 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
IEGAN: Multi-purpose Perceptual Quality Image Enhancement Using Generative Adversarial Network
Nov 22, 2018

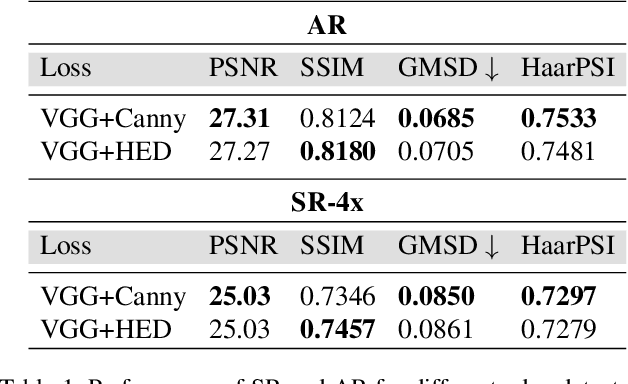
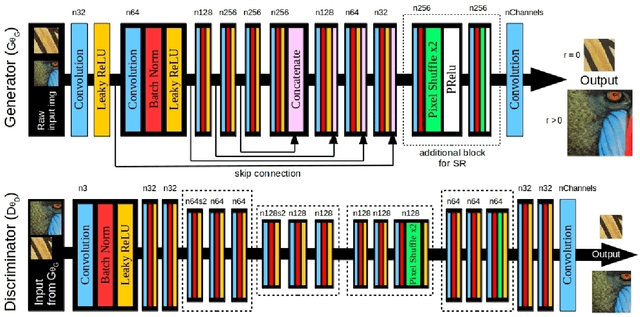
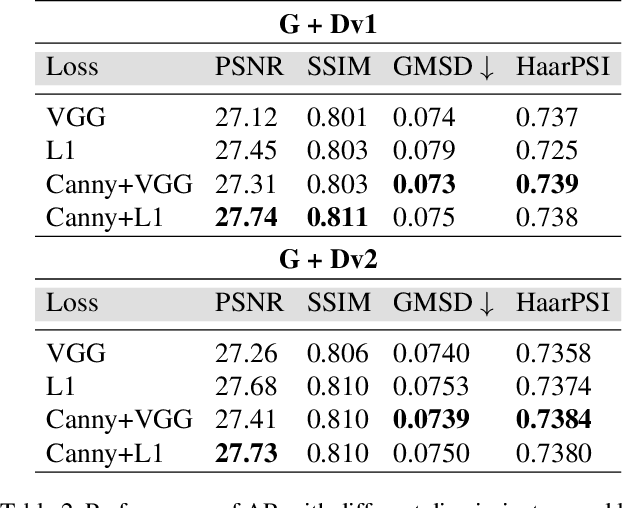
Despite the breakthroughs in quality of image enhancement, an end-to-end solution for simultaneous recovery of the finer texture details and sharpness for degraded images with low resolution is still unsolved. Some existing approaches focus on minimizing the pixel-wise reconstruction error which results in a high peak signal-to-noise ratio. The enhanced images fail to provide high-frequency details and are perceptually unsatisfying, i.e., they fail to match the quality expected in a photo-realistic image. In this paper, we present Image Enhancement Generative Adversarial Network (IEGAN), a versatile framework capable of inferring photo-realistic natural images for both artifact removal and super-resolution simultaneously. Moreover, we propose a new loss function consisting of a combination of reconstruction loss, feature loss and an edge loss counterpart. The feature loss helps to push the output image to the natural image manifold and the edge loss preserves the sharpness of the output image. The reconstruction loss provides low-level semantic information to the generator regarding the quality of the generated images compared to the original. Our approach has been experimentally proven to recover photo-realistic textures from heavily compressed low-resolution images on public benchmarks and our proposed high-resolution World100 dataset.
Semi-supervised CNN for Single Image Rain Removal
Jul 29, 2018

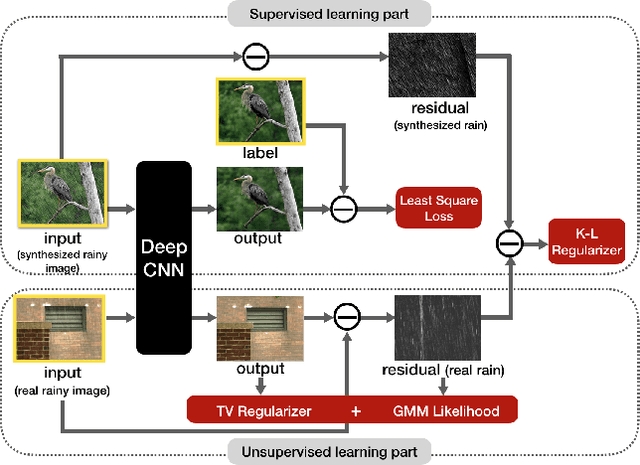
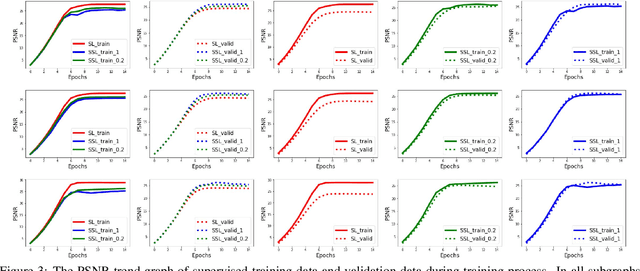
Single image rain removal is a typical inverse problem in computer vision. The deep learning technique has been verified to be effective to this task and achieved state-of-the-art performance. However, the method needs to pre-collect a large set of image pairs with/without rains for training, which not only makes the method laborsome to be practically implemented, but also tends to make the trained network bias to the training samples while less generalized to test samples with unseen rain types in training. To this issue, this paper firstly proposes a semisupervised learning paradigm to this task. Different from traditional deep learning methods which use only supervised image pairs with/without rains, we put the real rainy images, without need of their clean ones, into the network training process as well. This is realized by elaborately formulating the residual between an input rainy image and its expected network output (clear image without rains) as a concise patch-wised Mixture of Gaussians distribution. The entire objective function for training network is thus the combination of the supervised data loss (least square loss between input clear image and the network output) and the unsupervised data loss. In this way, all such unsupervised rainy images, which is much easier to collect than supervised ones, can be rationally fed into the network training process, and thus both the short-of-training-sample and bias-to-supervised-sample issues can be evidently alleviated. Experiments implemented on synthetic and real data experiments verify the superiority of our model as compared to the state-of-the-arts.
Region-Aware Network: Model Human's Top-Down Visual Perception Mechanism for Crowd Counting
Jun 23, 2021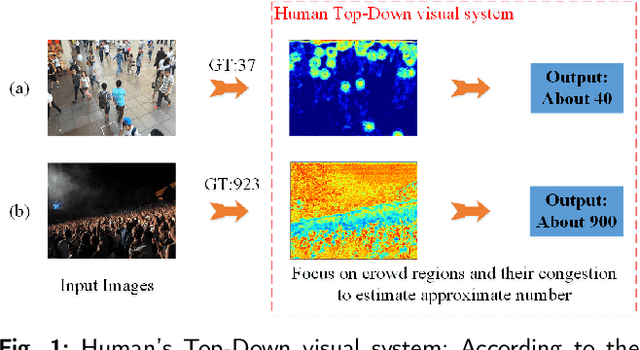

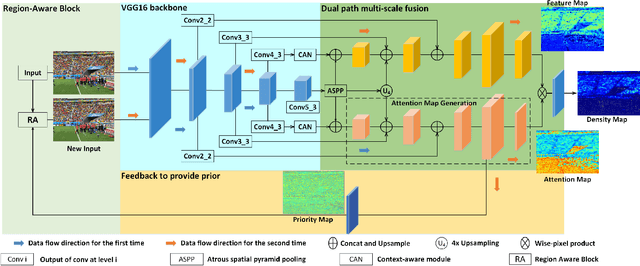
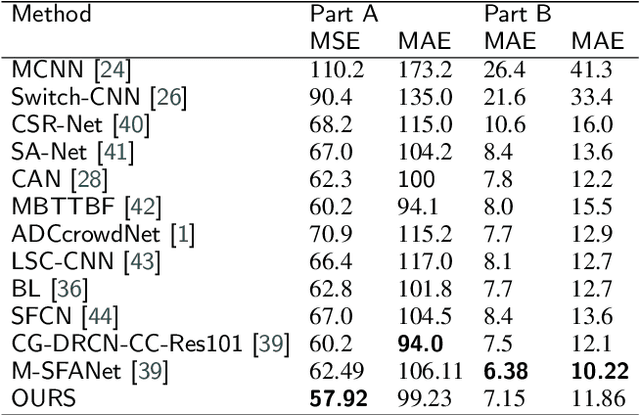
Background noise and scale variation are common problems that have been long recognized in crowd counting. Humans glance at a crowd image and instantly know the approximate number of human and where they are through attention the crowd regions and the congestion degree of crowd regions with a global receptive filed. Hence, in this paper, we propose a novel feedback network with Region-Aware block called RANet by modeling human's Top-Down visual perception mechanism. Firstly, we introduce a feedback architecture to generate priority maps that provide prior about candidate crowd regions in input images. The prior enables the RANet pay more attention to crowd regions. Then we design Region-Aware block that could adaptively encode the contextual information into input images through global receptive field. More specifically, we scan the whole input images and its priority maps in the form of column vector to obtain a relevance matrix estimating their similarity. The relevance matrix obtained would be utilized to build global relationships between pixels. Our method outperforms state-of-the-art crowd counting methods on several public datasets.
Single-pixel diffuser camera
May 06, 2021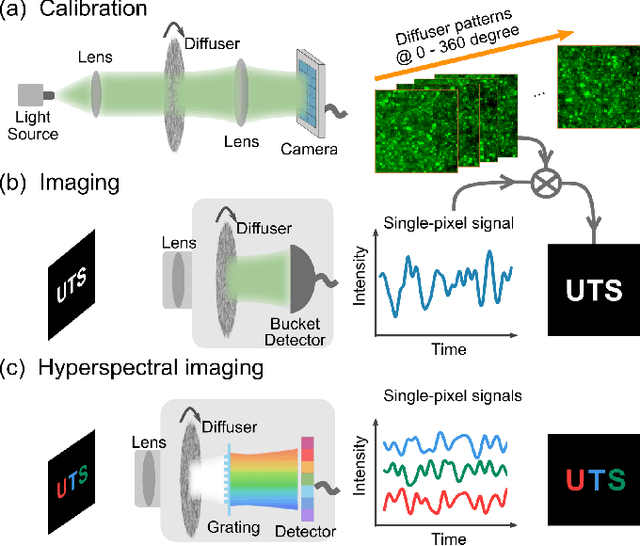
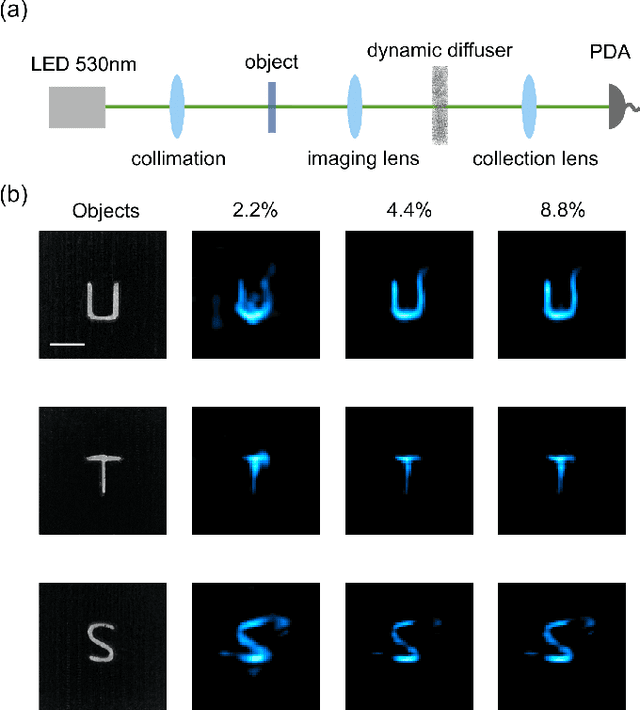
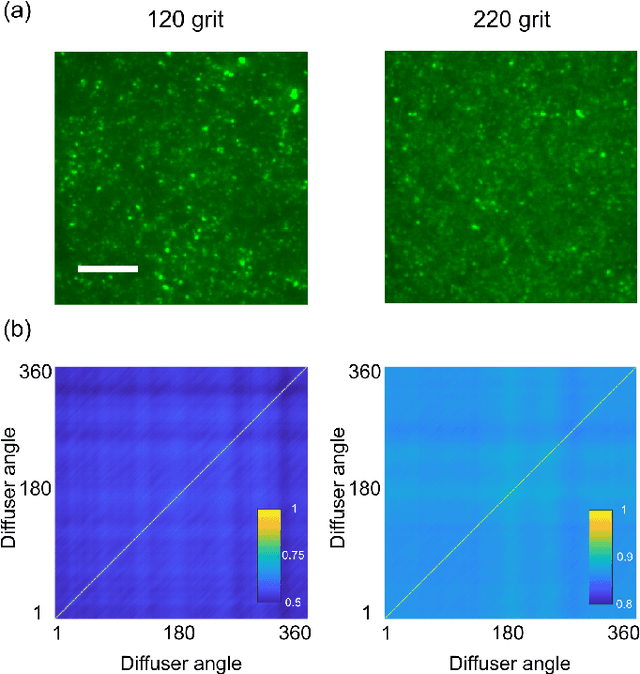
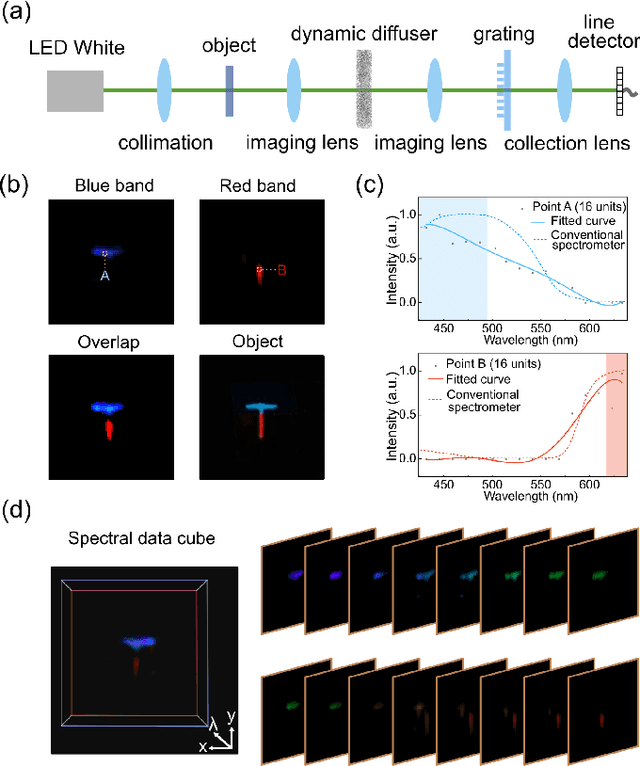
We present a compact, diffuser-assisted, single-pixel computational camera. A rotating ground glass diffuser is adopted, in preference to a commonly used digital micro-mirror device (DMD), to encode a two-dimensional (2D) image into single-pixel signals. We retrieve images with an 8.8% sampling ratio after the calibration of the pseudo-random pattern of the diffuser under incoherent illumination. Furthermore, we demonstrate hyperspectral imaging with line array detection by adding a diffraction grating. The implementation results in a cost-effective single-pixel camera for high-dimensional imaging, with potential for imaging in non-visible wavebands.
Auditing for Diversity using Representative Examples
Jul 15, 2021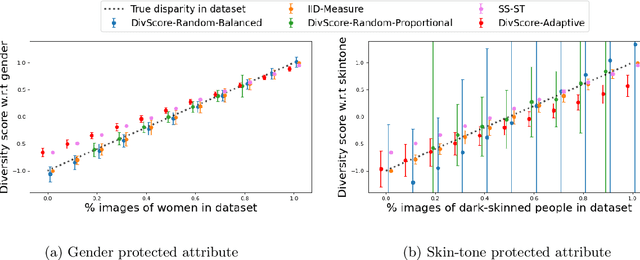
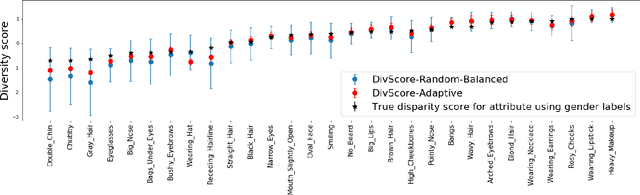
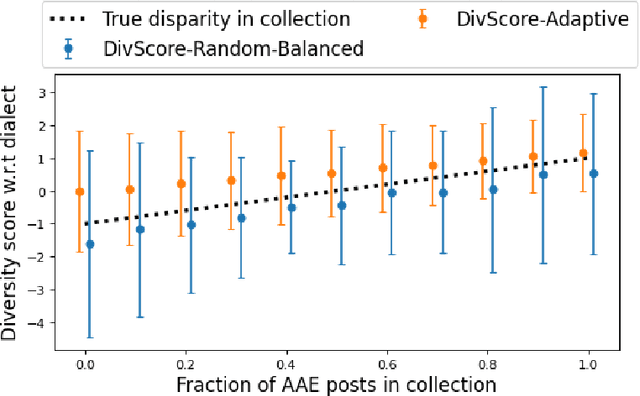
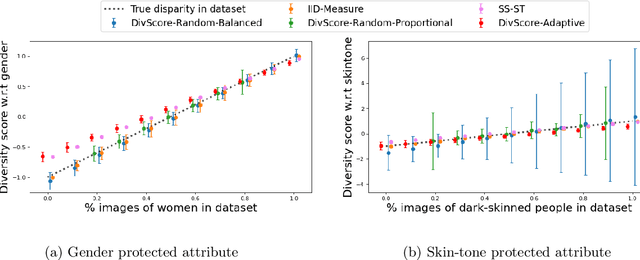
Assessing the diversity of a dataset of information associated with people is crucial before using such data for downstream applications. For a given dataset, this often involves computing the imbalance or disparity in the empirical marginal distribution of a protected attribute (e.g. gender, dialect, etc.). However, real-world datasets, such as images from Google Search or collections of Twitter posts, often do not have protected attributes labeled. Consequently, to derive disparity measures for such datasets, the elements need to hand-labeled or crowd-annotated, which are expensive processes. We propose a cost-effective approach to approximate the disparity of a given unlabeled dataset, with respect to a protected attribute, using a control set of labeled representative examples. Our proposed algorithm uses the pairwise similarity between elements in the dataset and elements in the control set to effectively bootstrap an approximation to the disparity of the dataset. Importantly, we show that using a control set whose size is much smaller than the size of the dataset is sufficient to achieve a small approximation error. Further, based on our theoretical framework, we also provide an algorithm to construct adaptive control sets that achieve smaller approximation errors than randomly chosen control sets. Simulations on two image datasets and one Twitter dataset demonstrate the efficacy of our approach (using random and adaptive control sets) in auditing the diversity of a wide variety of datasets.
Voice2Mesh: Cross-Modal 3D Face Model Generation from Voices
Apr 21, 2021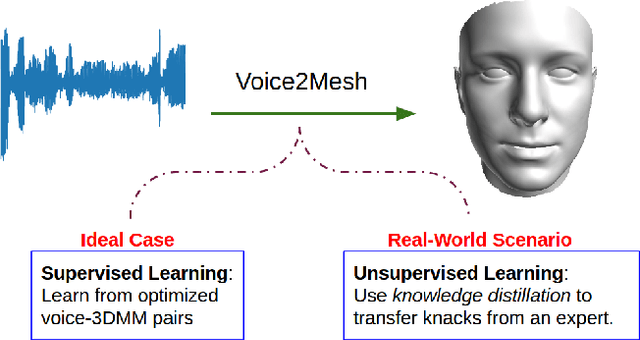
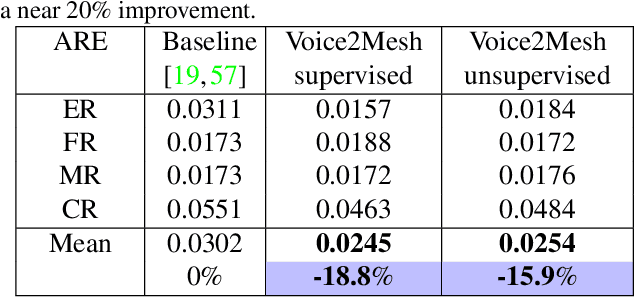
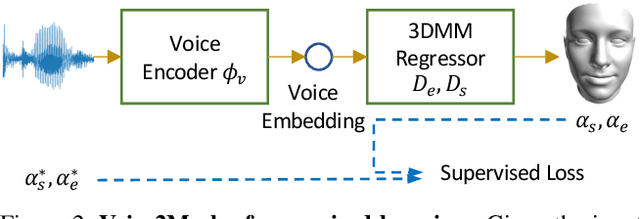

This work focuses on the analysis that whether 3D face models can be learned from only the speech inputs of speakers. Previous works for cross-modal face synthesis study image generation from voices. However, image synthesis includes variations such as hairstyles, backgrounds, and facial textures, that are arguably irrelevant to voice or without direct studies to show correlations. We instead investigate the ability to reconstruct 3D faces to concentrate on only geometry, which is more physiologically grounded. We propose both the supervised learning and unsupervised learning frameworks. Especially we demonstrate how unsupervised learning is possible in the absence of a direct voice-to-3D-face dataset under limited availability of 3D face scans when the model is equipped with knowledge distillation. To evaluate the performance, we also propose several metrics to measure the geometric fitness of two 3D faces based on points, lines, and regions. We find that 3D face shapes can be reconstructed from voices. Experimental results suggest that 3D faces can be reconstructed from voices, and our method can improve the performance over the baseline. The best performance gains (15% - 20%) on ear-to-ear distance ratio metric (ER) coincides with the intuition that one can roughly envision whether a speaker's face is overall wider or thinner only from a person's voice. See our project page for codes and data.
Memory Efficient 3D U-Net with Reversible Mobile Inverted Bottlenecks for Brain Tumor Segmentation
Apr 21, 2021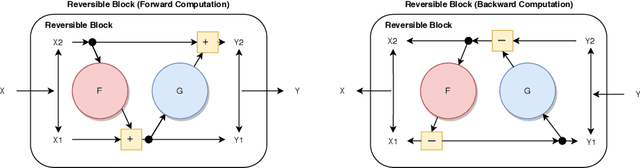

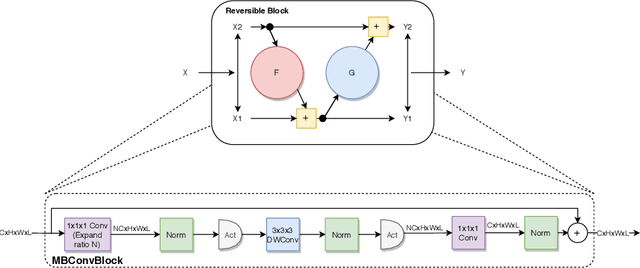
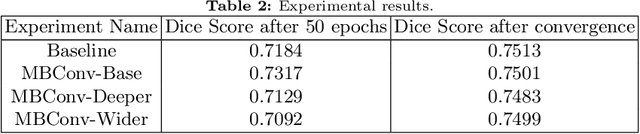
We propose combining memory saving techniques with traditional U-Net architectures to increase the complexity of the models on the Brain Tumor Segmentation (BraTS) challenge. The BraTS challenge consists of a 3D segmentation of a 240x240x155x4 input image into a set of tumor classes. Because of the large volume and need for 3D convolutional layers, this task is very memory intensive. To address this, prior approaches use smaller cropped images while constraining the model's depth and width. Our 3D U-Net uses a reversible version of the mobile inverted bottleneck block defined in MobileNetV2, MnasNet and the more recent EfficientNet architectures to save activation memory during training. Using reversible layers enables the model to recompute input activations given the outputs of that layer, saving memory by eliminating the need to store activations during the forward pass. The inverted residual bottleneck block uses lightweight depthwise separable convolutions to reduce computation by decomposing convolutions into a pointwise convolution and a depthwise convolution. Further, this block inverts traditional bottleneck blocks by placing an intermediate expansion layer between the input and output linear 1x1 convolution, reducing the total number of channels. Given a fixed memory budget, with these memory saving techniques, we are able to train image volumes up to 3x larger, models with 25% more depth, or models with up to 2x the number of channels than a corresponding non-reversible network.
* 11 pages, 5 figures, Published at MICCAI Brainles 2020
Convolutional Dictionary Pair Learning Network for Image Representation Learning
Jan 15, 2020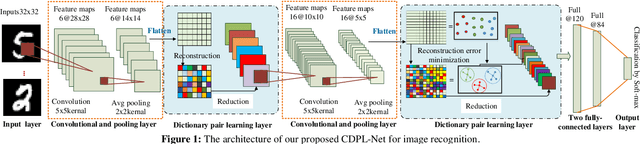
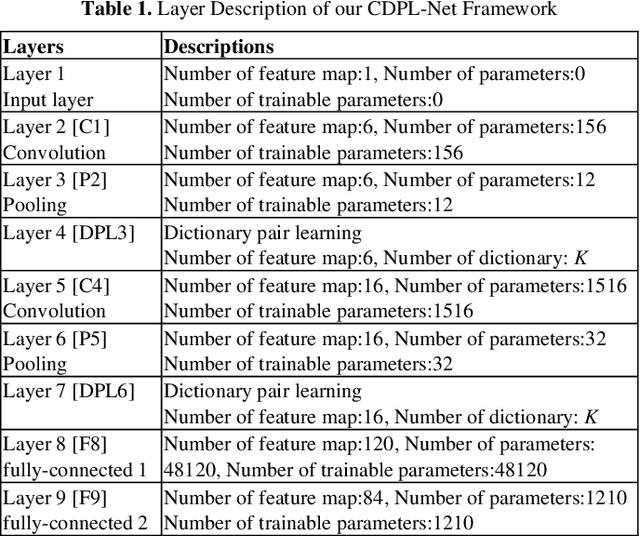
Both the Dictionary Learning (DL) and Convolutional Neural Networks (CNN) are powerful image representation learning systems based on different mechanisms and principles, however whether we can seamlessly integrate them to improve the per-formance is noteworthy exploring. To address this issue, we propose a novel generalized end-to-end representation learning architecture, dubbed Convolutional Dictionary Pair Learning Network (CDPL-Net) in this paper, which integrates the learning schemes of the CNN and dictionary pair learning into a unified framework. Generally, the architecture of CDPL-Net includes two convolutional/pooling layers and two dictionary pair learn-ing (DPL) layers in the representation learning module. Besides, it uses two fully-connected layers as the multi-layer perception layer in the nonlinear classification module. In particular, the DPL layer can jointly formulate the discriminative synthesis and analysis representations driven by minimizing the batch based reconstruction error over the flatted feature maps from the convolution/pooling layer. Moreover, DPL layer uses l1-norm on the analysis dictionary so that sparse representation can be delivered, and the embedding process will also be robust to noise. To speed up the training process of DPL layer, the efficient stochastic gradient descent is used. Extensive simulations on real databases show that our CDPL-Net can deliver enhanced performance over other state-of-the-art methods.
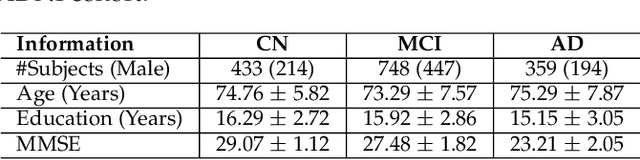
Medical Transformer: Universal Brain Encoder for 3D MRI Analysis
Apr 28, 2021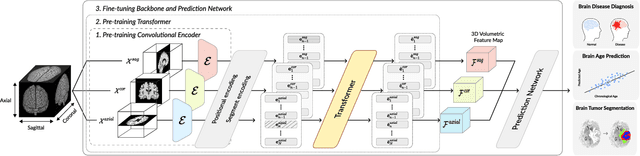
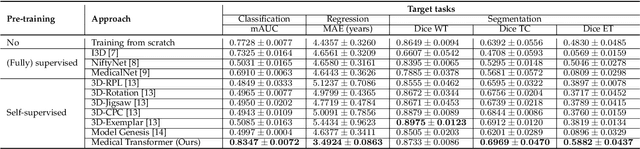
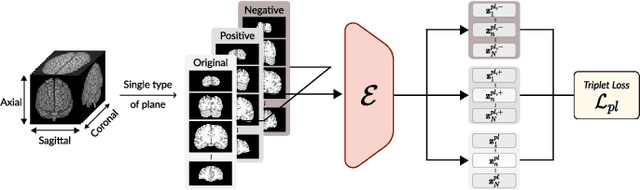
Transfer learning has gained attention in medical image analysis due to limited annotated 3D medical datasets for training data-driven deep learning models in the real world. Existing 3D-based methods have transferred the pre-trained models to downstream tasks, which achieved promising results with only a small number of training samples. However, they demand a massive amount of parameters to train the model for 3D medical imaging. In this work, we propose a novel transfer learning framework, called Medical Transformer, that effectively models 3D volumetric images in the form of a sequence of 2D image slices. To make a high-level representation in 3D-form empowering spatial relations better, we take a multi-view approach that leverages plenty of information from the three planes of 3D volume, while providing parameter-efficient training. For building a source model generally applicable to various tasks, we pre-train the model in a self-supervised learning manner for masked encoding vector prediction as a proxy task, using a large-scale normal, healthy brain magnetic resonance imaging (MRI) dataset. Our pre-trained model is evaluated on three downstream tasks: (i) brain disease diagnosis, (ii) brain age prediction, and (iii) brain tumor segmentation, which are actively studied in brain MRI research. The experimental results show that our Medical Transformer outperforms the state-of-the-art transfer learning methods, efficiently reducing the number of parameters up to about 92% for classification and
Learning Long-Term Style-Preserving Blind Video Temporal Consistency
Mar 12, 2021
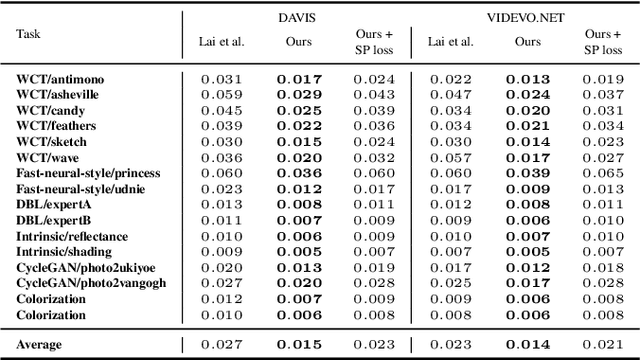

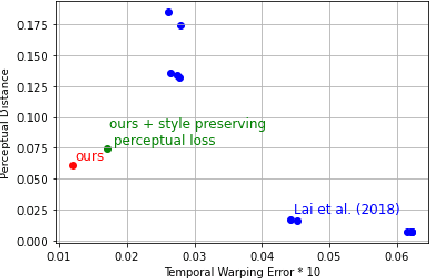
When trying to independently apply image-trained algorithms to successive frames in videos, noxious flickering tends to appear. State-of-the-art post-processing techniques that aim at fostering temporal consistency, generate other temporal artifacts and visually alter the style of videos. We propose a postprocessing model, agnostic to the transformation applied to videos (e.g. style transfer, image manipulation using GANs, etc.), in the form of a recurrent neural network. Our model is trained using a Ping Pong procedure and its corresponding loss, recently introduced for GAN video generation, as well as a novel style preserving perceptual loss. The former improves long-term temporal consistency learning, while the latter fosters style preservation. We evaluate our model on the DAVIS and videvo.net datasets and show that our approach offers state-of-the-art results concerning flicker removal, and better keeps the overall style of the videos than previous approaches.