 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Modeling Magnetic Particle Imaging for Dynamic Tracer Distributions
Jun 24, 2021
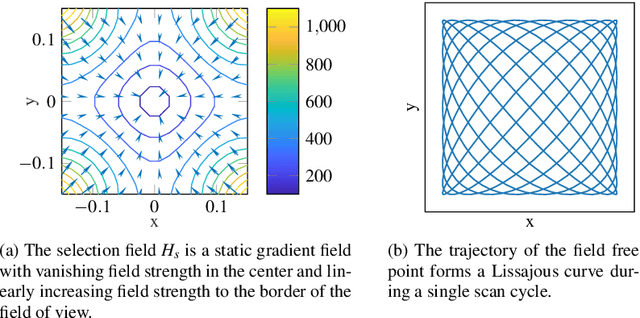
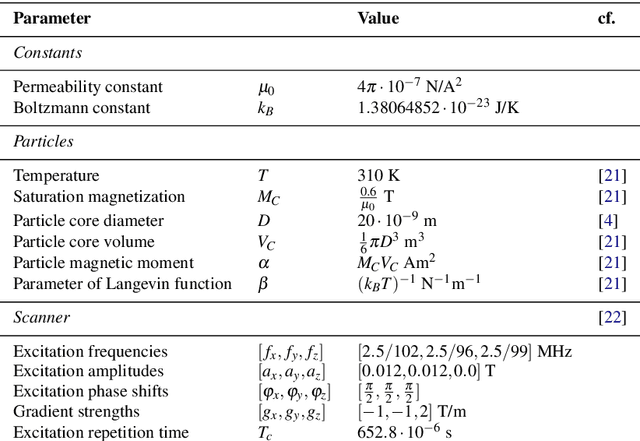
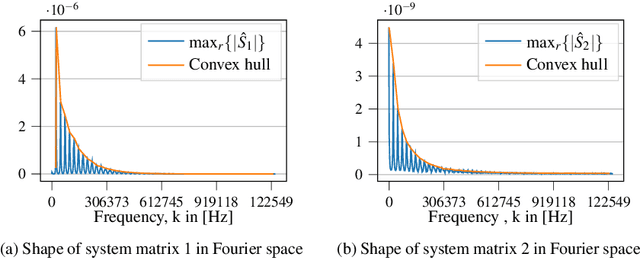
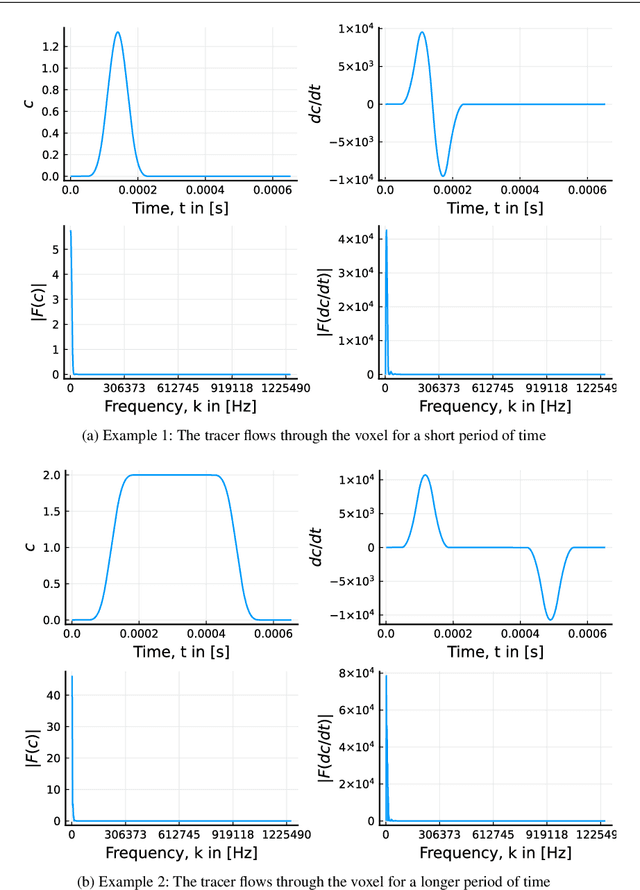
Magnetic Particle Imaging (MPI) is a promising tracer-based, functional medical imaging technique which measures the non-linear response of superparamagnetic iron oxide nanoparticles (SPION) to a dynamic magnetic field. For image reconstruction, system matrices from time-consuming calibration scans are used predominantly. Finding modeled forward operators for magnetic particle imaging, which are able to compete with measured matrices in practice, is an ongoing topic of research. The existing models for magnetic particle imaging are by design not suitable for dynamic tracer concentrations. Neither modeled nor measured system matrices account for changes in the concentration during a single scanning cycle. In this paper we present a new MPI forward model for dynamic concentrations. A standard model will be introduced briefly, followed by the changes due to the dynamic behavior of the tracer concentration. Furthermore, the relevance of this new extended model is examined by investigating the influence of the extension and example reconstructions with the new and the standard model.
Wave-based extreme deep learning based on non-linear time-Floquet entanglement
Jul 19, 2021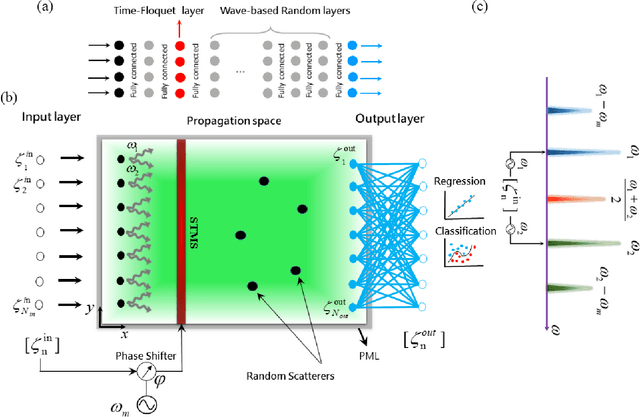
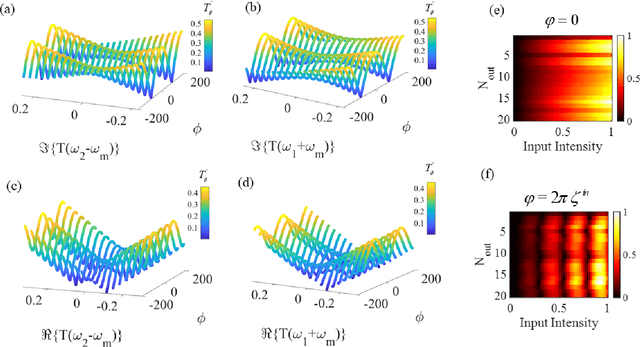
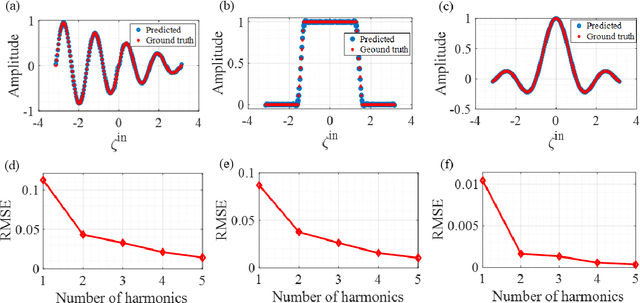
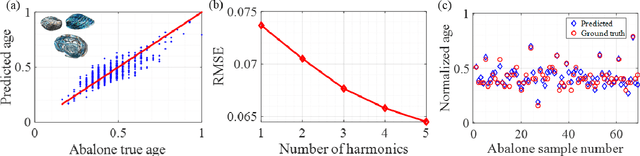
Wave-based analog signal processing holds the promise of extremely fast, on-the-fly, power-efficient data processing, occurring as a wave propagates through an artificially engineered medium. Yet, due to the fundamentally weak non-linearities of traditional wave materials, such analog processors have been so far largely confined to simple linear projections such as image edge detection or matrix multiplications. Complex neuromorphic computing tasks, which inherently require strong non-linearities, have so far remained out-of-reach of wave-based solutions, with a few attempts that implemented non-linearities on the digital front, or used weak and inflexible non-linear sensors, restraining the learning performance. Here, we tackle this issue by demonstrating the relevance of Time-Floquet physics to induce a strong non-linear entanglement between signal inputs at different frequencies, enabling a power-efficient and versatile wave platform for analog extreme deep learning involving a single, uniformly modulated dielectric layer and a scattering medium. We prove the efficiency of the method for extreme learning machines and reservoir computing to solve a range of challenging learning tasks, from forecasting chaotic time series to the simultaneous classification of distinct datasets. Our results open the way for wave-based machine learning with high energy efficiency, speed, and scalability.
Adaptive Illumination based Depth Sensing using Deep Learning
Mar 23, 2021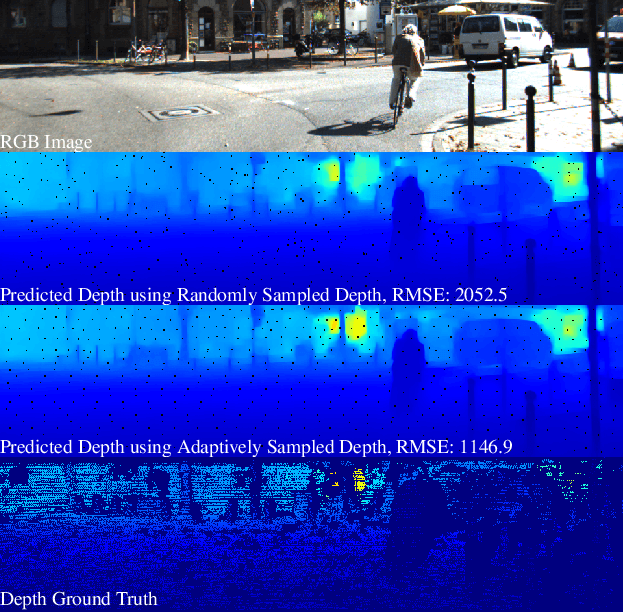
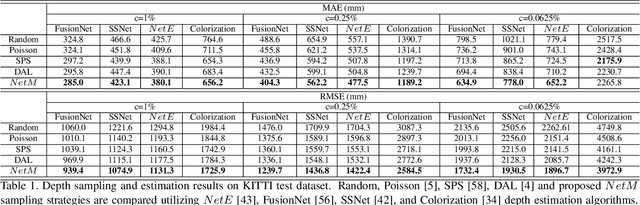
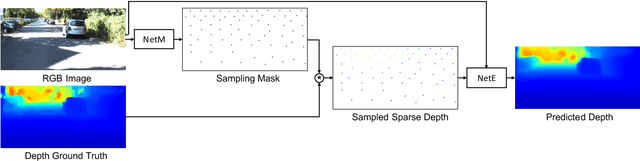
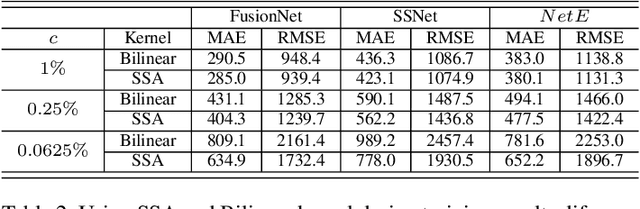
Dense depth map capture is challenging in existing active sparse illumination based depth acquisition techniques, such as LiDAR. Various techniques have been proposed to estimate a dense depth map based on fusion of the sparse depth map measurement with the RGB image. Recent advances in hardware enable adaptive depth measurements resulting in further improvement of the dense depth map estimation. In this paper, we study the topic of estimating dense depth from depth sampling. The adaptive sparse depth sampling network is jointly trained with a fusion network of an RGB image and sparse depth, to generate optimal adaptive sampling masks. We show that such adaptive sampling masks can generalize well to many RGB and sparse depth fusion algorithms under a variety of sampling rates (as low as $0.0625\%$). The proposed adaptive sampling method is fully differentiable and flexible to be trained end-to-end with upstream perception algorithms.
Learning from Crowds with Sparse and Imbalanced Annotations
Jul 11, 2021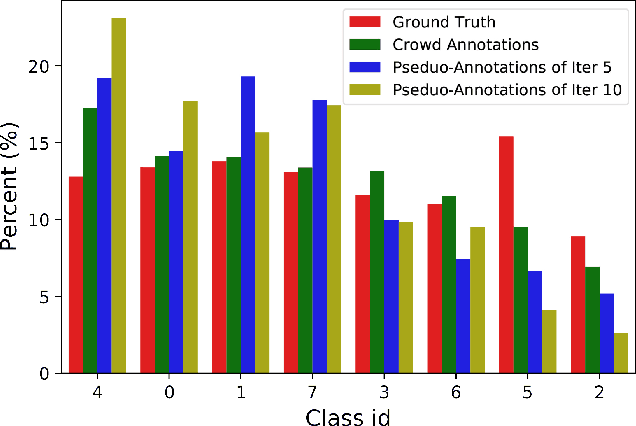
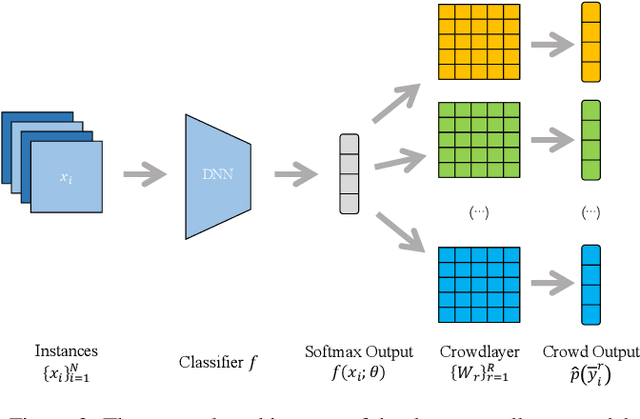
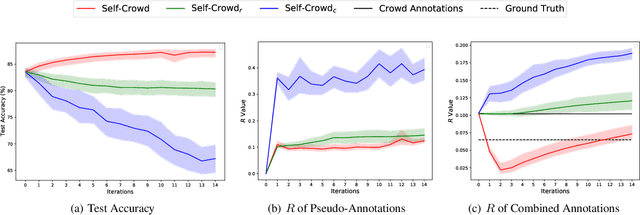
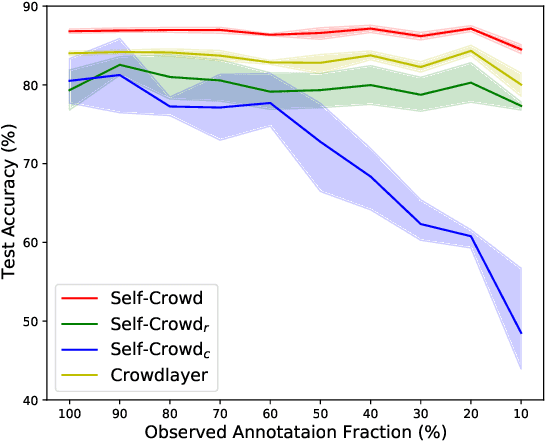
Traditional supervised learning requires ground truth labels for the training data, whose collection can be difficult in many cases. Recently, crowdsourcing has established itself as an efficient labeling solution through resorting to non-expert crowds. To reduce the labeling error effects, one common practice is to distribute each instance to multiple workers, whereas each worker only annotates a subset of data, resulting in the {\it sparse annotation} phenomenon. In this paper, we note that when meeting with class-imbalance, i.e., when the ground truth labels are {\it class-imbalanced}, the sparse annotations are prone to be skewly distributed, which thus can severely bias the learning algorithm. To combat this issue, we propose one self-training based approach named {\it Self-Crowd} by progressively adding confident pseudo-annotations and rebalancing the annotation distribution. Specifically, we propose one distribution aware confidence measure to select confident pseudo-annotations, which adopts the resampling strategy to oversample the minority annotations and undersample the majority annotations. On one real-world crowdsourcing image classification task, we show that the proposed method yields more balanced annotations throughout training than the distribution agnostic methods and substantially improves the learning performance at different annotation sparsity levels.
Animating Landscape: Self-Supervised Learning of Decoupled Motion and Appearance for Single-Image Video Synthesis
Oct 16, 2019

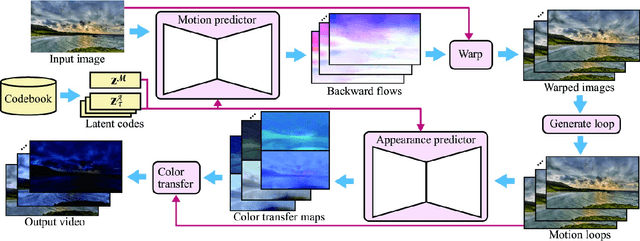

Automatic generation of a high-quality video from a single image remains a challenging task despite the recent advances in deep generative models. This paper proposes a method that can create a high-resolution, long-term animation using convolutional neural networks (CNNs) from a single landscape image where we mainly focus on skies and waters. Our key observation is that the motion (e.g., moving clouds) and appearance (e.g., time-varying colors in the sky) in natural scenes have different time scales. We thus learn them separately and predict them with decoupled control while handling future uncertainty in both predictions by introducing latent codes. Unlike previous methods that infer output frames directly, our CNNs predict spatially-smooth intermediate data, i.e., for motion, flow fields for warping, and for appearance, color transfer maps, via self-supervised learning, i.e., without explicitly-provided ground truth. These intermediate data are applied not to each previous output frame, but to the input image only once for each output frame. This design is crucial to alleviate error accumulation in long-term predictions, which is the essential problem in previous recurrent approaches. The output frames can be looped like cinemagraph, and also be controlled directly by specifying latent codes or indirectly via visual annotations. We demonstrate the effectiveness of our method through comparisons with the state-of-the-arts on video prediction as well as appearance manipulation.
Sylvester Matrix Based Similarity Estimation Method for Automation of Defect Detection in Textile Fabrics
Dec 09, 2020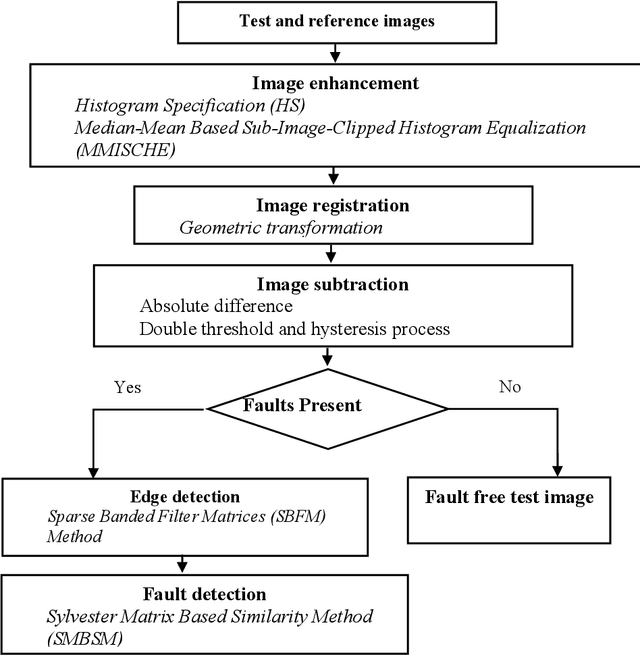

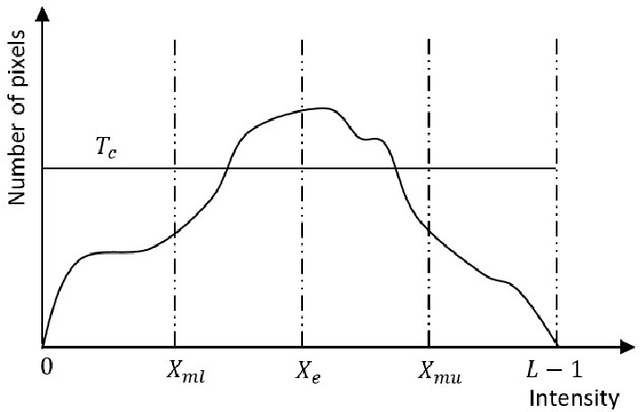
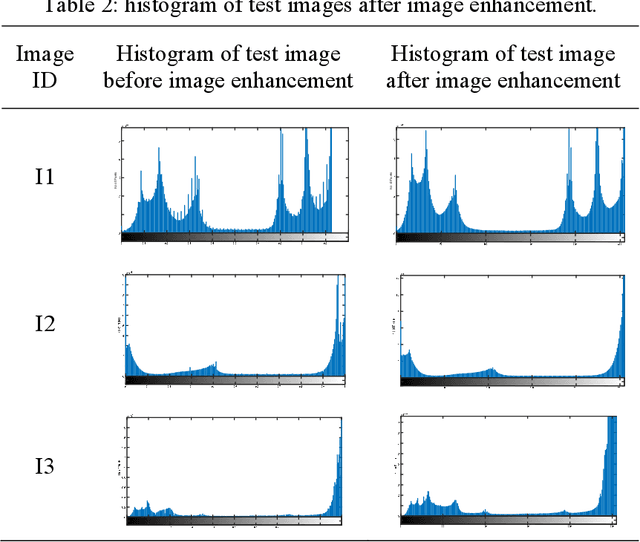
Fabric defect detection is a crucial quality control step in the textile manufacturing industry. In this article, machine vision system based on the Sylvester Matrix Based Similarity Method (SMBSM) is proposed to automate the defect detection process. The algorithm involves six phases, namely resolution matching, image enhancement using Histogram Specification and Median-Mean Based Sub-Image-Clipped Histogram Equalization, image registration through alignment and hysteresis process, image subtraction, edge detection, and fault detection by means of the rank of the Sylvester matrix. The experimental results demonstrate that the proposed method is robust and yields an accuracy of 93.4%, precision of 95.8%, with 2275 ms computational speed.
KCNet: An Insect-Inspired Single-Hidden-Layer Neural Network with Randomized Binary Weights for Prediction and Classification Tasks
Aug 17, 2021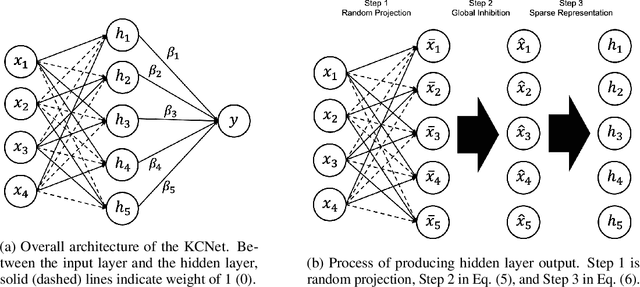
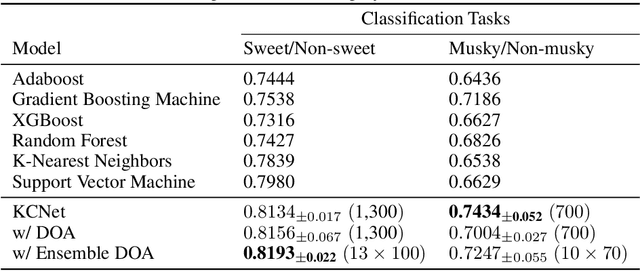
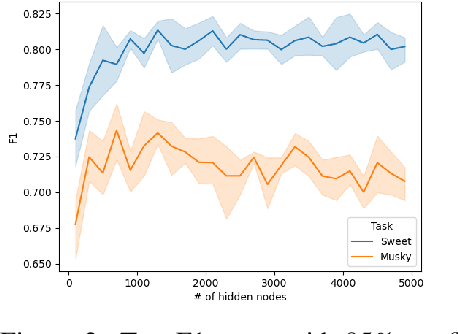
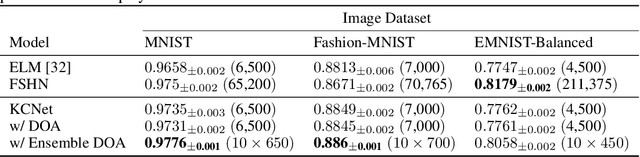
Fruit flies are established model systems for studying olfactory learning as they will readily learn to associate odors with both electric shock or sugar rewards. The mechanisms of the insect brain apparently responsible for odor learning form a relatively shallow neuronal architecture. Olfactory inputs are received by the antennal lobe (AL) of the brain, which produces an encoding of each odor mixture across ~50 sub-units known as glomeruli. Each of these glomeruli then project its component of this feature vector to several of ~2000 so-called Kenyon Cells (KCs) in a region of the brain known as the mushroom body (MB). Fly responses to odors are generated by small downstream neuropils that decode the higher-order representation from the MB. Research has shown that there is no recognizable pattern in the glomeruli--KC connections (and thus the particular higher-order representations); they are akin to fingerprints~-- even isogenic flies have different projections. Leveraging insights from this architecture, we propose KCNet, a single-hidden-layer neural network that contains sparse, randomized, binary weights between the input layer and the hidden layer and analytically learned weights between the hidden layer and the output layer. Furthermore, we also propose a dynamic optimization algorithm that enables the KCNet to increase performance beyond its structural limits by searching a more efficient set of inputs. For odorant-perception tasks that predict perceptual properties of an odorant, we show that KCNet outperforms existing data-driven approaches, such as XGBoost. For image-classification tasks, KCNet achieves reasonable performance on benchmark datasets (MNIST, Fashion-MNIST, and EMNIST) without any data-augmentation methods or convolutional layers and shows particularly fast running time. Thus, neural networks inspired by the insect brain can be both economical and perform well.
Spot the Difference: Topological Anomaly Detection via Geometric Alignment
Jun 09, 2021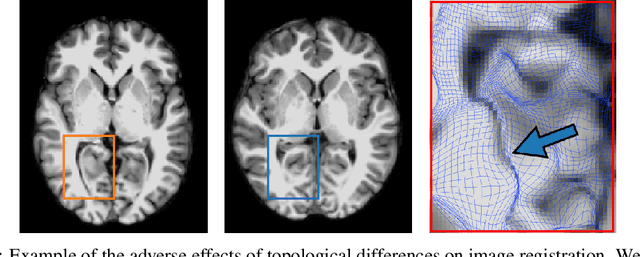
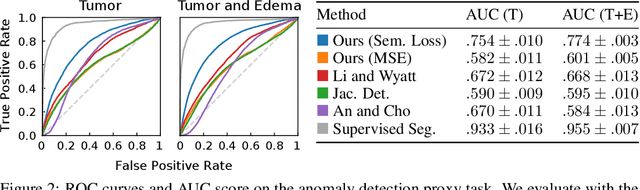
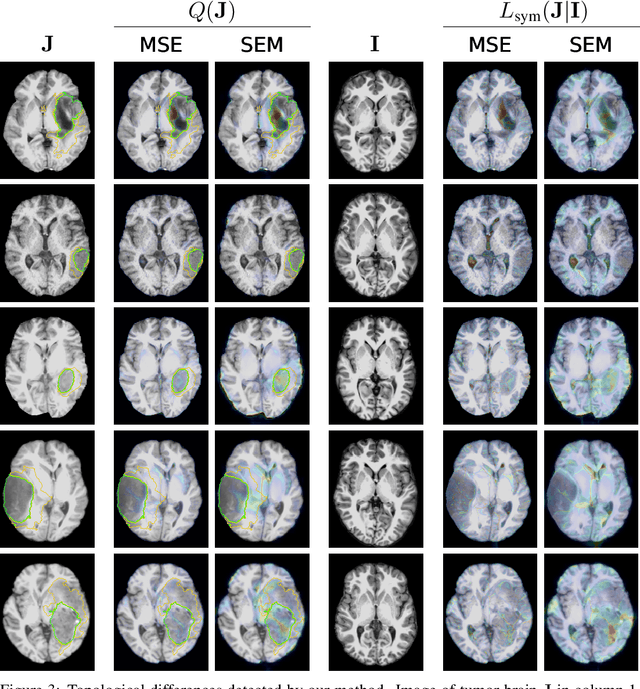
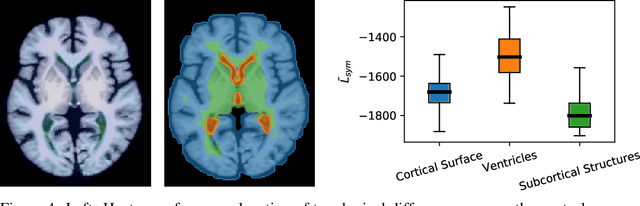
Geometric alignment appears in a variety of applications, ranging from domain adaptation, optimal transport, and normalizing flows in machine learning; optical flow and learned augmentation in computer vision and deformable registration within biomedical imaging. A recurring challenge is the alignment of domains whose topology is not the same; a problem that is routinely ignored, potentially introducing bias in downstream analysis. As a first step towards solving such alignment problems, we propose an unsupervised topological difference detection algorithm. The model is based on a conditional variational auto-encoder and detects topological anomalies with regards to a reference alongside the registration step. We consider both a) topological changes in the image under spatial variation and b) unexpected transformations. Our approach is validated on a proxy task of unsupervised anomaly detection in images.
Low-Rank Discriminative Least Squares Regression for Image Classification
Apr 16, 2019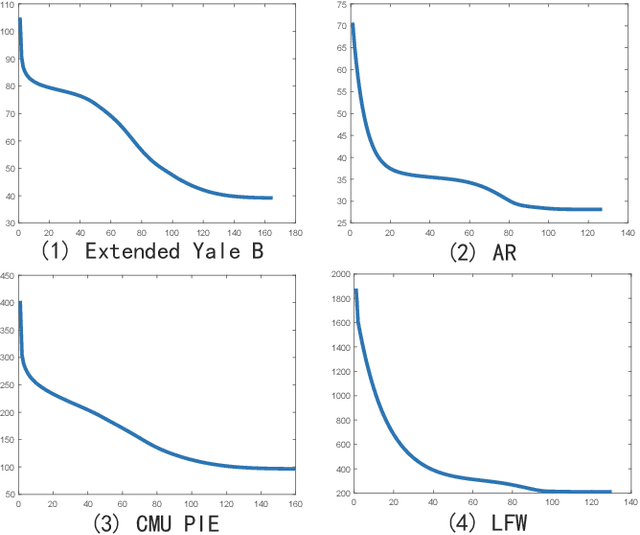


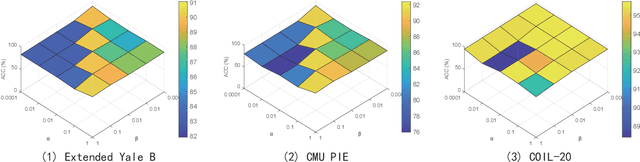
Latest least squares regression (LSR) methods mainly try to learn slack regression targets to replace strict zero-one labels. However, the difference of intra-class targets can also be highlighted when enlarging the distance between different classes, and roughly persuing relaxed targets may lead to the problem of overfitting. To solve above problems, we propose a low-rank discriminative least squares regression model (LRDLSR) for multi-class image classification. Specifically, LRDLSR class-wisely imposes low-rank constraint on the intra-class regression targets to encourage its compactness and similarity. Moreover, LRDLSR introduces an additional regularization term on the learned targets to avoid the problem of overfitting. These two improvements are helpful to learn a more discriminative projection for regression and thus achieving better classification performance. Experimental results over a range of image databases demonstrate the effectiveness of the proposed LRDLSR method.
Zero-Shot Domain Adaptation in CT Segmentation by Filtered Back Projection Augmentation
Jul 18, 2021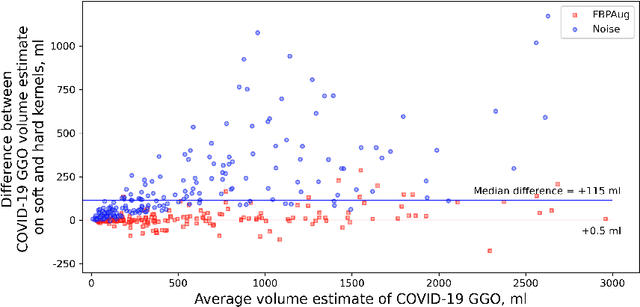


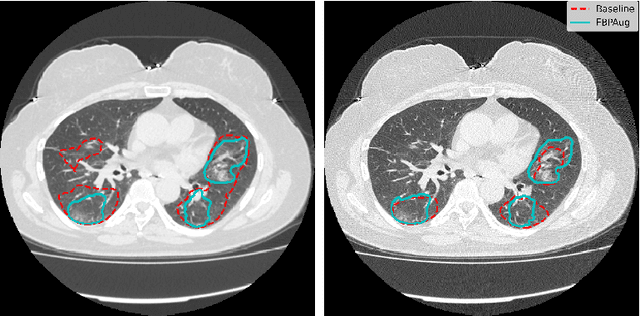
Domain shift is one of the most salient challenges in medical computer vision. Due to immense variability in scanners' parameters and imaging protocols, even images obtained from the same person and the same scanner could differ significantly. We address variability in computed tomography (CT) images caused by different convolution kernels used in the reconstruction process, the critical domain shift factor in CT. The choice of a convolution kernel affects pixels' granularity, image smoothness, and noise level. We analyze a dataset of paired CT images, where smooth and sharp images were reconstructed from the same sinograms with different kernels, thus providing identical anatomy but different style. Though identical predictions are desired, we show that the consistency, measured as the average Dice between predictions on pairs, is just 0.54. We propose Filtered Back-Projection Augmentation (FBPAug), a simple and surprisingly efficient approach to augment CT images in sinogram space emulating reconstruction with different kernels. We apply the proposed method in a zero-shot domain adaptation setup and show that the consistency boosts from 0.54 to 0.92 outperforming other augmentation approaches. Neither specific preparation of source domain data nor target domain data is required, so our publicly released FBPAug can be used as a plug-and-play module for zero-shot domain adaptation in any CT-based task.