 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Back to the Feature: Learning Robust Camera Localization from Pixels to Pose
Apr 07, 2021
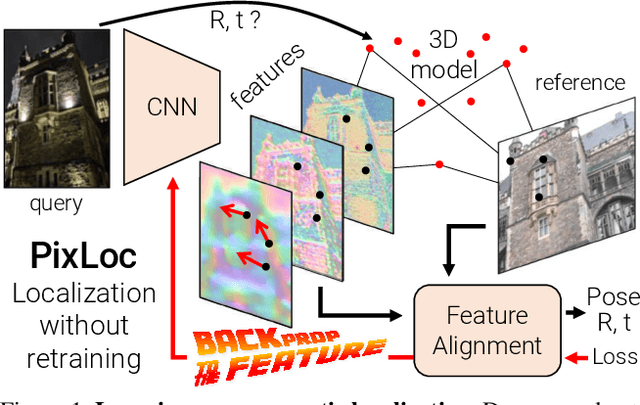
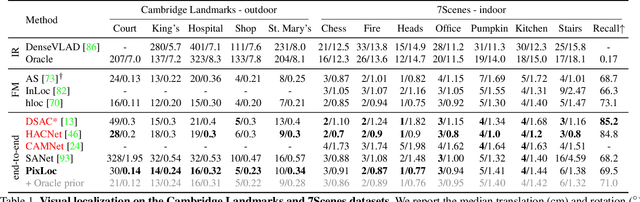
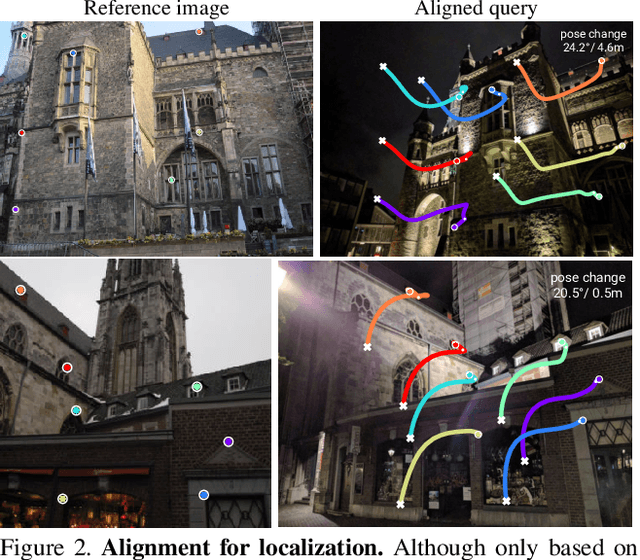
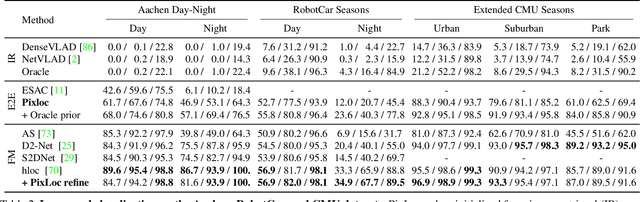
Camera pose estimation in known scenes is a 3D geometry task recently tackled by multiple learning algorithms. Many regress precise geometric quantities, like poses or 3D points, from an input image. This either fails to generalize to new viewpoints or ties the model parameters to a specific scene. In this paper, we go Back to the Feature: we argue that deep networks should focus on learning robust and invariant visual features, while the geometric estimation should be left to principled algorithms. We introduce PixLoc, a scene-agnostic neural network that estimates an accurate 6-DoF pose from an image and a 3D model. Our approach is based on the direct alignment of multiscale deep features, casting camera localization as metric learning. PixLoc learns strong data priors by end-to-end training from pixels to pose and exhibits exceptional generalization to new scenes by separating model parameters and scene geometry. The system can localize in large environments given coarse pose priors but also improve the accuracy of sparse feature matching by jointly refining keypoints and poses with little overhead. The code will be publicly available at https://github.com/cvg/pixloc.
Equivariant Networks for Pixelized Spheres
Jun 12, 2021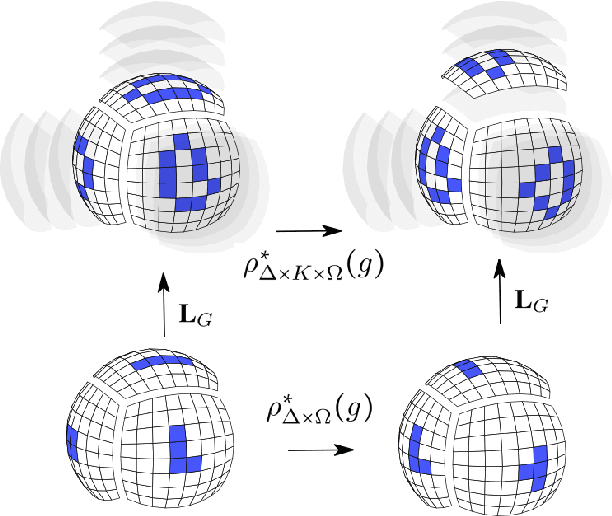
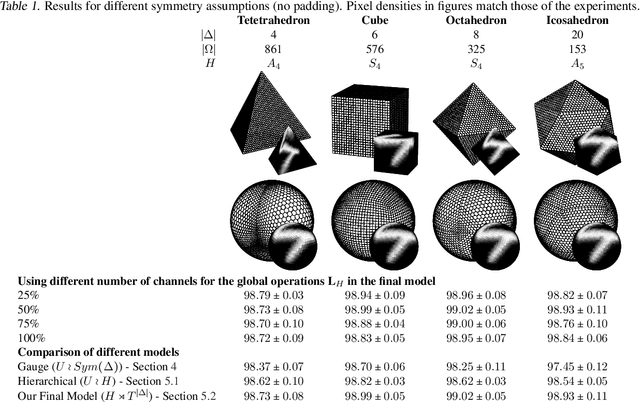
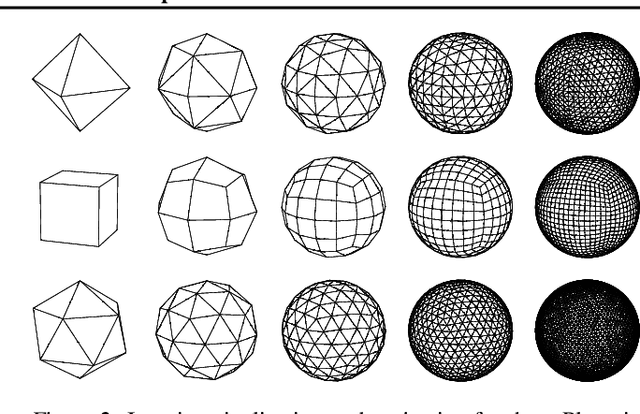
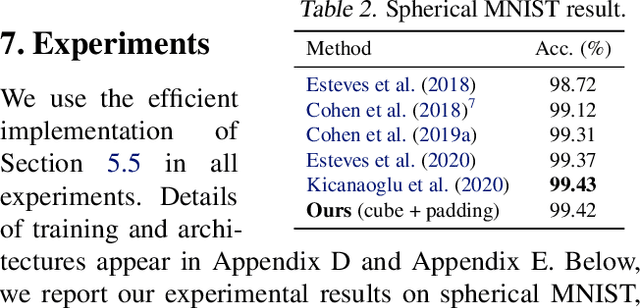
Pixelizations of Platonic solids such as the cube and icosahedron have been widely used to represent spherical data, from climate records to Cosmic Microwave Background maps. Platonic solids have well-known global symmetries. Once we pixelize each face of the solid, each face also possesses its own local symmetries in the form of Euclidean isometries. One way to combine these symmetries is through a hierarchy. However, this approach does not adequately model the interplay between the two levels of symmetry transformations. We show how to model this interplay using ideas from group theory, identify the equivariant linear maps, and introduce equivariant padding that respects these symmetries. Deep networks that use these maps as their building blocks generalize gauge equivariant CNNs on pixelized spheres. These deep networks achieve state-of-the-art results on semantic segmentation for climate data and omnidirectional image processing. Code is available at https://git.io/JGiZA.
Informed MCMC with Bayesian Neural Networks for Facial Image Analysis
Nov 29, 2018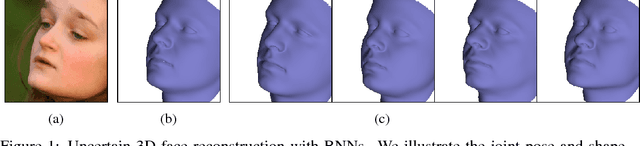
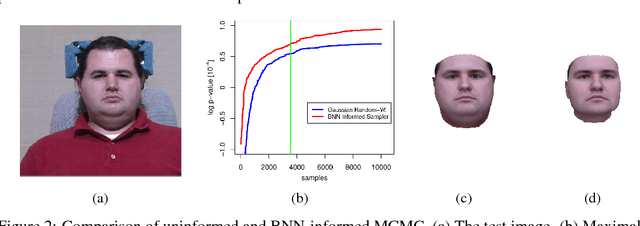
Computer vision tasks are difficult because of the large variability in the data that is induced by changes in light, background, partial occlusion as well as the varying pose, texture, and shape of objects. Generative approaches to computer vision allow us to overcome this difficulty by explicitly modeling the physical image formation process. Using generative object models, the analysis of an observed image is performed via Bayesian inference of the posterior distribution. This conceptually simple approach tends to fail in practice because of several difficulties stemming from sampling the posterior distribution: high-dimensionality and multi-modality of the posterior distribution as well as expensive simulation of the rendering process. The main difficulty of sampling approaches in a computer vision context is choosing the proposal distribution accurately so that maxima of the posterior are explored early and the algorithm quickly converges to a valid image interpretation. In this work, we propose to use a Bayesian Neural Network for estimating an image dependent proposal distribution. Compared to a standard Gaussian random walk proposal, this accelerates the sampler in finding regions of the posterior with high value. In this way, we can significantly reduce the number of samples needed to perform facial image analysis.
Ultrasound Matrix Imaging. I. The focused reflection matrix and the F-factor
Mar 02, 2021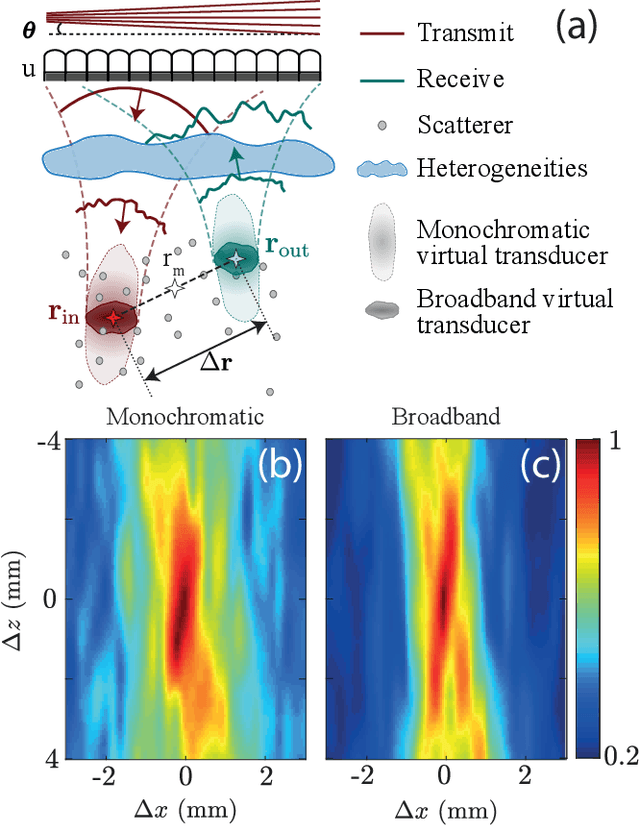
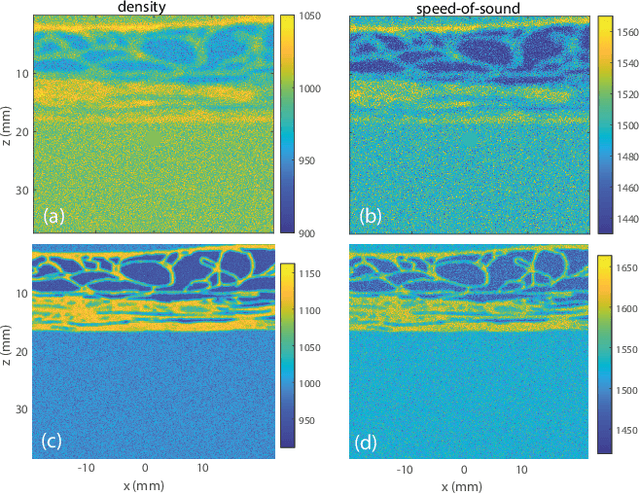
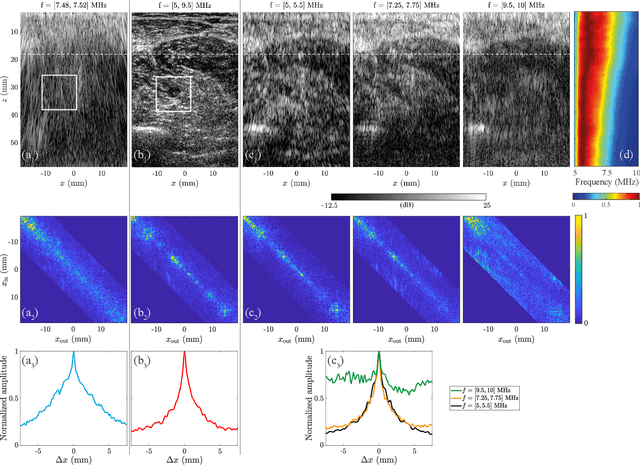
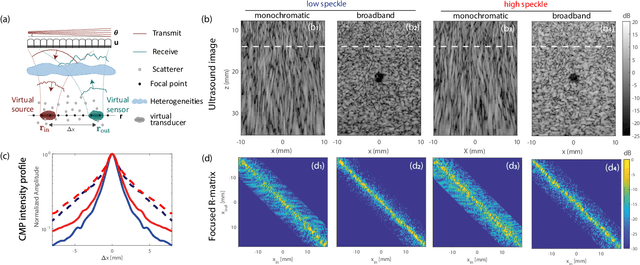
This is the first article in a series of two dealing with a matrix approach \alex{for} aberration quantification and correction in ultrasound imaging. Advanced synthetic beamforming relies on a double focusing operation at transmission and reception on each point of the medium. Ultrasound matrix imaging (UMI) consists in decoupling the location of these transmitted and received focal spots. The response between those virtual transducers form the so-called focused reflection matrix that actually contains much more information than a raw ultrasound image. In this paper, a time-frequency analysis of this matrix is performed, which highlights the single and multiple scattering contributions as well as the impact of aberrations in the monochromatic and broadband regimes. Interestingly, this analysis enables the measurement of the incoherent input-output point spread function at any pixel of this image. A focusing criterion can then be built, and its evolution used to quantify the amount of aberration throughout the ultrasound image. In contrast to the standard coherence factor used in the literature, this new indicator is robust to multiple scattering and electronic noise, thereby providing a highly contrasted map of the focusing quality. As a proof-of-concept, UMI is applied here to the in-vivo study of a human calf, but it can be extended to any kind of ultrasound diagnosis or non-destructive evaluation.
Heterogeneous Face Frontalization via Domain Agnostic Learning
Jul 17, 2021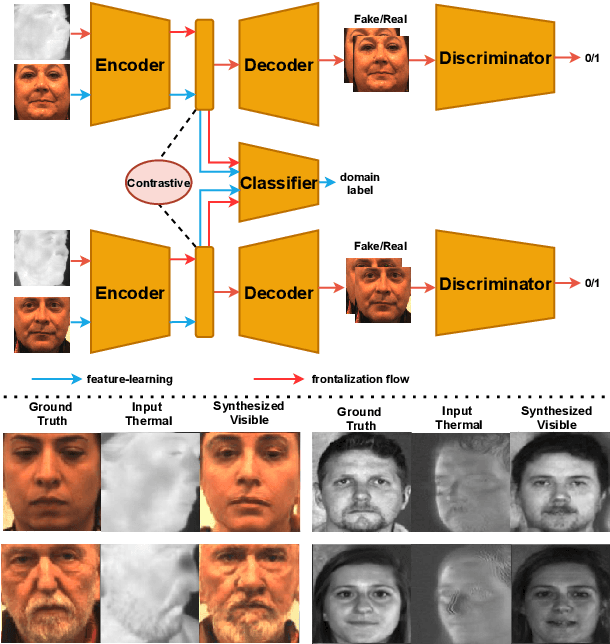
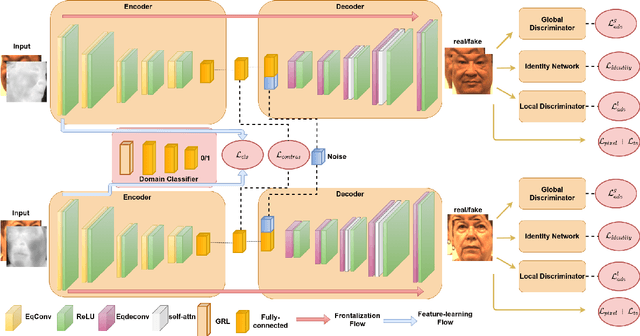
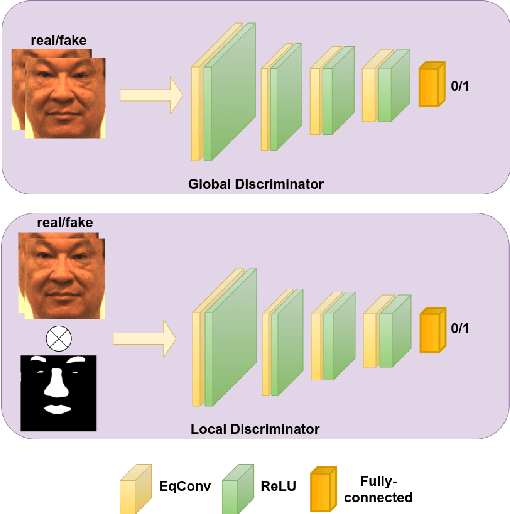
Recent advances in deep convolutional neural networks (DCNNs) have shown impressive performance improvements on thermal to visible face synthesis and matching problems. However, current DCNN-based synthesis models do not perform well on thermal faces with large pose variations. In order to deal with this problem, heterogeneous face frontalization methods are needed in which a model takes a thermal profile face image and generates a frontal visible face. This is an extremely difficult problem due to the large domain as well as large pose discrepancies between the two modalities. Despite its applications in biometrics and surveillance, this problem is relatively unexplored in the literature. We propose a domain agnostic learning-based generative adversarial network (DAL-GAN) which can synthesize frontal views in the visible domain from thermal faces with pose variations. DAL-GAN consists of a generator with an auxiliary classifier and two discriminators which capture both local and global texture discriminations for better synthesis. A contrastive constraint is enforced in the latent space of the generator with the help of a dual-path training strategy, which improves the feature vector discrimination. Finally, a multi-purpose loss function is utilized to guide the network in synthesizing identity preserving cross-domain frontalization. Extensive experimental results demonstrate that DAL-GAN can generate better quality frontal views compared to the other baseline methods.
Flow-based Kernel Prior with Application to Blind Super-Resolution
Mar 29, 2021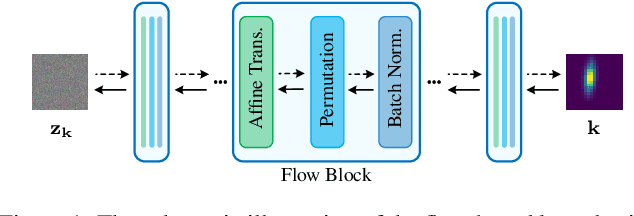

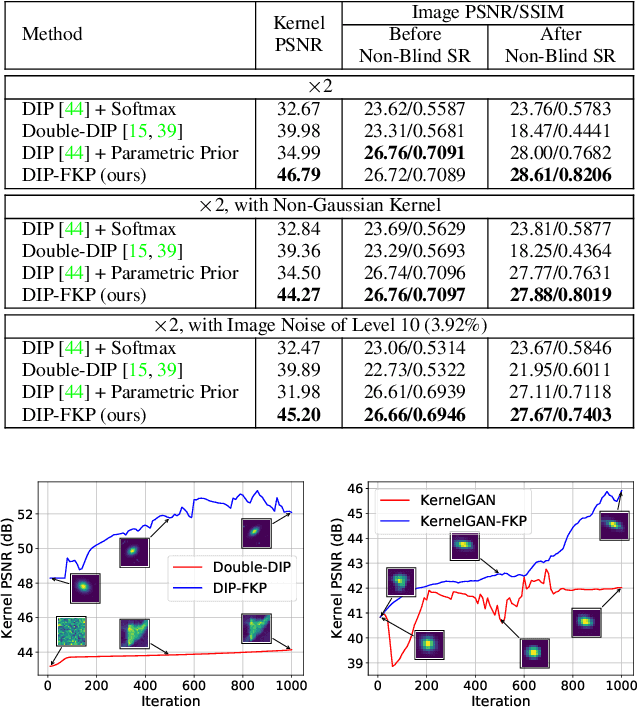
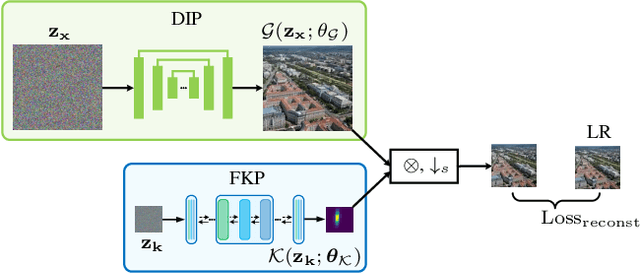
Kernel estimation is generally one of the key problems for blind image super-resolution (SR). Recently, Double-DIP proposes to model the kernel via a network architecture prior, while KernelGAN employs the deep linear network and several regularization losses to constrain the kernel space. However, they fail to fully exploit the general SR kernel assumption that anisotropic Gaussian kernels are sufficient for image SR. To address this issue, this paper proposes a normalizing flow-based kernel prior (FKP) for kernel modeling. By learning an invertible mapping between the anisotropic Gaussian kernel distribution and a tractable latent distribution, FKP can be easily used to replace the kernel modeling modules of Double-DIP and KernelGAN. Specifically, FKP optimizes the kernel in the latent space rather than the network parameter space, which allows it to generate reasonable kernel initialization, traverse the learned kernel manifold and improve the optimization stability. Extensive experiments on synthetic and real-world images demonstrate that the proposed FKP can significantly improve the kernel estimation accuracy with less parameters, runtime and memory usage, leading to state-of-the-art blind SR results.
Aligning Correlation Information for Domain Adaptation in Action Recognition
Jul 11, 2021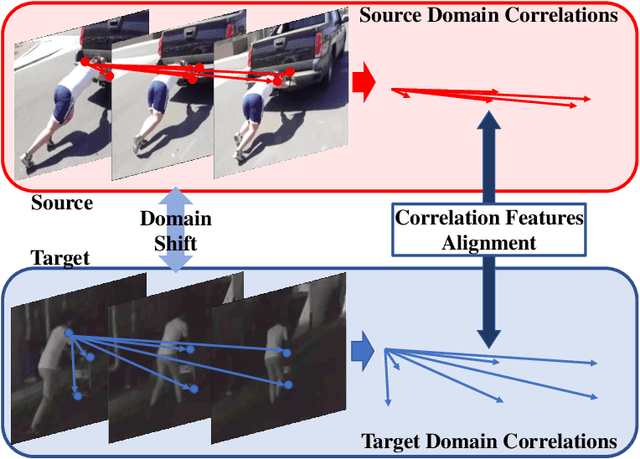
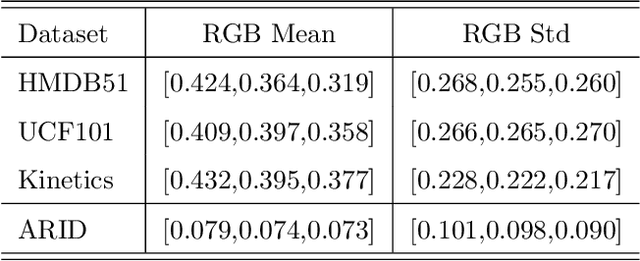
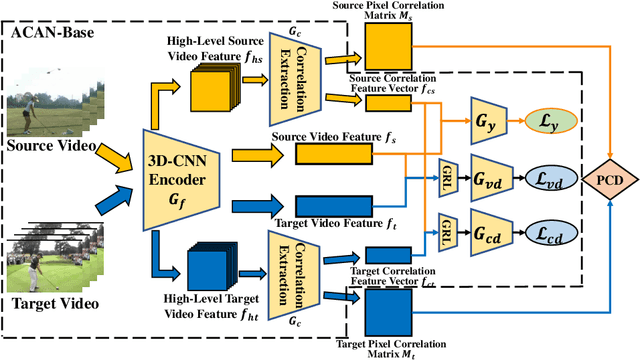

Domain adaptation (DA) approaches address domain shift and enable networks to be applied to different scenarios. Although various image DA approaches have been proposed in recent years, there is limited research towards video DA. This is partly due to the complexity in adapting the different modalities of features in videos, which includes the correlation features extracted as long-term dependencies of pixels across spatiotemporal dimensions. The correlation features are highly associated with action classes and proven their effectiveness in accurate video feature extraction through the supervised action recognition task. Yet correlation features of the same action would differ across domains due to domain shift. Therefore we propose a novel Adversarial Correlation Adaptation Network (ACAN) to align action videos by aligning pixel correlations. ACAN aims to minimize the distribution of correlation information, termed as Pixel Correlation Discrepancy (PCD). Additionally, video DA research is also limited by the lack of cross-domain video datasets with larger domain shifts. We, therefore, introduce a novel HMDB-ARID dataset with a larger domain shift caused by a larger statistical difference between domains. This dataset is built in an effort to leverage current datasets for dark video classification. Empirical results demonstrate the state-of-the-art performance of our proposed ACAN for both existing and the new video DA datasets.
Pay Attention with Focus: A Novel Learning Scheme for Classification of Whole Slide Images
Jun 11, 2021

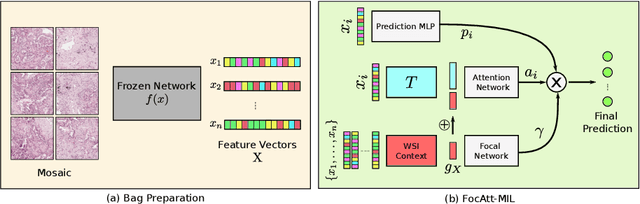
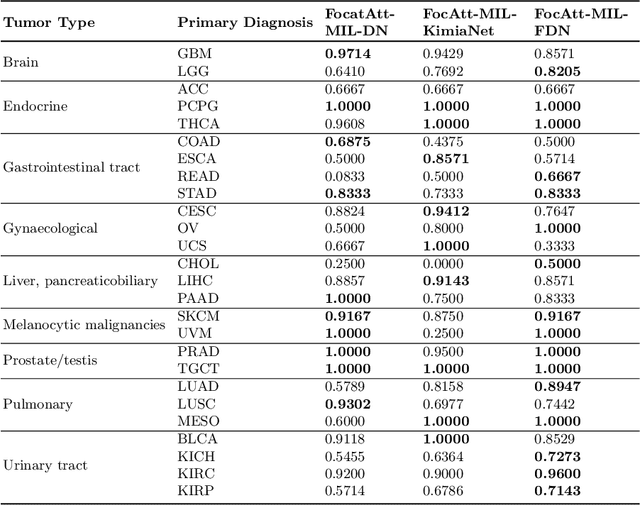
Deep learning methods such as convolutional neural networks (CNNs) are difficult to directly utilize to analyze whole slide images (WSIs) due to the large image dimensions. We overcome this limitation by proposing a novel two-stage approach. First, we extract a set of representative patches (called mosaic) from a WSI. Each patch of a mosaic is encoded to a feature vector using a deep network. The feature extractor model is fine-tuned using hierarchical target labels of WSIs, i.e., anatomic site and primary diagnosis. In the second stage, a set of encoded patch-level features from a WSI is used to compute the primary diagnosis probability through the proposed Pay Attention with Focus scheme, an attention-weighted averaging of predicted probabilities for all patches of a mosaic modulated by a trainable focal factor. Experimental results show that the proposed model can be robust, and effective for the classification of WSIs.
Attention-Based Keyword Localisation in Speech using Visual Grounding
Jun 16, 2021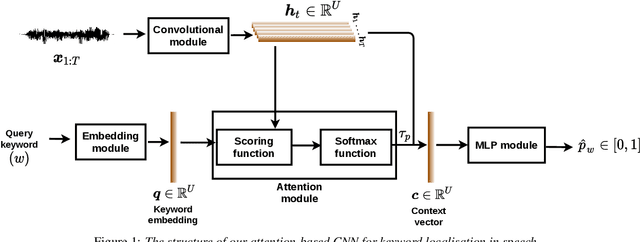
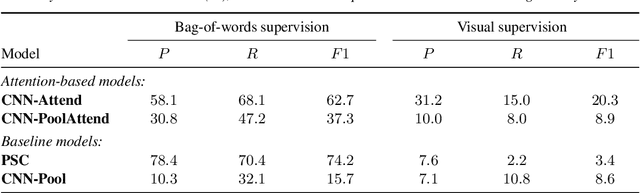
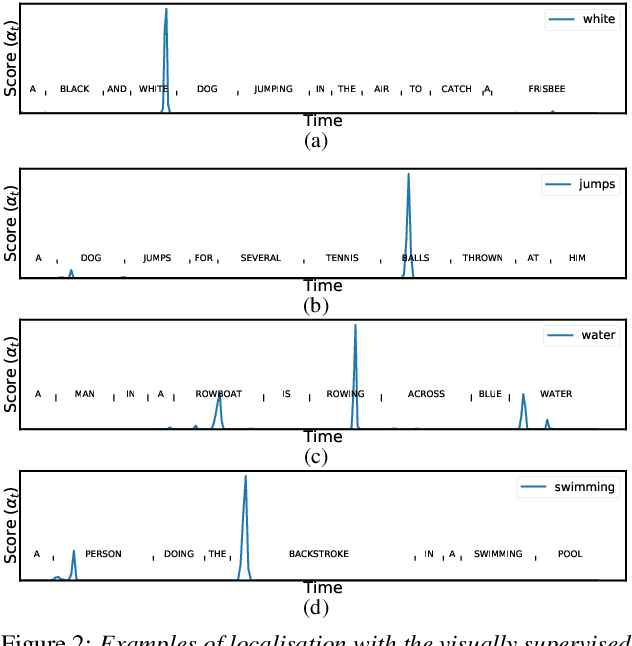
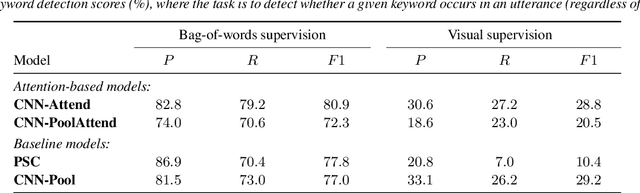
Visually grounded speech models learn from images paired with spoken captions. By tagging images with soft text labels using a trained visual classifier with a fixed vocabulary, previous work has shown that it is possible to train a model that can detect whether a particular text keyword occurs in speech utterances or not. Here we investigate whether visually grounded speech models can also do keyword localisation: predicting where, within an utterance, a given textual keyword occurs without any explicit text-based or alignment supervision. We specifically consider whether incorporating attention into a convolutional model is beneficial for localisation. Although absolute localisation performance with visually supervised models is still modest (compared to using unordered bag-of-word text labels for supervision), we show that attention provides a large gain in performance over previous visually grounded models. As in many other speech-image studies, we find that many of the incorrect localisations are due to semantic confusions, e.g. locating the word 'backstroke' for the query keyword 'swimming'.
Interval type-2 Beta Fuzzy Near set based approach to content based image retrieval
Dec 07, 2018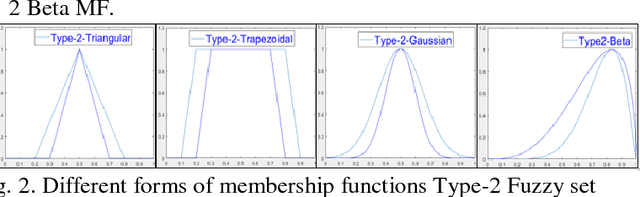
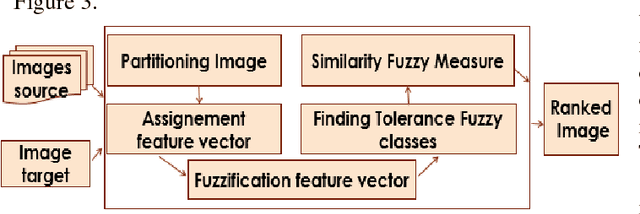

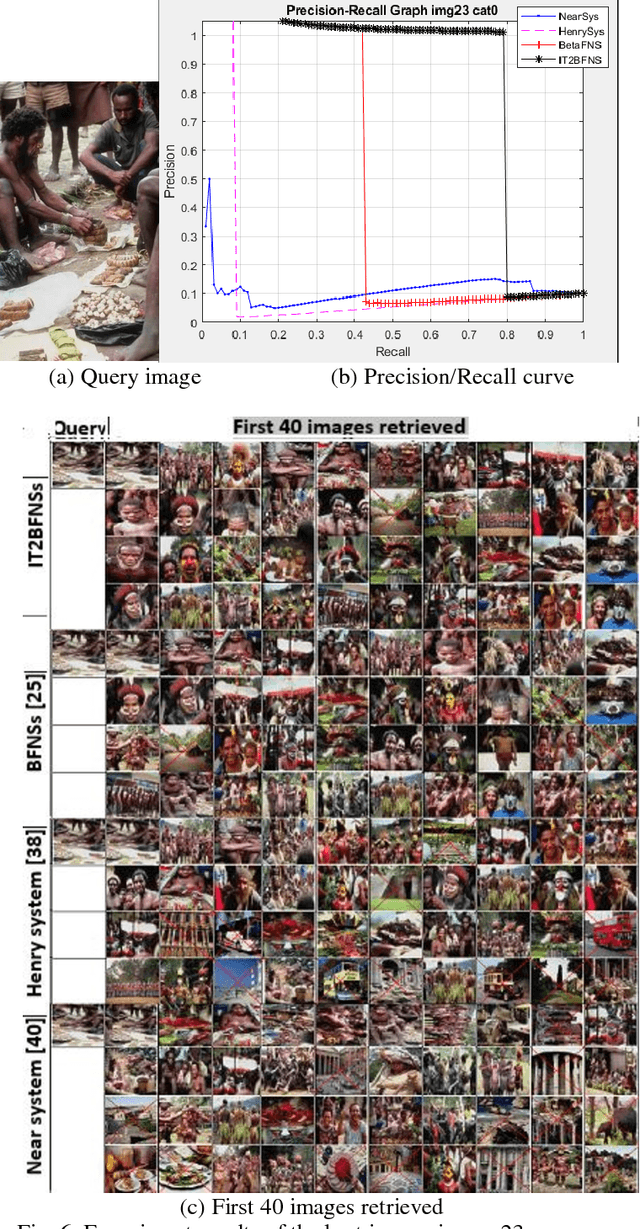
In an automated search system, similarity is a key concept in solving a human task. Indeed, human process is usually a natural categorization that underlies many natural abilities such as image recovery, language comprehension, decision making, or pattern recognition. In the image search axis, there are several ways to measure the similarity between images in an image database, to a query image. Image search by content is based on the similarity of the visual characteristics of the images. The distance function used to evaluate the similarity between images depends on the criteria of the search but also on the representation of the characteristics of the image; this is the main idea of the near and fuzzy sets approaches. In this article, we introduce a new category of beta type-2 fuzzy sets for the description of image characteristics as well as the near sets approach for image recovery. Finally, we illustrate our work with examples of image recovery problems used in the real world.