 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Image Classification Robustness through Selective CNN-Filters Fine-Tuning
Apr 08, 2019


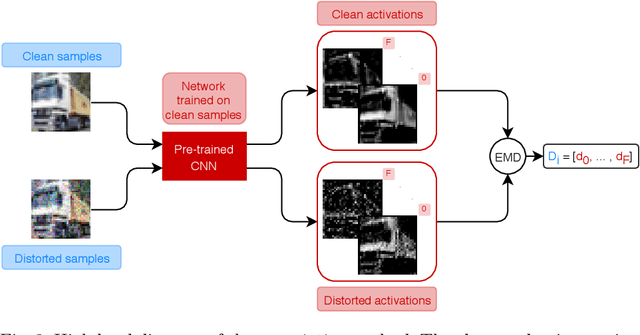
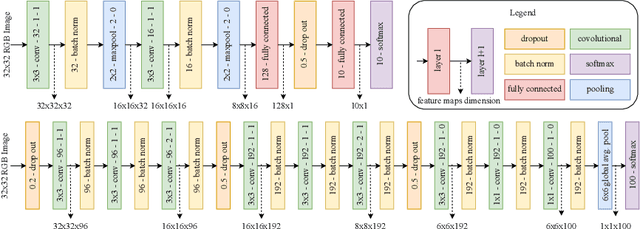
Image quality plays a big role in CNN-based image classification performance. Fine-tuning the network with distorted samples may be too costly for large networks. To solve this issue, we propose a transfer learning approach optimized to keep into account that in each layer of a CNN some filters are more susceptible to image distortion than others. Our method identifies the most susceptible filters and applies retraining only to the filters that show the highest activation maps distance between clean and distorted images. Filters are ranked using the Borda count election method and then only the most affected filters are fine-tuned. This significantly reduces the number of parameters to retrain. We evaluate this approach on the CIFAR-10 and CIFAR-100 datasets, testing it on two different models and two different types of distortion. Results show that the proposed transfer learning technique recovers most of the lost performance due to input data distortion, at a considerably faster pace with respect to existing methods, thanks to the reduced number of parameters to fine-tune. When few noisy samples are provided for training, our filter-level fine tuning performs particularly well, also outperforming state of the art layer-level transfer learning approaches.
RECON: Rapid Exploration for Open-World Navigation with Latent Goal Models
Apr 12, 2021
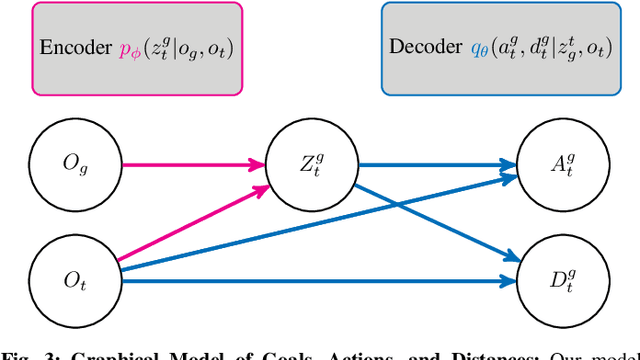
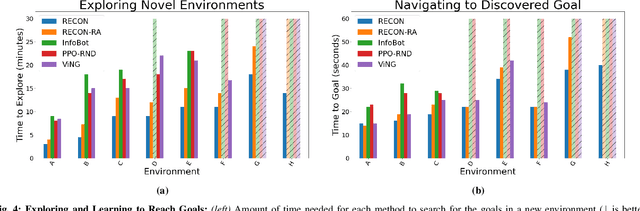
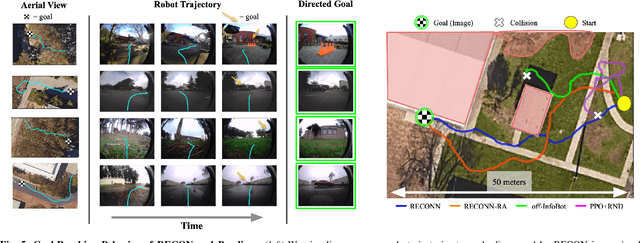
We describe a robotic learning system for autonomous navigation in diverse environments. At the core of our method are two components: (i) a non-parametric map that reflects the connectivity of the environment but does not require geometric reconstruction or localization, and (ii) a latent variable model of distances and actions that enables efficiently constructing and traversing this map. The model is trained on a large dataset of prior experience to predict the expected amount of time and next action needed to transit between the current image and a goal image. Training the model in this way enables it to develop a representation of goals robust to distracting information in the input images, which aids in deploying the system to quickly explore new environments. We demonstrate our method on a mobile ground robot in a range of outdoor navigation scenarios. Our method can learn to reach new goals, specified as images, in a radius of up to 80 meters in just 20 minutes, and reliably revisit these goals in changing environments. We also demonstrate our method's robustness to previously-unseen obstacles and variable weather conditions. We encourage the reader to visit the project website for videos of our experiments and demonstrations https://sites.google.com/view/recon-robot
An Attention and Prediction Guided Visual System for Small Target Motion Detection in Complex Natural Environments
Apr 28, 2021
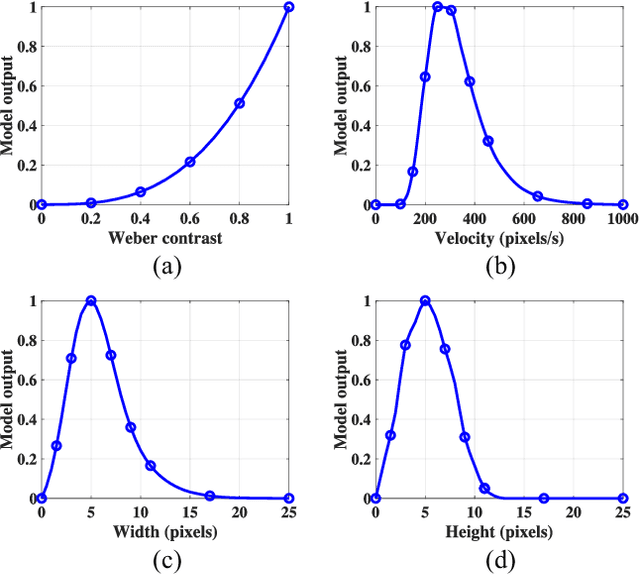
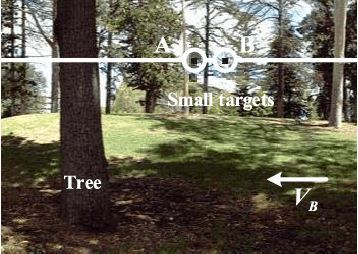
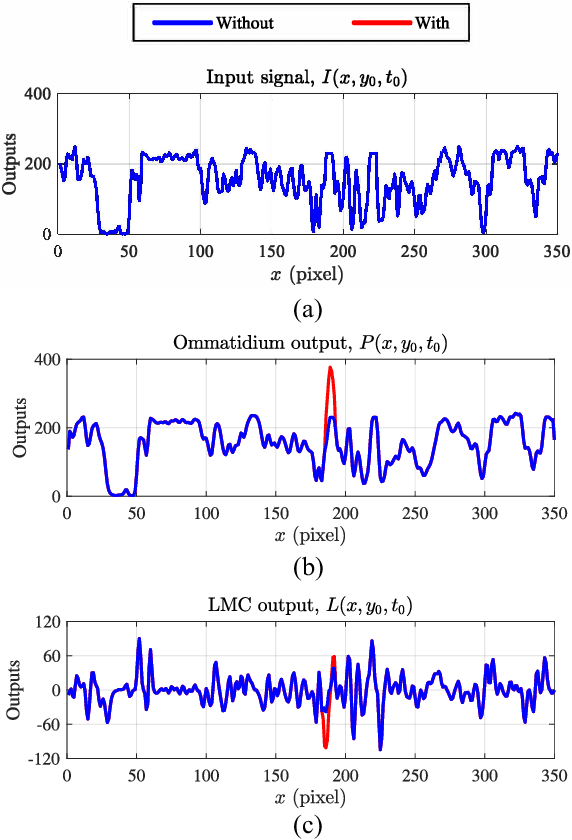
Small target motion detection within complex natural environment is an extremely challenging task for autonomous robots. Surprisingly, visual systems of insects have evolved to be highly efficient in detecting mates and tracking prey, even though targets are as small as a few pixels in visual field. The excellent sensitivity to small target motion relies on a class of specialized neurons called small target motion detectors (STMDs). However, existing STMD-based models are heavily dependent on visual contrast and perform poorly in complex natural environment where small targets always exhibit extremely low contrast to neighboring backgrounds. In this paper, we propose an attention and prediction guided visual system to overcome this limitation. The proposed visual system mainly consists of three subsystems, including an attention module, a STMD-based neural network, and a prediction module. The attention module searches for potential small targets in the predicted areas of input image and enhances their contrast to complex background. The STMD-based neural network receives the contrast-enhanced image and discriminates small moving targets from background false positives. The prediction module foresees future positions of the detected targets and generates a prediction map for the attention module. The three subsystems are connected in a recurrent architecture allowing information processed sequentially to activate specific areas for small target detection. Extensive experiments on synthetic and real-world datasets demonstrate the effectiveness and superiority of the proposed visual system for detecting small, low-contrast moving targets against complex natural environment.
Pre-training without Natural Images
Jan 21, 2021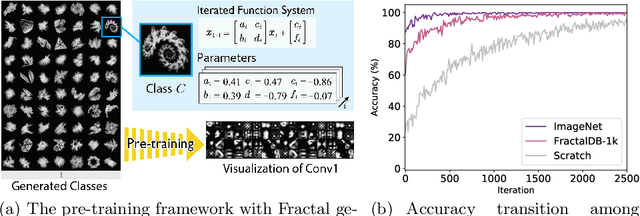
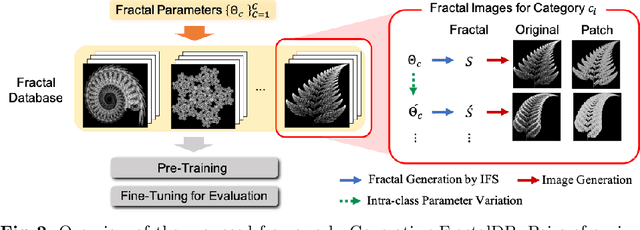

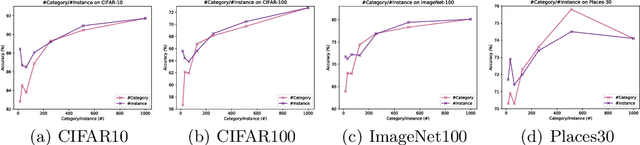
Is it possible to use convolutional neural networks pre-trained without any natural images to assist natural image understanding? The paper proposes a novel concept, Formula-driven Supervised Learning. We automatically generate image patterns and their category labels by assigning fractals, which are based on a natural law existing in the background knowledge of the real world. Theoretically, the use of automatically generated images instead of natural images in the pre-training phase allows us to generate an infinite scale dataset of labeled images. Although the models pre-trained with the proposed Fractal DataBase (FractalDB), a database without natural images, does not necessarily outperform models pre-trained with human annotated datasets at all settings, we are able to partially surpass the accuracy of ImageNet/Places pre-trained models. The image representation with the proposed FractalDB captures a unique feature in the visualization of convolutional layers and attentions.
Face Anonymization by Manipulating Decoupled Identity Representation
May 24, 2021

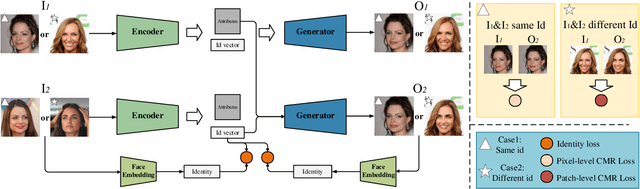

Privacy protection on human biological information has drawn increasing attention in recent years, among which face anonymization plays an importance role. We propose a novel approach which protects identity information of facial images from leakage with slightest modification. Specifically, we disentangle identity representation from other facial attributes leveraging the power of generative adversarial networks trained on a conditional multi-scale reconstruction (CMR) loss and an identity loss. We evaulate the disentangle ability of our model, and propose an effective method for identity anonymization, namely Anonymous Identity Generation (AIG), to reach the goal of face anonymization meanwhile maintaining similarity to the original image as much as possible. Quantitative and qualitative results demonstrate our method's superiority compared with the SOTAs on both visual quality and anonymization success rate.
Punny Captions: Witty Wordplay in Image Descriptions
May 31, 2018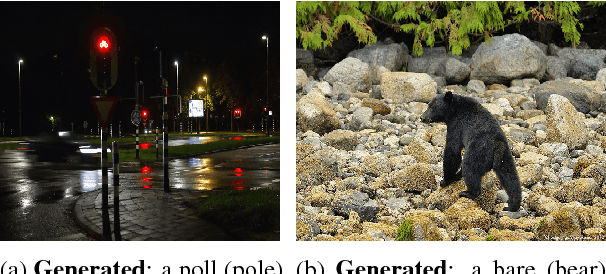
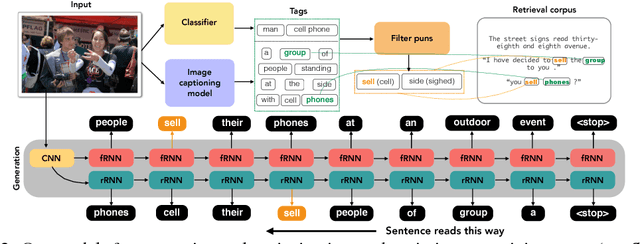
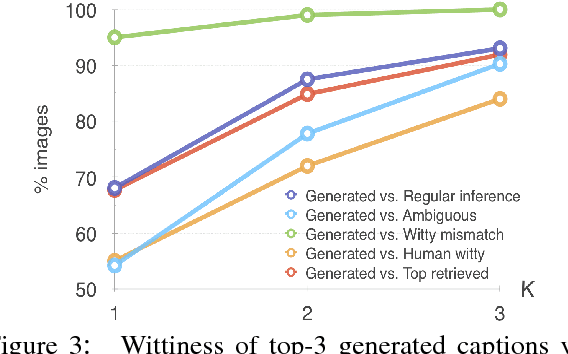

Wit is a form of rich interaction that is often grounded in a specific situation (e.g., a comment in response to an event). In this work, we attempt to build computational models that can produce witty descriptions for a given image. Inspired by a cognitive account of humor appreciation, we employ linguistic wordplay, specifically puns, in image descriptions. We develop two approaches which involve retrieving witty descriptions for a given image from a large corpus of sentences, or generating them via an encoder-decoder neural network architecture. We compare our approach against meaningful baseline approaches via human studies and show substantial improvements. We find that when a human is subject to similar constraints as the model regarding word usage and style, people vote the image descriptions generated by our model to be slightly wittier than human-written witty descriptions. Unsurprisingly, humans are almost always wittier than the model when they are free to choose the vocabulary, style, etc.
Convolutional Dictionary Pair Learning Network for Image Representation Learning
Jan 15, 2020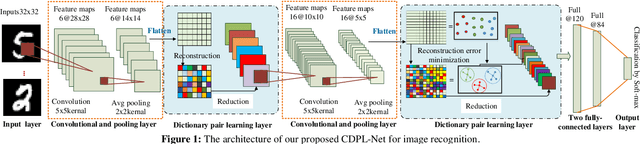
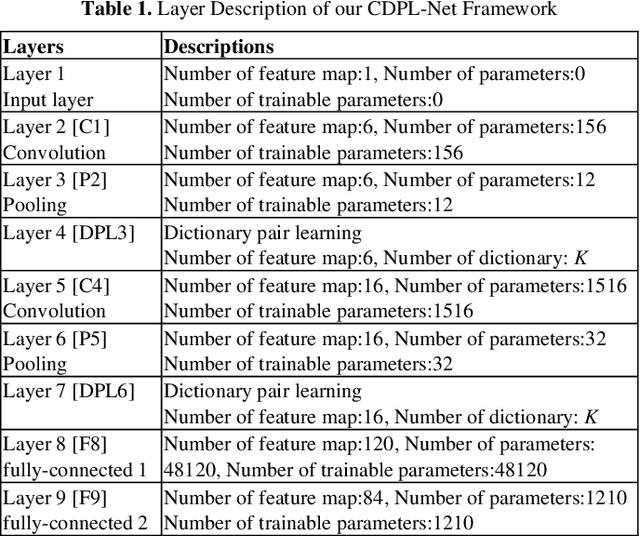
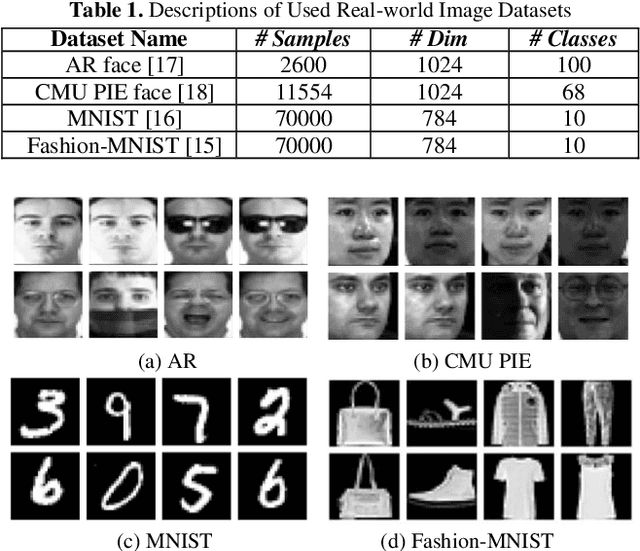
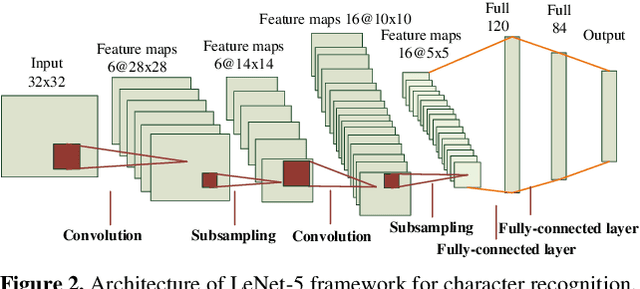
Both the Dictionary Learning (DL) and Convolutional Neural Networks (CNN) are powerful image representation learning systems based on different mechanisms and principles, however whether we can seamlessly integrate them to improve the per-formance is noteworthy exploring. To address this issue, we propose a novel generalized end-to-end representation learning architecture, dubbed Convolutional Dictionary Pair Learning Network (CDPL-Net) in this paper, which integrates the learning schemes of the CNN and dictionary pair learning into a unified framework. Generally, the architecture of CDPL-Net includes two convolutional/pooling layers and two dictionary pair learn-ing (DPL) layers in the representation learning module. Besides, it uses two fully-connected layers as the multi-layer perception layer in the nonlinear classification module. In particular, the DPL layer can jointly formulate the discriminative synthesis and analysis representations driven by minimizing the batch based reconstruction error over the flatted feature maps from the convolution/pooling layer. Moreover, DPL layer uses l1-norm on the analysis dictionary so that sparse representation can be delivered, and the embedding process will also be robust to noise. To speed up the training process of DPL layer, the efficient stochastic gradient descent is used. Extensive simulations on real databases show that our CDPL-Net can deliver enhanced performance over other state-of-the-art methods.
Ensemble Augmentation for Deep Neural Networks Using 1-D Time Series Vibration Data
Aug 06, 2021
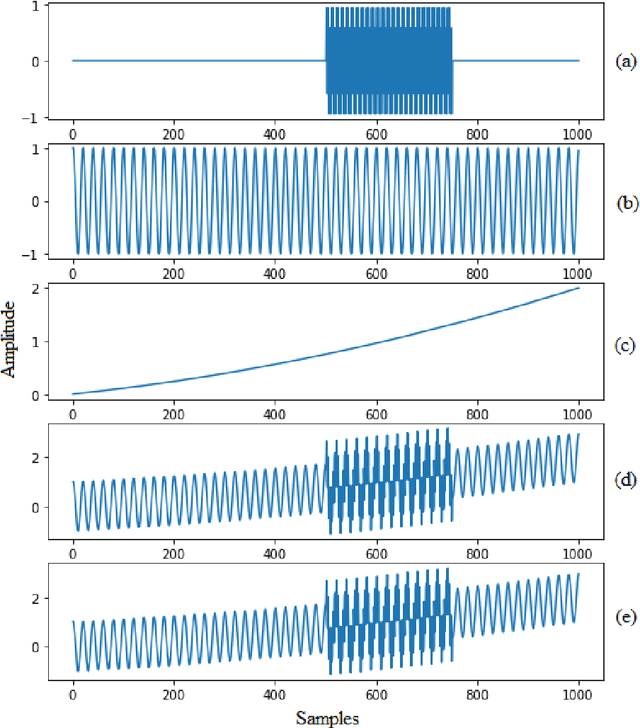
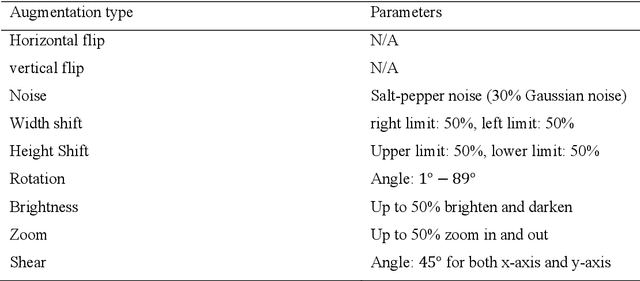
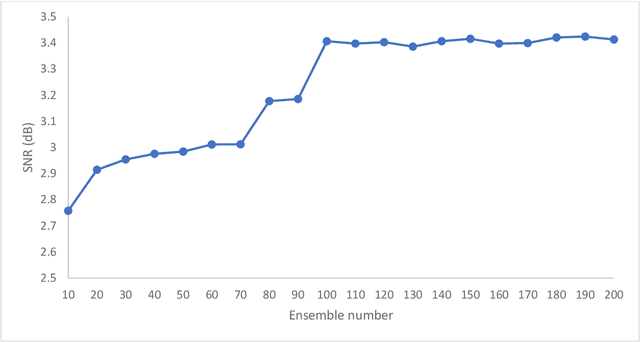
Time-series data are one of the fundamental types of raw data representation used in data-driven techniques. In machine condition monitoring, time-series vibration data are overly used in data mining for deep neural networks. Typically, vibration data is converted into images for classification using Deep Neural Networks (DNNs), and scalograms are the most effective form of image representation. However, the DNN classifiers require huge labeled training samples to reach their optimum performance. So, many forms of data augmentation techniques are applied to the classifiers to compensate for the lack of training samples. However, the scalograms are graphical representations where the existing augmentation techniques suffer because they either change the graphical meaning or have too much noise in the samples that change the physical meaning. In this study, a data augmentation technique named ensemble augmentation is proposed to overcome this limitation. This augmentation method uses the power of white noise added in ensembles to the original samples to generate real-like samples. After averaging the signal with ensembles, a new signal is obtained that contains the characteristics of the original signal. The parameters for the ensemble augmentation are validated using a simulated signal. The proposed method is evaluated using 10 class bearing vibration data using three state-of-the-art Transfer Learning (TL) models, namely, Inception-V3, MobileNet-V2, and ResNet50. Augmented samples are generated in two increments: the first increment generates the same number of fake samples as the training samples, and in the second increment, the number of samples is increased gradually. The outputs from the proposed method are compared with no augmentation, augmentations using deep convolution generative adversarial network (DCGAN), and several geometric transformation-based augmentations...
An Investigation of Feature-based Nonrigid Image Registration using Gaussian Process
Jan 12, 2020
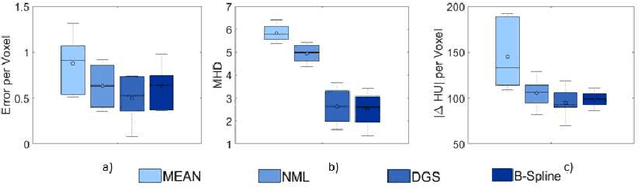
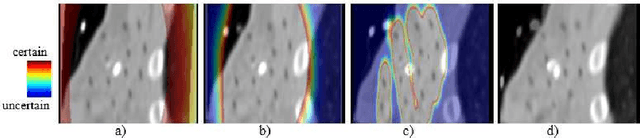
For a wide range of clinical applications, such as adaptive treatment planning or intraoperative image update, feature-based deformable registration (FDR) approaches are widely employed because of their simplicity and low computational complexity. FDR algorithms estimate a dense displacement field by interpolating a sparse field, which is given by the established correspondence between selected features. In this paper, we consider the deformation field as a Gaussian Process (GP), whereas the selected features are regarded as prior information on the valid deformations. Using GP, we are able to estimate the both dense displacement field and a corresponding uncertainty map at once. Furthermore, we evaluated the performance of different hyperparameter settings for squared exponential kernels with synthetic, phantom and clinical data respectively. The quantitative comparison shows, GP-based interpolation has performance on par with state-of-the-art B-spline interpolation. The greatest clinical benefit of GP-based interpolation is that it gives a reliable estimate of the mathematical uncertainty of the calculated dense displacement map.
IEGAN: Multi-purpose Perceptual Quality Image Enhancement Using Generative Adversarial Network
Nov 22, 2018
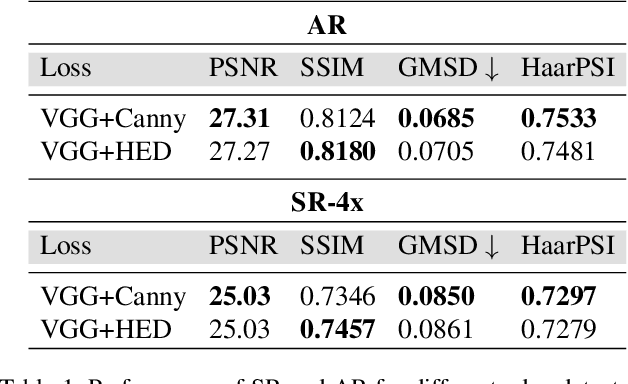
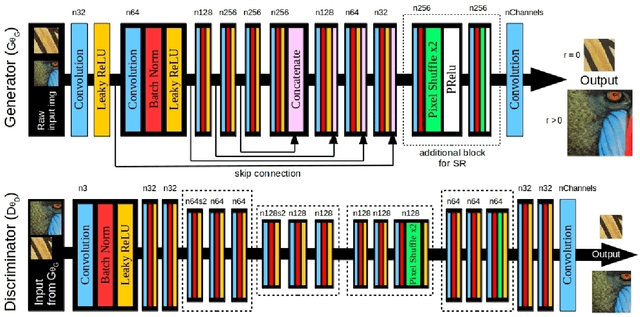
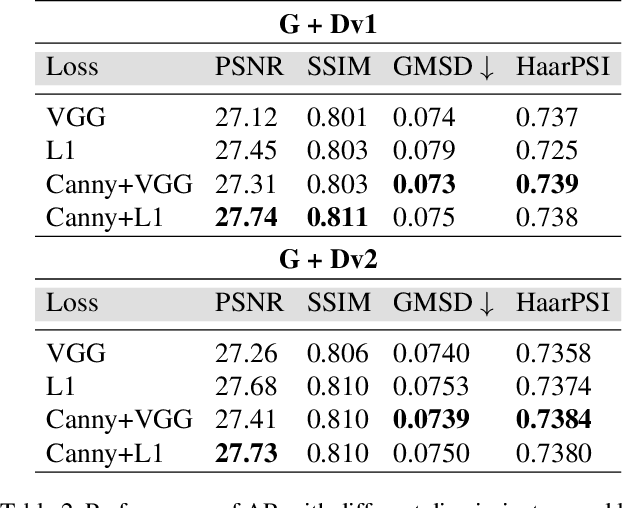
Despite the breakthroughs in quality of image enhancement, an end-to-end solution for simultaneous recovery of the finer texture details and sharpness for degraded images with low resolution is still unsolved. Some existing approaches focus on minimizing the pixel-wise reconstruction error which results in a high peak signal-to-noise ratio. The enhanced images fail to provide high-frequency details and are perceptually unsatisfying, i.e., they fail to match the quality expected in a photo-realistic image. In this paper, we present Image Enhancement Generative Adversarial Network (IEGAN), a versatile framework capable of inferring photo-realistic natural images for both artifact removal and super-resolution simultaneously. Moreover, we propose a new loss function consisting of a combination of reconstruction loss, feature loss and an edge loss counterpart. The feature loss helps to push the output image to the natural image manifold and the edge loss preserves the sharpness of the output image. The reconstruction loss provides low-level semantic information to the generator regarding the quality of the generated images compared to the original. Our approach has been experimentally proven to recover photo-realistic textures from heavily compressed low-resolution images on public benchmarks and our proposed high-resolution World100 dataset.