 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Self-Supervised Bootstrap Method for Single-Image 3D Face Reconstruction
Dec 17, 2018
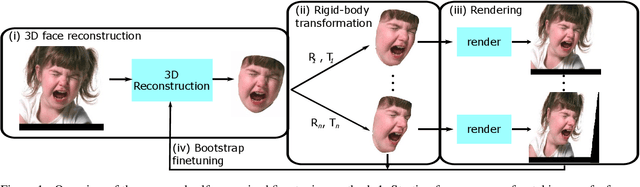

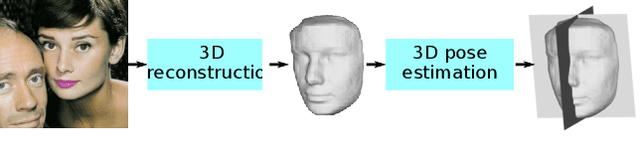
State-of-the-art methods for 3D reconstruction of faces from a single image require 2D-3D pairs of ground-truth data for supervision. Such data is costly to acquire, and most datasets available in the literature are restricted to pairs for which the input 2D images depict faces in a near fronto-parallel pose. Therefore, many data-driven methods for single-image 3D facial reconstruction perform poorly on profile and near-profile faces. We propose a method to improve the performance of single-image 3D facial reconstruction networks by utilizing the network to synthesize its own training data for fine-tuning, comprising: (i) single-image 3D reconstruction of faces in near-frontal images without ground-truth 3D shape; (ii) application of a rigid-body transformation to the reconstructed face model; (iii) rendering of the face model from new viewpoints; and (iv) use of the rendered image and corresponding 3D reconstruction as additional data for supervised fine-tuning. The new 2D-3D pairs thus produced have the same high-quality observed for near fronto-parallel reconstructions, thereby nudging the network towards more uniform performance as a function of the viewing angle of input faces. Application of the proposed technique to the fine-tuning of a state-of-the-art single-image 3D-reconstruction network for faces demonstrates the usefulness of the method, with particularly significant gains for profile or near-profile views.
Universal and Flexible Optical Aberration Correction Using Deep-Prior Based Deconvolution
Apr 07, 2021

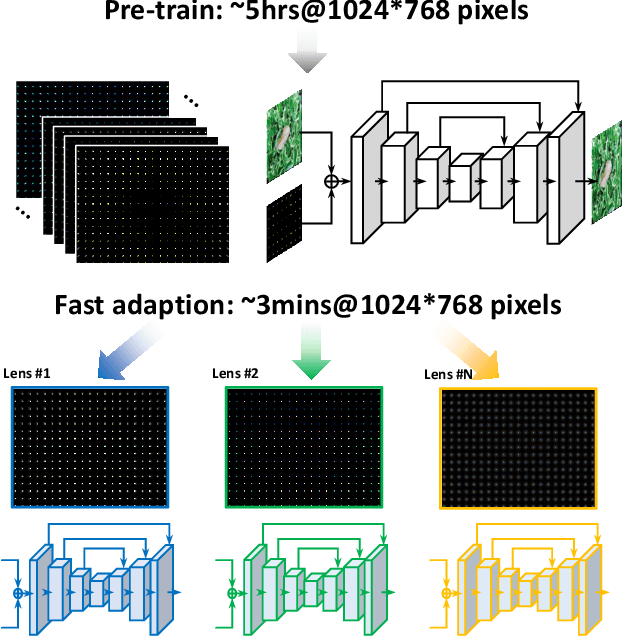
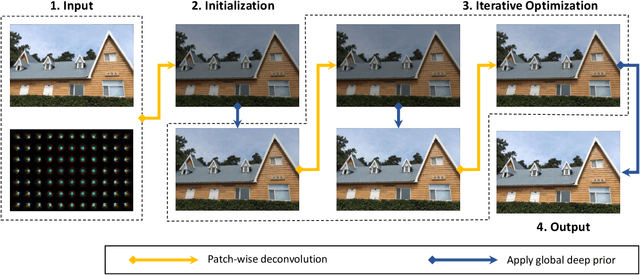
High quality imaging usually requires bulky and expensive lenses to compensate geometric and chromatic aberrations. This poses high constraints on the optical hash or low cost applications. Although one can utilize algorithmic reconstruction to remove the artifacts of low-end lenses, the degeneration from optical aberrations is spatially varying and the computation has to trade off efficiency for performance. For example, we need to conduct patch-wise optimization or train a large set of local deep neural networks to achieve high reconstruction performance across the whole image. In this paper, we propose a PSF aware plug-and-play deep network, which takes the aberrant image and PSF map as input and produces the latent high quality version via incorporating lens-specific deep priors, thus leading to a universal and flexible optical aberration correction method. Specifically, we pre-train a base model from a set of diverse lenses and then adapt it to a given lens by quickly refining the parameters, which largely alleviates the time and memory consumption of model learning. The approach is of high efficiency in both training and testing stages. Extensive results verify the promising applications of our proposed approach for compact low-end cameras.
Fairness Properties of Face Recognition and Obfuscation Systems
Aug 05, 2021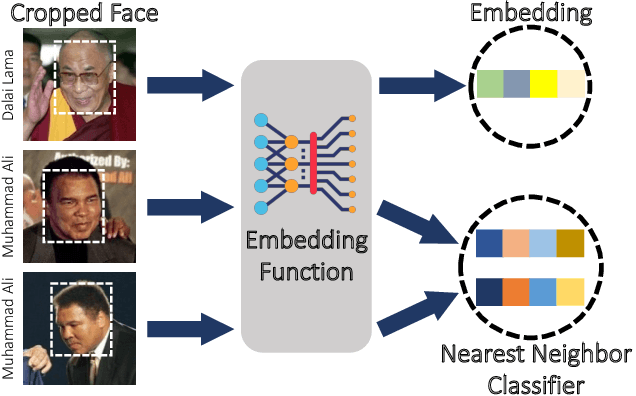
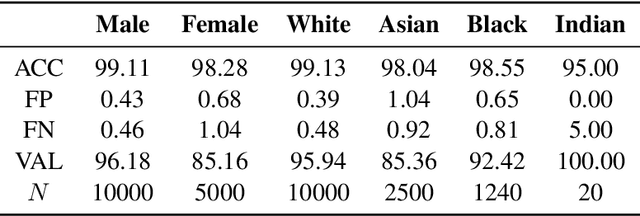
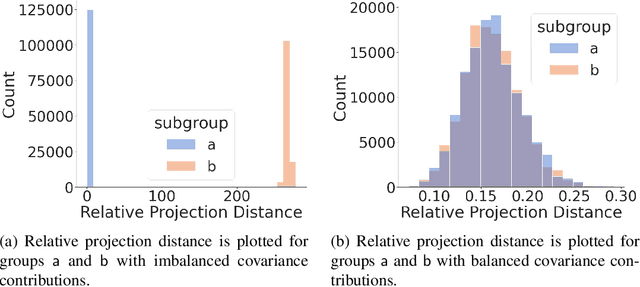
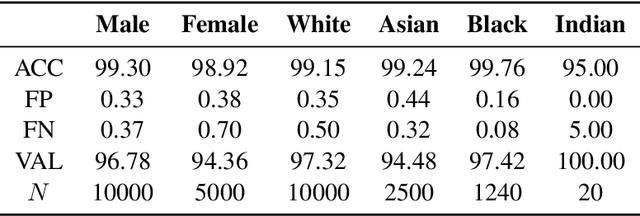
The proliferation of automated facial recognition in various commercial and government sectors has caused significant privacy concerns for individuals. A recent and popular approach to address these privacy concerns is to employ evasion attacks against the metric embedding networks powering facial recognition systems. Face obfuscation systems generate imperceptible perturbations, when added to an image, cause the facial recognition system to misidentify the user. The key to these approaches is the generation of perturbations using a pre-trained metric embedding network followed by their application to an online system, whose model might be proprietary. This dependence of face obfuscation on metric embedding networks, which are known to be unfair in the context of facial recognition, surfaces the question of demographic fairness -- \textit{are there demographic disparities in the performance of face obfuscation systems?} To address this question, we perform an analytical and empirical exploration of the performance of recent face obfuscation systems that rely on deep embedding networks. We find that metric embedding networks are demographically aware; they cluster faces in the embedding space based on their demographic attributes. We observe that this effect carries through to the face obfuscation systems: faces belonging to minority groups incur reduced utility compared to those from majority groups. For example, the disparity in average obfuscation success rate on the online Face++ API can reach up to 20 percentage points. Further, for some demographic groups, the average perturbation size increases by up to 17\% when choosing a target identity belonging to a different demographic group versus the same demographic group. Finally, we present a simple analytical model to provide insights into these phenomena.
A Reference Architecture for Plausible Threat Image Projection (TIP) Within 3D X-ray Computed Tomography Volumes
Jan 15, 2020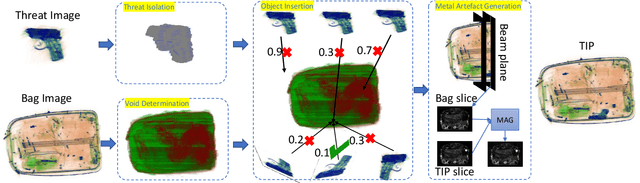
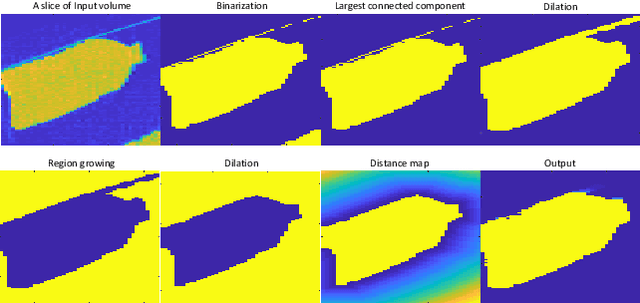

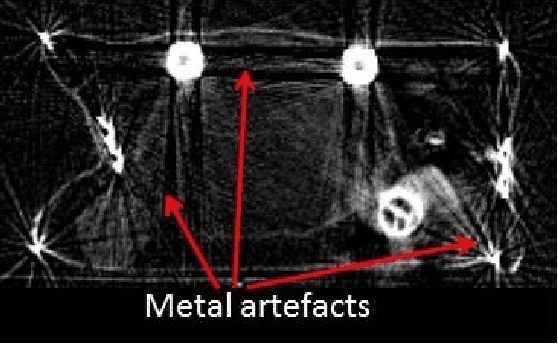
Threat Image Projection (TIP) is a technique used in X-ray security baggage screening systems that superimposes a threat object signature onto a benign X-ray baggage image in a plausible and realistic manner. It has been shown to be highly effective in evaluating the ongoing performance of human operators, improving their vigilance and performance on threat detection. However, with the increasing use of 3D Computed Tomography (CT) in aviation security for both hold and cabin baggage screening a significant challenge arises in extending TIP to 3D CT volumes due to the difficulty in 3D CT volume segmentation and the proper insertion location determination. In this paper, we present an approach for 3D TIP in CT volumes targeting realistic and plausible threat object insertion within 3D CT baggage images. The proposed approach consists of dual threat (source) and baggage (target) volume segmentation, particle swarm optimisation based insertion determination and metal artefact generation. In addition, we propose a TIP quality score metric to evaluate the quality of generated TIP volumes. Qualitative evaluations on real 3D CT baggage imagery show that our approach is able to generate realistic and plausible TIP which are indiscernible from real CT volumes and the TIP quality scores are consistent with human evaluations.
A Simple Baseline for StyleGAN Inversion
Apr 15, 2021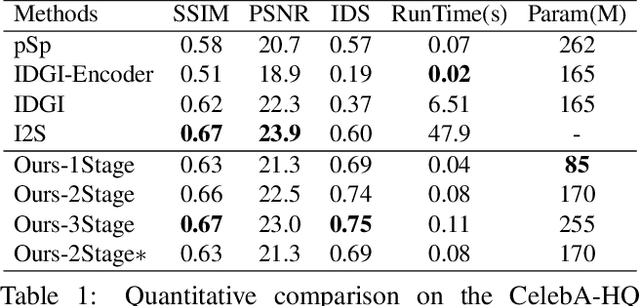
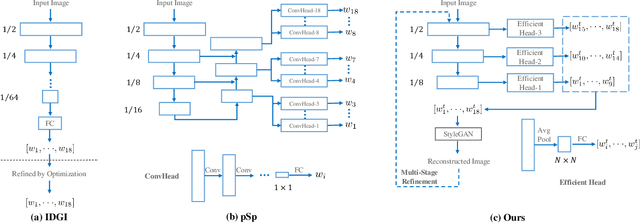
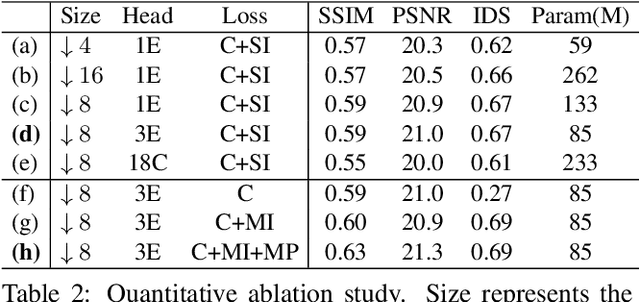

This paper studies the problem of StyleGAN inversion, which plays an essential role in enabling the pretrained StyleGAN to be used for real facial image editing tasks. This problem has the high demand for quality and efficiency. Existing optimization-based methods can produce high quality results, but the optimization often takes a long time. On the contrary, forward-based methods are usually faster but the quality of their results is inferior. In this paper, we present a new feed-forward network for StyleGAN inversion, with significant improvement in terms of efficiency and quality. In our inversion network, we introduce: 1) a shallower backbone with multiple efficient heads across scales; 2) multi-layer identity loss and multi-layer face parsing loss to the loss function; and 3) multi-stage refinement. Combining these designs together forms a simple and efficient baseline method which exploits all benefits of optimization-based and forward-based methods. Quantitative and qualitative results show that our method performs better than existing forward-based methods and comparably to state-of-the-art optimization-based methods, while maintaining the high efficiency as well as forward-based methods. Moreover, a number of real image editing applications demonstrate the efficacy of our method. Our project page is ~\url{https://wty-ustc.github.io/inversion}.
Convolutional Nets for Diabetic Retinopathy Screening in Bangladeshi Patients
Jul 31, 2021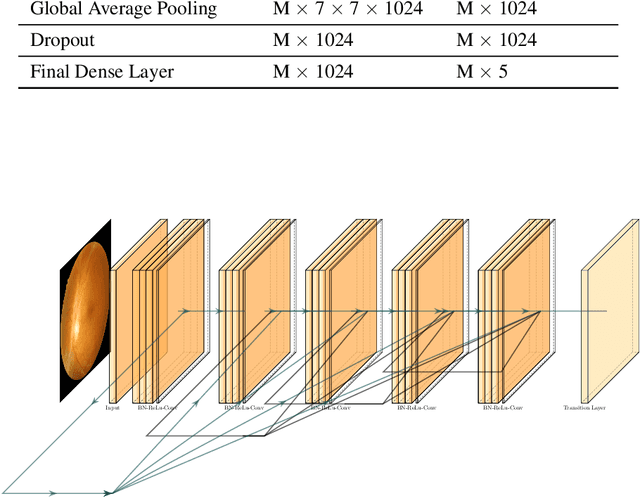
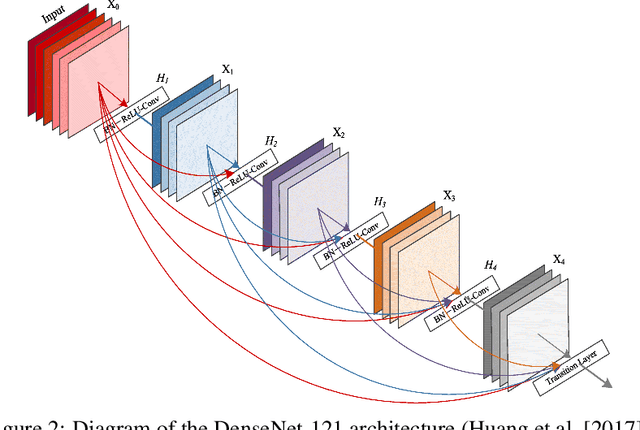
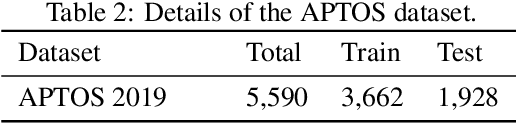
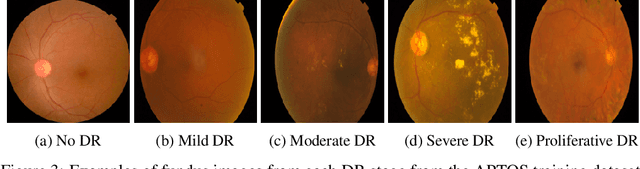
Diabetes is one of the most prevalent chronic diseases in Bangladesh, and as a result, Diabetic Retinopathy (DR) is widespread in the population. DR, an eye illness caused by diabetes, can lead to blindness if it is not identified and treated in its early stages. Unfortunately, diagnosis of DR requires medically trained professionals, but Bangladesh has limited specialists in comparison to its population. Moreover, the screening process is often expensive, prohibiting many from receiving timely and proper diagnosis. To address the problem, we introduce a deep learning algorithm which screens for different stages of DR. We use a state-of-the-art CNN architecture to diagnose patients based on retinal fundus imagery. This paper is an experimental evaluation of the algorithm we developed for DR diagnosis and screening specifically for Bangladeshi patients. We perform this validation study using separate pools of retinal image data of real patients from a hospital and field studies in Bangladesh. Our results show that the algorithm is effective at screening Bangladeshi eyes even when trained on a public dataset which is out of domain, and can accurately determine the stage of DR as well, achieving an overall accuracy of 92.27\% and 93.02\% on two validation sets of Bangladeshi eyes. The results confirm the ability of the algorithm to be used in real clinical settings and applications due to its high accuracy and classwise metrics. Our algorithm is implemented in the application Drishti, which is used to screen for DR in patients living in rural areas in Bangladesh, where access to professional screening is limited.
Co-training for Deep Object Detection: Comparing Single-modal and Multi-modal Approaches
Apr 23, 2021

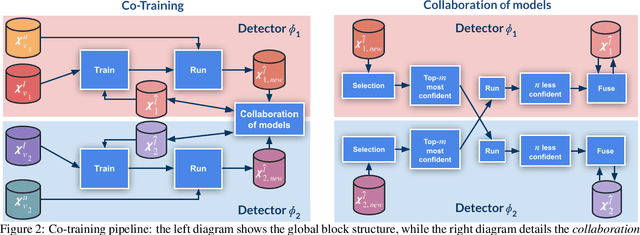
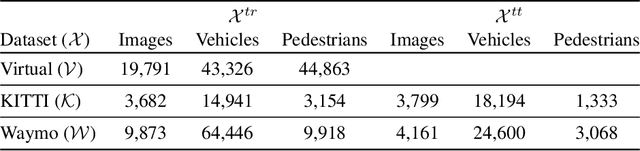
Top-performing computer vision models are powered by convolutional neural networks (CNNs). Training an accurate CNN highly depends on both the raw sensor data and their associated ground truth (GT). Collecting such GT is usually done through human labeling, which is time-consuming and does not scale as we wish. This data labeling bottleneck may be intensified due to domain shifts among image sensors, which could force per-sensor data labeling. In this paper, we focus on the use of co-training, a semi-supervised learning (SSL) method, for obtaining self-labeled object bounding boxes (BBs), i.e., the GT to train deep object detectors. In particular, we assess the goodness of multi-modal co-training by relying on two different views of an image, namely, appearance (RGB) and estimated depth (D). Moreover, we compare appearance-based single-modal co-training with multi-modal. Our results suggest that in a standard SSL setting (no domain shift, a few human-labeled data) and under virtual-to-real domain shift (many virtual-world labeled data, no human-labeled data) multi-modal co-training outperforms single-modal. In the latter case, by performing GAN-based domain translation both co-training modalities are on pair; at least, when using an off-the-shelf depth estimation model not specifically trained on the translated images.
Instance and Pair-Aware Dynamic Networks for Re-Identification
Mar 29, 2021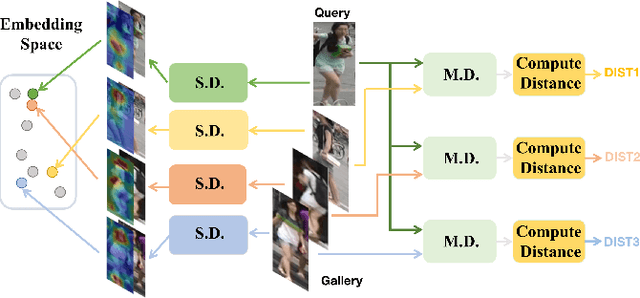
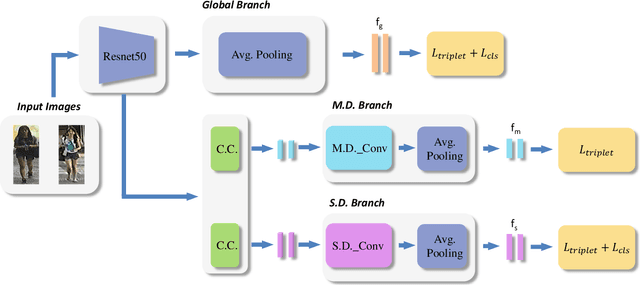
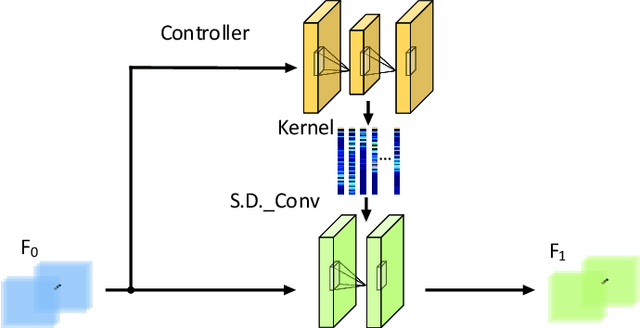

Re-identification (ReID) is to identify the same instance across different cameras. Existing ReID methods mostly utilize alignment-based or attention-based strategies to generate effective feature representations. However, most of these methods only extract general feature by employing single input image itself, overlooking the exploration of relevance between comparing images. To fill this gap, we propose a novel end-to-end trainable dynamic convolution framework named Instance and Pair-Aware Dynamic Networks in this paper. The proposed model is composed of three main branches where a self-guided dynamic branch is constructed to strengthen instance-specific features, focusing on every single image. Furthermore, we also design a mutual-guided dynamic branch to generate pair-aware features for each pair of images to be compared. Extensive experiments are conducted in order to verify the effectiveness of our proposed algorithm. We evaluate our algorithm in several mainstream person and vehicle ReID datasets including CUHK03, DukeMTMCreID, Market-1501, VeRi776 and VehicleID. In some datasets our algorithm outperforms state-of-the-art methods and in others, our algorithm achieves a comparable performance.
Multimodal Sensor Fusion In Single Thermal image Super-Resolution
Dec 21, 2018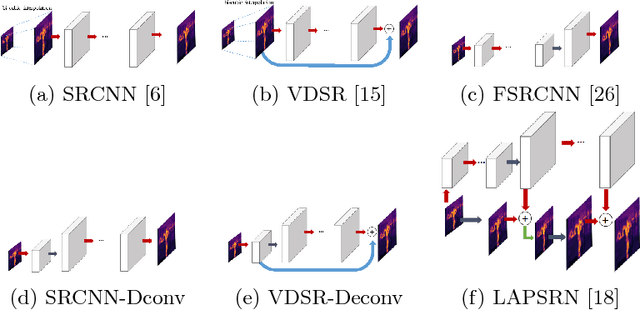


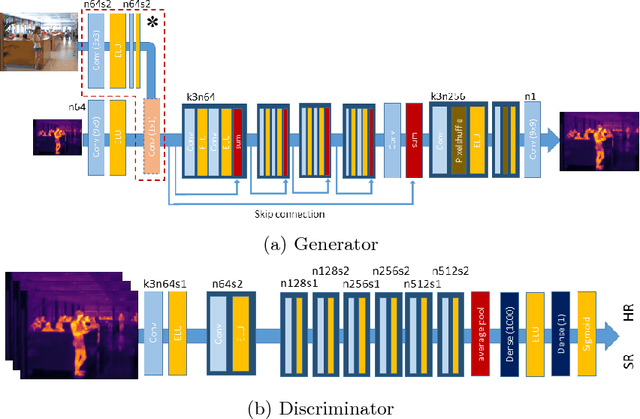
With the fast growth in the visual surveillance and security sectors, thermal infrared images have become increasingly necessary ina large variety of industrial applications. This is true even though IR sensors are still more expensive than their RGB counterpart having the same resolution. In this paper, we propose a deep learning solution to enhance the thermal image resolution. The following results are given:(I) Introduction of a multimodal, visual-thermal fusion model that ad-dresses thermal image super-resolution, via integrating high-frequency information from the visual image. (II) Investigation of different net-work architecture schemes in the literature, their up-sampling methods,learning procedures, and their optimization functions by showing their beneficial contribution to the super-resolution problem. (III) A bench-mark ULB17-VT dataset that contains thermal images and their visual images counterpart is presented. (IV) Presentation of a qualitative evaluation of a large test set with 58 samples and 22 raters which shows that our proposed model performs better against state-of-the-arts.
Interpretable Deep Feature Propagation for Early Action Recognition
Jul 11, 2021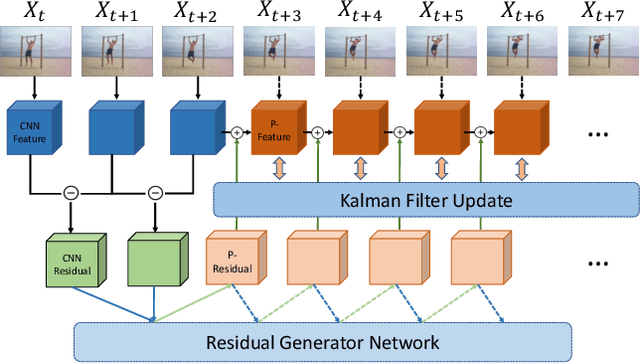
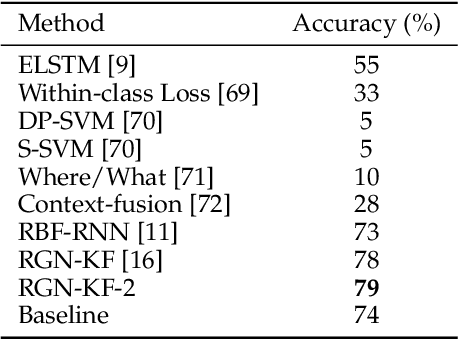
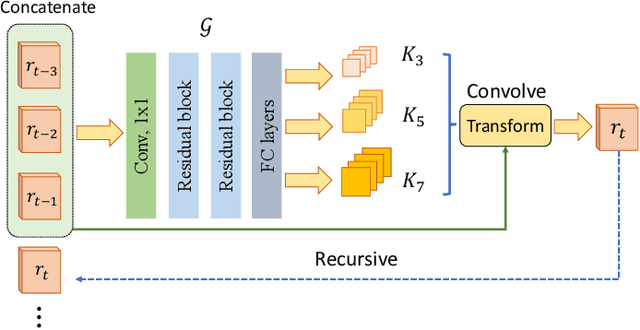
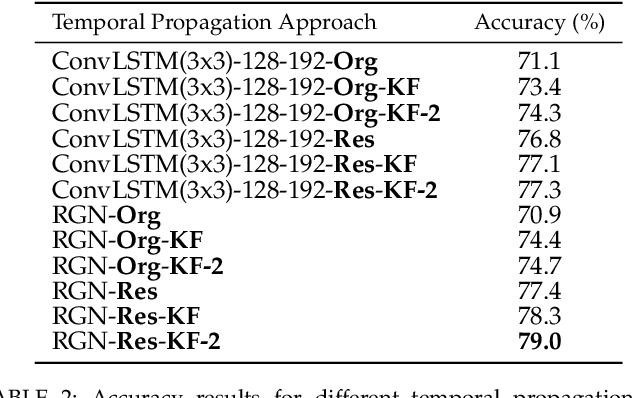
Early action recognition (action prediction) from limited preliminary observations plays a critical role for streaming vision systems that demand real-time inference, as video actions often possess elongated temporal spans which cause undesired latency. In this study, we address action prediction by investigating how action patterns evolve over time in a spatial feature space. There are three key components to our system. First, we work with intermediate-layer ConvNet features, which allow for abstraction from raw data, while retaining spatial layout. Second, instead of propagating features per se, we propagate their residuals across time, which allows for a compact representation that reduces redundancy. Third, we employ a Kalman filter to combat error build-up and unify across prediction start times. Extensive experimental results on multiple benchmarks show that our approach leads to competitive performance in action prediction. Notably, we investigate the learned components of our system to shed light on their otherwise opaque natures in two ways. First, we document that our learned feature propagation module works as a spatial shifting mechanism under convolution to propagate current observations into the future. Thus, it captures flow-based image motion information. Second, the learned Kalman filter adaptively updates prior estimation to aid the sequence learning process.