 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Weakly Supervised Convolutional Network for Change Segmentation and Classification
Nov 06, 2020
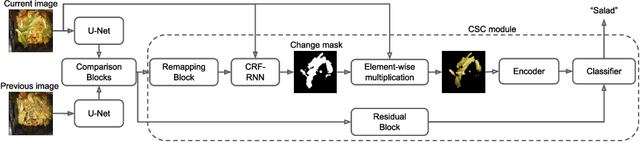
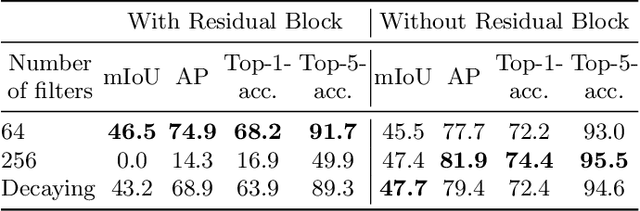
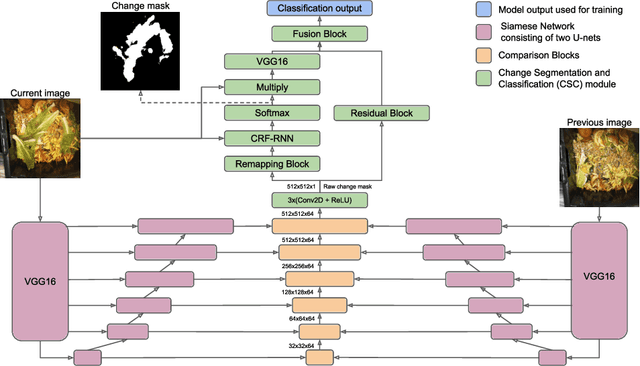
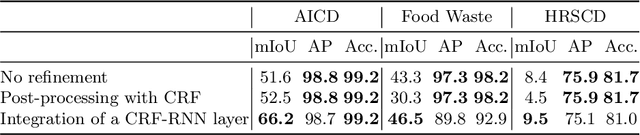
Fully supervised change detection methods require difficult to procure pixel-level labels, while weakly supervised approaches can be trained with image-level labels. However, most of these approaches require a combination of changed and unchanged image pairs for training. Thus, these methods can not directly be used for datasets where only changed image pairs are available. We present W-CDNet, a novel weakly supervised change detection network that can be trained with image-level semantic labels. Additionally, W-CDNet can be trained with two different types of datasets, either containing changed image pairs only or a mixture of changed and unchanged image pairs. Since we use image-level semantic labels for training, we simultaneously create a change mask and label the changed object for single-label images. W-CDNet employs a W-shaped siamese U-net to extract feature maps from an image pair which then get compared in order to create a raw change mask. The core part of our model, the Change Segmentation and Classification (CSC) module, learns an accurate change mask at a hidden layer by using a custom Remapping Block and then segmenting the current input image with the change mask. The segmented image is used to predict the image-level semantic label. The correct label can only be predicted if the change mask actually marks relevant change. This forces the model to learn an accurate change mask. We demonstrate the segmentation and classification performance of our approach and achieve top results on AICD and HRSCD, two public aerial imaging change detection datasets as well as on a Food Waste change detection dataset. Our code is available at https://github.com/PhiAbs/W-CDNet .
Convolutional Mesh Regression for Single-Image Human Shape Reconstruction
May 08, 2019

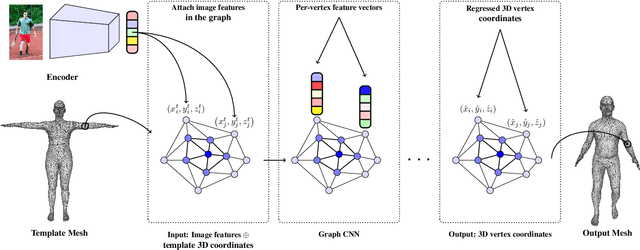
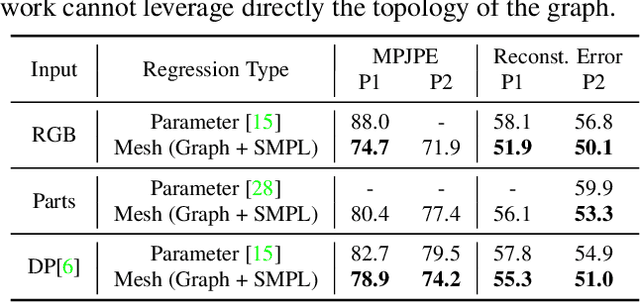
This paper addresses the problem of 3D human pose and shape estimation from a single image. Previous approaches consider a parametric model of the human body, SMPL, and attempt to regress the model parameters that give rise to a mesh consistent with image evidence. This parameter regression has been a very challenging task, with model-based approaches underperforming compared to nonparametric solutions in terms of pose estimation. In our work, we propose to relax this heavy reliance on the model's parameter space. We still retain the topology of the SMPL template mesh, but instead of predicting model parameters, we directly regress the 3D location of the mesh vertices. This is a heavy task for a typical network, but our key insight is that the regression becomes significantly easier using a Graph-CNN. This architecture allows us to explicitly encode the template mesh structure within the network and leverage the spatial locality the mesh has to offer. Image-based features are attached to the mesh vertices and the Graph-CNN is responsible to process them on the mesh structure, while the regression target for each vertex is its 3D location. Having recovered the complete 3D geometry of the mesh, if we still require a specific model parametrization, this can be reliably regressed from the vertices locations. We demonstrate the flexibility and the effectiveness of our proposed graph-based mesh regression by attaching different types of features on the mesh vertices. In all cases, we outperform the comparable baselines relying on model parameter regression, while we also achieve state-of-the-art results among model-based pose estimation approaches.
A novel three-stage training strategy for long-tailed classification
Apr 20, 2021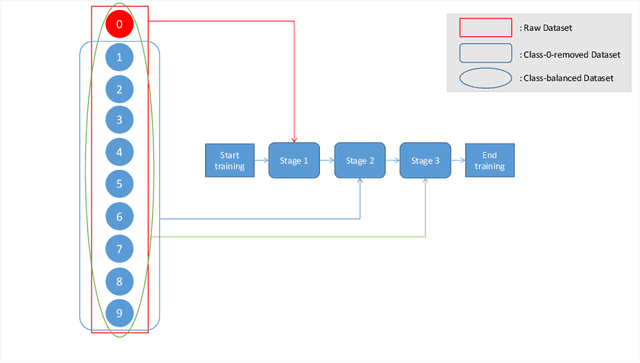
The long-tailed distribution datasets poses great challenges for deep learning based classification models on how to handle the class imbalance problem. Existing solutions usually involve class-balacing strategies or transfer learing from head- to tail-classes or use two-stages learning strategy to re-train the classifier. However, the existing methods are difficult to solve the low quality problem when images are obtained by SAR. To address this problem, we establish a novel three-stages training strategy, which has excellent results for processing SAR image datasets with long-tailed distribution. Specifically, we divide training procedure into three stages. The first stage is to use all kinds of images for rough-training, so as to get the rough-training model with rich content. The second stage is to make the rough model learn the feature expression by using the residual dataset with the class 0 removed. The third stage is to fine tune the model using class-balanced datasets with all 10 classes (including the overall model fine tuning and classifier re-optimization). Through this new training strategy, we only use the information of SAR image dataset and the network model with very small parameters to achieve the top 1 accuracy of 22.34 in development phase.
PRISM: A Unified Framework of Parameterized Submodular Information Measures for Targeted Data Subset Selection and Summarization
Feb 27, 2021

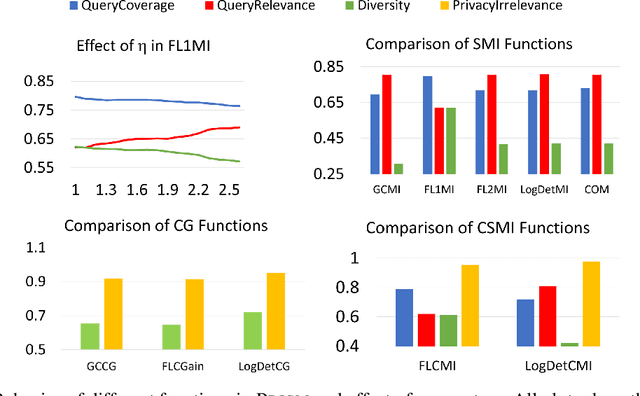
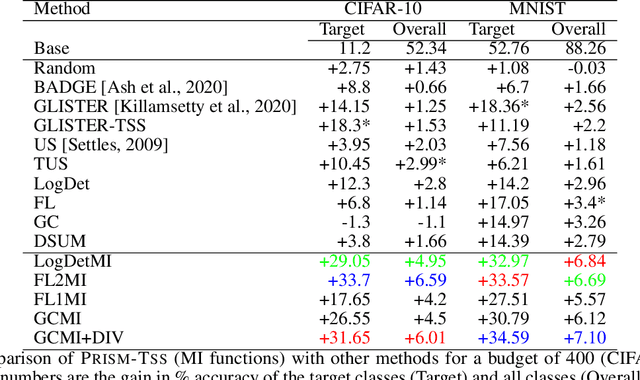
With increasing data, techniques for finding smaller, yet effective subsets with specific characteristics become important. Motivated by this, we present PRISM, a rich class of Parameterized Submodular Information Measures, that can be used in applications where such targeted subsets are desired. We demonstrate the utility of PRISM in two such applications. First, we apply PRISM to improve a supervised model's performance at a given additional labeling cost by targeted subset selection (PRISM-TSS) where a subset of unlabeled points matching a target set are added to the training set. We show that PRISM-TSS generalizes and is connected to several existing approaches to targeted data subset selection. Second, we apply PRISM to a more nuanced targeted summarization (PRISM-TSUM) where data (e.g., image collections, text or videos) is summarized for quicker human consumption with additional user intent. PRISM-TSUM handles multiple flavors of targeted summarization such as query-focused, topic-irrelevant, privacy-preserving and update summarization in a unified way. We show that PRISM-TSUM also generalizes and unifies several existing past work on targeted summarization. Through extensive experiments on image classification and image-collection summarization we empirically verify the superiority of PRISM-TSS and PRISM-TSUM over the state-of-the-art.
Increasing the robustness of DNNs against image corruptions by playing the Game of Noise
Feb 26, 2020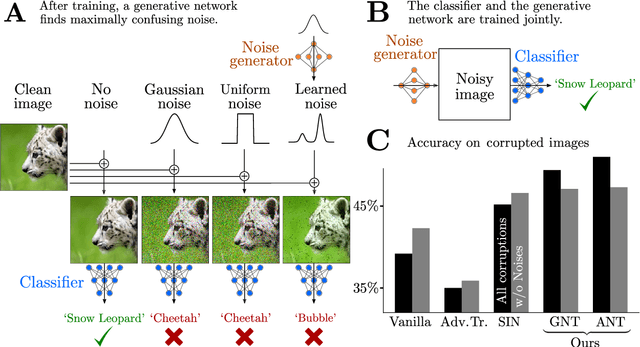
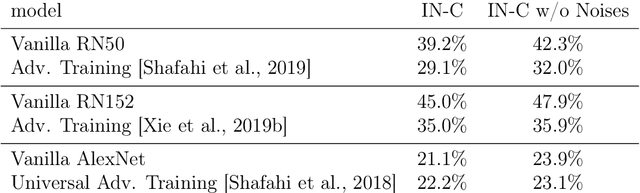
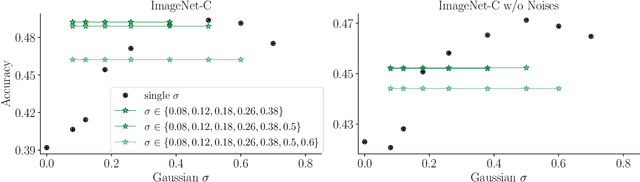
The human visual system is remarkably robust against a wide range of naturally occurring variations and corruptions like rain or snow. In contrast, the performance of modern image recognition models strongly degrades when evaluated on previously unseen corruptions. Here, we demonstrate that a simple but properly tuned training with additive Gaussian and Speckle noise generalizes surprisingly well to unseen corruptions, easily reaching the previous state of the art on the corruption benchmark ImageNet-C (with ResNet50) and on MNIST-C. We build on top of these strong baseline results and show that an adversarial training of the recognition model against uncorrelated worst-case noise distributions leads to an additional increase in performance. This regularization can be combined with previously proposed defense methods for further improvement.
AVA: Adversarial Vignetting Attack against Visual Recognition
May 12, 2021
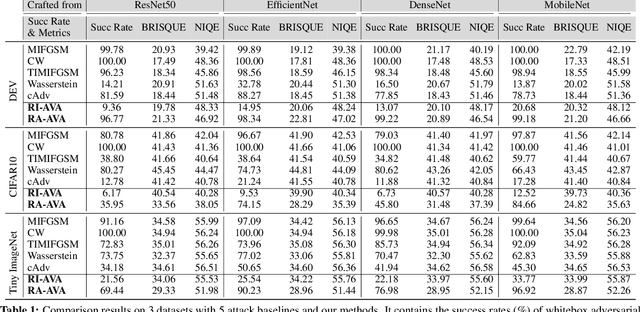
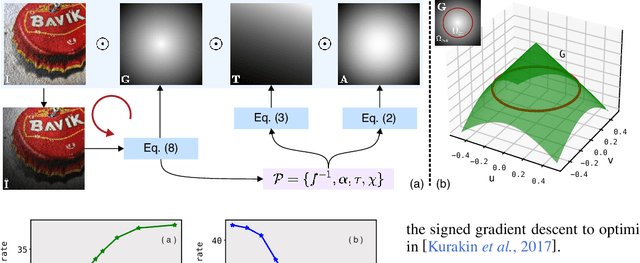
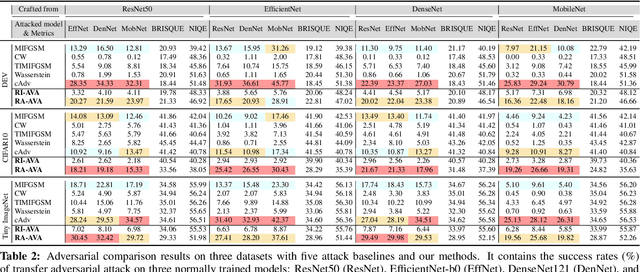
Vignetting is an inherited imaging phenomenon within almost all optical systems, showing as a radial intensity darkening toward the corners of an image. Since it is a common effect for photography and usually appears as a slight intensity variation, people usually regard it as a part of a photo and would not even want to post-process it. Due to this natural advantage, in this work, we study vignetting from a new viewpoint, i.e., adversarial vignetting attack (AVA), which aims to embed intentionally misleading information into vignetting and produce a natural adversarial example without noise patterns. This example can fool the state-of-the-art deep convolutional neural networks (CNNs) but is imperceptible to humans. To this end, we first propose the radial-isotropic adversarial vignetting attack (RI-AVA) based on the physical model of vignetting, where the physical parameters (e.g., illumination factor and focal length) are tuned through the guidance of target CNN models. To achieve higher transferability across different CNNs, we further propose radial-anisotropic adversarial vignetting attack (RA-AVA) by allowing the effective regions of vignetting to be radial-anisotropic and shape-free. Moreover, we propose the geometry-aware level-set optimization method to solve the adversarial vignetting regions and physical parameters jointly. We validate the proposed methods on three popular datasets, i.e., DEV, CIFAR10, and Tiny ImageNet, by attacking four CNNs, e.g., ResNet50, EfficientNet-B0, DenseNet121, and MobileNet-V2, demonstrating the advantages of our methods over baseline methods on both transferability and image quality.
A Multiple Source Hourglass Deep Network for Multi-Focus Image Fusion
Aug 28, 2019
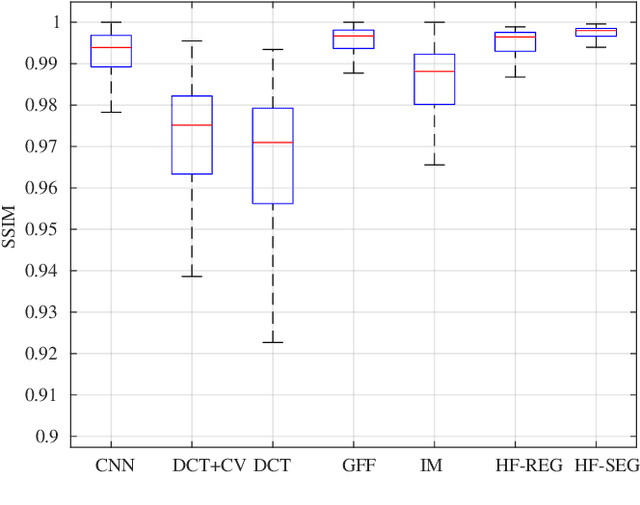

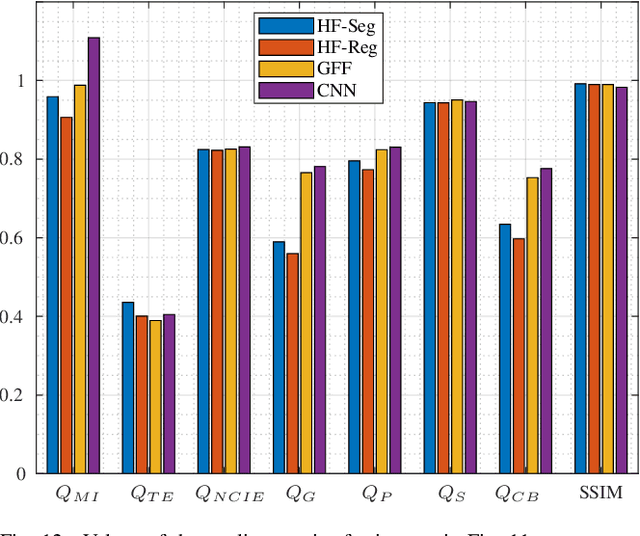
Multi-Focus Image Fusion seeks to improve the quality of an acquired burst of images with different focus planes. For solving the task, an activity level measurement and a fusion rule are typically established to select and fuse the most relevant information from the sources. However, the design of this kind of method by hand is really hard and sometimes restricted to solution spaces where the optimal all-in-focus images are not contained. Then, we propose here two fast and straightforward approaches for image fusion based on deep neural networks. Our solution uses a multiple source Hourglass architecture trained in an end-to-end fashion. Models are data-driven and can be easily generalized for other kinds of fusion problems. A segmentation approach is used for recognition of the focus map, while the weighted average rule is used for fusion. We designed a training loss function for our regression-based fusion function, which allows the network to learn both the activity level measurement and the fusion rule. Experimental results show our approach has comparable results to the state-of-the-art methods with a 60X increase of computational efficiency for 520X520 resolution images.
Repurposing GANs for One-shot Semantic Part Segmentation
Mar 24, 2021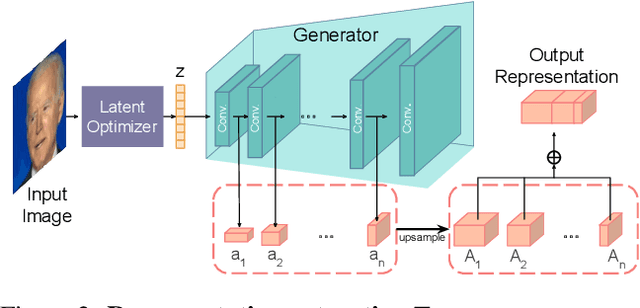
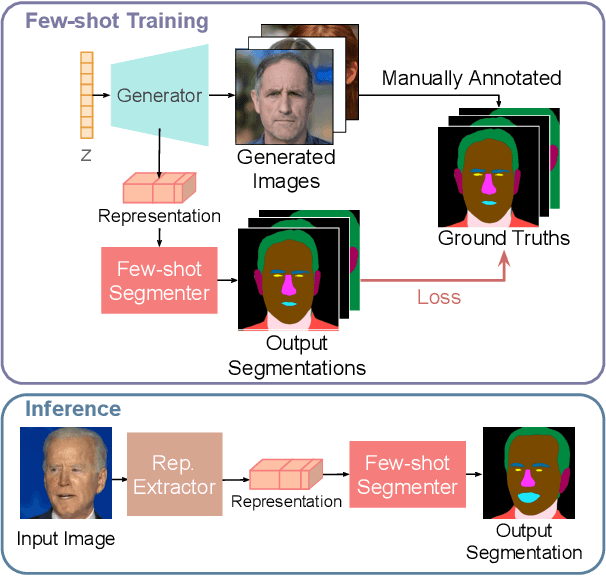

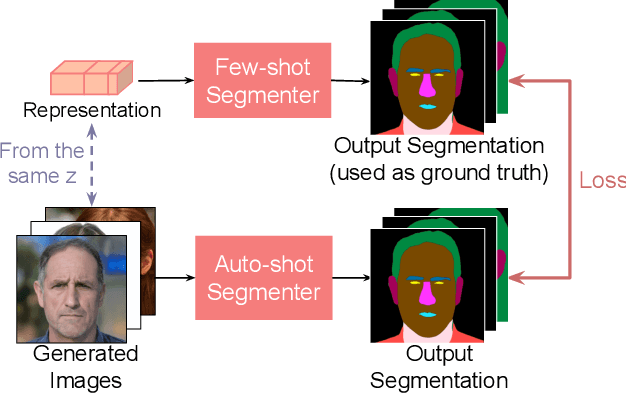
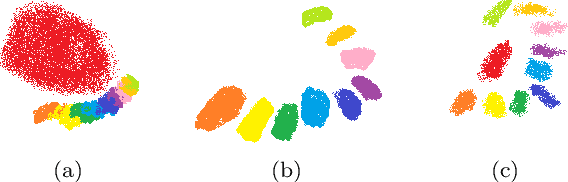
While GANs have shown success in realistic image generation, the idea of using GANs for other tasks unrelated to synthesis is underexplored. Do GANs learn meaningful structural parts of objects during their attempt to reproduce those objects? In this work, we test this hypothesis and propose a simple and effective approach based on GANs for semantic part segmentation that requires as few as one label example along with an unlabeled dataset. Our key idea is to leverage a trained GAN to extract pixel-wise representation from the input image and use it as feature vectors for a segmentation network. Our experiments demonstrate that GANs representation is "readily discriminative" and produces surprisingly good results that are comparable to those from supervised baselines trained with significantly more labels. We believe this novel repurposing of GANs underlies a new class of unsupervised representation learning that is applicable to many other tasks. More results are available at https://repurposegans.github.io/.
Demographic Fairness in Face Identification: The Watchlist Imbalance Effect
Jun 30, 2021
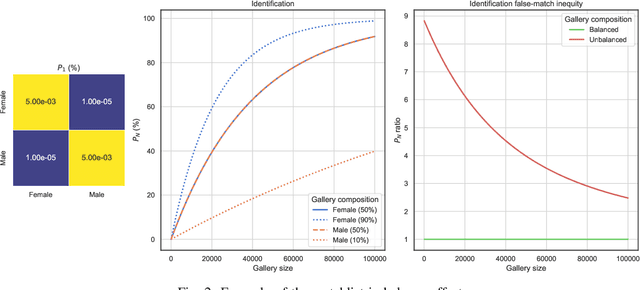

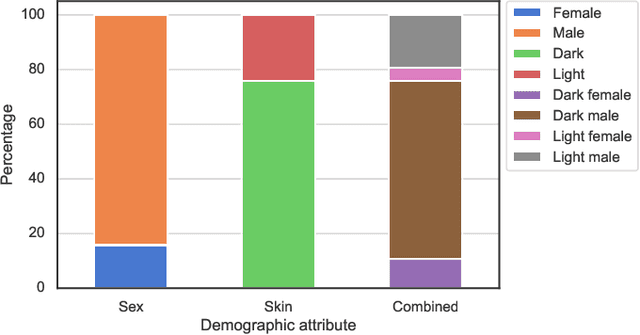
Recently, different researchers have found that the gallery composition of a face database can induce performance differentials to facial identification systems in which a probe image is compared against up to all stored reference images to reach a biometric decision. This negative effect is referred to as "watchlist imbalance effect". In this work, we present a method to theoretically estimate said effect for a biometric identification system given its verification performance across demographic groups and the composition of the used gallery. Further, we report results for identification experiments on differently composed demographic subsets, i.e. females and males, of the public academic MORPH database using the open-source ArcFace face recognition system. It is shown that the database composition has a huge impact on performance differentials in biometric identification systems, even if performance differentials are less pronounced in the verification scenario. This study represents the first detailed analysis of the watchlist imbalance effect which is expected to be of high interest for future research in the field of facial recognition.
Convolutional Transformer based Dual Discriminator Generative Adversarial Networks for Video Anomaly Detection
Jul 29, 2021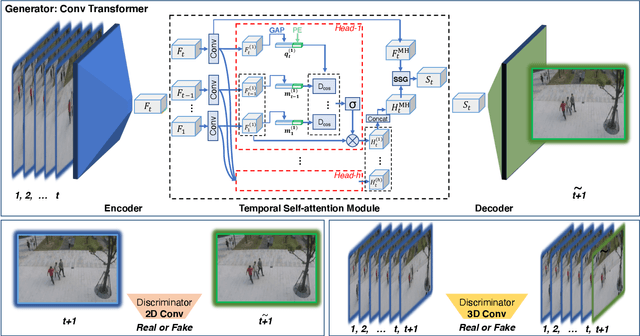

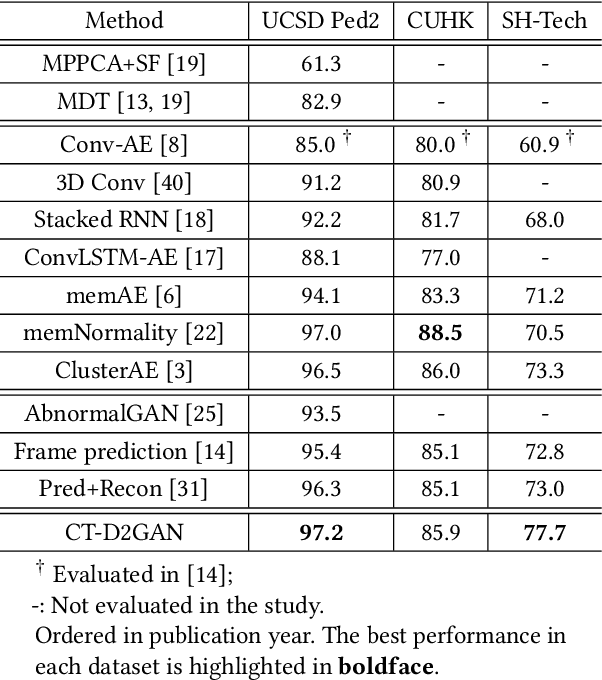
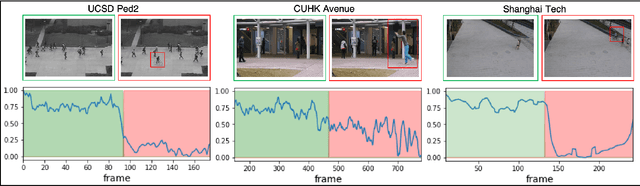
Detecting abnormal activities in real-world surveillance videos is an important yet challenging task as the prior knowledge about video anomalies is usually limited or unavailable. Despite that many approaches have been developed to resolve this problem, few of them can capture the normal spatio-temporal patterns effectively and efficiently. Moreover, existing works seldom explicitly consider the local consistency at frame level and global coherence of temporal dynamics in video sequences. To this end, we propose Convolutional Transformer based Dual Discriminator Generative Adversarial Networks (CT-D2GAN) to perform unsupervised video anomaly detection. Specifically, we first present a convolutional transformer to perform future frame prediction. It contains three key components, i.e., a convolutional encoder to capture the spatial information of the input video clips, a temporal self-attention module to encode the temporal dynamics, and a convolutional decoder to integrate spatio-temporal features and predict the future frame. Next, a dual discriminator based adversarial training procedure, which jointly considers an image discriminator that can maintain the local consistency at frame-level and a video discriminator that can enforce the global coherence of temporal dynamics, is employed to enhance the future frame prediction. Finally, the prediction error is used to identify abnormal video frames. Thoroughly empirical studies on three public video anomaly detection datasets, i.e., UCSD Ped2, CUHK Avenue, and Shanghai Tech Campus, demonstrate the effectiveness of the proposed adversarial spatio-temporal modeling framework.