 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Advantages and Bottlenecks of Quantum Machine Learning for Remote Sensing
Jan 26, 2021
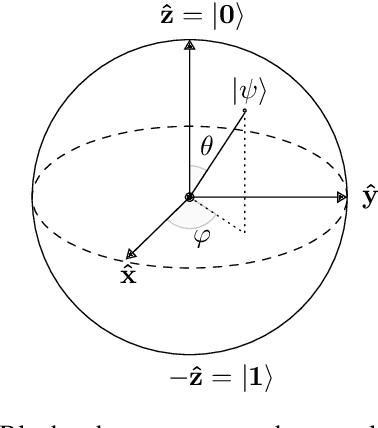
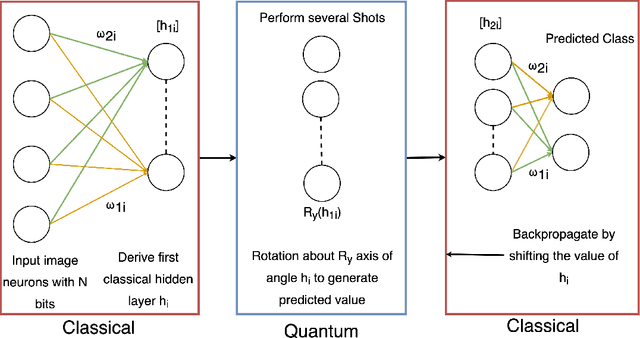

This concept paper aims to provide a brief outline of quantum computers, explore existing methods of quantum image classification techniques, so focusing on remote sensing applications, and discuss the bottlenecks of performing these algorithms on currently available open source platforms. Initial results demonstrate feasibility. Next steps include expanding the size of the quantum hidden layer and increasing the variety of output image options.
Keep Drawing It: Iterative language-based image generation and editing
Nov 24, 2018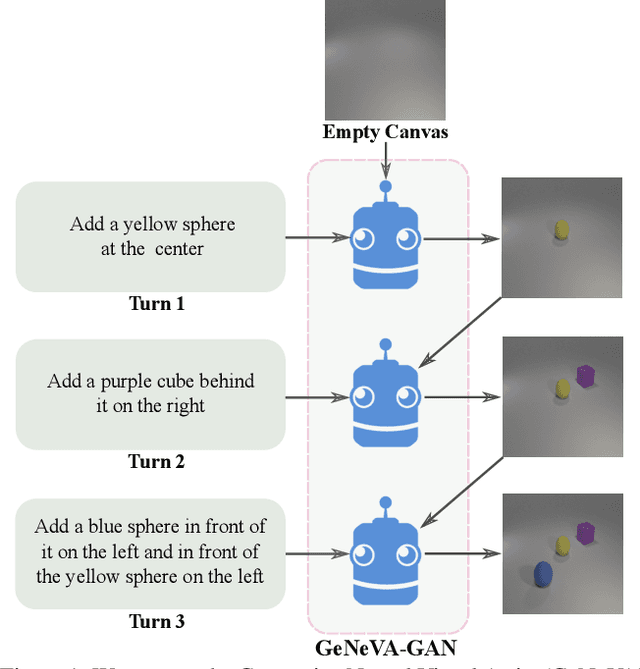
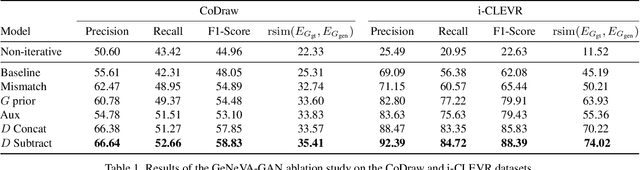

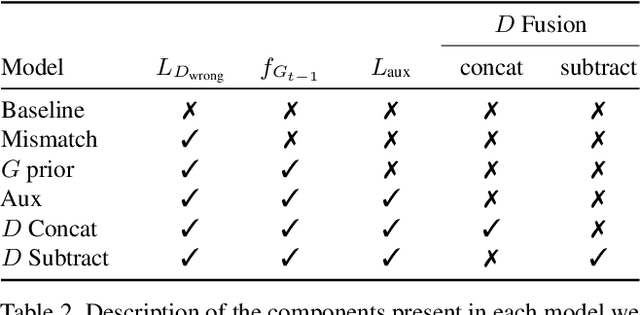
Conditional text-to-image generation approaches commonly focus on generating a single image in a single step. One practical extension beyond one-step generation is an interactive system that generates an image iteratively, conditioned on ongoing linguistic input / feedback. This is significantly more challenging as such a system must understand and keep track of the ongoing context and history. In this work, we present a recurrent image generation model which takes into account both the generated output up to the current step as well as all past instructions for generation. We show that our model is able to generate the background, add new objects, apply simple transformations to existing objects, and correct previous mistakes. We believe our approach is an important step toward interactive generation.
Adaptive Learning Rate and Momentum for Training Deep Neural Networks
Jun 22, 2021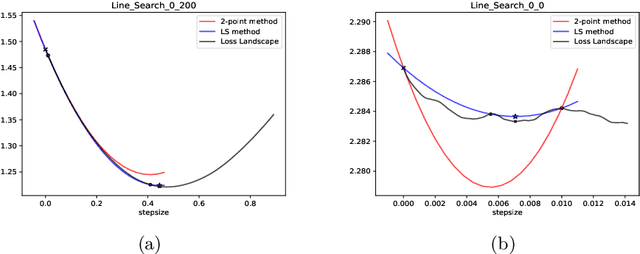
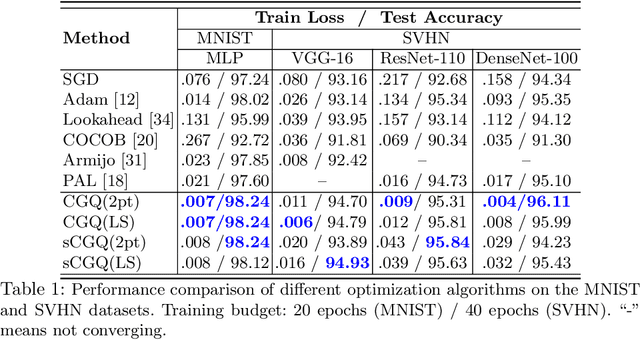

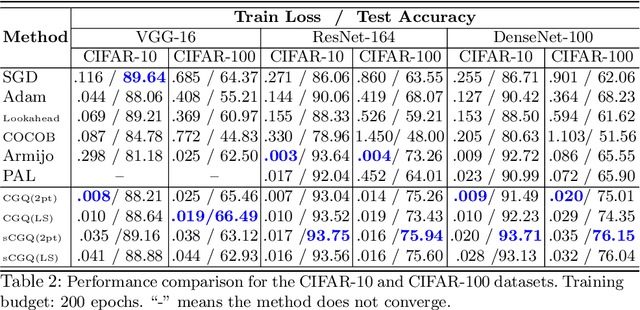
Recent progress on deep learning relies heavily on the quality and efficiency of training algorithms. In this paper, we develop a fast training method motivated by the nonlinear Conjugate Gradient (CG) framework. We propose the Conjugate Gradient with Quadratic line-search (CGQ) method. On the one hand, a quadratic line-search determines the step size according to current loss landscape. On the other hand, the momentum factor is dynamically updated in computing the conjugate gradient parameter (like Polak-Ribiere). Theoretical results to ensure the convergence of our method in strong convex settings is developed. And experiments in image classification datasets show that our method yields faster convergence than other local solvers and has better generalization capability (test set accuracy). One major advantage of the paper method is that tedious hand tuning of hyperparameters like the learning rate and momentum is avoided.
Uncertainty Quantification of the 4th kind; optimal posterior accuracy-uncertainty tradeoff with the minimum enclosing ball
Aug 24, 2021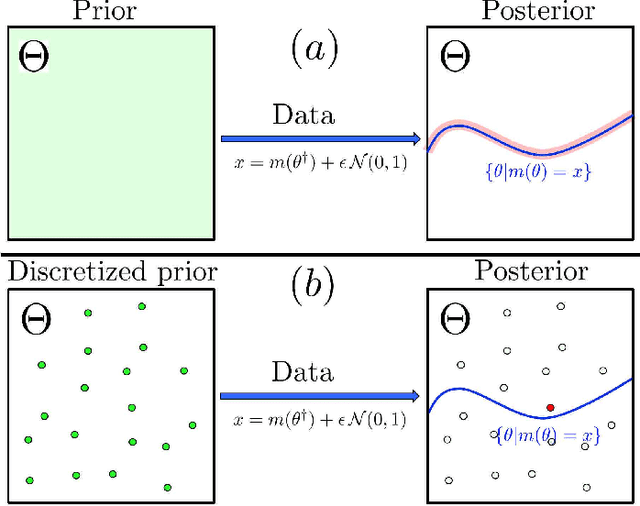
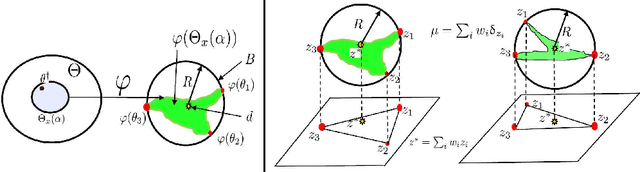
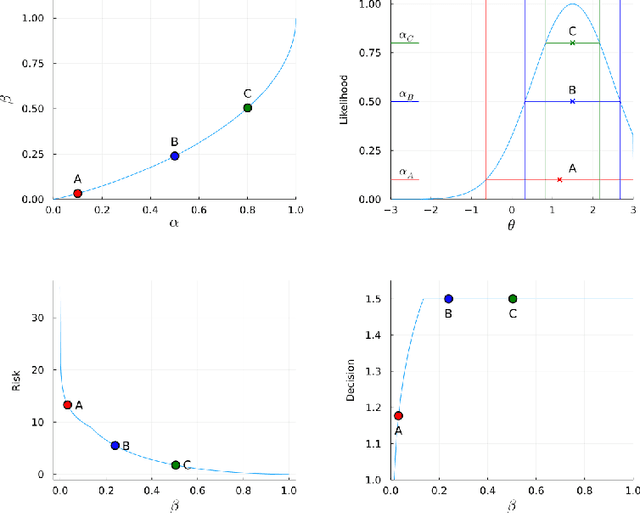
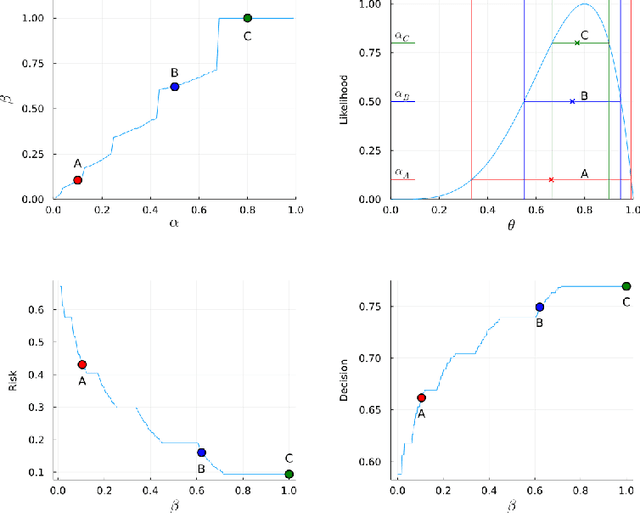
There are essentially three kinds of approaches to Uncertainty Quantification (UQ): (A) robust optimization, (B) Bayesian, (C) decision theory. Although (A) is robust, it is unfavorable with respect to accuracy and data assimilation. (B) requires a prior, it is generally brittle and posterior estimations can be slow. Although (C) leads to the identification of an optimal prior, its approximation suffers from the curse of dimensionality and the notion of risk is one that is averaged with respect to the distribution of the data. We introduce a 4th kind which is a hybrid between (A), (B), (C), and hypothesis testing. It can be summarized as, after observing a sample $x$, (1) defining a likelihood region through the relative likelihood and (2) playing a minmax game in that region to define optimal estimators and their risk. The resulting method has several desirable properties (a) an optimal prior is identified after measuring the data, and the notion of risk is a posterior one, (b) the determination of the optimal estimate and its risk can be reduced to computing the minimum enclosing ball of the image of the likelihood region under the quantity of interest map (which is fast and not subject to the curse of dimensionality). The method is characterized by a parameter in $ [0,1]$ acting as an assumed lower bound on the rarity of the observed data (the relative likelihood). When that parameter is near $1$, the method produces a posterior distribution concentrated around a maximum likelihood estimate with tight but low confidence UQ estimates. When that parameter is near $0$, the method produces a maximal risk posterior distribution with high confidence UQ estimates. In addition to navigating the accuracy-uncertainty tradeoff, the proposed method addresses the brittleness of Bayesian inference by navigating the robustness-accuracy tradeoff associated with data assimilation.
SIMILAR: Submodular Information Measures Based Active Learning In Realistic Scenarios
Jul 01, 2021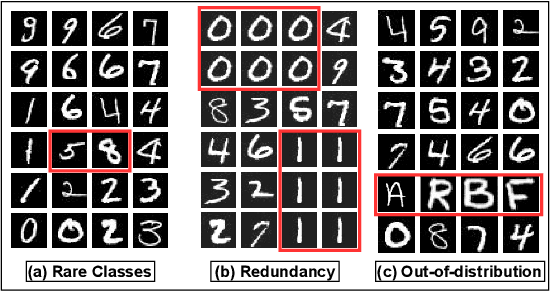

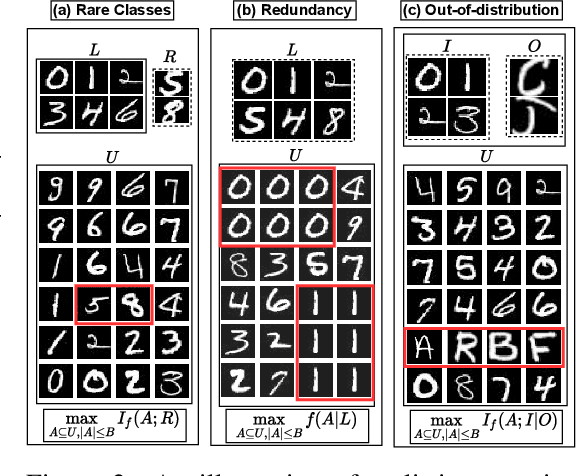
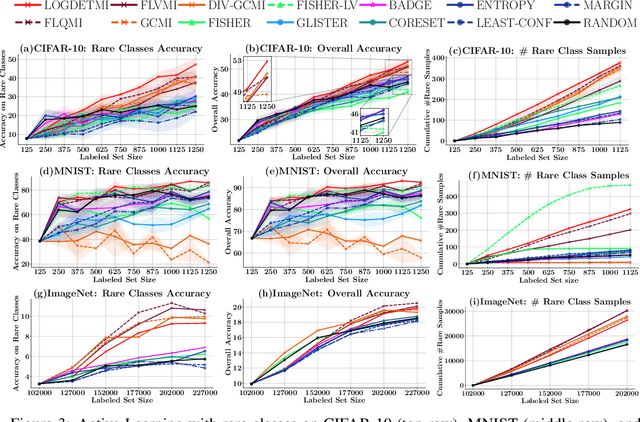
Active learning has proven to be useful for minimizing labeling costs by selecting the most informative samples. However, existing active learning methods do not work well in realistic scenarios such as imbalance or rare classes, out-of-distribution data in the unlabeled set, and redundancy. In this work, we propose SIMILAR (Submodular Information Measures based actIve LeARning), a unified active learning framework using recently proposed submodular information measures (SIM) as acquisition functions. We argue that SIMILAR not only works in standard active learning, but also easily extends to the realistic settings considered above and acts as a one-stop solution for active learning that is scalable to large real-world datasets. Empirically, we show that SIMILAR significantly outperforms existing active learning algorithms by as much as ~5% - 18% in the case of rare classes and ~5% - 10% in the case of out-of-distribution data on several image classification tasks like CIFAR-10, MNIST, and ImageNet.
Semi-Sparsity for Smoothing Filters
Jul 01, 2021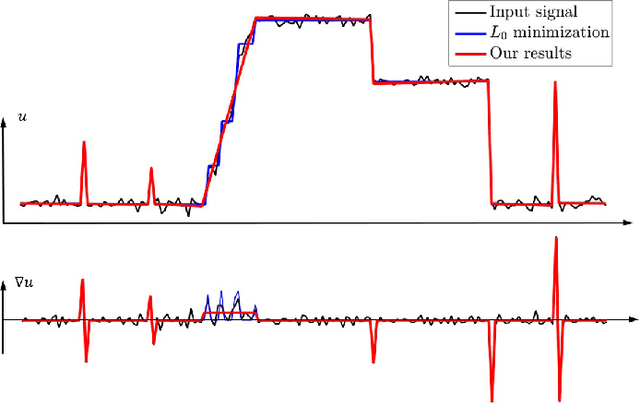
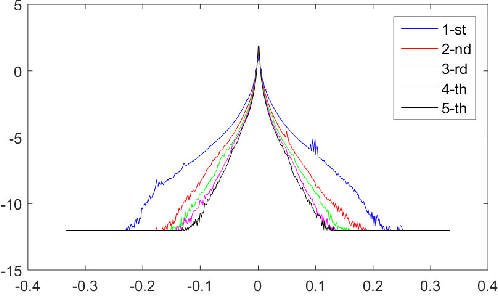

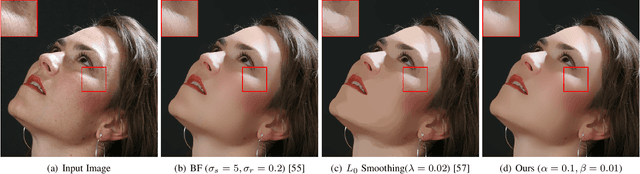
In this paper, we propose an interesting semi-sparsity smoothing algorithm based on a novel sparsity-inducing optimization framework. This method is derived from the multiple observations, that is, semi-sparsity prior knowledge is more universally applicable, especially in areas where sparsity is not fully admitted, such as polynomial-smoothing surfaces. We illustrate that this semi-sparsity can be identified into a generalized $L_0$-norm minimization in higher-order gradient domains, thereby giving rise to a new ``feature-aware'' filtering method with a powerful simultaneous-fitting ability in both sparse features (singularities and sharpening edges) and non-sparse regions (polynomial-smoothing surfaces). Notice that a direct solver is always unavailable due to the non-convexity and combinatorial nature of $L_0$-norm minimization. Instead, we solve the model based on an efficient half-quadratic splitting minimization with fast Fourier transforms (FFTs) for acceleration. We finally demonstrate its versatility and many benefits to a series of signal/image processing and computer vision applications.
Attention Based Semantic Segmentation on UAV Dataset for Natural Disaster Damage Assessment
May 30, 2021
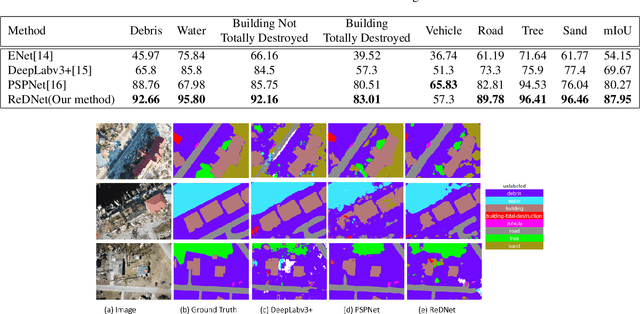
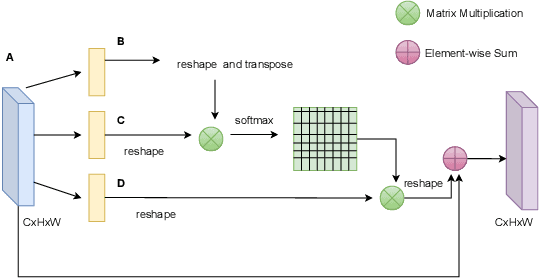
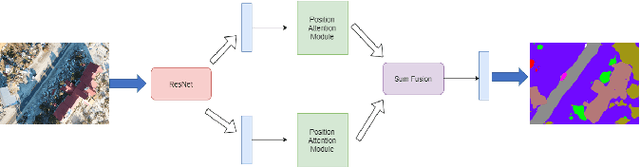
The detrimental impacts of climate change include stronger and more destructive hurricanes happening all over the world. Identifying different damaged structures of an area including buildings and roads are vital since it helps the rescue team to plan their efforts to minimize the damage by a natural disaster. Semantic segmentation helps to identify different parts of an image. We implement a novel self-attention based semantic segmentation model on a high resolution UAV dataset and attain Mean IoU score of around88%on the test set. The result inspires to use self-attention schemes in natural disaster damage assessment which will save human lives and reduce economic losses.
Inter Extreme Points Geodesics for Weakly Supervised Segmentation
Jul 01, 2021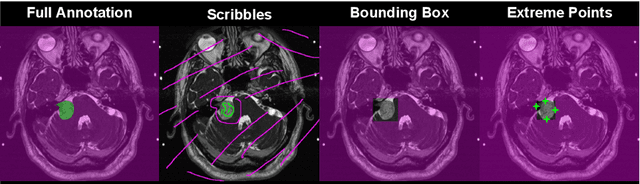
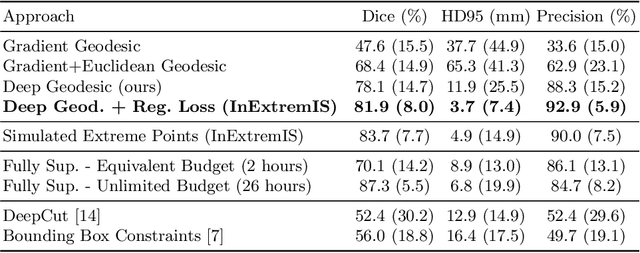
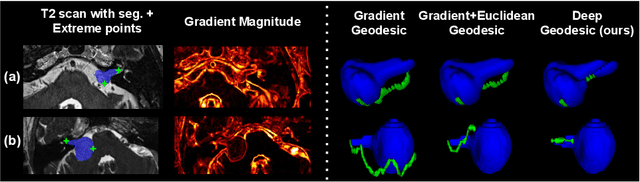
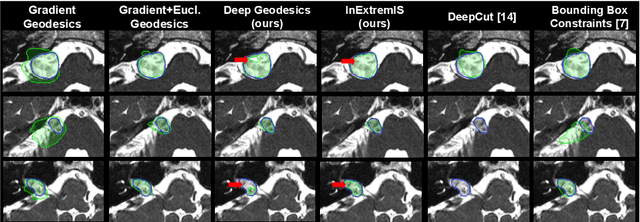
We introduce $\textit{InExtremIS}$, a weakly supervised 3D approach to train a deep image segmentation network using particularly weak train-time annotations: only 6 extreme clicks at the boundary of the objects of interest. Our fully-automatic method is trained end-to-end and does not require any test-time annotations. From the extreme points, 3D bounding boxes are extracted around objects of interest. Then, deep geodesics connecting extreme points are generated to increase the amount of "annotated" voxels within the bounding boxes. Finally, a weakly supervised regularised loss derived from a Conditional Random Field formulation is used to encourage prediction consistency over homogeneous regions. Extensive experiments are performed on a large open dataset for Vestibular Schwannoma segmentation. $\textit{InExtremIS}$ obtained competitive performance, approaching full supervision and outperforming significantly other weakly supervised techniques based on bounding boxes. Moreover, given a fixed annotation time budget, $\textit{InExtremIS}$ outperforms full supervision. Our code and data are available online.
Speech2Video: Cross-Modal Distillation for Speech to Video Generation
Jul 10, 2021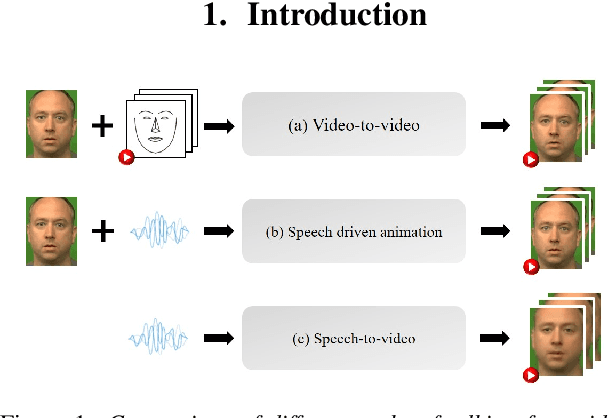
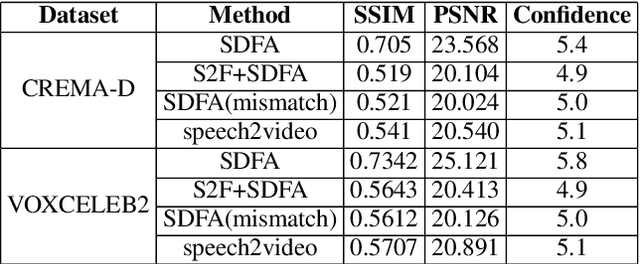
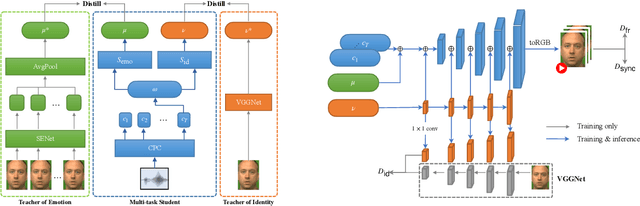
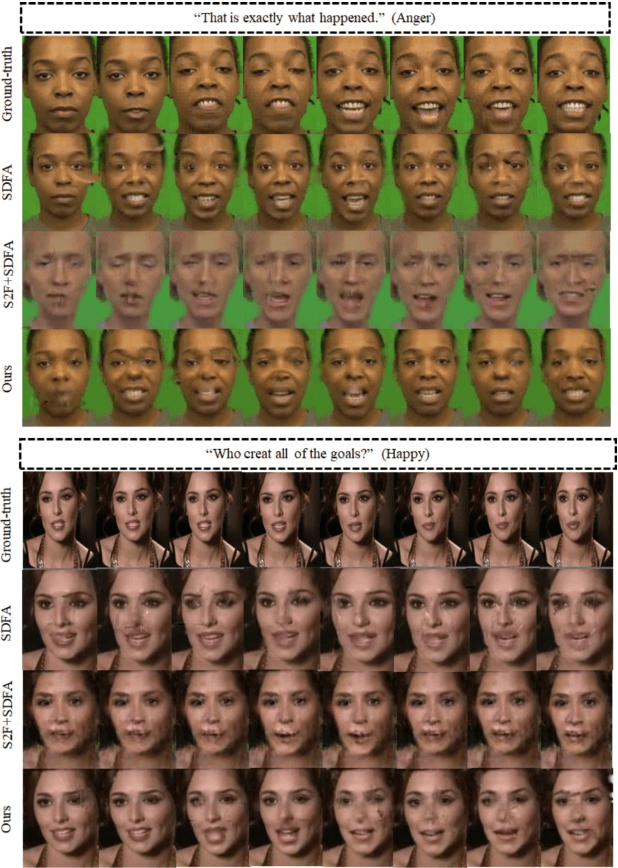
This paper investigates a novel task of talking face video generation solely from speeches. The speech-to-video generation technique can spark interesting applications in entertainment, customer service, and human-computer-interaction industries. Indeed, the timbre, accent and speed in speeches could contain rich information relevant to speakers' appearance. The challenge mainly lies in disentangling the distinct visual attributes from audio signals. In this article, we propose a light-weight, cross-modal distillation method to extract disentangled emotional and identity information from unlabelled video inputs. The extracted features are then integrated by a generative adversarial network into talking face video clips. With carefully crafted discriminators, the proposed framework achieves realistic generation results. Experiments with observed individuals demonstrated that the proposed framework captures the emotional expressions solely from speeches, and produces spontaneous facial motion in the video output. Compared to the baseline method where speeches are combined with a static image of the speaker, the results of the proposed framework is almost indistinguishable. User studies also show that the proposed method outperforms the existing algorithms in terms of emotion expression in the generated videos.
Anomaly Detection using Deep Learning based Image Completion
Nov 16, 2018
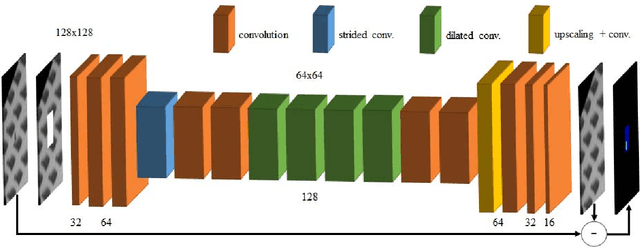
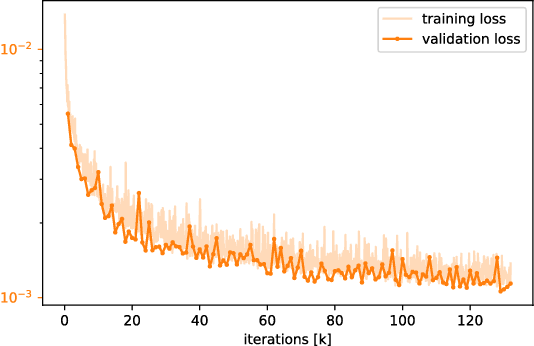
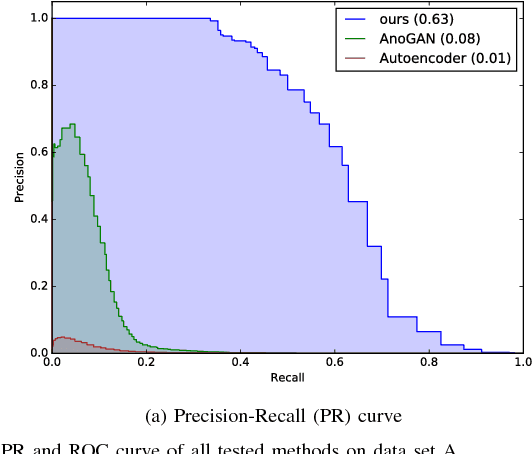
Automated surface inspection is an important task in many manufacturing industries and often requires machine learning driven solutions. Supervised approaches, however, can be challenging, since it is often difficult to obtain large amounts of labeled training data. In this work, we instead perform one-class unsupervised learning on fault-free samples by training a deep convolutional neural network to complete images whose center regions are cut out. Since the network is trained exclusively on fault-free data, it completes the image patches with a fault-free version of the missing image region. The pixel-wise reconstruction error within the cut out region is an anomaly image which can be used for anomaly detection. Results on surface images of decorated plastic parts demonstrate that this approach is suitable for detection of visible anomalies and moreover surpasses all other tested methods.