 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Data Efficient Unsupervised Domain Adaptation for Cross-Modality Image Segmentation
Aug 12, 2019

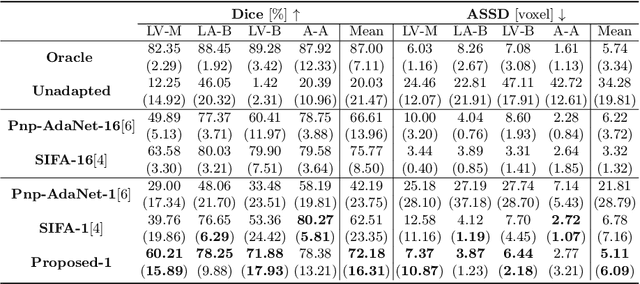
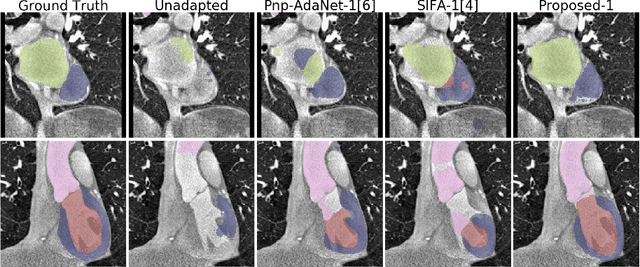
Deep learning models trained on medical images from a source domain (e.g. imaging modality) often fail when deployed on images from a different target domain, despite imaging common anatomical structures. Deep unsupervised domain adaptation (UDA) aims to improve the performance of a deep neural network model on a target domain, using solely unlabelled target domain data and labelled source domain data. However, current state-of-the-art methods exhibit reduced performance when target data is scarce. In this work, we introduce a new data efficient UDA method for multi-domain medical image segmentation. The proposed method combines a novel VAE-based feature prior matching, which is data-efficient, and domain adversarial training to learn a shared domain-invariant latent space which is exploited during segmentation. Our method is evaluated on a public multi-modality cardiac image segmentation dataset by adapting from the labelled source domain (3D MRI) to the unlabelled target domain (3D CT). We show that by using only one single unlabelled 3D CT scan, the proposed architecture outperforms the state-of-the-art in the same setting. Finally, we perform ablation studies on prior matching and domain adversarial training to shed light on the theoretical grounding of the proposed method.
Overcoming the Distance Estimation Bottleneck in Camera Trap Distance Sampling
May 10, 2021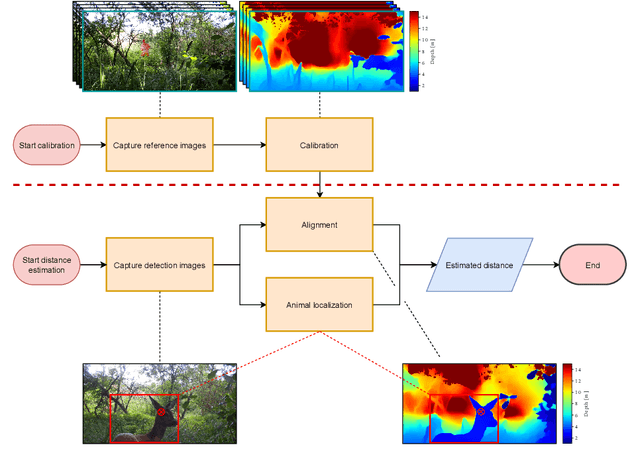
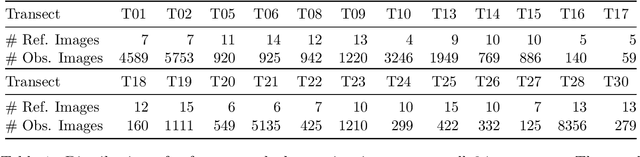

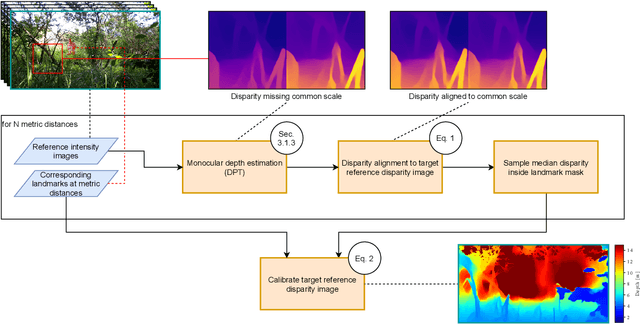
Biodiversity crisis is still accelerating. Estimating animal abundance is of critical importance to assess, for example, the consequences of land-use change and invasive species on species composition, or the effectiveness of conservation interventions. Camera trap distance sampling (CTDS) is a recently developed monitoring method providing reliable estimates of wildlife population density and abundance. However, in current applications of CTDS, the required camera-to-animal distance measurements are derived by laborious, manual and subjective estimation methods. To overcome this distance estimation bottleneck in CTDS, this study proposes a completely automatized workflow utilizing state-of-the-art methods of image processing and pattern recognition.
ID-Unet: Iterative Soft and Hard Deformation for View Synthesis
Mar 04, 2021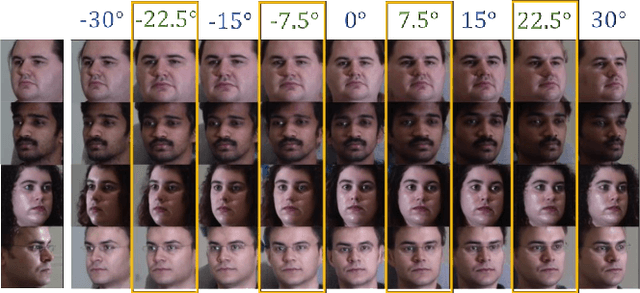
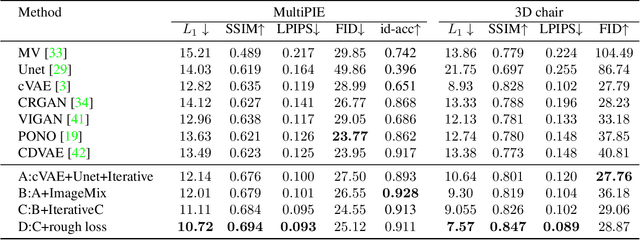
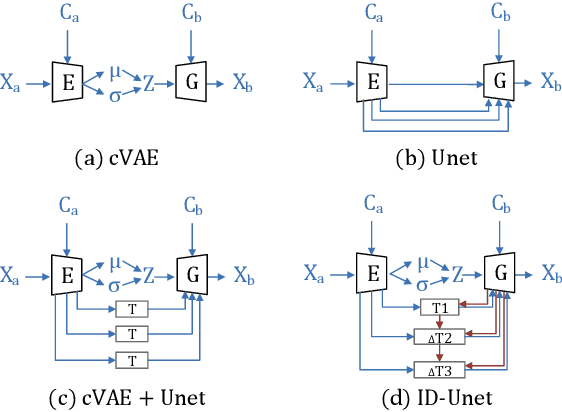
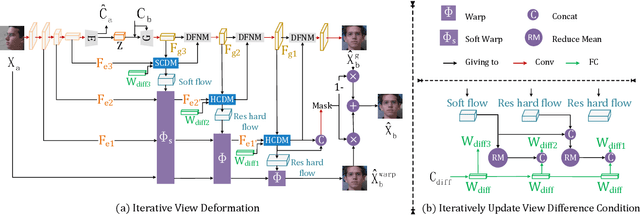
View synthesis is usually done by an autoencoder, in which the encoder maps a source view image into a latent content code, and the decoder transforms it into a target view image according to the condition. However, the source contents are often not well kept in this setting, which leads to unnecessary changes during the view translation. Although adding skipped connections, like Unet, alleviates the problem, but it often causes the failure on the view conformity. This paper proposes a new architecture by performing the source-to-target deformation in an iterative way. Instead of simply incorporating the features from multiple layers of the encoder, we design soft and hard deformation modules, which warp the encoder features to the target view at different resolutions, and give results to the decoder to complement the details. Particularly, the current warping flow is not only used to align the feature of the same resolution, but also as an approximation to coarsely deform the high resolution feature. Then the residual flow is estimated and applied in the high resolution, so that the deformation is built up in the coarse-to-fine fashion. To better constrain the model, we synthesize a rough target view image based on the intermediate flows and their warped features. The extensive ablation studies and the final results on two different data sets show the effectiveness of the proposed model.
Semantic Guided Single Image Reflection Removal
Jul 30, 2019


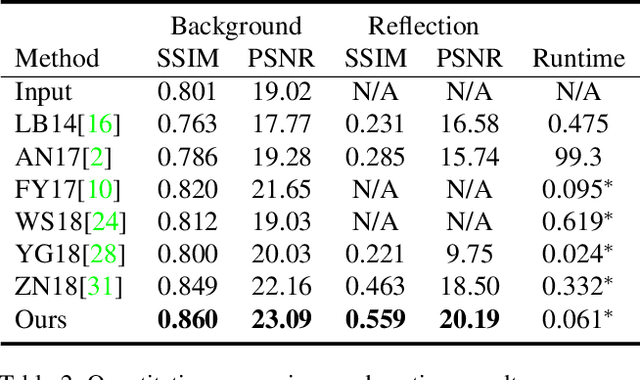
Reflection is common in images capturing scenes behind a glass window, which is not only a disturbance visually but also influence the performance of other computer vision algorithms. Single image reflection removal is an ill-posed problem because the color at each pixel needs to be separated into two values, i.e., the desired clear background and the reflection. To solve it, existing methods propose priors such as smoothness, color consistency. However, the low-level priors are not reliable in complex scenes, for instance, when capturing a real outdoor scene through a window, both the foreground and background contain both smooth and sharp area and a variety of color. In this paper, inspired by the fact that human can separate the two layers easily by recognizing the objects, we use the object semantic as guidance to force the same semantic object belong to the same layer. Extensive experiments on different datasets show that adding the semantic information offers a significant improvement to reflection separation. We also demonstrate the applications of the proposed method to other computer vision tasks.
Machine Friendly Machine Learning: Interpretation of Computed Tomography Without Image Reconstruction
Dec 03, 2018
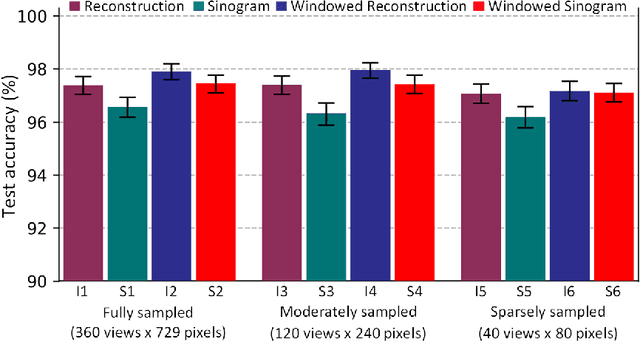
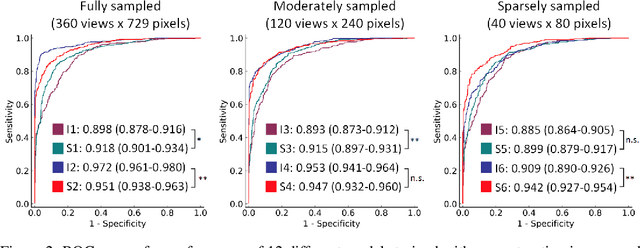

Recent advancements in deep learning for automated image processing and classification have accelerated many new applications for medical image analysis. However, most deep learning applications have been developed using reconstructed, human-interpretable medical images. While image reconstruction from raw sensor data is required for the creation of medical images, the reconstruction process only uses a partial representation of all the data acquired. Here we report the development of a system to directly process raw computed tomography (CT) data in sinogram-space, bypassing the intermediary step of image reconstruction. Two classification tasks were evaluated for their feasibility for sinogram-space machine learning: body region identification and intracranial hemorrhage (ICH) detection. Our proposed SinoNet performed favorably compared to conventional reconstructed image-space-based systems for both tasks, regardless of scanning geometries in terms of projections or detectors. Further, SinoNet performed significantly better when using sparsely sampled sinograms than conventional networks operating in image-space. As a result, sinogram-space algorithms could be used in field settings for binary diagnosis testing, triage, and in clinical settings where low radiation dose is desired. These findings also demonstrate another strength of deep learning where it can analyze and interpret sinograms that are virtually impossible for human experts.
Vision-Based Food Analysis for Automatic Dietary Assessment
Aug 06, 2021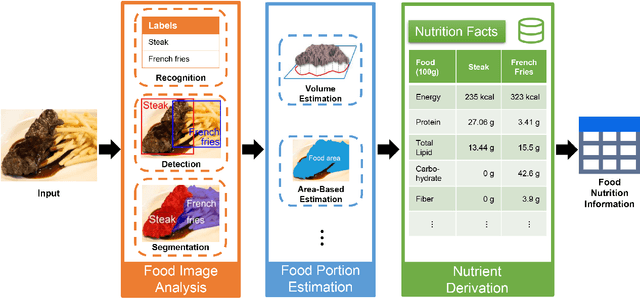
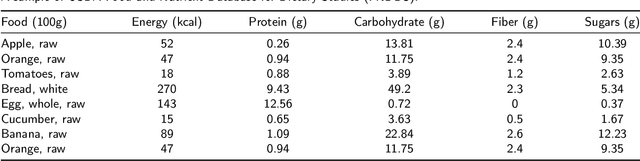
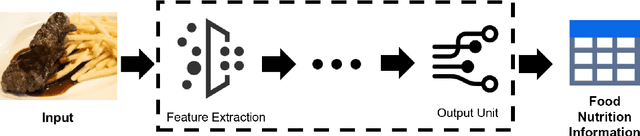
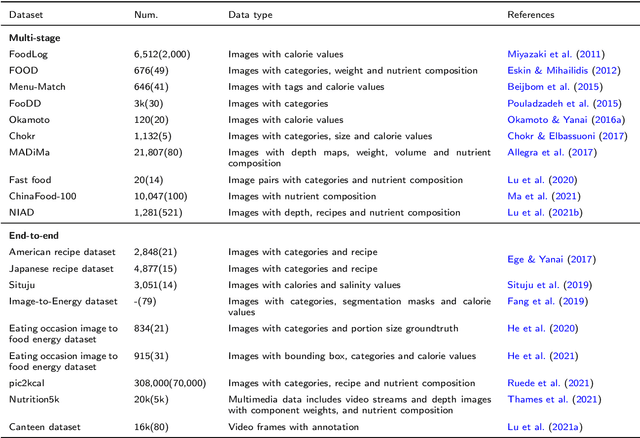
Background: Maintaining a healthy diet is vital to avoid health-related issues, e.g., undernutrition, obesity and many non-communicable diseases. An indispensable part of the health diet is dietary assessment. Traditional manual recording methods are burdensome and contain substantial biases and errors. Recent advances in Artificial Intelligence, especially computer vision technologies, have made it possible to develop automatic dietary assessment solutions, which are more convenient, less time-consuming and even more accurate to monitor daily food intake. Scope and approach: This review presents one unified Vision-Based Dietary Assessment (VBDA) framework, which generally consists of three stages: food image analysis, volume estimation and nutrient derivation. Vision-based food analysis methods, including food recognition, detection and segmentation, are systematically summarized, and methods of volume estimation and nutrient derivation are also given. The prosperity of deep learning makes VBDA gradually move to an end-to-end implementation, which applies food images to a single network to directly estimate the nutrition. The recently proposed end-to-end methods are also discussed. We further analyze existing dietary assessment datasets, indicating that one large-scale benchmark is urgently needed, and finally highlight key challenges and future trends for VBDA. Key findings and conclusions: After thorough exploration, we find that multi-task end-to-end deep learning approaches are one important trend of VBDA. Despite considerable research progress, many challenges remain for VBDA due to the meal complexity. We also provide the latest ideas for future development of VBDA, e.g., fine-grained food analysis and accurate volume estimation. This survey aims to encourage researchers to propose more practical solutions for VBDA.
ICodeNet -- A Hierarchical Neural Network Approach for Source Code Author Identification
Jan 30, 2021
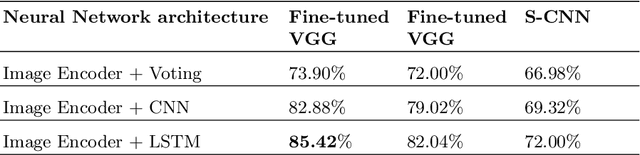
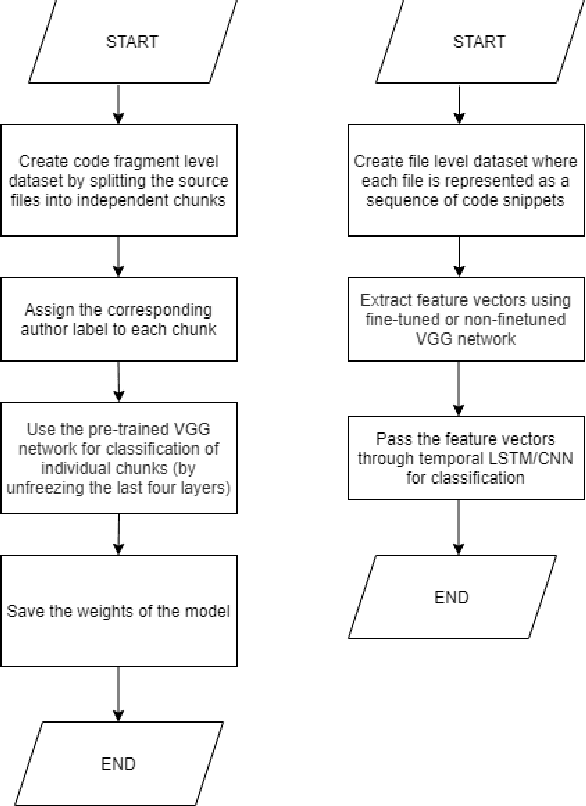
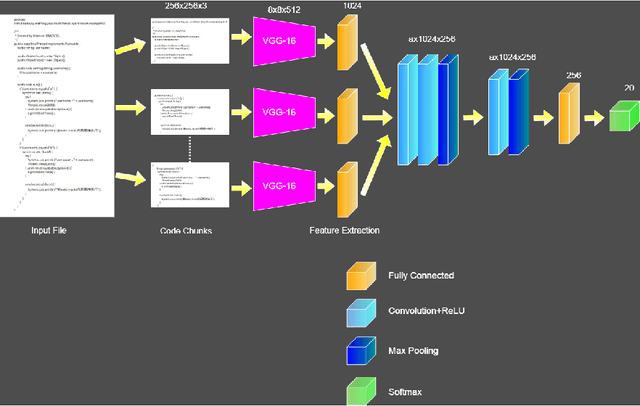
With the open-source revolution, source codes are now more easily accessible than ever. This has, however, made it easier for malicious users and institutions to copy the code without giving regards to the license, or credit to the original author. Therefore, source code author identification is a critical task with paramount importance. In this paper, we propose ICodeNet - a hierarchical neural network that can be used for source code file-level tasks. The ICodeNet processes source code in image format and is employed for the task of per file author identification. The ICodeNet consists of an ImageNet trained VGG encoder followed by a shallow neural network. The shallow network is based either on CNN or LSTM. Different variations of models are evaluated on a source code author classification dataset. We have also compared our image-based hierarchical neural network model with simple image-based CNN architecture and text-based CNN and LSTM models to highlight its novelty and efficiency.
Real Image Denoising with Feature Attention
Apr 16, 2019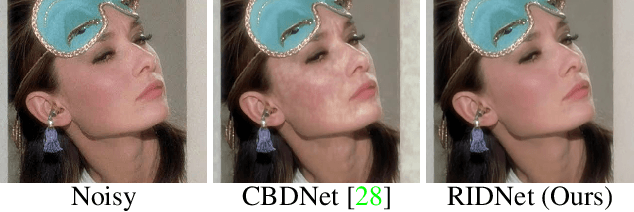

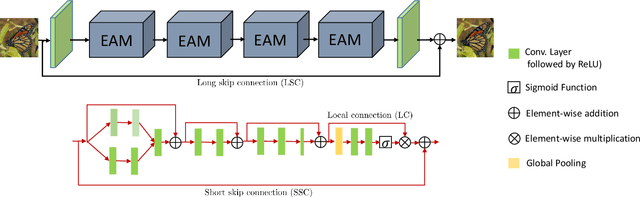

Deep convolutional neural networks perform better on images containing spatially invariant noise (synthetic noise); however, their performance is limited on real-noisy photographs and requires multiple stage network modeling. To advance the practicability of denoising algorithms, this paper proposes a novel single-stage blind real image denoising network (RIDNet) by employing a modular architecture. We use a residual on the residual structure to ease the flow of low-frequency information and apply feature attention to exploit the channel dependencies. Furthermore, the evaluation in terms of quantitative metrics and visual quality on three synthetic and four real noisy datasets against 19 state-of-the-art algorithms demonstrate the superiority of our RIDNet.
eGAN: Unsupervised approach to class imbalance using transfer learning
Apr 09, 2021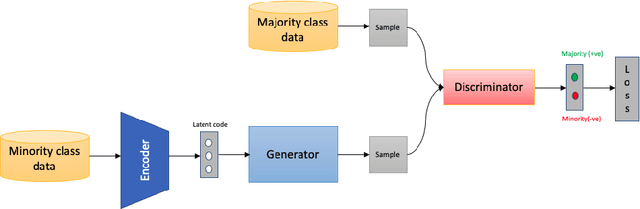


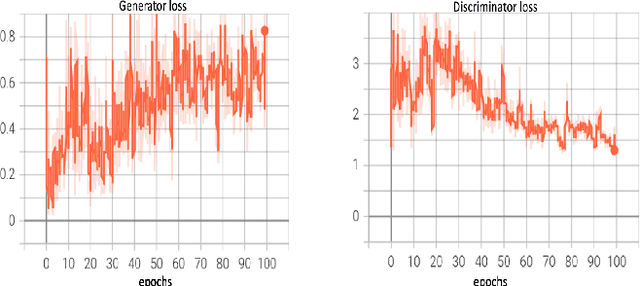
Class imbalance is an inherent problem in many machine learning classification tasks. This often leads to trained models that are unusable for any practical purpose. In this study we explore an unsupervised approach to address these imbalances by leveraging transfer learning from pre-trained image classification models to encoder-based Generative Adversarial Network (eGAN). To the best of our knowledge, this is the first work to tackle this problem using GAN without needing to augment with synthesized fake images. In the proposed approach we use the discriminator network to output a negative or positive score. We classify as minority, test samples with negative scores and as majority those with positive scores. Our approach eliminates epistemic uncertainty in model predictions, as the P(minority) + P(majority) need not sum up to 1. The impact of transfer learning and combinations of different pre-trained image classification models at the generator and discriminator is also explored. Best result of 0.69 F1-score was obtained on CIFAR-10 classification task with imbalance ratio of 1:2500. Our approach also provides a mechanism of thresholding the specificity or sensitivity of our machine learning system. Keywords: Class imbalance, Transfer Learning, GAN, nash equilibrium
HPRNet: Hierarchical Point Regression for Whole-Body Human Pose Estimation
Jun 08, 2021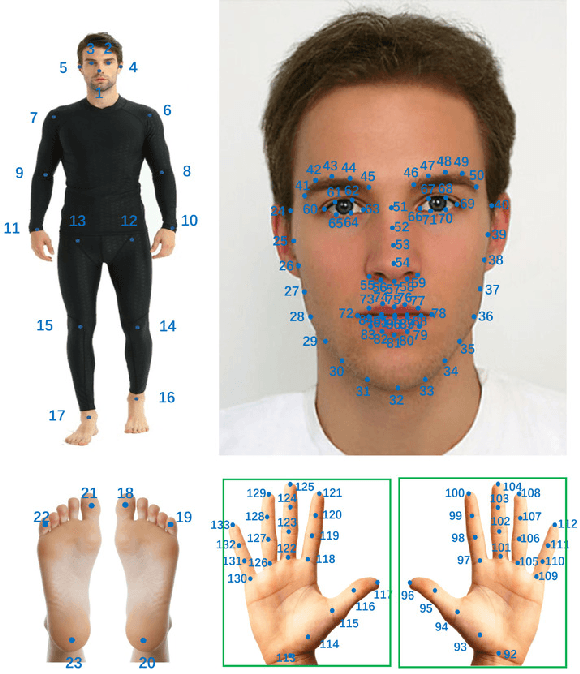

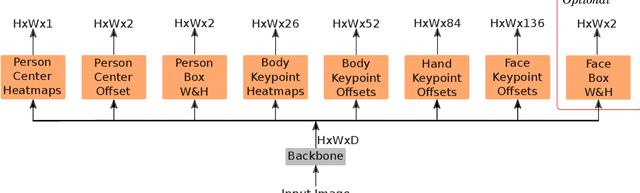

In this paper, we present a new bottom-up one-stage method for whole-body pose estimation, which we name "hierarchical point regression," or HPRNet for short, referring to the network that implements this method. To handle the scale variance among different body parts, we build a hierarchical point representation of body parts and jointly regress them. Unlike the existing two-stage methods, our method predicts whole-body pose in a constant time independent of the number of people in an image. On the COCO WholeBody dataset, HPRNet significantly outperforms all previous bottom-up methods on the keypoint detection of all whole-body parts (i.e. body, foot, face and hand); it also achieves state-of-the-art results in the face (75.4 AP) and hand (50.4 AP) keypoint detection. Code and models are available at https://github.com/nerminsamet/HPRNet.git.