 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Calibrate Straight Lines for Fisheye Image Rectification
May 01, 2019

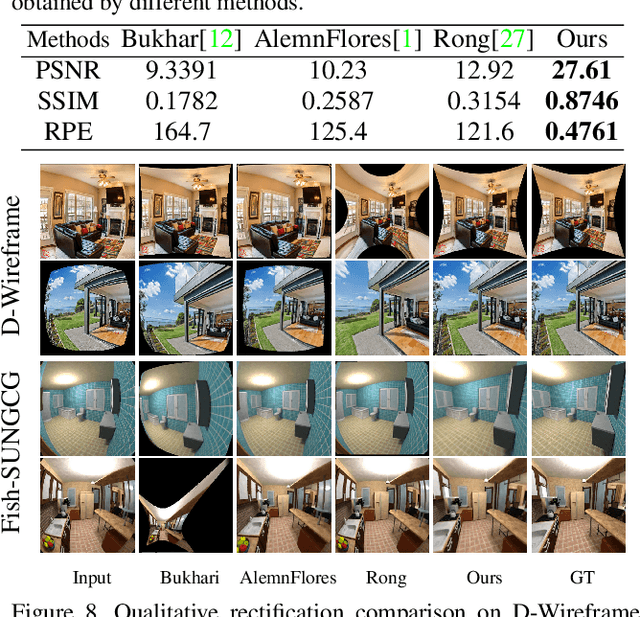
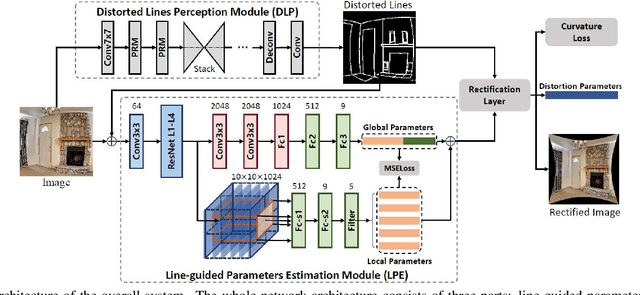
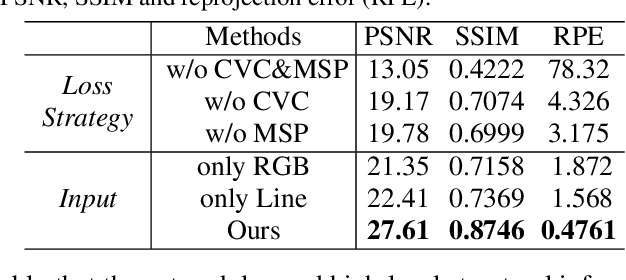
This paper presents a new deep-learning based method to simultaneously calibrate the intrinsic parameters of fisheye lens and rectify the distorted images. Assuming that the distorted lines generated by fisheye projection should be straight after rectification, we propose a novel deep neural network to impose explicit geometry constraints onto processes of the fisheye lens calibration and the distorted image rectification. In addition, considering the nonlinearity of distortion distribution in fisheye images, the proposed network fully exploits multi-scale perception to equalize the rectification effects on the whole image. To train and evaluate the proposed model, we also create a new largescale dataset labeled with corresponding distortion parameters and well-annotated distorted lines. Compared with the state-of-the-art methods, our model achieves the best published rectification quality and the most accurate estimation of distortion parameters on a large set of synthetic and real fisheye images.
Semantic Image Networks for Human Action Recognition
Jan 21, 2019
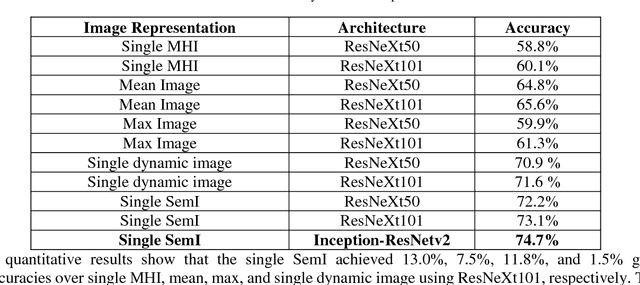

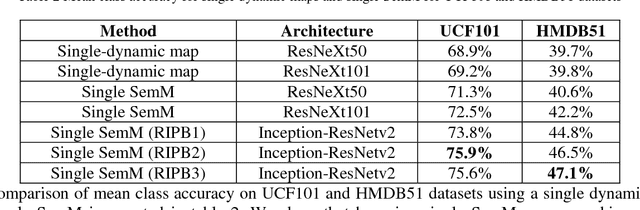
In this paper, we propose the use of a semantic image, an improved representation for video analysis, principally in combination with Inception networks. The semantic image is obtained by applying localized sparse segmentation using global clustering (LSSGC) prior to the approximate rank pooling which summarizes the motion characteristics in single or multiple images. It incorporates the background information by overlaying a static background from the window onto the subsequent segmented frames. The idea is to improve the action-motion dynamics by focusing on the region which is important for action recognition and encoding the temporal variances using the frame ranking method. We also propose the sequential combination of Inception-ResNetv2 and long-short-term memory network (LSTM) to leverage the temporal variances for improved recognition performance. Extensive analysis has been carried out on UCF101 and HMDB51 datasets which are widely used in action recognition studies. We show that (i) the semantic image generates better activations and converges faster than its original variant, (ii) using segmentation prior to approximate rank pooling yields better recognition performance, (iii) The use of LSTM leverages the temporal variance information from approximate rank pooling to model the action behavior better than the base network, (iv) the proposed representations can be adaptive as they can be used with existing methods such as temporal segment networks to improve the recognition performance, and (v) our proposed four-stream network architecture comprising of semantic images and semantic optical flows achieves state-of-the-art performance, 95.9% and 73.5% recognition accuracy on UCF101 and HMDB51, respectively.
GRDN:Grouped Residual Dense Network for Real Image Denoising and GAN-based Real-world Noise Modeling
May 27, 2019
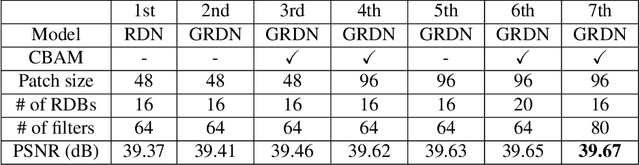
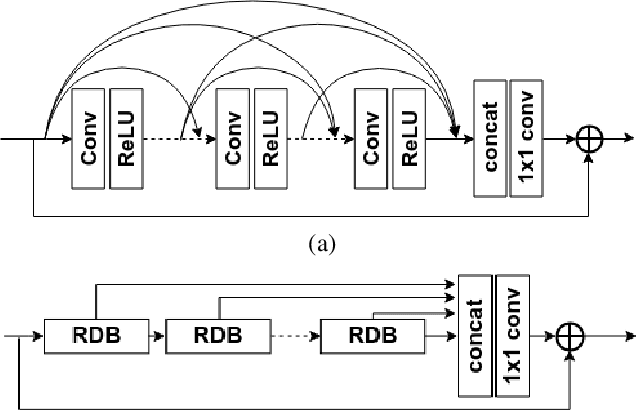
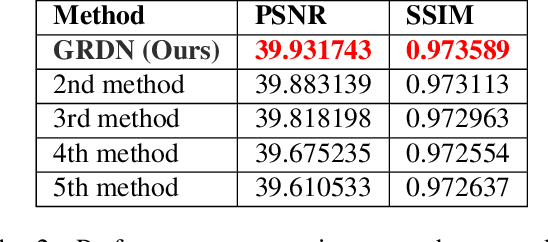
Recent research on image denoising has progressed with the development of deep learning architectures, especially convolutional neural networks. However, real-world image denoising is still very challenging because it is not possible to obtain ideal pairs of ground-truth images and real-world noisy images. Owing to the recent release of benchmark datasets, the interest of the image denoising community is now moving toward the real-world denoising problem. In this paper, we propose a grouped residual dense network (GRDN), which is an extended and generalized architecture of the state-of-the-art residual dense network (RDN). The core part of RDN is defined as grouped residual dense block (GRDB) and used as a building module of GRDN. We experimentally show that the image denoising performance can be significantly improved by cascading GRDBs. In addition to the network architecture design, we also develop a new generative adversarial network-based real-world noise modeling method. We demonstrate the superiority of the proposed methods by achieving the highest score in terms of both the peak signal-to-noise ratio and the structural similarity in the NTIRE2019 Real Image Denoising Challenge - Track 2:sRGB.
RelTransformer: Balancing the Visual Relationship Detection from Local Context, Scene and Memory
Apr 24, 2021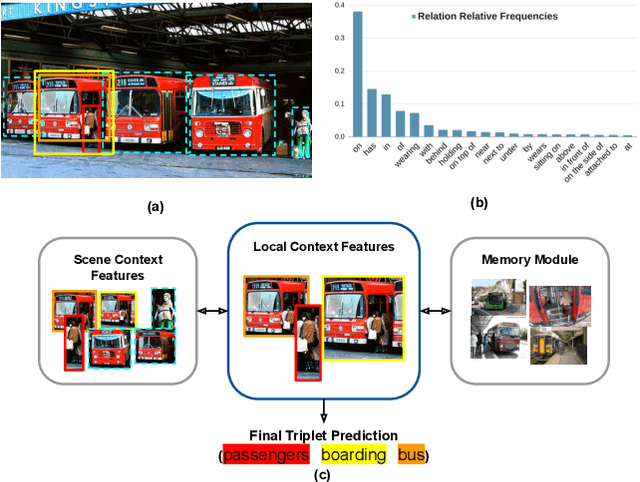
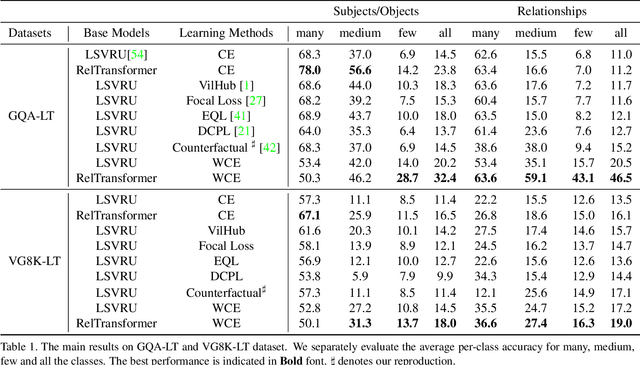
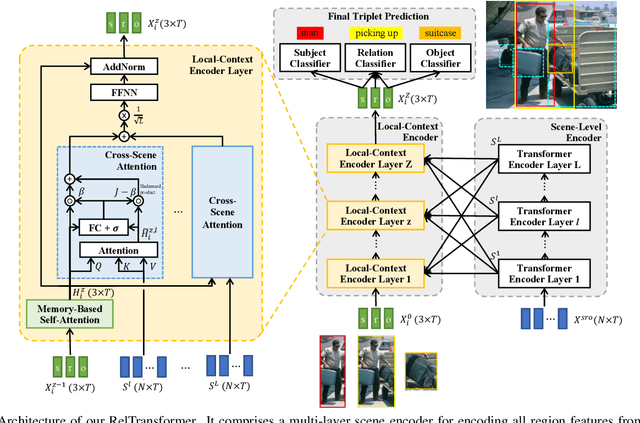
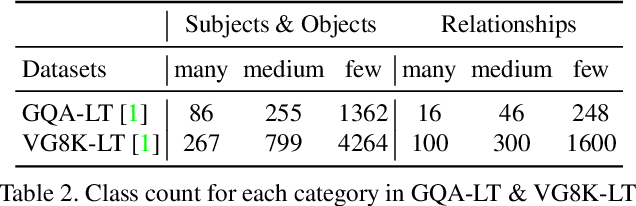
Visual relationship recognition (VRR) is a fundamental scene understanding task. The structure that VRR provides is essential to improve the AI interpretability in downstream tasks such as image captioning and visual question answering. Several recent studies showed that the long-tail problem in VRR is even more critical than that in object recognition due to the compositional complexity and structure. To overcome this limitation, we propose a novel transformer-based framework, dubbed as RelTransformer, which performs relationship prediction using rich semantic features from multiple image levels. We assume that more abundantcon textual features can generate more accurate and discriminative relationships, which can be useful when sufficient training data are lacking. The key feature of our model is its ability to aggregate three different-level features (local context, scene, and dataset-level) to compositionally predict the visual relationship. We evaluate our model on the visual genome and two "long-tail" VRR datasets, GQA-LT and VG8k-LT. Extensive experiments demonstrate that our RelTransformer could improve over the state-of-the-art baselines on all the datasets. In addition, our model significantly improves the accuracy of GQA-LT by 27.4% upon the best baselines on tail-relationship prediction. Our code is available in https://github.com/Vision-CAIR/RelTransformer.
Principled change point detection via representation learning
Jun 04, 2021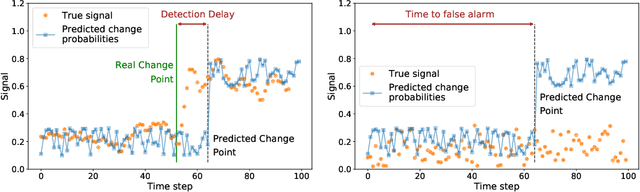
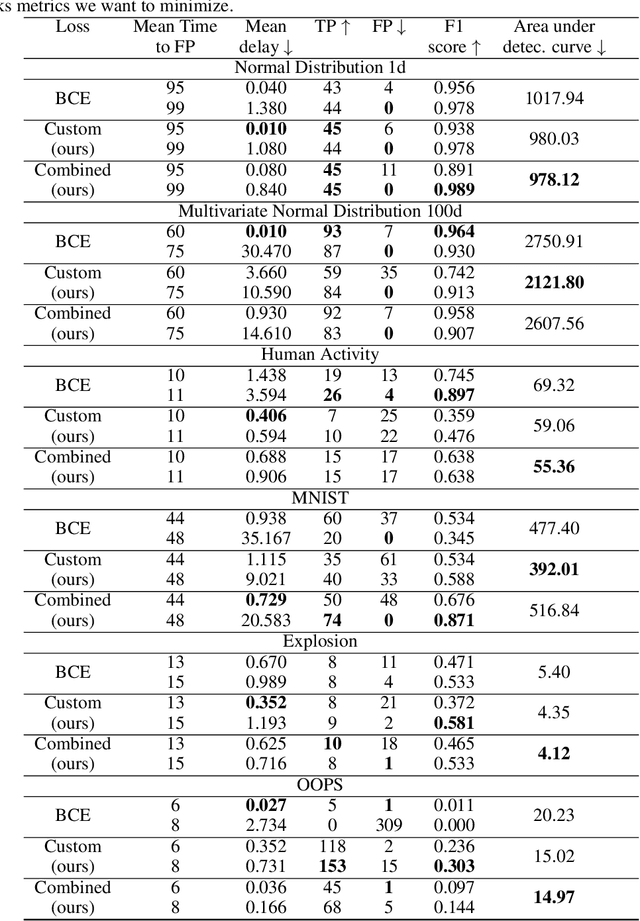
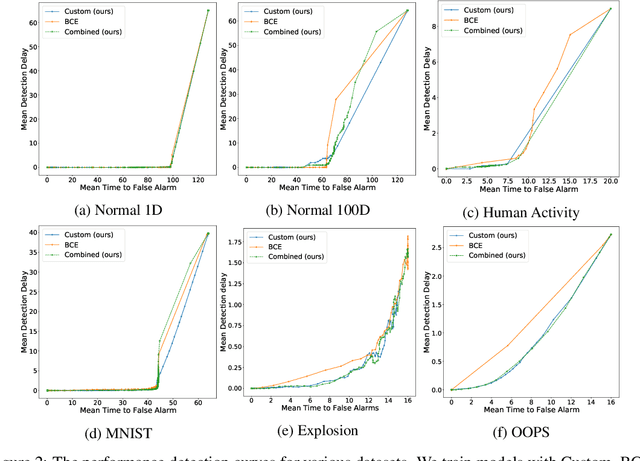
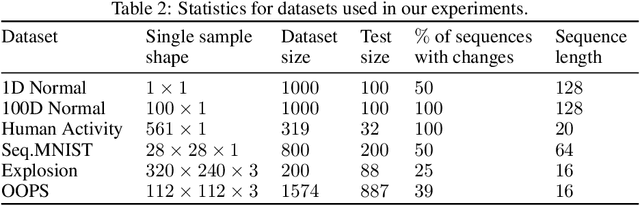
Change points are abrupt alterations in the distribution of sequential data. A change-point detection (CPD) model aims at quick detection of such changes. Classic approaches perform poorly for semi-structured sequential data because of the absence of adequate data representation learning. To deal with it, we introduce a principled differentiable loss function that considers the specificity of the CPD task. The theoretical results suggest that this function approximates well classic rigorous solutions. For such loss function, we propose an end-to-end method for the training of deep representation learning CPD models. Our experiments provide evidence that the proposed approach improves baseline results of change point detection for various data types, including real-world videos and image sequences, and improve representations for them.
Combination of Multiple Global Descriptors for Image Retrieval
Mar 26, 2019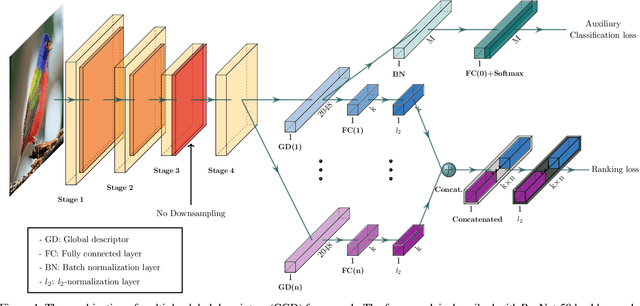

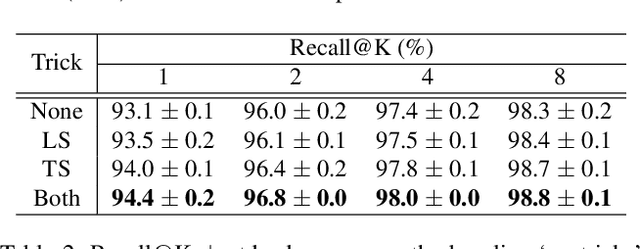
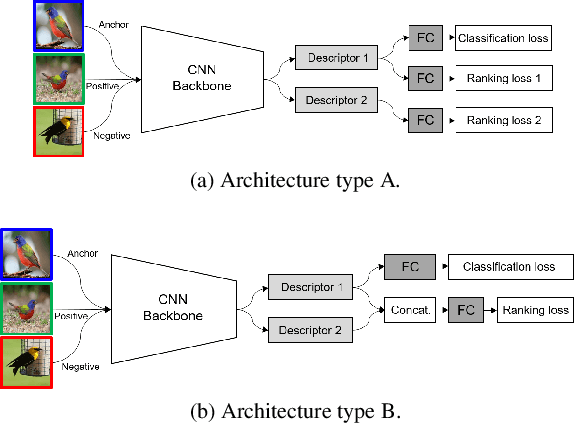
Recent studies in image retrieval task have shown that ensembling different models and combining multiple global descriptors lead to performance improvement. However, training different models for ensemble is not only difficult but also inefficient with respect to time or memory. In this paper, we propose a novel framework that exploits multiple global descriptors to get an ensemble-like effect while it can be trained in an end-to-end manner. The proposed framework is flexible and expandable by the global descriptor, CNN backbone, loss, and dataset. Moreover, we investigate the effectiveness of combining multiple global descriptors with quantitative and qualitative analysis. Our extensive experiments show that the combined descriptor outperforms a single global descriptor, as it can utilize different types of feature properties. In the benchmark evaluation, the proposed framework achieves the state-of-the-art performance on the CARS196, CUB200-2011, In-shop Clothes and Stanford Online Products on image retrieval tasks by a large margin compared to competing approaches.
TetraTSDF: 3D human reconstruction from a single image with a tetrahedral outer shell
Apr 22, 2020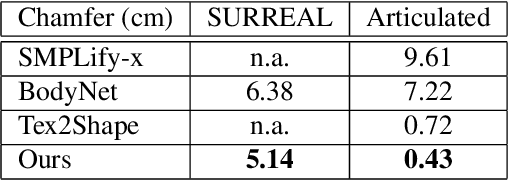
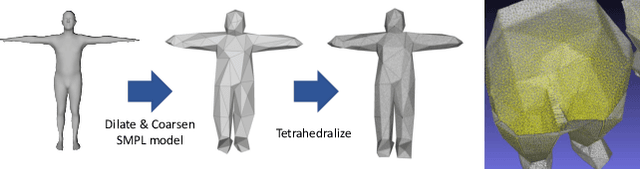

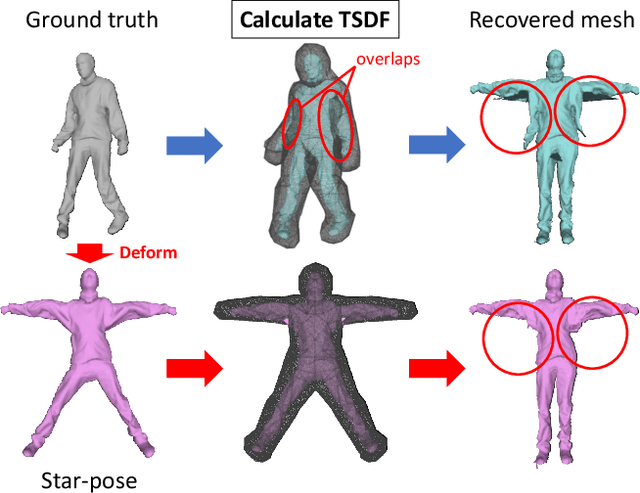
Recovering the 3D shape of a person from its 2D appearance is ill-posed due to ambiguities. Nevertheless, with the help of convolutional neural networks (CNN) and prior knowledge on the 3D human body, it is possible to overcome such ambiguities to recover detailed 3D shapes of human bodies from single images. Current solutions, however, fail to reconstruct all the details of a person wearing loose clothes. This is because of either (a) huge memory requirement that cannot be maintained even on modern GPUs or (b) the compact 3D representation that cannot encode all the details. In this paper, we propose the tetrahedral outer shell volumetric truncated signed distance function (TetraTSDF) model for the human body, and its corresponding part connection network (PCN) for 3D human body shape regression. Our proposed model is compact, dense, accurate, and yet well suited for CNN-based regression task. Our proposed PCN allows us to learn the distribution of the TSDF in the tetrahedral volume from a single image in an end-to-end manner. Results show that our proposed method allows to reconstruct detailed shapes of humans wearing loose clothes from single RGB images.
Hallucination In Object Detection -- A Study In Visual Part Verification
Jun 04, 2021
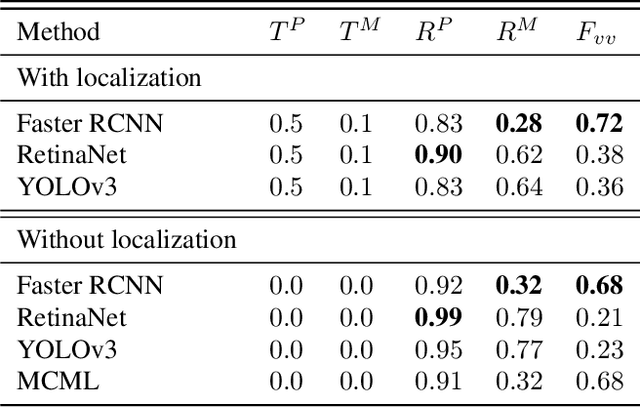

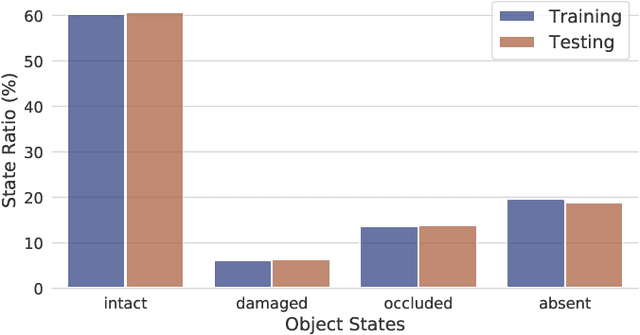
We show that object detectors can hallucinate and detect missing objects; potentially even accurately localized at their expected, but non-existing, position. This is particularly problematic for applications that rely on visual part verification: detecting if an object part is present or absent. We show how popular object detectors hallucinate objects in a visual part verification task and introduce the first visual part verification dataset: DelftBikes, which has 10,000 bike photographs, with 22 densely annotated parts per image, where some parts may be missing. We explicitly annotated an extra object state label for each part to reflect if a part is missing or intact. We propose to evaluate visual part verification by relying on recall and compare popular object detectors on DelftBikes.
Fine-grained MRI Reconstruction using Attentive Selection Generative Adversarial Networks
Mar 13, 2021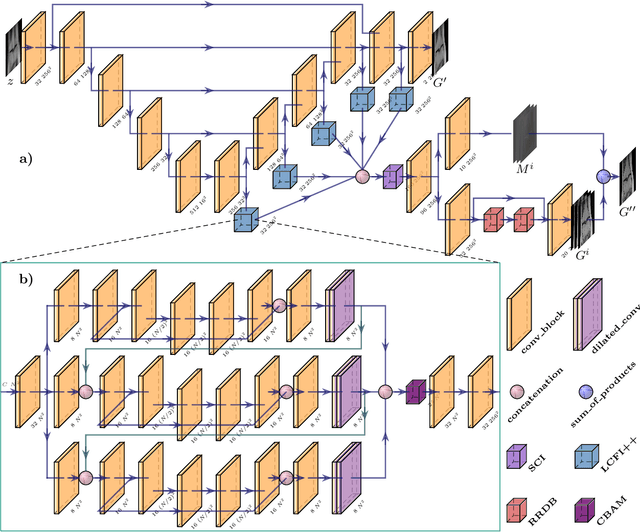
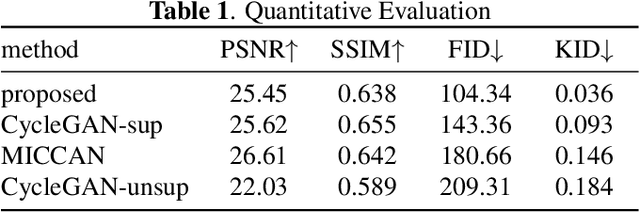
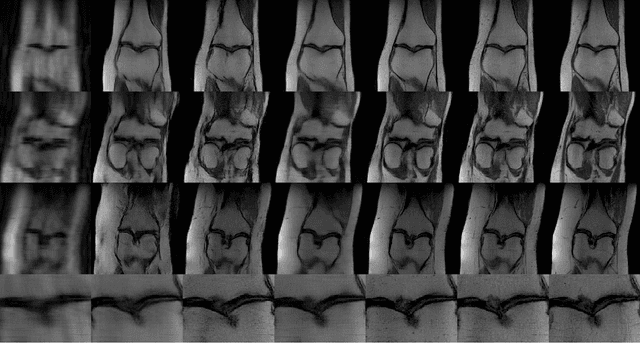
Compressed sensing (CS) leverages the sparsity prior to provide the foundation for fast magnetic resonance imaging (fastMRI). However, iterative solvers for ill-posed problems hinder their adaption to time-critical applications. Moreover, such a prior can be neither rich to capture complicated anatomical structures nor applicable to meet the demand of high-fidelity reconstructions in modern MRI. Inspired by the state-of-the-art methods in image generation, we propose a novel attention-based deep learning framework to provide high-quality MRI reconstruction. We incorporate large-field contextual feature integration and attention selection in a generative adversarial network (GAN) framework. We demonstrate that the proposed model can produce superior results compared to other deep learning-based methods in terms of image quality, and relevance to the MRI reconstruction in an extremely low sampling rate diet.
Image Super-Resolution as a Defense Against Adversarial Attacks
Jan 07, 2019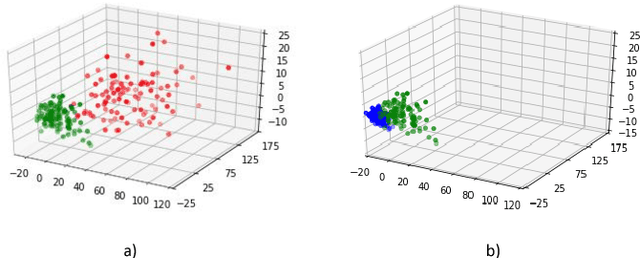
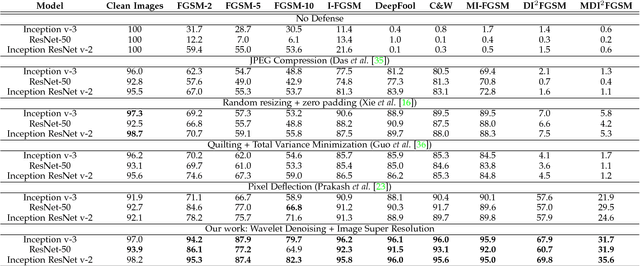
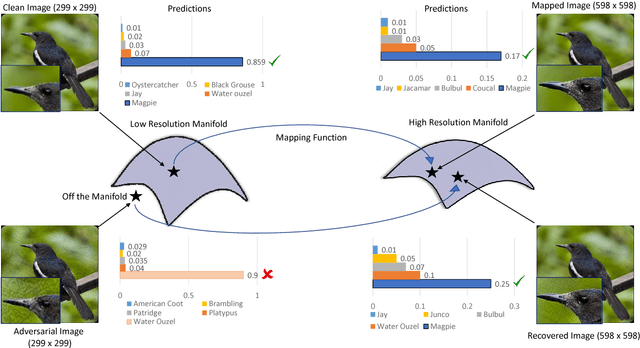
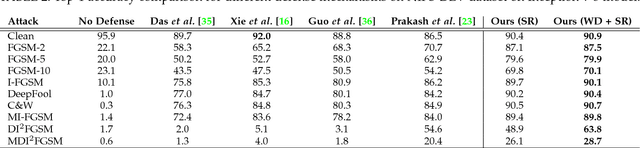
Convolutional Neural Networks have achieved significant success across multiple computer vision tasks. However, they are vulnerable to carefully crafted, human imperceptible adversarial noise patterns which constrain their deployment in critical security-sensitive systems. This paper proposes a computationally efficient image enhancement approach that provides a strong defense mechanism to effectively mitigate the effect of such adversarial perturbations. We show that the deep image restoration networks learn mapping functions that can bring \textit{off-the-manifold} adversarial samples onto the natural image manifold, thus restoring classifier beliefs towards correct classes. A distinguishing feature of our approach is that, in addition to providing robustness against attacks, it simultaneously enhances image quality and retains models performance on clean images. Furthermore, the proposed method does not modify the classifier or requires a separate mechanism to detect adversarial images. The effectiveness of the scheme has been demonstrated through extensive experiments, where it has proven a strong defense in both white-box and black-box attack settings. The proposed scheme is simple and has the following advantages: (1) it does not require any model training or parameter optimization, (2) it complements other existing defense mechanisms, (3) it is agnostic to the attacked model and attack type and (4) it provides superior performance across all popular attack algorithms. Our codes are publicly available at https://github.com/aamir-mustafa/super-resolution-adversarial-defense.