 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FDeblur-GAN: Fingerprint Deblurring using Generative Adversarial Network
Jun 21, 2021

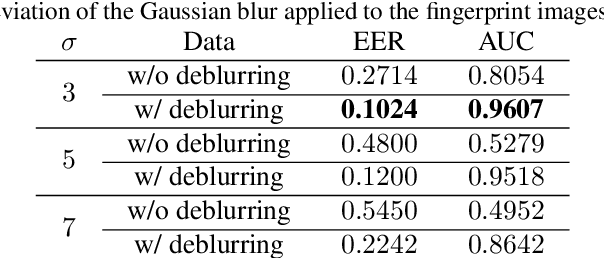
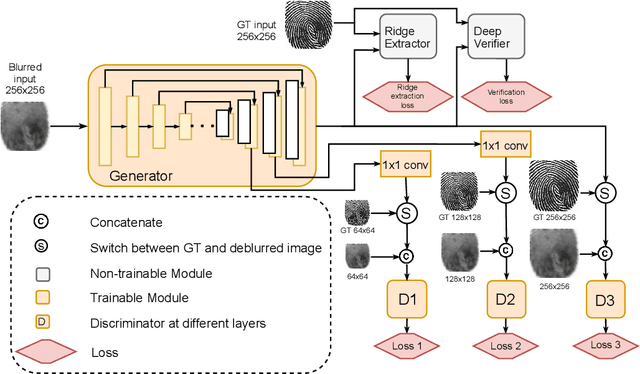
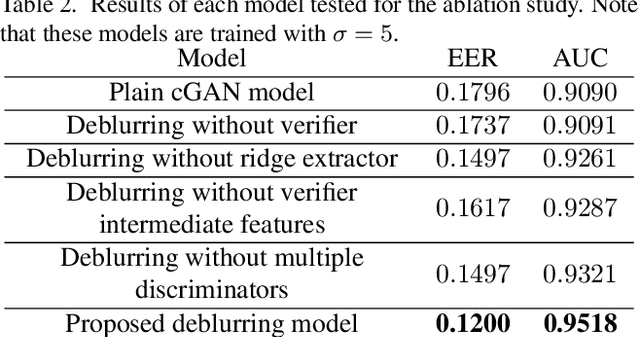
While working with fingerprint images acquired from crime scenes, mobile cameras, or low-quality sensors, it becomes difficult for automated identification systems to verify the identity due to image blur and distortion. We propose a fingerprint deblurring model FDeblur-GAN, based on the conditional Generative Adversarial Networks (cGANs) and multi-stage framework of the stack GAN. Additionally, we integrate two auxiliary sub-networks into the model for the deblurring task. The first sub-network is a ridge extractor model. It is added to generate ridge maps to ensure that fingerprint information and minutiae are preserved in the deblurring process and prevent the model from generating erroneous minutiae. The second sub-network is a verifier that helps the generator to preserve the ID information during the generation process. Using a database of blurred fingerprints and corresponding ridge maps, the deep network learns to deblur from the input blurry samples. We evaluate the proposed method in combination with two different fingerprint matching algorithms. We achieved an accuracy of 95.18% on our fingerprint database for the task of matching deblurred and ground truth fingerprints.
Feature Fusion Vision Transformer for Fine-Grained Visual Categorization
Jul 07, 2021
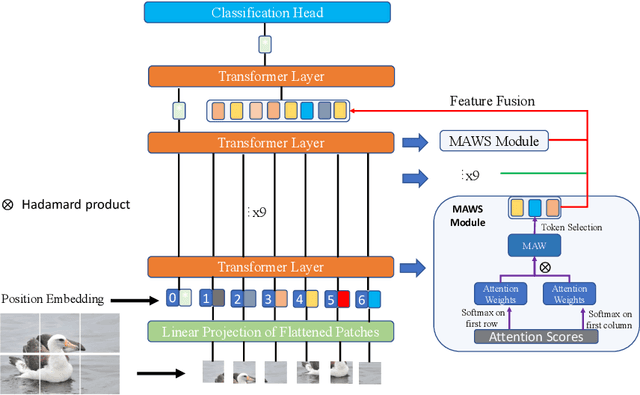
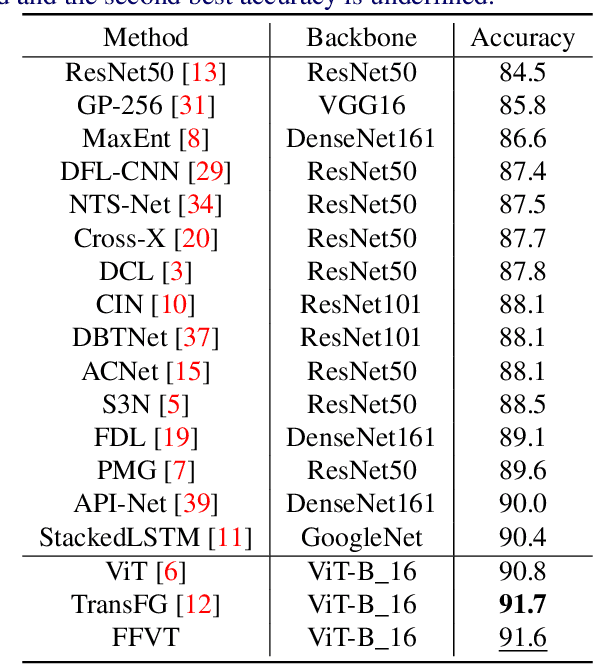
The core for tackling the fine-grained visual categorization (FGVC) is to learn subtle yet discriminative features. Most previous works achieve this by explicitly selecting the discriminative parts or integrating the attention mechanism via CNN-based approaches.However, these methods enhance the computational complexity and make the modeldominated by the regions containing the most of the objects. Recently, vision trans-former (ViT) has achieved SOTA performance on general image recognition tasks. Theself-attention mechanism aggregates and weights the information from all patches to the classification token, making it perfectly suitable for FGVC. Nonetheless, the classifi-cation token in the deep layer pays more attention to the global information, lacking the local and low-level features that are essential for FGVC. In this work, we proposea novel pure transformer-based framework Feature Fusion Vision Transformer (FFVT)where we aggregate the important tokens from each transformer layer to compensate thelocal, low-level and middle-level information. We design a novel token selection mod-ule called mutual attention weight selection (MAWS) to guide the network effectively and efficiently towards selecting discriminative tokens without introducing extra param-eters. We verify the effectiveness of FFVT on three benchmarks where FFVT achieves the state-of-the-art performance.
Semi-Supervised Raw-to-Raw Mapping
Jun 29, 2021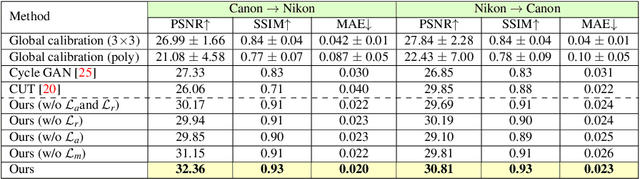
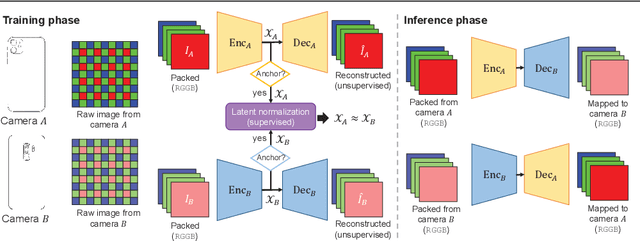
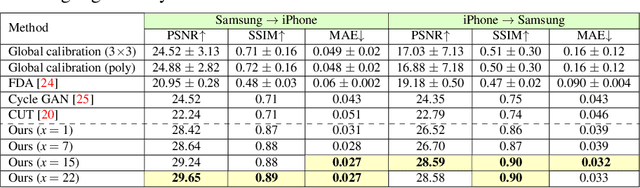

The raw-RGB colors of a camera sensor vary due to the spectral sensitivity differences across different sensor makes and models. This paper focuses on the task of mapping between different sensor raw-RGB color spaces. Prior work addressed this problem using a pairwise calibration to achieve accurate color mapping. Although being accurate, this approach is less practical as it requires: (1) capturing pair of images by both camera devices with a color calibration object placed in each new scene; (2) accurate image alignment or manual annotation of the color calibration object. This paper aims to tackle color mapping in the raw space through a more practical setup. Specifically, we present a semi-supervised raw-to-raw mapping method trained on a small set of paired images alongside an unpaired set of images captured by each camera device. Through extensive experiments, we show that our method achieves better results compared to other domain adaptation alternatives in addition to the single-calibration solution. We have generated a new dataset of raw images from two different smartphone cameras as part of this effort. Our dataset includes unpaired and paired sets for our semi-supervised training and evaluation.
A Survey of Modern Deep Learning based Object Detection Models
Apr 24, 2021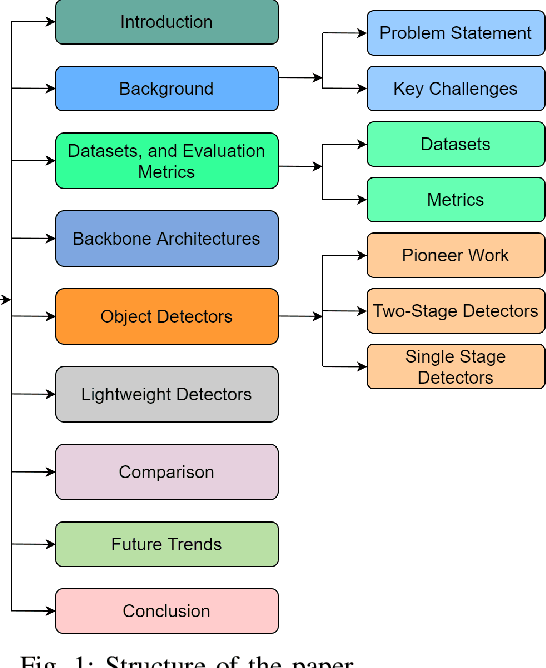


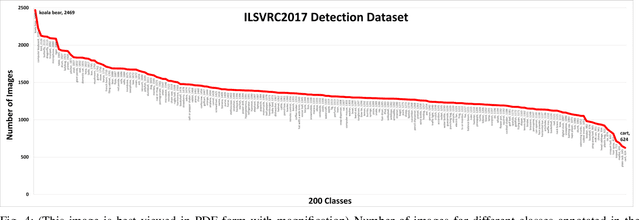
Object Detection is the task of classification and localization of objects in an image or video. It has gained prominence in recent years due to its widespread applications. This article surveys recent developments in deep learning based object detectors. Concise overview of benchmark datasets and evaluation metrics used in detection is also provided along with some of the prominent backbone architectures used in recognition tasks. It also covers contemporary lightweight classification models used on edge devices. Lastly, we compare the performances of these architectures on multiple metrics.
Diff2Dist: Learning Spectrally Distinct Edge Functions, with Applications to Cell Morphology Analysis
Jun 29, 2021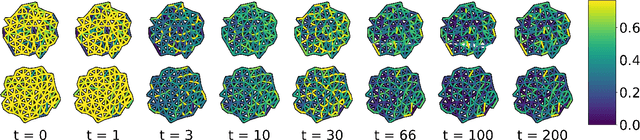
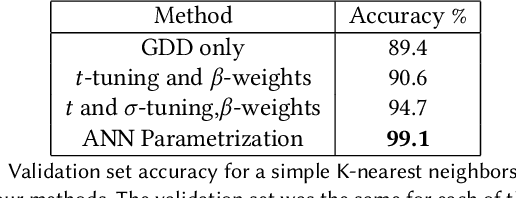
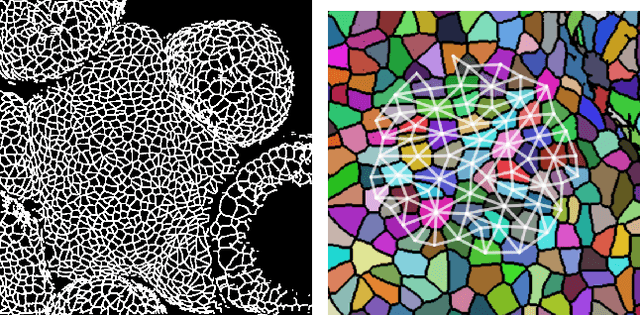
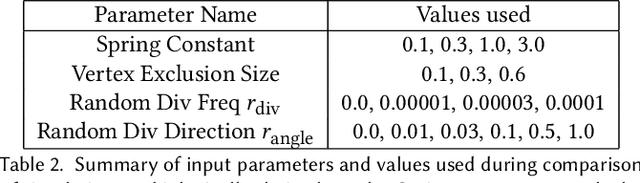
We present a method for learning "spectrally descriptive" edge weights for graphs. We generalize a previously known distance measure on graphs (Graph Diffusion Distance), thereby allowing it to be tuned to minimize an arbitrary loss function. Because all steps involved in calculating this modified GDD are differentiable, we demonstrate that it is possible for a small neural network model to learn edge weights which minimize loss. GDD alone does not effectively discriminate between graphs constructed from shoot apical meristem images of wild-type vs. mutant \emph{Arabidopsis thaliana} specimens. However, training edge weights and kernel parameters with contrastive loss produces a learned distance metric with large margins between these graph categories. We demonstrate this by showing improved performance of a simple k-nearest-neighbors classifier on the learned distance matrix. We also demonstrate a further application of this method to biological image analysis: once trained, we use our model to compute the distance between the biological graphs and a set of graphs output by a cell division simulator. This allows us to identify simulation parameter regimes which are similar to each class of graph in our original dataset.
Classification, Slippage, Failure and Discovery
Apr 08, 2021


This text argues for the potential of machine learning infused classification systems as vectors for a technically-engaged and constructive technology critique. The text describes this potential with several experiments in image data creation and neural network based classification. The text considers varying aspects of slippage in classification and considers the potential for discovery - as opposed to disaster - stemming from machine learning systems when they fail to perform as anticipated.
Unsupervised Deep Features for Privacy Image Classification
Sep 24, 2019
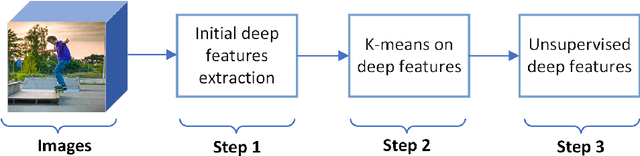

Sharing images online poses security threats to a wide range of users due to the unawareness of privacy information. Deep features have been demonstrated to be a powerful representation for images. However, deep features usually suffer from the issues of a large size and requiring a huge amount of data for fine-tuning. In contrast to normal images (e.g., scene images), privacy images are often limited because of sensitive information. In this paper, we propose a novel approach that can work on limited data and generate deep features of smaller size. For training images, we first extract the initial deep features from the pre-trained model and then employ the K-means clustering algorithm to learn the centroids of these initial deep features. We use the learned centroids from training features to extract the final features for each testing image and encode our final features with the triangle encoding. To improve the discriminability of the features, we further perform the fusion of two proposed unsupervised deep features obtained from different layers. Experimental results show that the proposed features outperform state-of-the-art deep features, in terms of both classification accuracy and testing time.
To Beta or Not To Beta: Information Bottleneck for DigitaL Image Forensics
Aug 11, 2019
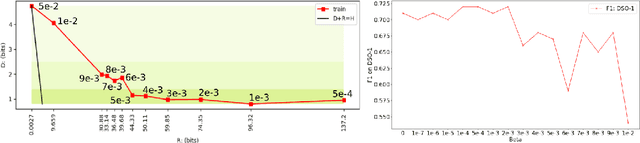

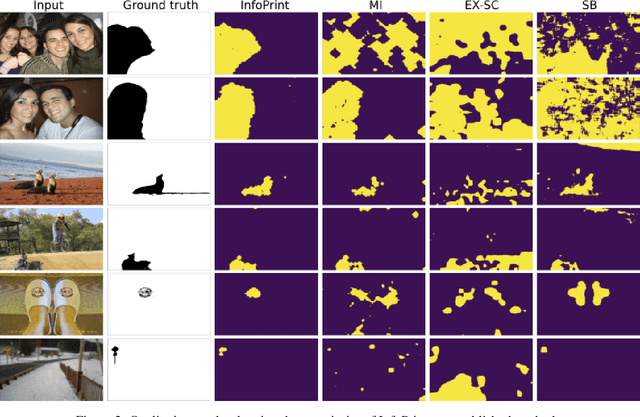
We consider an information theoretic approach to address the problem of identifying fake digital images. We propose an innovative method to formulate the issue of localizing manipulated regions in an image as a deep representation learning problem using the Information Bottleneck (IB), which has recently gained popularity as a framework for interpreting deep neural networks. Tampered images pose a serious predicament since digitized media is a ubiquitous part of our lives. These are facilitated by the easy availability of image editing software and aggravated by recent advances in deep generative models such as GANs. We propose InfoPrint, a computationally efficient solution to the IB formulation using approximate variational inference and compare it to a numerical solution that is computationally expensive. Testing on a number of standard datasets, we demonstrate that InfoPrint outperforms the state-of-the-art and the numerical solution. Additionally, it also has the ability to detect alterations made by inpainting GANs.
TNT: Text-Conditioned Network with Transductive Inference for Few-Shot Video Classification
Jun 21, 2021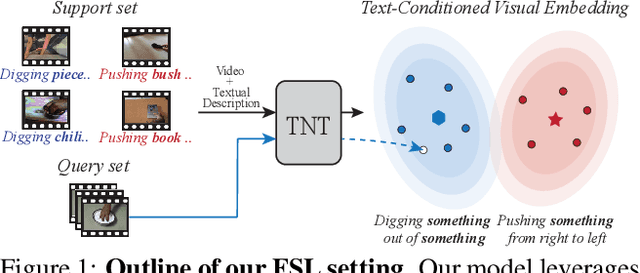
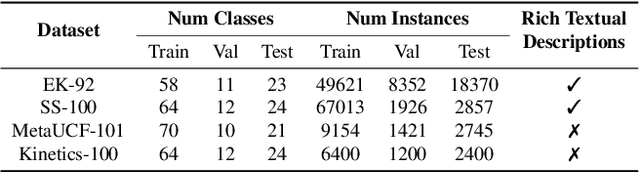
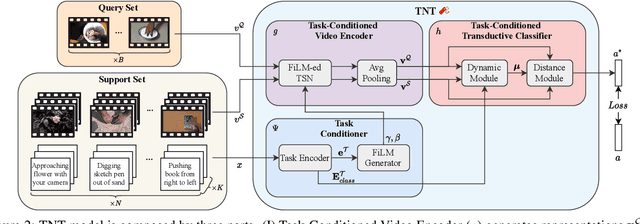
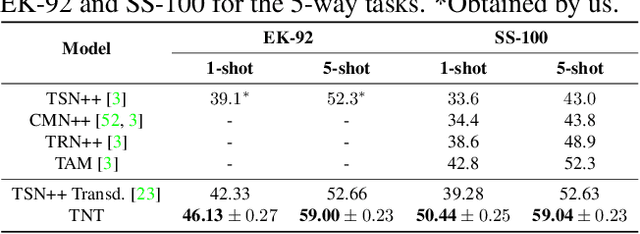
Recently, few-shot learning has received increasing interest. Existing efforts have been focused on image classification, with very few attempts dedicated to the more challenging few-shot video classification problem. These few attempts aim to effectively exploit the temporal dimension in videos for better learning in low data regimes. However, they have largely ignored a key characteristic of video which could be vital for few-shot recognition, that is, videos are often accompanied by rich text descriptions. In this paper, for the first time, we propose to leverage these human-provided textual descriptions as privileged information when training a few-shot video classification model. Specifically, we formulate a text-based task conditioner to adapt video features to the few-shot learning task. Our model follows a transductive setting where query samples and support textual descriptions can be used to update the support set class prototype to further improve the task-adaptation ability of the model. Our model obtains state-of-the-art performance on four challenging benchmarks in few-shot video action classification.
Self-Paced Uncertainty Estimation for One-shot Person Re-Identification
Apr 19, 2021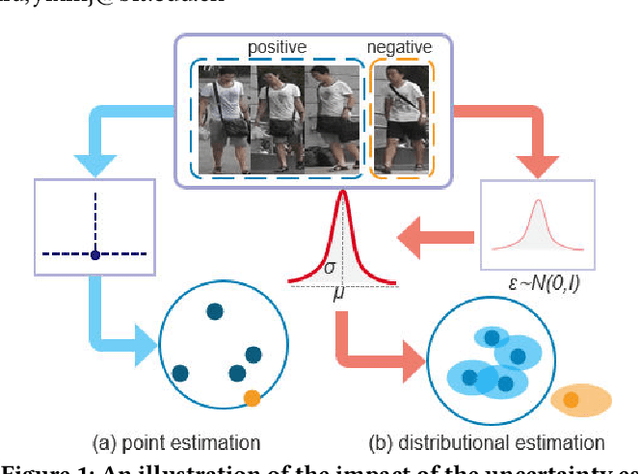
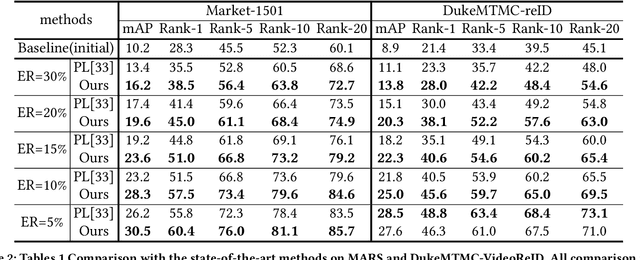
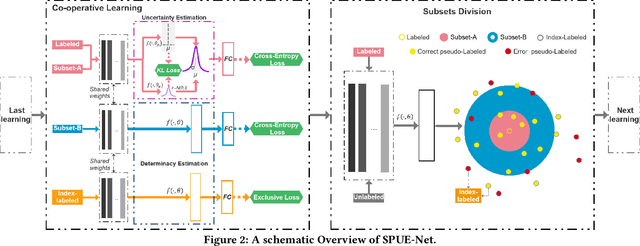
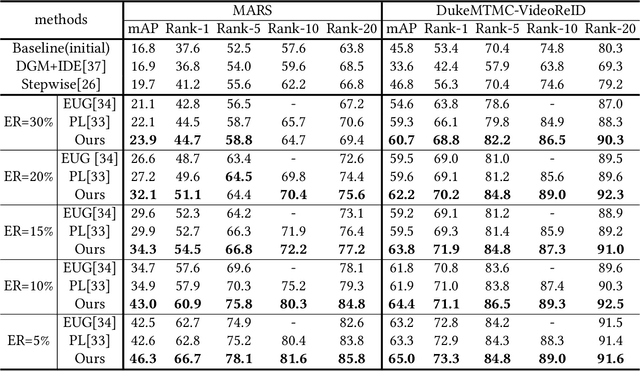
The one-shot Person Re-ID scenario faces two kinds of uncertainties when constructing the prediction model from $X$ to $Y$. The first is model uncertainty, which captures the noise of the parameters in DNNs due to a lack of training data. The second is data uncertainty, which can be divided into two sub-types: one is image noise, where severe occlusion and the complex background contain irrelevant information about the identity; the other is label noise, where mislabeled affects visual appearance learning. In this paper, to tackle these issues, we propose a novel Self-Paced Uncertainty Estimation Network (SPUE-Net) for one-shot Person Re-ID. By introducing a self-paced sampling strategy, our method can estimate the pseudo-labels of unlabeled samples iteratively to expand the labeled samples gradually and remove model uncertainty without extra supervision. We divide the pseudo-label samples into two subsets to make the use of training samples more reasonable and effective. In addition, we apply a Co-operative learning method of local uncertainty estimation combined with determinacy estimation to achieve better hidden space feature mining and to improve the precision of selected pseudo-labeled samples, which reduces data uncertainty. Extensive comparative evaluation experiments on video-based and image-based datasets show that SPUE-Net has significant advantages over the state-of-the-art methods.