 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Interval type-2 Beta Fuzzy Near set based approach to content based image retrieval
Dec 07, 2018
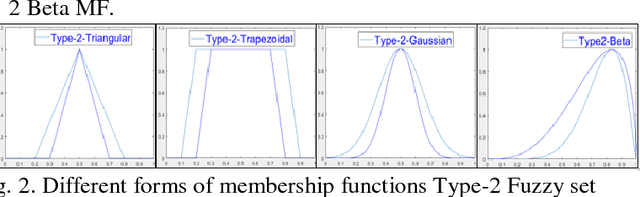
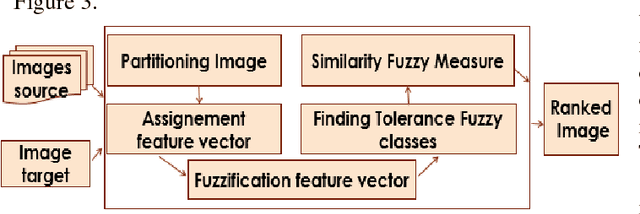

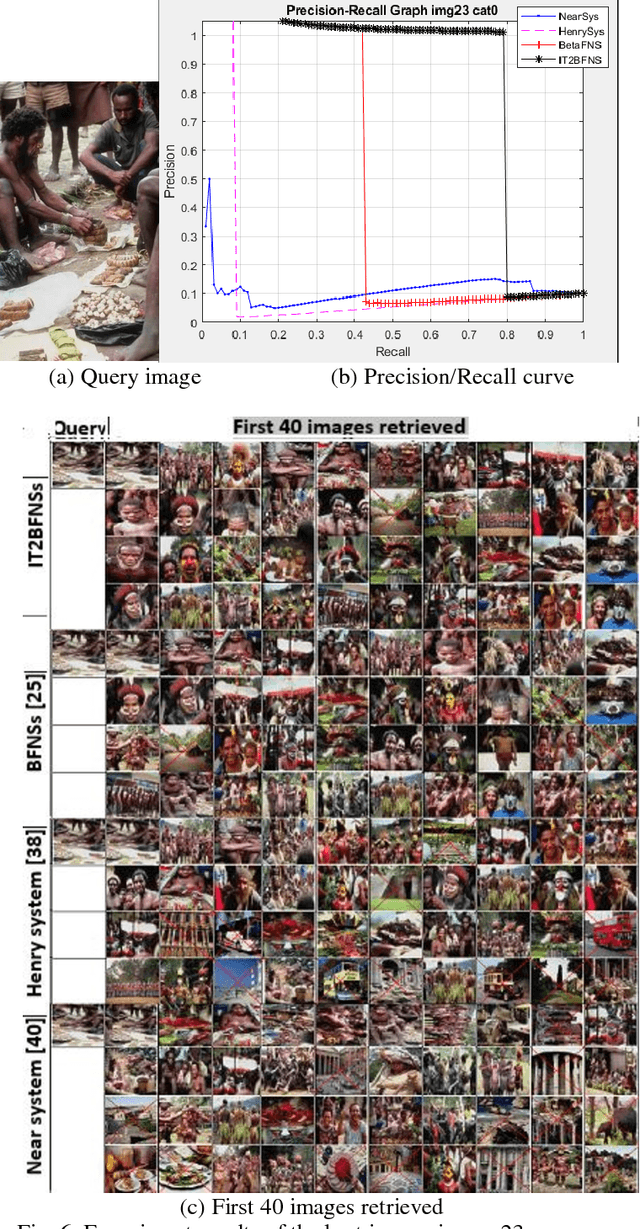
In an automated search system, similarity is a key concept in solving a human task. Indeed, human process is usually a natural categorization that underlies many natural abilities such as image recovery, language comprehension, decision making, or pattern recognition. In the image search axis, there are several ways to measure the similarity between images in an image database, to a query image. Image search by content is based on the similarity of the visual characteristics of the images. The distance function used to evaluate the similarity between images depends on the criteria of the search but also on the representation of the characteristics of the image; this is the main idea of the near and fuzzy sets approaches. In this article, we introduce a new category of beta type-2 fuzzy sets for the description of image characteristics as well as the near sets approach for image recovery. Finally, we illustrate our work with examples of image recovery problems used in the real world.
THUNDR: Transformer-based 3D HUmaN Reconstruction with Markers
Jun 17, 2021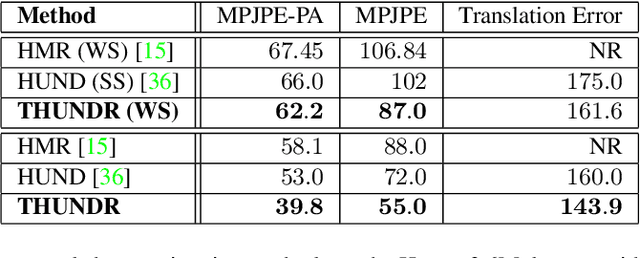
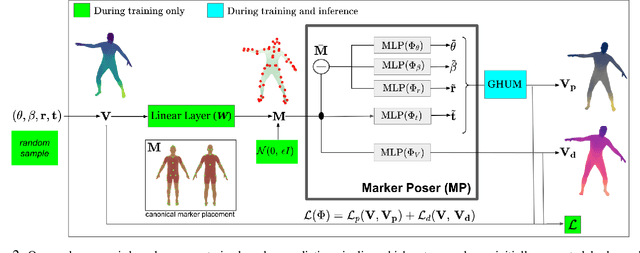
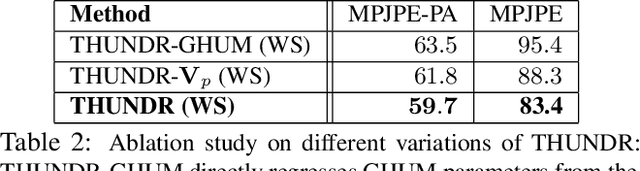
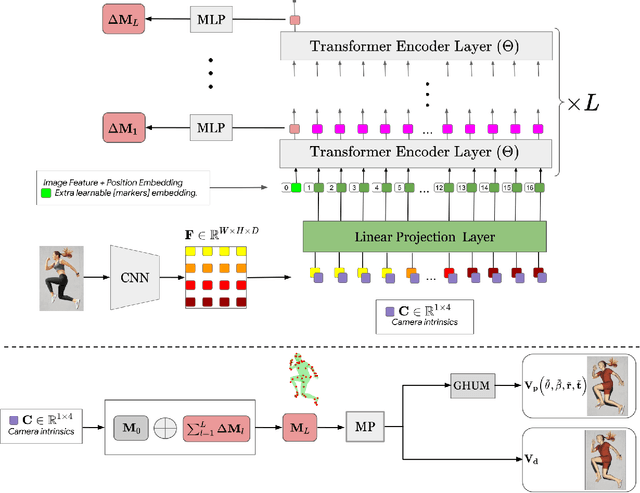
We present THUNDR, a transformer-based deep neural network methodology to reconstruct the 3d pose and shape of people, given monocular RGB images. Key to our methodology is an intermediate 3d marker representation, where we aim to combine the predictive power of model-free-output architectures and the regularizing, anthropometrically-preserving properties of a statistical human surface model like GHUM -- a recently introduced, expressive full body statistical 3d human model, trained end-to-end. Our novel transformer-based prediction pipeline can focus on image regions relevant to the task, supports self-supervised regimes, and ensures that solutions are consistent with human anthropometry. We show state-of-the-art results on Human3.6M and 3DPW, for both the fully-supervised and the self-supervised models, for the task of inferring 3d human shape, joint positions, and global translation. Moreover, we observe very solid 3d reconstruction performance for difficult human poses collected in the wild.
Recovery Analysis for Plug-and-Play Priors using the Restricted Eigenvalue Condition
Jun 07, 2021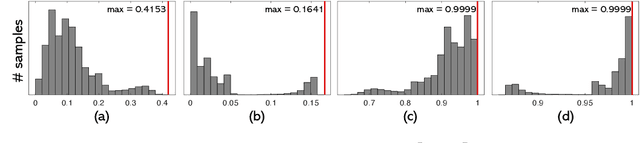
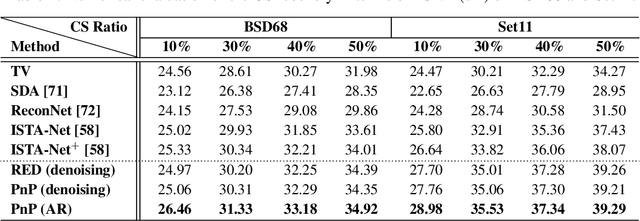
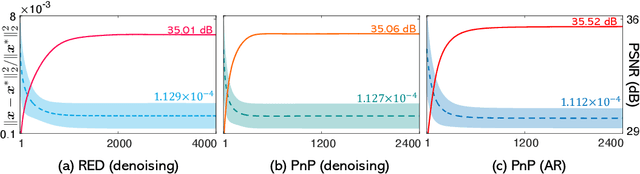
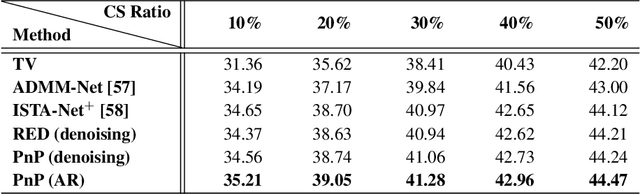
The plug-and-play priors (PnP) and regularization by denoising (RED) methods have become widely used for solving inverse problems by leveraging pre-trained deep denoisers as image priors. While the empirical imaging performance and the theoretical convergence properties of these algorithms have been widely investigated, their recovery properties have not previously been theoretically analyzed. We address this gap by showing how to establish theoretical recovery guarantees for PnP/RED by assuming that the solution of these methods lies near the fixed-points of a deep neural network. We also present numerical results comparing the recovery performance of PnP/RED in compressive sensing against that of recent compressive sensing algorithms based on generative models. Our numerical results suggest that PnP with a pre-trained artifact removal network provides significantly better results compared to the existing state-of-the-art methods.
A Cloud-Edge-Terminal Collaborative System for Temperature Measurement in COVID-19 Prevention
Jul 11, 2021
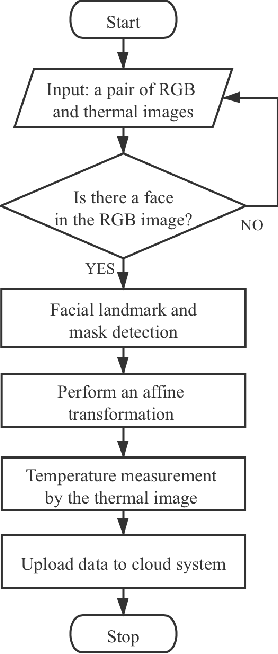
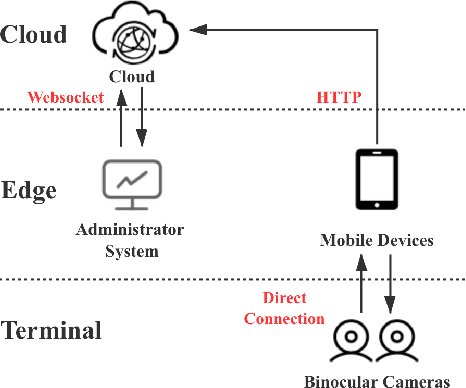

To prevent the spread of coronavirus disease 2019 (COVID-19), preliminary temperature measurement and mask detection in public areas are conducted. However, the existing temperature measurement methods face the problems of safety and deployment. In this paper, to realize safe and accurate temperature measurement even when a person's face is partially obscured, we propose a cloud-edge-terminal collaborative system with a lightweight infrared temperature measurement model. A binocular camera with an RGB lens and a thermal lens is utilized to simultaneously capture image pairs. Then, a mobile detection model based on a multi-task cascaded convolutional network (MTCNN) is proposed to realize face alignment and mask detection on the RGB images. For accurate temperature measurement, we transform the facial landmarks on the RGB images to the thermal images by an affine transformation and select a more accurate temperature measurement area on the forehead. The collected information is uploaded to the cloud in real time for COVID-19 prevention. Experiments show that the detection model is only 6.1M and the average detection speed is 257ms. At a distance of 1m, the error of indoor temperature measurement is about 3%. That is, the proposed system can realize real-time temperature measurement in public areas.
ID-Unet: Iterative Soft and Hard Deformation for View Synthesis
Mar 03, 2021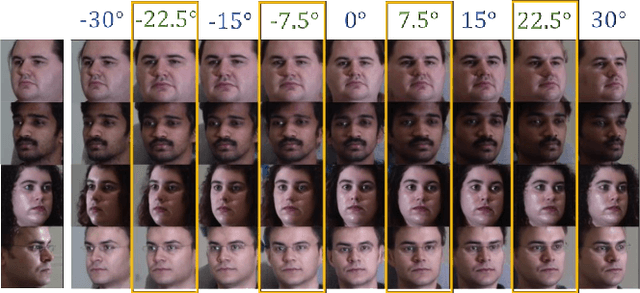
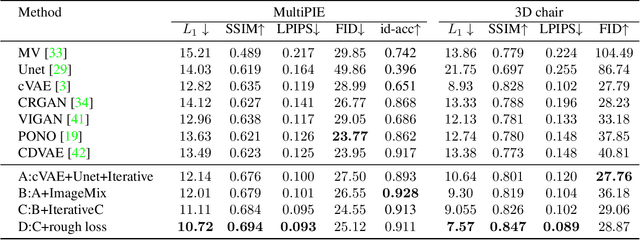
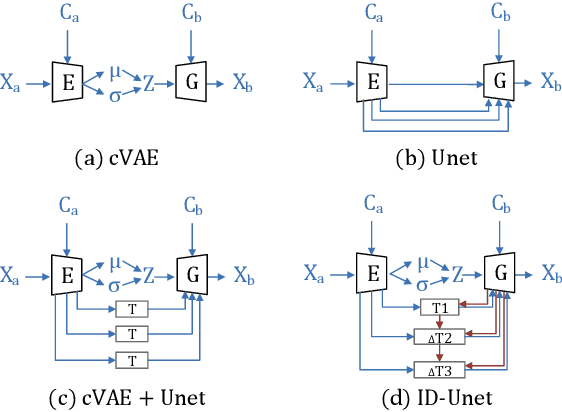
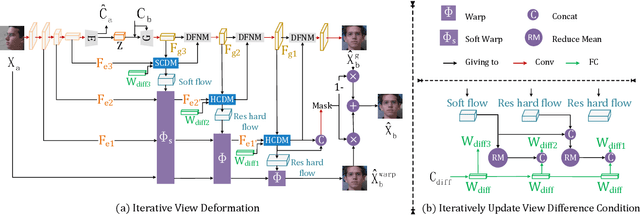
View synthesis is usually done by an autoencoder, in which the encoder maps a source view image into a latent content code, and the decoder transforms it into a target view image according to the condition. However, the source contents are often not well kept in this setting, which leads to unnecessary changes during the view translation. Although adding skipped connections, like Unet, alleviates the problem, but it often causes the failure on the view conformity. This paper proposes a new architecture by performing the source-to-target deformation in an iterative way. Instead of simply incorporating the features from multiple layers of the encoder, we design soft and hard deformation modules, which warp the encoder features to the target view at different resolutions, and give results to the decoder to complement the details. Particularly, the current warping flow is not only used to align the feature of the same resolution, but also as an approximation to coarsely deform the high resolution feature. Then the residual flow is estimated and applied in the high resolution, so that the deformation is built up in the coarse-to-fine fashion. To better constrain the model, we synthesize a rough target view image based on the intermediate flows and their warped features. The extensive ablation studies and the final results on two different data sets show the effectiveness of the proposed model.
Integrating Novelty Detection Capabilities with MSL Mastcam Operations to Enhance Data Analysis
Mar 23, 2021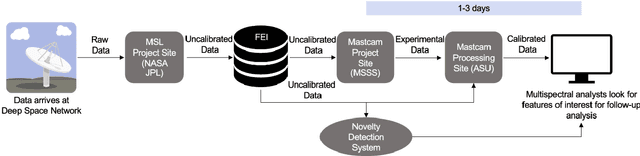



While innovations in scientific instrumentation have pushed the boundaries of Mars rover mission capabilities, the increase in data complexity has pressured Mars Science Laboratory (MSL) and future Mars rover operations staff to quickly analyze complex data sets to meet progressively shorter tactical and strategic planning timelines. MSLWEB is an internal data tracking tool used by operations staff to perform first pass analysis on MSL image sequences, a series of products taken by the Mast camera, Mastcam. Mastcam's multiband multispectral image sequences require more complex analysis compared to standard 3-band RGB images. Typically, these are analyzed using traditional methods to identify unique features within the sequence. Given the short time frame of tactical planning in which downlinked images might need to be analyzed (within 5-10 hours before the next uplink), there exists a need to triage analysis time to focus on the most important sequences and parts of a sequence. We address this need by creating products for MSLWEB that use novelty detection to help operations staff identify unusual data that might be diagnostic of new or atypical compositions or mineralogies detected within an imaging scene. This was achieved in two ways: 1) by creating products for each sequence to identify novel regions in the image, and 2) by assigning multispectral sequences a sortable novelty score. These new products provide colorized heat maps of inferred novelty that operations staff can use to rapidly review downlinked data and focus their efforts on analyzing potentially new kinds of diagnostic multispectral signatures. This approach has the potential to guide scientists to new discoveries by quickly drawing their attention to often subtle variations not detectable with simple color composites.
Skeleton Image Representation for 3D Action Recognition based on Tree Structure and Reference Joints
Sep 11, 2019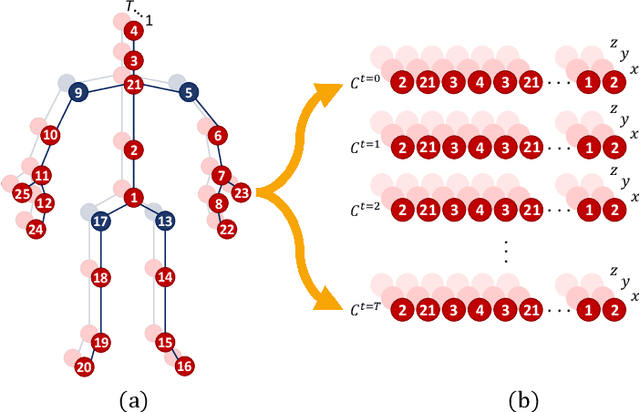
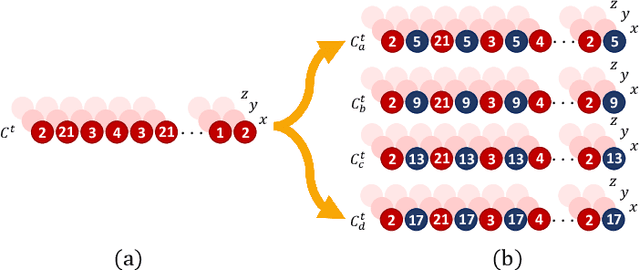
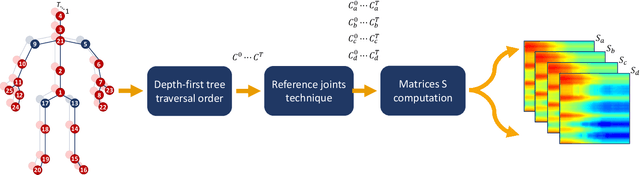
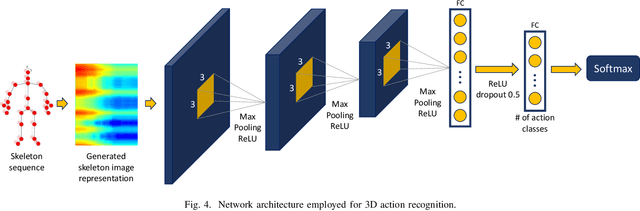
In the last years, the computer vision research community has studied on how to model temporal dynamics in videos to employ 3D human action recognition. To that end, two main baseline approaches have been researched: (i) Recurrent Neural Networks (RNNs) with Long-Short Term Memory (LSTM); and (ii) skeleton image representations used as input to a Convolutional Neural Network (CNN). Although RNN approaches present excellent results, such methods lack the ability to efficiently learn the spatial relations between the skeleton joints. On the other hand, the representations used to feed CNN approaches present the advantage of having the natural ability of learning structural information from 2D arrays (i.e., they learn spatial relations from the skeleton joints). To further improve such representations, we introduce the Tree Structure Reference Joints Image (TSRJI), a novel skeleton image representation to be used as input to CNNs. The proposed representation has the advantage of combining the use of reference joints and a tree structure skeleton. While the former incorporates different spatial relationships between the joints, the latter preserves important spatial relations by traversing a skeleton tree with a depth-first order algorithm. Experimental results demonstrate the effectiveness of the proposed representation for 3D action recognition on two datasets achieving state-of-the-art results on the recent NTU RGB+D~120 dataset.
Self-supervised Change Detection in Multi-view Remote Sensing Images
Mar 10, 2021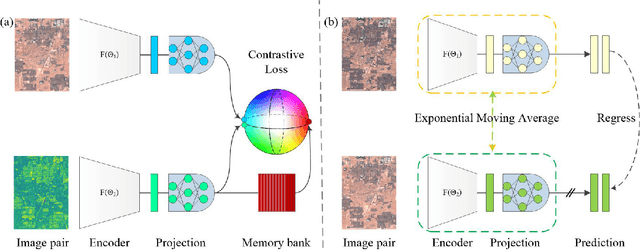
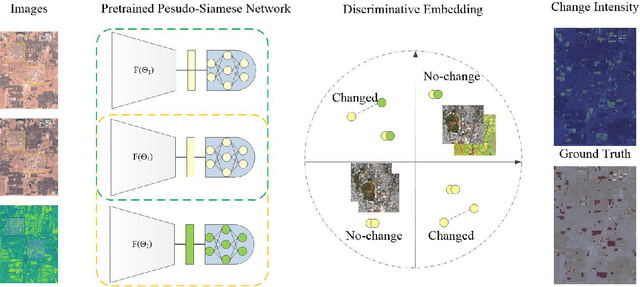
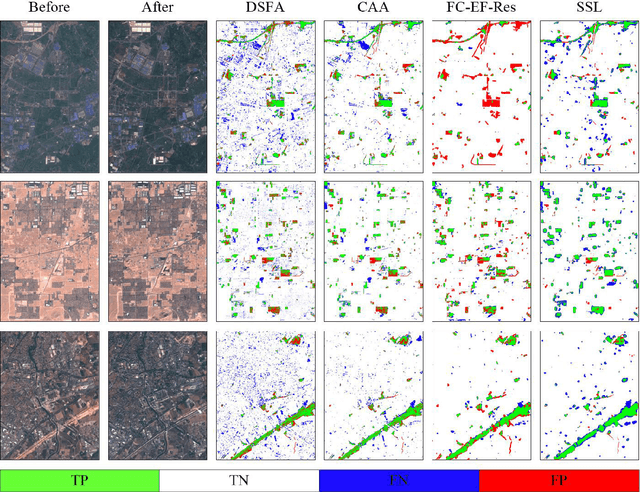
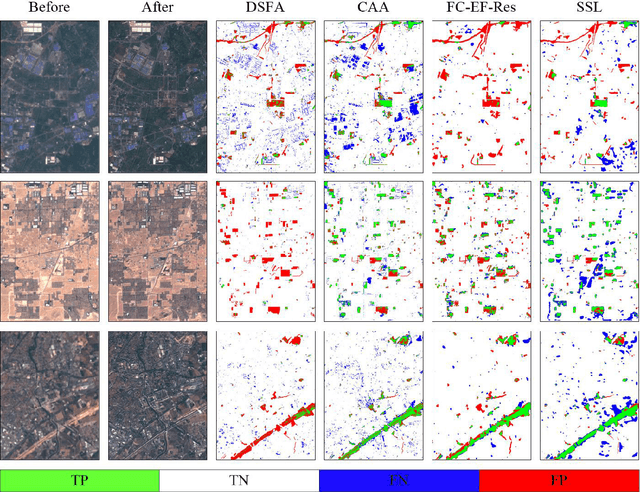
The vast amount of unlabeled multi-temporal and multi-sensor remote sensing data acquired by the many Earth Observation satellites present a challenge for change detection. Recently, many generative model-based methods have been proposed for remote sensing image change detection on such unlabeled data. However, the high diversities in the learned features weaken the discrimination of the relevant change indicators in unsupervised change detection tasks. Moreover, these methods lack research on massive archived images. In this work, a self-supervised change detection approach based on an unlabeled multi-view setting is proposed to overcome this limitation. This is achieved by the use of a multi-view contrastive loss and an implicit contrastive strategy in the feature alignment between multi-view images. In this approach, a pseudo-Siamese network is trained to regress the output between its two branches pre-trained in a contrastive way on a large dataset of multi-temporal homogeneous or heterogeneous image patches. Finally, the feature distance between the outputs of the two branches is used to define a change measure, which can be analyzed by thresholding to get the final binary change map. Experiments are carried out on five homogeneous and heterogeneous remote sensing image datasets. The proposed SSL approach is compared with other supervised and unsupervised state-of-the-art change detection methods. Results demonstrate both improvements over state-of-the-art unsupervised methods and that the proposed SSL approach narrows the gap between unsupervised and supervised change detection.
RGB Matters: Learning 7-DoF Grasp Poses on Monocular RGBD Images
Mar 03, 2021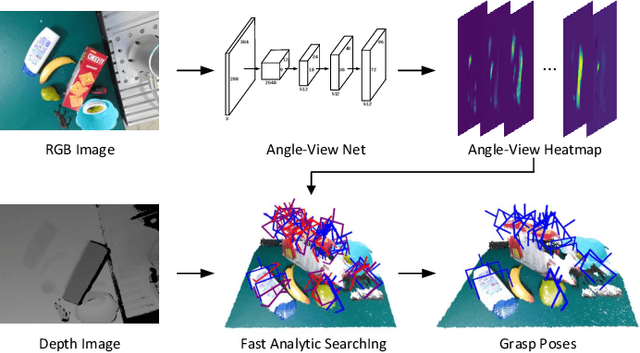
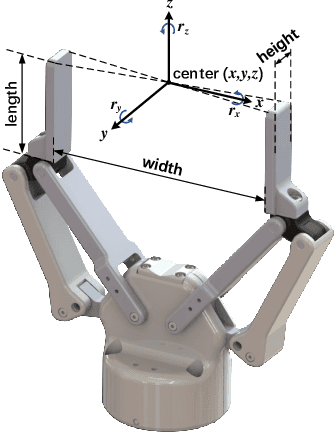
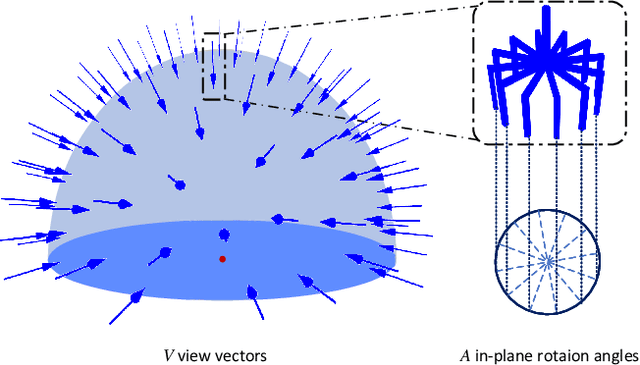
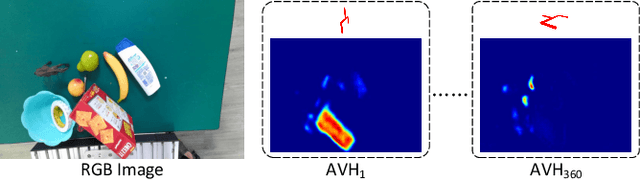
General object grasping is an important yet unsolved problem in the field of robotics. Most of the current methods either generate grasp poses with few DoF that fail to cover most of the success grasps, or only take the unstable depth image or point cloud as input which may lead to poor results in some cases. In this paper, we propose RGBD-Grasp, a pipeline that solves this problem by decoupling 7-DoF grasp detection into two sub-tasks where RGB and depth information are processed separately. In the first stage, an encoder-decoder like convolutional neural network Angle-View Net(AVN) is proposed to predict the SO(3) orientation of the gripper at every location of the image. Consequently, a Fast Analytic Searching(FAS) module calculates the opening width and the distance of the gripper to the grasp point. By decoupling the grasp detection problem and introducing the stable RGB modality, our pipeline alleviates the requirement for the high-quality depth image and is robust to depth sensor noise. We achieve state-of-the-art results on GraspNet-1Billion dataset compared with several baselines. Real robot experiments on a UR5 robot with an Intel Realsense camera and a Robotiq two-finger gripper show high success rates for both single object scenes and cluttered scenes. Our code and trained model will be made publicly available.
An Uncertainty-Aware Deep Learning Framework for Defect Detection in Casting Products
Jul 24, 2021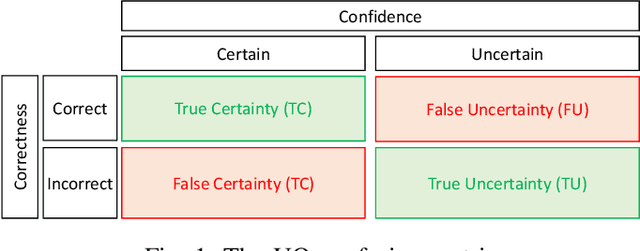
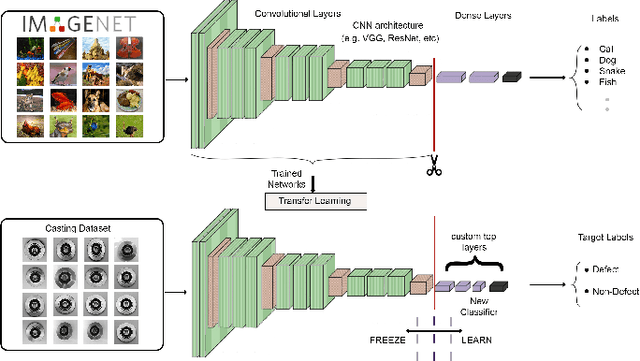
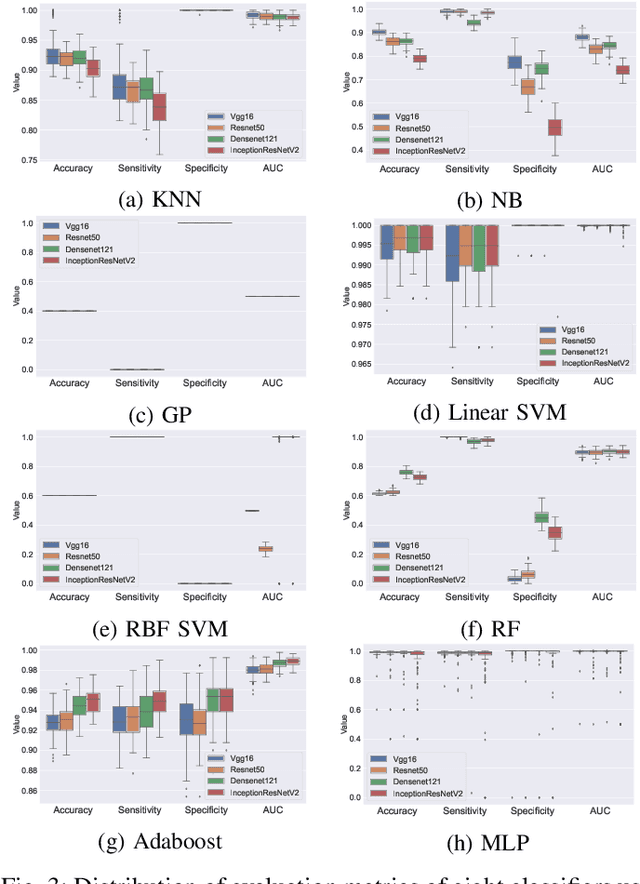
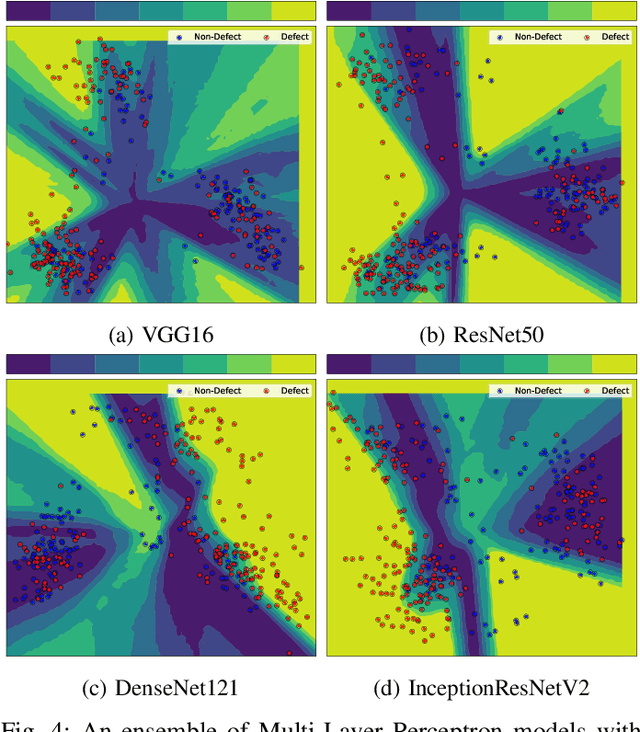
Defects are unavoidable in casting production owing to the complexity of the casting process. While conventional human-visual inspection of casting products is slow and unproductive in mass productions, an automatic and reliable defect detection not just enhances the quality control process but positively improves productivity. However, casting defect detection is a challenging task due to diversity and variation in defects' appearance. Convolutional neural networks (CNNs) have been widely applied in both image classification and defect detection tasks. Howbeit, CNNs with frequentist inference require a massive amount of data to train on and still fall short in reporting beneficial estimates of their predictive uncertainty. Accordingly, leveraging the transfer learning paradigm, we first apply four powerful CNN-based models (VGG16, ResNet50, DenseNet121, and InceptionResNetV2) on a small dataset to extract meaningful features. Extracted features are then processed by various machine learning algorithms to perform the classification task. Simulation results demonstrate that linear support vector machine (SVM) and multi-layer perceptron (MLP) show the finest performance in defect detection of casting images. Secondly, to achieve a reliable classification and to measure epistemic uncertainty, we employ an uncertainty quantification (UQ) technique (ensemble of MLP models) using features extracted from four pre-trained CNNs. UQ confusion matrix and uncertainty accuracy metric are also utilized to evaluate the predictive uncertainty estimates. Comprehensive comparisons reveal that UQ method based on VGG16 outperforms others to fetch uncertainty. We believe an uncertainty-aware automatic defect detection solution will reinforce casting productions quality assurance.