 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Probabilistic and Geometric Depth: Detecting Objects in Perspective
Jul 29, 2021
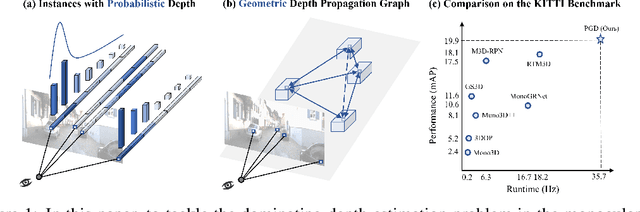
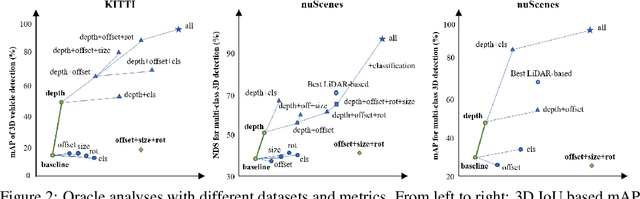
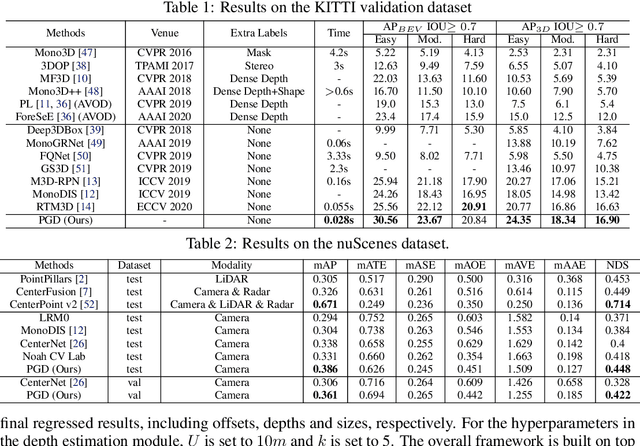
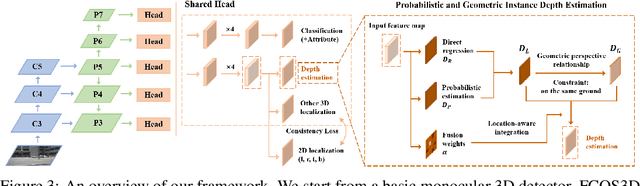
3D object detection is an important capability needed in various practical applications such as driver assistance systems. Monocular 3D detection, as an economical solution compared to conventional settings relying on binocular vision or LiDAR, has drawn increasing attention recently but still yields unsatisfactory results. This paper first presents a systematic study on this problem and observes that the current monocular 3D detection problem can be simplified as an instance depth estimation problem: The inaccurate instance depth blocks all the other 3D attribute predictions from improving the overall detection performance. However, recent methods directly estimate the depth based on isolated instances or pixels while ignoring the geometric relations across different objects, which can be valuable constraints as the key information about depth is not directly manifest in the monocular image. Therefore, we construct geometric relation graphs across predicted objects and use the graph to facilitate depth estimation. As the preliminary depth estimation of each instance is usually inaccurate in this ill-posed setting, we incorporate a probabilistic representation to capture the uncertainty. It provides an important indicator to identify confident predictions and further guide the depth propagation. Despite the simplicity of the basic idea, our method obtains significant improvements on KITTI and nuScenes benchmarks, achieving the 1st place out of all monocular vision-only methods while still maintaining real-time efficiency. Code and models will be released at https://github.com/open-mmlab/mmdetection3d.
Rethinking Text Line Recognition Models
Apr 21, 2021
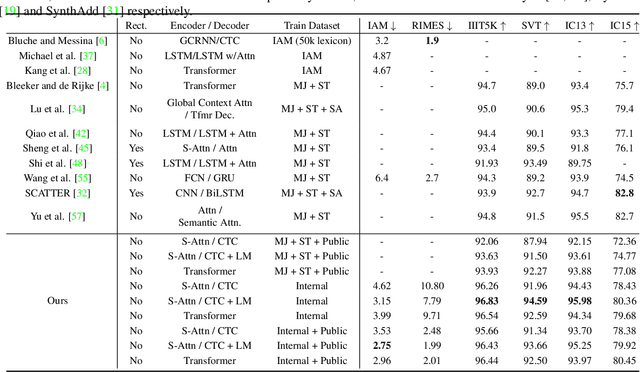

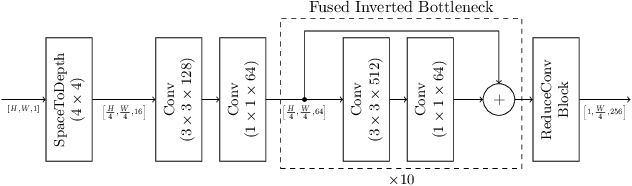
In this paper, we study the problem of text line recognition. Unlike most approaches targeting specific domains such as scene-text or handwritten documents, we investigate the general problem of developing a universal architecture that can extract text from any image, regardless of source or input modality. We consider two decoder families (Connectionist Temporal Classification and Transformer) and three encoder modules (Bidirectional LSTMs, Self-Attention, and GRCLs), and conduct extensive experiments to compare their accuracy and performance on widely used public datasets of scene and handwritten text. We find that a combination that so far has received little attention in the literature, namely a Self-Attention encoder coupled with the CTC decoder, when compounded with an external language model and trained on both public and internal data, outperforms all the others in accuracy and computational complexity. Unlike the more common Transformer-based models, this architecture can handle inputs of arbitrary length, a requirement for universal line recognition. Using an internal dataset collected from multiple sources, we also expose the limitations of current public datasets in evaluating the accuracy of line recognizers, as the relatively narrow image width and sequence length distributions do not allow to observe the quality degradation of the Transformer approach when applied to the transcription of long lines.
Adaptivity without Compromise: A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization
Jan 26, 2021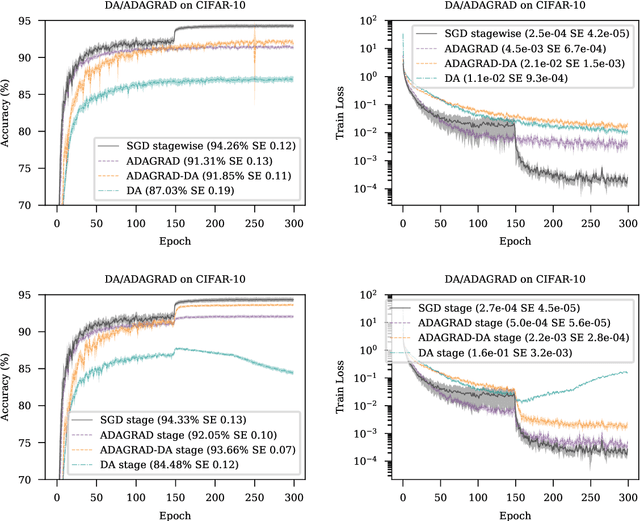
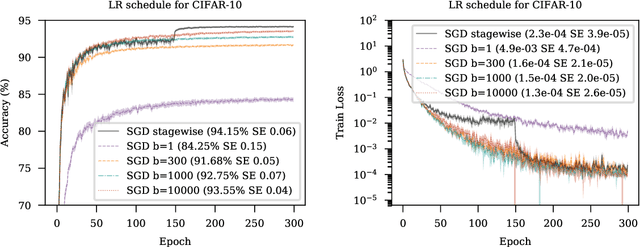
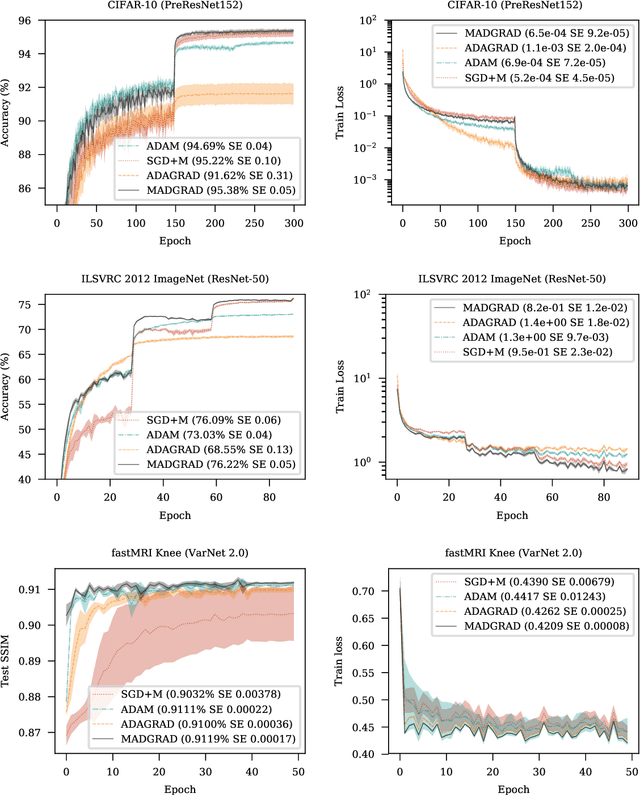
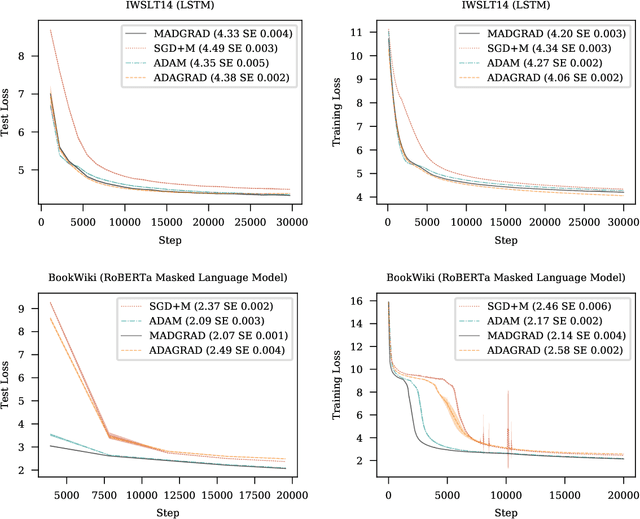
We introduce MADGRAD, a novel optimization method in the family of AdaGrad adaptive gradient methods. MADGRAD shows excellent performance on deep learning optimization problems from multiple fields, including classification and image-to-image tasks in vision, and recurrent and bidirectionally-masked models in natural language processing. For each of these tasks, MADGRAD matches or outperforms both SGD and ADAM in test set performance, even on problems for which adaptive methods normally perform poorly.
Hand-Drawn Electrical Circuit Recognition using Object Detection and Node Recognition
Jun 22, 2021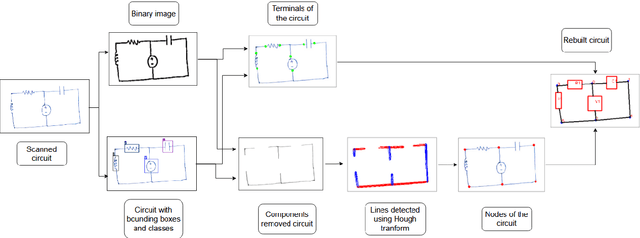
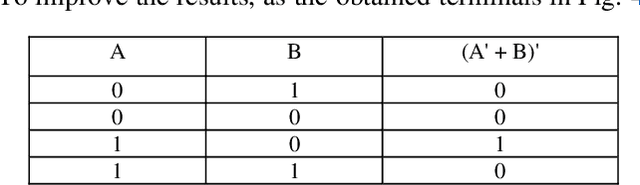

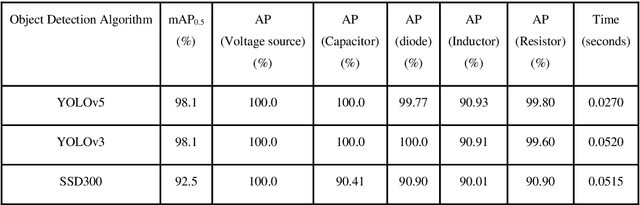
With the recent developments in neural networks, there has been a resurgence in algorithms for the automatic generation of simulation ready electronic circuits from hand-drawn circuits. However, most of the approaches in literature were confined to classify different types of electrical components and only a few of those methods have shown a way to rebuild the circuit schematic from the scanned image, which is extremely important for further automation of netlist generation. This paper proposes a real-time algorithm for the automatic recognition of hand-drawn electrical circuits based on object detection and circuit node recognition. The proposed approach employs You Only Look Once version 5 (YOLOv5) for detection of circuit components and a novel Hough transform based approach for node recognition. Using YOLOv5 object detection algorithm, a mean average precision (mAP0.5) of 98.2% is achieved in detecting the components. The proposed method is also able to rebuild the circuit schematic with 80% accuracy.
Semantic Feature Matching for Robust Mapping in Agriculture
Jul 09, 2021
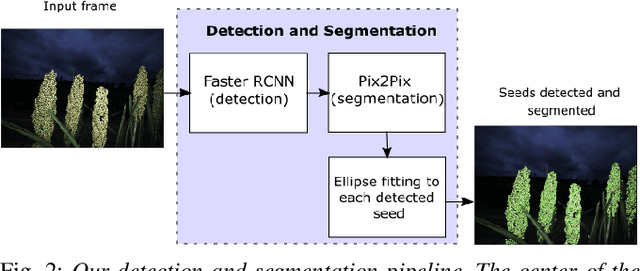
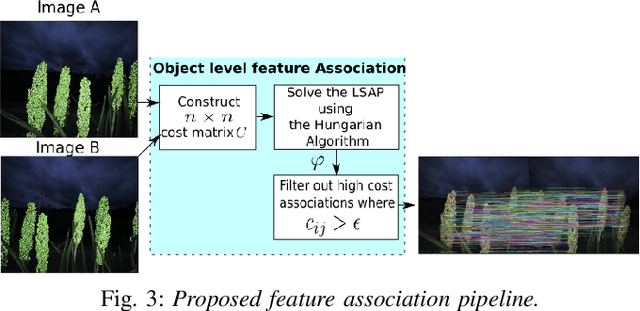
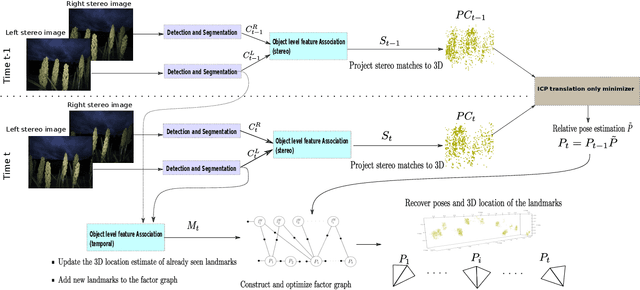
Visual Simultaneous Localization and Mapping (SLAM) systems are an essential component in agricultural robotics that enable autonomous navigation and the construction of accurate 3D maps of agricultural fields. However, lack of texture, varying illumination conditions, and lack of structure in the environment pose a challenge for Visual-SLAM systems that rely on traditional feature extraction and matching algorithms such as ORB or SIFT. This paper proposes 1) an object-level feature association algorithm that enables the creation of 3D reconstructions robustly by taking advantage of the structure in robotic navigation in agricultural fields, and 2) An object-level SLAM system that utilizes recent advances in deep learning-based object detection and segmentation algorithms to detect and segment semantic objects in the environment used as landmarks for SLAM. We test our SLAM system on a stereo image dataset of a sorghum field. We show that our object-based feature association algorithm enables us to map 78% of a sorghum range on average. In contrast, with traditional visual features, we achieve an average mapped distance of 38%. We also compare our system against ORB-SLAM2, a state-of-the-art visual SLAM algorithm.
Deep Face Image Retrieval: a Comparative Study with Dictionary Learning
Dec 13, 2018
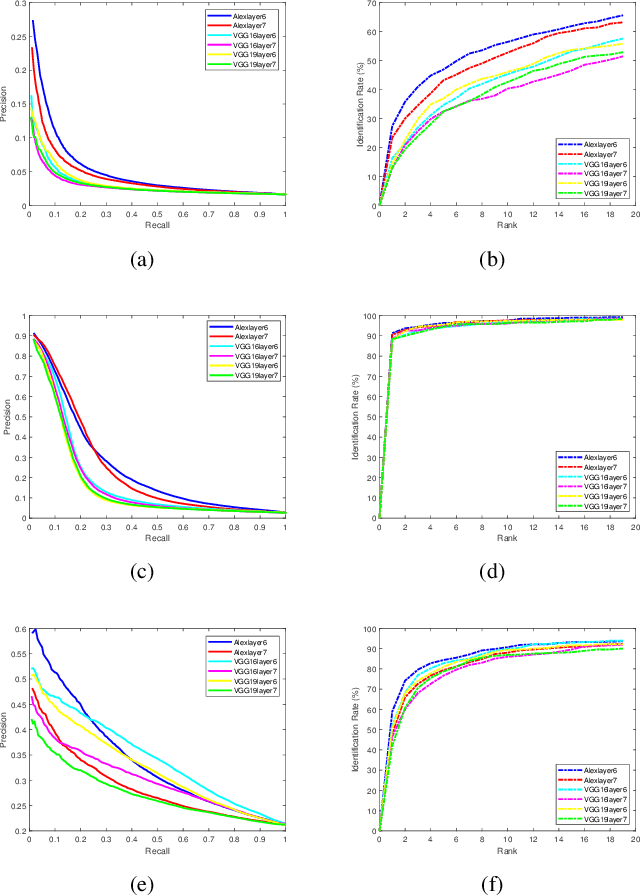
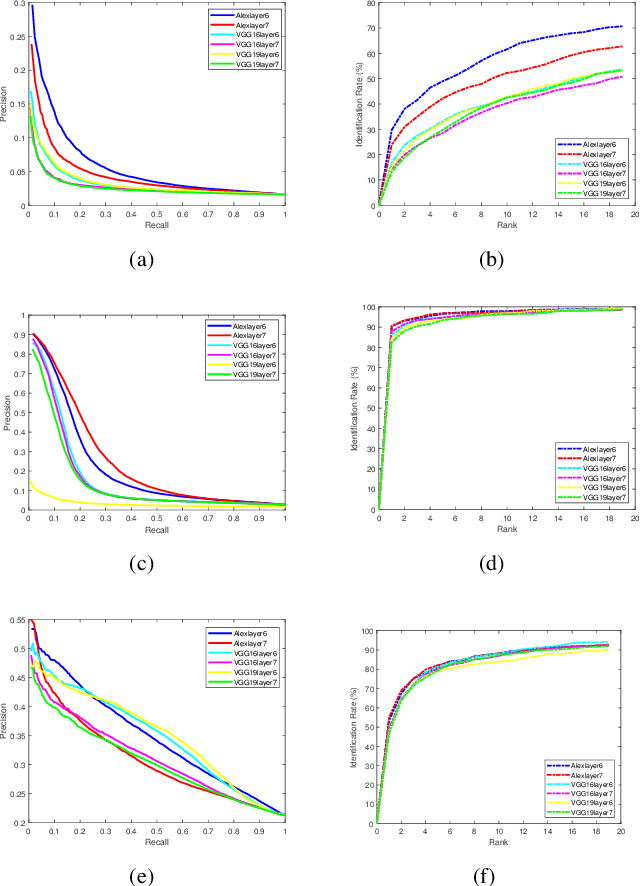
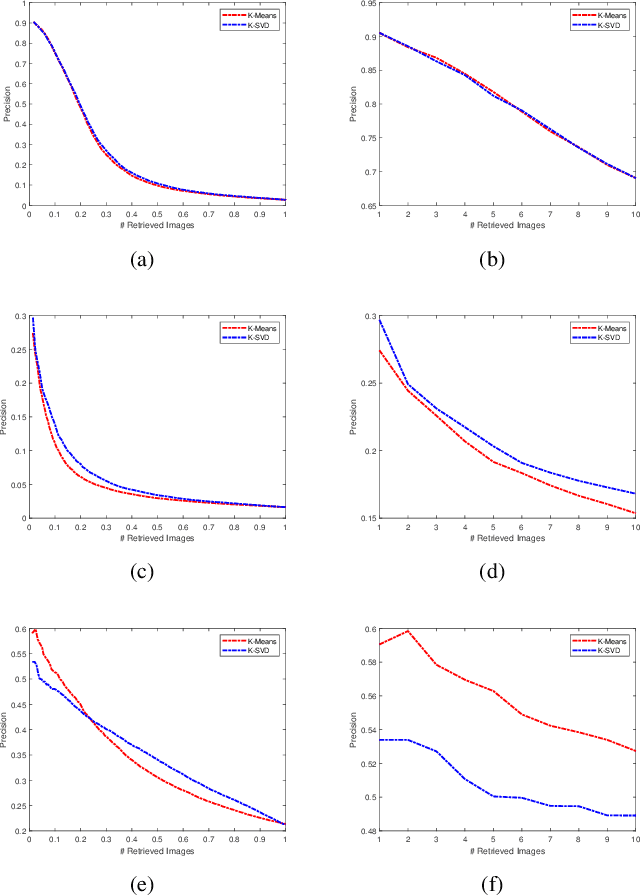
Facial image retrieval is a challenging task since faces have many similar features (areas), which makes it difficult for the retrieval systems to distinguish faces of different people. With the advent of deep learning, deep networks are often applied to extract powerful features that are used in many areas of computer vision. This paper investigates the application of different deep learning models for face image retrieval, namely, Alexlayer6, Alexlayer7, VGG16layer6, VGG16layer7, VGG19layer6, and VGG19layer7, with two types of dictionary learning techniques, namely $K$-means and $K$-SVD. We also investigate some coefficient learning techniques such as the Homotopy, Lasso, Elastic Net and SSF and their effect on the face retrieval system. The comparative results of the experiments conducted on three standard face image datasets show that the best performers for face image retrieval are Alexlayer7 with $K$-means and SSF, Alexlayer6 with $K$-SVD and SSF, and Alexlayer6 with $K$-means and SSF. The APR and ARR of these methods were further compared to some of the state of the art methods based on local descriptors. The experimental results show that deep learning outperforms most of those methods and therefore can be recommended for use in practice of face image retrieval
Efficient automated U-Net based tree crown delineation using UAV multi-spectral imagery on embedded devices
Jul 16, 2021



Delineation approaches provide significant benefits to various domains, including agriculture, environmental and natural disasters monitoring. Most of the work in the literature utilize traditional segmentation methods that require a large amount of computational and storage resources. Deep learning has transformed computer vision and dramatically improved machine translation, though it requires massive dataset for training and significant resources for inference. More importantly, energy-efficient embedded vision hardware delivering real-time and robust performance is crucial in the aforementioned application. In this work, we propose a U-Net based tree delineation method, which is effectively trained using multi-spectral imagery but can then delineate single-spectrum images. The deep architecture that also performs localization, i.e., a class label corresponds to each pixel, has been successfully used to allow training with a small set of segmented images. The ground truth data were generated using traditional image denoising and segmentation approaches. To be able to execute the proposed DNN efficiently in embedded platforms designed for deep learning approaches, we employ traditional model compression and acceleration methods. Extensive evaluation studies using data collected from UAVs equipped with multi-spectral cameras demonstrate the effectiveness of the proposed methods in terms of delineation accuracy and execution efficiency.
Rethinking Content and Style: Exploring Bias for Unsupervised Disentanglement
Feb 21, 2021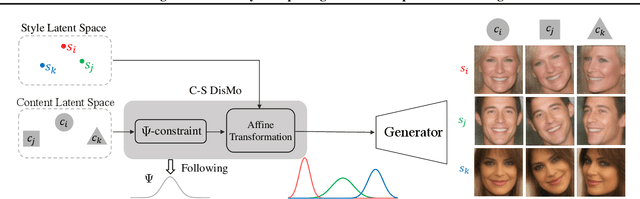
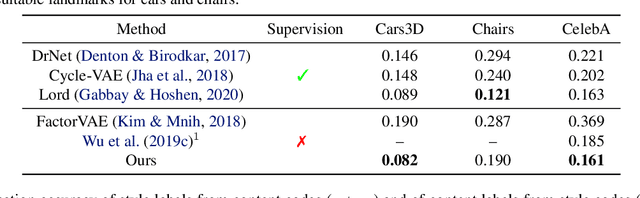


Content and style (C-S) disentanglement intends to decompose the underlying explanatory factors of objects into two independent subspaces. From the unsupervised disentanglement perspective, we rethink content and style and propose a formulation for unsupervised C-S disentanglement based on our assumption that different factors are of different importance and popularity for image reconstruction, which serves as a data bias. The corresponding model inductive bias is introduced by our proposed C-S disentanglement Module (C-S DisMo), which assigns different and independent roles to content and style when approximating the real data distributions. Specifically, each content embedding from the dataset, which encodes the most dominant factors for image reconstruction, is assumed to be sampled from a shared distribution across the dataset. The style embedding for a particular image, encoding the remaining factors, is used to customize the shared distribution through an affine transformation. The experiments on several popular datasets demonstrate that our method achieves the state-of-the-art unsupervised C-S disentanglement, which is comparable or even better than supervised methods. We verify the effectiveness of our method by downstream tasks: domain translation and single-view 3D reconstruction. Project page at https://github.com/xrenaa/CS-DisMo.
Synergistic Multi-spectral CT Reconstruction with Directional Total Variation
Jan 06, 2021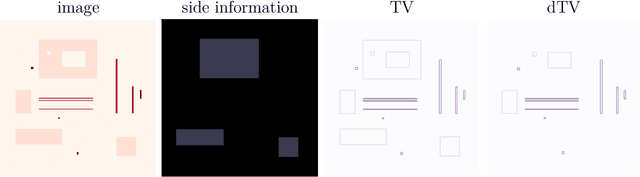
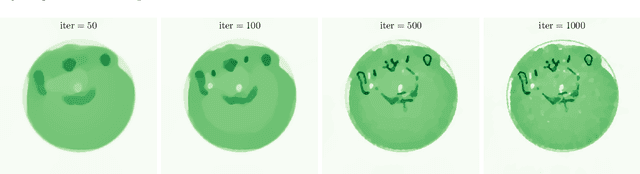
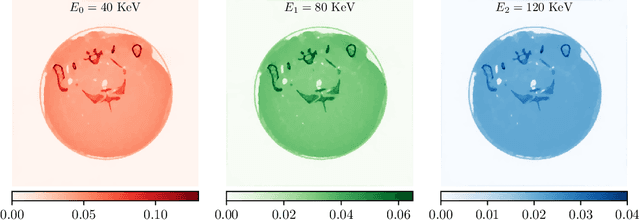
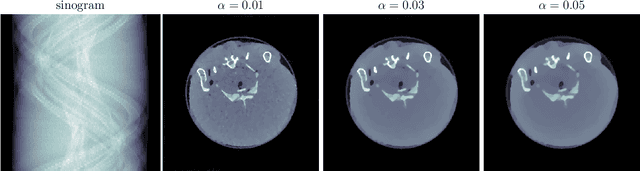
This work considers synergistic multi-spectral CT reconstruction where information from all available energy channels is combined to improve the reconstruction of each individual channel, we propose to fuse this available data (represented by a single sinogram) to obtain a polyenergetic image which keeps structural information shared by the energy channels with increased signal-to-noise-ratio. This new image is used as prior information during the minimization process through the directional total variation. We analyze the use of directional total variation within variational regularization and iterative regularization. Our numerical results on simulated and experimental data show significant improvements in terms of image quality and in computational speed.
Vision-Guided Active Tactile Perception for Crack Detection and Reconstruction
May 13, 2021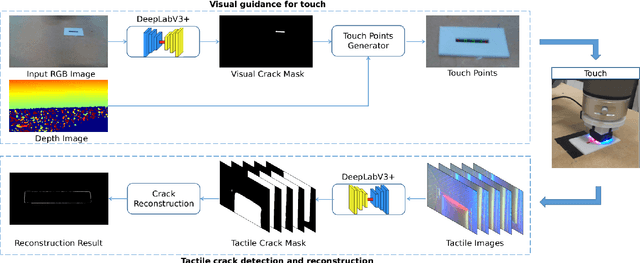
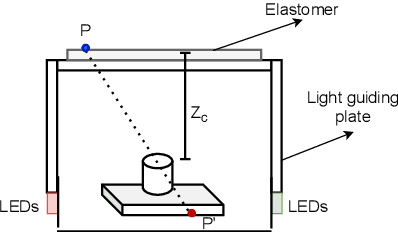


Crack detection is of great significance for monitoring the integrity and well-being of the infrastructure such as bridges and underground pipelines, which are harsh environments for people to access. In recent years, computer vision techniques have been applied in detecting cracks in concrete structures. However, they suffer from variances in light conditions and shadows, lacking robustness and resulting in many false positives. To address the uncertainty in vision, human inspectors actively touch the surface of the structures, guided by vision, which has not been explored in autonomous crack detection. In this paper, we propose a novel approach to detect and reconstruct cracks in concrete structures using vision-guided active tactile perception. Given an RGB-D image of a structure, the rough profile of the crack in the structure surface will first be segmented with a fine-tuned Deep Convolutional Neural Networks, and a set of contact points are generated to guide the collection of tactile images by a camera-based optical tactile sensor. When contacts are made, a pixel-wise mask of the crack can be obtained from the tactile images and therefore the profile of the crack can be refined by aligning the RGB-D image and the tactile images. Extensive experiment results have shown that the proposed method improves the effectiveness and robustness of crack detection and reconstruction significantly, compared to crack detection with vision only, and has the potential to enable robots to help humans with the inspection and repair of the concrete infrastructure.