 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Aggregation of Regional Convolutional Activations for Content Based Image Retrieval
Sep 20, 2019




One of the key challenges of deep learning based image retrieval remains in aggregating convolutional activations into one highly representative feature vector. Ideally, this descriptor should encode semantic, spatial and low level information. Even though off-the-shelf pre-trained neural networks can already produce good representations in combination with aggregation methods, appropriate fine tuning for the task of image retrieval has shown to significantly boost retrieval performance. In this paper, we present a simple yet effective supervised aggregation method built on top of existing regional pooling approaches. In addition to the maximum activation of a given region, we calculate regional average activations of extracted feature maps. Subsequently, weights for each of the pooled feature vectors are learned to perform a weighted aggregation to a single feature vector. Furthermore, we apply our newly proposed NRA loss function for deep metric learning to fine tune the backbone neural network and to learn the aggregation weights. Our method achieves state-of-the-art results for the INRIA Holidays data set and competitive results for the Oxford Buildings and Paris data sets while reducing the training time significantly.
CHEF: A Cheap and Fast Pipeline for Iteratively Cleaning Label Uncertainties (Technical Report)
Jul 24, 2021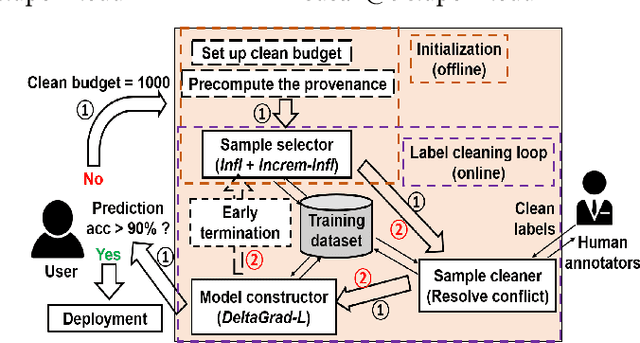
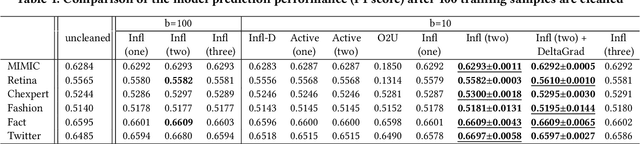
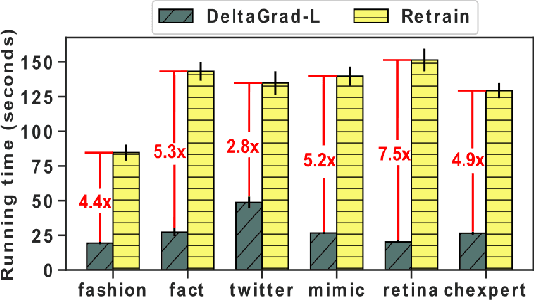
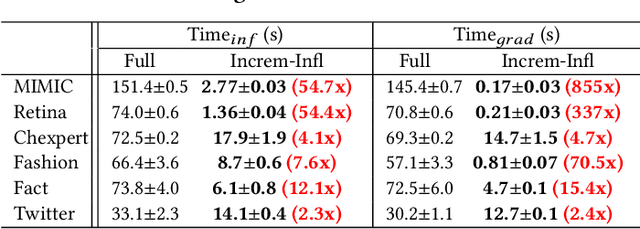
High-quality labels are expensive to obtain for many machine learning tasks, such as medical image classification tasks. Therefore, probabilistic (weak) labels produced by weak supervision tools are used to seed a process in which influential samples with weak labels are identified and cleaned by several human annotators to improve the model performance. To lower the overall cost and computational overhead of this process, we propose a solution called CHEF (CHEap and Fast label cleaning), which consists of the following three components. First, to reduce the cost of human annotators, we use Infl, which prioritizes the most influential training samples for cleaning and provides cleaned labels to save the cost of one human annotator. Second, to accelerate the sample selector phase and the model constructor phase, we use Increm-Infl to incrementally produce influential samples, and DeltaGrad-L to incrementally update the model. Third, we redesign the typical label cleaning pipeline so that human annotators iteratively clean smaller batch of samples rather than one big batch of samples. This yields better over all model performance and enables possible early termination when the expected model performance has been achieved. Extensive experiments show that our approach gives good model prediction performance while achieving significant speed-ups.
RGB Stream Is Enough for Temporal Action Detection
Jul 09, 2021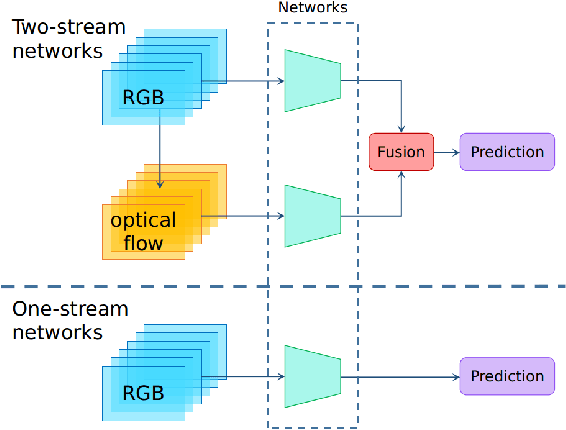
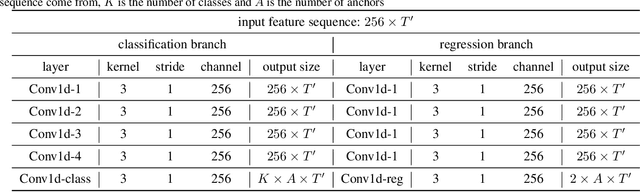
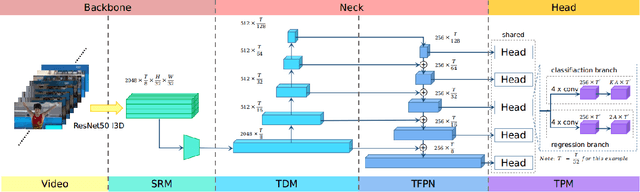
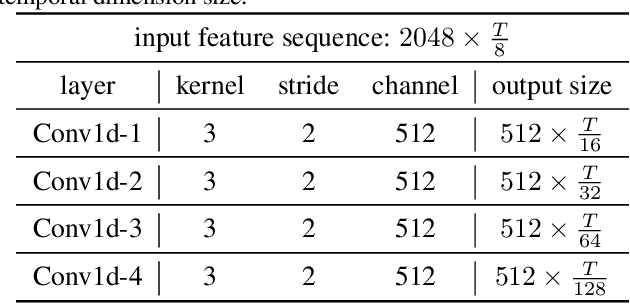
State-of-the-art temporal action detectors to date are based on two-stream input including RGB frames and optical flow. Although combining RGB frames and optical flow boosts performance significantly, optical flow is a hand-designed representation which not only requires heavy computation, but also makes it methodologically unsatisfactory that two-stream methods are often not learned end-to-end jointly with the flow. In this paper, we argue that optical flow is dispensable in high-accuracy temporal action detection and image level data augmentation (ILDA) is the key solution to avoid performance degradation when optical flow is removed. To evaluate the effectiveness of ILDA, we design a simple yet efficient one-stage temporal action detector based on single RGB stream named DaoTAD. Our results show that when trained with ILDA, DaoTAD has comparable accuracy with all existing state-of-the-art two-stream detectors while surpassing the inference speed of previous methods by a large margin and the inference speed is astounding 6668 fps on GeForce GTX 1080 Ti. Code is available at \url{https://github.com/Media-Smart/vedatad}.
Adversarial Relighting against Face Recognition
Aug 18, 2021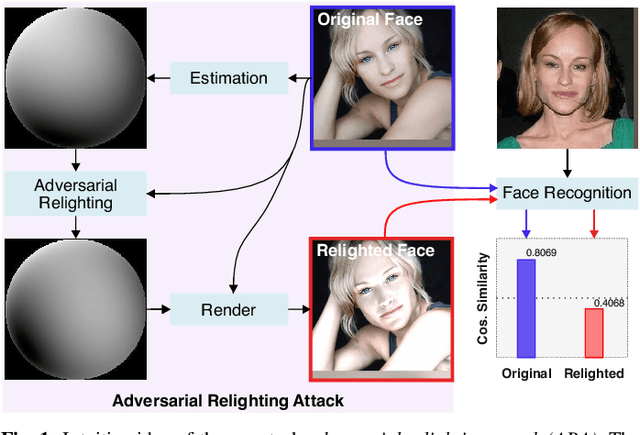

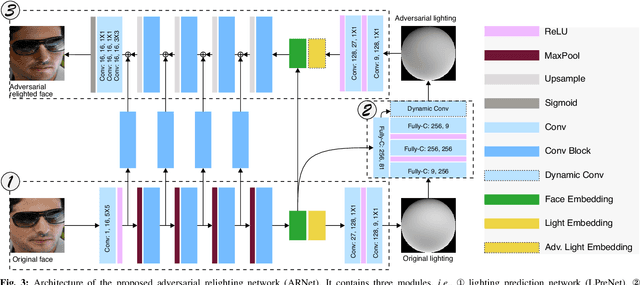
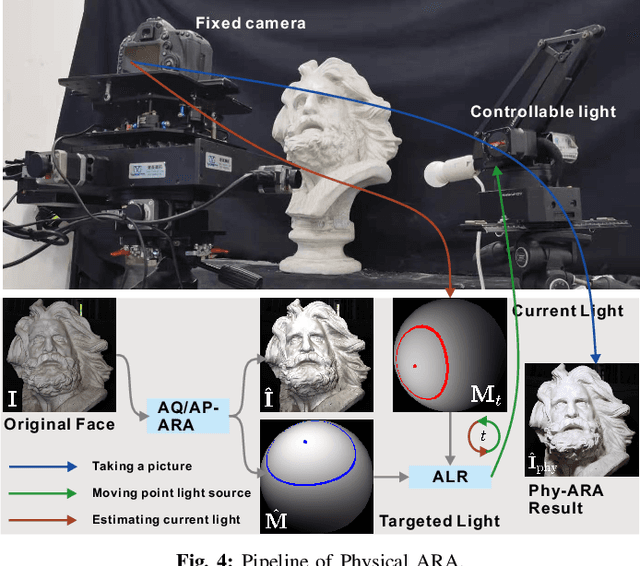
Deep face recognition (FR) has achieved significantly high accuracy on several challenging datasets and fosters successful real-world applications, even showing high robustness to the illumination variation that is usually regarded as a main threat to the FR system. However, in the real world, illumination variation caused by diverse lighting conditions cannot be fully covered by the limited face dataset. In this paper, we study the threat of lighting against FR from a new angle, i.e., adversarial attack, and identify a new task, i.e., adversarial relighting. Given a face image, adversarial relighting aims to produce a naturally relighted counterpart while fooling the state-of-the-art deep FR methods. To this end, we first propose the physical model-based adversarial relighting attack (ARA) denoted as albedo-quotient-based adversarial relighting attack (AQ-ARA). It generates natural adversarial light under the physical lighting model and guidance of FR systems and synthesizes adversarially relighted face images. Moreover, we propose the auto-predictive adversarial relighting attack (AP-ARA) by training an adversarial relighting network (ARNet) to automatically predict the adversarial light in a one-step manner according to different input faces, allowing efficiency-sensitive applications. More importantly, we propose to transfer the above digital attacks to physical ARA (Phy-ARA) through a precise relighting device, making the estimated adversarial lighting condition reproducible in the real world. We validate our methods on three state-of-the-art deep FR methods, i.e., FaceNet, ArcFace, and CosFace, on two public datasets. The extensive and insightful results demonstrate our work can generate realistic adversarial relighted face images fooling FR easily, revealing the threat of specific light directions and strengths.
Data augmentation in Bayesian neural networks and the cold posterior effect
Jun 10, 2021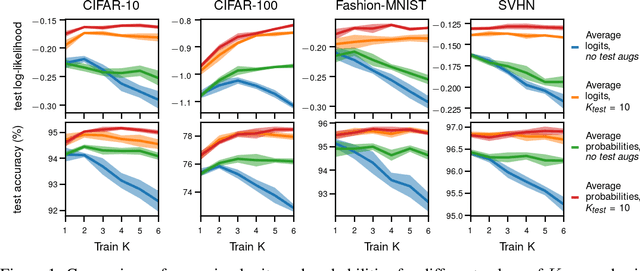
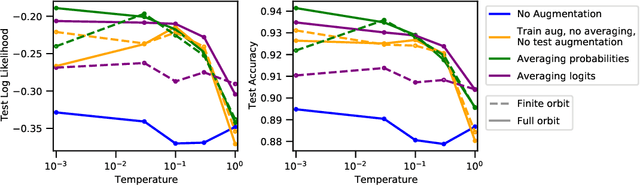
Data augmentation is a highly effective approach for improving performance in deep neural networks. The standard view is that it creates an enlarged dataset by adding synthetic data, which raises a problem when combining it with Bayesian inference: how much data are we really conditioning on? This question is particularly relevant to recent observations linking data augmentation to the cold posterior effect. We investigate various principled ways of finding a log-likelihood for augmented datasets. Our approach prescribes augmenting the same underlying image multiple times, both at test and train-time, and averaging either the logits or the predictive probabilities. Empirically, we observe the best performance with averaging probabilities. While there are interactions with the cold posterior effect, neither averaging logits or averaging probabilities eliminates it.
A Survey of Modern Deep Learning based Object Detection Models
May 12, 2021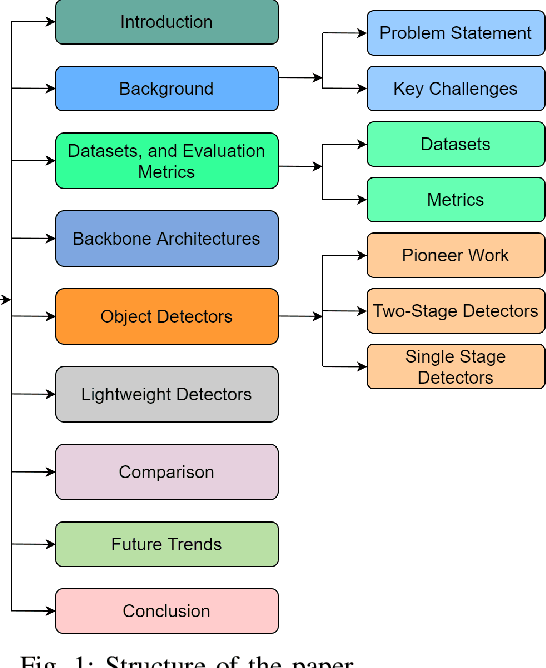


Object Detection is the task of classification and localization of objects in an image or video. It has gained prominence in recent years due to its widespread applications. This article surveys recent developments in deep learning based object detectors. Concise overview of benchmark datasets and evaluation metrics used in detection is also provided along with some of the prominent backbone architectures used in recognition tasks. It also covers contemporary lightweight classification models used on edge devices. Lastly, we compare the performances of these architectures on multiple metrics.
Evidential fully convolutional network for semantic segmentation
Mar 25, 2021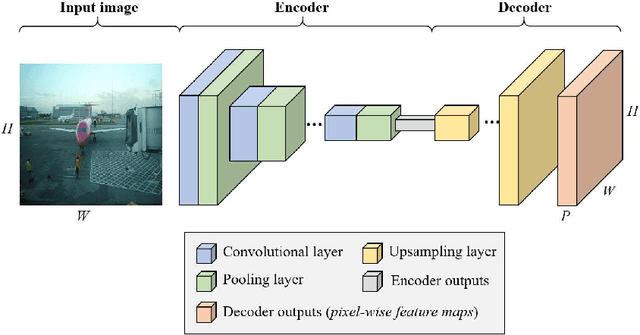

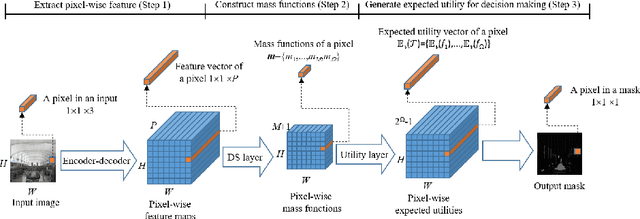

We propose a hybrid architecture composed of a fully convolutional network (FCN) and a Dempster-Shafer layer for image semantic segmentation. In the so-called evidential FCN (E-FCN), an encoder-decoder architecture first extracts pixel-wise feature maps from an input image. A Dempster-Shafer layer then computes mass functions at each pixel location based on distances to prototypes. Finally, a utility layer performs semantic segmentation from mass functions and allows for imprecise classification of ambiguous pixels and outliers. We propose an end-to-end learning strategy for jointly updating the network parameters, which can make use of soft (imprecise) labels. Experiments using three databases (Pascal VOC 2011, MIT-scene Parsing and SIFT Flow) show that the proposed combination improves the accuracy and calibration of semantic segmentation by assigning confusing pixels to multi-class sets.
Calibration based Minimalistic Multi-Exposure Digital Sensor Camera Robust Linear High Dynamic Range Enhancement Technique Demonstration
Jan 14, 2021
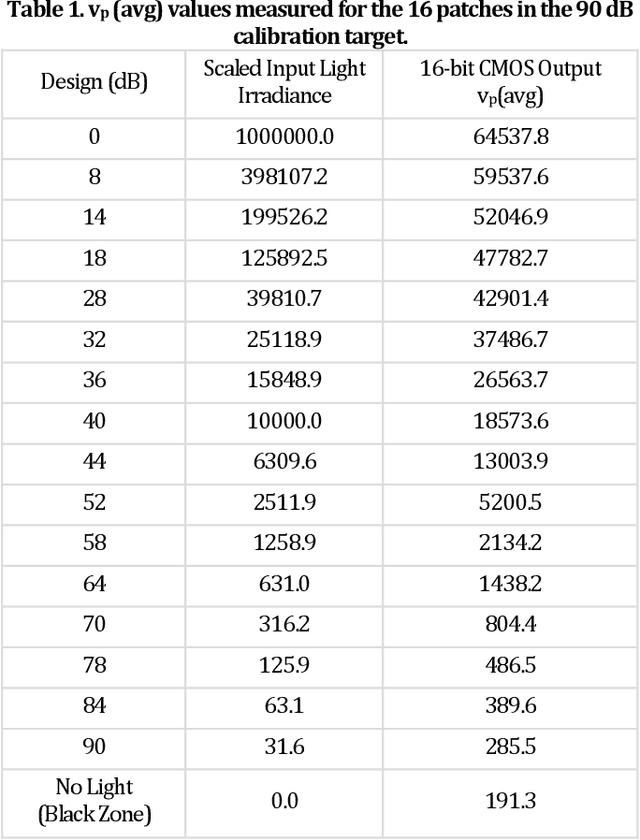

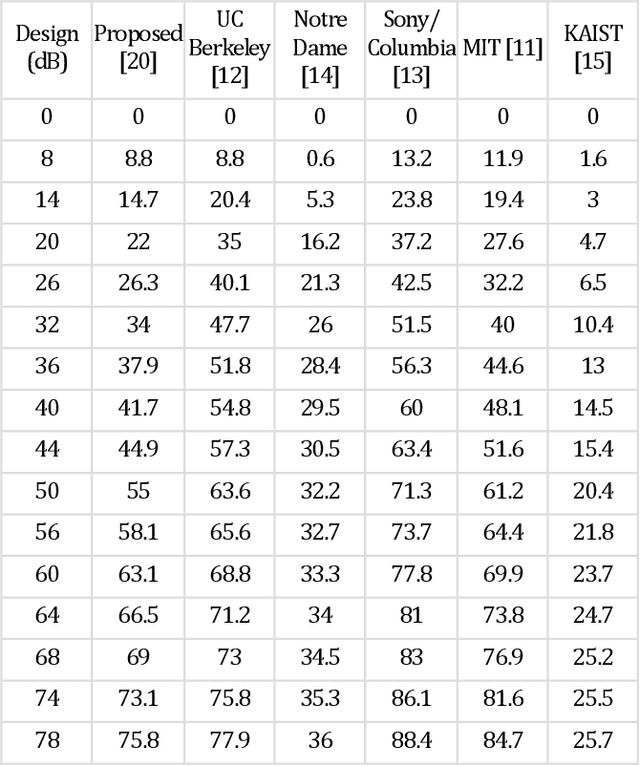
Demonstrated for a digital image sensor based camera is a calibration target optimized method for finding the Camera Response Function (CRF). The proposed method uses localized known target zone pixel outputs spatial averaging and histogram analysis for saturated pixel detection. Using the proposed CRF generation method with a 87 dB High Dynamic Range (HDR) silicon CMOS image sensor camera viewing a 90 dB HDR calibration target, experimentally produced is a non-linear CRF with a limited 40 dB linear CRF zone. Next, a 78 dB test target is deployed to test the camera with this measured CRF and its restricted 40 dB zone. By engaging the proposed minimal exposures, weighting free, multi-exposure imaging method with 2 images, demonstrated is a highly robust recovery of the test target. In addition, the 78 dB test target recovery with 16 individual DR value patches stays robust over a factor of 20 change in test target illumination lighting. In comparison, a non-robust test target image recovery is produced by 5 leading prior-art multi-exposure HDR recovery algorithms using 16 images having 16 different exposure times, with each consecutive image having a sensor dwell time increasing by a factor of 2. Further validation of the proposed HDR image recovery method is provided using two additional experiments, the first using a 78 dB calibrated target combined with a natural indoor scene to form a hybrid design target and a second experiment using an uncalibrated indoor natural scene. The proposed technique applies to all digital image sensor based cameras having exposure time and illumination controls. In addition, the proposed methods apply to various sensor technologies, spectral bands, and imaging applications.
AIRD: Adversarial Learning Framework for Image Repurposing Detection
Apr 09, 2019
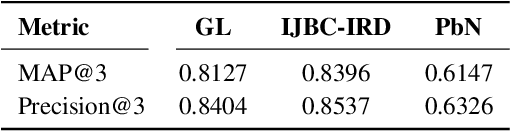
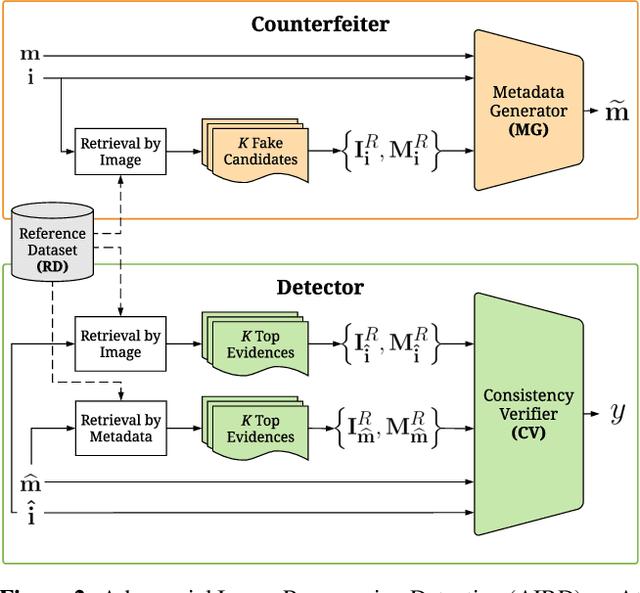
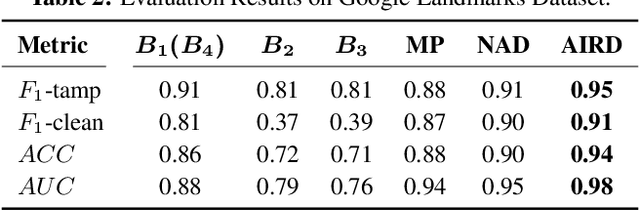
Image repurposing is a commonly used method for spreading misinformation on social media and online forums, which involves publishing untampered images with modified metadata to create rumors and further propaganda. While manual verification is possible, given vast amounts of verified knowledge available on the internet, the increasing prevalence and ease of this form of semantic manipulation call for the development of robust automatic ways of assessing the semantic integrity of multimedia data. In this paper, we present a novel method for image repurposing detection that is based on the real-world adversarial interplay between a bad actor who repurposes images with counterfeit metadata and a watchdog who verifies the semantic consistency between images and their accompanying metadata, where both players have access to a reference dataset of verified content, which they can use to achieve their goals. The proposed method exhibits state-of-the-art performance on location-identity, subject-identity and painting-artist verification, showing its efficacy across a diverse set of scenarios.
Extraction of Key-frames of Endoscopic Videos by using Depth Information
Jun 30, 2021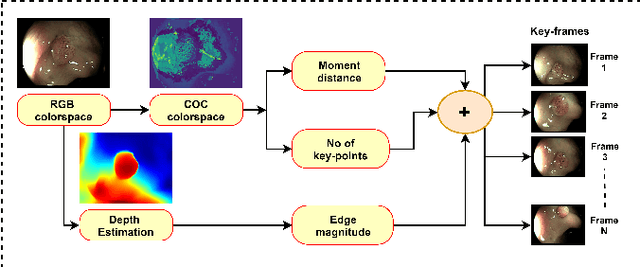
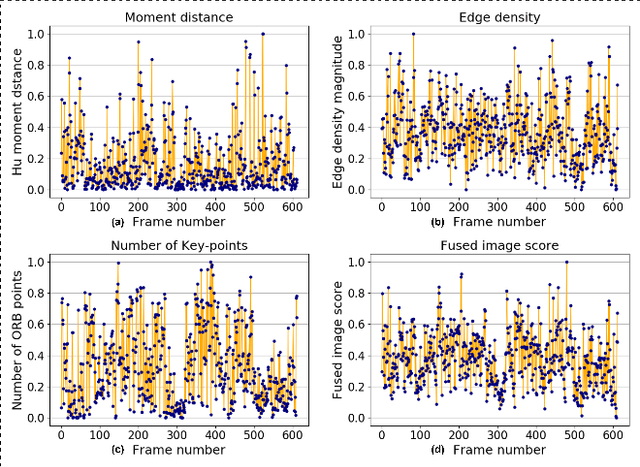
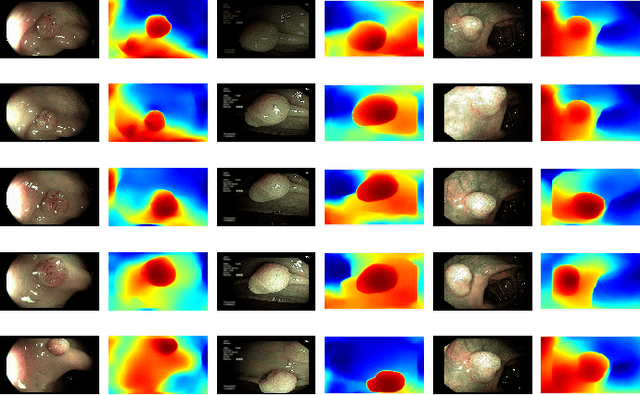

A deep learning-based monocular depth estimation (MDE) technique is proposed for selection of most informative frames (key frames) of an endoscopic video. In most of the cases, ground truth depth maps of polyps are not readily available and that is why the transfer learning approach is adopted in our method. An endoscopic modalities generally capture thousands of frames. In this scenario, it is quite important to discard low-quality and clinically irrelevant frames of an endoscopic video while the most informative frames should be retained for clinical diagnosis. In this view, a key-frame selection strategy is proposed by utilizing the depth information of polyps. In our method, image moment, edge magnitude, and key-points are considered for adaptively selecting the key frames. One important application of our proposed method could be the 3D reconstruction of polyps with the help of extracted key frames. Also, polyps are localized with the help of extracted depth maps.