 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rethinking Text Line Recognition Models
Apr 15, 2021

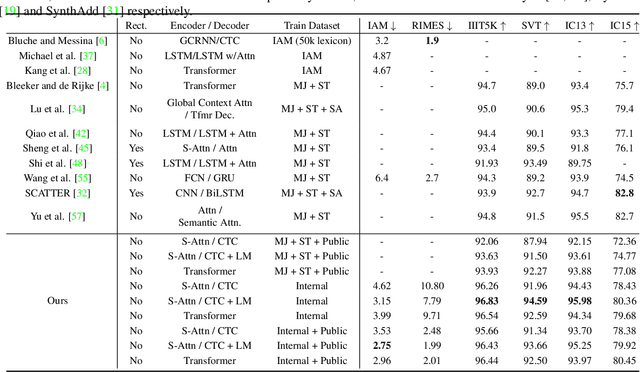

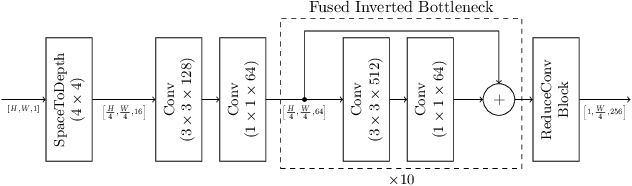
In this paper, we study the problem of text line recognition. Unlike most approaches targeting specific domains such as scene-text or handwritten documents, we investigate the general problem of developing a universal architecture that can extract text from any image, regardless of source or input modality. We consider two decoder families (Connectionist Temporal Classification and Transformer) and three encoder modules (Bidirectional LSTMs, Self-Attention, and GRCLs), and conduct extensive experiments to compare their accuracy and performance on widely used public datasets of scene and handwritten text. We find that a combination that so far has received little attention in the literature, namely a Self-Attention encoder coupled with the CTC decoder, when compounded with an external language model and trained on both public and internal data, outperforms all the others in accuracy and computational complexity. Unlike the more common Transformer-based models, this architecture can handle inputs of arbitrary length, a requirement for universal line recognition. Using an internal dataset collected from multiple sources, we also expose the limitations of current public datasets in evaluating the accuracy of line recognizers, as the relatively narrow image width and sequence length distributions do not allow to observe the quality degradation of the Transformer approach when applied to the transcription of long lines.
Interval type-2 Beta Fuzzy Near set based approach to content based image retrieval
Dec 07, 2018
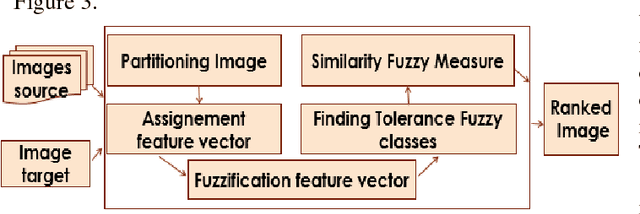

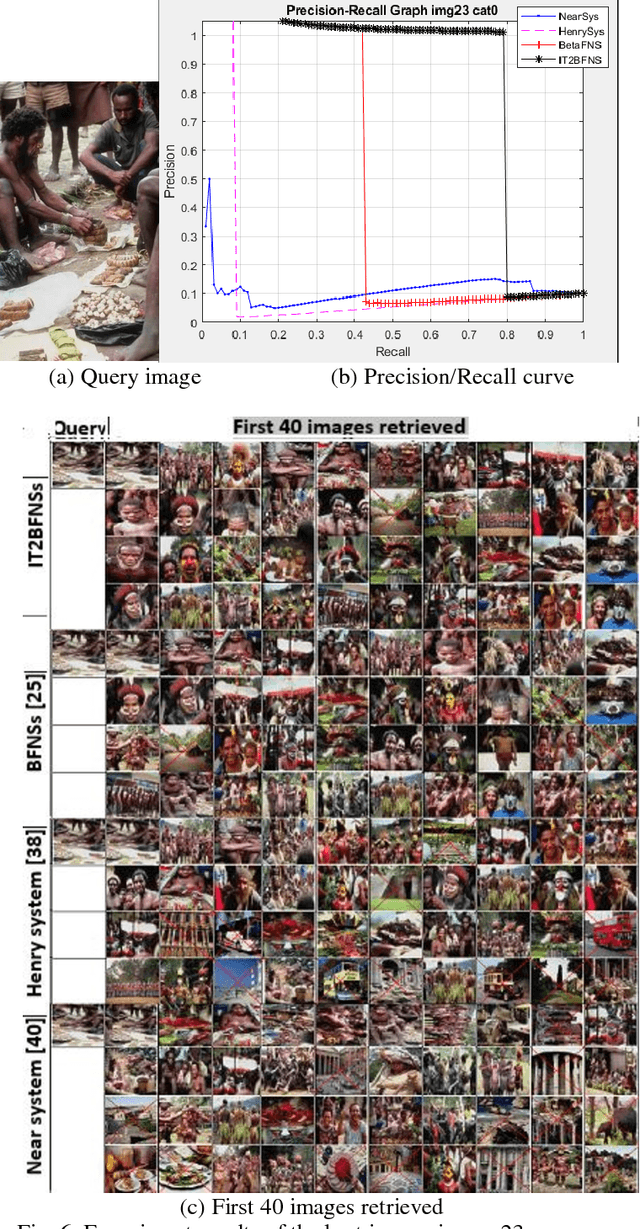
In an automated search system, similarity is a key concept in solving a human task. Indeed, human process is usually a natural categorization that underlies many natural abilities such as image recovery, language comprehension, decision making, or pattern recognition. In the image search axis, there are several ways to measure the similarity between images in an image database, to a query image. Image search by content is based on the similarity of the visual characteristics of the images. The distance function used to evaluate the similarity between images depends on the criteria of the search but also on the representation of the characteristics of the image; this is the main idea of the near and fuzzy sets approaches. In this article, we introduce a new category of beta type-2 fuzzy sets for the description of image characteristics as well as the near sets approach for image recovery. Finally, we illustrate our work with examples of image recovery problems used in the real world.
Co-training for Deep Object Detection: Comparing Single-modal and Multi-modal Approaches
Apr 23, 2021

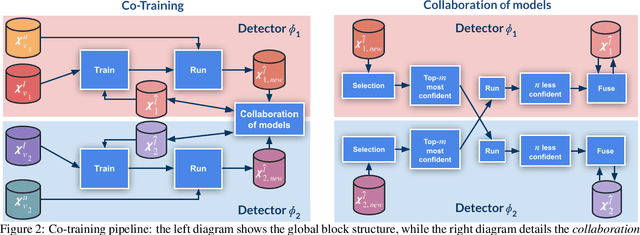
Top-performing computer vision models are powered by convolutional neural networks (CNNs). Training an accurate CNN highly depends on both the raw sensor data and their associated ground truth (GT). Collecting such GT is usually done through human labeling, which is time-consuming and does not scale as we wish. This data labeling bottleneck may be intensified due to domain shifts among image sensors, which could force per-sensor data labeling. In this paper, we focus on the use of co-training, a semi-supervised learning (SSL) method, for obtaining self-labeled object bounding boxes (BBs), i.e., the GT to train deep object detectors. In particular, we assess the goodness of multi-modal co-training by relying on two different views of an image, namely, appearance (RGB) and estimated depth (D). Moreover, we compare appearance-based single-modal co-training with multi-modal. Our results suggest that in a standard SSL setting (no domain shift, a few human-labeled data) and under virtual-to-real domain shift (many virtual-world labeled data, no human-labeled data) multi-modal co-training outperforms single-modal. In the latter case, by performing GAN-based domain translation both co-training modalities are on pair; at least, when using an off-the-shelf depth estimation model not specifically trained on the translated images.
Skeleton Image Representation for 3D Action Recognition based on Tree Structure and Reference Joints
Sep 11, 2019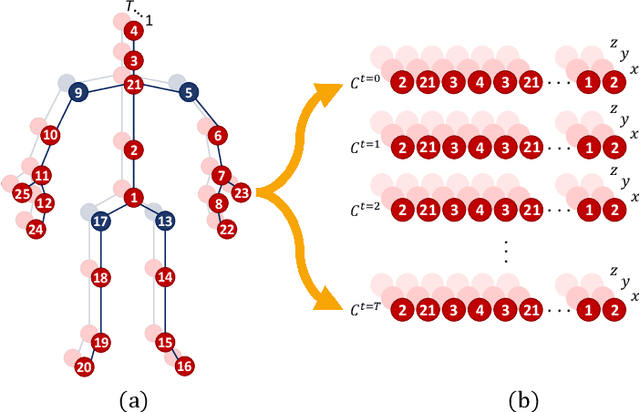
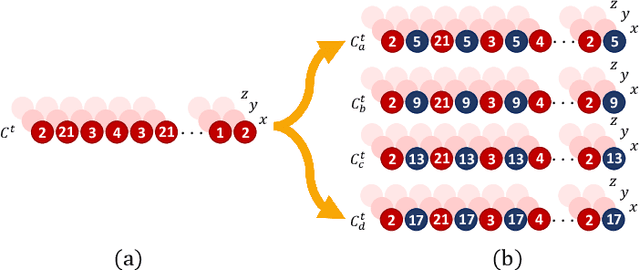
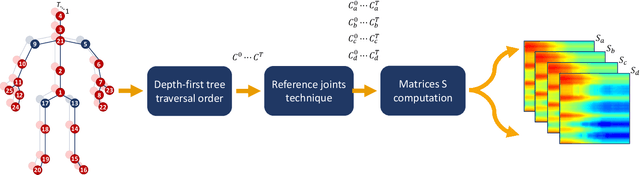
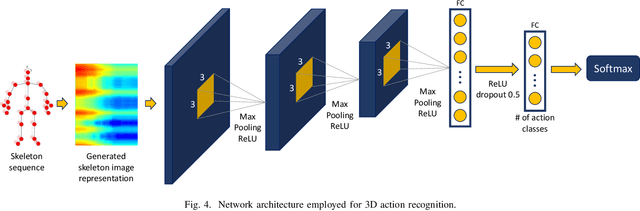
In the last years, the computer vision research community has studied on how to model temporal dynamics in videos to employ 3D human action recognition. To that end, two main baseline approaches have been researched: (i) Recurrent Neural Networks (RNNs) with Long-Short Term Memory (LSTM); and (ii) skeleton image representations used as input to a Convolutional Neural Network (CNN). Although RNN approaches present excellent results, such methods lack the ability to efficiently learn the spatial relations between the skeleton joints. On the other hand, the representations used to feed CNN approaches present the advantage of having the natural ability of learning structural information from 2D arrays (i.e., they learn spatial relations from the skeleton joints). To further improve such representations, we introduce the Tree Structure Reference Joints Image (TSRJI), a novel skeleton image representation to be used as input to CNNs. The proposed representation has the advantage of combining the use of reference joints and a tree structure skeleton. While the former incorporates different spatial relationships between the joints, the latter preserves important spatial relations by traversing a skeleton tree with a depth-first order algorithm. Experimental results demonstrate the effectiveness of the proposed representation for 3D action recognition on two datasets achieving state-of-the-art results on the recent NTU RGB+D~120 dataset.
Review on Optical Image Hiding and Watermarking Techniques
Apr 16, 2018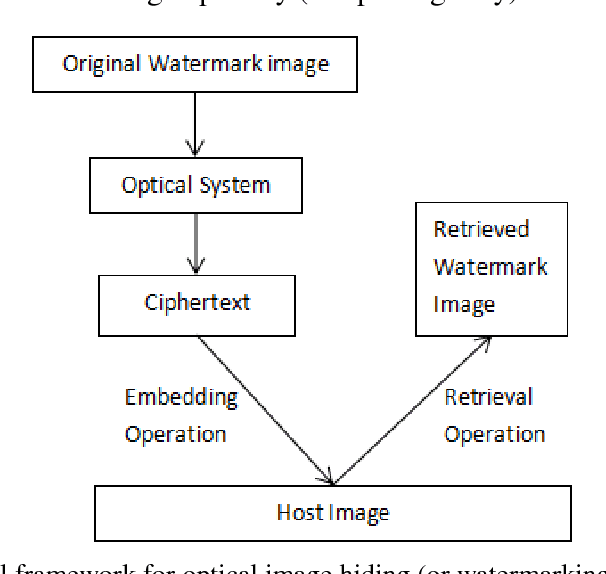
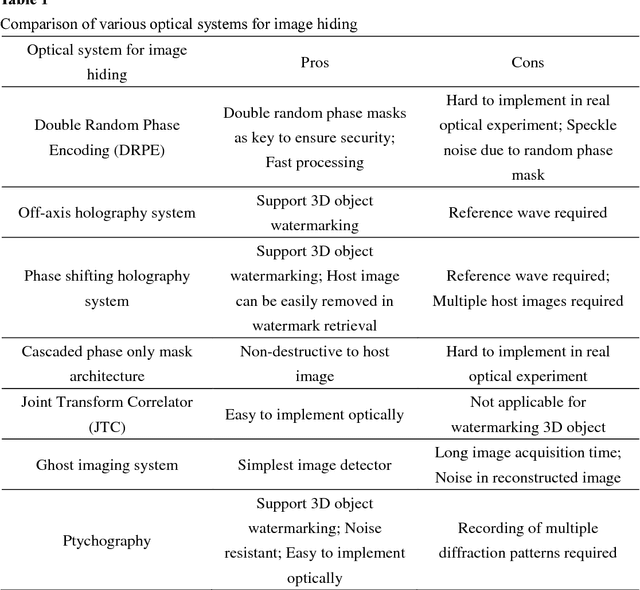

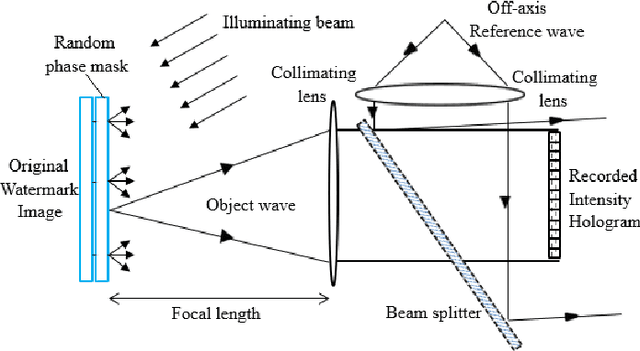
Information security is a critical issue in modern society and image watermarking can effectively prevent unauthorized information access. Optical image watermarking techniques generally have advantages of parallel high-speed processing and multi-dimensional capabilities compared with digital approaches. This paper provides a comprehensive review on the research works related to optical image hiding and watermarking techniques conducted in the past decade. The past research works are focused on two major aspects, various optical systems for image hiding and the methods for embedding optical system output into a host image. A summary of the state-of-the-art works is made from these two perspectives.
Universal and Flexible Optical Aberration Correction Using Deep-Prior Based Deconvolution
Apr 07, 2021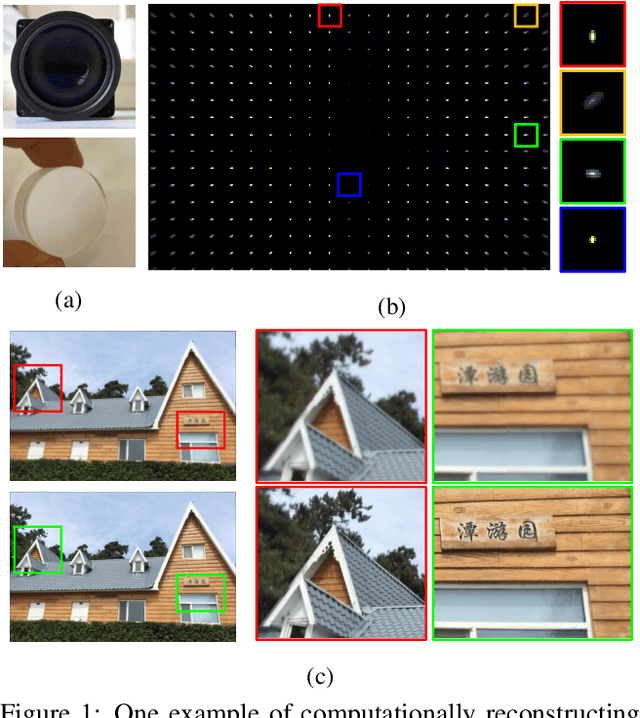

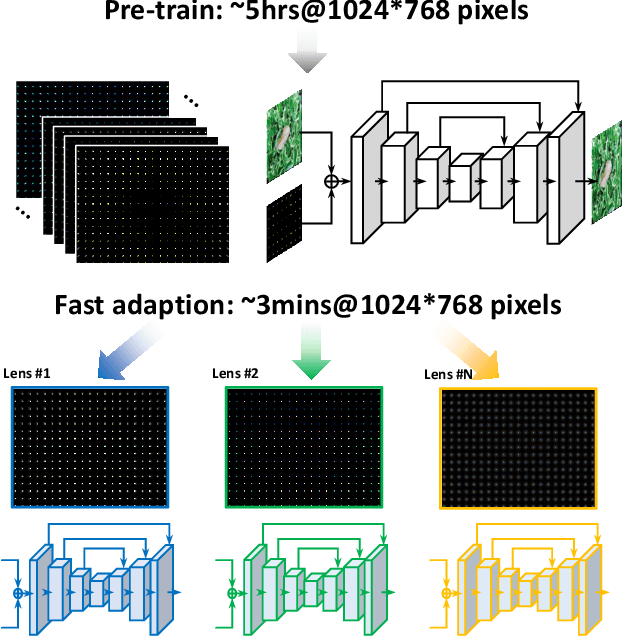
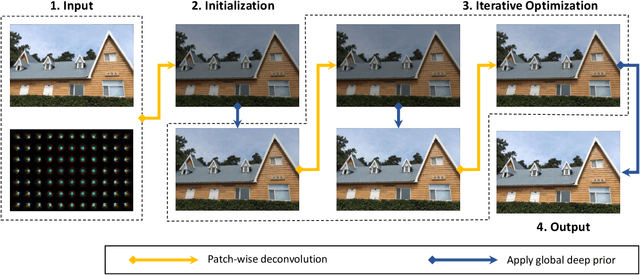
High quality imaging usually requires bulky and expensive lenses to compensate geometric and chromatic aberrations. This poses high constraints on the optical hash or low cost applications. Although one can utilize algorithmic reconstruction to remove the artifacts of low-end lenses, the degeneration from optical aberrations is spatially varying and the computation has to trade off efficiency for performance. For example, we need to conduct patch-wise optimization or train a large set of local deep neural networks to achieve high reconstruction performance across the whole image. In this paper, we propose a PSF aware plug-and-play deep network, which takes the aberrant image and PSF map as input and produces the latent high quality version via incorporating lens-specific deep priors, thus leading to a universal and flexible optical aberration correction method. Specifically, we pre-train a base model from a set of diverse lenses and then adapt it to a given lens by quickly refining the parameters, which largely alleviates the time and memory consumption of model learning. The approach is of high efficiency in both training and testing stages. Extensive results verify the promising applications of our proposed approach for compact low-end cameras.
A Simple Baseline for StyleGAN Inversion
Apr 15, 2021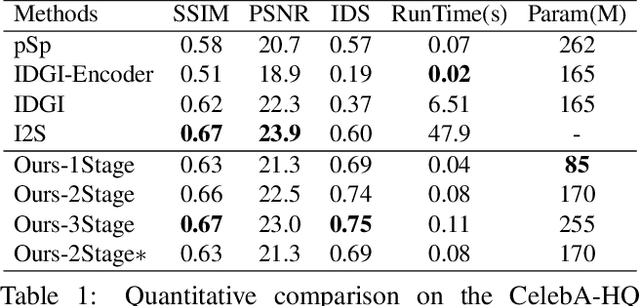
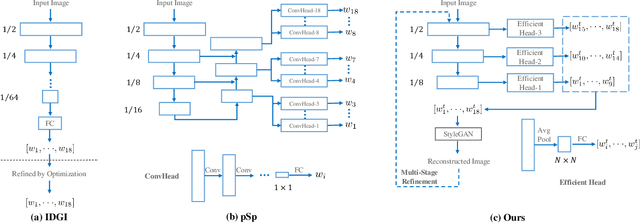
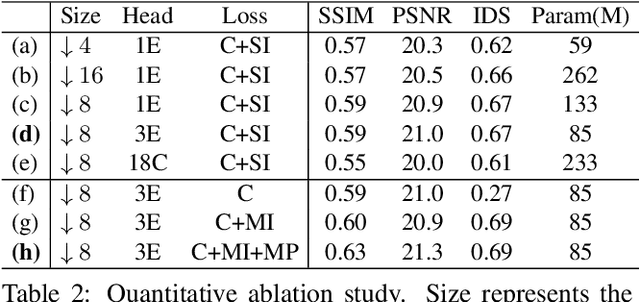

This paper studies the problem of StyleGAN inversion, which plays an essential role in enabling the pretrained StyleGAN to be used for real facial image editing tasks. This problem has the high demand for quality and efficiency. Existing optimization-based methods can produce high quality results, but the optimization often takes a long time. On the contrary, forward-based methods are usually faster but the quality of their results is inferior. In this paper, we present a new feed-forward network for StyleGAN inversion, with significant improvement in terms of efficiency and quality. In our inversion network, we introduce: 1) a shallower backbone with multiple efficient heads across scales; 2) multi-layer identity loss and multi-layer face parsing loss to the loss function; and 3) multi-stage refinement. Combining these designs together forms a simple and efficient baseline method which exploits all benefits of optimization-based and forward-based methods. Quantitative and qualitative results show that our method performs better than existing forward-based methods and comparably to state-of-the-art optimization-based methods, while maintaining the high efficiency as well as forward-based methods. Moreover, a number of real image editing applications demonstrate the efficacy of our method. Our project page is ~\url{https://wty-ustc.github.io/inversion}.
Free Hyperbolic Neural Networks with Limited Radii
Jul 23, 2021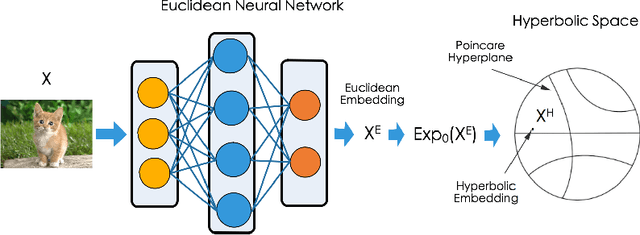

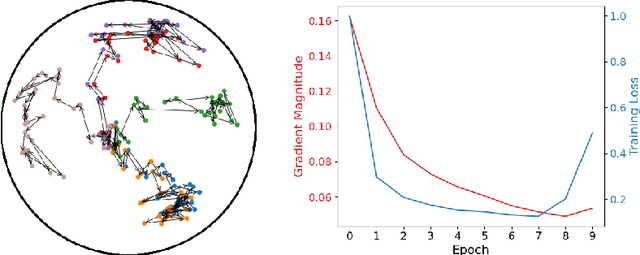

Non-Euclidean geometry with constant negative curvature, i.e., hyperbolic space, has attracted sustained attention in the community of machine learning. Hyperbolic space, owing to its ability to embed hierarchical structures continuously with low distortion, has been applied for learning data with tree-like structures. Hyperbolic Neural Networks (HNNs) that operate directly in hyperbolic space have also been proposed recently to further exploit the potential of hyperbolic representations. While HNNs have achieved better performance than Euclidean neural networks (ENNs) on datasets with implicit hierarchical structure, they still perform poorly on standard classification benchmarks such as CIFAR and ImageNet. The traditional wisdom is that it is critical for the data to respect the hyperbolic geometry when applying HNNs. In this paper, we first conduct an empirical study showing that the inferior performance of HNNs on standard recognition datasets can be attributed to the notorious vanishing gradient problem. We further discovered that this problem stems from the hybrid architecture of HNNs. Our analysis leads to a simple yet effective solution called Feature Clipping, which regularizes the hyperbolic embedding whenever its norm exceeding a given threshold. Our thorough experiments show that the proposed method can successfully avoid the vanishing gradient problem when training HNNs with backpropagation. The improved HNNs are able to achieve comparable performance with ENNs on standard image recognition datasets including MNIST, CIFAR10, CIFAR100 and ImageNet, while demonstrating more adversarial robustness and stronger out-of-distribution detection capability.
Local Morphometry of Closed, Implicit Surfaces
Jul 29, 2021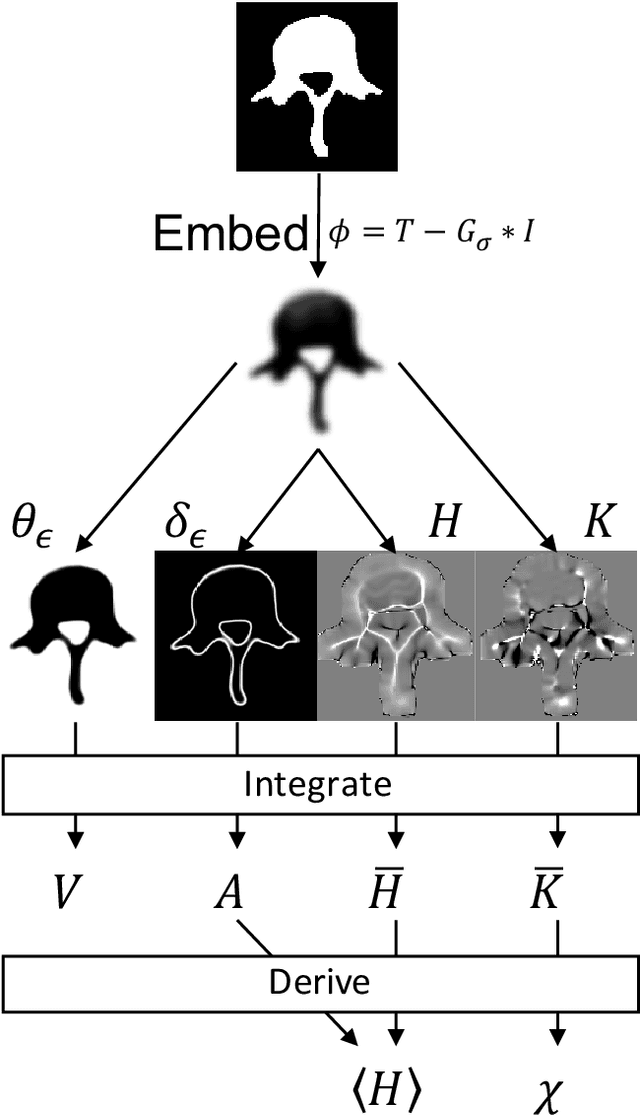
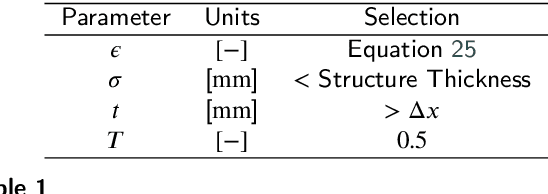
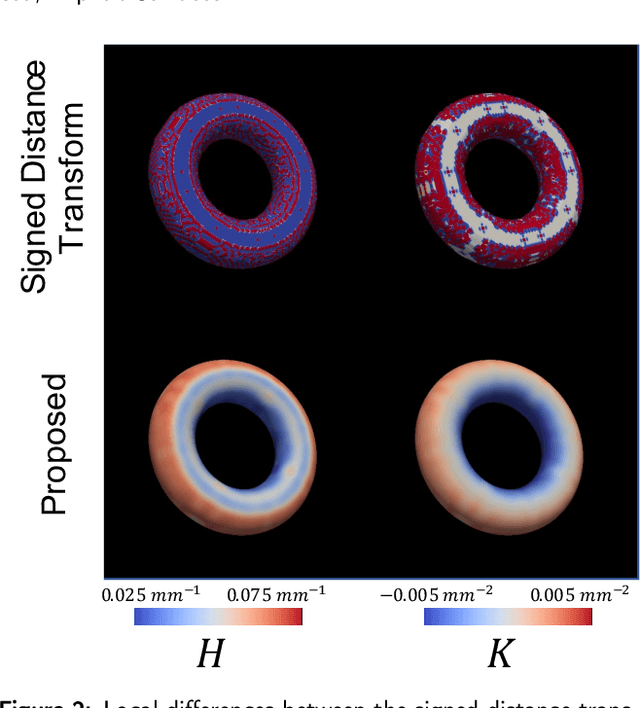
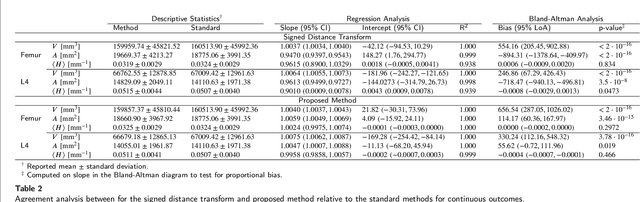
Anatomical structures such as the hippocampus, liver, and bones can be analyzed as orientable, closed surfaces. This permits the computation of volume, surface area, mean curvature, Gaussian curvature, and the Euler-Poincar\'e characteristic as well as comparison of these morphometrics between structures of different topology. The structures are commonly represented implicitly in curve evolution problems as the zero level set of an embedding. Practically, binary images of anatomical structures are embedded using a signed distance transform. However, quantization prevents the accurate computation of curvatures, leading to considerable errors in morphometry. This paper presents a fast, simple embedding procedure for accurate local morphometry as the zero crossing of the Gaussian blurred binary image. The proposed method was validated based on the femur and fourth lumbar vertebrae of 50 clinical computed tomography datasets. The results show that the signed distance transform leads to large quantization errors in the computed local curvature. Global validation of morphometry using regression and Bland-Altman analysis revealed that the coefficient of determination for the average mean curvature is improved from 93.8% with the signed distance transform to 100% with the proposed method. For the surface area, the proportional bias is improved from -5.0% for the signed distance transform to +0.6% for the proposed method. The Euler-Poincar\'e characteristic is improved from unusable in the signed distance transform to 98% accuracy for the proposed method. The proposed method enables an improved local and global evaluation of curvature for purposes of morphometry on closed, implicit surfaces.
Keyframe-Focused Visual Imitation Learning
Jun 11, 2021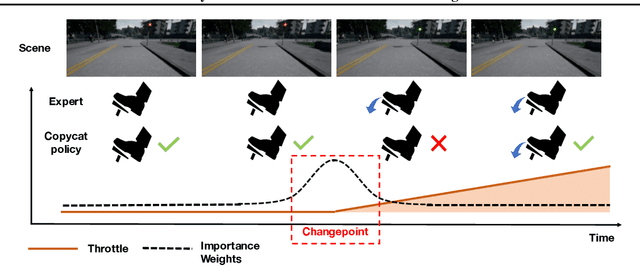
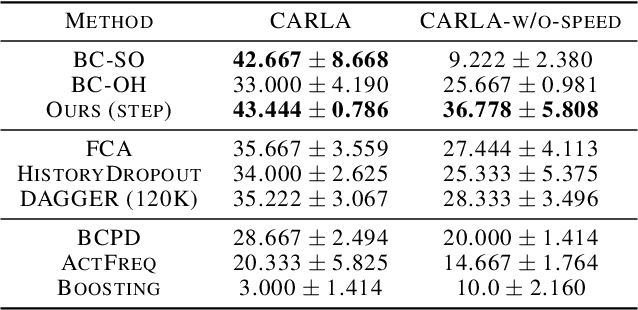
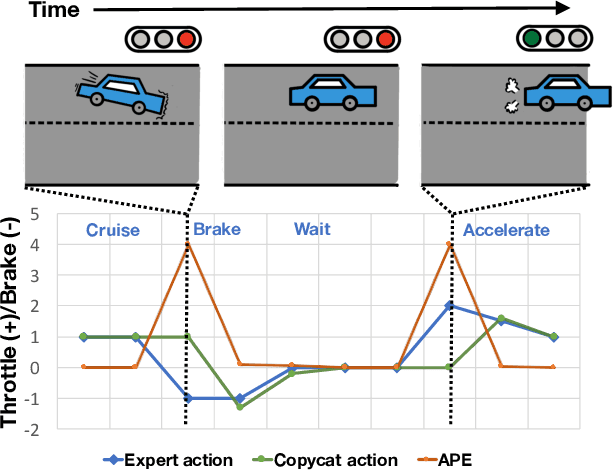

Imitation learning trains control policies by mimicking pre-recorded expert demonstrations. In partially observable settings, imitation policies must rely on observation histories, but many seemingly paradoxical results show better performance for policies that only access the most recent observation. Recent solutions ranging from causal graph learning to deep information bottlenecks have shown promising results, but failed to scale to realistic settings such as visual imitation. We propose a solution that outperforms these prior approaches by upweighting demonstration keyframes corresponding to expert action changepoints. This simple approach easily scales to complex visual imitation settings. Our experimental results demonstrate consistent performance improvements over all baselines on image-based Gym MuJoCo continuous control tasks. Finally, on the CARLA photorealistic vision-based urban driving simulator, we resolve a long-standing issue in behavioral cloning for driving by demonstrating effective imitation from observation histories. Supplementary materials and code at: \url{https://tinyurl.com/imitation-keyframes}.