 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sensing population distribution from satellite imagery via deep learning: model selection, neighboring effect, and systematic biases
Mar 03, 2021
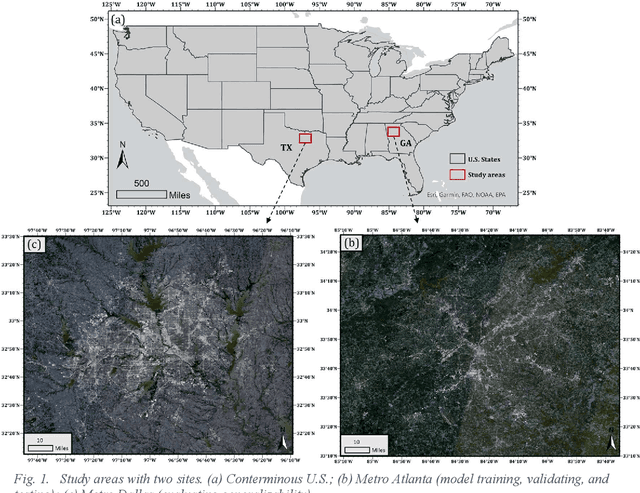
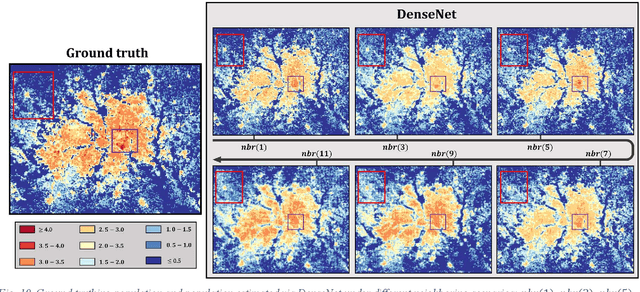
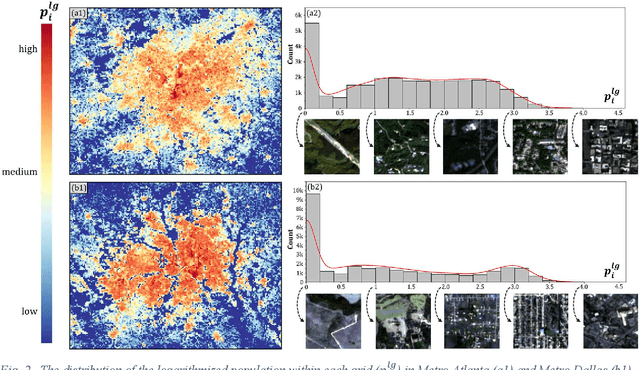
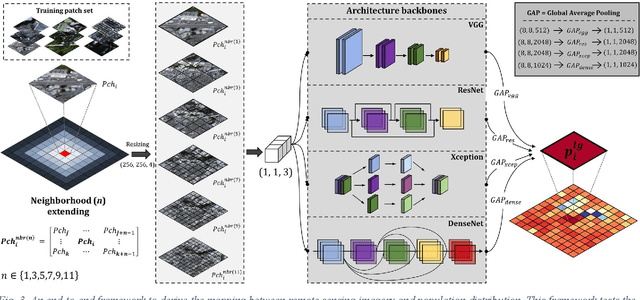
The rapid development of remote sensing techniques provides rich, large-coverage, and high-temporal information of the ground, which can be coupled with the emerging deep learning approaches that enable latent features and hidden geographical patterns to be extracted. This study marks the first attempt to cross-compare performances of popular state-of-the-art deep learning models in estimating population distribution from remote sensing images, investigate the contribution of neighboring effect, and explore the potential systematic population estimation biases. We conduct an end-to-end training of four popular deep learning architectures, i.e., VGG, ResNet, Xception, and DenseNet, by establishing a mapping between Sentinel-2 image patches and their corresponding population count from the LandScan population grid. The results reveal that DenseNet outperforms the other three models, while VGG has the worst performances in all evaluating metrics under all selected neighboring scenarios. As for the neighboring effect, contradicting existing studies, our results suggest that the increase of neighboring sizes leads to reduced population estimation performance, which is found universal for all four selected models in all evaluating metrics. In addition, there exists a notable, universal bias that all selected deep learning models tend to overestimate sparsely populated image patches and underestimate densely populated image patches, regardless of neighboring sizes. The methodological, experimental, and contextual knowledge this study provides is expected to benefit a wide range of future studies that estimate population distribution via remote sensing imagery.
On the Duality Between Retinex and Image Dehazing
Apr 06, 2018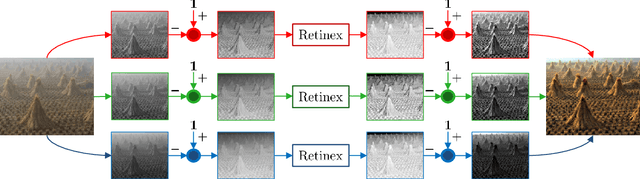
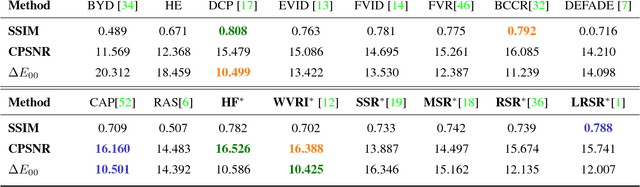

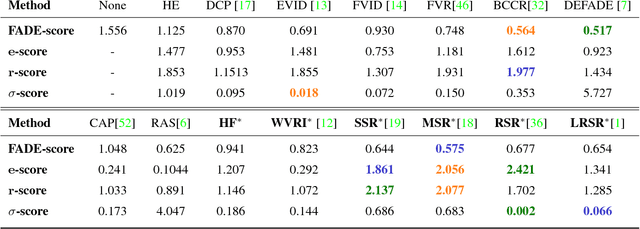
Image dehazing deals with the removal of undesired loss of visibility in outdoor images due to the presence of fog. Retinex is a color vision model mimicking the ability of the Human Visual System to robustly discount varying illuminations when observing a scene under different spectral lighting conditions. Retinex has been widely explored in the computer vision literature for image enhancement and other related tasks. While these two problems are apparently unrelated, the goal of this work is to show that they can be connected by a simple linear relationship. Specifically, most Retinex-based algorithms have the characteristic feature of always increasing image brightness, which turns them into ideal candidates for effective image dehazing by directly applying Retinex to a hazy image whose intensities have been inverted. In this paper, we give theoretical proof that Retinex on inverted intensities is a solution to the image dehazing problem. Comprehensive qualitative and quantitative results indicate that several classical and modern implementations of Retinex can be transformed into competing image dehazing algorithms performing on pair with more complex fog removal methods, and can overcome some of the main challenges associated with this problem.
Supervised learning for crop/weed classification based on color and texture features
Jun 19, 2021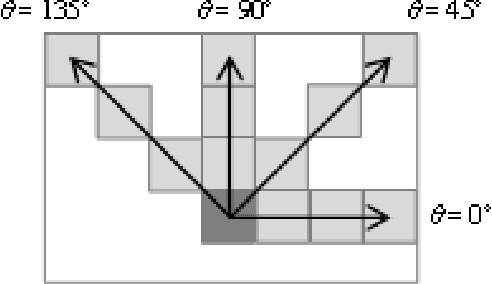

Computer vision techniques have attracted a great interest in precision agriculture, recently. The common goal of all computer vision-based precision agriculture tasks is to detect the objects of interest (e.g., crop, weed) and discriminating them from the background. The Weeds are unwanted plants growing among crops competing for nutrients, water, and sunlight, causing losses to crop yields. Weed detection and mapping is critical for site-specific weed management to reduce the cost of labor and impact of herbicides. This paper investigates the use of color and texture features for discrimination of Soybean crops and weeds. Feature extraction methods including two color spaces (RGB, HSV), gray level Co-occurrence matrix (GLCM), and Local Binary Pattern (LBP) are used to train the Support Vector Machine (SVM) classifier. The experiment was carried out on image dataset of soybean crop, obtained from an unmanned aerial vehicle (UAV), which is publicly available. The results from the experiment showed that the highest accuracy (above 96%) was obtained from the combination of color and LBP features.
MixStyle Neural Networks for Domain Generalization and Adaptation
Jul 05, 2021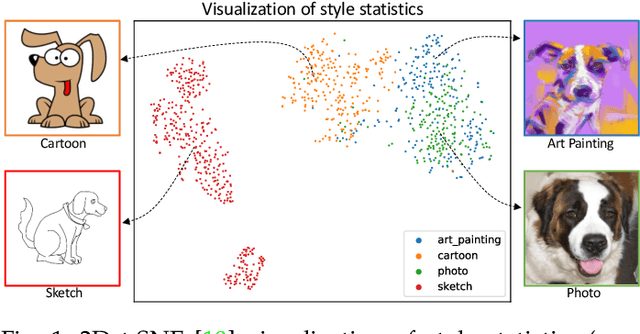
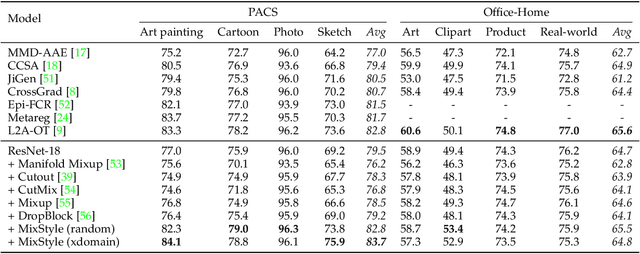
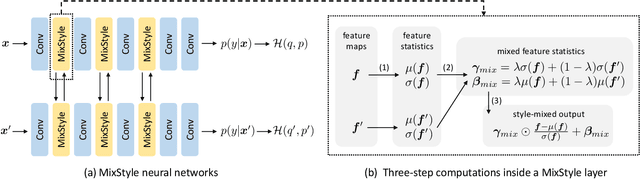
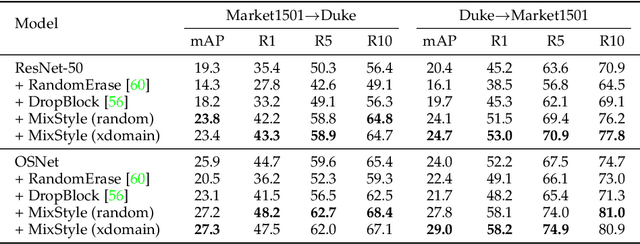
Convolutional neural networks (CNNs) often have poor generalization performance under domain shift. One way to improve domain generalization is to collect diverse source data from multiple relevant domains so that a CNN model is allowed to learn more domain-invariant, and hence generalizable representations. In this work, we address domain generalization with MixStyle, a plug-and-play, parameter-free module that is simply inserted to shallow CNN layers and requires no modification to training objectives. Specifically, MixStyle probabilistically mixes feature statistics between instances. This idea is inspired by the observation that visual domains can often be characterized by image styles which are in turn encapsulated within instance-level feature statistics in shallow CNN layers. Therefore, inserting MixStyle modules in effect synthesizes novel domains albeit in an implicit way. MixStyle is not only simple and flexible, but also versatile -- it can be used for problems whereby unlabeled images are available, such as semi-supervised domain generalization and unsupervised domain adaptation, with a simple extension to mix feature statistics between labeled and pseudo-labeled instances. We demonstrate through extensive experiments that MixStyle can significantly boost the out-of-distribution generalization performance across a wide range of tasks including object recognition, instance retrieval, and reinforcement learning.
JigsawGAN: Self-supervised Learning for Solving Jigsaw Puzzles with Generative Adversarial Networks
Jan 19, 2021
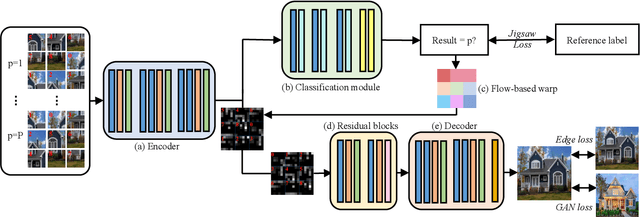
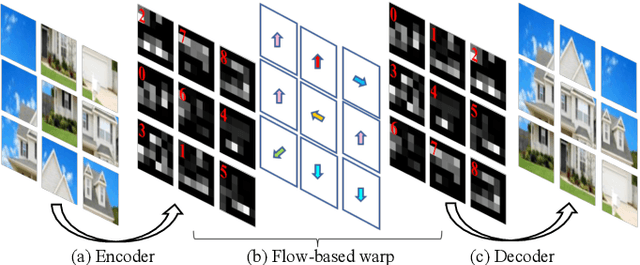

The paper proposes a solution based on Generative Adversarial Network (GAN) for solving jigsaw puzzles. The problem assumes that an image is cut into equal square pieces, and asks to recover the image according to pieces information. Conventional jigsaw solvers often determine piece relationships based on the piece boundaries, which ignore the important semantic information. In this paper, we propose JigsawGAN, a GAN-based self-supervised method for solving jigsaw puzzles with unpaired images (with no prior knowledge of the initial images). We design a multi-task pipeline that includes, (1) a classification branch to classify jigsaw permutations, and (2) a GAN branch to recover features to images with correct orders. The classification branch is constrained by the pseudo-labels generated according to the shuffled pieces. The GAN branch concentrates on the image semantic information, among which the generator produces the natural images to fool the discriminator with reassembled pieces, while the discriminator distinguishes whether a given image belongs to the synthesized or the real target manifold. These two branches are connected by a flow-based warp that is applied to warp features to correct order according to the classification results. The proposed method can solve jigsaw puzzles more efficiently by utilizing both semantic information and edge information simultaneously. Qualitative and quantitative comparisons against several leading prior methods demonstrate the superiority of our method.
DF^2AM: Dual-level Feature Fusion and Affinity Modeling for RGB-Infrared Cross-modality Person Re-identification
Apr 01, 2021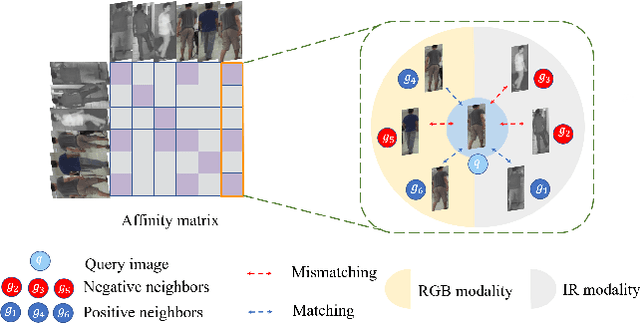
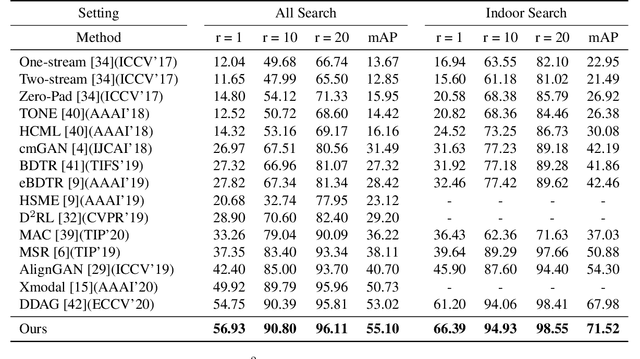
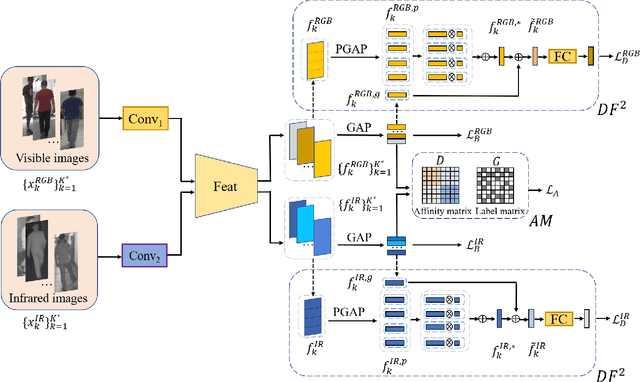
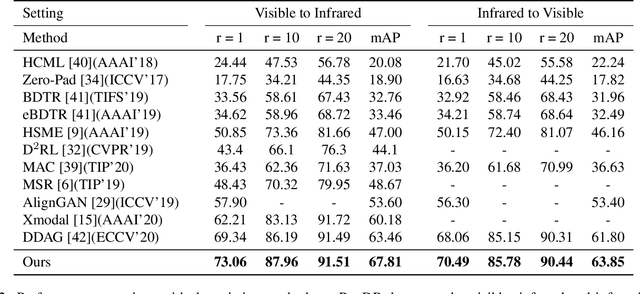
RGB-infrared person re-identification is a challenging task due to the intra-class variations and cross-modality discrepancy. Existing works mainly focus on learning modality-shared global representations by aligning image styles or feature distributions across modalities, while local feature from body part and relationships between person images are largely neglected. In this paper, we propose a Dual-level (i.e., local and global) Feature Fusion (DF^2) module by learning attention for discriminative feature from local to global manner. In particular, the attention for a local feature is determined locally, i.e., applying a learned transformation function on itself. Meanwhile, to further mining the relationships between global features from person images, we propose an Affinities Modeling (AM) module to obtain the optimal intra- and inter-modality image matching. Specifically, AM employes intra-class compactness and inter-class separability in the sample similarities as supervised information to model the affinities between intra- and inter-modality samples. Experimental results show that our proposed method outperforms state-of-the-arts by large margins on two widely used cross-modality re-ID datasets SYSU-MM01 and RegDB, respectively.
Domain Transformer: Predicting Samples of Unseen, Future Domains
Jun 10, 2021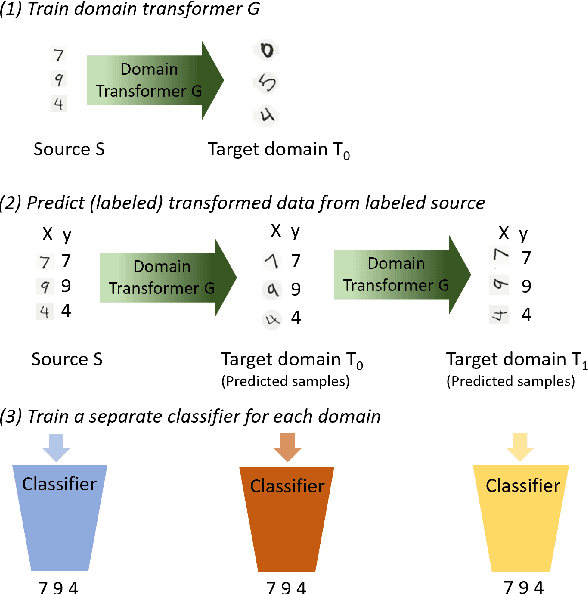
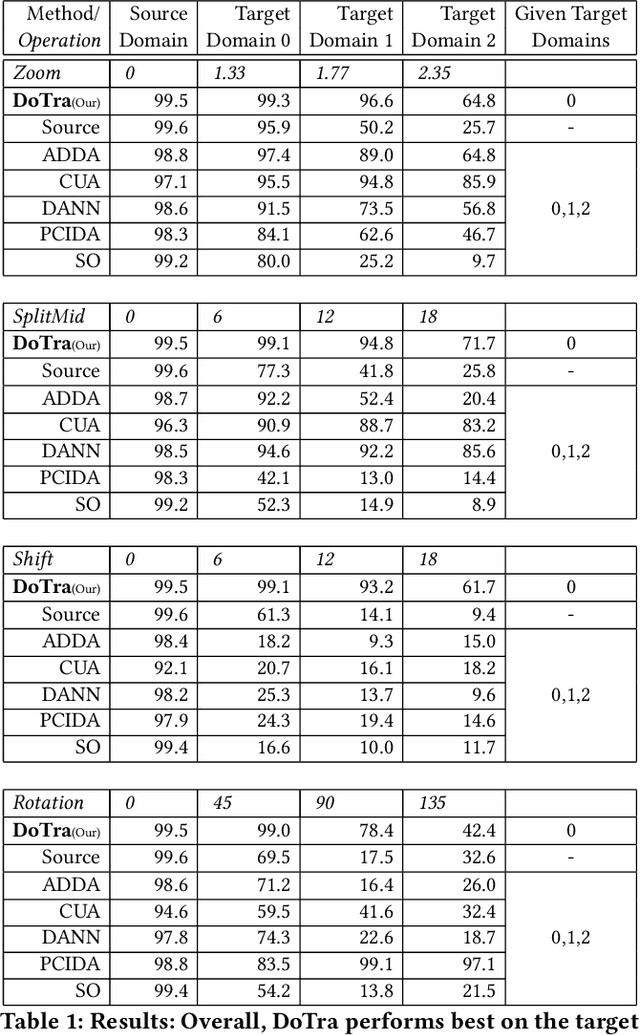
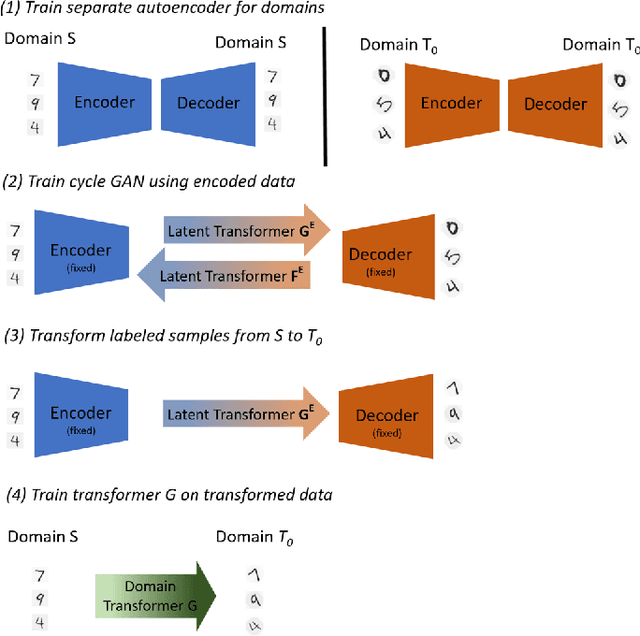

The data distribution commonly evolves over time leading to problems such as concept drift that often decrease classifier performance. We seek to predict unseen data (and their labels) allowing us to tackle challenges due to a non-constant data distribution in a \emph{proactive} manner rather than detecting and reacting to already existing changes that might already have led to errors. To this end, we learn a domain transformer in an unsupervised manner that allows generating data of unseen domains. Our approach first matches independently learned latent representations of two given domains obtained from an auto-encoder using a Cycle-GAN. In turn, a transformation of the original samples can be learned that can be applied iteratively to extrapolate to unseen domains. Our evaluation on CNNs on image data confirms the usefulness of the approach. It also achieves very good results on the well-known problem of unsupervised domain adaption, where labels but not samples have to be predicted.
Geographical Knowledge-driven Representation Learning for Remote Sensing Images
Jul 12, 2021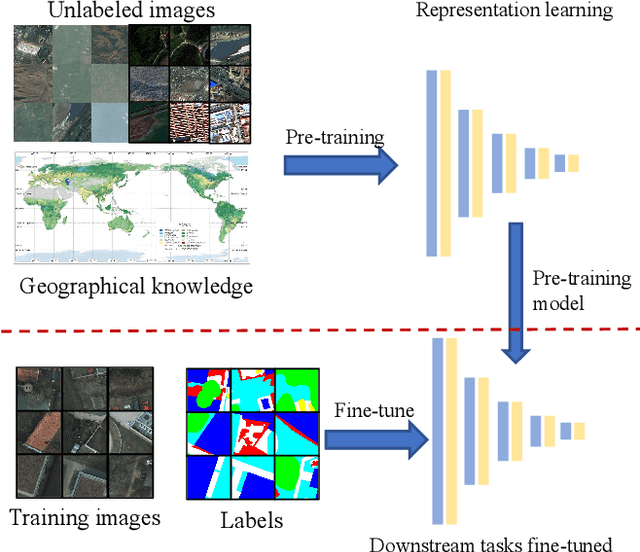
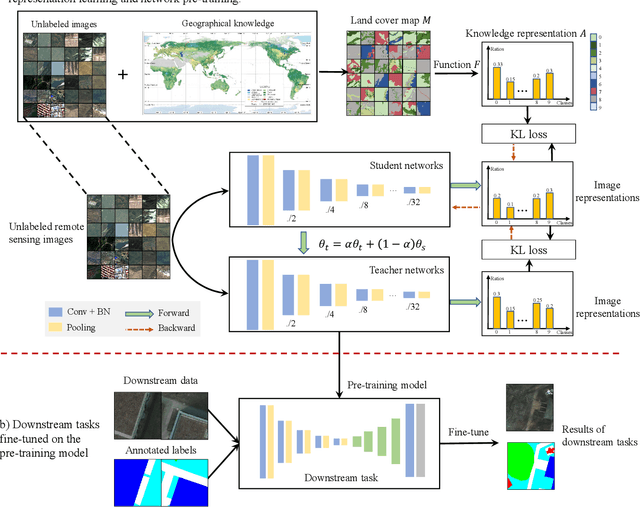
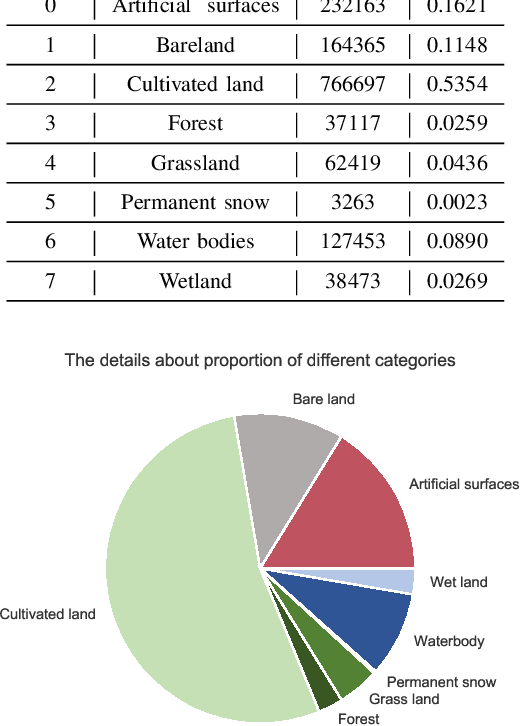
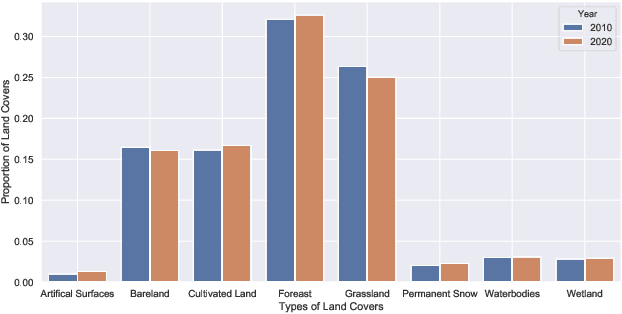
The proliferation of remote sensing satellites has resulted in a massive amount of remote sensing images. However, due to human and material resource constraints, the vast majority of remote sensing images remain unlabeled. As a result, it cannot be applied to currently available deep learning methods. To fully utilize the remaining unlabeled images, we propose a Geographical Knowledge-driven Representation learning method for remote sensing images (GeoKR), improving network performance and reduce the demand for annotated data. The global land cover products and geographical location associated with each remote sensing image are regarded as geographical knowledge to provide supervision for representation learning and network pre-training. An efficient pre-training framework is proposed to eliminate the supervision noises caused by imaging times and resolutions difference between remote sensing images and geographical knowledge. A large scale pre-training dataset Levir-KR is proposed to support network pre-training. It contains 1,431,950 remote sensing images from Gaofen series satellites with various resolutions. Experimental results demonstrate that our proposed method outperforms ImageNet pre-training and self-supervised representation learning methods and significantly reduces the burden of data annotation on downstream tasks such as scene classification, semantic segmentation, object detection, and cloud / snow detection. It demonstrates that our proposed method can be used as a novel paradigm for pre-training neural networks. Codes will be available on https://github.com/flyakon/Geographical-Knowledge-driven-Representaion-Learning.
Image Cartoon-Texture Decomposition Using Isotropic Patch Recurrence
Nov 10, 2018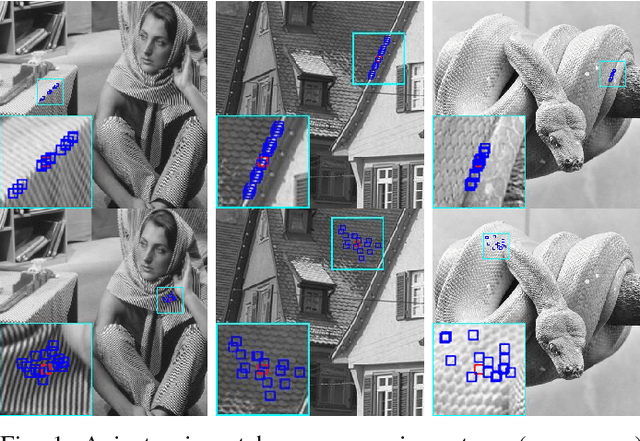
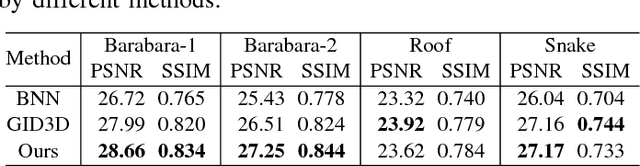

Aiming at separating the cartoon and texture layers from an image, cartoon-texture decomposition approaches resort to image priors to model cartoon and texture respectively. In recent years, patch recurrence has emerged as a powerful prior for image recovery. However, the existing strategies of using patch recurrence are ineffective to cartoon-texture decomposition, as both cartoon contours and texture patterns exhibit strong patch recurrence in images. To address this issue, we introduce the isotropy prior of patch recurrence, that the spatial configuration of similar patches in texture exhibits the isotropic structure which is different from that in cartoon, to model the texture component. Based on the isotropic patch recurrence, we construct a nonlocal sparsification system which can effectively distinguish well-patterned features from contour edges. Incorporating the constructed nonlocal system into morphology component analysis, we develop an effective method to both noiseless and noisy cartoon-texture decomposition. The experimental results have demonstrated the superior performance of the proposed method to the existing ones, as well as the effectiveness of the isotropic patch recurrence prior.
ForgeryNet: A Versatile Benchmark for Comprehensive Forgery Analysis
Mar 09, 2021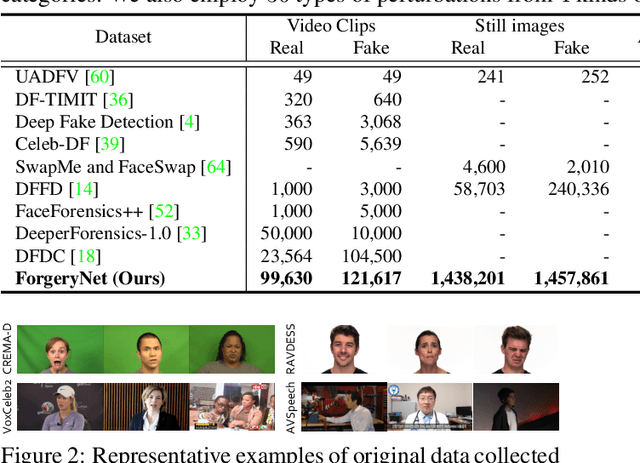
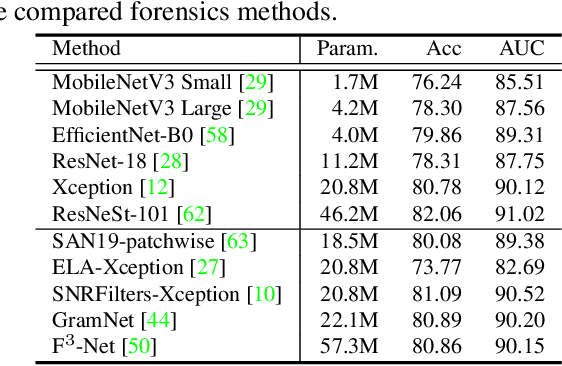

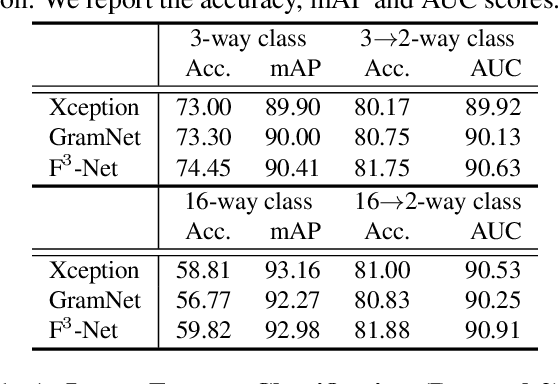
The rapid progress of photorealistic synthesis techniques has reached at a critical point where the boundary between real and manipulated images starts to blur. Thus, benchmarking and advancing digital forgery analysis have become a pressing issue. However, existing face forgery datasets either have limited diversity or only support coarse-grained analysis. To counter this emerging threat, we construct the ForgeryNet dataset, an extremely large face forgery dataset with unified annotations in image- and video-level data across four tasks: 1) Image Forgery Classification, including two-way (real / fake), three-way (real / fake with identity-replaced forgery approaches / fake with identity-remained forgery approaches), and n-way (real and 15 respective forgery approaches) classification. 2) Spatial Forgery Localization, which segments the manipulated area of fake images compared to their corresponding source real images. 3) Video Forgery Classification, which re-defines the video-level forgery classification with manipulated frames in random positions. This task is important because attackers in real world are free to manipulate any target frame. and 4) Temporal Forgery Localization, to localize the temporal segments which are manipulated. ForgeryNet is by far the largest publicly available deep face forgery dataset in terms of data-scale (2.9 million images, 221,247 videos), manipulations (7 image-level approaches, 8 video-level approaches), perturbations (36 independent and more mixed perturbations) and annotations (6.3 million classification labels, 2.9 million manipulated area annotations and 221,247 temporal forgery segment labels). We perform extensive benchmarking and studies of existing face forensics methods and obtain several valuable observations.