 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Category-Specific Mesh Reconstruction from Image Collections
Jul 30, 2018
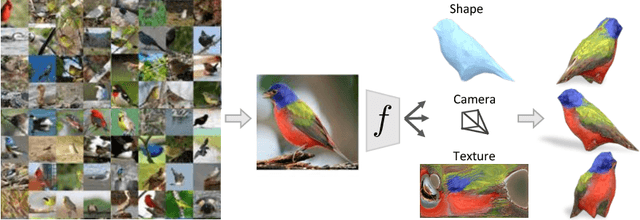
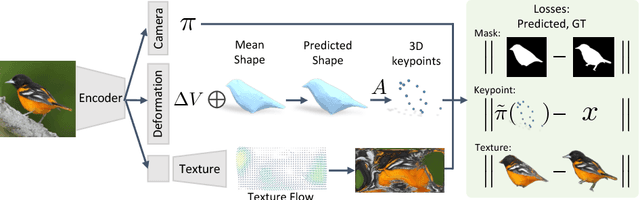
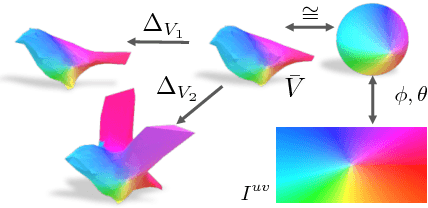

We present a learning framework for recovering the 3D shape, camera, and texture of an object from a single image. The shape is represented as a deformable 3D mesh model of an object category where a shape is parameterized by a learned mean shape and per-instance predicted deformation. Our approach allows leveraging an annotated image collection for training, where the deformable model and the 3D prediction mechanism are learned without relying on ground-truth 3D or multi-view supervision. Our representation enables us to go beyond existing 3D prediction approaches by incorporating texture inference as prediction of an image in a canonical appearance space. Additionally, we show that semantic keypoints can be easily associated with the predicted shapes. We present qualitative and quantitative results of our approach on CUB and PASCAL3D datasets and show that we can learn to predict diverse shapes and textures across objects using only annotated image collections. The project website can be found at https://akanazawa.github.io/cmr/.
Stride and Translation Invariance in CNNs
Mar 18, 2021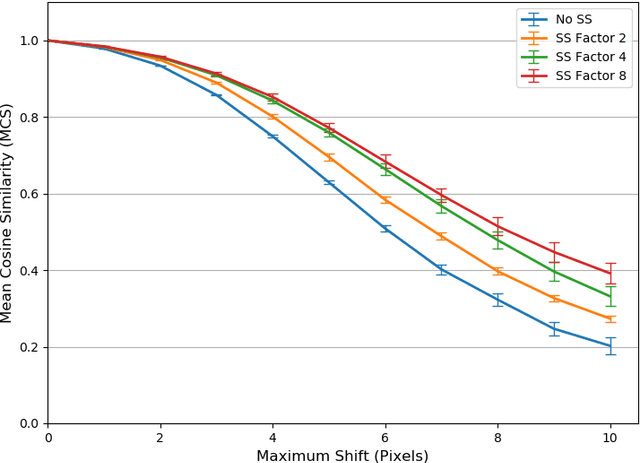
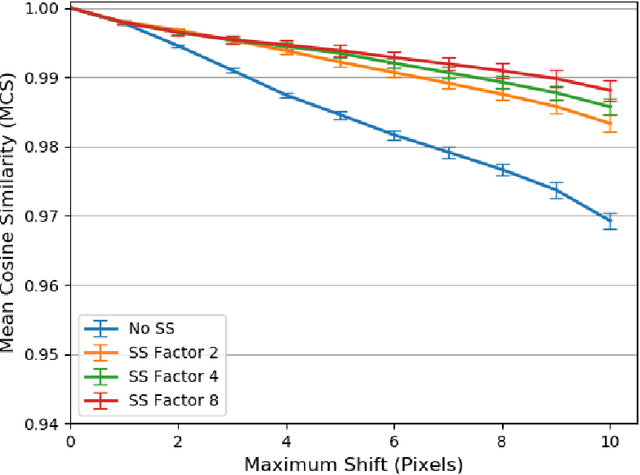
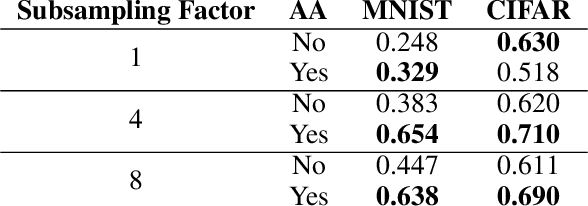
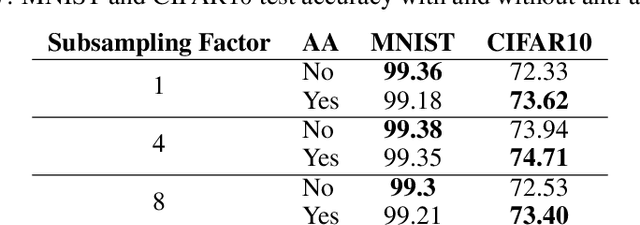
Convolutional Neural Networks have become the standard for image classification tasks, however, these architectures are not invariant to translations of the input image. This lack of invariance is attributed to the use of stride which ignores the sampling theorem, and fully connected layers which lack spatial reasoning. We show that stride can greatly benefit translation invariance given that it is combined with sufficient similarity between neighbouring pixels, a characteristic which we refer to as local homogeneity. We also observe that this characteristic is dataset-specific and dictates the relationship between pooling kernel size and stride required for translation invariance. Furthermore we find that a trade-off exists between generalization and translation invariance in the case of pooling kernel size, as larger kernel sizes lead to better invariance but poorer generalization. Finally we explore the efficacy of other solutions proposed, namely global average pooling, anti-aliasing, and data augmentation, both empirically and through the lens of local homogeneity.
Free Hyperbolic Neural Networks with Limited Radii
Jul 23, 2021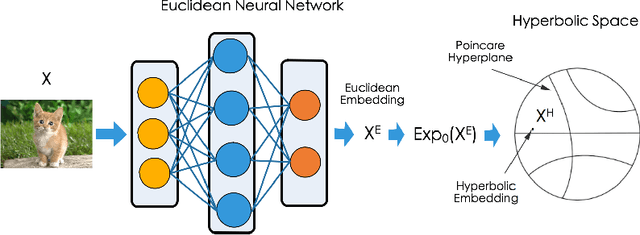

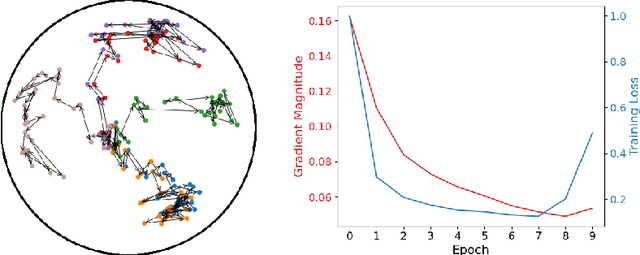

Non-Euclidean geometry with constant negative curvature, i.e., hyperbolic space, has attracted sustained attention in the community of machine learning. Hyperbolic space, owing to its ability to embed hierarchical structures continuously with low distortion, has been applied for learning data with tree-like structures. Hyperbolic Neural Networks (HNNs) that operate directly in hyperbolic space have also been proposed recently to further exploit the potential of hyperbolic representations. While HNNs have achieved better performance than Euclidean neural networks (ENNs) on datasets with implicit hierarchical structure, they still perform poorly on standard classification benchmarks such as CIFAR and ImageNet. The traditional wisdom is that it is critical for the data to respect the hyperbolic geometry when applying HNNs. In this paper, we first conduct an empirical study showing that the inferior performance of HNNs on standard recognition datasets can be attributed to the notorious vanishing gradient problem. We further discovered that this problem stems from the hybrid architecture of HNNs. Our analysis leads to a simple yet effective solution called Feature Clipping, which regularizes the hyperbolic embedding whenever its norm exceeding a given threshold. Our thorough experiments show that the proposed method can successfully avoid the vanishing gradient problem when training HNNs with backpropagation. The improved HNNs are able to achieve comparable performance with ENNs on standard image recognition datasets including MNIST, CIFAR10, CIFAR100 and ImageNet, while demonstrating more adversarial robustness and stronger out-of-distribution detection capability.
Polarimetric image augmentation
May 22, 2020


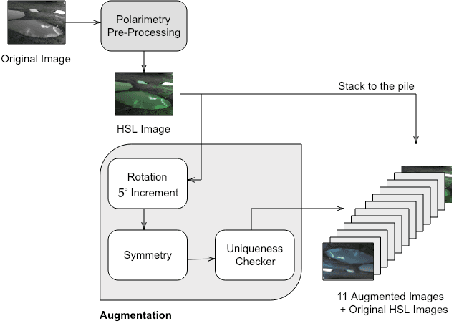
Robotics applications in urban environments are subject to obstacles that exhibit specular reflections hampering autonomous navigation. On the other hand, these reflections are highly polarized and this extra information can successfully be used to segment the specular areas. In nature, polarized light is obtained by reflection or scattering. Deep Convolutional Neural Networks (DCNNs) have shown excellent segmentation results, but require a significant amount of data to achieve best performances. The lack of data is usually overcomed by using augmentation methods. However, unlike RGB images, polarization images are not only scalar (intensity) images and standard augmentation techniques cannot be applied straightforwardly. We propose to enhance deep learning models through a regularized augmentation procedure applied to polarimetric data in order to characterize scenes more effectively under challenging conditions. We subsequently observe an average of 18.1% improvement in IoU between non augmented and regularized training procedures on real world data.
An audiovisual and contextual approach for categorical and continuous emotion recognition in-the-wild
Jul 10, 2021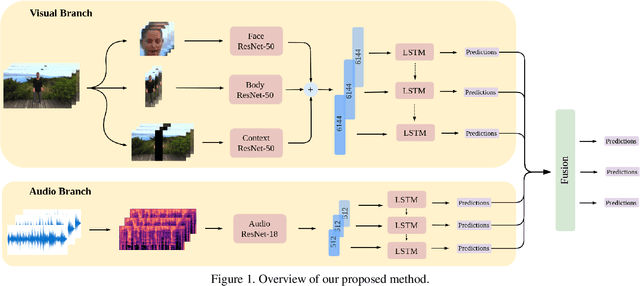
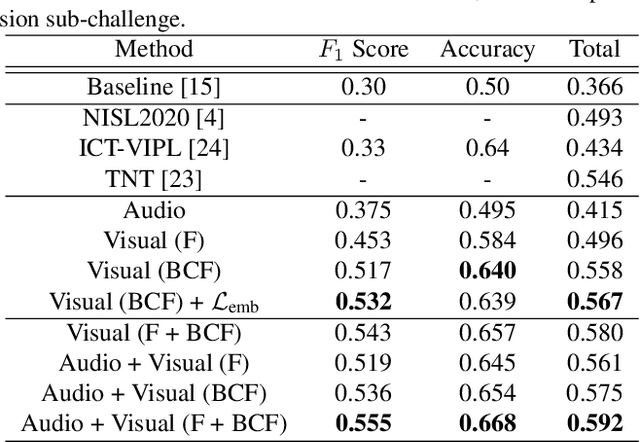
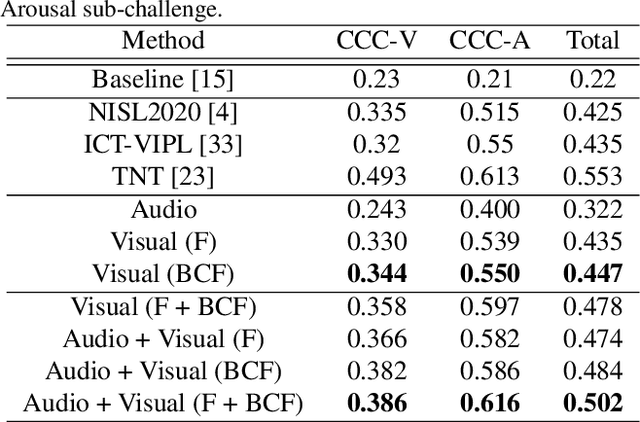
In this work we tackle the task of video-based audio-visual emotion recognition, within the premises of the 2nd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW). Poor illumination conditions, head/body orientation and low image resolution constitute factors that can potentially hinder performance in case of methodologies that solely rely on the extraction and analysis of facial features. In order to alleviate this problem, we leverage bodily as well as contextual features, as part of a broader emotion recognition framework. We choose to use a standard CNN-RNN cascade as the backbone of our proposed model for sequence-to-sequence (seq2seq) learning. Apart from learning through the RGB input modality, we construct an aural stream which operates on sequences of extracted mel-spectrograms. Our extensive experiments on the challenging and newly assembled Affect-in-the-wild-2 (Aff-Wild2) dataset verify the superiority of our methods over existing approaches, while by properly incorporating all of the aforementioned modules in a network ensemble, we manage to surpass the previous best published recognition scores, in the official validation set. All the code was implemented using PyTorch\footnote{\url{https://pytorch.org/}} and is publicly available\footnote{\url{https://github.com/PanosAntoniadis/NTUA-ABAW2021}}.
To Beta or Not To Beta: Information Bottleneck for DigitaL Image Forensics
Aug 11, 2019
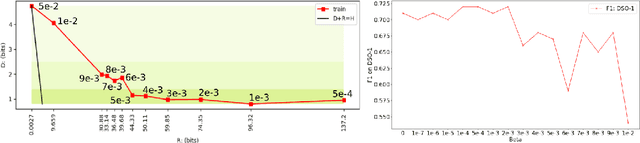

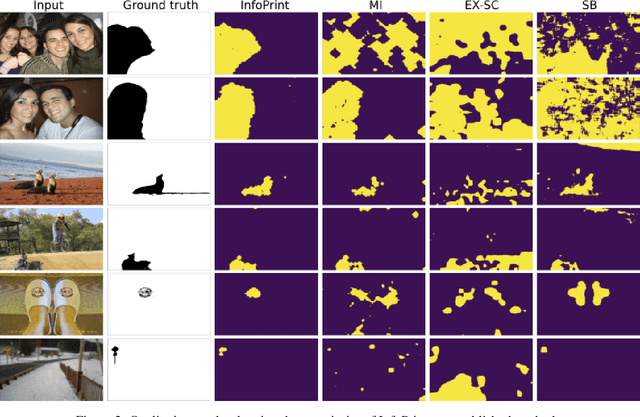
We consider an information theoretic approach to address the problem of identifying fake digital images. We propose an innovative method to formulate the issue of localizing manipulated regions in an image as a deep representation learning problem using the Information Bottleneck (IB), which has recently gained popularity as a framework for interpreting deep neural networks. Tampered images pose a serious predicament since digitized media is a ubiquitous part of our lives. These are facilitated by the easy availability of image editing software and aggravated by recent advances in deep generative models such as GANs. We propose InfoPrint, a computationally efficient solution to the IB formulation using approximate variational inference and compare it to a numerical solution that is computationally expensive. Testing on a number of standard datasets, we demonstrate that InfoPrint outperforms the state-of-the-art and the numerical solution. Additionally, it also has the ability to detect alterations made by inpainting GANs.
RECON: Rapid Exploration for Open-World Navigation with Latent Goal Models
Apr 14, 2021
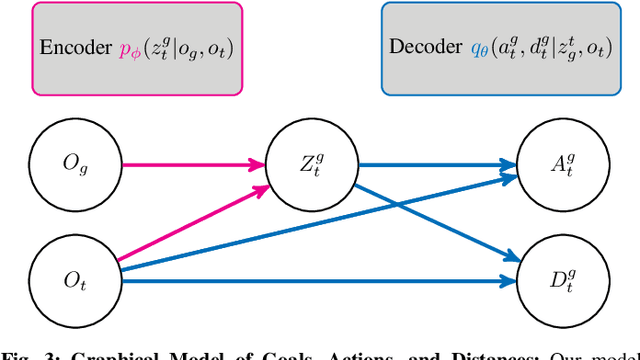
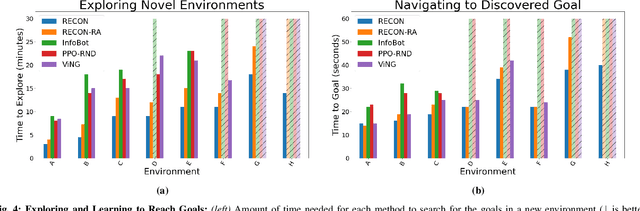
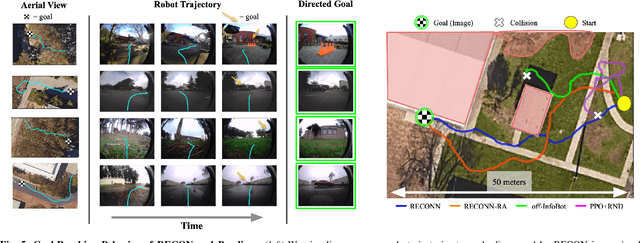
We describe a robotic learning system for autonomous navigation in diverse environments. At the core of our method are two components: (i) a non-parametric map that reflects the connectivity of the environment but does not require geometric reconstruction or localization, and (ii) a latent variable model of distances and actions that enables efficiently constructing and traversing this map. The model is trained on a large dataset of prior experience to predict the expected amount of time and next action needed to transit between the current image and a goal image. Training the model in this way enables it to develop a representation of goals robust to distracting information in the input images, which aids in deploying the system to quickly explore new environments. We demonstrate our method on a mobile ground robot in a range of outdoor navigation scenarios. Our method can learn to reach new goals, specified as images, in a radius of up to 80 meters in just 20 minutes, and reliably revisit these goals in changing environments. We also demonstrate our method's robustness to previously-unseen obstacles and variable weather conditions. We encourage the reader to visit the project website for videos of our experiments and demonstrations https://sites.google.com/view/recon-robot
Local Morphometry of Closed, Implicit Surfaces
Jul 29, 2021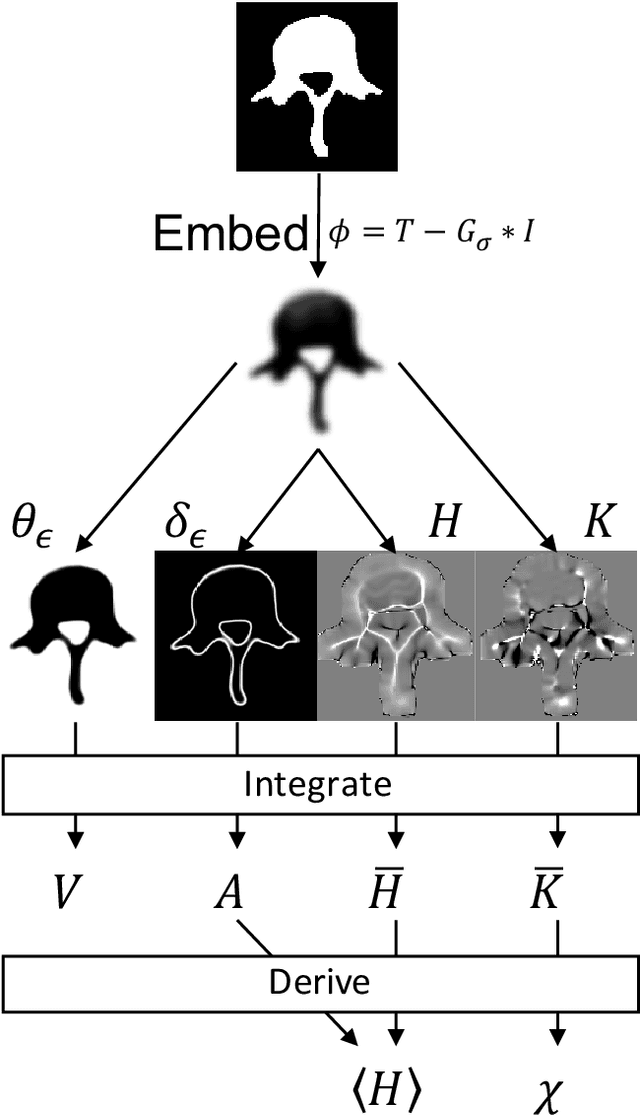
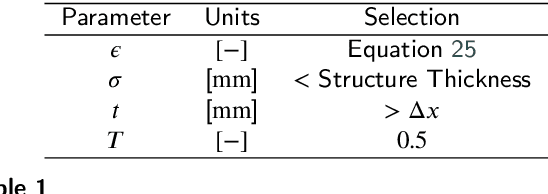
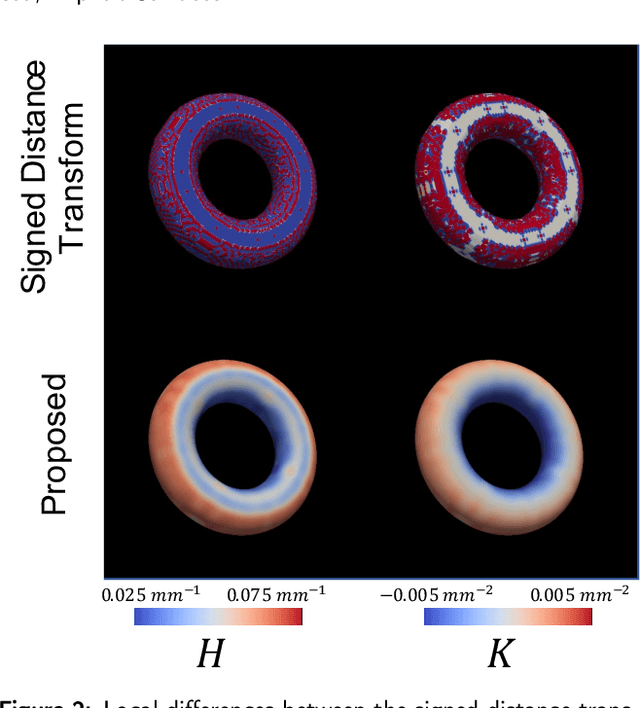
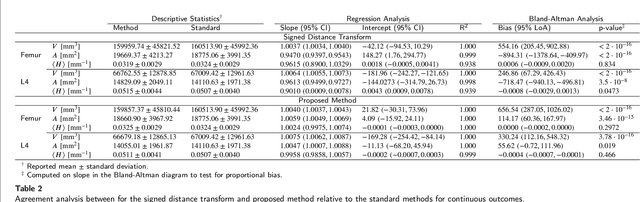
Anatomical structures such as the hippocampus, liver, and bones can be analyzed as orientable, closed surfaces. This permits the computation of volume, surface area, mean curvature, Gaussian curvature, and the Euler-Poincar\'e characteristic as well as comparison of these morphometrics between structures of different topology. The structures are commonly represented implicitly in curve evolution problems as the zero level set of an embedding. Practically, binary images of anatomical structures are embedded using a signed distance transform. However, quantization prevents the accurate computation of curvatures, leading to considerable errors in morphometry. This paper presents a fast, simple embedding procedure for accurate local morphometry as the zero crossing of the Gaussian blurred binary image. The proposed method was validated based on the femur and fourth lumbar vertebrae of 50 clinical computed tomography datasets. The results show that the signed distance transform leads to large quantization errors in the computed local curvature. Global validation of morphometry using regression and Bland-Altman analysis revealed that the coefficient of determination for the average mean curvature is improved from 93.8% with the signed distance transform to 100% with the proposed method. For the surface area, the proportional bias is improved from -5.0% for the signed distance transform to +0.6% for the proposed method. The Euler-Poincar\'e characteristic is improved from unusable in the signed distance transform to 98% accuracy for the proposed method. The proposed method enables an improved local and global evaluation of curvature for purposes of morphometry on closed, implicit surfaces.
Improving Image Clustering With Multiple Pretrained CNN Feature Extractors
Jul 20, 2018
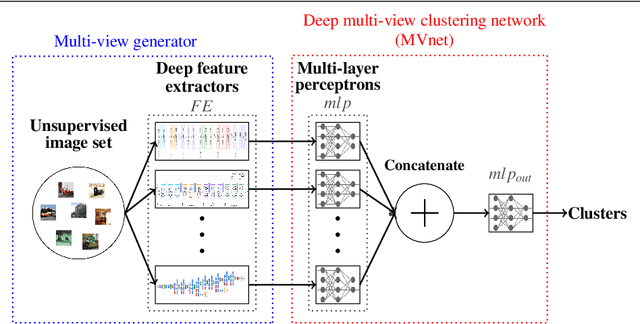
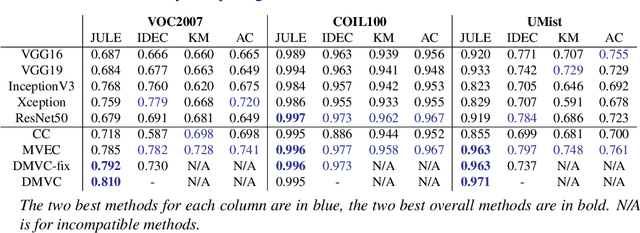

For many image clustering problems, replacing raw image data with features extracted by a pretrained convolutional neural network (CNN), leads to better clustering performance. However, the specific features extracted, and, by extension, the selected CNN architecture, can have a major impact on the clustering results. In practice, this crucial design choice is often decided arbitrarily due to the impossibility of using cross-validation with unsupervised learning problems. However, information contained in the different pretrained CNN architectures may be complementary, even when pretrained on the same data. To improve clustering performance, we rephrase the image clustering problem as a multi-view clustering (MVC) problem that considers multiple different pretrained feature extractors as different "views" of the same data. We then propose a multi-input neural network architecture that is trained end-to-end to solve the MVC problem effectively. Our experimental results, conducted on three different natural image datasets, show that: 1. using multiple pretrained CNNs jointly as feature extractors improves image clustering; 2. using an end-to-end approach improves MVC; and 3. combining both produces state-of-the-art results for the problem of image clustering.
Shifts: A Dataset of Real Distributional Shift Across Multiple Large-Scale Tasks
Jul 23, 2021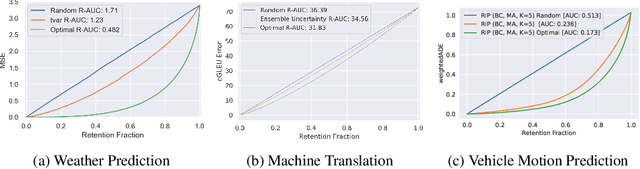
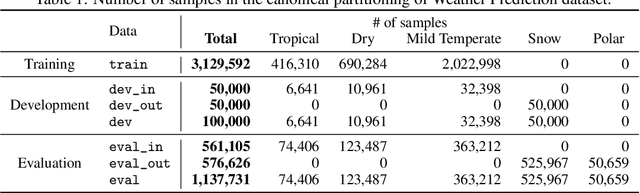
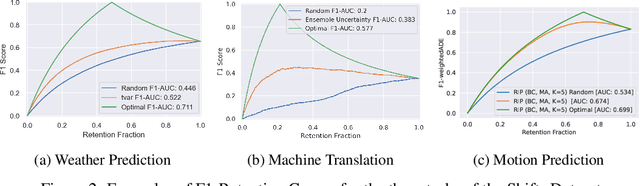
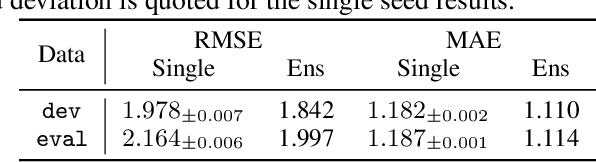
There has been significant research done on developing methods for improving robustness to distributional shift and uncertainty estimation. In contrast, only limited work has examined developing standard datasets and benchmarks for assessing these approaches. Additionally, most work on uncertainty estimation and robustness has developed new techniques based on small-scale regression or image classification tasks. However, many tasks of practical interest have different modalities, such as tabular data, audio, text, or sensor data, which offer significant challenges involving regression and discrete or continuous structured prediction. Thus, given the current state of the field, a standardized large-scale dataset of tasks across a range of modalities affected by distributional shifts is necessary. This will enable researchers to meaningfully evaluate the plethora of recently developed uncertainty quantification methods, as well as assessment criteria and state-of-the-art baselines. In this work, we propose the \emph{Shifts Dataset} for evaluation of uncertainty estimates and robustness to distributional shift. The dataset, which has been collected from industrial sources and services, is composed of three tasks, with each corresponding to a particular data modality: tabular weather prediction, machine translation, and self-driving car (SDC) vehicle motion prediction. All of these data modalities and tasks are affected by real, `in-the-wild' distributional shifts and pose interesting challenges with respect to uncertainty estimation. In this work we provide a description of the dataset and baseline results for all tasks.