 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Informed MCMC with Bayesian Neural Networks for Facial Image Analysis
Nov 29, 2018
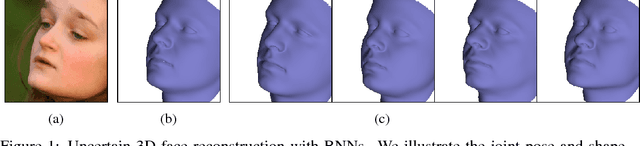
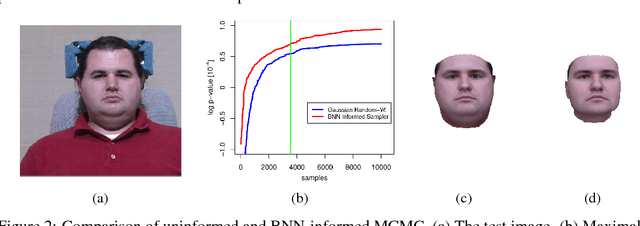
Computer vision tasks are difficult because of the large variability in the data that is induced by changes in light, background, partial occlusion as well as the varying pose, texture, and shape of objects. Generative approaches to computer vision allow us to overcome this difficulty by explicitly modeling the physical image formation process. Using generative object models, the analysis of an observed image is performed via Bayesian inference of the posterior distribution. This conceptually simple approach tends to fail in practice because of several difficulties stemming from sampling the posterior distribution: high-dimensionality and multi-modality of the posterior distribution as well as expensive simulation of the rendering process. The main difficulty of sampling approaches in a computer vision context is choosing the proposal distribution accurately so that maxima of the posterior are explored early and the algorithm quickly converges to a valid image interpretation. In this work, we propose to use a Bayesian Neural Network for estimating an image dependent proposal distribution. Compared to a standard Gaussian random walk proposal, this accelerates the sampler in finding regions of the posterior with high value. In this way, we can significantly reduce the number of samples needed to perform facial image analysis.
Effectiveness of regional diffusion MRI measures in distinguishing multiple sclerosis abnormalities within the cervical spinal cord
Aug 09, 2021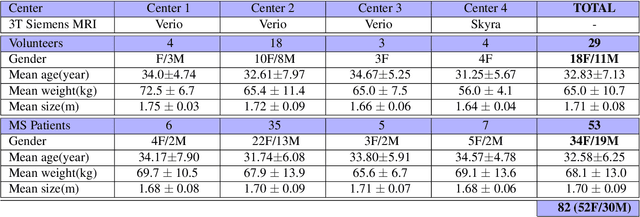
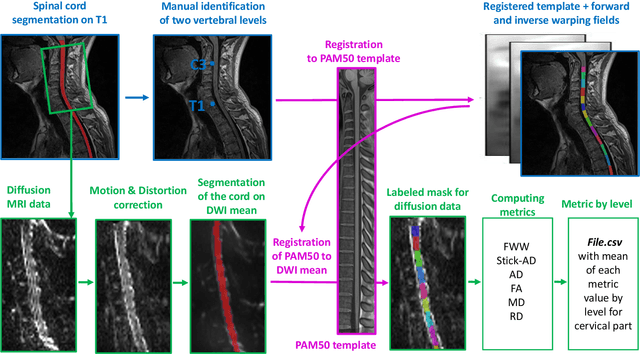
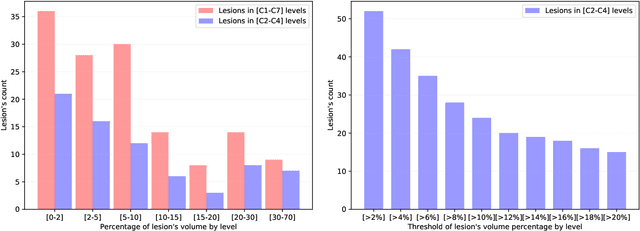
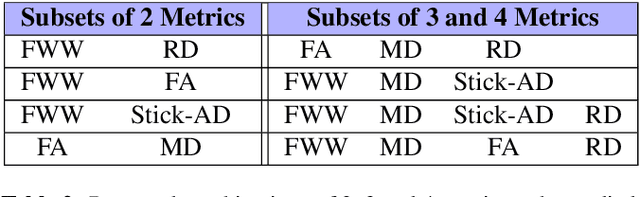
Multiple sclerosis is an inflammatory disorder of the central nervous system. Quantitative MRI has huge potential to provide intrinsic and normative values of tissue properties useful for diagnosis, prognosis and ultimately clinical follow-up of this disease. However, there is a large discrepancy between the clinical observations and how the pathology is exhibited in MRI brain scans. Complementary to brain imaging, the study of multiple sclerosis lesions in the spinal cord has recently gained interest as a potential marker for early physical impairment. Therefore, investigating how the spinal cord is damaged using quantitative imaging, in particular, diffusion MRI, becomes an acute challenge. In this work, we extract average diffusion MRI metrics per vertebral level from spinal cord data acquired from multiple clinical sites. The diffusion-based metrics involved are extracted from the diffusion tensor imaging and Ball-and-Stick models and quantified for every cervical vertebral level using a collection of image processing methods and an atlas-based approach. Then, we perform a statistical analysis study to characterize the feasibility of these metrics to detect lesions. Specifically, we study the usefulness of combining different metrics to improve the accuracy prediction score associated with the presence of multiple sclerosis lesions. We demonstrate the grade of sensitivity to underlying microstructure changes in MS patients of each metric. Ball-and-Stick provides novel information about the MS damage to tissue microstructure. In addition, we show that choosing a subset of metrics: [FA, RD, MD] and [FWW, MD, Stick-AD, RD], which bring complementary information, has significantly increased the prediction score of the presence of the MS lesion in the cervical spinal cord.
DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort
Apr 20, 2021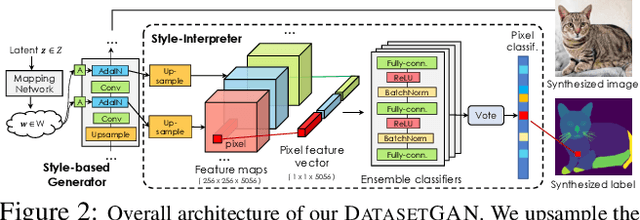
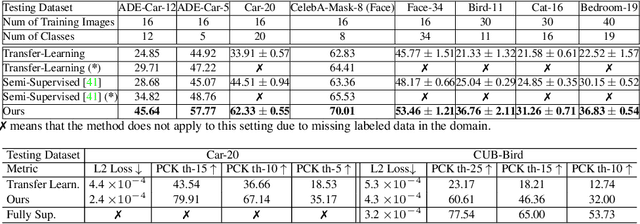
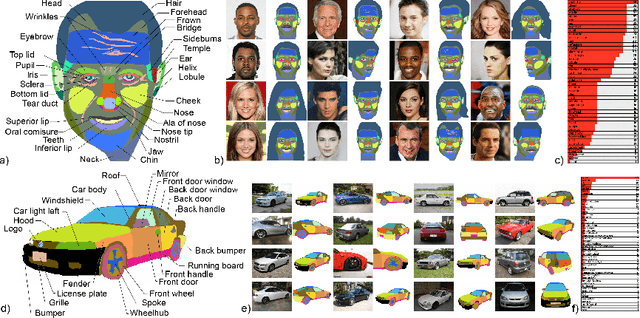
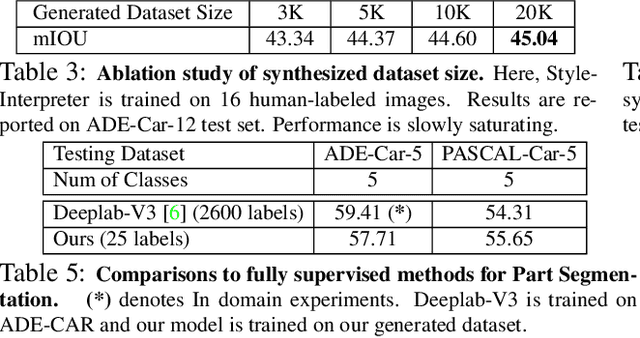
We introduce DatasetGAN: an automatic procedure to generate massive datasets of high-quality semantically segmented images requiring minimal human effort. Current deep networks are extremely data-hungry, benefiting from training on large-scale datasets, which are time consuming to annotate. Our method relies on the power of recent GANs to generate realistic images. We show how the GAN latent code can be decoded to produce a semantic segmentation of the image. Training the decoder only needs a few labeled examples to generalize to the rest of the latent space, resulting in an infinite annotated dataset generator! These generated datasets can then be used for training any computer vision architecture just as real datasets are. As only a few images need to be manually segmented, it becomes possible to annotate images in extreme detail and generate datasets with rich object and part segmentations. To showcase the power of our approach, we generated datasets for 7 image segmentation tasks which include pixel-level labels for 34 human face parts, and 32 car parts. Our approach outperforms all semi-supervised baselines significantly and is on par with fully supervised methods, which in some cases require as much as 100x more annotated data as our method.
Rethinking of Pedestrian Attribute Recognition: A Reliable Evaluation under Zero-Shot Pedestrian Identity Setting
Jul 08, 2021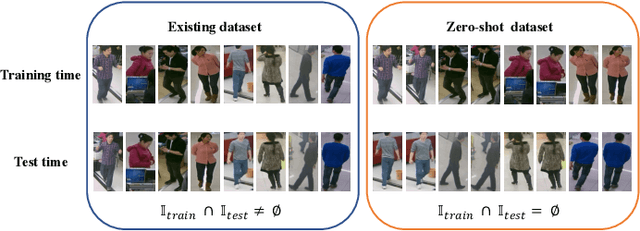


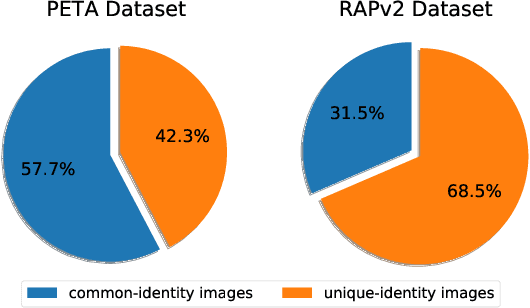
Pedestrian attribute recognition aims to assign multiple attributes to one pedestrian image captured by a video surveillance camera. Although numerous methods are proposed and make tremendous progress, we argue that it is time to step back and analyze the status quo of the area. We review and rethink the recent progress from three perspectives. First, given that there is no explicit and complete definition of pedestrian attribute recognition, we formally define and distinguish pedestrian attribute recognition from other similar tasks. Second, based on the proposed definition, we expose the limitations of the existing datasets, which violate the academic norm and are inconsistent with the essential requirement of practical industry application. Thus, we propose two datasets, PETA\textsubscript{$ZS$} and RAP\textsubscript{$ZS$}, constructed following the zero-shot settings on pedestrian identity. In addition, we also introduce several realistic criteria for future pedestrian attribute dataset construction. Finally, we reimplement existing state-of-the-art methods and introduce a strong baseline method to give reliable evaluations and fair comparisons. Experiments are conducted on four existing datasets and two proposed datasets to measure progress on pedestrian attribute recognition.
Direct multimodal few-shot learning of speech and images
Dec 10, 2020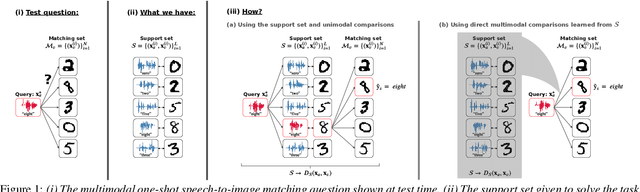

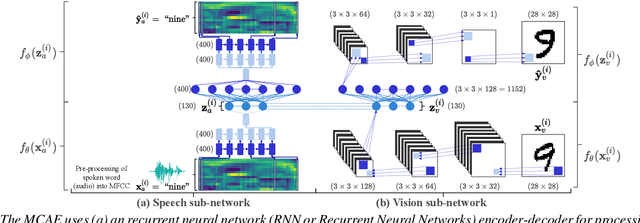
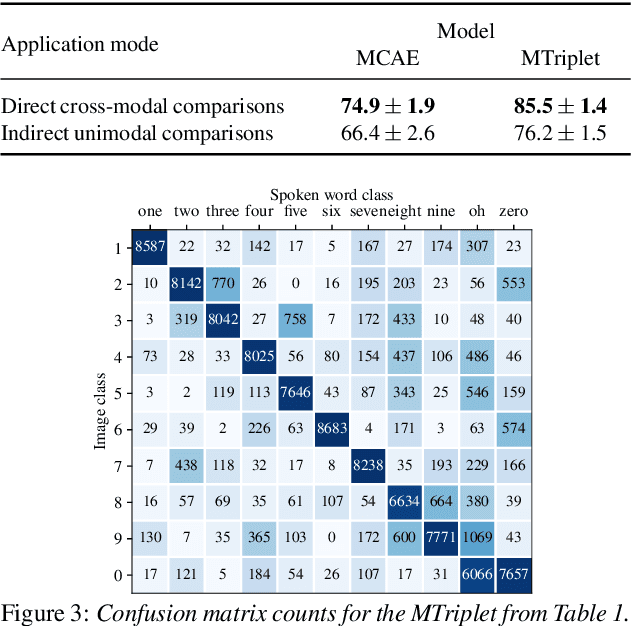
We propose direct multimodal few-shot models that learn a shared embedding space of spoken words and images from only a few paired examples. Imagine an agent is shown an image along with a spoken word describing the object in the picture, e.g. pen, book and eraser. After observing a few paired examples of each class, the model is asked to identify the "book" in a set of unseen pictures. Previous work used a two-step indirect approach relying on learned unimodal representations: speech-speech and image-image comparisons are performed across the support set of given speech-image pairs. We propose two direct models which instead learn a single multimodal space where inputs from different modalities are directly comparable: a multimodal triplet network (MTriplet) and a multimodal correspondence autoencoder (MCAE). To train these direct models, we mine speech-image pairs: the support set is used to pair up unlabelled in-domain speech and images. In a speech-to-image digit matching task, direct models outperform indirect models, with the MTriplet achieving the best multimodal five-shot accuracy. We show that the improvements are due to the combination of unsupervised and transfer learning in the direct models, and the absence of two-step compounding errors.
Increasing the robustness of DNNs against image corruptions by playing the Game of Noise
Feb 26, 2020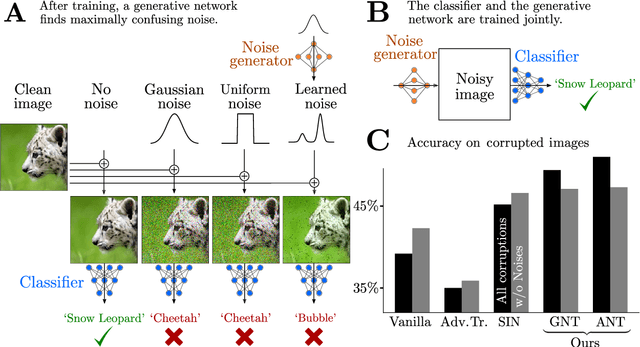
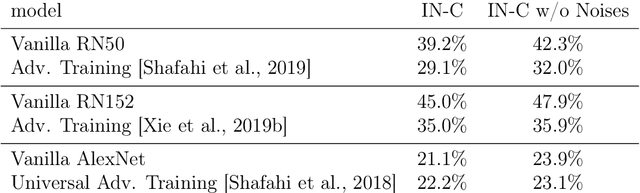
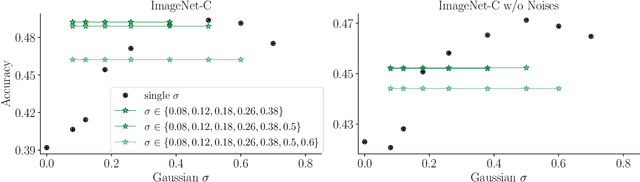
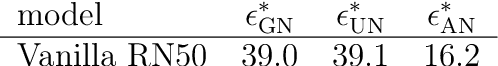
The human visual system is remarkably robust against a wide range of naturally occurring variations and corruptions like rain or snow. In contrast, the performance of modern image recognition models strongly degrades when evaluated on previously unseen corruptions. Here, we demonstrate that a simple but properly tuned training with additive Gaussian and Speckle noise generalizes surprisingly well to unseen corruptions, easily reaching the previous state of the art on the corruption benchmark ImageNet-C (with ResNet50) and on MNIST-C. We build on top of these strong baseline results and show that an adversarial training of the recognition model against uncorrelated worst-case noise distributions leads to an additional increase in performance. This regularization can be combined with previously proposed defense methods for further improvement.
Benefits of Linear Conditioning for Segmentation using Metadata
Feb 18, 2021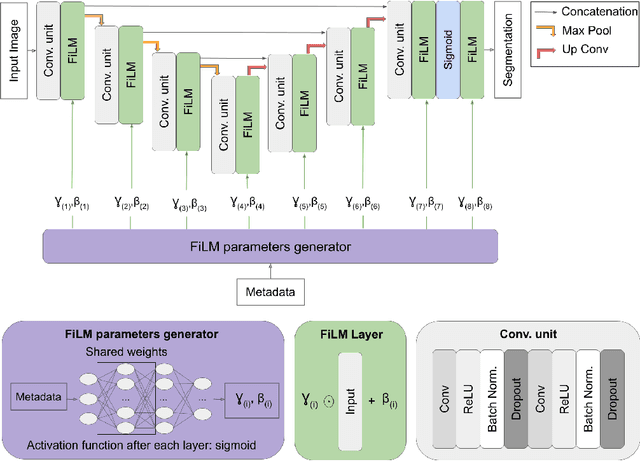
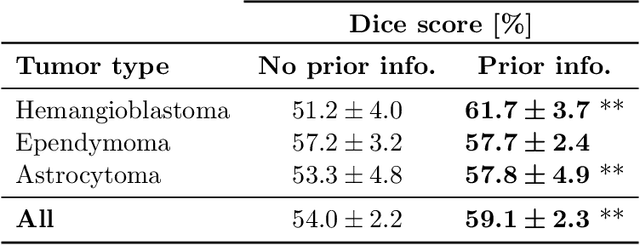
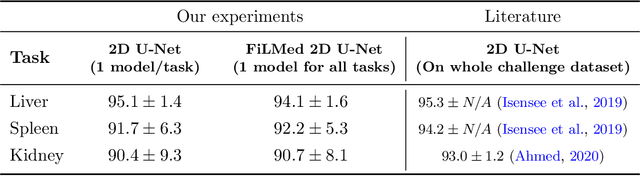
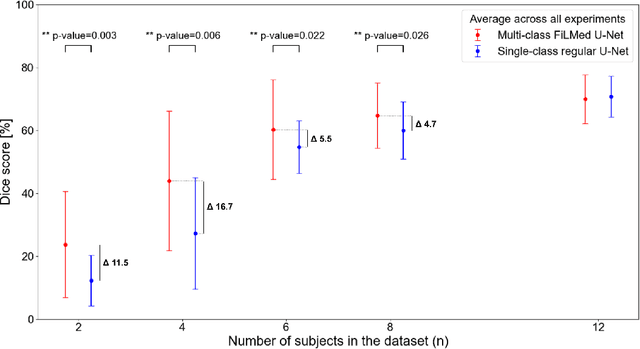
Medical images are often accompanied by metadata describing the image (vendor, acquisition parameters) and the patient (disease type or severity, demographics, genomics). This metadata is usually disregarded by image segmentation methods. In this work, we adapt a linear conditioning method called FiLM (Feature-wise Linear Modulation) for image segmentation tasks. This FiLM adaptation enables integrating metadata into segmentation models for better performance. We observed an average Dice score increase of 5.1% on spinal cord tumor segmentation when incorporating the tumor type with FiLM. The metadata modulates the segmentation process through low-cost affine transformations applied on feature maps which can be included in any neural network's architecture. Additionally, we assess the relevance of segmentation FiLM layers for tackling common challenges in medical imaging: training with limited or unbalanced number of annotated data, multi-class training with missing segmentations, and model adaptation to multiple tasks. Our results demonstrated the following benefits of FiLM for segmentation: FiLMed U-Net was robust to missing labels and reached higher Dice scores with few labels (up to 16.7%) compared to single-task U-Net. The code is open-source and available at www.ivadomed.org.
Multirate Training of Neural Networks
Jun 20, 2021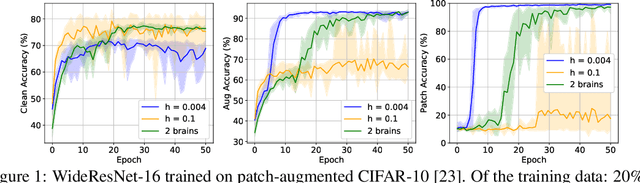
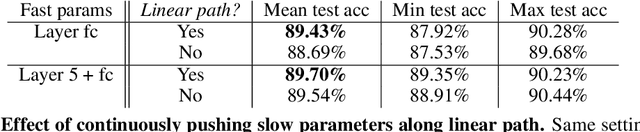
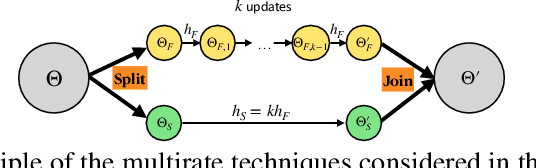
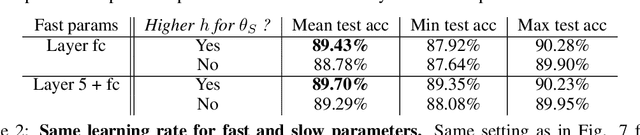
We propose multirate training of neural networks: partitioning neural network parameters into "fast" and "slow" parts which are trained simultaneously using different learning rates. By choosing appropriate partitionings we can obtain large computational speed-ups for transfer learning tasks. We show that for various transfer learning applications in vision and NLP we can fine-tune deep neural networks in almost half the time, without reducing the generalization performance of the resulting model. We also discuss other splitting choices for the neural network parameters which are beneficial in enhancing generalization performance in settings where neural networks are trained from scratch. Finally, we propose an additional multirate technique which can learn different features present in the data by training the full network on different time scales simultaneously. The benefits of using this approach are illustrated for ResNet architectures on image data. Our paper unlocks the potential of using multirate techniques for neural network training and provides many starting points for future work in this area.
PSIGAN: Joint probabilistic segmentation and image distribution matching for unpaired cross-modality adaptation based MRI segmentation
Jul 18, 2020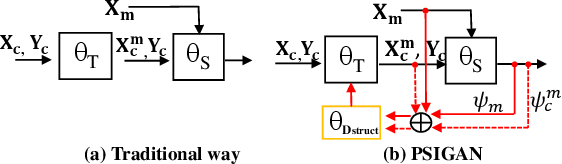
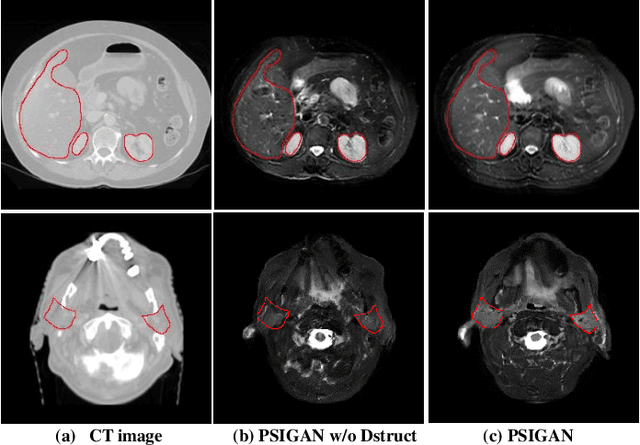
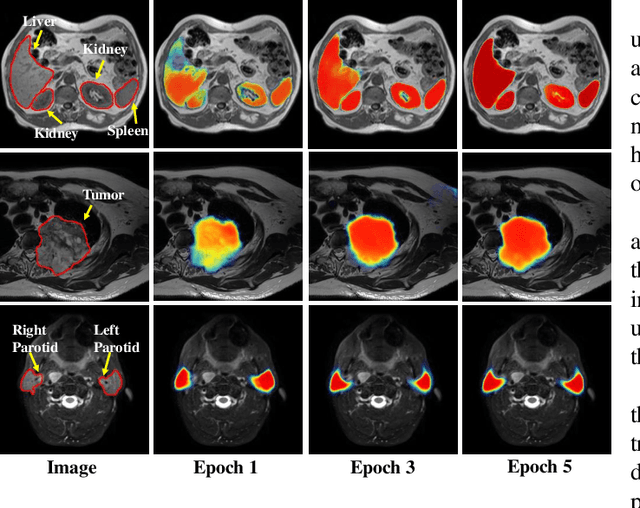
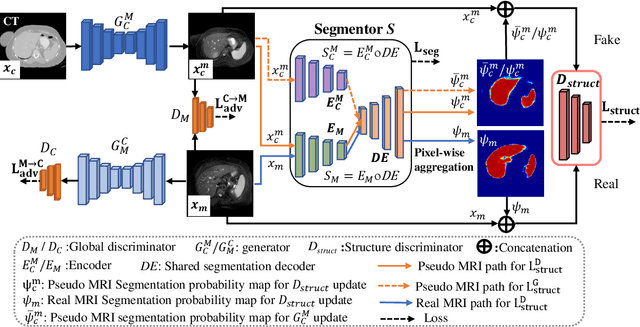
We developed a new joint probabilistic segmentation and image distribution matching generative adversarial network (PSIGAN) for unsupervised domain adaptation (UDA) and multi-organ segmentation from magnetic resonance (MRI) images. Our UDA approach models the co-dependency between images and their segmentation as a joint probability distribution using a new structure discriminator. The structure discriminator computes structure of interest focused adversarial loss by combining the generated pseudo MRI with probabilistic segmentations produced by a simultaneously trained segmentation sub-network. The segmentation sub-network is trained using the pseudo MRI produced by the generator sub-network. This leads to a cyclical optimization of both the generator and segmentation sub-networks that are jointly trained as part of an end-to-end network. Extensive experiments and comparisons against multiple state-of-the-art methods were done on four different MRI sequences totalling 257 scans for generating multi-organ and tumor segmentation. The experiments included, (a) 20 T1-weighted (T1w) in-phase mdixon and (b) 20 T2-weighted (T2w) abdominal MRI for segmenting liver, spleen, left and right kidneys, (c) 162 T2-weighted fat suppressed head and neck MRI (T2wFS) for parotid gland segmentation, and (d) 75 T2w MRI for lung tumor segmentation. Our method achieved an overall average DSC of 0.87 on T1w and 0.90 on T2w for the abdominal organs, 0.82 on T2wFS for the parotid glands, and 0.77 on T2w MRI for lung tumors.
* This paper has been accepted by IEEE Transactions on Medical Imaging
Cross-Modal Analysis of Human Detection for Robotics: An Industrial Case Study
Aug 03, 2021
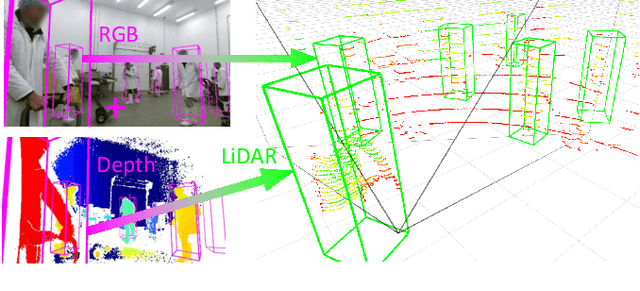
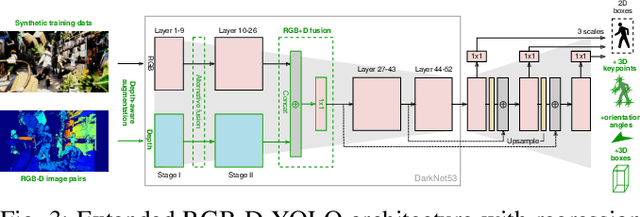
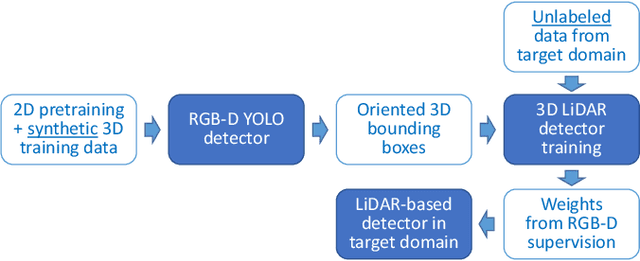
Advances in sensing and learning algorithms have led to increasingly mature solutions for human detection by robots, particularly in selected use-cases such as pedestrian detection for self-driving cars or close-range person detection in consumer settings. Despite this progress, the simple question "which sensor-algorithm combination is best suited for a person detection task at hand?" remains hard to answer. In this paper, we tackle this issue by conducting a systematic cross-modal analysis of sensor-algorithm combinations typically used in robotics. We compare the performance of state-of-the-art person detectors for 2D range data, 3D lidar, and RGB-D data as well as selected combinations thereof in a challenging industrial use-case. We further address the related problems of data scarcity in the industrial target domain, and that recent research on human detection in 3D point clouds has mostly focused on autonomous driving scenarios. To leverage these methodological advances for robotics applications, we utilize a simple, yet effective multi-sensor transfer learning strategy by extending a strong image-based RGB-D detector to provide cross-modal supervision for lidar detectors in the form of weak 3D bounding box labels. Our results show a large variance among the different approaches in terms of detection performance, generalization, frame rates and computational requirements. As our use-case contains difficulties representative for a wide range of service robot applications, we believe that these results point to relevant open challenges for further research and provide valuable support to practitioners for the design of their robot system.