 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Object Networks: Image Generation with Disentangled 3D Representation
Dec 06, 2018
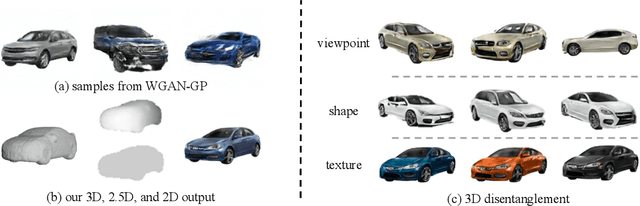
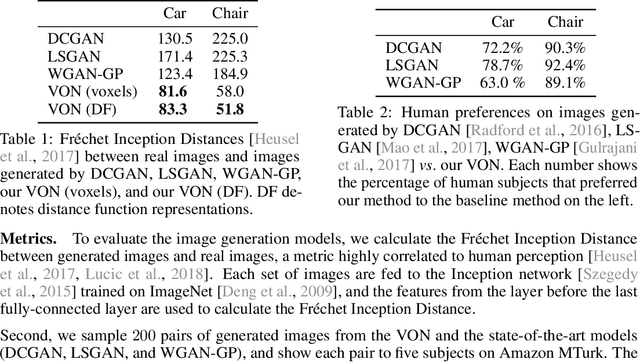
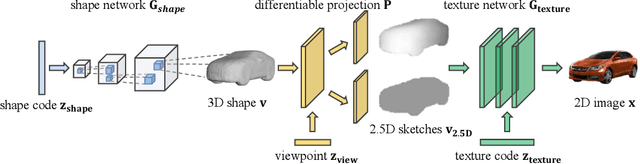

Recent progress in deep generative models has led to tremendous breakthroughs in image generation. However, while existing models can synthesize photorealistic images, they lack an understanding of our underlying 3D world. We present a new generative model, Visual Object Networks (VON), synthesizing natural images of objects with a disentangled 3D representation. Inspired by classic graphics rendering pipelines, we unravel our image formation process into three conditionally independent factors---shape, viewpoint, and texture---and present an end-to-end adversarial learning framework that jointly models 3D shapes and 2D images. Our model first learns to synthesize 3D shapes that are indistinguishable from real shapes. It then renders the object's 2.5D sketches (i.e., silhouette and depth map) from its shape under a sampled viewpoint. Finally, it learns to add realistic texture to these 2.5D sketches to generate natural images. The VON not only generates images that are more realistic than state-of-the-art 2D image synthesis methods, but also enables many 3D operations such as changing the viewpoint of a generated image, editing of shape and texture, linear interpolation in texture and shape space, and transferring appearance across different objects and viewpoints.
Indices Matter: Learning to Index for Deep Image Matting
Aug 02, 2019
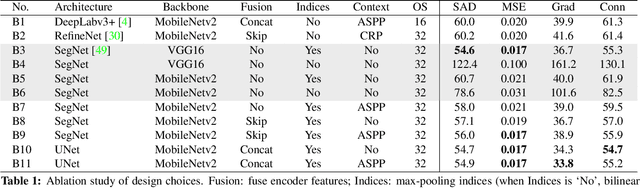
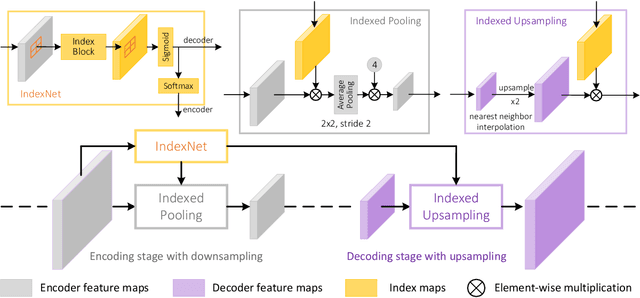
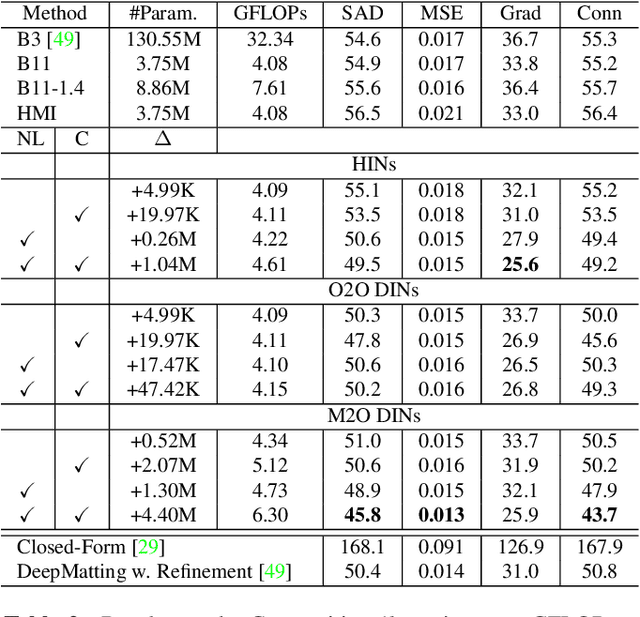
We show that existing upsampling operators can be unified with the notion of the index function. This notion is inspired by an observation in the decoding process of deep image matting where indices-guided unpooling can recover boundary details much better than other upsampling operators such as bilinear interpolation. By looking at the indices as a function of the feature map, we introduce the concept of learning to index, and present a novel index-guided encoder-decoder framework where indices are self-learned adaptively from data and are used to guide the pooling and upsampling operators, without the need of supervision. At the core of this framework is a flexible network module, termed IndexNet, which dynamically predicts indices given an input. Due to its flexibility, IndexNet can be used as a plug-in applying to any off-the-shelf convolutional networks that have coupled downsampling and upsampling stages. We demonstrate the effectiveness of IndexNet on the task of natural image matting where the quality of learned indices can be visually observed from predicted alpha mattes. Results on the Composition-1k matting dataset show that our model built on MobileNetv2 exhibits at least $16.1\%$ improvement over the seminal VGG-16 based deep matting baseline, with less training data and lower model capacity. Code and models has been made available at: https://tinyurl.com/IndexNetV1
A Game-Theoretic Taxonomy of Visual Concepts in DNNs
Jun 21, 2021
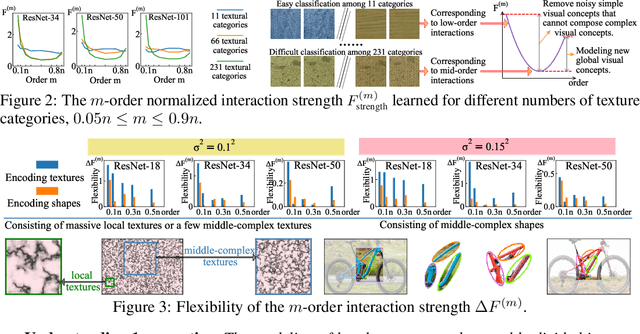
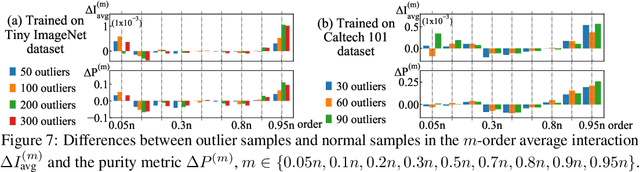
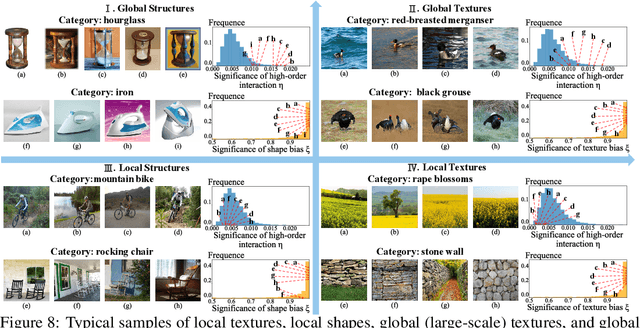
In this paper, we rethink how a DNN encodes visual concepts of different complexities from a new perspective, i.e. the game-theoretic multi-order interactions between pixels in an image. Beyond the categorical taxonomy of objects and the cognitive taxonomy of textures and shapes, we provide a new taxonomy of visual concepts, which helps us interpret the encoding of shapes and textures, in terms of concept complexities. In this way, based on multi-order interactions, we find three distinctive signal-processing behaviors of DNNs encoding textures. Besides, we also discover the flexibility for a DNN to encode shapes is lower than the flexibility of encoding textures. Furthermore, we analyze how DNNs encode outlier samples, and explore the impacts of network architectures on interactions. Additionally, we clarify the crucial role of the multi-order interactions in real-world applications. The code will be released when the paper is accepted.
Learning High Fidelity Depths of Dressed Humans by Watching Social Media Dance Videos
Mar 04, 2021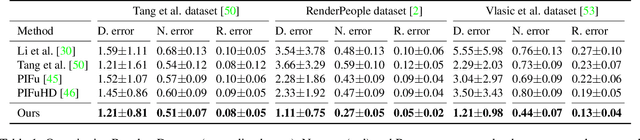
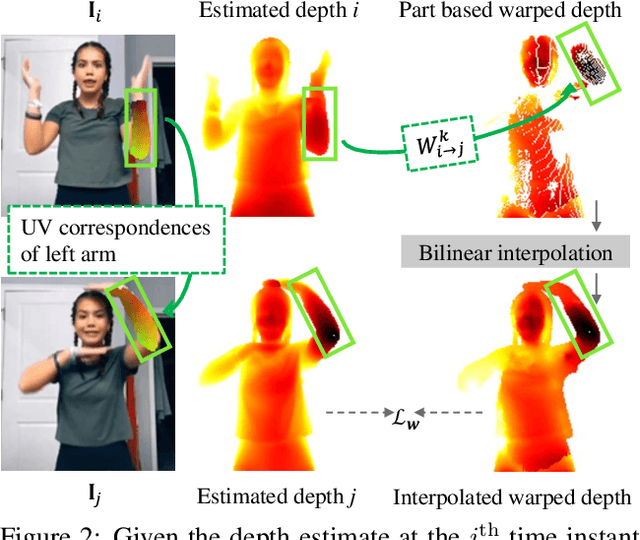

A key challenge of learning the geometry of dressed humans lies in the limited availability of the ground truth data (e.g., 3D scanned models), which results in the performance degradation of 3D human reconstruction when applying to real-world imagery. We address this challenge by leveraging a new data resource: a number of social media dance videos that span diverse appearance, clothing styles, performances, and identities. Each video depicts dynamic movements of the body and clothes of a single person while lacking the 3D ground truth geometry. To utilize these videos, we present a new method to use the local transformation that warps the predicted local geometry of the person from an image to that of another image at a different time instant. This allows self-supervision as enforcing a temporal coherence over the predictions. In addition, we jointly learn the depth along with the surface normals that are highly responsive to local texture, wrinkle, and shade by maximizing their geometric consistency. Our method is end-to-end trainable, resulting in high fidelity depth estimation that predicts fine geometry faithful to the input real image. We demonstrate that our method outperforms the state-of-the-art human depth estimation and human shape recovery approaches on both real and rendered images.
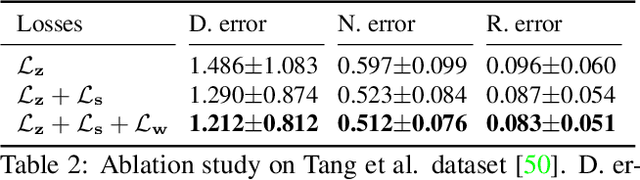
Uniformity in Heterogeneity:Diving Deep into Count Interval Partition for Crowd Counting
Jul 27, 2021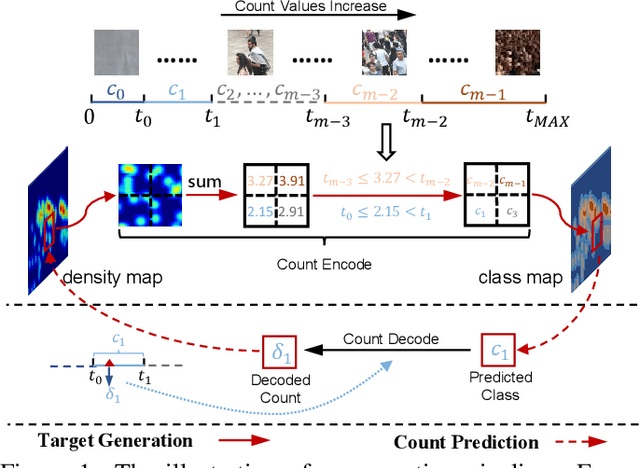
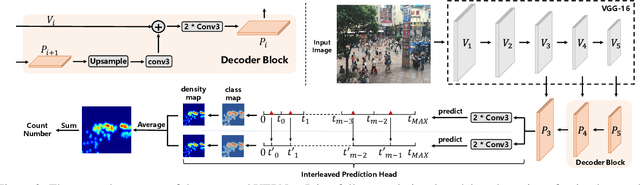
Recently, the problem of inaccurate learning targets in crowd counting draws increasing attention. Inspired by a few pioneering work, we solve this problem by trying to predict the indices of pre-defined interval bins of counts instead of the count values themselves. However, an inappropriate interval setting might make the count error contributions from different intervals extremely imbalanced, leading to inferior counting performance. Therefore, we propose a novel count interval partition criterion called Uniform Error Partition (UEP), which always keeps the expected counting error contributions equal for all intervals to minimize the prediction risk. Then to mitigate the inevitably introduced discretization errors in the count quantization process, we propose another criterion called Mean Count Proxies (MCP). The MCP criterion selects the best count proxy for each interval to represent its count value during inference, making the overall expected discretization error of an image nearly negligible. As far as we are aware, this work is the first to delve into such a classification task and ends up with a promising solution for count interval partition. Following the above two theoretically demonstrated criterions, we propose a simple yet effective model termed Uniform Error Partition Network (UEPNet), which achieves state-of-the-art performance on several challenging datasets. The codes will be available at: https://github.com/TencentYoutuResearch/CrowdCounting-UEPNet.
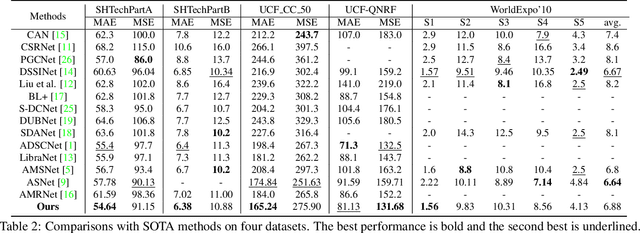
Shallow Attention Network for Polyp Segmentation
Aug 02, 2021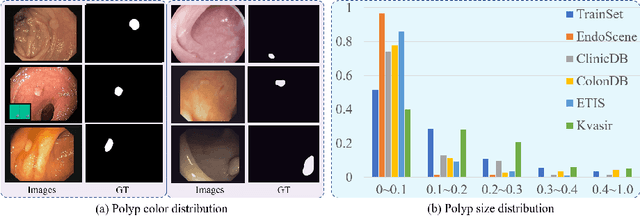
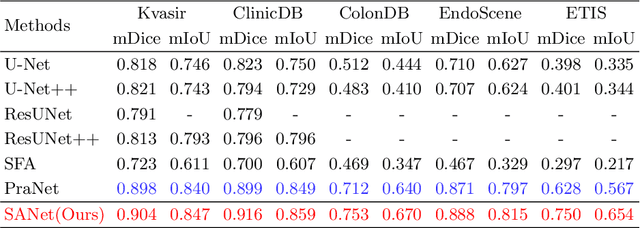
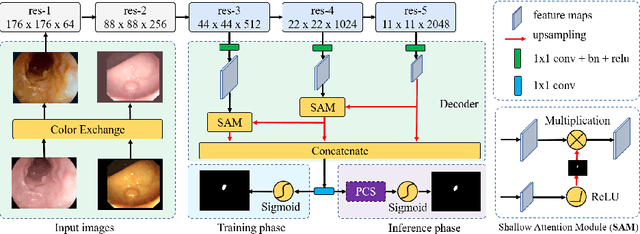
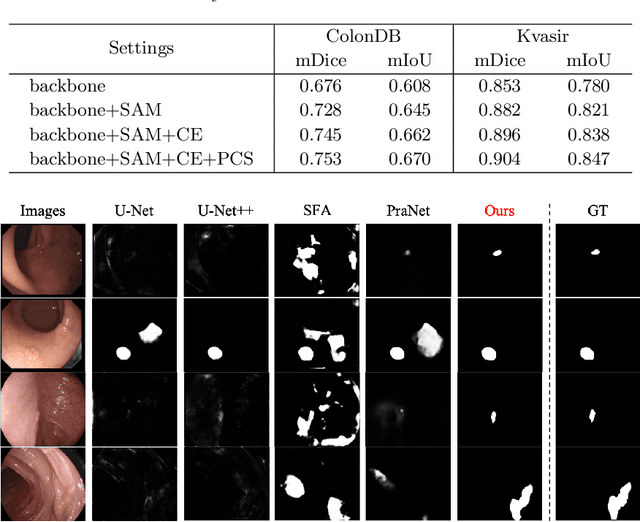
Accurate polyp segmentation is of great importance for colorectal cancer diagnosis. However, even with a powerful deep neural network, there still exists three big challenges that impede the development of polyp segmentation. (i) Samples collected under different conditions show inconsistent colors, causing the feature distribution gap and overfitting issue; (ii) Due to repeated feature downsampling, small polyps are easily degraded; (iii) Foreground and background pixels are imbalanced, leading to a biased training. To address the above issues, we propose the Shallow Attention Network (SANet) for polyp segmentation. Specifically, to eliminate the effects of color, we design the color exchange operation to decouple the image contents and colors, and force the model to focus more on the target shape and structure. Furthermore, to enhance the segmentation quality of small polyps, we propose the shallow attention module to filter out the background noise of shallow features. Thanks to the high resolution of shallow features, small polyps can be preserved correctly. In addition, to ease the severe pixel imbalance for small polyps, we propose a probability correction strategy (PCS) during the inference phase. Note that even though PCS is not involved in the training phase, it can still work well on a biased model and consistently improve the segmentation performance. Quantitative and qualitative experimental results on five challenging benchmarks confirm that our proposed SANet outperforms previous state-of-the-art methods by a large margin and achieves a speed about 72FPS.
Beyond Product Quantization: Deep Progressive Quantization for Image Retrieval
Jul 15, 2019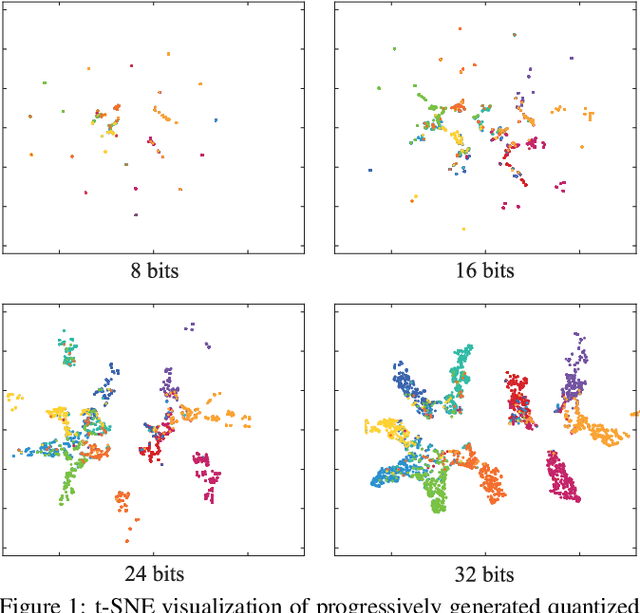
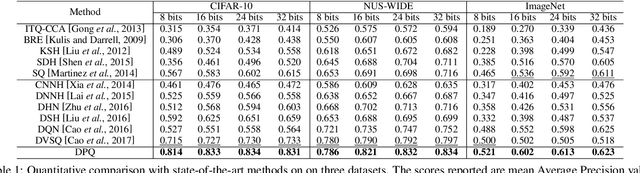
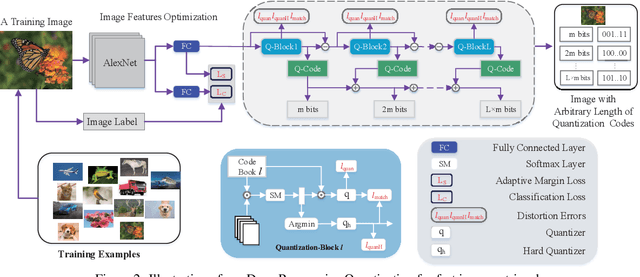

Product Quantization (PQ) has long been a mainstream for generating an exponentially large codebook at very low memory/time cost. Despite its success, PQ is still tricky for the decomposition of high-dimensional vector space, and the retraining of model is usually unavoidable when the code length changes. In this work, we propose a deep progressive quantization (DPQ) model, as an alternative to PQ, for large scale image retrieval. DPQ learns the quantization codes sequentially and approximates the original feature space progressively. Therefore, we can train the quantization codes with different code lengths simultaneously. Specifically, we first utilize the label information for guiding the learning of visual features, and then apply several quantization blocks to progressively approach the visual features. Each quantization block is designed to be a layer of a convolutional neural network, and the whole framework can be trained in an end-to-end manner. Experimental results on the benchmark datasets show that our model significantly outperforms the state-of-the-art for image retrieval. Our model is trained once for different code lengths and therefore requires less computation time. Additional ablation study demonstrates the effect of each component of our proposed model. Our code is released at https://github.com/cfm-uestc/DPQ.
A Comprehensive Review for Breast Histopathology Image Analysis Using Classical and Deep Neural Networks
Mar 27, 2020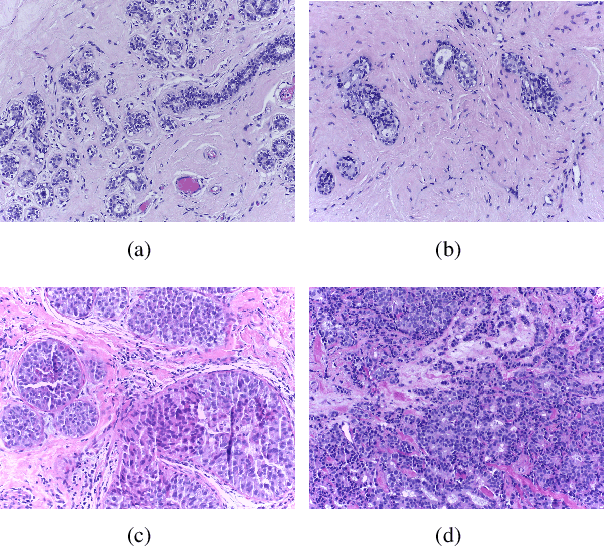
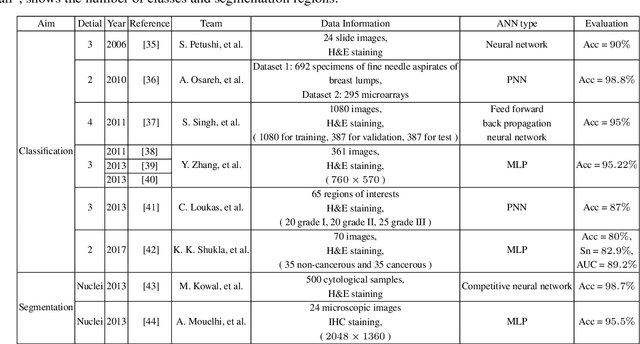
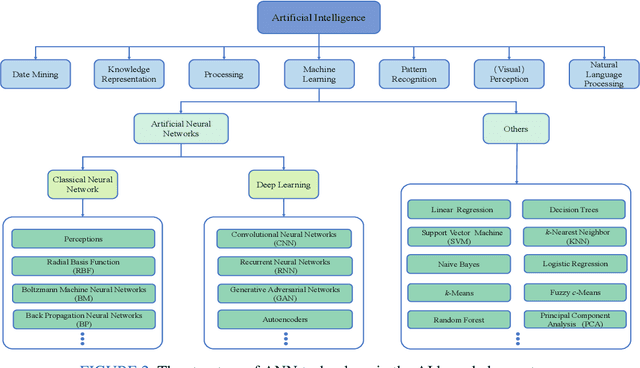
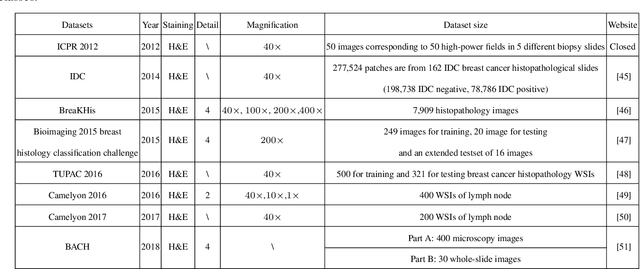
Breast cancer is one of the most common and deadliest cancers among women. Since histopathological images contain sufficient phenotypic information, they play an indispensable role in the diagnosis and treatment of breast cancers. To improve the accuracy and objectivity of Breast Histopathological Image Analysis (BHIA), Artificial Neural Network (ANN) approaches are widely used in the segmentation and classification tasks of breast histopathological images. In this review, we present a comprehensive overview of the BHIA techniques based on ANNs. First of all, we categorize the BHIA systems into classical and deep neural networks for in-depth investigation. Then, the relevant studies based on BHIA systems are presented. After that, we analyze the existing models to discover the most suitable algorithms. Finally, publicly accessible datasets, along with their download links, are provided for the convenience of future researchers.
Combining Spiking Neural Network and Artificial Neural Network for Enhanced Image Classification
Feb 21, 2021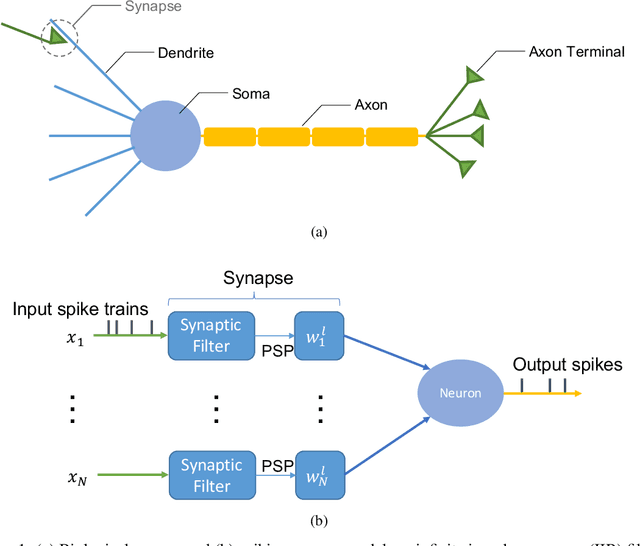
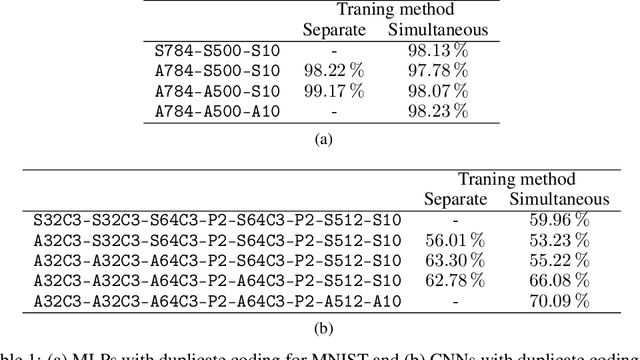
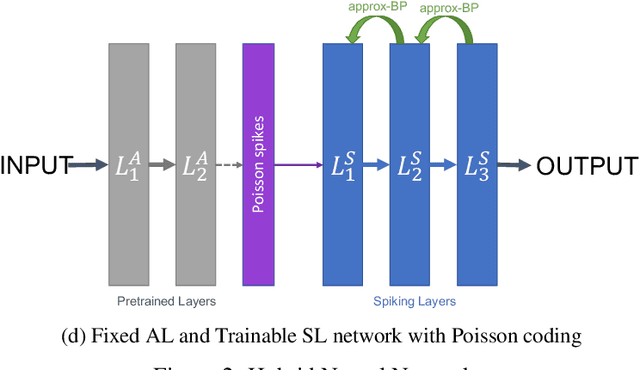

With the continued innovations of deep neural networks, spiking neural networks (SNNs) that more closely resemble biological brain synapses have attracted attention owing to their low power consumption. However, for continuous data values, they must employ a coding process to convert the values to spike trains. Thus, they have not yet exceeded the performance of artificial neural networks (ANNs), which handle such values directly. To this end, we combine an ANN and an SNN to build versatile hybrid neural networks (HNNs) that improve the concerned performance.
Does deep machine vision have just noticeable difference (JND)?
Feb 16, 2021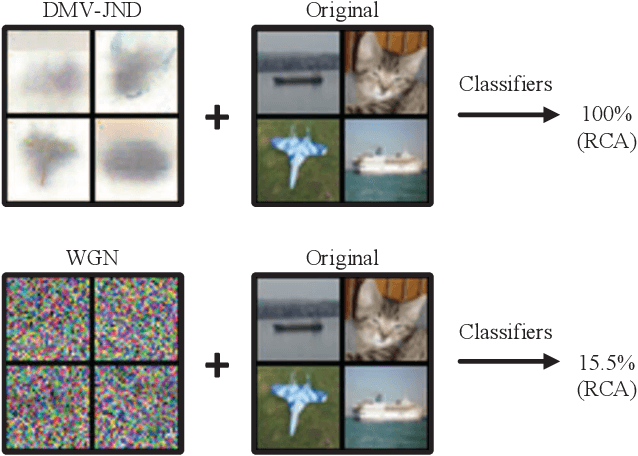

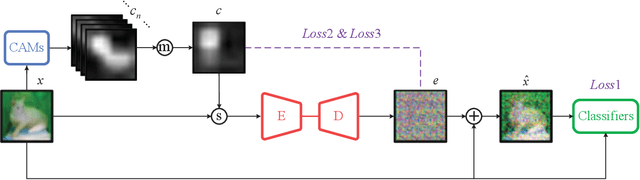
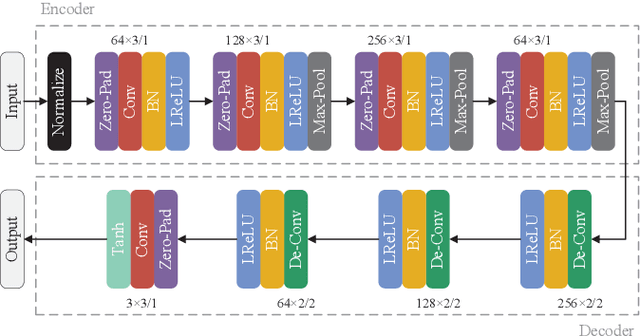
As an important perceptual characteristic of the Human Visual System (HVS), the Just Noticeable Difference (JND) has been studied for decades with image/video processing (e.g., perceptual image/video coding). However, there is little exploration on the existence of JND for AI, like Deep Machine Vision (DMV), although the DMV has made great strides in many machine vision tasks. In this paper, we take an initial attempt, and demonstrate that DMV does have the JND, termed as DMVJND. Besides, we propose a JND model for the classification task in DMV. It has been discovered that DMV can tolerate distorted images with average PSNR of only 9.56dB (the lower the better), by generating JND via unsupervised learning with our DMVJND-NET. In particular, a semantic-guided redundancy assessment strategy is designed to constrain the magnitude and spatial distribution of the JND. Experimental results on classification tasks demonstrate that we successfully find and model the JND for deep machine vision. Meanwhile, our DMV-JND paves a possible direction for DMV oriented image/video compression, watermarking, quality assessment, deep neural network security, and so on.