 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Practical Fast Gradient Sign Attack against Mammographic Image Classifier
Jan 27, 2020
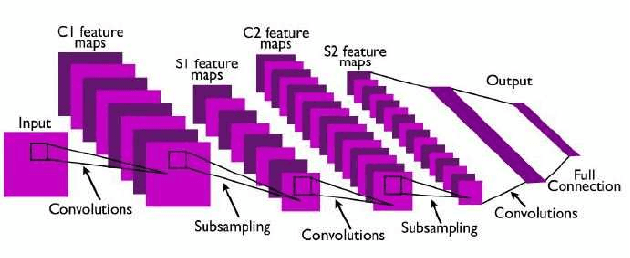
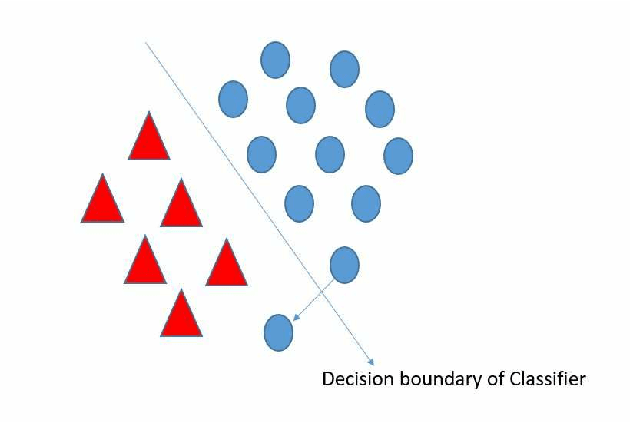
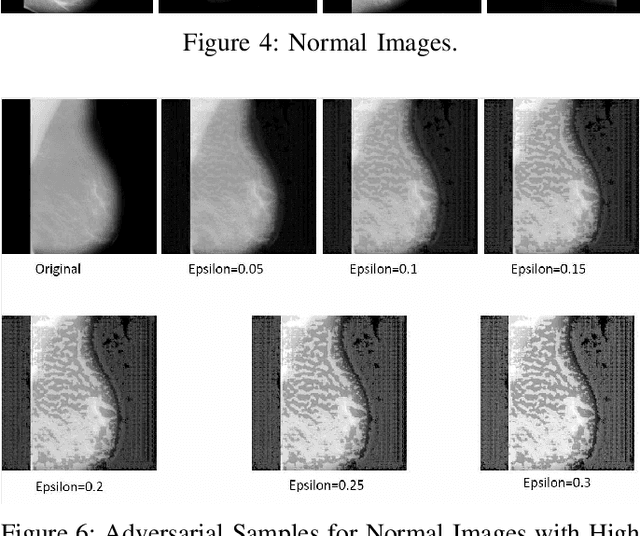
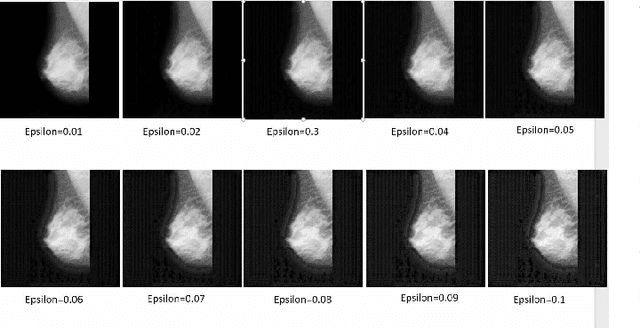
Artificial intelligence (AI) has been a topic of major research for many years. Especially, with the emergence of deep neural network (DNN), these studies have been tremendously successful. Today machines are capable of making faster, more accurate decision than human. Thanks to the great development of machine learning (ML) techniques, ML have been used many different fields such as education, medicine, malware detection, autonomous car etc. In spite of having this degree of interest and much successful research, ML models are still vulnerable to adversarial attacks. Attackers can manipulate clean data in order to fool the ML classifiers to achieve their desire target. For instance; a benign sample can be modified as a malicious sample or a malicious one can be altered as benign while this modification can not be recognized by human observer. This can lead to many financial losses, or serious injuries, even deaths. The motivation behind this paper is that we emphasize this issue and want to raise awareness. Therefore, the security gap of mammographic image classifier against adversarial attack is demonstrated. We use mamographic images to train our model then evaluate our model performance in terms of accuracy. Later on, we poison original dataset and generate adversarial samples that missclassified by the model. We then using structural similarity index (SSIM) analyze similarity between clean images and adversarial images. Finally, we show how successful we are to misuse by using different poisoning factors.
Explainable Deep Few-shot Anomaly Detection with Deviation Networks
Aug 01, 2021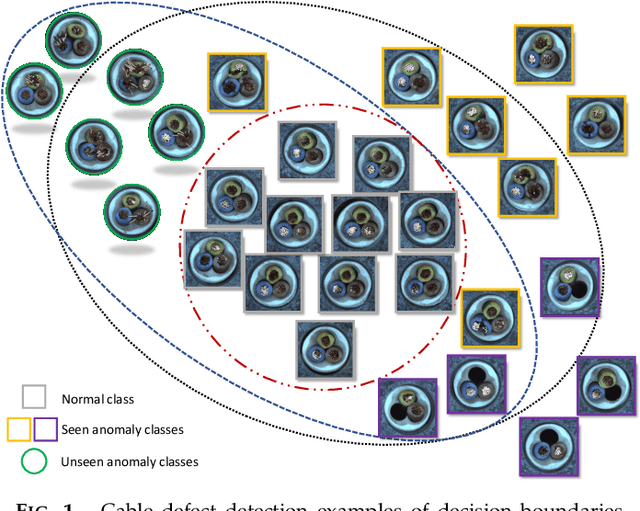
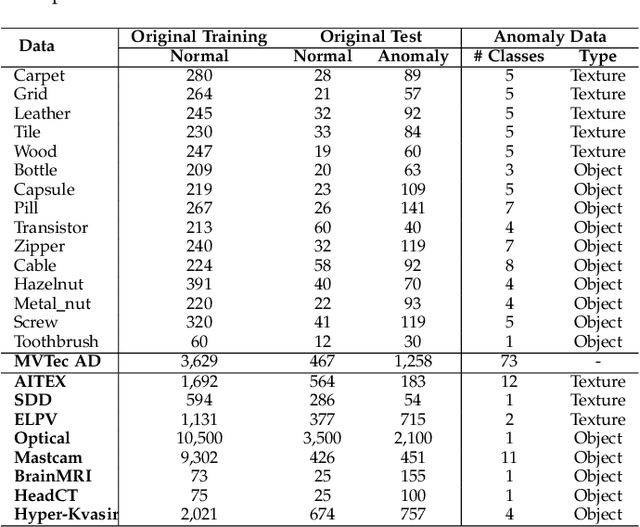
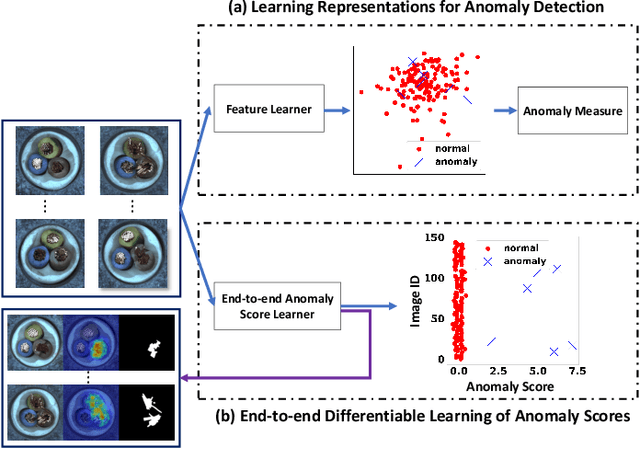
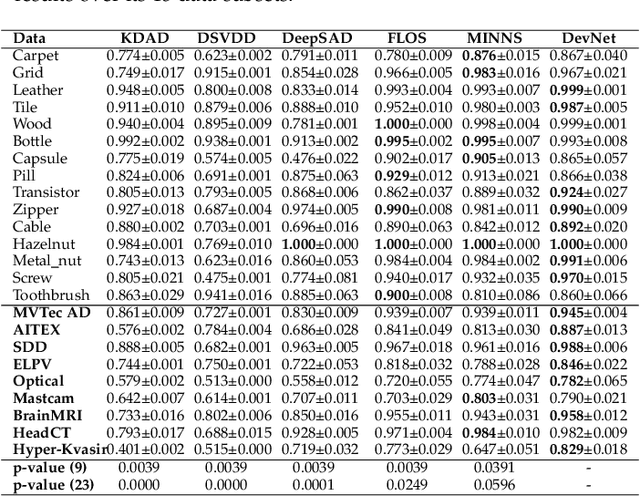
Existing anomaly detection paradigms overwhelmingly focus on training detection models using exclusively normal data or unlabeled data (mostly normal samples). One notorious issue with these approaches is that they are weak in discriminating anomalies from normal samples due to the lack of the knowledge about the anomalies. Here, we study the problem of few-shot anomaly detection, in which we aim at using a few labeled anomaly examples to train sample-efficient discriminative detection models. To address this problem, we introduce a novel weakly-supervised anomaly detection framework to train detection models without assuming the examples illustrating all possible classes of anomaly. Specifically, the proposed approach learns discriminative normality (regularity) by leveraging the labeled anomalies and a prior probability to enforce expressive representations of normality and unbounded deviated representations of abnormality. This is achieved by an end-to-end optimization of anomaly scores with a neural deviation learning, in which the anomaly scores of normal samples are imposed to approximate scalar scores drawn from the prior while that of anomaly examples is enforced to have statistically significant deviations from these sampled scores in the upper tail. Furthermore, our model is optimized to learn fine-grained normality and abnormality by top-K multiple-instance-learning-based feature subspace deviation learning, allowing more generalized representations. Comprehensive experiments on nine real-world image anomaly detection benchmarks show that our model is substantially more sample-efficient and robust, and performs significantly better than state-of-the-art competing methods in both closed-set and open-set settings. Our model can also offer explanation capability as a result of its prior-driven anomaly score learning. Code and datasets are available at: https://git.io/DevNet.
Confidence-Aware Learning for Camouflaged Object Detection
Jun 22, 2021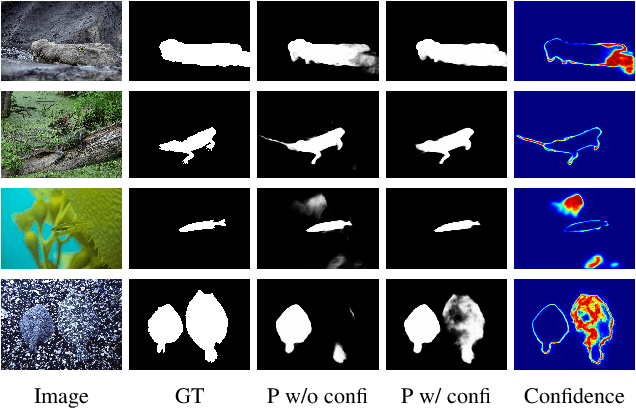
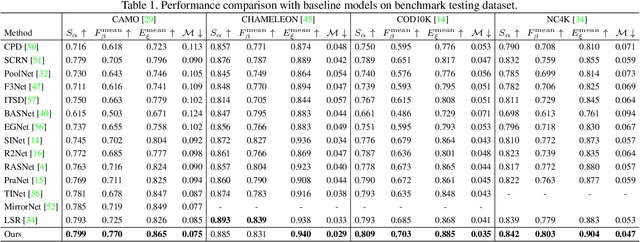
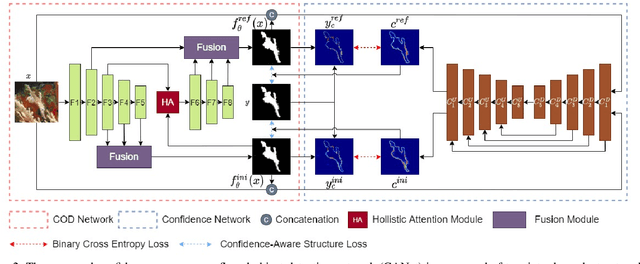
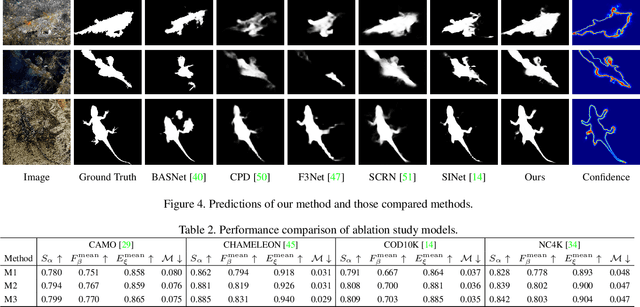
Confidence-aware learning is proven as an effective solution to prevent networks becoming overconfident. We present a confidence-aware camouflaged object detection framework using dynamic supervision to produce both accurate camouflage map and meaningful "confidence" representing model awareness about the current prediction. A camouflaged object detection network is designed to produce our camouflage prediction. Then, we concatenate it with the input image and feed it to the confidence estimation network to produce an one channel confidence map.We generate dynamic supervision for the confidence estimation network, representing the agreement of camouflage prediction with the ground truth camouflage map. With the produced confidence map, we introduce confidence-aware learning with the confidence map as guidance to pay more attention to the hard/low-confidence pixels in the loss function. We claim that, once trained, our confidence estimation network can evaluate pixel-wise accuracy of the prediction without relying on the ground truth camouflage map. Extensive results on four camouflaged object detection testing datasets illustrate the superior performance of the proposed model in explaining the camouflage prediction.
RoI Tanh-polar Transformer Network for Face Parsing in the Wild
Feb 04, 2021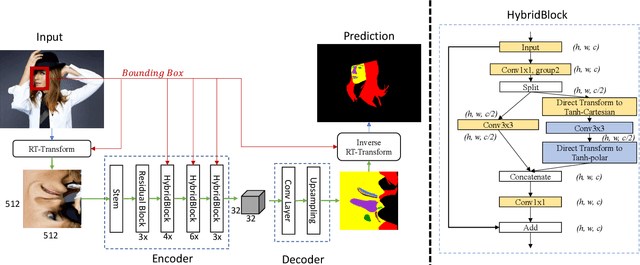


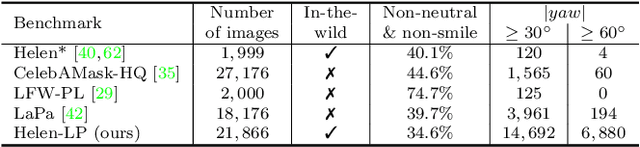
Face parsing aims to predict pixel-wise labels for facial components of a target face in an image. Existing approaches usually crop the target face from the input image with respect to a bounding box calculated during pre-processing, and thus can only parse inner facial Regions of Interest (RoIs). Peripheral regions like hair are ignored and nearby faces that are partially included in the bounding box can cause distractions. Moreover, these methods are only trained and evaluated on near-frontal portrait images and thus their performance for in-the-wild cases were unexplored. To address these issues, this paper makes three contributions. First, we introduce iBugMask dataset for face parsing in the wild containing 1,000 manually annotated images with large variations in sizes, poses, expressions and background, and Helen-LP, a large-pose training set containing 21,866 images generated using head pose augmentation. Second, we propose RoI Tanh-polar transform that warps the whole image to a Tanh-polar representation with a fixed ratio between the face area and the context, guided by the target bounding box. The new representation contains all information in the original image, and allows for rotation equivariance in the convolutional neural networks (CNNs). Third, we propose a hybrid residual representation learning block, coined HybridBlock, that contains convolutional layers in both the Tanh-polar space and the Tanh-Cartesian space, allowing for receptive fields of different shapes in CNNs. Through extensive experiments, we show that the proposed method significantly improves the state-of-the-art for face parsing in the wild.
MLFcGAN: Multi-level Feature Fusion based Conditional GAN for Underwater Image Color Correction
Feb 13, 2020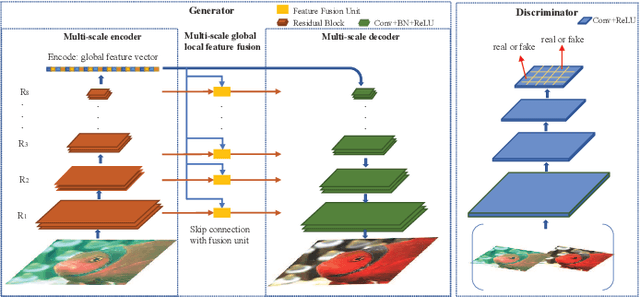



Color correction for underwater images has received increasing interests, due to its critical role in facilitating available mature vision algorithms for underwater scenarios. Inspired by the stunning success of deep convolutional neural networks (DCNNs) techniques in many vision tasks, especially the strength in extracting features in multiple scales, we propose a deep multi-scale feature fusion net based on the conditional generative adversarial network (GAN) for underwater image color correction. In our network, multi-scale features are extracted first, followed by augmenting local features on each scale with global features. This design was verified to facilitate more effective and faster network learning, resulting in better performance in both color correction and detail preservation. We conducted extensive experiments and compared with the state-of-the-art approaches quantitatively and qualitatively, showing that our method achieves significant improvements.
Task-driven Self-supervised Bi-channel Networks Learning for Diagnosis of Breast Cancers with Mammography
Jan 15, 2021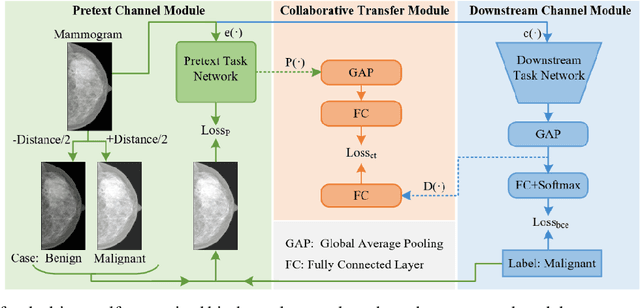

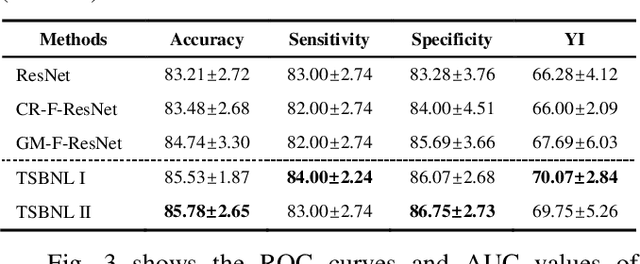
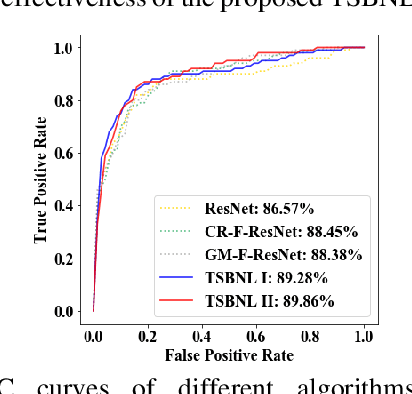
Deep learning can promote the mammography-based computer-aided diagnosis (CAD) for breast cancers, but it generally suffers from the small size sample problem. In this work, a task-driven self-supervised bi-channel networks (TSBNL) framework is proposed to improve the performance of classification network with limited mammograms. In particular, a new gray-scale image mapping (GSIM) task for image restoration is designed as the pretext task to improve discriminate feature representation with label information of mammograms. The TSBNL then innovatively integrates this image restoration network and the downstream classification network into a unified SSL framework, and transfers the knowledge from the pretext network to the classification network with improved diagnostic accuracy. The proposed algorithm is evaluated on a public INbreast mammogram dataset. The experimental results indicate that it outperforms the conventional SSL algorithms for diagnosis of breast cancers with limited samples.
Unsupervised Deep Features for Privacy Image Classification
Sep 24, 2019
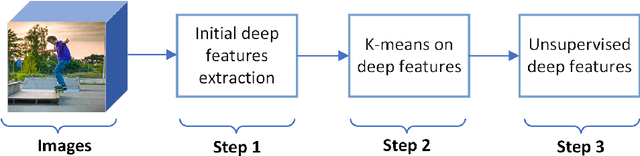

Sharing images online poses security threats to a wide range of users due to the unawareness of privacy information. Deep features have been demonstrated to be a powerful representation for images. However, deep features usually suffer from the issues of a large size and requiring a huge amount of data for fine-tuning. In contrast to normal images (e.g., scene images), privacy images are often limited because of sensitive information. In this paper, we propose a novel approach that can work on limited data and generate deep features of smaller size. For training images, we first extract the initial deep features from the pre-trained model and then employ the K-means clustering algorithm to learn the centroids of these initial deep features. We use the learned centroids from training features to extract the final features for each testing image and encode our final features with the triangle encoding. To improve the discriminability of the features, we further perform the fusion of two proposed unsupervised deep features obtained from different layers. Experimental results show that the proposed features outperform state-of-the-art deep features, in terms of both classification accuracy and testing time.
COTR: Correspondence Transformer for Matching Across Images
Mar 25, 2021
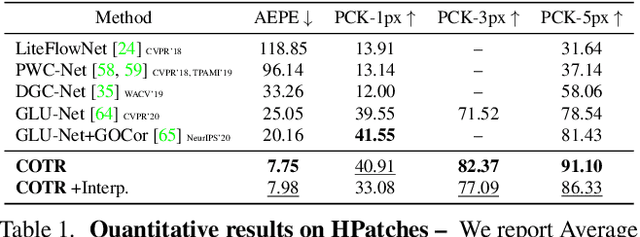
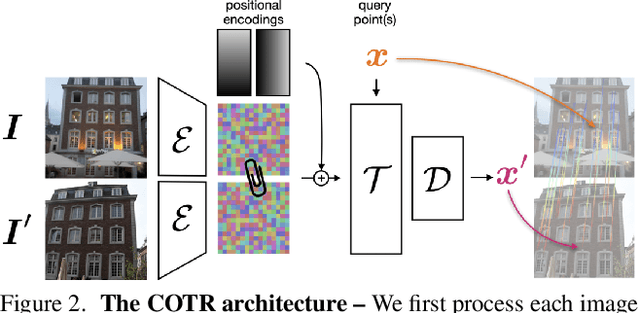
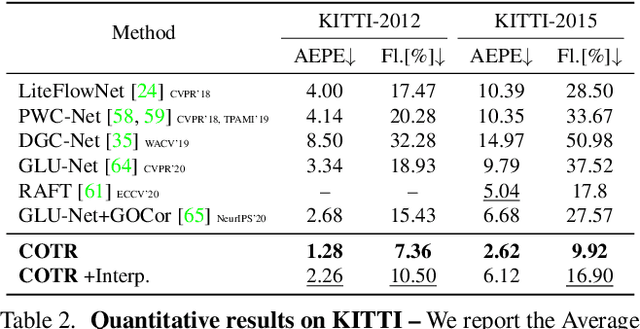
We propose a novel framework for finding correspondences in images based on a deep neural network that, given two images and a query point in one of them, finds its correspondence in the other. By doing so, one has the option to query only the points of interest and retrieve sparse correspondences, or to query all points in an image and obtain dense mappings. Importantly, in order to capture both local and global priors, and to let our model relate between image regions using the most relevant among said priors, we realize our network using a transformer. At inference time, we apply our correspondence network by recursively zooming in around the estimates, yielding a multiscale pipeline able to provide highly-accurate correspondences. Our method significantly outperforms the state of the art on both sparse and dense correspondence problems on multiple datasets and tasks, ranging from wide-baseline stereo to optical flow, without any retraining for a specific dataset. We commit to releasing data, code, and all the tools necessary to train from scratch and ensure reproducibility.
To Beta or Not To Beta: Information Bottleneck for DigitaL Image Forensics
Aug 11, 2019
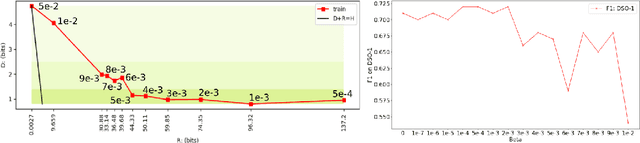

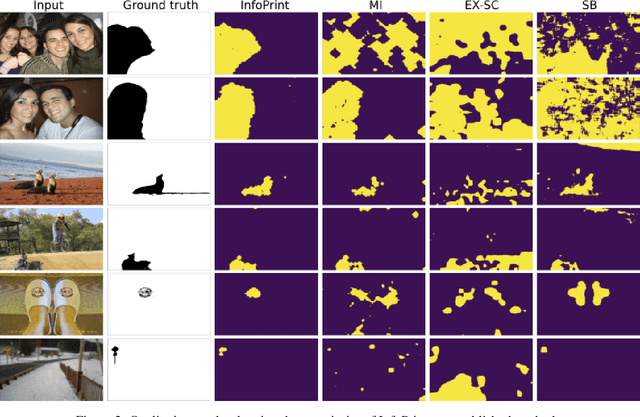
We consider an information theoretic approach to address the problem of identifying fake digital images. We propose an innovative method to formulate the issue of localizing manipulated regions in an image as a deep representation learning problem using the Information Bottleneck (IB), which has recently gained popularity as a framework for interpreting deep neural networks. Tampered images pose a serious predicament since digitized media is a ubiquitous part of our lives. These are facilitated by the easy availability of image editing software and aggravated by recent advances in deep generative models such as GANs. We propose InfoPrint, a computationally efficient solution to the IB formulation using approximate variational inference and compare it to a numerical solution that is computationally expensive. Testing on a number of standard datasets, we demonstrate that InfoPrint outperforms the state-of-the-art and the numerical solution. Additionally, it also has the ability to detect alterations made by inpainting GANs.
HOME: Heatmap Output for future Motion Estimation
May 23, 2021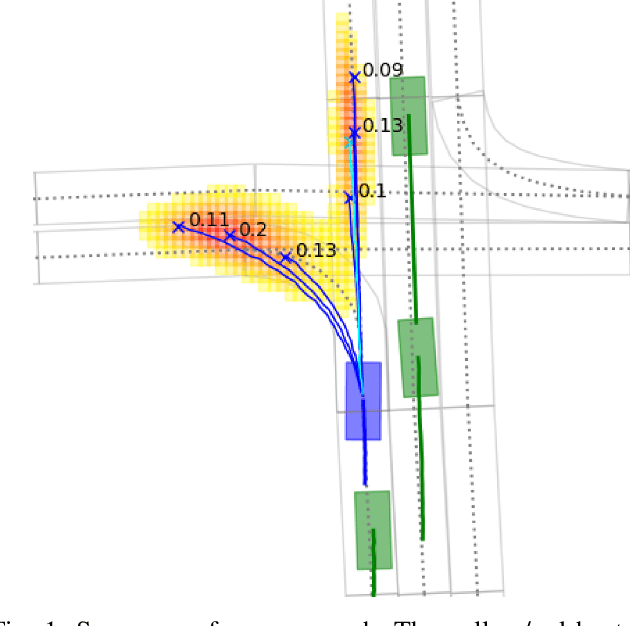
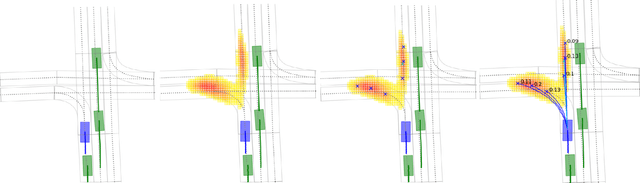
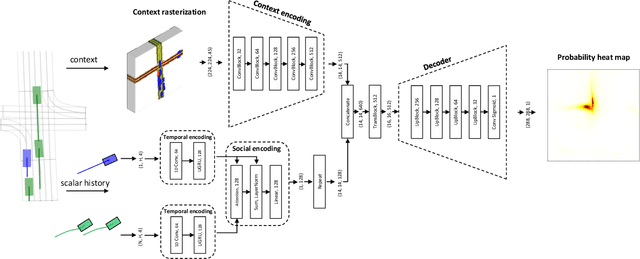
In this paper, we propose HOME, a framework tackling the motion forecasting problem with an image output representing the probability distribution of the agent's future location. This method allows for a simple architecture with classic convolution networks coupled with attention mechanism for agent interactions, and outputs an unconstrained 2D top-view representation of the agent's possible future. Based on this output, we design two methods to sample a finite set of agent's future locations. These methods allow us to control the optimization trade-off between miss rate and final displacement error for multiple modalities without having to retrain any part of the model. We apply our method to the Argoverse Motion Forecasting Benchmark and achieve 1st place on the online leaderboard.