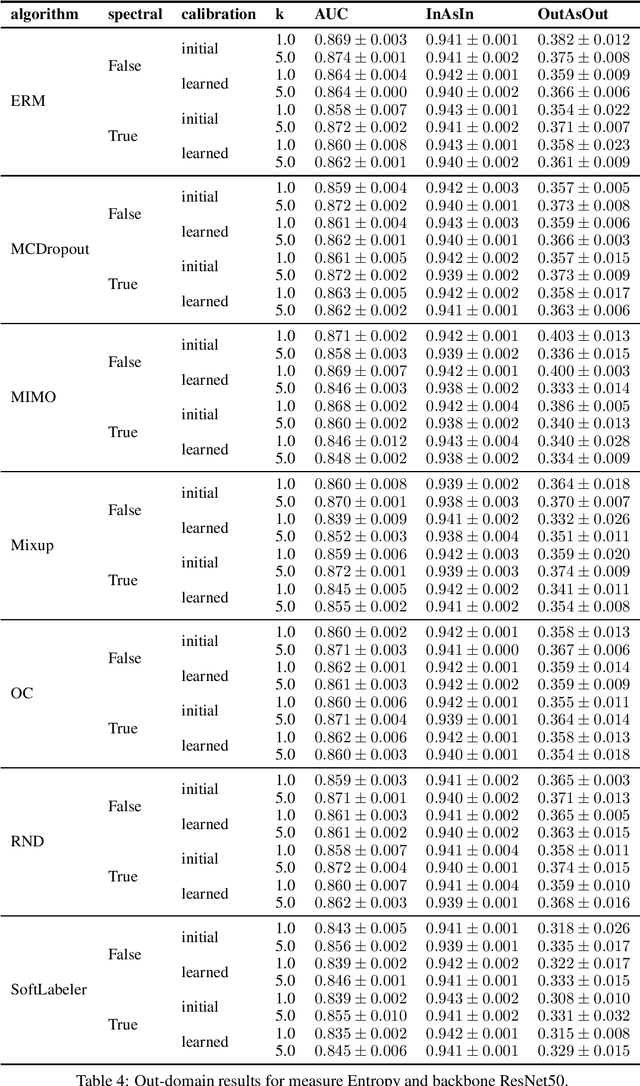
Being uncertain when facing the unknown is key to intelligent decision making. However, machine learning algorithms lack reliable estimates about their predictive uncertainty. This leads to wrong and overly-confident decisions when encountering classes unseen during training. Despite the importance of equipping classifiers with uncertainty estimates ready for the real world, prior work has focused on small datasets and little or no class discrepancy between training and testing data. To close this gap, we introduce UIMNET: a realistic, ImageNet-scale test-bed to evaluate predictive uncertainty estimates for deep image classifiers. Our benchmark provides implementations of eight state-of-the-art algorithms, six uncertainty measures, four in-domain metrics, three out-domain metrics, and a fully automated pipeline to train, calibrate, ensemble, select, and evaluate models. Our test-bed is open-source and all of our results are reproducible from a fixed commit in our repository. Adding new datasets, algorithms, measures, or metrics is a matter of a few lines of code-in so hoping that UIMNET becomes a stepping stone towards realistic, rigorous, and reproducible research in uncertainty estimation. Our results show that ensembles of ERM classifiers as well as single MIMO classifiers are the two best alternatives currently available to measure uncertainty about both in-domain and out-domain classes.
Semi-supervised CNN for Single Image Rain Removal
Jul 29, 2018

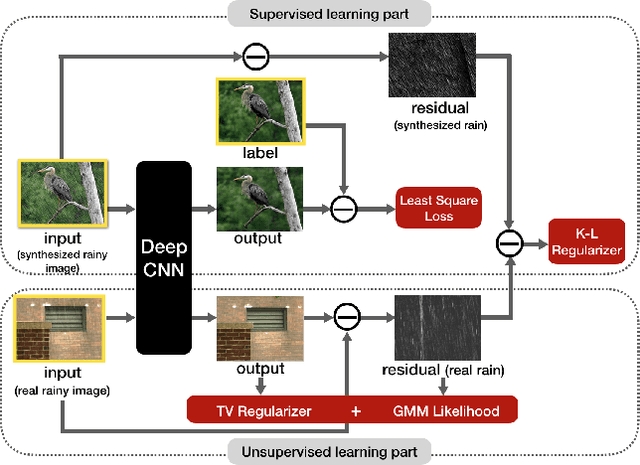
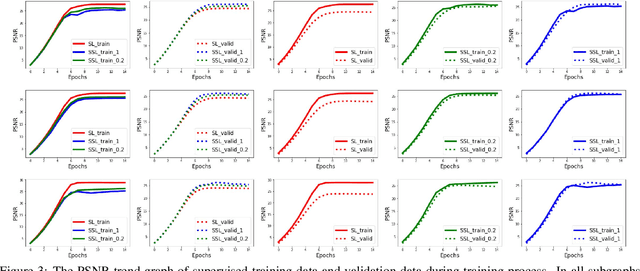
Single image rain removal is a typical inverse problem in computer vision. The deep learning technique has been verified to be effective to this task and achieved state-of-the-art performance. However, the method needs to pre-collect a large set of image pairs with/without rains for training, which not only makes the method laborsome to be practically implemented, but also tends to make the trained network bias to the training samples while less generalized to test samples with unseen rain types in training. To this issue, this paper firstly proposes a semisupervised learning paradigm to this task. Different from traditional deep learning methods which use only supervised image pairs with/without rains, we put the real rainy images, without need of their clean ones, into the network training process as well. This is realized by elaborately formulating the residual between an input rainy image and its expected network output (clear image without rains) as a concise patch-wised Mixture of Gaussians distribution. The entire objective function for training network is thus the combination of the supervised data loss (least square loss between input clear image and the network output) and the unsupervised data loss. In this way, all such unsupervised rainy images, which is much easier to collect than supervised ones, can be rationally fed into the network training process, and thus both the short-of-training-sample and bias-to-supervised-sample issues can be evidently alleviated. Experiments implemented on synthetic and real data experiments verify the superiority of our model as compared to the state-of-the-arts.