 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Long-Term Temporally Consistent Unpaired Video Translation from Simulated Surgical 3D Data
Mar 31, 2021
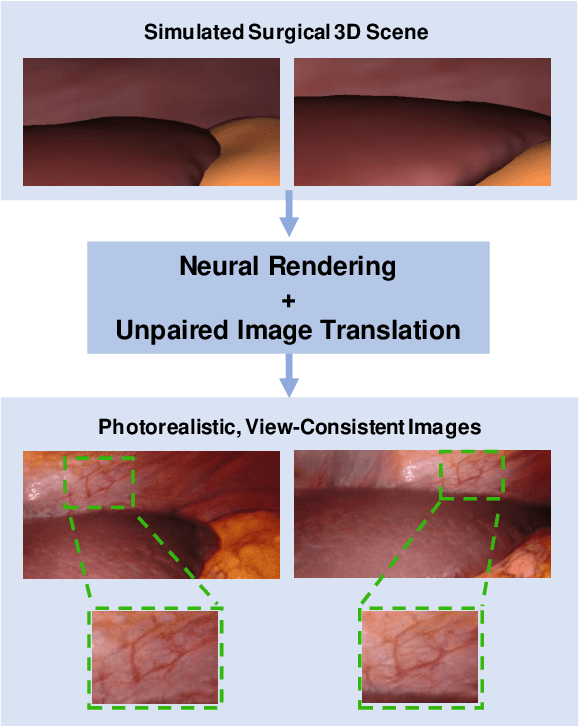
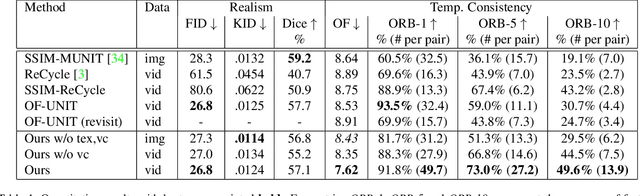
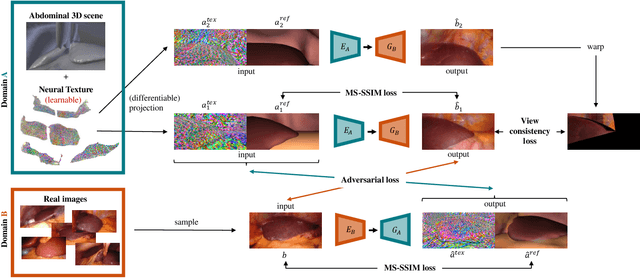
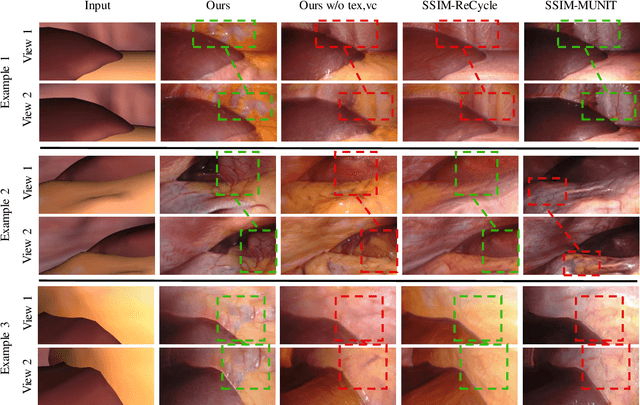
Research in unpaired video translation has mainly focused on short-term temporal consistency by conditioning on neighboring frames. However for transfer from simulated to photorealistic sequences, available information on the underlying geometry offers potential for achieving global consistency across views. We propose a novel approach which combines unpaired image translation with neural rendering to transfer simulated to photorealistic surgical abdominal scenes. By introducing global learnable textures and a lighting-invariant view-consistency loss, our method produces consistent translations of arbitrary views and thus enables long-term consistent video synthesis. We design and test our model to generate video sequences from minimally-invasive surgical abdominal scenes. Because labeled data is often limited in this domain, photorealistic data where ground truth information from the simulated domain is preserved is especially relevant. By extending existing image-based methods to view-consistent videos, we aim to impact the applicability of simulated training and evaluation environments for surgical applications. Code and data will be made publicly available soon.
Adversarial Driving: Attacking End-to-End Autonomous Driving Systems
Mar 21, 2021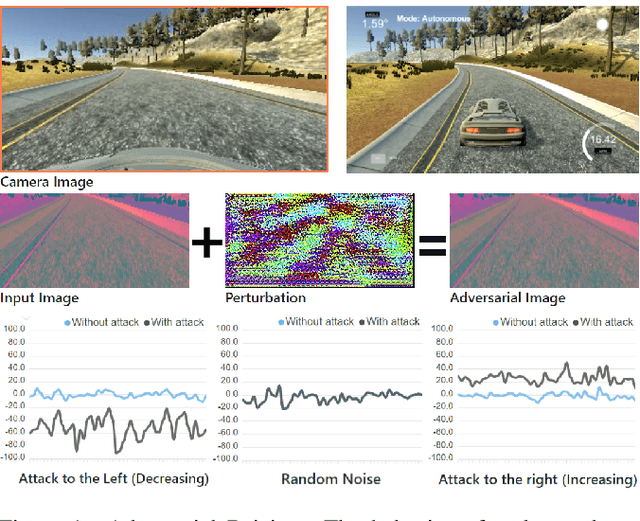
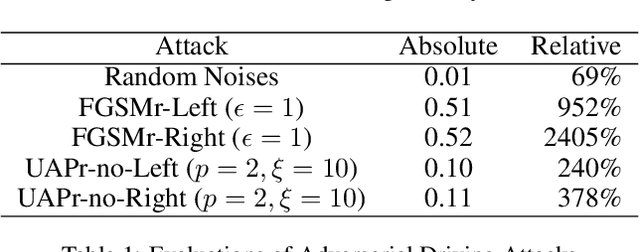
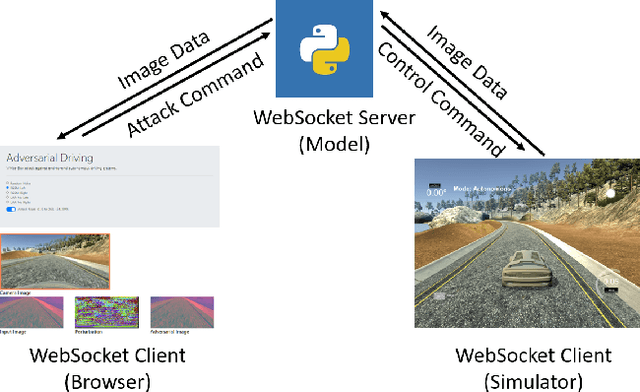
As the research in deep neural networks advances, deep convolutional networks become feasible for automated driving tasks. There is an emerging trend of employing end-to-end models in the automation of driving tasks. However, previous research unveils that deep neural networks are vulnerable to adversarial attacks in classification tasks. While for regression tasks such as autonomous driving, the effect of these attacks remains rarely explored. In this research, we devise two white-box targeted attacks against end-to-end autonomous driving systems. The driving model takes an image as input and outputs the steering angle. Our attacks can manipulate the behaviour of the autonomous driving system only by perturbing the input image. Both attacks can be initiated in real-time on CPUs without employing GPUs. This demo aims to raise concerns over applications of end-to-end models in safety-critical systems.
Image-Level Attentional Context Modeling Using Nested-Graph Neural Networks
Nov 12, 2018
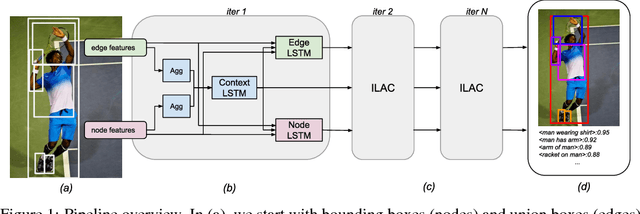

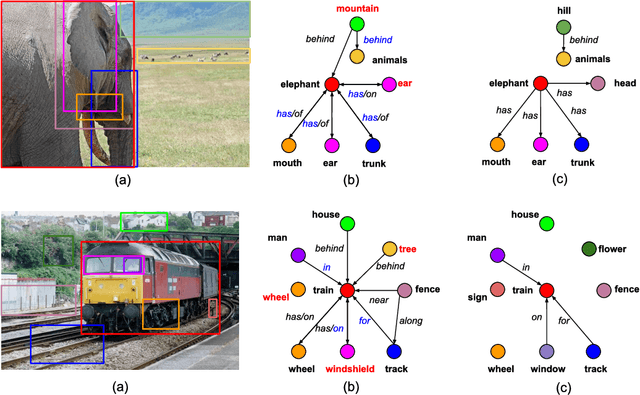
We introduce a new scene graph generation method called image-level attentional context modeling (ILAC). Our model includes an attentional graph network that effectively propagates contextual information across the graph using image-level features. Whereas previous works use an object-centric context, we build an image-level context agent to encode the scene properties. The proposed method comprises a single-stream network that iteratively refines the scene graph with a nested graph neural network. We demonstrate that our approach achieves competitive performance with the state-of-the-art for scene graph generation on the Visual Genome dataset, while requiring fewer parameters than other methods. We also show that ILAC can improve regular object detectors by incorporating relational image-level information.
Two-stage Image Classification Supervised by a Single Teacher Single Student Model
Sep 26, 2019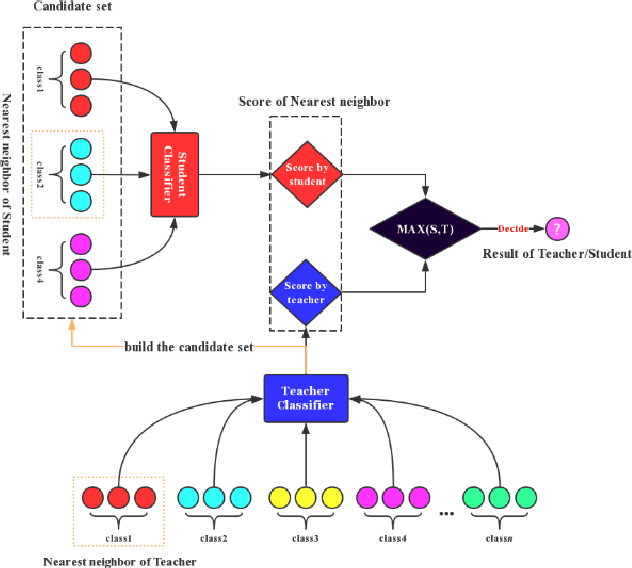
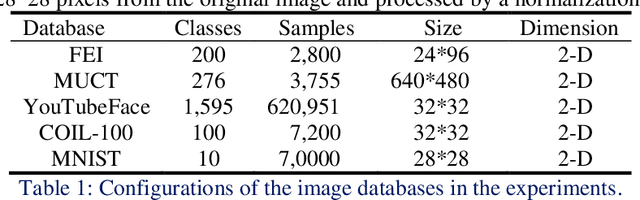
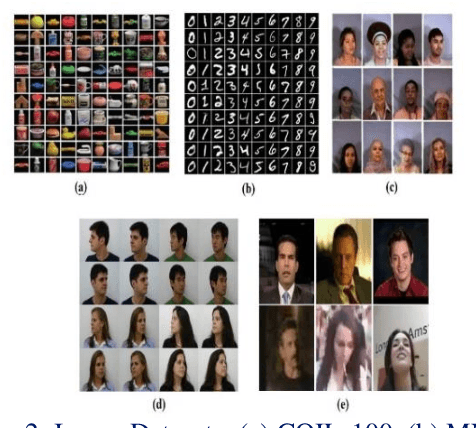
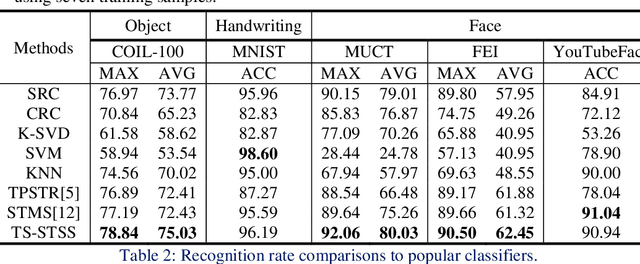
The two-stage strategy has been widely used in image classification. However, these methods barely take the classification criteria of the first stage into consideration in the second prediction stage. In this paper, we propose a novel two-stage representation method (TSR), and convert it to a Single-Teacher Single-Student (STSS) problem in our two-stage image classification framework. We seek the nearest neighbours of the test sample to choose candidate target classes. Meanwhile, the first stage classifier is formulated as the teacher, which holds the classification scores. The samples of the candidate classes are utilized to learn a student classifier based on L2-minimization in the second stage. The student will be supervised by the teacher classifier, which approves the student only if it obtains a higher score. In actuality, the proposed framework generates a stronger classifier by staging two weaker classifiers in a novel way. The experiments conducted on several face and object databases show that our proposed framework is effective and outperforms multiple popular classification methods.
Online Adaptive Image Reconstruction (OnAIR) Using Dictionary Models
Sep 06, 2018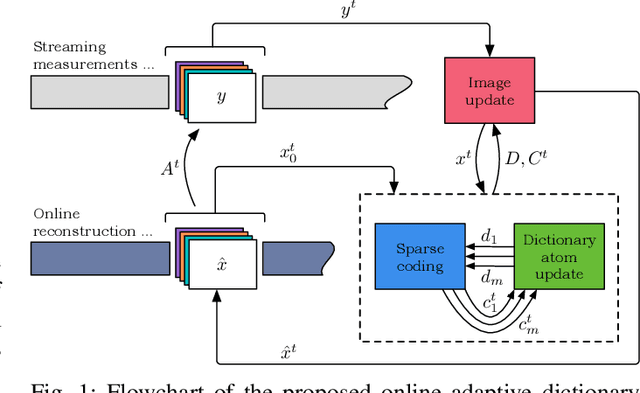
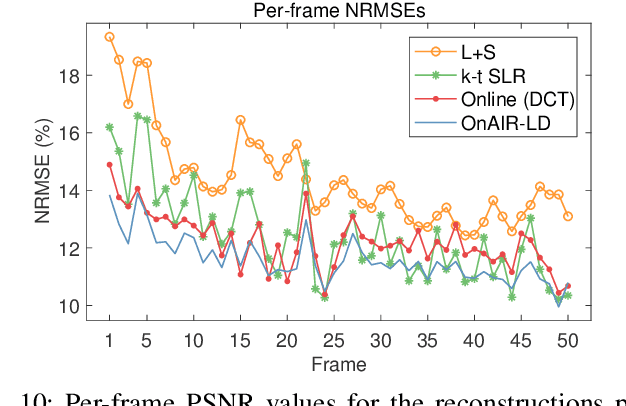


Sparsity and low-rank models have been popular for reconstructing images and videos from limited or corrupted measurements. Dictionary or transform learning methods are useful in applications such as denoising, inpainting, and medical image reconstruction. This paper proposes a framework for online (or time-sequential) adaptive reconstruction of dynamic image sequences from linear (typically undersampled) measurements. We model the spatiotemporal patches of the underlying dynamic image sequence as sparse in a dictionary, and we simultaneously estimate the dictionary and the images sequentially from streaming measurements. Multiple constraints on the adapted dictionary are also considered such as a unitary matrix, or low-rank dictionary atoms that provide additional efficiency or robustness. The proposed online algorithms are memory efficient and involve simple updates of the dictionary atoms, sparse coefficients, and images. Numerical experiments demonstrate the usefulness of the proposed methods in inverse problems such as video reconstruction or inpainting from noisy, subsampled pixels, and dynamic magnetic resonance image reconstruction from very limited measurements.
Deep Network Approximation With Accuracy Independent of Number of Neurons
Jul 06, 2021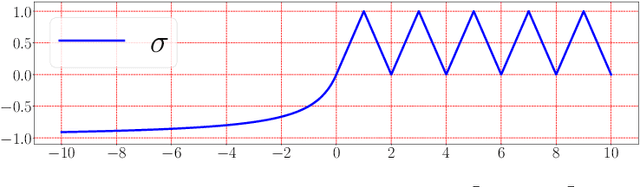
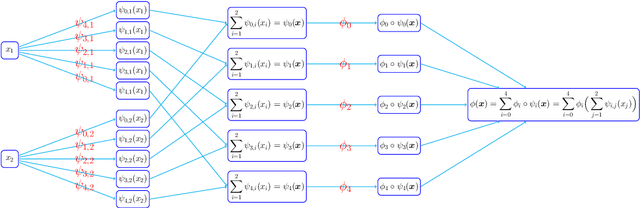
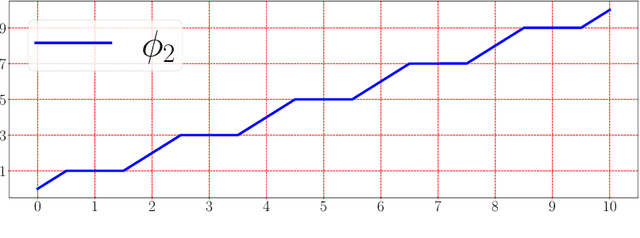
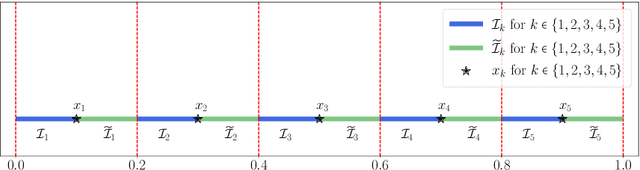
This paper develops simple feed-forward neural networks that achieve the universal approximation property for all continuous functions with a fixed finite number of neurons. These neural networks are simple because they are designed with a simple and computable continuous activation function $\sigma$ leveraging a triangular-wave function and a softsign function. We prove that $\sigma$-activated networks with width $36d(2d+1)$ and depth $11$ can approximate any continuous function on a $d$-dimensioanl hypercube within an arbitrarily small error. Hence, for supervised learning and its related regression problems, the hypothesis space generated by these networks with a size not smaller than $36d(2d+1)\times 11$ is dense in the space of continuous functions. Furthermore, classification functions arising from image and signal classification are in the hypothesis space generated by $\sigma$-activated networks with width $36d(2d+1)$ and depth $12$, when there exist pairwise disjoint closed bounded subsets of $\mathbb{R}^d$ such that the samples of the same class are located in the same subset.
Contemplating real-world object classification
Mar 27, 2021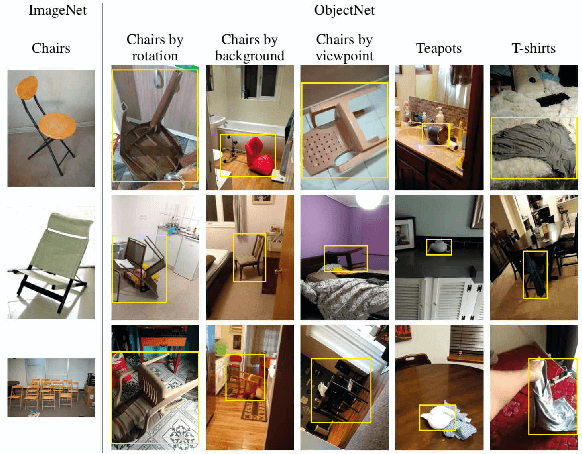

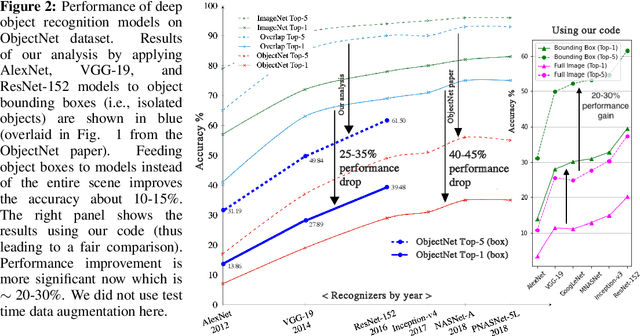
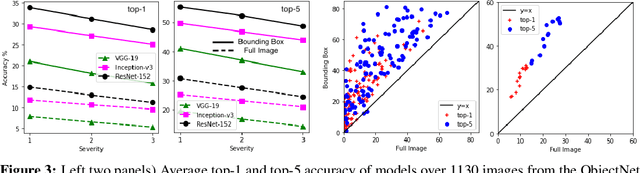
Deep object recognition models have been very successful over benchmark datasets such as ImageNet. How accurate and robust are they to distribution shifts arising from natural and synthetic variations in datasets? Prior research on this problem has primarily focused on ImageNet variations (e.g., ImageNetV2, ImageNet-A). To avoid potential inherited biases in these studies, we take a different approach. Specifically, we reanalyze the ObjectNet dataset recently proposed by Barbu et al. containing objects in daily life situations. They showed a dramatic performance drop of the state of the art object recognition models on this dataset. Due to the importance and implications of their results regarding the generalization ability of deep models, we take a second look at their analysis. We find that applying deep models to the isolated objects, rather than the entire scene as is done in the original paper, results in around 20-30% performance improvement. Relative to the numbers reported in Barbu et al., around 10-15% of the performance loss is recovered, without any test time data augmentation. Despite this gain, however, we conclude that deep models still suffer drastically on the ObjectNet dataset. We also investigate the robustness of models against synthetic image perturbations such as geometric transformations (e.g., scale, rotation, translation), natural image distortions (e.g., impulse noise, blur) as well as adversarial attacks (e.g., FGSM and PGD-5). Our results indicate that limiting the object area as much as possible (i.e., from the entire image to the bounding box to the segmentation mask) leads to consistent improvement in accuracy and robustness.
Saliency detection based on structural dissimilarity induced by image quality assessment model
May 24, 2019The distinctiveness of image regions is widely used as the cue of saliency. Generally, the distinctiveness is computed according to the absolute difference of features. However, according to the image quality assessment (IQA) studies, the human visual system is highly sensitive to structural changes rather than absolute difference. Accordingly, we propose the computation of the structural dissimilarity between image patches as the distinctiveness measure for saliency detection. Similar to IQA models, the structural dissimilarity is computed based on the correlation of the structural features. The global structural dissimilarity of a patch to all the other patches represents saliency of the patch. We adopt two widely used structural features, namely the local contrast and gradient magnitude, into the structural dissimilarity computation in the proposed model. Without any postprocessing, the proposed model based on the correlation of either of the two structural features outperforms 11 state-of-the-art saliency models on three saliency databases.
* For associated source code, see https://github.com/yangli-xjtu/SDS
Multi-Instance Multi-Scale CNN for Medical Image Classification
Jul 18, 2019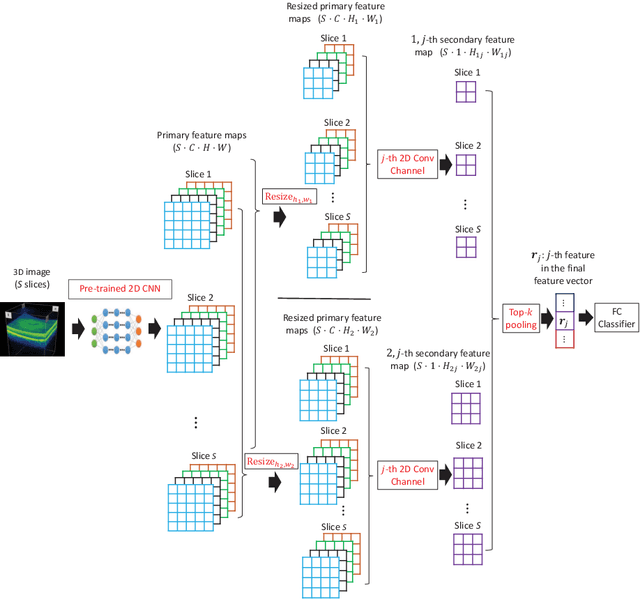
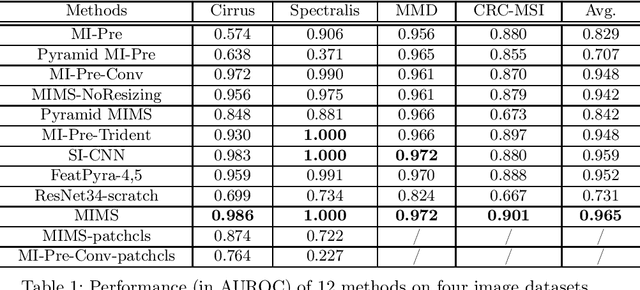
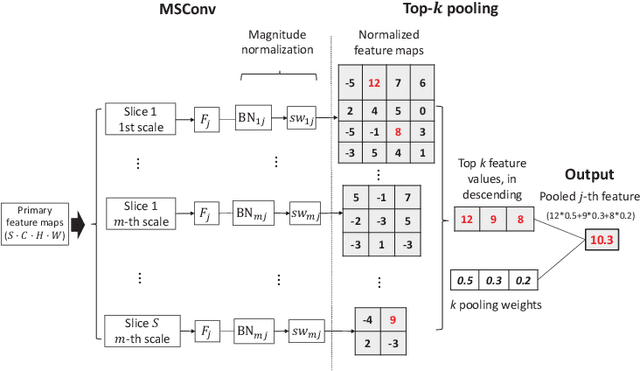

Deep learning for medical image classification faces three major challenges: 1) the number of annotated medical images for training are usually small; 2) regions of interest (ROIs) are relatively small with unclear boundaries in the whole medical images, and may appear in arbitrary positions across the x,y (and also z in 3D images) dimensions. However often only labels of the whole images are annotated, and localized ROIs are unavailable; and 3) ROIs in medical images often appear in varying sizes (scales). We approach these three challenges with a Multi-Instance Multi-Scale (MIMS) CNN: 1) We propose a multi-scale convolutional layer, which extracts patterns of different receptive fields with a shared set of convolutional kernels, so that scale-invariant patterns are captured by this compact set of kernels. As this layer contains only a small number of parameters, training on small datasets becomes feasible; 2) We propose a "top-k pooling" to aggregate the feature maps in varying scales from multiple spatial dimensions, allowing the model to be trained using weak annotations within the multiple instance learning (MIL) framework. Our method is shown to perform well on three classification tasks involving two 3D and two 2D medical image datasets.
Indoor Panorama Planar 3D Reconstruction via Divide and Conquer
Jun 27, 2021
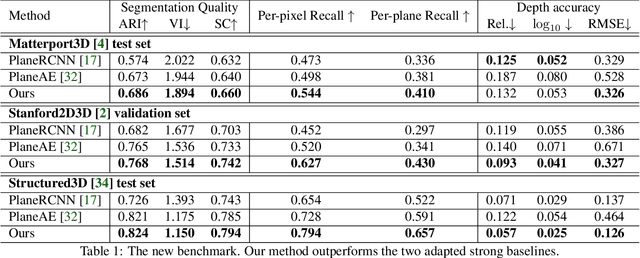
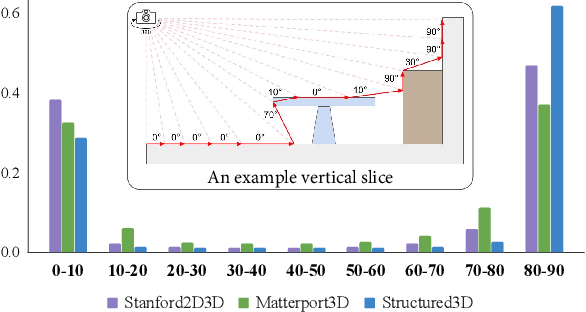
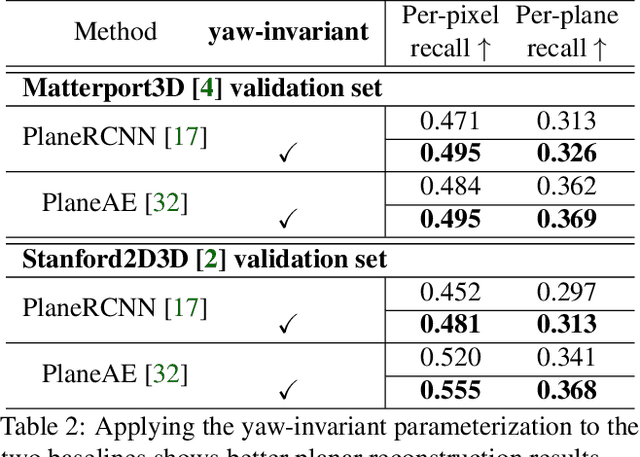
Indoor panorama typically consists of human-made structures parallel or perpendicular to gravity. We leverage this phenomenon to approximate the scene in a 360-degree image with (H)orizontal-planes and (V)ertical-planes. To this end, we propose an effective divide-and-conquer strategy that divides pixels based on their plane orientation estimation; then, the succeeding instance segmentation module conquers the task of planes clustering more easily in each plane orientation group. Besides, parameters of V-planes depend on camera yaw rotation, but translation-invariant CNNs are less aware of the yaw change. We thus propose a yaw-invariant V-planar reparameterization for CNNs to learn. We create a benchmark for indoor panorama planar reconstruction by extending existing 360 depth datasets with ground truth H\&V-planes (referred to as PanoH&V dataset) and adopt state-of-the-art planar reconstruction methods to predict H\&V-planes as our baselines. Our method outperforms the baselines by a large margin on the proposed dataset.