 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Temporal Early Exits for Efficient Video Object Detection
Jun 21, 2021
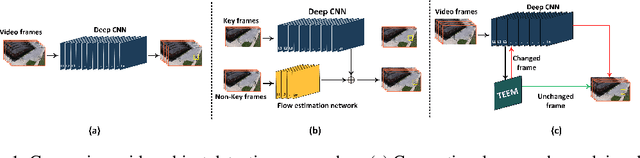
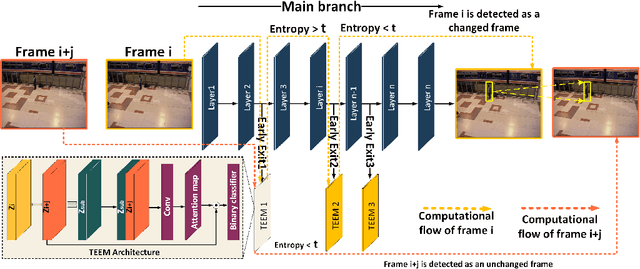
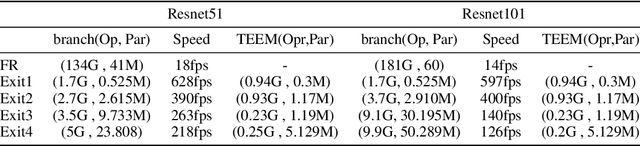

Transferring image-based object detectors to the domain of video remains challenging under resource constraints. Previous efforts utilised optical flow to allow unchanged features to be propagated, however, the overhead is considerable when working with very slowly changing scenes from applications such as surveillance. In this paper, we propose temporal early exits to reduce the computational complexity of per-frame video object detection. Multiple temporal early exit modules with low computational overhead are inserted at early layers of the backbone network to identify the semantic differences between consecutive frames. Full computation is only required if the frame is identified as having a semantic change to previous frames; otherwise, detection results from previous frames are reused. Experiments on CDnet show that our method significantly reduces the computational complexity and execution of per-frame video object detection up to $34 \times$ compared to existing methods with an acceptable reduction of 2.2\% in mAP.
Information Maximization Clustering via Multi-View Self-Labelling
Mar 12, 2021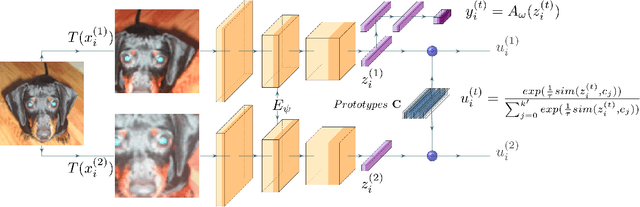
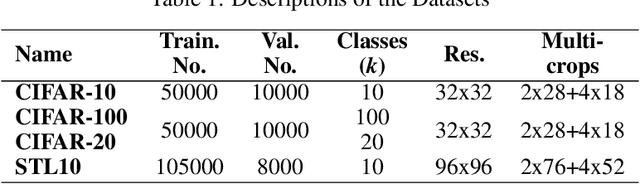
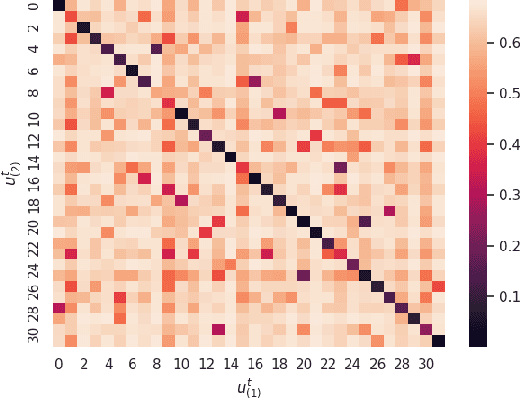
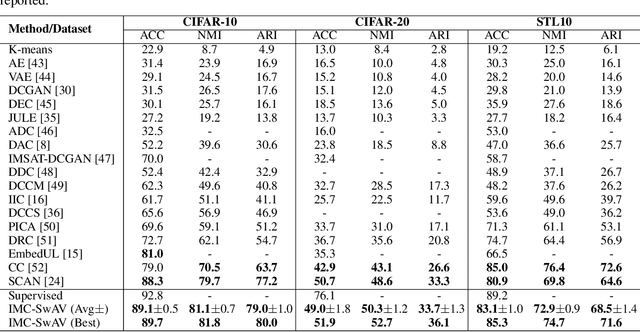
Image clustering is a particularly challenging computer vision task, which aims to generate annotations without human supervision. Recent advances focus on the use of self-supervised learning strategies in image clustering, by first learning valuable semantics and then clustering the image representations. These multiple-phase algorithms, however, increase the computational time and their final performance is reliant on the first stage. By extending the self-supervised approach, we propose a novel single-phase clustering method that simultaneously learns meaningful representations and assigns the corresponding annotations. This is achieved by integrating a discrete representation into the self-supervised paradigm through a classifier net. Specifically, the proposed clustering objective employs mutual information, and maximizes the dependency between the integrated discrete representation and a discrete probability distribution. The discrete probability distribution is derived though the self-supervised process by comparing the learnt latent representation with a set of trainable prototypes. To enhance the learning performance of the classifier, we jointly apply the mutual information across multi-crop views. Our empirical results show that the proposed framework outperforms state-of-the-art techniques with the average accuracy of 89.1% and 49.0%, respectively, on CIFAR-10 and CIFAR-100/20 datasets. Finally, the proposed method also demonstrates attractive robustness to parameter settings, making it ready to be applicable to other datasets.
Semantic Hierarchy Preserving Deep Hashing for Large-scale Image Retrieval
Jan 31, 2019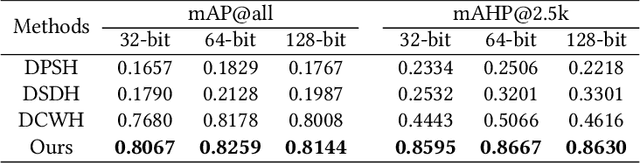

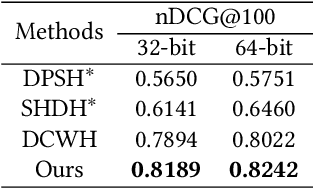
Convolutional neural networks have been widely used in content-based image retrieval. To better deal with large-scale data, the deep hashing model is proposed as an effective method, which maps an image to a binary code that can be used for hashing search. However, most existing deep hashing models only utilize fine-level semantic labels or convert them to similar/dissimilar labels for training. The natural semantic hierarchy structures are ignored in the training stage of the deep hashing model. In this paper, we present an effective algorithm to train a deep hashing model that can preserve a semantic hierarchy structure for large-scale image retrieval. Experiments on two datasets show that our method improves the fine-level retrieval performance. Meanwhile, our model achieves state-of-the-art results in terms of hierarchical retrieval.
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Mar 30, 2021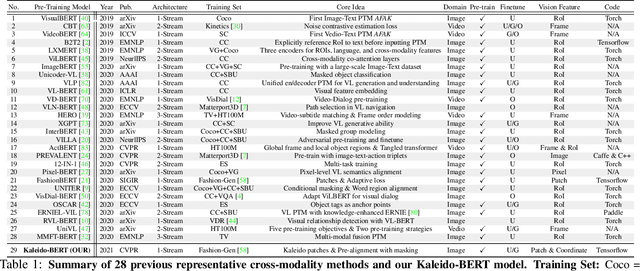
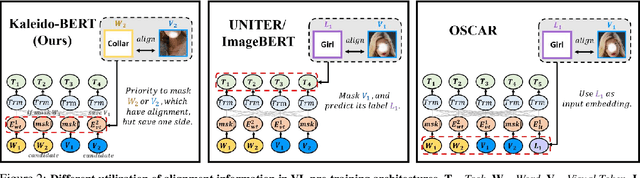
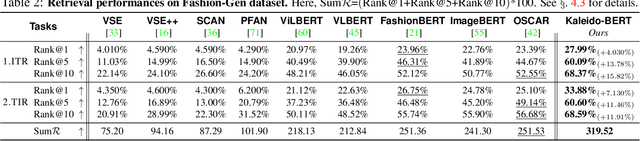
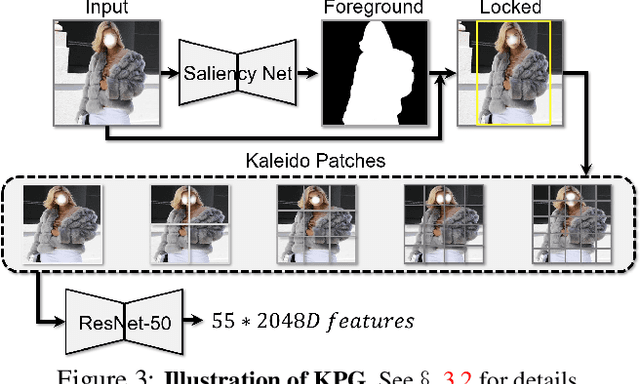
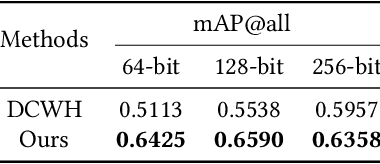
We present a new vision-language (VL) pre-training model dubbed Kaleido-BERT, which introduces a novel kaleido strategy for fashion cross-modality representations from transformers. In contrast to random masking strategy of recent VL models, we design alignment guided masking to jointly focus more on image-text semantic relations. To this end, we carry out five novel tasks, i.e., rotation, jigsaw, camouflage, grey-to-color, and blank-to-color for self-supervised VL pre-training at patches of different scale. Kaleido-BERT is conceptually simple and easy to extend to the existing BERT framework, it attains new state-of-the-art results by large margins on four downstream tasks, including text retrieval (R@1: 4.03% absolute improvement), image retrieval (R@1: 7.13% abs imv.), category recognition (ACC: 3.28% abs imv.), and fashion captioning (Bleu4: 1.2 abs imv.). We validate the efficiency of Kaleido-BERT on a wide range of e-commerical websites, demonstrating its broader potential in real-world applications.
Attention-aware Generalized Mean Pooling for Image Retrieval
Nov 01, 2018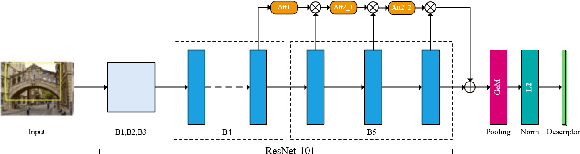
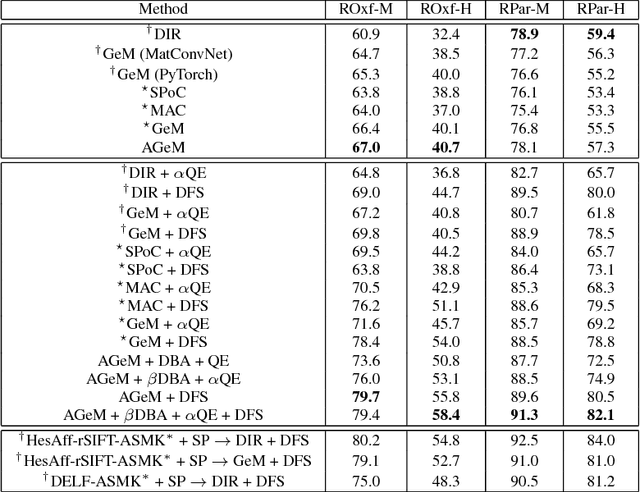
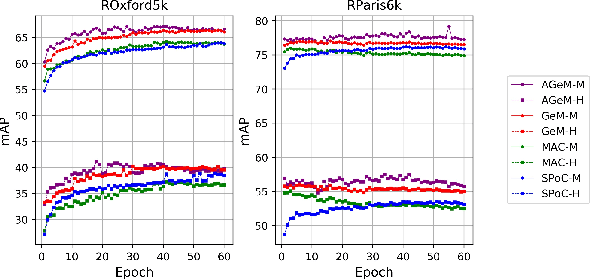
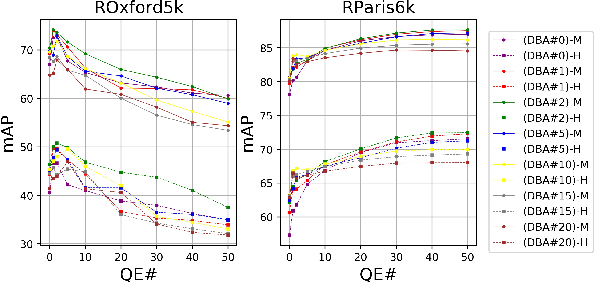
It has been shown that image descriptors extracted by convolutional neural networks (CNNs) achieve remarkable results for retrieval problems. In this paper, we apply attention mechanism to CNN, which aims at enhancing more relevant features that correspond to important keypoints in the input image. The generated attention-aware features are then aggregated by the previous state-of-the-art generalized mean (GeM) pooling followed by normalization to produce a compact global descriptor, which can be efficiently compared to other image descriptors by the dot product. An extensive comparison of our proposed approach with state-of-the-art methods is performed on the new challenging ROxford5k and RParis6k retrieval benchmarks. Results indicate significant improvement over previous work. In particular, our attention-aware GeM (AGeM) descriptor outperforms state-of-the-art method on ROxford5k under the `Hard' evaluation protocal.
Constrained Contrastive Distribution Learning for Unsupervised Anomaly Detection and Localisation in Medical Images
Mar 05, 2021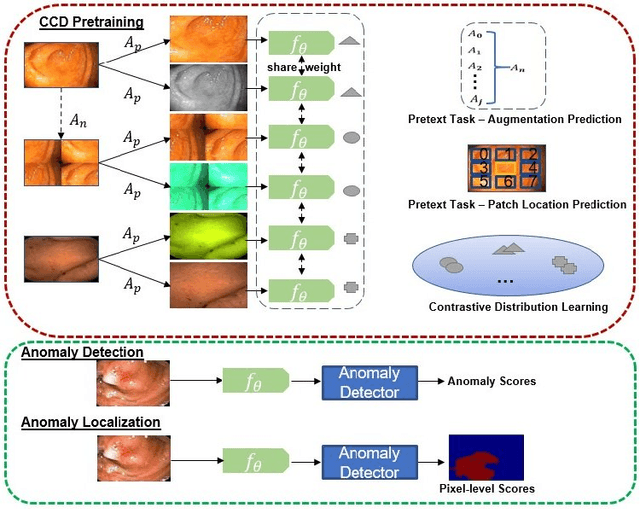
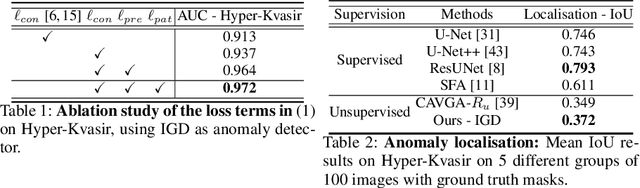
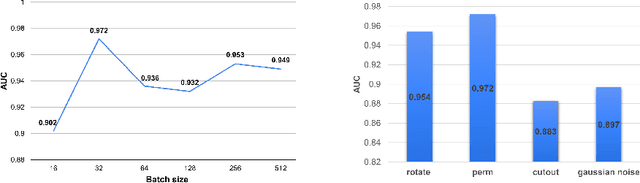
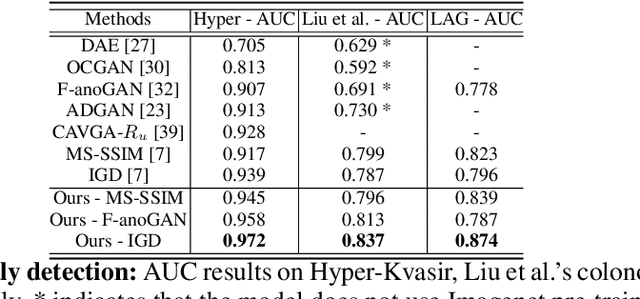
Unsupervised anomaly detection (UAD) learns one-class classifiers exclusively with normal (i.e., healthy) images to detect any abnormal (i.e., unhealthy) samples that do not conform to the expected normal patterns. UAD has two main advantages over its fully supervised counterpart. Firstly, it is able to directly leverage large datasets available from health screening programs that contain mostly normal image samples, avoiding the costly manual labelling of abnormal samples and the subsequent issues involved in training with extremely class-imbalanced data. Further, UAD approaches can potentially detect and localise any type of lesions that deviate from the normal patterns. One significant challenge faced by UAD methods is how to learn effective low-dimensional image representations to detect and localise subtle abnormalities, generally consisting of small lesions. To address this challenge, we propose a novel self-supervised representation learning method, called Constrained Contrastive Distribution learning for anomaly detection (CCD), which learns fine-grained feature representations by simultaneously predicting the distribution of augmented data and image contexts using contrastive learning with pretext constraints. The learned representations can be leveraged to train more anomaly-sensitive detection models. Extensive experiment results show that our method outperforms current state-of-the-art UAD approaches on three different colonoscopy and fundus screening datasets. Our code is available at https://github.com/tianyu0207/CCD.
eProduct: A Million-Scale Visual Search Benchmark to Address Product Recognition Challenges
Jul 13, 2021
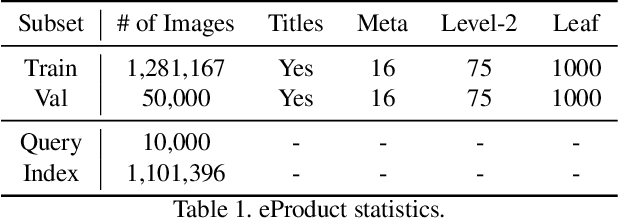
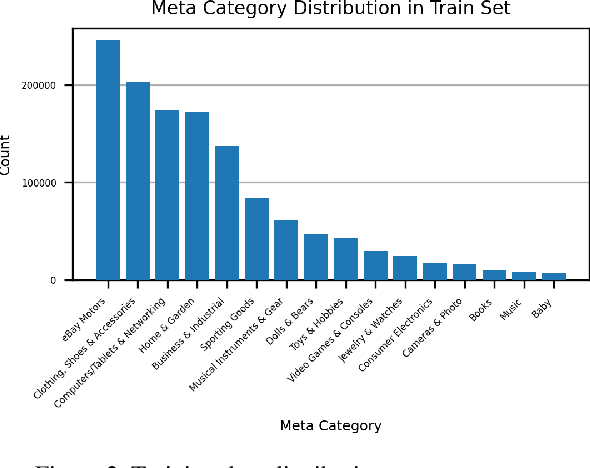
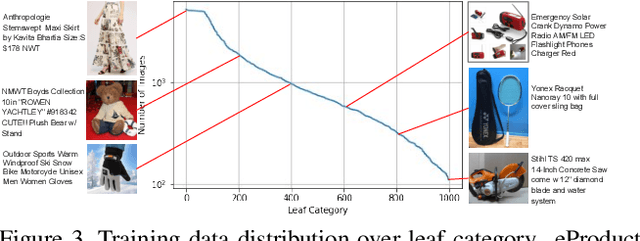
Large-scale product recognition is one of the major applications of computer vision and machine learning in the e-commerce domain. Since the number of products is typically much larger than the number of categories of products, image-based product recognition is often cast as a visual search rather than a classification problem. It is also one of the instances of super fine-grained recognition, where there are many products with slight or subtle visual differences. It has always been a challenge to create a benchmark dataset for training and evaluation on various visual search solutions in a real-world setting. This motivated creation of eProduct, a dataset consisting of 2.5 million product images towards accelerating development in the areas of self-supervised learning, weakly-supervised learning, and multimodal learning, for fine-grained recognition. We present eProduct as a training set and an evaluation set, where the training set contains 1.3M+ listing images with titles and hierarchical category labels, for model development, and the evaluation set includes 10,000 query and 1.1 million index images for visual search evaluation. We will present eProduct's construction steps, provide analysis about its diversity and cover the performance of baseline models trained on it.
An Empirical Method to Quantify the Peripheral Performance Degradation in Deep Networks
Dec 04, 2020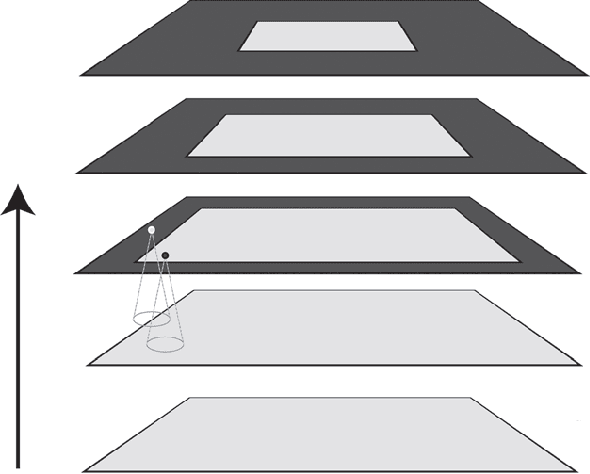
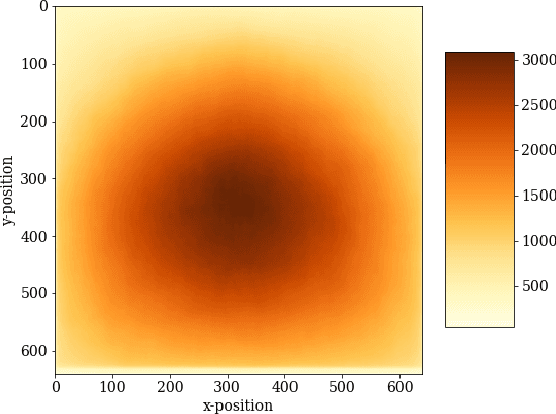


When applying a convolutional kernel to an image, if the output is to remain the same size as the input then some form of padding is required around the image boundary, meaning that for each layer of convolution in a convolutional neural network (CNN), a strip of pixels equal to the half-width of the kernel size is produced with a non-veridical representation. Although most CNN kernels are small to reduce the parameter load of a network, this non-veridical area compounds with each convolutional layer. The tendency toward deeper and deeper networks combined with stride-based down-sampling means that the propagation of this region can end up covering a non-negligable portion of the image. Although this issue with convolutions has been well acknowledged over the years, the impact of this degraded peripheral representation on modern network behavior has not been fully quantified. What are the limits of translation invariance? Does image padding successfully mitigate the issue, or is performance affected as an object moves between the image border and center? Using Mask R-CNN as an experimental model, we design a dataset and methodology to quantify the spatial dependency of network performance. Our dataset is constructed by inserting objects into high resolution backgrounds, thereby allowing us to crop sub-images which place target objects at specific locations relative to the image border. By probing the behaviour of Mask R-CNN across a selection of target locations, we see clear patterns of performance degredation near the image boundary, and in particular in the image corners. Quantifying both the extent and magnitude of this spatial anisotropy in network performance is important for the deployment of deep networks into unconstrained and realistic environments in which the location of objects or regions of interest are not guaranteed to be well localized within a given image.
Instance Localization for Self-supervised Detection Pretraining
Feb 16, 2021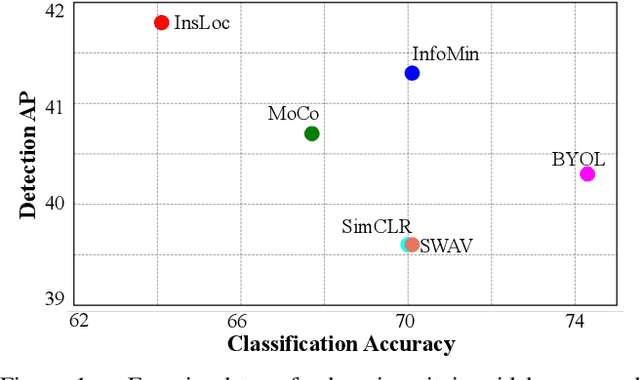
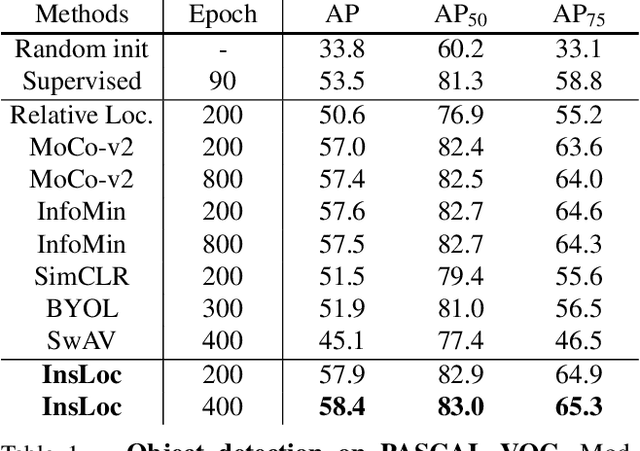
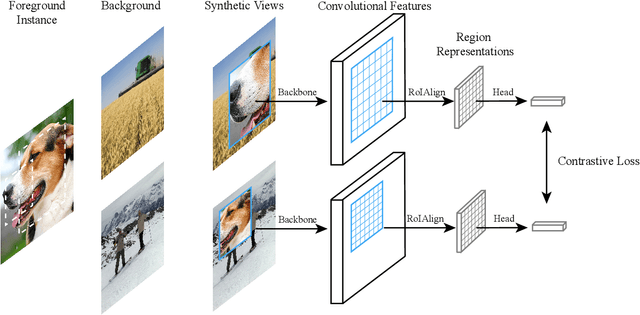
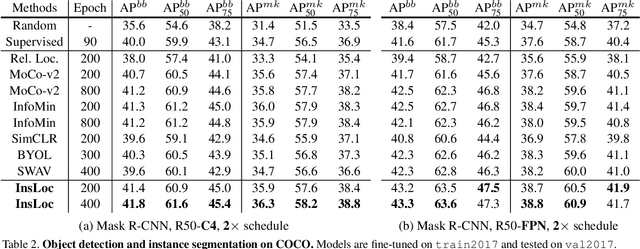
Prior research on self-supervised learning has led to considerable progress on image classification, but often with degraded transfer performance on object detection. The objective of this paper is to advance self-supervised pretrained models specifically for object detection. Based on the inherent difference between classification and detection, we propose a new self-supervised pretext task, called instance localization. Image instances are pasted at various locations and scales onto background images. The pretext task is to predict the instance category given the composited images as well as the foreground bounding boxes. We show that integration of bounding boxes into pretraining promotes better task alignment and architecture alignment for transfer learning. In addition, we propose an augmentation method on the bounding boxes to further enhance the feature alignment. As a result, our model becomes weaker at Imagenet semantic classification but stronger at image patch localization, with an overall stronger pretrained model for object detection. Experimental results demonstrate that our approach yields state-of-the-art transfer learning results for object detection on PASCAL VOC and MSCOCO.
Visual Object Networks: Image Generation with Disentangled 3D Representation
Dec 06, 2018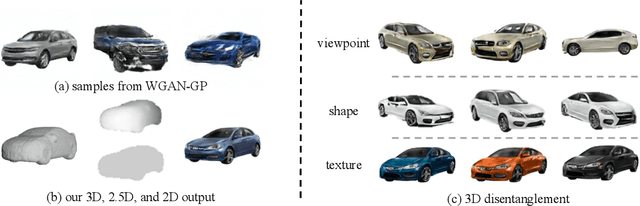
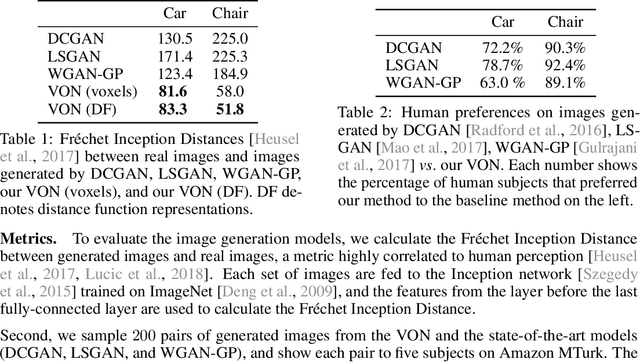
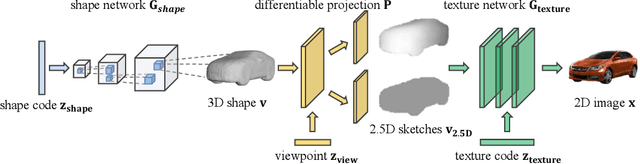

Recent progress in deep generative models has led to tremendous breakthroughs in image generation. However, while existing models can synthesize photorealistic images, they lack an understanding of our underlying 3D world. We present a new generative model, Visual Object Networks (VON), synthesizing natural images of objects with a disentangled 3D representation. Inspired by classic graphics rendering pipelines, we unravel our image formation process into three conditionally independent factors---shape, viewpoint, and texture---and present an end-to-end adversarial learning framework that jointly models 3D shapes and 2D images. Our model first learns to synthesize 3D shapes that are indistinguishable from real shapes. It then renders the object's 2.5D sketches (i.e., silhouette and depth map) from its shape under a sampled viewpoint. Finally, it learns to add realistic texture to these 2.5D sketches to generate natural images. The VON not only generates images that are more realistic than state-of-the-art 2D image synthesis methods, but also enables many 3D operations such as changing the viewpoint of a generated image, editing of shape and texture, linear interpolation in texture and shape space, and transferring appearance across different objects and viewpoints.