 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Going Full-TILT Boogie on Document Understanding with Text-Image-Layout Transformer
Feb 18, 2021
We address the challenging problem of Natural Language Comprehension beyond plain-text documents by introducing the TILT neural network architecture which simultaneously learns layout information, visual features, and textual semantics. Contrary to previous approaches, we rely on a decoder capable of solving all problems involving natural language. The layout is represented as an attention bias and complemented with contextualized visual information, while the core of our model is a pretrained encoder-decoder Transformer. We trained our network on real-world documents with different layouts, such as tables, figures, and forms. Our novel approach achieves state-of-the-art in extracting information from documents and answering questions, demanding layout understanding (DocVQA, CORD, WikiOps, SROIE). At the same time, we simplify the process by employing an end-to-end model.
Attentive CutMix: An Enhanced Data Augmentation Approach for Deep Learning Based Image Classification
Apr 05, 2020
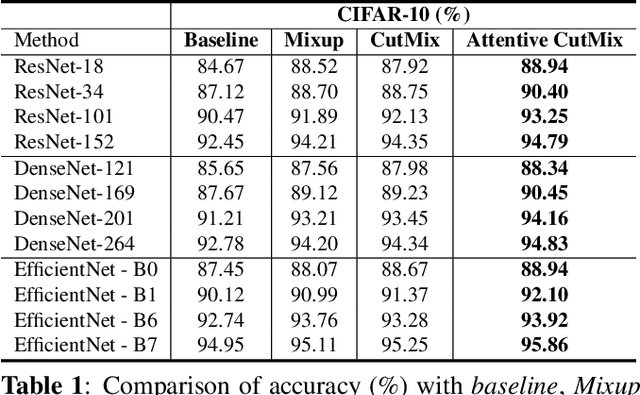
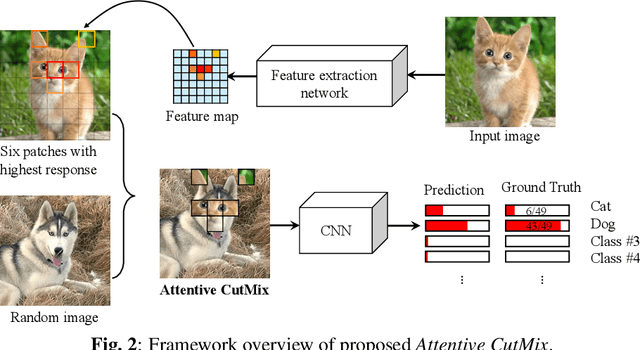
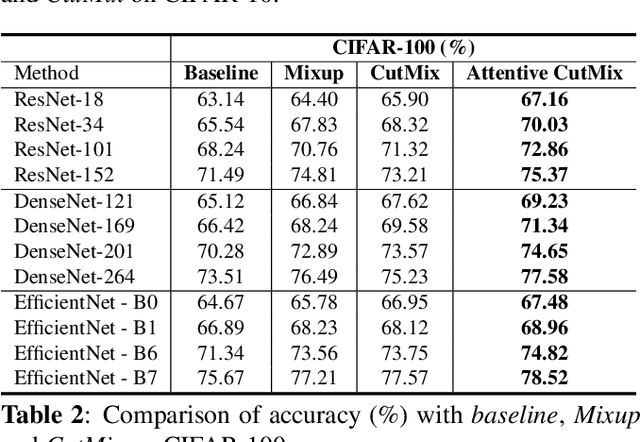
Convolutional neural networks (CNN) are capable of learning robust representation with different regularization methods and activations as convolutional layers are spatially correlated. Based on this property, a large variety of regional dropout strategies have been proposed, such as Cutout, DropBlock, CutMix, etc. These methods aim to promote the network to generalize better by partially occluding the discriminative parts of objects. However, all of them perform this operation randomly, without capturing the most important region(s) within an object. In this paper, we propose Attentive CutMix, a naturally enhanced augmentation strategy based on CutMix. In each training iteration, we choose the most descriptive regions based on the intermediate attention maps from a feature extractor, which enables searching for the most discriminative parts in an image. Our proposed method is simple yet effective, easy to implement and can boost the baseline significantly. Extensive experiments on CIFAR-10/100, ImageNet datasets with various CNN architectures (in a unified setting) demonstrate the effectiveness of our proposed method, which consistently outperforms the baseline CutMix and other methods by a significant margin.
Animating Landscape: Self-Supervised Learning of Decoupled Motion and Appearance for Single-Image Video Synthesis
Oct 16, 2019

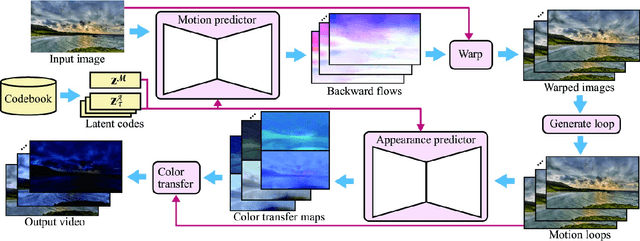

Automatic generation of a high-quality video from a single image remains a challenging task despite the recent advances in deep generative models. This paper proposes a method that can create a high-resolution, long-term animation using convolutional neural networks (CNNs) from a single landscape image where we mainly focus on skies and waters. Our key observation is that the motion (e.g., moving clouds) and appearance (e.g., time-varying colors in the sky) in natural scenes have different time scales. We thus learn them separately and predict them with decoupled control while handling future uncertainty in both predictions by introducing latent codes. Unlike previous methods that infer output frames directly, our CNNs predict spatially-smooth intermediate data, i.e., for motion, flow fields for warping, and for appearance, color transfer maps, via self-supervised learning, i.e., without explicitly-provided ground truth. These intermediate data are applied not to each previous output frame, but to the input image only once for each output frame. This design is crucial to alleviate error accumulation in long-term predictions, which is the essential problem in previous recurrent approaches. The output frames can be looped like cinemagraph, and also be controlled directly by specifying latent codes or indirectly via visual annotations. We demonstrate the effectiveness of our method through comparisons with the state-of-the-arts on video prediction as well as appearance manipulation.
Weighted Sparse Subspace Representation: A Unified Framework for Subspace Clustering, Constrained Clustering, and Active Learning
Jun 08, 2021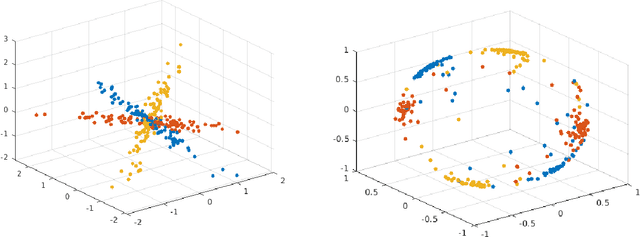
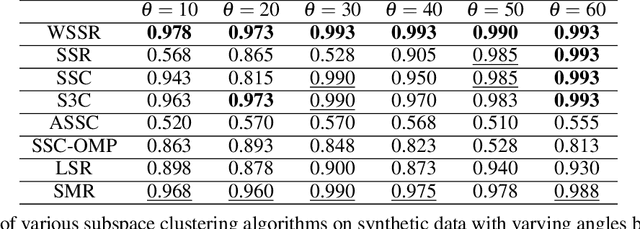
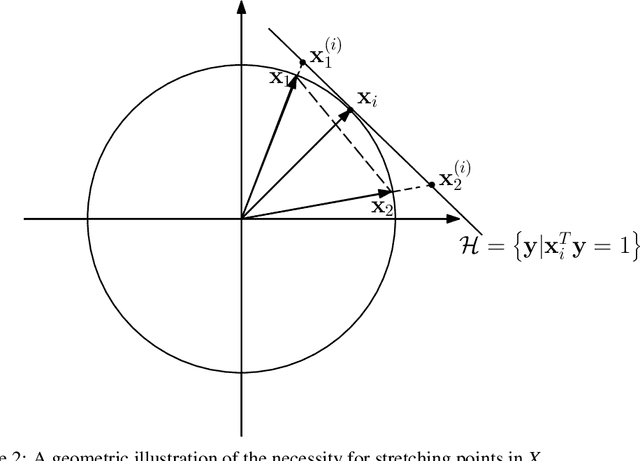
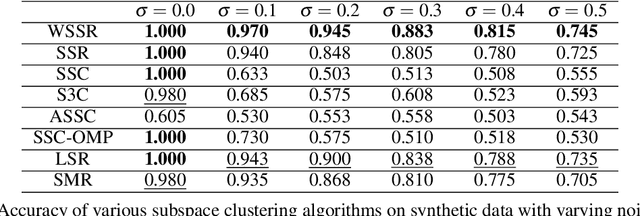
Spectral-based subspace clustering methods have proved successful in many challenging applications such as gene sequencing, image recognition, and motion segmentation. In this work, we first propose a novel spectral-based subspace clustering algorithm that seeks to represent each point as a sparse convex combination of a few nearby points. We then extend the algorithm to constrained clustering and active learning settings. Our motivation for developing such a framework stems from the fact that typically either a small amount of labelled data is available in advance; or it is possible to label some points at a cost. The latter scenario is typically encountered in the process of validating a cluster assignment. Extensive experiments on simulated and real data sets show that the proposed approach is effective and competitive with state-of-the-art methods.
Attention-Based Keyword Localisation in Speech using Visual Grounding
Jun 23, 2021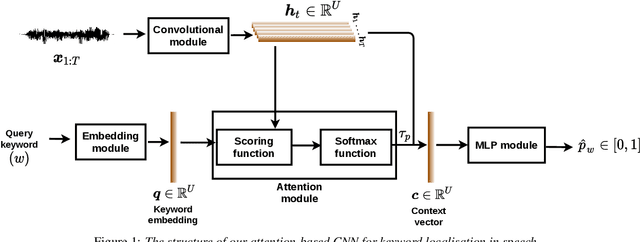
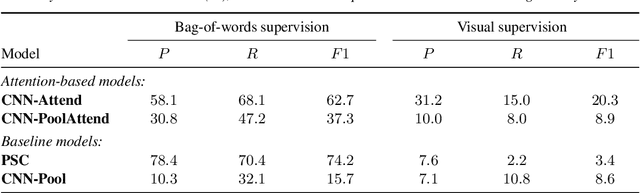
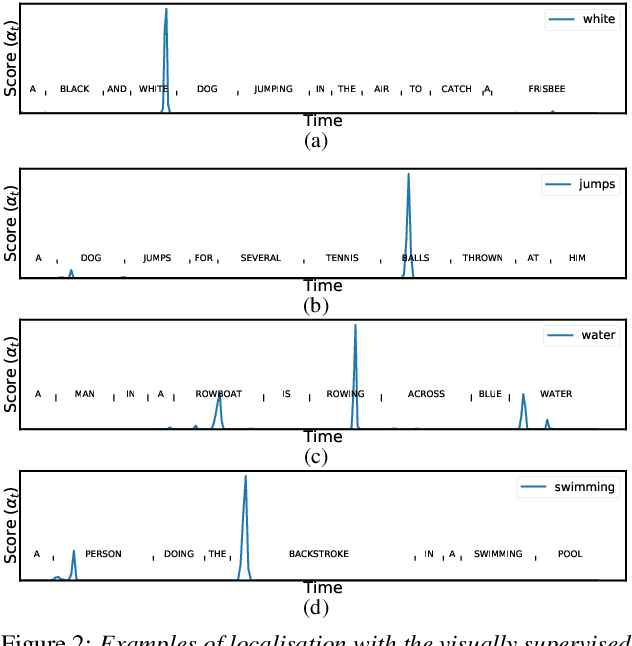
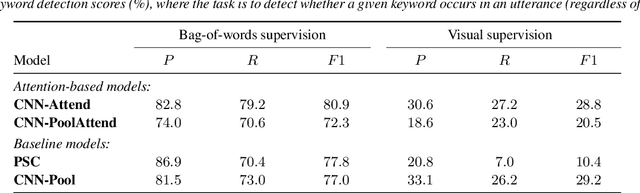
Visually grounded speech models learn from images paired with spoken captions. By tagging images with soft text labels using a trained visual classifier with a fixed vocabulary, previous work has shown that it is possible to train a model that can detect whether a particular text keyword occurs in speech utterances or not. Here we investigate whether visually grounded speech models can also do keyword localisation: predicting where, within an utterance, a given textual keyword occurs without any explicit text-based or alignment supervision. We specifically consider whether incorporating attention into a convolutional model is beneficial for localisation. Although absolute localisation performance with visually supervised models is still modest (compared to using unordered bag-of-word text labels for supervision), we show that attention provides a large gain in performance over previous visually grounded models. As in many other speech-image studies, we find that many of the incorrect localisations are due to semantic confusions, e.g. locating the word 'backstroke' for the query keyword 'swimming'.
VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
Apr 22, 2021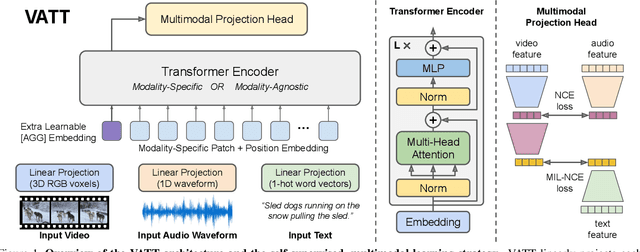
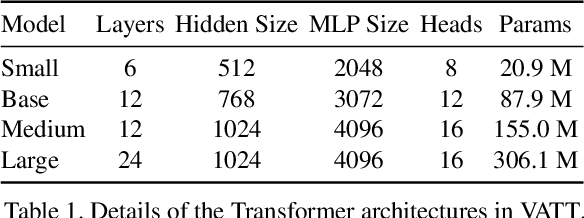
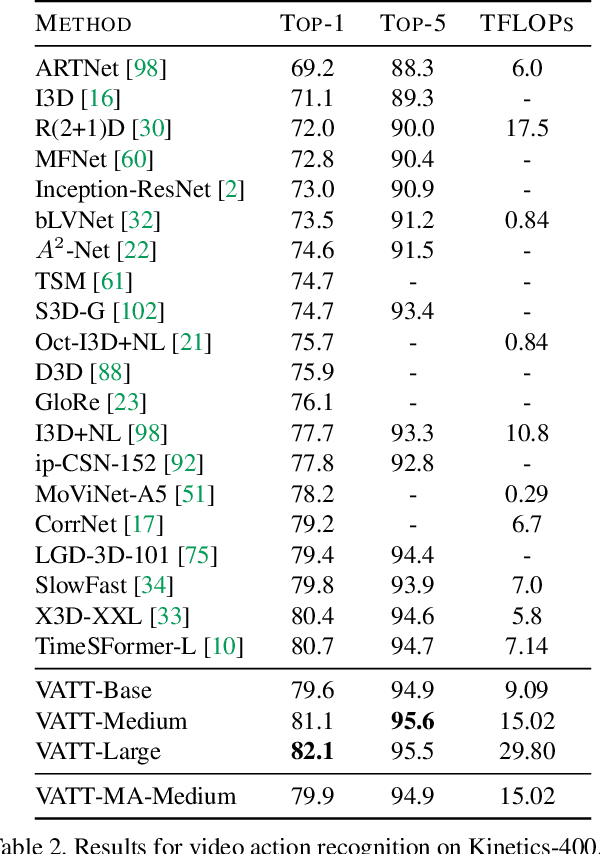
We present a framework for learning multimodal representations from unlabeled data using convolution-free Transformer architectures. Specifically, our Video-Audio-Text Transformer (VATT) takes raw signals as inputs and extracts multimodal representations that are rich enough to benefit a variety of downstream tasks. We train VATT end-to-end from scratch using multimodal contrastive losses and evaluate its performance by the downstream tasks of video action recognition, audio event classification, image classification, and text-to-video retrieval. Furthermore, we study a modality-agnostic single-backbone Transformer by sharing weights among the three modalities. We show that the convolution-free VATT outperforms state-of-the-art ConvNet-based architectures in the downstream tasks. Especially, VATT's vision Transformer achieves the top-1 accuracy of 82.1% on Kinetics-400, 83.6% on Kinetics-600,and 41.1% on Moments in Time, new records while avoiding supervised pre-training. Transferring to image classification leads to 78.7% top-1 accuracy on ImageNet compared to 64.7% by training the same Transformer from scratch, showing the generalizability of our model despite the domain gap between videos and images. VATT's audio Transformer also sets a new record on waveform-based audio event recognition by achieving the mAP of 39.4% on AudioSet without any supervised pre-training.
Estimating the Robustness of Classification Models by the Structure of the Learned Feature-Space
Jun 23, 2021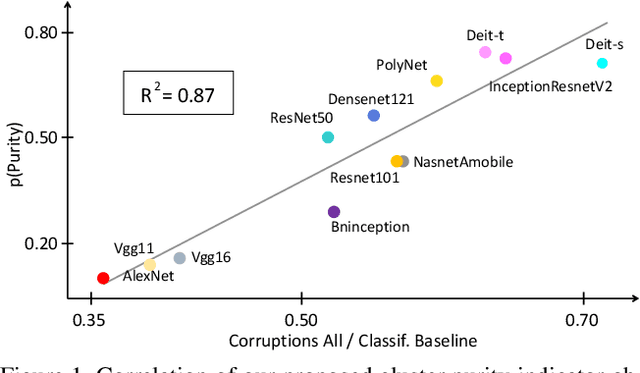
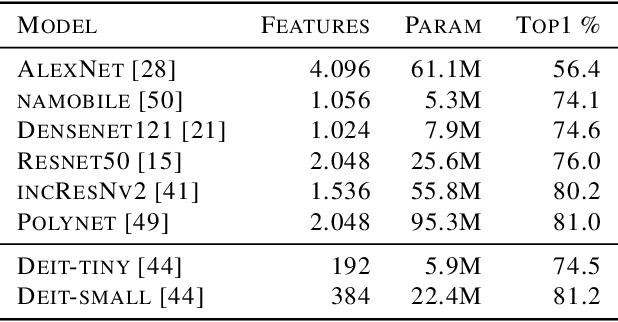
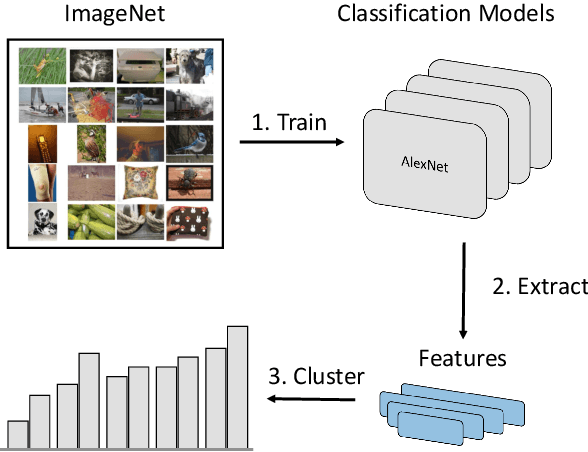
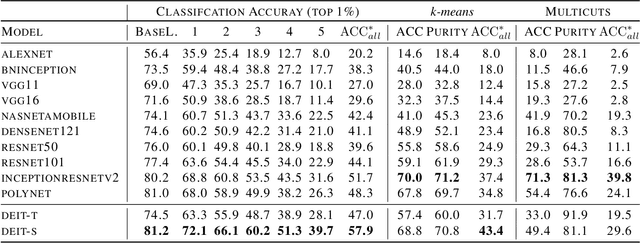
Over the last decade, the development of deep image classification networks has mostly been driven by the search for the best performance in terms of classification accuracy on standardized benchmarks like ImageNet. More recently, this focus has been expanded by the notion of model robustness, i.e. the generalization abilities of models towards previously unseen changes in the data distribution. While new benchmarks, like ImageNet-C, have been introduced to measure robustness properties, we argue that fixed testsets are only able to capture a small portion of possible data variations and are thus limited and prone to generate new overfitted solutions. To overcome these drawbacks, we suggest to estimate the robustness of a model directly from the structure of its learned feature-space. We introduce robustness indicators which are obtained via unsupervised clustering of latent representations inside a trained classifier and show very high correlations to the model performance on corrupted test data.
Self-supervised Detransformation Autoencoder for Representation Learning in Open Set Recognition
May 28, 2021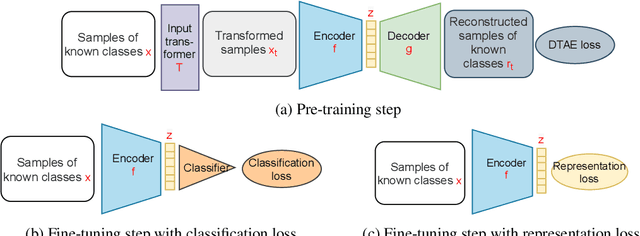

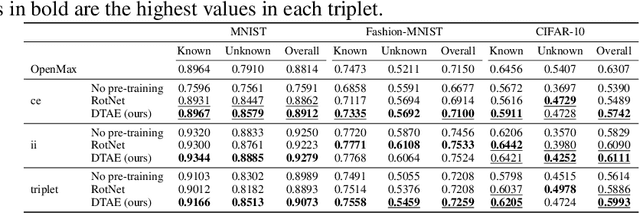
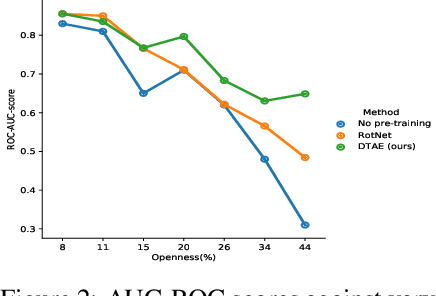
The objective of Open set recognition (OSR) is to learn a classifier that can reject the unknown samples while classifying the known classes accurately. In this paper, we propose a self-supervision method, Detransformation Autoencoder (DTAE), for the OSR problem. This proposed method engages in learning representations that are invariant to the transformations of the input data. Experiments on several standard image datasets indicate that the pre-training process significantly improves the model performance in the OSR tasks. Meanwhile, our proposed self-supervision method achieves significant gains in detecting the unknown class and classifying the known classes. Moreover, our analysis indicates that DTAE can yield representations that contain more target class information and less transformation information than RotNet.
A Generalized Deep Learning Framework for Whole-Slide Image Segmentation and Analysis
Jan 01, 2020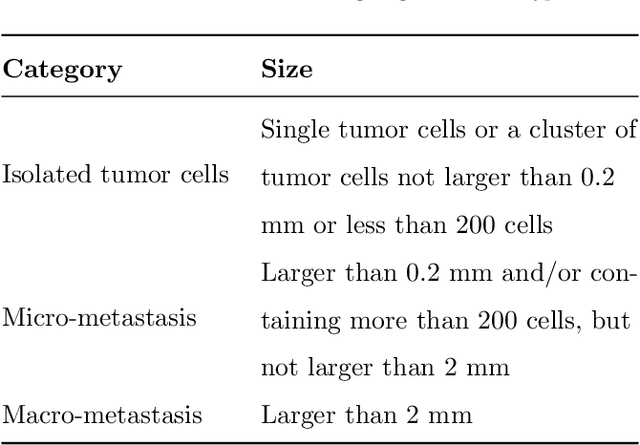
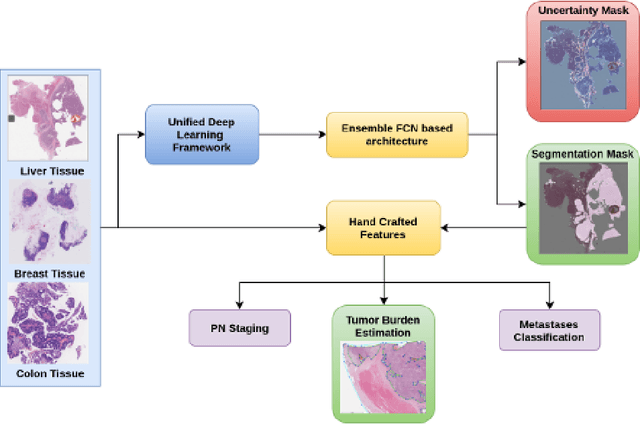

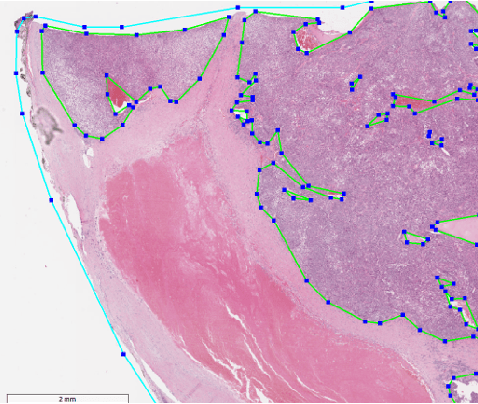
Histopathology tissue analysis is considered the gold standard in cancer diagnosis and prognosis. Given the large size of these images and the increase in the number of potential cancer cases, an automated solution as an aid to histopathologists is highly desirable. In the recent past, deep learning-based techniques have provided state of the art results in a wide variety of image analysis tasks, including analysis of digitized slides. However, the size of images and variability in histopathology tasks makes it a challenge to develop an integrated framework for histopathology image analysis. We propose a deep learning-based framework for histopathology tissue analysis. We demonstrate the generalizability of our framework, including training and inference, on several open-source datasets, which include CAMELYON (breast cancer metastases), DigestPath (colon cancer), and PAIP (liver cancer) datasets. We discuss multiple types of uncertainties pertaining to data and model, namely aleatoric and epistemic, respectively. Simultaneously, we demonstrate our model generalization across different data distribution by evaluating some samples on TCGA data. On CAMELYON16 test data (n=139) for the task of lesion detection, the FROC score achieved was 0.86 and in the CAMELYON17 test-data (n=500) for the task of pN-staging the Cohen's kappa score achieved was 0.9090 (third in the open leaderboard). On DigestPath test data (n=212) for the task of tumor segmentation, a Dice score of 0.782 was achieved (fourth in the challenge). On PAIP test data (n=40) for the task of viable tumor segmentation, a Jaccard Index of 0.75 (third in the challenge) was achieved, and for viable tumor burden, a score of 0.633 was achieved (second in the challenge). Our entire framework and related documentation are freely available at GitHub and PyPi.
Low-Rank Discriminative Least Squares Regression for Image Classification
Apr 16, 2019


Latest least squares regression (LSR) methods mainly try to learn slack regression targets to replace strict zero-one labels. However, the difference of intra-class targets can also be highlighted when enlarging the distance between different classes, and roughly persuing relaxed targets may lead to the problem of overfitting. To solve above problems, we propose a low-rank discriminative least squares regression model (LRDLSR) for multi-class image classification. Specifically, LRDLSR class-wisely imposes low-rank constraint on the intra-class regression targets to encourage its compactness and similarity. Moreover, LRDLSR introduces an additional regularization term on the learned targets to avoid the problem of overfitting. These two improvements are helpful to learn a more discriminative projection for regression and thus achieving better classification performance. Experimental results over a range of image databases demonstrate the effectiveness of the proposed LRDLSR method.