 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Generative Abstract Reasoning: Completing Raven's Progressive Matrix via Rule Abstraction and Selection
Jan 18, 2024
Endowing machines with abstract reasoning ability has been a long-term research topic in artificial intelligence. Raven's Progressive Matrix (RPM) is widely used to probe abstract visual reasoning in machine intelligence, where models need to understand the underlying rules and select the missing bottom-right images out of candidate sets to complete image matrices. The participators can display powerful reasoning ability by inferring the underlying attribute-changing rules and imagining the missing images at arbitrary positions. However, existing solvers can hardly manifest such an ability in realistic RPM problems. In this paper, we propose a conditional generative model to solve answer generation problems through Rule AbstractIon and SElection (RAISE) in the latent space. RAISE encodes image attributes as latent concepts and decomposes underlying rules into atomic rules by means of concepts, which are abstracted as global learnable parameters. When generating the answer, RAISE selects proper atomic rules out of the global knowledge set for each concept and composes them into the integrated rule of an RPM. In most configurations, RAISE outperforms the compared generative solvers in tasks of generating bottom-right and arbitrary-position answers. We test RAISE in the odd-one-out task and two held-out configurations to demonstrate how learning decoupled latent concepts and atomic rules helps find the image breaking the underlying rules and handle RPMs with unseen combinations of rules and attributes.
Machine Learning for Shipwreck Segmentation from Side Scan Sonar Imagery: Dataset and Benchmark
Jan 25, 2024Open-source benchmark datasets have been a critical component for advancing machine learning for robot perception in terrestrial applications. Benchmark datasets enable the widespread development of state-of-the-art machine learning methods, which require large datasets for training, validation, and thorough comparison to competing approaches. Underwater environments impose several operational challenges that hinder efforts to collect large benchmark datasets for marine robot perception. Furthermore, a low abundance of targets of interest relative to the size of the search space leads to increased time and cost required to collect useful datasets for a specific task. As a result, there is limited availability of labeled benchmark datasets for underwater applications. We present the AI4Shipwrecks dataset, which consists of 24 distinct shipwreck sites totaling 286 high-resolution labeled side scan sonar images to advance the state-of-the-art in autonomous sonar image understanding. We leverage the unique abundance of targets in Thunder Bay National Marine Sanctuary in Lake Huron, MI, to collect and compile a sonar imagery benchmark dataset through surveys with an autonomous underwater vehicle (AUV). We consulted with expert marine archaeologists for the labeling of robotically gathered data. We then leverage this dataset to perform benchmark experiments for comparison of state-of-the-art supervised segmentation methods, and we present insights on opportunities and open challenges for the field. The dataset and benchmarking tools will be released as an open-source benchmark dataset to spur innovation in machine learning for Great Lakes and ocean exploration. The dataset and accompanying software are available at https://umfieldrobotics.github.io/ai4shipwrecks/.
Diffusion-based Data Augmentation for Object Counting Problems
Jan 25, 2024Crowd counting is an important problem in computer vision due to its wide range of applications in image understanding. Currently, this problem is typically addressed using deep learning approaches, such as Convolutional Neural Networks (CNNs) and Transformers. However, deep networks are data-driven and are prone to overfitting, especially when the available labeled crowd dataset is limited. To overcome this limitation, we have designed a pipeline that utilizes a diffusion model to generate extensive training data. We are the first to generate images conditioned on a location dot map (a binary dot map that specifies the location of human heads) with a diffusion model. We are also the first to use these diverse synthetic data to augment the crowd counting models. Our proposed smoothed density map input for ControlNet significantly improves ControlNet's performance in generating crowds in the correct locations. Also, Our proposed counting loss for the diffusion model effectively minimizes the discrepancies between the location dot map and the crowd images generated. Additionally, our innovative guidance sampling further directs the diffusion process toward regions where the generated crowd images align most accurately with the location dot map. Collectively, we have enhanced ControlNet's ability to generate specified objects from a location dot map, which can be used for data augmentation in various counting problems. Moreover, our framework is versatile and can be easily adapted to all kinds of counting problems. Extensive experiments demonstrate that our framework improves the counting performance on the ShanghaiTech, NWPU-Crowd, UCF-QNRF, and TRANCOS datasets, showcasing its effectiveness.
Bootstrapping OTS-Funcimg Pre-training Model (Botfip) -- A Comprehensive Symbolic Regression Framework
Jan 18, 2024In the field of scientific computing, many problem-solving approaches tend to focus only on the process and final outcome, even in AI for science, there is a lack of deep multimodal information mining behind the data, missing a multimodal framework akin to that in the image-text domain. In this paper, we take Symbolic Regression(SR) as our focal point and, drawing inspiration from the BLIP model in the image-text domain, propose a scientific computing multimodal framework based on Function Images (Funcimg) and Operation Tree Sequence (OTS), named Bootstrapping OTS-Funcimg Pre-training Model (Botfip). In SR experiments, we validate the advantages of Botfip in low-complexity SR problems, showcasing its potential. As a MED framework, Botfip holds promise for future applications in a broader range of scientific computing problems.
Texture Matching GAN for CT Image Enhancement
Dec 20, 2023Deep neural networks (DNN) are commonly used to denoise and sharpen X-ray computed tomography (CT) images with the goal of reducing patient X-ray dosage while maintaining reconstruction quality. However, naive application of DNN-based methods can result in image texture that is undesirable in clinical applications. Alternatively, generative adversarial network (GAN) based methods can produce appropriate texture, but naive application of GANs can introduce inaccurate or even unreal image detail. In this paper, we propose a texture matching generative adversarial network (TMGAN) that enhances CT images while generating an image texture that can be matched to a target texture. We use parallel generators to separate anatomical features from the generated texture, which allows the GAN to be trained to match the desired texture without directly affecting the underlying CT image. We demonstrate that TMGAN generates enhanced image quality while also producing image texture that is desirable for clinical application.
Segment Any Cell: A SAM-based Auto-prompting Fine-tuning Framework for Nuclei Segmentation
Jan 24, 2024In the rapidly evolving field of AI research, foundational models like BERT and GPT have significantly advanced language and vision tasks. The advent of pretrain-prompting models such as ChatGPT and Segmentation Anything Model (SAM) has further revolutionized image segmentation. However, their applications in specialized areas, particularly in nuclei segmentation within medical imaging, reveal a key challenge: the generation of high-quality, informative prompts is as crucial as applying state-of-the-art (SOTA) fine-tuning techniques on foundation models. To address this, we introduce Segment Any Cell (SAC), an innovative framework that enhances SAM specifically for nuclei segmentation. SAC integrates a Low-Rank Adaptation (LoRA) within the attention layer of the Transformer to improve the fine-tuning process, outperforming existing SOTA methods. It also introduces an innovative auto-prompt generator that produces effective prompts to guide segmentation, a critical factor in handling the complexities of nuclei segmentation in biomedical imaging. Our extensive experiments demonstrate the superiority of SAC in nuclei segmentation tasks, proving its effectiveness as a tool for pathologists and researchers. Our contributions include a novel prompt generation strategy, automated adaptability for diverse segmentation tasks, the innovative application of Low-Rank Attention Adaptation in SAM, and a versatile framework for semantic segmentation challenges.
Towards Effective Multiple-in-One Image Restoration: A Sequential and Prompt Learning Strategy
Jan 07, 2024While single task image restoration (IR) has achieved significant successes, it remains a challenging issue to train a single model which can tackle multiple IR tasks. In this work, we investigate in-depth the multiple-in-one (MiO) IR problem, which comprises seven popular IR tasks. We point out that MiO IR faces two pivotal challenges: the optimization of diverse objectives and the adaptation to multiple tasks. To tackle these challenges, we present two simple yet effective strategies. The first strategy, referred to as sequential learning, attempts to address how to optimize the diverse objectives, which guides the network to incrementally learn individual IR tasks in a sequential manner rather than mixing them together. The second strategy, i.e., prompt learning, attempts to address how to adapt to the different IR tasks, which assists the network to understand the specific task and improves the generalization ability. By evaluating on 19 test sets, we demonstrate that the sequential and prompt learning strategies can significantly enhance the MiO performance of commonly used CNN and Transformer backbones. Our experiments also reveal that the two strategies can supplement each other to learn better degradation representations and enhance the model robustness. It is expected that our proposed MiO IR formulation and strategies could facilitate the research on how to train IR models with higher generalization capabilities.
Sat2Scene: 3D Urban Scene Generation from Satellite Images with Diffusion
Jan 19, 2024Directly generating scenes from satellite imagery offers exciting possibilities for integration into applications like games and map services. However, challenges arise from significant view changes and scene scale. Previous efforts mainly focused on image or video generation, lacking exploration into the adaptability of scene generation for arbitrary views. Existing 3D generation works either operate at the object level or are difficult to utilize the geometry obtained from satellite imagery. To overcome these limitations, we propose a novel architecture for direct 3D scene generation by introducing diffusion models into 3D sparse representations and combining them with neural rendering techniques. Specifically, our approach generates texture colors at the point level for a given geometry using a 3D diffusion model first, which is then transformed into a scene representation in a feed-forward manner. The representation can be utilized to render arbitrary views which would excel in both single-frame quality and inter-frame consistency. Experiments in two city-scale datasets show that our model demonstrates proficiency in generating photo-realistic street-view image sequences and cross-view urban scenes from satellite imagery.
Exploring ISAC Technology for UAV SAR Imaging
Jan 19, 2024This paper illustrates the potential of an Integrated Sensing and Communication (ISAC) system, operating in the sub-6 GHz frequency range, for Synthetic Aperture Radar (SAR) imaging via an Unmanned Aerial Vehicle (UAV) employed as an aerial base station. The primary aim is to validate the system's ability to generate SAR imagery within the confines of modern communication standards, including considerations like power limits, carrier frequency, bandwidth, and other relevant parameters. The paper presents two methods for processing the signal reflected by the scene. Additionally, we analyze two key performance indicators for their respective fields, the Noise Equivalent Sigma Zero (NESZ) and the Bit Error Rate (BER), using the QUAsi Deterministic RadIo channel GenerAtor (QuaDRiGa), demonstrating the system's capability to image buried targets in challenging scenarios. The paper shows simulated Impulse Response Functions (IRF) as possible pulse compression techniques under different assumptions. An experimental campaign is conducted to validate the proposed setup by producing a SAR image of the environment captured using a UAV flying with a Software-Defined Radio (SDR) as a payload.
Guided Image Restoration via Simultaneous Feature and Image Guided Fusion
Dec 14, 2023
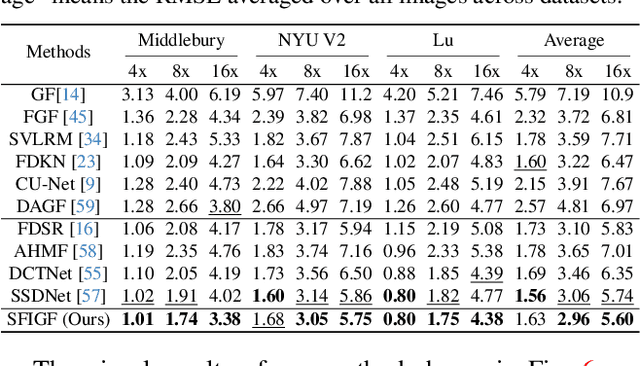
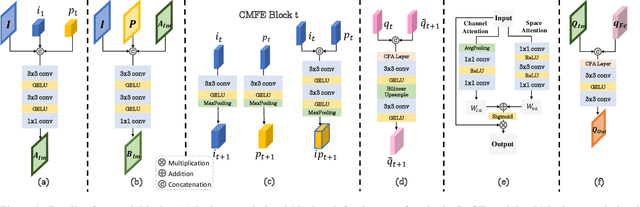
Guided image restoration (GIR), such as guided depth map super-resolution and pan-sharpening, aims to enhance a target image using guidance information from another image of the same scene. Currently, joint image filtering-inspired deep learning-based methods represent the state-of-the-art for GIR tasks. Those methods either deal with GIR in an end-to-end way by elaborately designing filtering-oriented deep neural network (DNN) modules, focusing on the feature-level fusion of inputs; or explicitly making use of the traditional joint filtering mechanism by parameterizing filtering coefficients with DNNs, working on image-level fusion. The former ones are good at recovering contextual information but tend to lose fine-grained details, while the latter ones can better retain textual information but might lead to content distortions. In this work, to inherit the advantages of both methodologies while mitigating their limitations, we proposed a Simultaneous Feature and Image Guided Fusion (SFIGF) network, that simultaneously considers feature and image-level guided fusion following the guided filter (GF) mechanism. In the feature domain, we connect the cross-attention (CA) with GF, and propose a GF-inspired CA module for better feature-level fusion; in the image domain, we fully explore the GF mechanism and design GF-like structure for better image-level fusion. Since guided fusion is implemented in both feature and image domains, the proposed SFIGF is expected to faithfully reconstruct both contextual and textual information from sources and thus lead to better GIR results. We apply SFIGF to 4 typical GIR tasks, and experimental results on these tasks demonstrate its effectiveness and general availability.