 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AxonEM Dataset: 3D Axon Instance Segmentation of Brain Cortical Regions
Jul 12, 2021
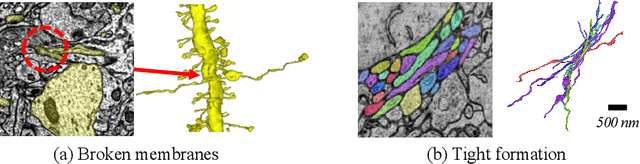

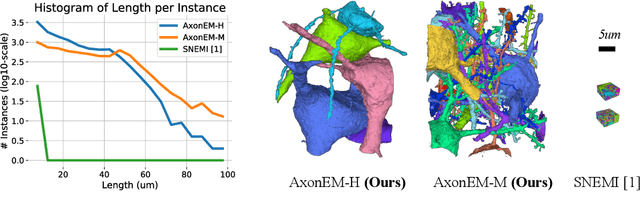

Electron microscopy (EM) enables the reconstruction of neural circuits at the level of individual synapses, which has been transformative for scientific discoveries. However, due to the complex morphology, an accurate reconstruction of cortical axons has become a major challenge. Worse still, there is no publicly available large-scale EM dataset from the cortex that provides dense ground truth segmentation for axons, making it difficult to develop and evaluate large-scale axon reconstruction methods. To address this, we introduce the AxonEM dataset, which consists of two 30x30x30 um^3 EM image volumes from the human and mouse cortex, respectively. We thoroughly proofread over 18,000 axon instances to provide dense 3D axon instance segmentation, enabling large-scale evaluation of axon reconstruction methods. In addition, we densely annotate nine ground truth subvolumes for training, per each data volume. With this, we reproduce two published state-of-the-art methods and provide their evaluation results as a baseline. We publicly release our code and data at https://connectomics-bazaar.github.io/proj/AxonEM/index.html to foster the development of advanced methods.
Attention Based Semantic Segmentation on UAV Dataset for Natural Disaster Damage Assessment
Jun 01, 2021
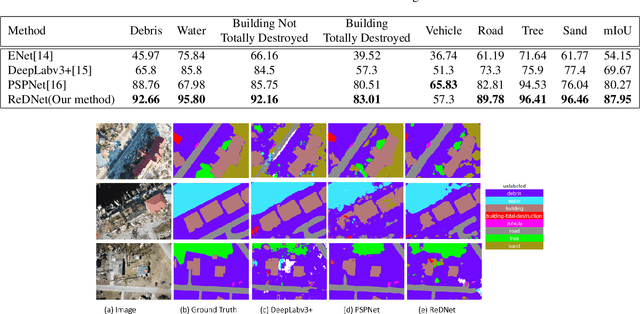
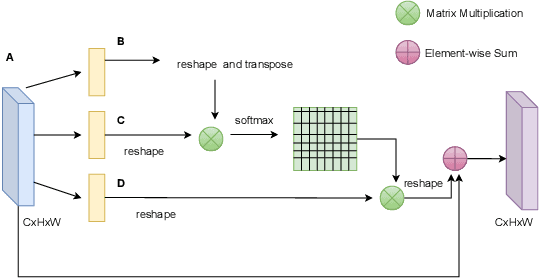
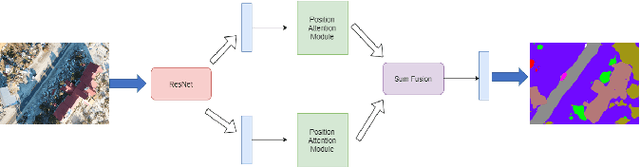
The detrimental impacts of climate change include stronger and more destructive hurricanes happening all over the world. Identifying different damaged structures of an area including buildings and roads are vital since it helps the rescue team to plan their efforts to minimize the damage caused by a natural disaster. Semantic segmentation helps to identify different parts of an image. We implement a novel self-attention based semantic segmentation model on a high resolution UAV dataset and attain Mean IoU score of around 88% on the test set. The result inspires to use self-attention schemes in natural disaster damage assessment which will save human lives and reduce economic losses.
Semantic Distribution-aware Contrastive Adaptation for Semantic Segmentation
May 11, 2021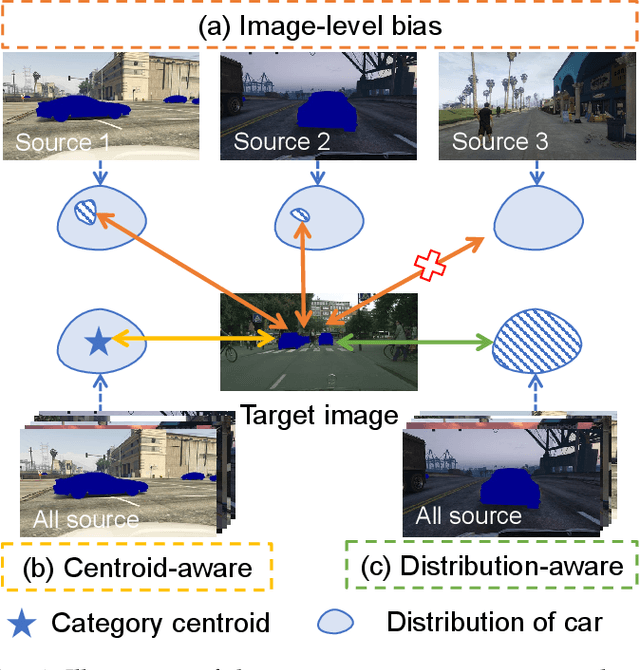
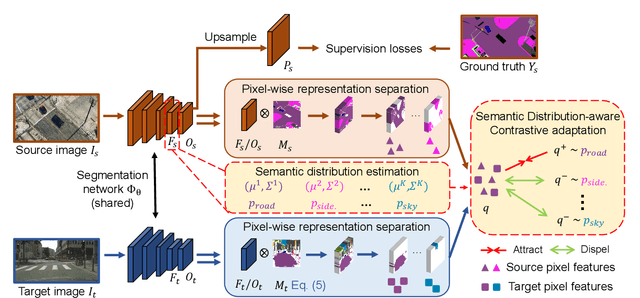
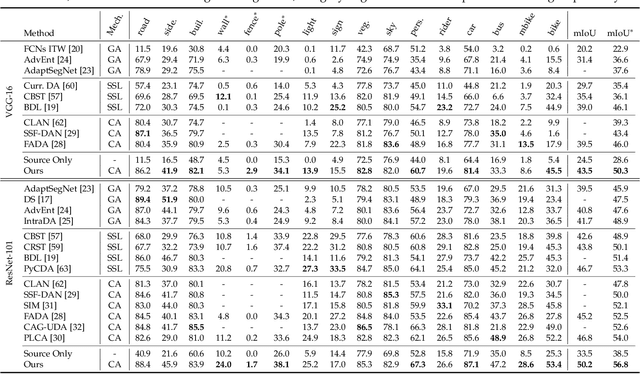
Domain adaptive semantic segmentation refers to making predictions on a certain target domain with only annotations of a specific source domain. Current state-of-the-art works suggest that performing category alignment can alleviate domain shift reasonably. However, they are mainly based on image-to-image adversarial training and little consideration is given to semantic variations of an object among images, failing to capture a comprehensive picture of different categories. This motivates us to explore a holistic representative, the semantic distribution from each category in source domain, to mitigate the problem above. In this paper, we present semantic distribution-aware contrastive adaptation algorithm that enables pixel-wise representation alignment under the guidance of semantic distributions. Specifically, we first design a pixel-wise contrastive loss by considering the correspondences between semantic distributions and pixel-wise representations from both domains. Essentially, clusters of pixel representations from the same category should cluster together and those from different categories should spread out. Next, an upper bound on this formulation is derived by involving the learning of an infinite number of (dis)similar pairs, making it efficient. Finally, we verify that SDCA can further improve segmentation accuracy when integrated with the self-supervised learning. We evaluate SDCA on multiple benchmarks, achieving considerable improvements over existing algorithms.The code is publicly available at https://github.com/BIT-DA/SDCA
GANs for Medical Image Analysis
Sep 13, 2018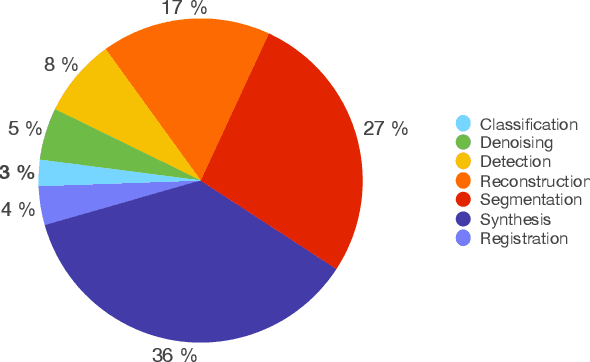

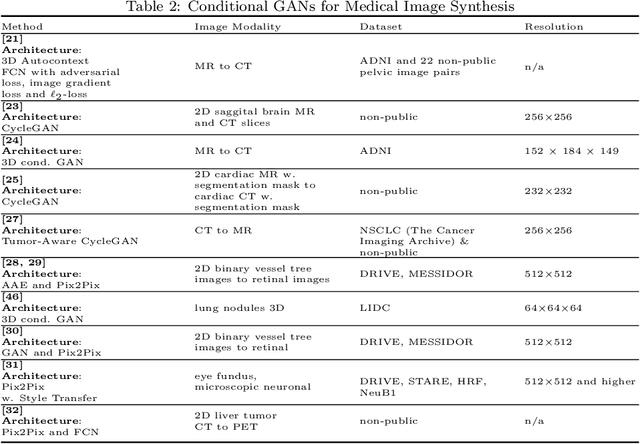
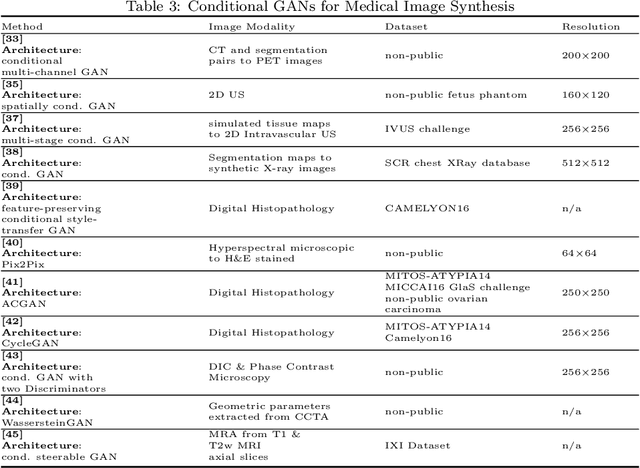
Generative Adversarial Networks (GANs) and their extensions have carved open many exciting ways to tackle well known and challenging medical image analysis problems such as medical image denoising, reconstruction, segmentation, data simulation, detection or classification. Furthermore, their ability to synthesize images at unprecedented levels of realism also gives hope that the chronic scarcity of labeled data in the medical field can be resolved with the help of these generative models. In this review paper, a broad overview of recent literature on GANs for medical applications is given, the shortcomings and opportunities of the proposed methods are thoroughly discussed and potential future work is elaborated. A total of 63 papers published until end of July 2018 are reviewed. For quick access, the papers and important details such as the underlying method, datasets and performance are summarized in tables.
Self-Supervised Feature Learning of 1D Convolutional Neural Networks with Contrastive Loss for Eating Detection Using an In-Ear Microphone
Aug 03, 2021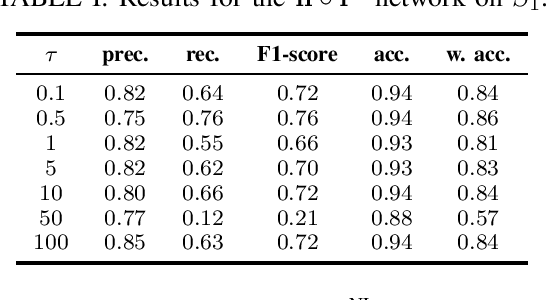
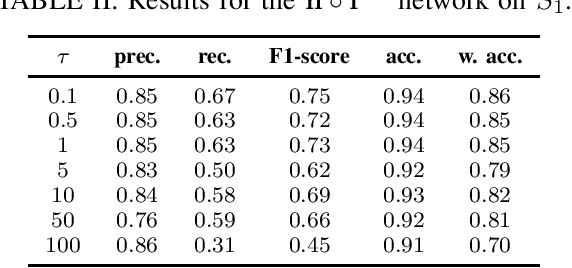
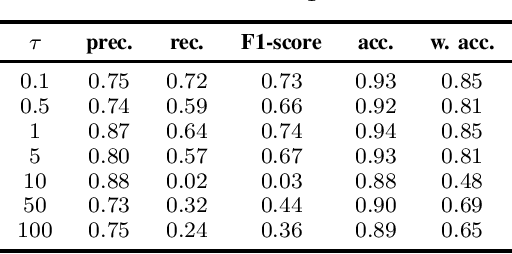
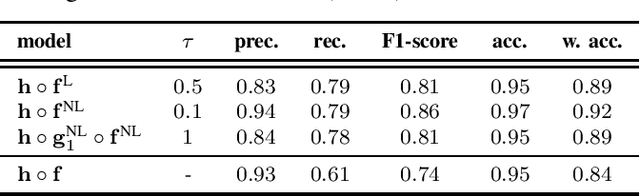
The importance of automated and objective monitoring of dietary behavior is becoming increasingly accepted. The advancements in sensor technology along with recent achievements in machine-learning--based signal-processing algorithms have enabled the development of dietary monitoring solutions that yield highly accurate results. A common bottleneck for developing and training machine learning algorithms is obtaining labeled data for training supervised algorithms, and in particular ground truth annotations. Manual ground truth annotation is laborious, cumbersome, can sometimes introduce errors, and is sometimes impossible in free-living data collection. As a result, there is a need to decrease the labeled data required for training. Additionally, unlabeled data, gathered in-the-wild from existing wearables (such as Bluetooth earbuds) can be used to train and fine-tune eating-detection models. In this work, we focus on training a feature extractor for audio signals captured by an in-ear microphone for the task of eating detection in a self-supervised way. We base our approach on the SimCLR method for image classification, proposed by Chen et al. from the domain of computer vision. Results are promising as our self-supervised method achieves similar results to supervised training alternatives, and its overall effectiveness is comparable to current state-of-the-art methods. Code is available at https://github.com/mug-auth/ssl-chewing .
A Machine learning approach for rapid disaster response based on multi-modal data. The case of housing & shelter needs
Aug 09, 2021



Along with climate change, more frequent extreme events, such as flooding and tropical cyclones, threaten the livelihoods and wellbeing of poor and vulnerable populations. One of the most immediate needs of people affected by a disaster is finding shelter. While the proliferation of data on disasters is already helping to save lives, identifying damages in buildings, assessing shelter needs, and finding appropriate places to establish emergency shelters or settlements require a wide range of data to be combined rapidly. To address this gap and make a headway in comprehensive assessments, this paper proposes a machine learning workflow that aims to fuse and rapidly analyse multimodal data. This workflow is built around open and online data to ensure scalability and broad accessibility. Based on a database of 19 characteristics for more than 200 disasters worldwide, a fusion approach at the decision level was used. This technique allows the collected multimodal data to share a common semantic space that facilitates the prediction of individual variables. Each fused numerical vector was fed into an unsupervised clustering algorithm called Self-Organizing-Maps (SOM). The trained SOM serves as a predictor for future cases, allowing predicting consequences such as total deaths, total people affected, and total damage, and provides specific recommendations for assessments in the shelter and housing sector. To achieve such prediction, a satellite image from before the disaster and the geographic and demographic conditions are shown to the trained model, which achieved a prediction accuracy of 62 %
Benchmarking convolutional neural networks for diagnosing Lyme disease from images
Jun 28, 2021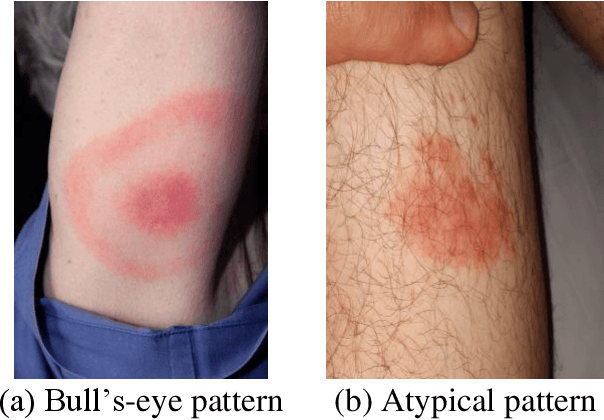
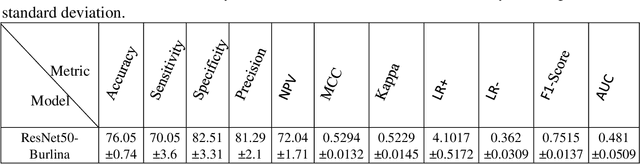
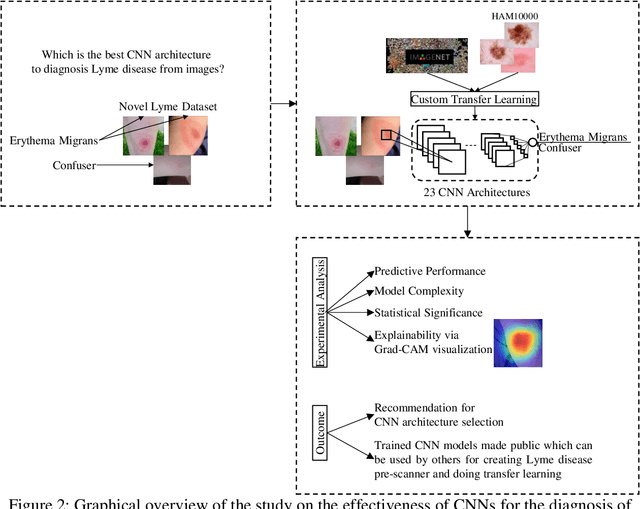
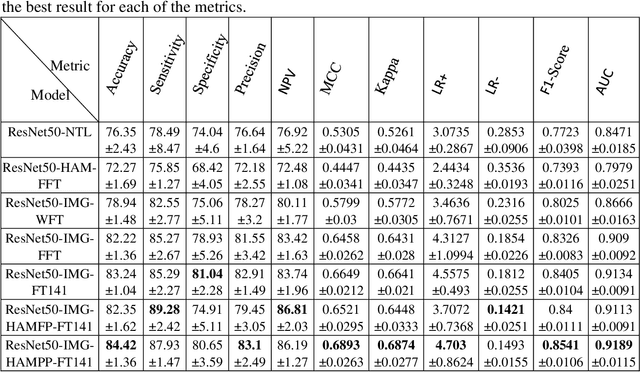
Lyme disease is one of the most common infectious vector-borne diseases in the world. In the early stage, the disease manifests itself in most cases with erythema migrans (EM) skin lesions. Better diagnosis of these early forms would allow improving the prognosis by preventing the transition to a severe late form thanks to appropriate antibiotic therapy. Recent studies show that convolutional neural networks (CNNs) perform very well to identify skin lesions from the image but, there is not much work for Lyme disease prediction from EM lesion images. The main objective of this study is to extensively analyze the effectiveness of CNNs for diagnosing Lyme disease from images and to find out the best CNN architecture for the purpose. There is no publicly available EM image dataset for Lyme disease prediction mainly because of privacy concerns. In this study, we utilized an EM dataset consisting of images collected from Clermont-Ferrand University Hospital Center (CF-CHU) of France and the internet. CF-CHU collected the images from several hospitals in France. This dataset was labeled by expert dermatologists and infectiologists from CF-CHU. First, we benchmarked this dataset for twenty-three well-known CNN architectures in terms of predictive performance metrics, computational complexity metrics, and statistical significance tests. Second, to improve the performance of the CNNs, we used transfer learning from ImageNet pre-trained models as well as pre-trained the CNNs with the skin lesion dataset "Human Against Machine with 10000 training images (HAM1000)". In that process, we searched for the best performing number of layers to unfreeze during transfer learning fine-tuning for each of the CNNs. Third, for model explainability, we utilized Gradient-weighted Class Activation Mapping to visualize the regions of input that are significant to the CNNs for making predictions. Fourth, we provided guidelines for model selection based on predictive performance and computational complexity. Our study confirmed the effectiveness and potential of even some lightweight CNNs to be used for Lyme disease pre-scanner mobile applications. We also made all the trained models publicly available at https://dappem.limos.fr/download.html, which can be used by others for transfer learning and building pre-scanners for Lyme disease.
SINGA-Easy: An Easy-to-Use Framework for MultiModal Analysis
Aug 03, 2021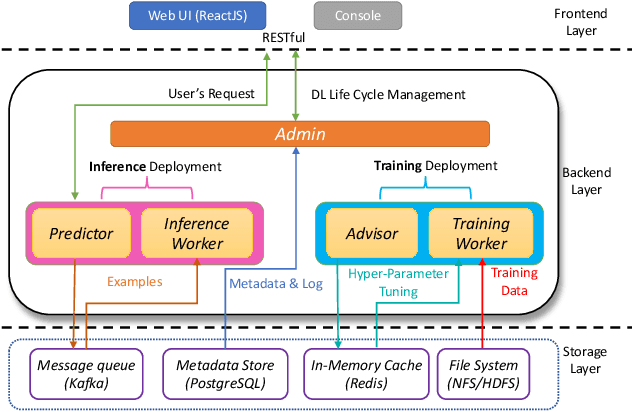

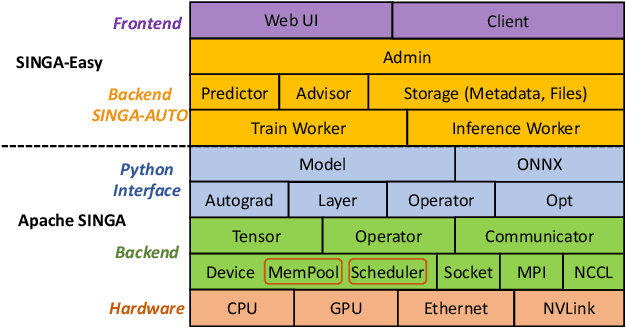

Deep learning has achieved great success in a wide spectrum of multimedia applications such as image classification, natural language processing and multimodal data analysis. Recent years have seen the development of many deep learning frameworks that provide a high-level programming interface for users to design models, conduct training and deploy inference. However, it remains challenging to build an efficient end-to-end multimedia application with most existing frameworks. Specifically, in terms of usability, it is demanding for non-experts to implement deep learning models, obtain the right settings for the entire machine learning pipeline, manage models and datasets, and exploit external data sources all together. Further, in terms of adaptability, elastic computation solutions are much needed as the actual serving workload fluctuates constantly, and scaling the hardware resources to handle the fluctuating workload is typically infeasible. To address these challenges, we introduce SINGA-Easy, a new deep learning framework that provides distributed hyper-parameter tuning at the training stage, dynamic computational cost control at the inference stage, and intuitive user interactions with multimedia contents facilitated by model explanation. Our experiments on the training and deployment of multi-modality data analysis applications show that the framework is both usable and adaptable to dynamic inference loads. We implement SINGA-Easy on top of Apache SINGA and demonstrate our system with the entire machine learning life cycle.
Unsupervised learning of multimodal image registration using domain adaptation with projected Earth Move's discrepancies
May 28, 2020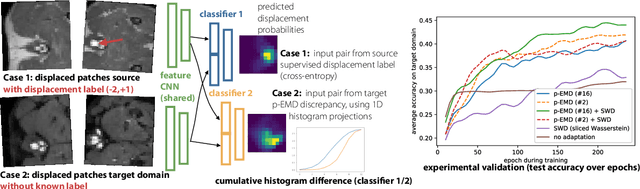
Multimodal image registration is a very challenging problem for deep learning approaches. Most current work focuses on either supervised learning that requires labelled training scans and may yield models that bias towards annotated structures or unsupervised approaches that are based on hand-crafted similarity metrics and may therefore not outperform their classical non-trained counterparts. We believe that unsupervised domain adaptation can be beneficial in overcoming the current limitations for multimodal registration, where good metrics are hard to define. Domain adaptation has so far been mainly limited to classification problems. We propose the first use of unsupervised domain adaptation for discrete multimodal registration. Based on a source domain for which quantised displacement labels are available as supervision, we transfer the output distribution of the network to better resemble the target domain (other modality) using classifier discrepancies. To improve upon the sliced Wasserstein metric for 2D histograms, we present a novel approximation that projects predictions into 1D and computes the L1 distance of their cumulative sums. Our proof-of-concept demonstrates the applicability of domain transfer from mono- to multimodal (multi-contrast) 2D registration of canine MRI scans and improves the registration accuracy from 33% (using sliced Wasserstein) to 44%.
Admix: Enhancing the Transferability of Adversarial Attacks
Jan 31, 2021

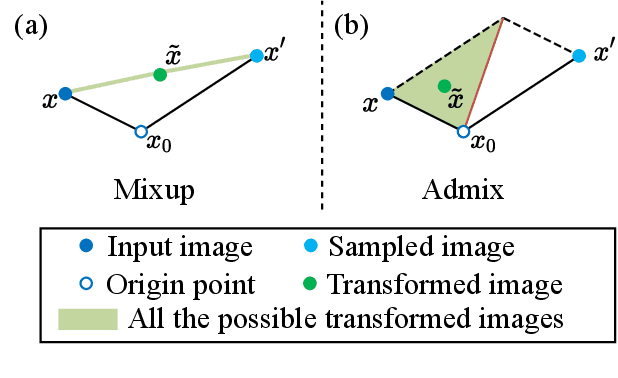
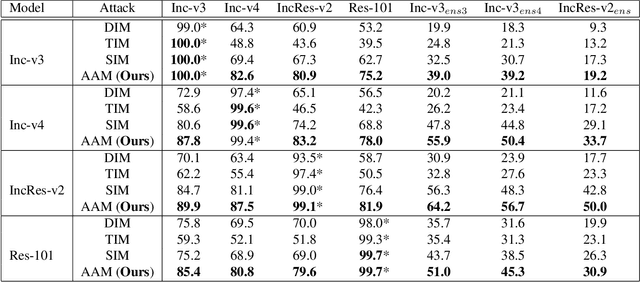
Although adversarial attacks have achieved incredible attack success rates under the white-box setting, most existing adversaries often exhibit weak transferability under the black-box setting. To address this issue, various input transformations have been proposed to enhance the attack transferability. In this work, We observe that all the existing transformations are applied on a single image, which might limit the transferability of the crafted adversaries. Hence, we propose a new input transformation based attack called Admix Attack Method (AAM) that considers both the original image and an image randomly picked from other categories. Instead of directly calculating the gradient on the original input, AAM calculates the gradient on the admixed image interpolated by the two images in order to craft adversaries with higher transferablility. Empirical evaluations on the standard ImageNet dataset demonstrate that AAM could achieve much higher transferability than the existing input transformation methods. By incorporating with other input transformations, our method could further improve the transferability and outperform the state-of-the-art combination of input transformations by a clear margin of 3.4% on average when attacking nine advanced defense models.