 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning More with Less: GAN-based Medical Image Augmentation
May 07, 2019


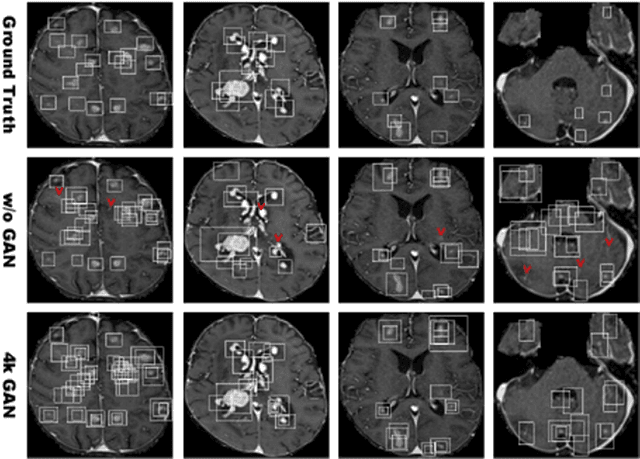
Convolutional Neural Network (CNN)-based accurate prediction typically requires large-scale annotated training data. In Medical Imaging, however, both obtaining medical data and annotating them by expert physicians are challenging; to overcome this lack of data, Data Augmentation (DA) using Generative Adversarial Networks (GANs) is essential, since they can synthesize additional annotated training data to handle small and fragmented medical images from various scanners--those generated images, realistic but completely novel, can further fill the real image distribution uncovered by the original dataset. As a tutorial, this paper introduces GAN-based Medical Image Augmentation, along with tricks to boost classification/object detection/segmentation performance using them, based on our experience and related work. Moreover, we show our first GAN-based DA work using automatic bounding box annotation, for robust CNN-based brain metastases detection on 256 x 256 MR images; GAN-based DA can boost 10% sensitivity in diagnosis with a clinically acceptable number of additional False Positives, even with highly-rough and inconsistent bounding boxes.
Image2Reverb: Cross-Modal Reverb Impulse Response Synthesis
Mar 26, 2021
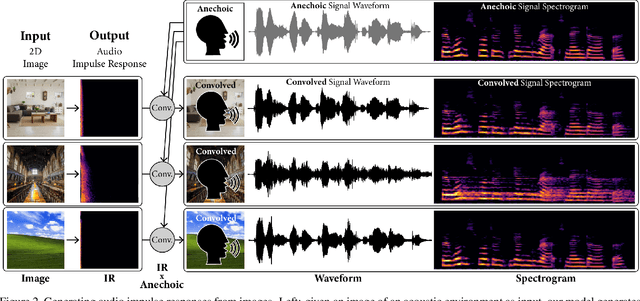
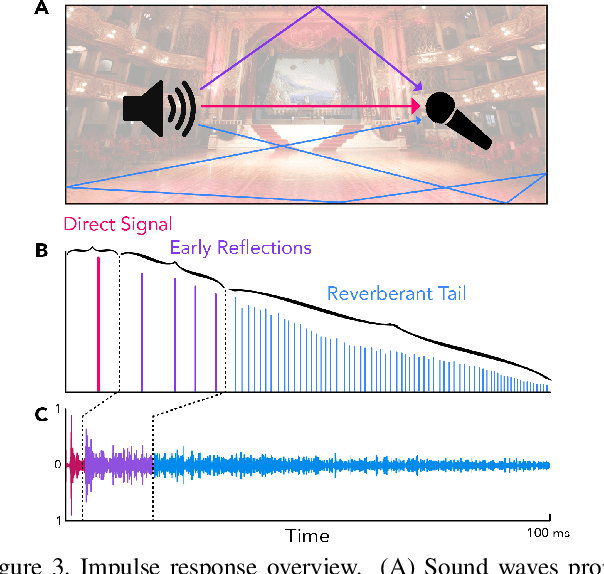
Measuring the acoustic characteristics of a space is often done by capturing its impulse response (IR), a representation of how a full-range stimulus sound excites it. This is the first work that generates an IR from a single image, which we call Image2Reverb. This IR is then applied to other signals using convolution, simulating the reverberant characteristics of the space shown in the image. Recording these IRs is both time-intensive and expensive, and often infeasible for inaccessible locations. We use an end-to-end neural network architecture to generate plausible audio impulse responses from single images of acoustic environments. We evaluate our method both by comparisons to ground truth data and by human expert evaluation. We demonstrate our approach by generating plausible impulse responses from diverse settings and formats including well known places, musical halls, rooms in paintings, images from animations and computer games, synthetic environments generated from text, panoramic images, and video conference backgrounds.
Joint Denoising and Demosaicking with Green Channel Prior for Real-world Burst Images
Jan 25, 2021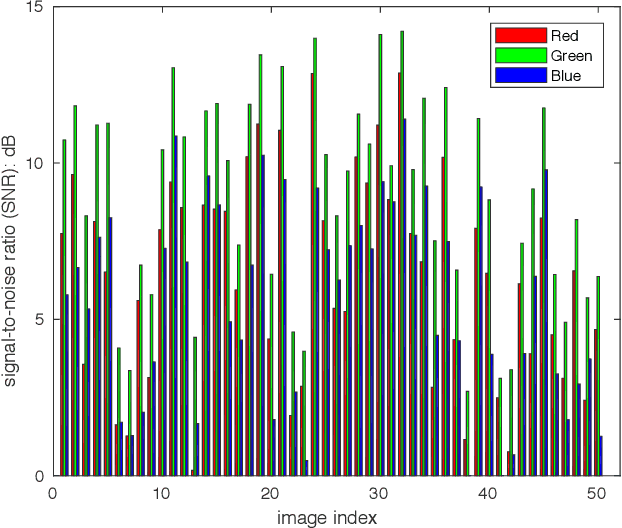


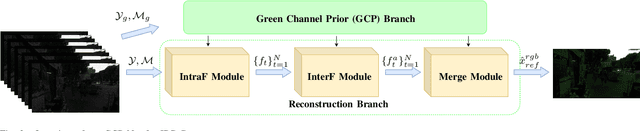
Denoising and demosaicking are essential yet correlated steps to reconstruct a full color image from the raw color filter array (CFA) data. By learning a deep convolutional neural network (CNN), significant progress has been achieved to perform denoising and demosaicking jointly. However, most existing CNN-based joint denoising and demosaicking (JDD) methods work on a single image while assuming additive white Gaussian noise, which limits their performance on real-world applications. In this work, we study the JDD problem for real-world burst images, namely JDD-B. Considering the fact that the green channel has twice the sampling rate and better quality than the red and blue channels in CFA raw data, we propose to use this green channel prior (GCP) to build a GCP-Net for the JDD-B task. In GCP-Net, the GCP features extracted from green channels are utilized to guide the feature extraction and feature upsampling of the whole image. To compensate for the shift between frames, the offset is also estimated from GCP features to reduce the impact of noise. Our GCP-Net can preserve more image structures and details than other JDD methods while removing noise. Experiments on synthetic and real-world noisy images demonstrate the effectiveness of GCP-Net quantitatively and qualitatively.
ID-Unet: Iterative Soft and Hard Deformation for View Synthesis
Mar 08, 2021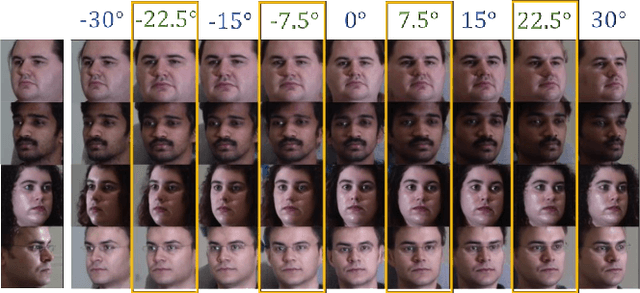
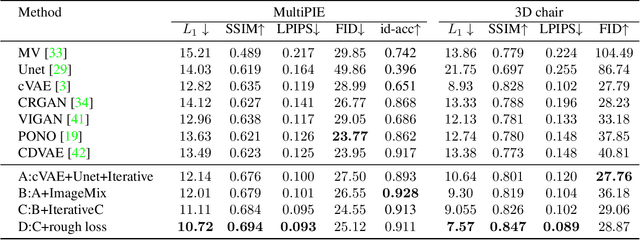
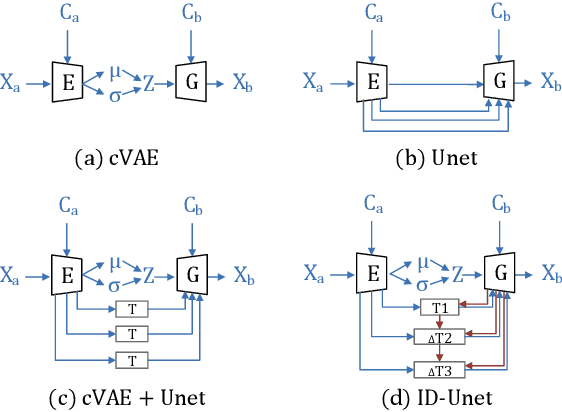
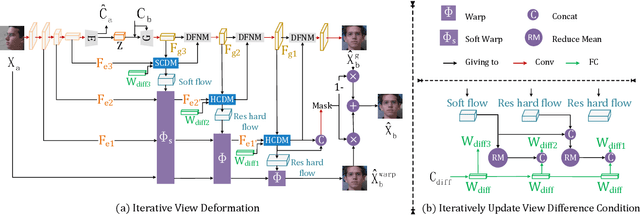
View synthesis is usually done by an autoencoder, in which the encoder maps a source view image into a latent content code, and the decoder transforms it into a target view image according to the condition. However, the source contents are often not well kept in this setting, which leads to unnecessary changes during the view translation. Although adding skipped connections, like Unet, alleviates the problem, but it often causes the failure on the view conformity. This paper proposes a new architecture by performing the source-to-target deformation in an iterative way. Instead of simply incorporating the features from multiple layers of the encoder, we design soft and hard deformation modules, which warp the encoder features to the target view at different resolutions, and give results to the decoder to complement the details. Particularly, the current warping flow is not only used to align the feature of the same resolution, but also as an approximation to coarsely deform the high resolution feature. Then the residual flow is estimated and applied in the high resolution, so that the deformation is built up in the coarse-to-fine fashion. To better constrain the model, we synthesize a rough target view image based on the intermediate flows and their warped features. The extensive ablation studies and the final results on two different data sets show the effectiveness of the proposed model.
The Hitchhiker's Guide to Prior-Shift Adaptation
Jun 22, 2021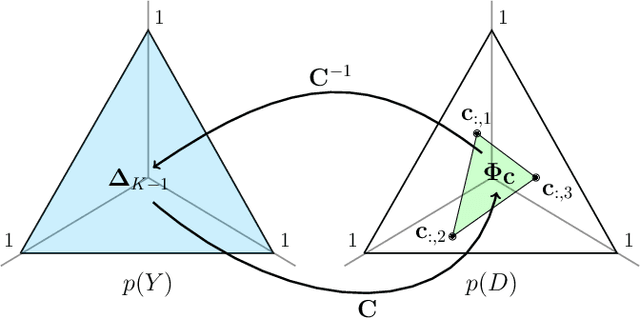
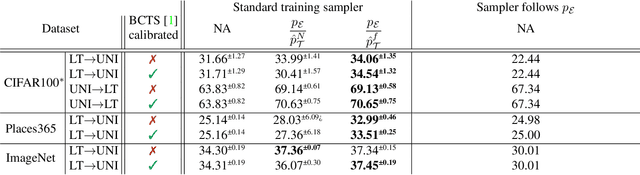
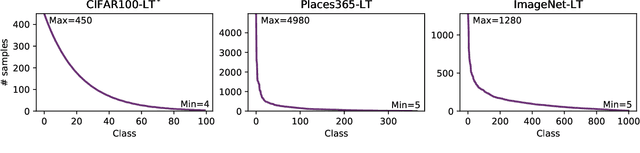
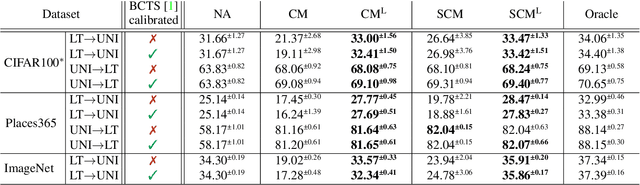
In many computer vision classification tasks, class priors at test time often differ from priors on the training set. In the case of such prior shift, classifiers must be adapted correspondingly to maintain close to optimal performance. This paper analyzes methods for adaptation of probabilistic classifiers to new priors and for estimating new priors on an unlabeled test set. We propose a novel method to address a known issue of prior estimation methods based on confusion matrices, where inconsistent estimates of decision probabilities and confusion matrices lead to negative values in the estimated priors. Experiments on fine-grained image classification datasets provide insight into the best practice of prior shift estimation and classifier adaptation and show that the proposed method achieves state-of-the-art results in prior adaptation. Applying the best practice to two tasks with naturally imbalanced priors, learning from web-crawled images and plant species classification, increased the recognition accuracy by 1.1% and 3.4% respectively.
Kanerva++: extending The Kanerva Machine with differentiable, locally block allocated latent memory
Feb 20, 2021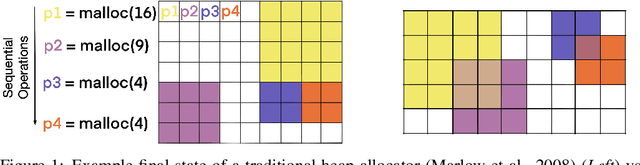
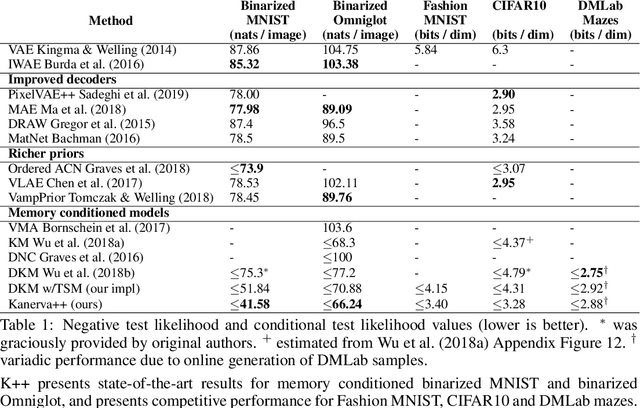
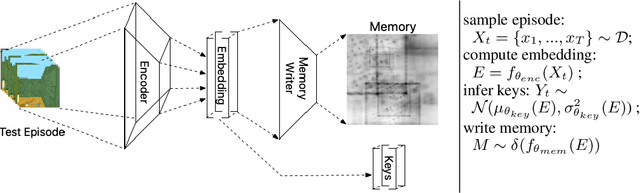
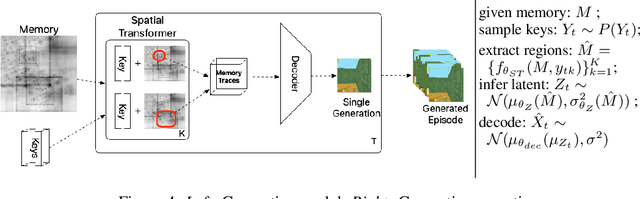
Episodic and semantic memory are critical components of the human memory model. The theory of complementary learning systems (McClelland et al., 1995) suggests that the compressed representation produced by a serial event (episodic memory) is later restructured to build a more generalized form of reusable knowledge (semantic memory). In this work we develop a new principled Bayesian memory allocation scheme that bridges the gap between episodic and semantic memory via a hierarchical latent variable model. We take inspiration from traditional heap allocation and extend the idea of locally contiguous memory to the Kanerva Machine, enabling a novel differentiable block allocated latent memory. In contrast to the Kanerva Machine, we simplify the process of memory writing by treating it as a fully feed forward deterministic process, relying on the stochasticity of the read key distribution to disperse information within the memory. We demonstrate that this allocation scheme improves performance in conditional image generation, resulting in new state-of-the-art likelihood values on binarized MNIST (<=41.58 nats/image) , binarized Omniglot (<=66.24 nats/image), as well as presenting competitive performance on CIFAR10, DMLab Mazes, Celeb-A and ImageNet32x32.
Vision-Guided Active Tactile Perception for Crack Detection and Reconstruction
May 13, 2021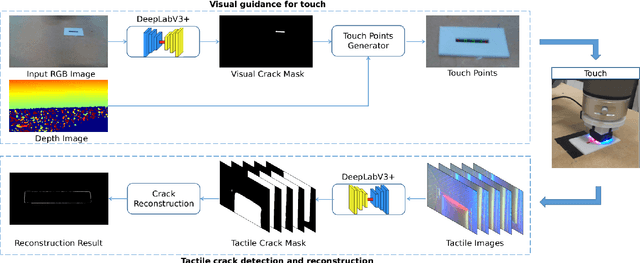
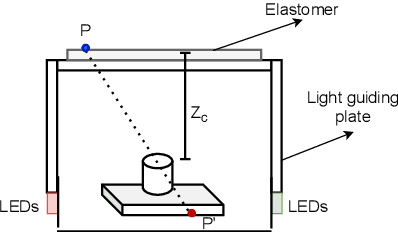


Crack detection is of great significance for monitoring the integrity and well-being of the infrastructure such as bridges and underground pipelines, which are harsh environments for people to access. In recent years, computer vision techniques have been applied in detecting cracks in concrete structures. However, they suffer from variances in light conditions and shadows, lacking robustness and resulting in many false positives. To address the uncertainty in vision, human inspectors actively touch the surface of the structures, guided by vision, which has not been explored in autonomous crack detection. In this paper, we propose a novel approach to detect and reconstruct cracks in concrete structures using vision-guided active tactile perception. Given an RGB-D image of a structure, the rough profile of the crack in the structure surface will first be segmented with a fine-tuned Deep Convolutional Neural Networks, and a set of contact points are generated to guide the collection of tactile images by a camera-based optical tactile sensor. When contacts are made, a pixel-wise mask of the crack can be obtained from the tactile images and therefore the profile of the crack can be refined by aligning the RGB-D image and the tactile images. Extensive experiment results have shown that the proposed method improves the effectiveness and robustness of crack detection and reconstruction significantly, compared to crack detection with vision only, and has the potential to enable robots to help humans with the inspection and repair of the concrete infrastructure.
StyleCariGAN: Caricature Generation via StyleGAN Feature Map Modulation
Jul 09, 2021
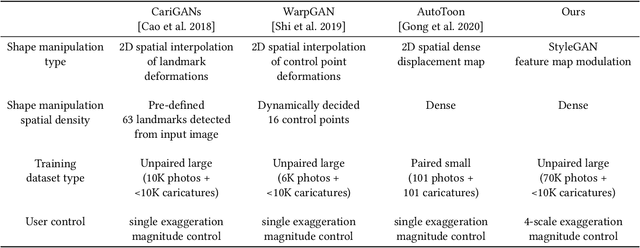


We present a caricature generation framework based on shape and style manipulation using StyleGAN. Our framework, dubbed StyleCariGAN, automatically creates a realistic and detailed caricature from an input photo with optional controls on shape exaggeration degree and color stylization type. The key component of our method is shape exaggeration blocks that are used for modulating coarse layer feature maps of StyleGAN to produce desirable caricature shape exaggerations. We first build a layer-mixed StyleGAN for photo-to-caricature style conversion by swapping fine layers of the StyleGAN for photos to the corresponding layers of the StyleGAN trained to generate caricatures. Given an input photo, the layer-mixed model produces detailed color stylization for a caricature but without shape exaggerations. We then append shape exaggeration blocks to the coarse layers of the layer-mixed model and train the blocks to create shape exaggerations while preserving the characteristic appearances of the input. Experimental results show that our StyleCariGAN generates realistic and detailed caricatures compared to the current state-of-the-art methods. We demonstrate StyleCariGAN also supports other StyleGAN-based image manipulations, such as facial expression control.
* Accepted to SIGGRAPH 2021. For supplementary material, see http://cg.postech.ac.kr/papers/2021_StyleCariGAN_supp.zip
Self-Supervised Iterative Contextual Smoothing for Efficient Adversarial Defense against Gray- and Black-Box Attack
Jun 22, 2021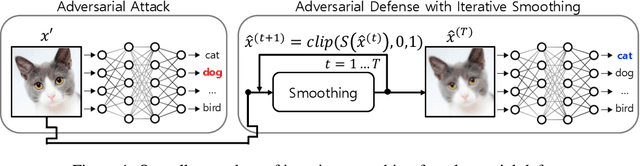
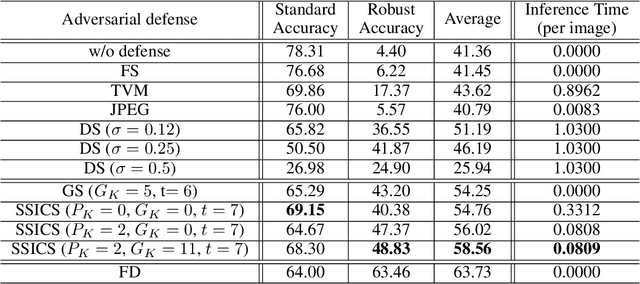
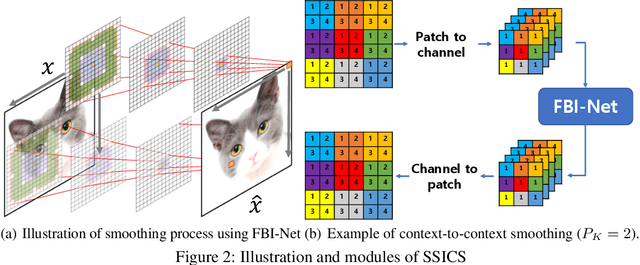
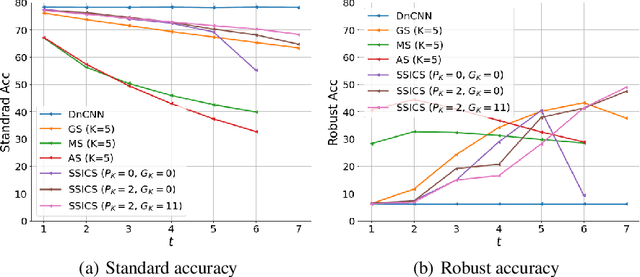
We propose a novel and effective input transformation based adversarial defense method against gray- and black-box attack, which is computationally efficient and does not require any adversarial training or retraining of a classification model. We first show that a very simple iterative Gaussian smoothing can effectively wash out adversarial noise and achieve substantially high robust accuracy. Based on the observation, we propose Self-Supervised Iterative Contextual Smoothing (SSICS), which aims to reconstruct the original discriminative features from the Gaussian-smoothed image in context-adaptive manner, while still smoothing out the adversarial noise. From the experiments on ImageNet, we show that our SSICS achieves both high standard accuracy and very competitive robust accuracy for the gray- and black-box attacks; e.g., transfer-based PGD-attack and score-based attack. A note-worthy point to stress is that our defense is free of computationally expensive adversarial training, yet, can approach its robust accuracy via input transformation.
Pan-Cancer Integrative Histology-Genomic Analysis via Interpretable Multimodal Deep Learning
Aug 04, 2021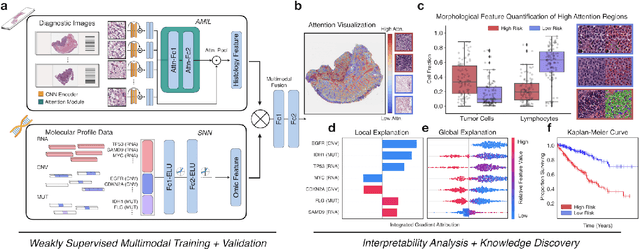
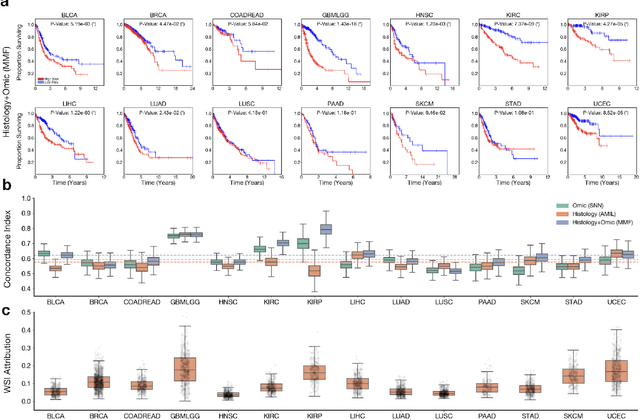
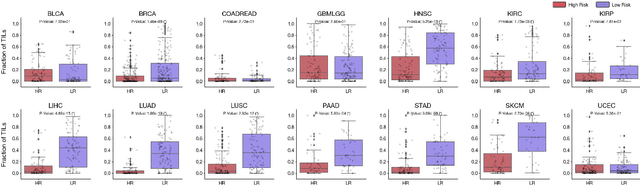
The rapidly emerging field of deep learning-based computational pathology has demonstrated promise in developing objective prognostic models from histology whole slide images. However, most prognostic models are either based on histology or genomics alone and do not address how histology and genomics can be integrated to develop joint image-omic prognostic models. Additionally identifying explainable morphological and molecular descriptors from these models that govern such prognosis is of interest. We used multimodal deep learning to integrate gigapixel whole slide pathology images, RNA-seq abundance, copy number variation, and mutation data from 5,720 patients across 14 major cancer types. Our interpretable, weakly-supervised, multimodal deep learning algorithm is able to fuse these heterogeneous modalities for predicting outcomes and discover prognostic features from these modalities that corroborate with poor and favorable outcomes via multimodal interpretability. We compared our model with unimodal deep learning models trained on histology slides and molecular profiles alone, and demonstrate performance increase in risk stratification on 9 out of 14 cancers. In addition, we analyze morphologic and molecular markers responsible for prognostic predictions across all cancer types. All analyzed data, including morphological and molecular correlates of patient prognosis across the 14 cancer types at a disease and patient level are presented in an interactive open-access database (http://pancancer.mahmoodlab.org) to allow for further exploration and prognostic biomarker discovery. To validate that these model explanations are prognostic, we further analyzed high attention morphological regions in WSIs, which indicates that tumor-infiltrating lymphocyte presence corroborates with favorable cancer prognosis on 9 out of 14 cancer types studied.