 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Product semantics translation from brain activity via adversarial learning
Mar 29, 2021

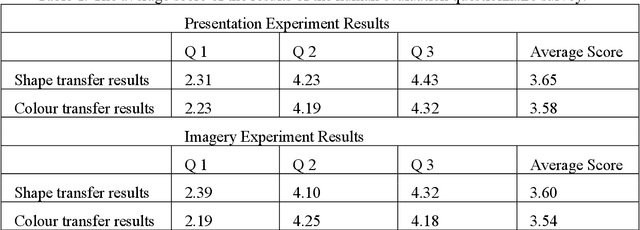


A small change of design semantics may affect a user's satisfaction with a product. To modify a design semantic of a given product from personalised brain activity via adversarial learning, in this work, we propose a deep generative transformation model to modify product semantics from the brain signal. We attempt to accomplish such synthesis: 1) synthesising the product image with new features corresponding to EEG signal; 2) maintaining the other image features that irrelevant to EEG signal. We leverage the idea of StarGAN and the model is designed to synthesise products with preferred design semantics (colour & shape) via adversarial learning from brain activity, and is applied with a case study to generate shoes with different design semantics from recorded EEG signals. To verify our proposed cognitive transformation model, a case study has been presented. The results work as a proof-of-concept that our framework has the potential to synthesis product semantic from brain activity.
CInC Flow: Characterizable Invertible 3x3 Convolution
Jul 03, 2021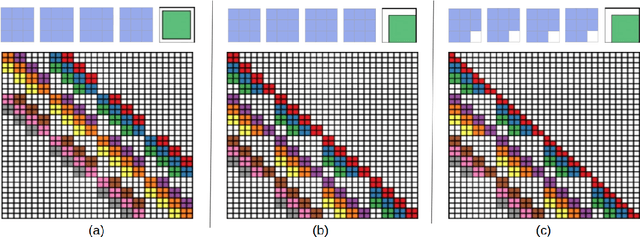

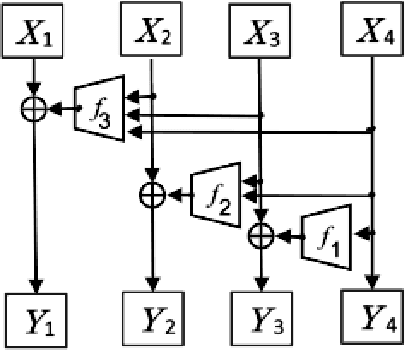
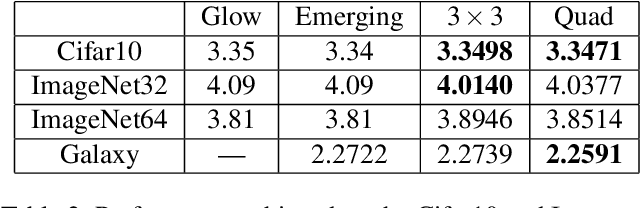
Normalizing flows are an essential alternative to GANs for generative modelling, which can be optimized directly on the maximum likelihood of the dataset. They also allow computation of the exact latent vector corresponding to an image since they are composed of invertible transformations. However, the requirement of invertibility of the transformation prevents standard and expressive neural network models such as CNNs from being directly used. Emergent convolutions were proposed to construct an invertible 3$\times$3 CNN layer using a pair of masked CNN layers, making them inefficient. We study conditions such that 3$\times$3 CNNs are invertible, allowing them to construct expressive normalizing flows. We derive necessary and sufficient conditions on a padded CNN for it to be invertible. Our conditions for invertibility are simple, can easily be maintained during the training process. Since we require only a single CNN layer for every effective invertible CNN layer, our approach is more efficient than emerging convolutions. We also proposed a coupling method, Quad-coupling. We benchmark our approach and show similar performance results to emergent convolutions while improving the model's efficiency.
Instance Localization for Self-supervised Detection Pretraining
Feb 16, 2021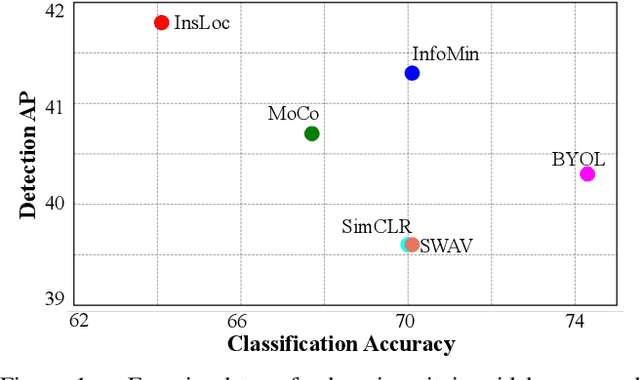
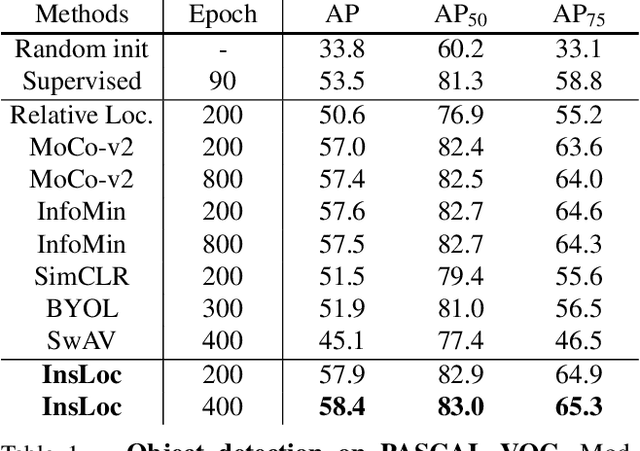
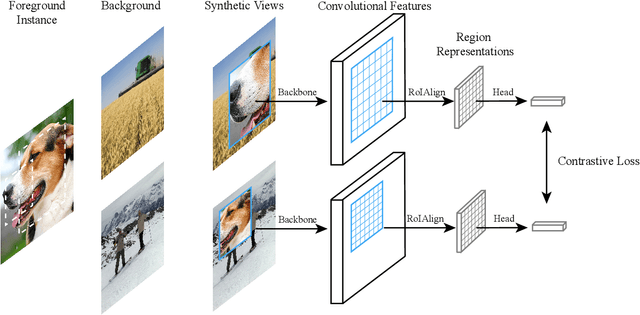
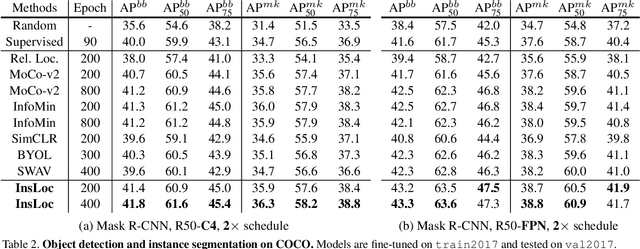
Prior research on self-supervised learning has led to considerable progress on image classification, but often with degraded transfer performance on object detection. The objective of this paper is to advance self-supervised pretrained models specifically for object detection. Based on the inherent difference between classification and detection, we propose a new self-supervised pretext task, called instance localization. Image instances are pasted at various locations and scales onto background images. The pretext task is to predict the instance category given the composited images as well as the foreground bounding boxes. We show that integration of bounding boxes into pretraining promotes better task alignment and architecture alignment for transfer learning. In addition, we propose an augmentation method on the bounding boxes to further enhance the feature alignment. As a result, our model becomes weaker at Imagenet semantic classification but stronger at image patch localization, with an overall stronger pretrained model for object detection. Experimental results demonstrate that our approach yields state-of-the-art transfer learning results for object detection on PASCAL VOC and MSCOCO.
Multi-defect microscopy image restoration under limited data conditions
Oct 31, 2019
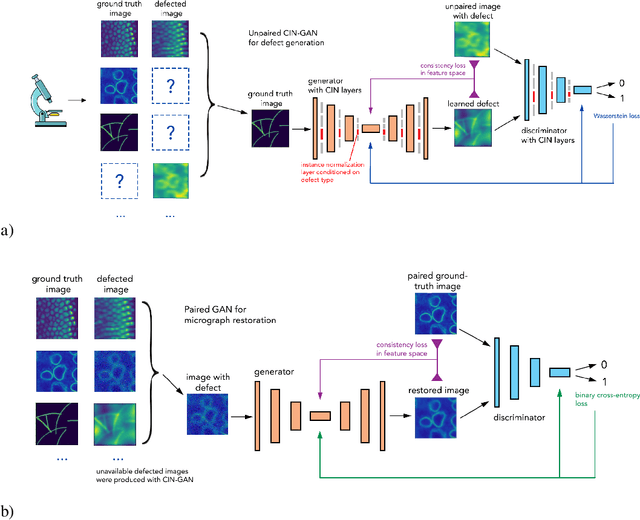

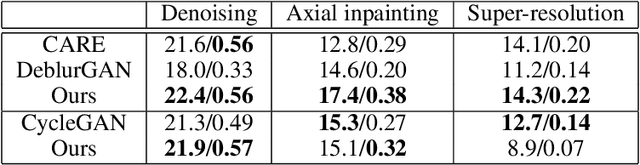
Deep learning methods are becoming widely used for restoration of defects associated with fluorescence microscopy imaging. One of the major challenges in application of such methods is the availability of training data. In this work, we pro-pose a unified method for reconstruction of multi-defect fluorescence microscopy images when training data is limited. Our approach consists of two steps: first, we perform data augmentation using Generative Adversarial Network (GAN) with conditional instance normalization (CIN); second, we train a conditional GAN(cGAN) on paired ground-truth and defected images to perform restoration. The experiments on three common types of imaging defects with different amounts of training data, show that the proposed method gives comparable results or outperforms CARE, deblurGAN and CycleGAN in restored image quality when limited data is available.
Fine-grained Domain Adaptive Crowd Counting via Point-derived Segmentation
Aug 06, 2021
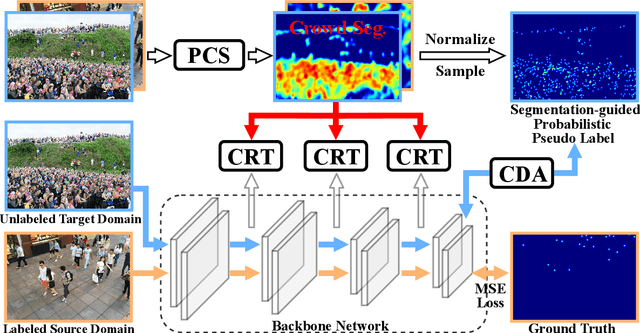
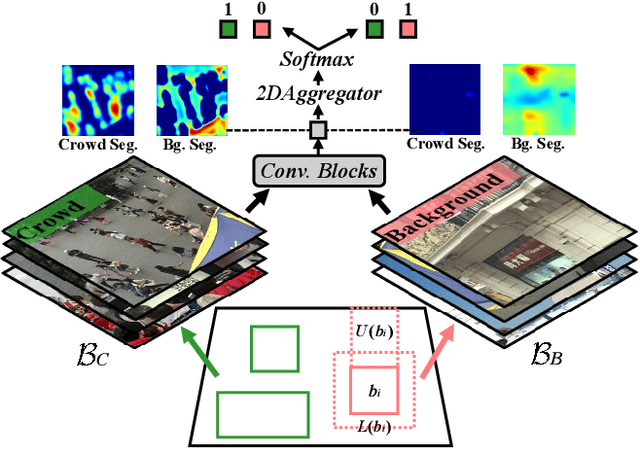
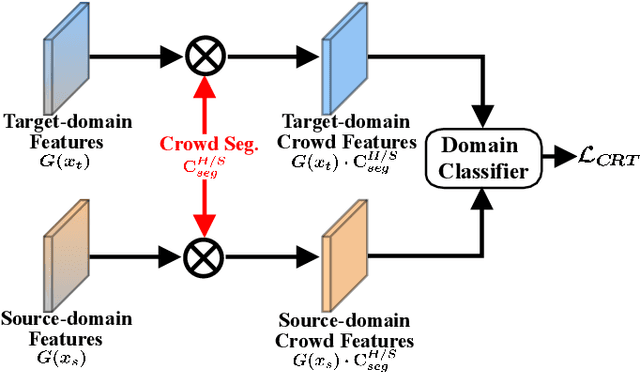
Existing domain adaptation methods for crowd counting view each crowd image as a whole and reduce domain discrepancies on crowds and backgrounds simultaneously. However, we argue that these methods are suboptimal, as crowds and backgrounds have quite different characteristics and backgrounds may vary dramatically in different crowd scenes (see Fig.~\ref{teaser}). This makes crowds not well aligned across domains together with backgrounds in a holistic manner. To this end, we propose to untangle crowds and backgrounds from crowd images and design fine-grained domain adaption methods for crowd counting. Different from other tasks which possess region-based fine-grained annotations (e.g., segments or bounding boxes), crowd counting only annotates one point on each human head, which impedes the implementation of fine-grained adaptation methods. To tackle this issue, we propose a novel and effective schema to learn crowd segmentation from point-level crowd counting annotations in the context of Multiple Instance Learning. We further leverage the derived segments to propose a crowd-aware fine-grained domain adaptation framework for crowd counting, which consists of two novel adaptation modules, i.e., Crowd Region Transfer (CRT) and Crowd Density Alignment (CDA). Specifically, the CRT module is designed to guide crowd features transfer across domains beyond background distractions, and the CDA module dedicates to constraining the target-domain crowd density distributions. Extensive experiments on multiple cross-domain settings (i.e., Synthetic $\rightarrow$ Real, Fixed $\rightarrow$ Fickle, Normal $\rightarrow$ BadWeather) demonstrate the superiority of the proposed method compared with state-of-the-art methods.
Hyperspectral Denoising Using Unsupervised Disentangled Spatio-Spectral Deep Priors
Feb 24, 2021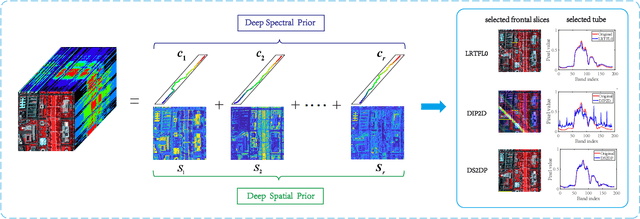
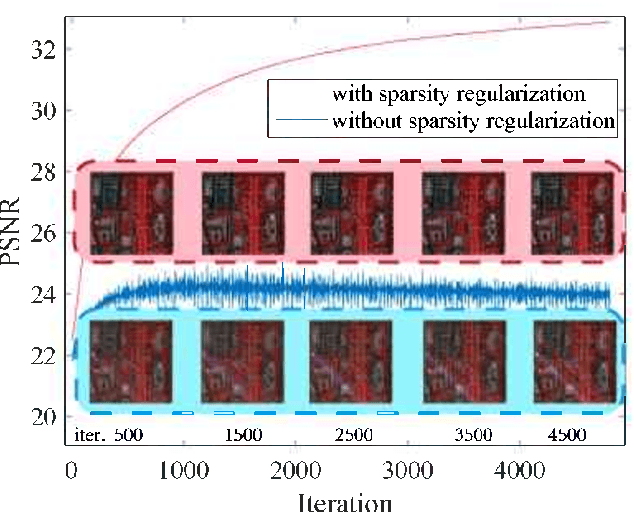
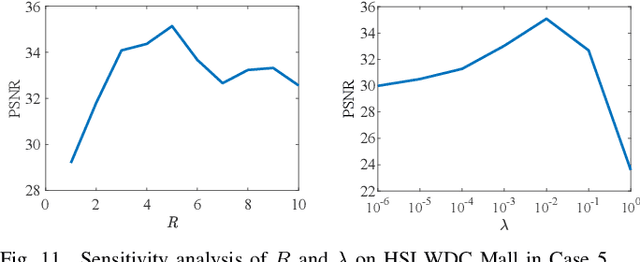
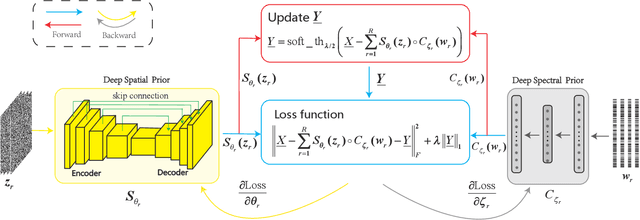
Image denoising is often empowered by accurate prior information. In recent years, data-driven neural network priors have shown promising performance for RGB natural image denoising. Compared to classic handcrafted priors (e.g., sparsity and total variation), the "deep priors" are learned using a large number of training samples -- which can accurately model the complex image generating process. However, data-driven priors are hard to acquire for hyperspectral images (HSIs) due to the lack of training data. A remedy is to use the so-called unsupervised deep image prior (DIP). Under the unsupervised DIP framework, it is hypothesized and empirically demonstrated that proper neural network structures are reasonable priors of certain types of images, and the network weights can be learned without training data. Nonetheless, the most effective unsupervised DIP structures were proposed for natural images instead of HSIs. The performance of unsupervised DIP-based HSI denoising is limited by a couple of serious challenges, namely, network structure design and network complexity. This work puts forth an unsupervised DIP framework that is based on the classic spatio-spectral decomposition of HSIs. Utilizing the so-called linear mixture model of HSIs, two types of unsupervised DIPs, i.e., U-Net-like network and fully-connected networks, are employed to model the abundance maps and endmembers contained in the HSIs, respectively. This way, empirically validated unsupervised DIP structures for natural images can be easily incorporated for HSI denoising. Besides, the decomposition also substantially reduces network complexity. An efficient alternating optimization algorithm is proposed to handle the formulated denoising problem. Semi-real and real data experiments are employed to showcase the effectiveness of the proposed approach.
Regularized Evolution for Image Classifier Architecture Search
Oct 26, 2018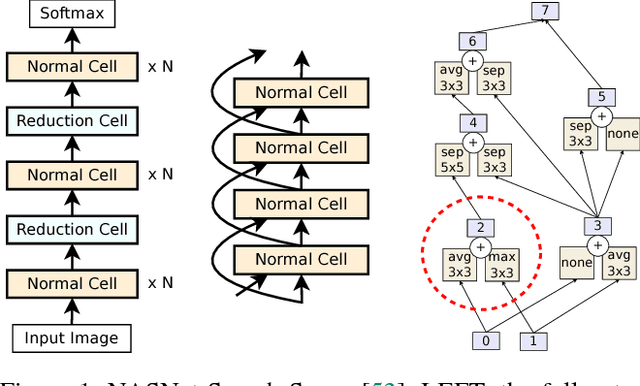
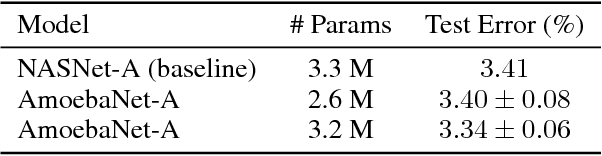
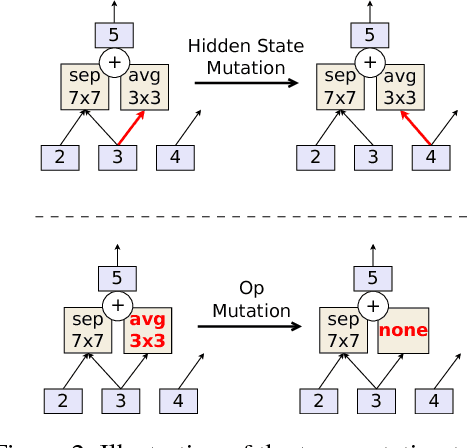
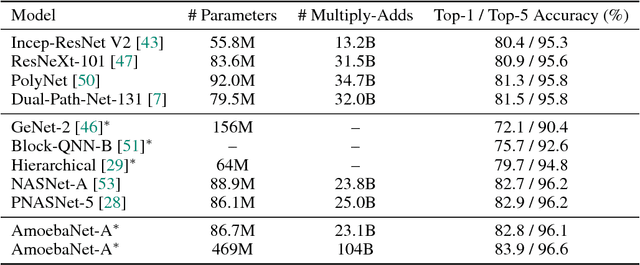
The effort devoted to hand-crafting neural network image classifiers has motivated the use of architecture search to discover them automatically. Although evolutionary algorithms have been repeatedly applied to neural network topologies, the image classifiers thus discovered have remained inferior to human-crafted ones. Here, we evolve an image classifier---AmoebaNet-A---that surpasses hand-designs for the first time. To do this, we modify the tournament selection evolutionary algorithm by introducing an age property to favor the younger genotypes. Matching size, AmoebaNet-A has comparable accuracy to current state-of-the-art ImageNet models discovered with more complex architecture-search methods. Scaled to larger size, AmoebaNet-A sets a new state-of-the-art 83.9% top-1 / 96.6% top-5 ImageNet accuracy. In a controlled comparison against a well known reinforcement learning algorithm, we give evidence that evolution can obtain results faster with the same hardware, especially at the earlier stages of the search. This is relevant when fewer compute resources are available. Evolution is, thus, a simple method to effectively discover high-quality architectures.
RelTransformer: Balancing the Visual Relationship Detection from Local Context, Scene and Memory
Apr 24, 2021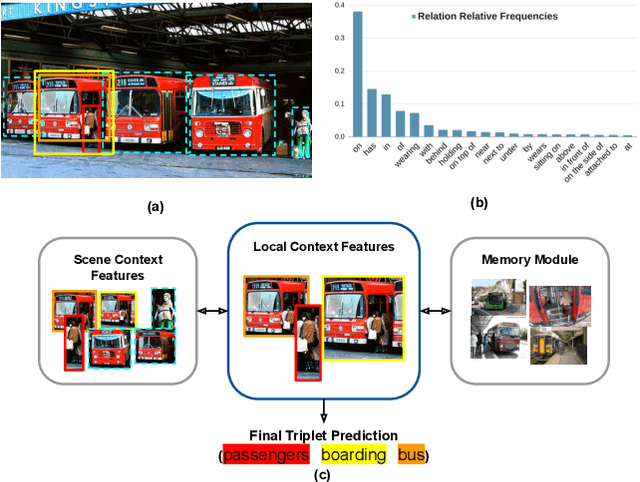
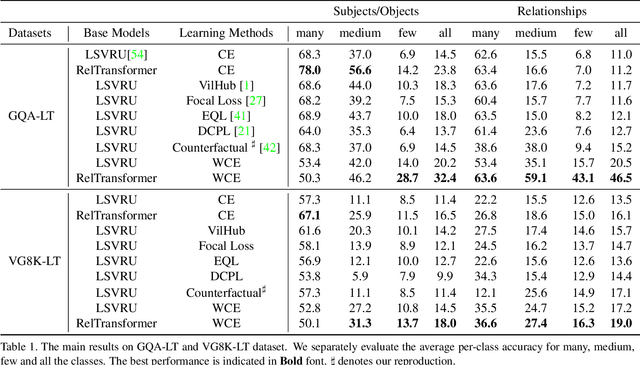
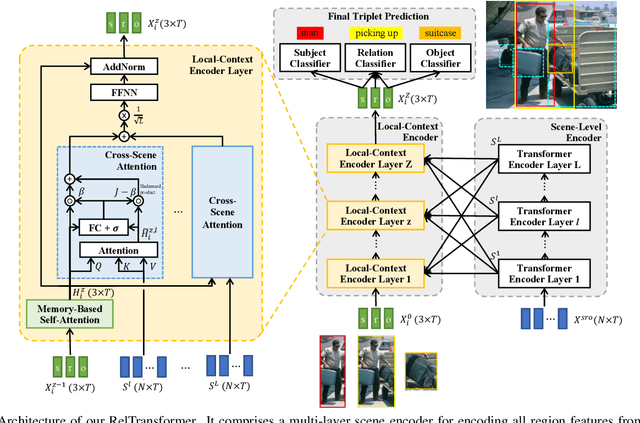
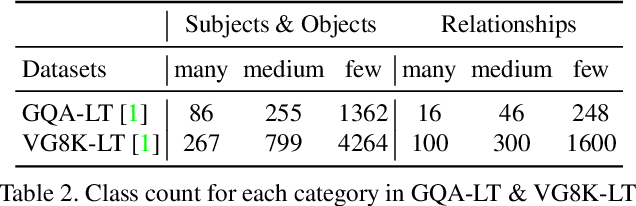
Visual relationship recognition (VRR) is a fundamental scene understanding task. The structure that VRR provides is essential to improve the AI interpretability in downstream tasks such as image captioning and visual question answering. Several recent studies showed that the long-tail problem in VRR is even more critical than that in object recognition due to the compositional complexity and structure. To overcome this limitation, we propose a novel transformer-based framework, dubbed as RelTransformer, which performs relationship prediction using rich semantic features from multiple image levels. We assume that more abundantcon textual features can generate more accurate and discriminative relationships, which can be useful when sufficient training data are lacking. The key feature of our model is its ability to aggregate three different-level features (local context, scene, and dataset-level) to compositionally predict the visual relationship. We evaluate our model on the visual genome and two "long-tail" VRR datasets, GQA-LT and VG8k-LT. Extensive experiments demonstrate that our RelTransformer could improve over the state-of-the-art baselines on all the datasets. In addition, our model significantly improves the accuracy of GQA-LT by 27.4% upon the best baselines on tail-relationship prediction. Our code is available in https://github.com/Vision-CAIR/RelTransformer.
Does deep machine vision have just noticeable difference (JND)?
Feb 16, 2021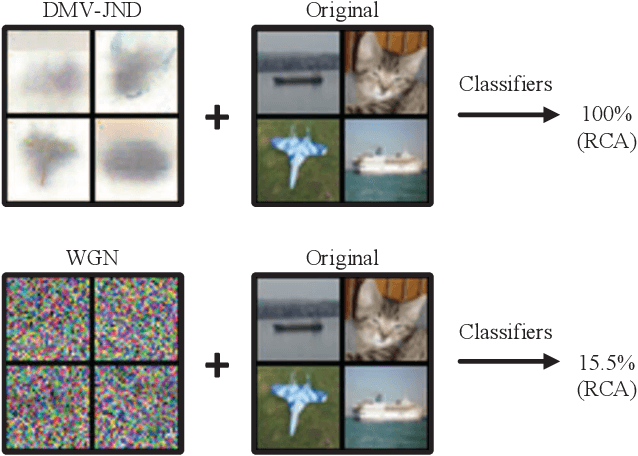

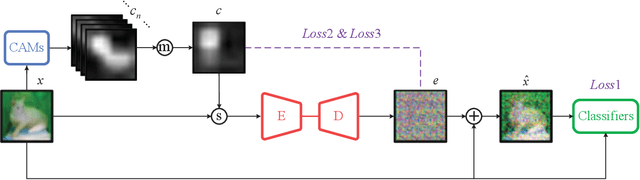
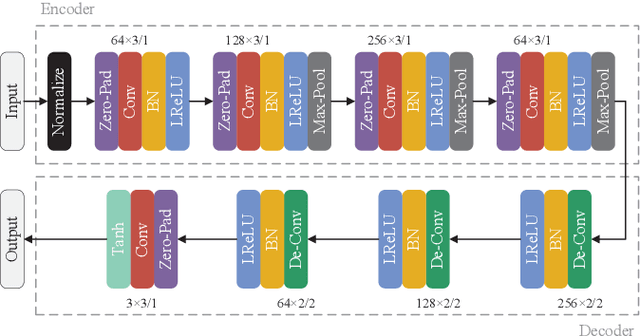
As an important perceptual characteristic of the Human Visual System (HVS), the Just Noticeable Difference (JND) has been studied for decades with image/video processing (e.g., perceptual image/video coding). However, there is little exploration on the existence of JND for AI, like Deep Machine Vision (DMV), although the DMV has made great strides in many machine vision tasks. In this paper, we take an initial attempt, and demonstrate that DMV does have the JND, termed as DMVJND. Besides, we propose a JND model for the classification task in DMV. It has been discovered that DMV can tolerate distorted images with average PSNR of only 9.56dB (the lower the better), by generating JND via unsupervised learning with our DMVJND-NET. In particular, a semantic-guided redundancy assessment strategy is designed to constrain the magnitude and spatial distribution of the JND. Experimental results on classification tasks demonstrate that we successfully find and model the JND for deep machine vision. Meanwhile, our DMV-JND paves a possible direction for DMV oriented image/video compression, watermarking, quality assessment, deep neural network security, and so on.
A new system for evaluating brand importance: A use case from the fashion industry
Jun 24, 2021
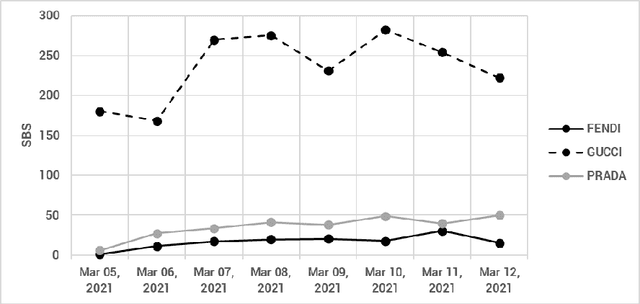


Today brand managers and marketing specialists can leverage huge amount of data to reveal patterns and trends in consumer perceptions, monitoring positive or negative associations of brands with respect to desired topics. In this study, we apply the Semantic Brand Score (SBS) indicator to assess brand importance in the fashion industry. To this purpose, we measure and visualize text data using the SBS Business Intelligence App (SBS BI), which relies on methods and tools of text mining and social network analysis. We collected and analyzed about 206,000 tweets that mentioned the fashion brands Fendi, Gucci and Prada, during the period from March 5 to March 12, 2021. From the analysis of the three SBS dimensions - prevalence, diversity and connectivity - we found that Gucci dominated the discourse, with high values of SBS. We use this case study as an example to present a new system for evaluating brand importance and image, through the analysis of (big) textual data.