 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-Modal Analysis of Human Detection for Robotics: An Industrial Case Study
Aug 03, 2021

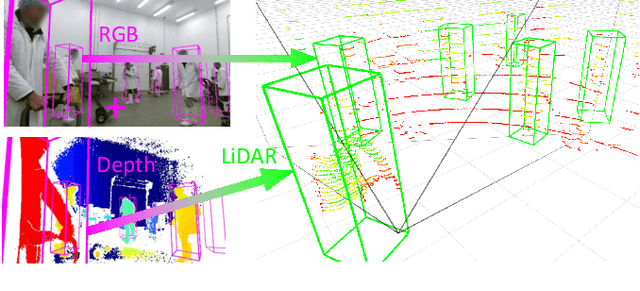
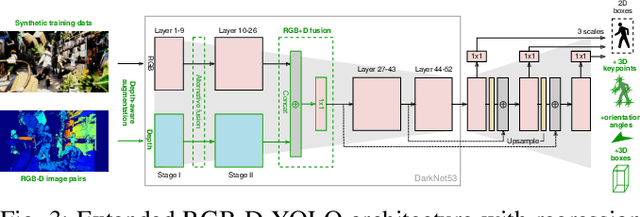
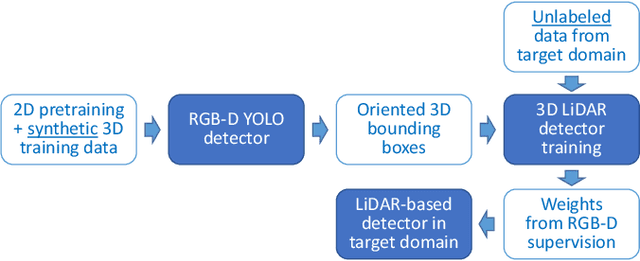
Advances in sensing and learning algorithms have led to increasingly mature solutions for human detection by robots, particularly in selected use-cases such as pedestrian detection for self-driving cars or close-range person detection in consumer settings. Despite this progress, the simple question "which sensor-algorithm combination is best suited for a person detection task at hand?" remains hard to answer. In this paper, we tackle this issue by conducting a systematic cross-modal analysis of sensor-algorithm combinations typically used in robotics. We compare the performance of state-of-the-art person detectors for 2D range data, 3D lidar, and RGB-D data as well as selected combinations thereof in a challenging industrial use-case. We further address the related problems of data scarcity in the industrial target domain, and that recent research on human detection in 3D point clouds has mostly focused on autonomous driving scenarios. To leverage these methodological advances for robotics applications, we utilize a simple, yet effective multi-sensor transfer learning strategy by extending a strong image-based RGB-D detector to provide cross-modal supervision for lidar detectors in the form of weak 3D bounding box labels. Our results show a large variance among the different approaches in terms of detection performance, generalization, frame rates and computational requirements. As our use-case contains difficulties representative for a wide range of service robot applications, we believe that these results point to relevant open challenges for further research and provide valuable support to practitioners for the design of their robot system.
A Multiple Source Hourglass Deep Network for Multi-Focus Image Fusion
Aug 28, 2019
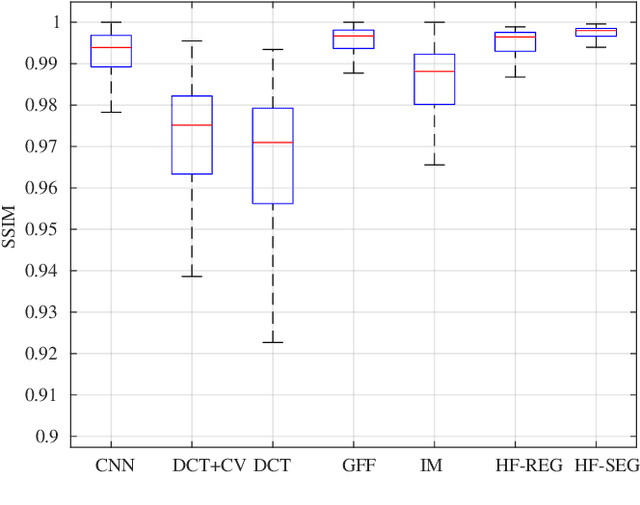

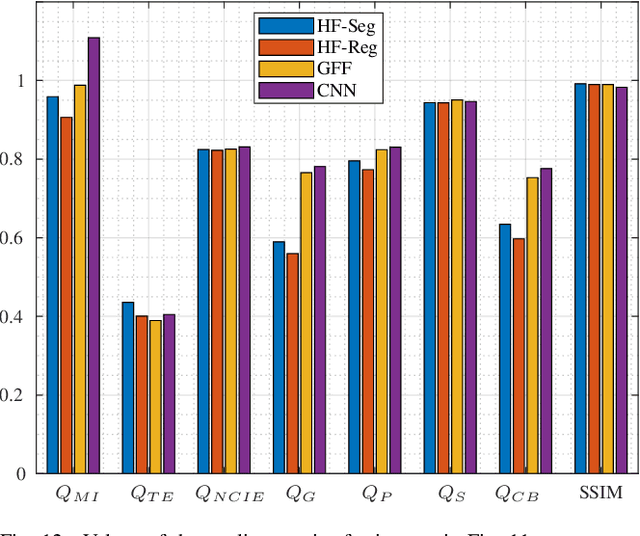
Multi-Focus Image Fusion seeks to improve the quality of an acquired burst of images with different focus planes. For solving the task, an activity level measurement and a fusion rule are typically established to select and fuse the most relevant information from the sources. However, the design of this kind of method by hand is really hard and sometimes restricted to solution spaces where the optimal all-in-focus images are not contained. Then, we propose here two fast and straightforward approaches for image fusion based on deep neural networks. Our solution uses a multiple source Hourglass architecture trained in an end-to-end fashion. Models are data-driven and can be easily generalized for other kinds of fusion problems. A segmentation approach is used for recognition of the focus map, while the weighted average rule is used for fusion. We designed a training loss function for our regression-based fusion function, which allows the network to learn both the activity level measurement and the fusion rule. Experimental results show our approach has comparable results to the state-of-the-art methods with a 60X increase of computational efficiency for 520X520 resolution images.
How to represent part-whole hierarchies in a neural network
Feb 25, 2021
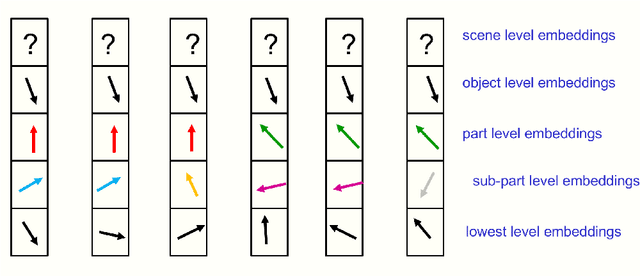
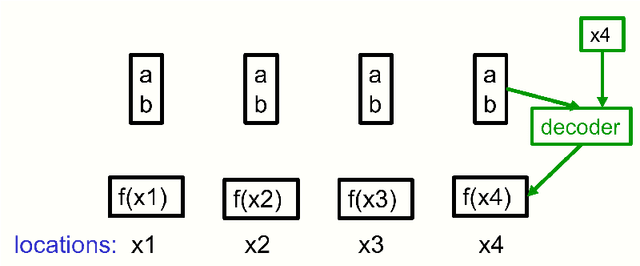
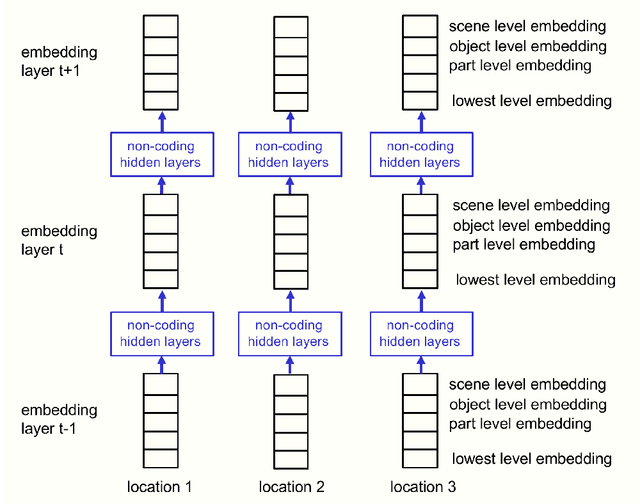
This paper does not describe a working system. Instead, it presents a single idea about representation which allows advances made by several different groups to be combined into an imaginary system called GLOM. The advances include transformers, neural fields, contrastive representation learning, distillation and capsules. GLOM answers the question: How can a neural network with a fixed architecture parse an image into a part-whole hierarchy which has a different structure for each image? The idea is simply to use islands of identical vectors to represent the nodes in the parse tree. If GLOM can be made to work, it should significantly improve the interpretability of the representations produced by transformer-like systems when applied to vision or language
Adaptive image-feature learning for disease classification using inductive graph networks
May 08, 2019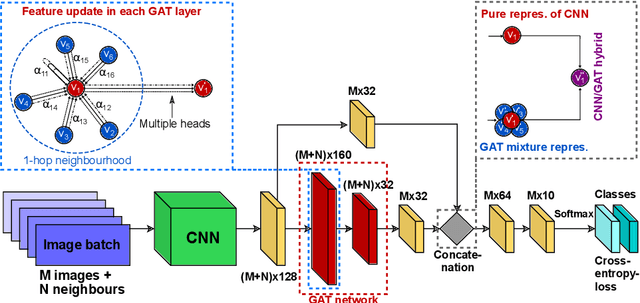
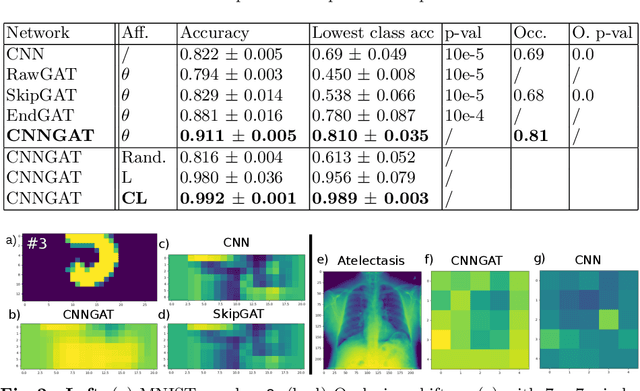

Recently, Geometric Deep Learning (GDL) has been introduced as a novel and versatile framework for computer-aided disease classification. GDL uses patient meta-information such as age and gender to model patient cohort relations in a graph structure. Concepts from graph signal processing are leveraged to learn the optimal mapping of multi-modal features, e.g. from images to disease classes. Related studies so far have considered image features that are extracted in a pre-processing step. We hypothesize that such an approach prevents the network from optimizing feature representations towards achieving the best performance in the graph network. We propose a new network architecture that exploits an inductive end-to-end learning approach for disease classification, where filters from both the CNN and the graph are trained jointly. We validate this architecture against state-of-the-art inductive graph networks and demonstrate significantly improved classification scores on a modified MNIST toy dataset, as well as comparable classification results with higher stability on a chest X-ray image dataset. Additionally, we explain how the structural information of the graph affects both the image filters and the feature learning.
Red blood cell image generation for data augmentation using Conditional Generative Adversarial Networks
Jan 18, 2019

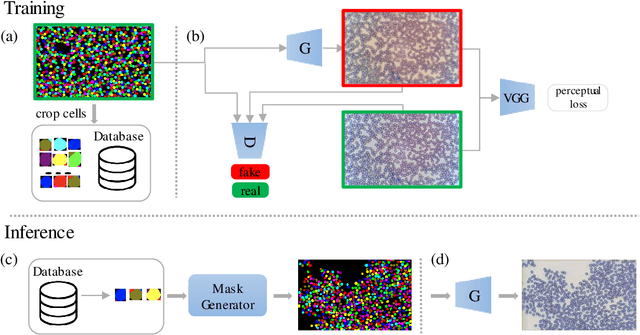
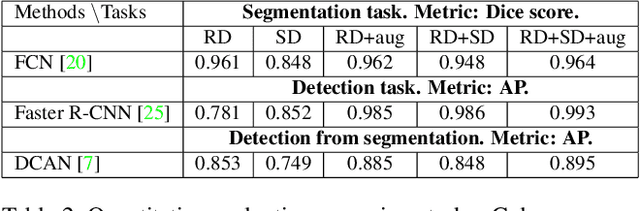
In this paper, we describe how to apply image-to-image translation techniques to medical blood smear data to generate new data samples and meaningfully increase small datasets. Specifically, given the segmentation mask of the microscopy image, we are able to generate photorealistic images of blood cells which are further used alongside real data during the network training for segmentation and object detection tasks. This image data generation approach is based on conditional generative adversarial networks which have proven capabilities to high-quality image synthesis. In addition to synthesizing blood images, we synthesize segmentation mask as well which leads to a diverse variety of generated samples. The effectiveness of the technique is thoroughly analyzed and quantified through a number of experiments on a manually collected and annotated dataset of blood smear taken under a microscope.
What and When to Look?: Temporal Span Proposal Network for Video Visual Relation Detection
Jul 15, 2021
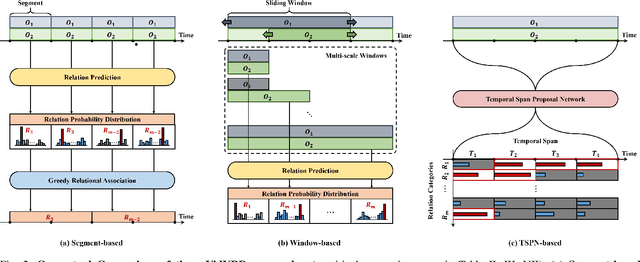
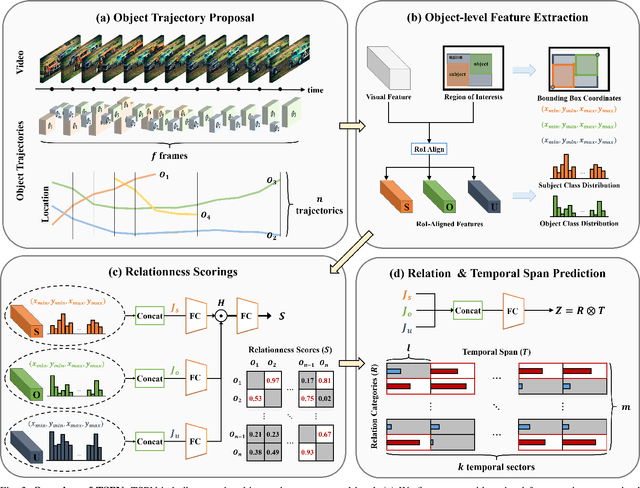

Identifying relations between objects is central to understanding the scene. While several works have been proposed for relation modeling in the image domain, there have been many constraints in the video domain due to challenging dynamics of spatio-temporal interactions (e.g., Between which objects are there an interaction? When do relations occur and end?). To date, two representative methods have been proposed to tackle Video Visual Relation Detection (VidVRD): segment-based and window-based. We first point out the limitations these two methods have and propose Temporal Span Proposal Network (TSPN), a novel method with two advantages in terms of efficiency and effectiveness. 1) TSPN tells what to look: it sparsifies relation search space by scoring relationness (i.e., confidence score for the existence of a relation between pair of objects) of object pair. 2) TSPN tells when to look: it leverages the full video context to simultaneously predict the temporal span and categories of the entire relations. TSPN demonstrates its effectiveness by achieving new state-of-the-art by a significant margin on two VidVRD benchmarks (ImageNet-VidVDR and VidOR) while also showing lower time complexity than existing methods - in particular, twice as efficient as a popular segment-based approach.
Co-matching: Combating Noisy Labels by Augmentation Anchoring
Mar 23, 2021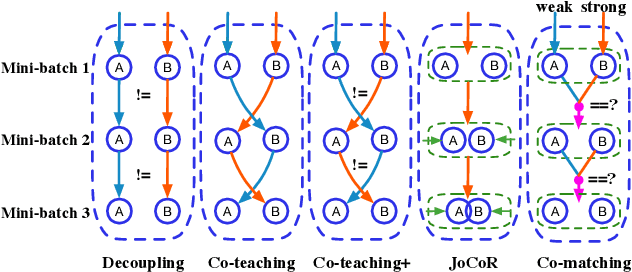
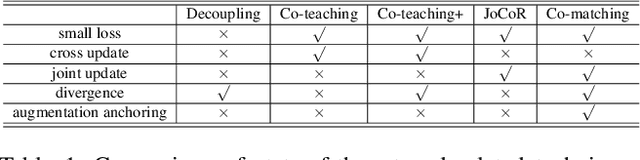
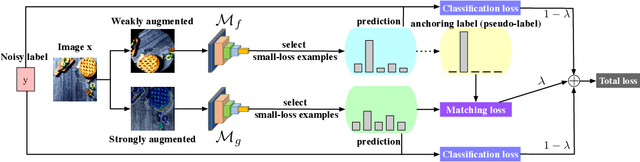

Deep learning with noisy labels is challenging as deep neural networks have the high capacity to memorize the noisy labels. In this paper, we propose a learning algorithm called Co-matching, which balances the consistency and divergence between two networks by augmentation anchoring. Specifically, we have one network generate anchoring label from its prediction on a weakly-augmented image. Meanwhile, we force its peer network, taking the strongly-augmented version of the same image as input, to generate prediction close to the anchoring label. We then update two networks simultaneously by selecting small-loss instances to minimize both unsupervised matching loss (i.e., measure the consistency of the two networks) and supervised classification loss (i.e. measure the classification performance). Besides, the unsupervised matching loss makes our method not heavily rely on noisy labels, which prevents memorization of noisy labels. Experiments on three benchmark datasets demonstrate that Co-matching achieves results comparable to the state-of-the-art methods.
Speeding up scaled gradient projection methods using deep neural networks for inverse problems in image processing
Feb 07, 2019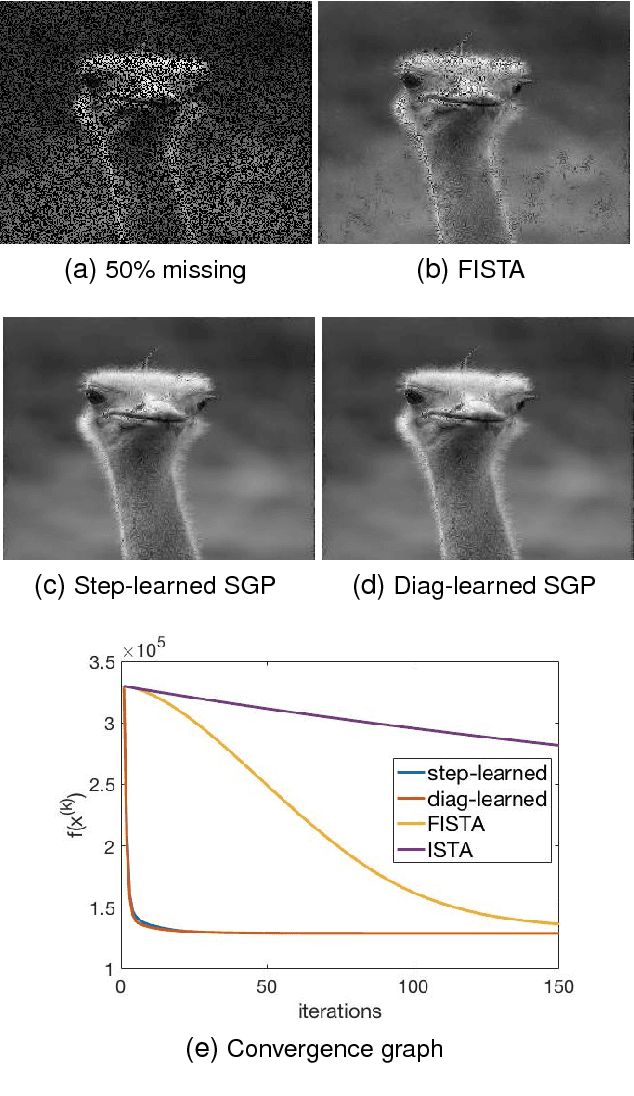
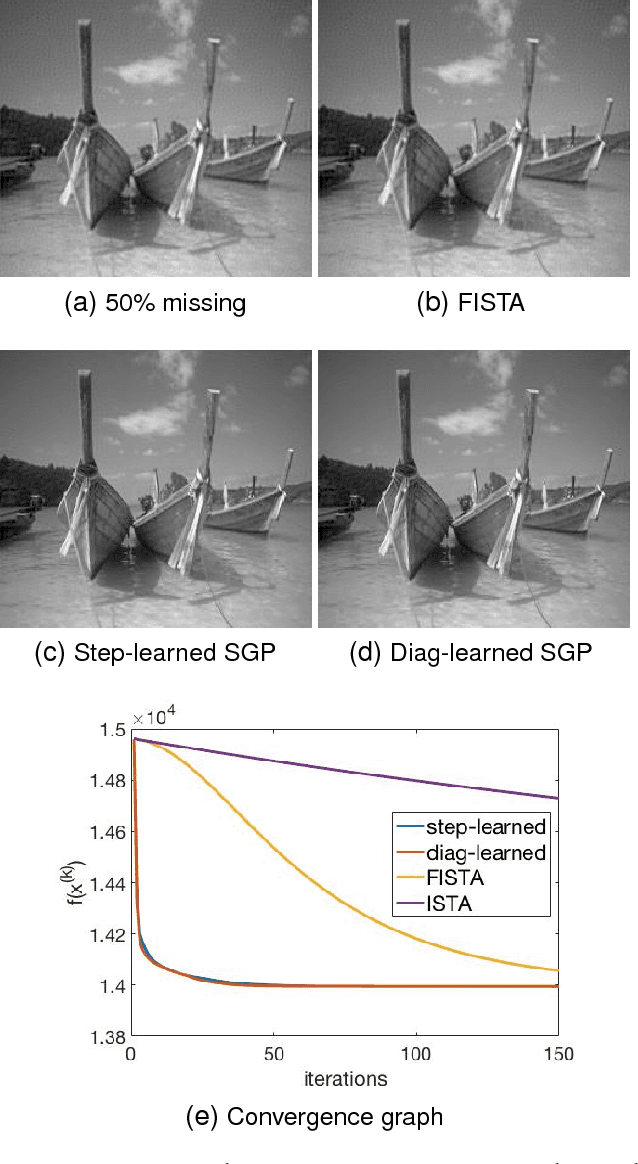
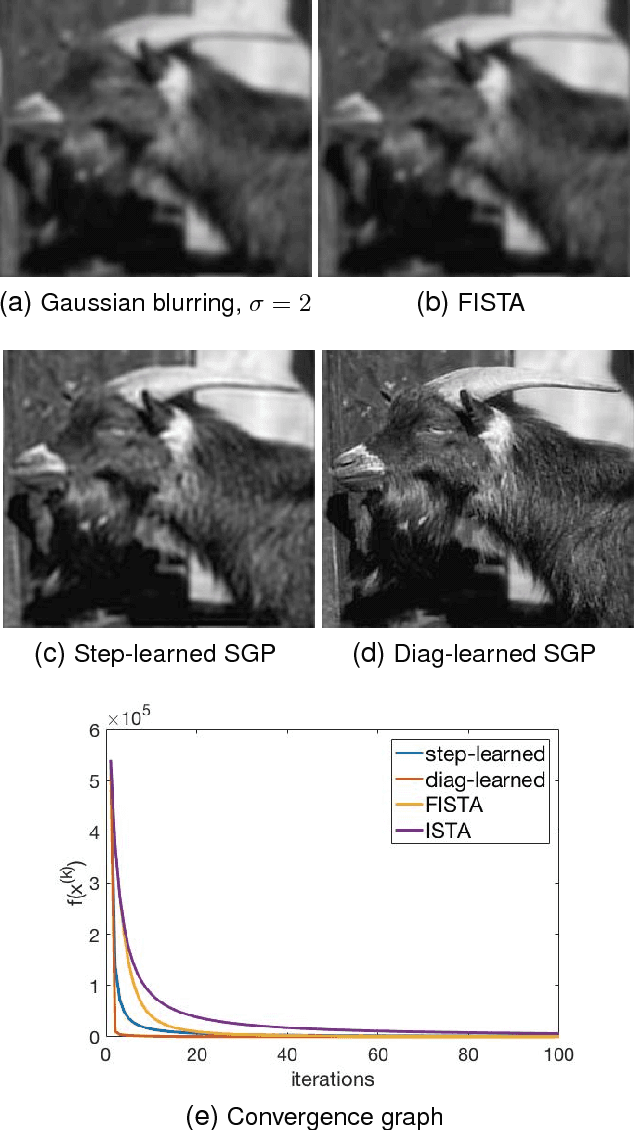
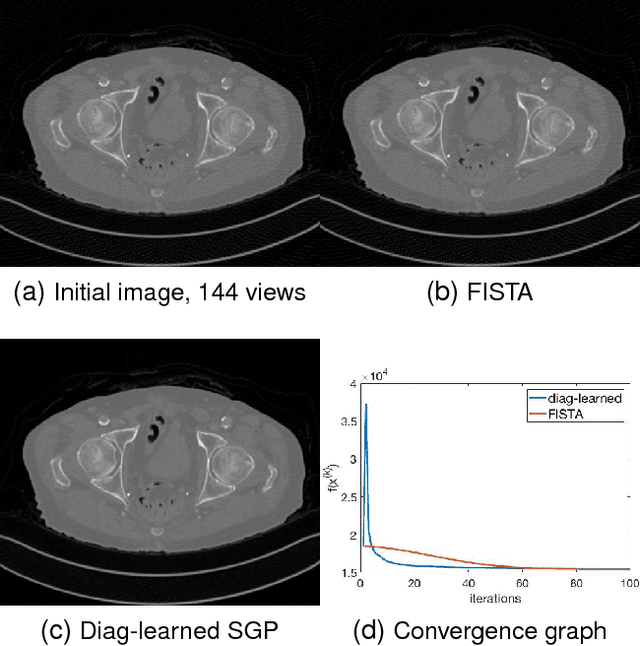
Conventional optimization based methods have utilized forward models with image priors to solve inverse problems in image processing. Recently, deep neural networks (DNN) have been investigated to significantly improve the image quality of the solution for inverse problems. Most DNN based inverse problems have focused on using data-driven image priors with massive amount of data. However, these methods often do not inherit nice properties of conventional approaches using theoretically well-grounded optimization algorithms such as monotone, global convergence. Here we investigate another possibility of using DNN for inverse problems in image processing. We propose methods to use DNNs to seamlessly speed up convergence rates of conventional optimization based methods. Our DNN-incorporated scaled gradient projection methods, without breaking theoretical properties, significantly improved convergence speed over state-of-the-art conventional optimization methods such as ISTA or FISTA in practice for inverse problems such as image inpainting, compressive image recovery with partial Fourier samples, image deblurring, and medical image reconstruction with sparse-view projections.
Doc2Im: document to image conversion through self-attentive embedding
Nov 08, 2018
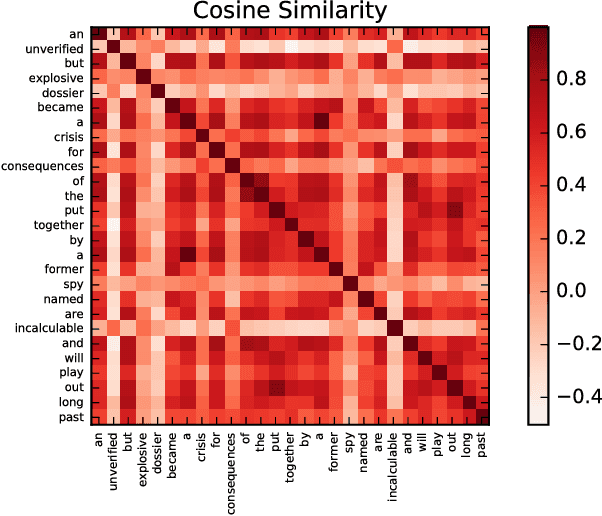
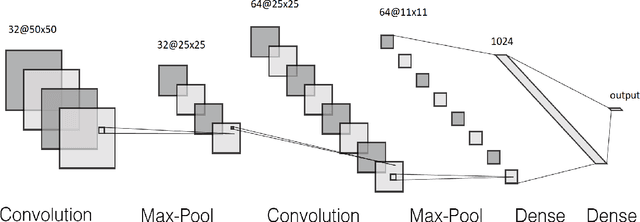
Text classification is a fundamental task in NLP applications. Latest research in this field has largely been divided into two major sub-fields. Learning representations is one sub-field and learning deeper models, both sequential and convolutional, which again connects back to the representation is the other side. We posit the idea that the stronger the representation is, the simpler classifier models are needed to achieve higher performance. In this paper we propose a completely novel direction to text classification research, wherein we convert text to a representation very similar to images, such that any deep network able to handle images is equally able to handle text. We take a deeper look at the representation of documents as an image and subsequently utilize very simple convolution based models taken as is from computer vision domain. This image can be cropped, re-scaled, re-sampled and augmented just like any other image to work with most of the state-of-the-art large convolution based models which have been designed to handle large image datasets. We show impressive results with some of the latest benchmarks in the related fields. We perform transfer learning experiments, both from text to text domain and also from image to text domain. We believe this is a paradigm shift from the way document understanding and text classification has been traditionally done, and will drive numerous novel research ideas in the community.
No-Reference Color Image Quality Assessment: From Entropy to Perceptual Quality
Dec 27, 2018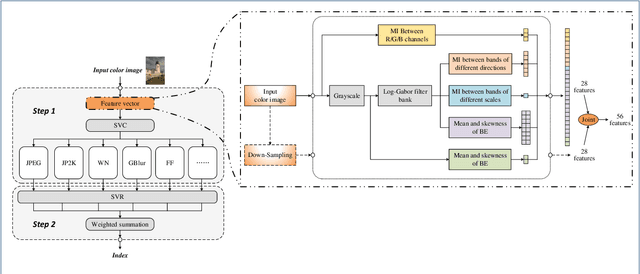

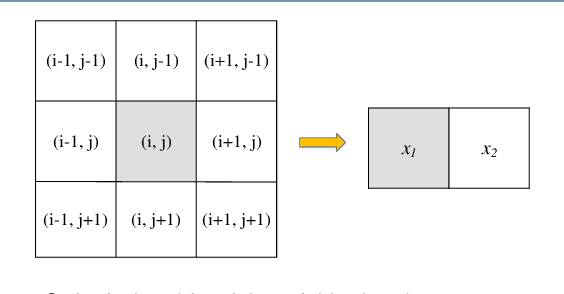
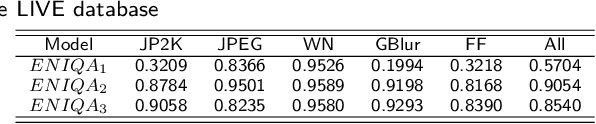
This paper presents a high-performance general-purpose no-reference (NR) image quality assessment (IQA) method based on image entropy. The image features are extracted from two domains. In the spatial domain, the mutual information between the color channels and the two-dimensional entropy are calculated. In the frequency domain, the two-dimensional entropy and the mutual information of the filtered sub-band images are computed as the feature set of the input color image. Then, with all the extracted features, the support vector classifier (SVC) for distortion classification and support vector regression (SVR) are utilized for the quality prediction, to obtain the final quality assessment score. The proposed method, which we call entropy-based no-reference image quality assessment (ENIQA), can assess the quality of different categories of distorted images, and has a low complexity. The proposed ENIQA method was assessed on the LIVE and TID2013 databases and showed a superior performance. The experimental results confirmed that the proposed ENIQA method has a high consistency of objective and subjective assessment on color images, which indicates the good overall performance and generalization ability of ENIQA. The source code is available on github https://github.com/jacob6/ENIQA.