 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Permutation-invariant Feature Restructuring for Correlation-aware Image Set-based Recognition
Aug 03, 2019
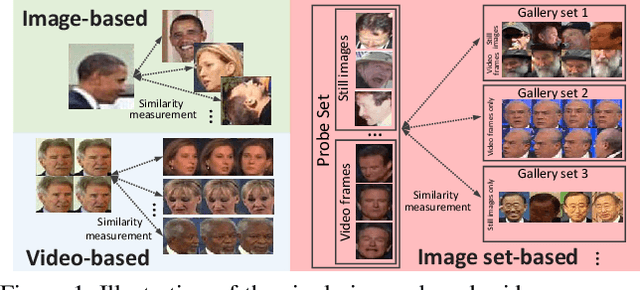
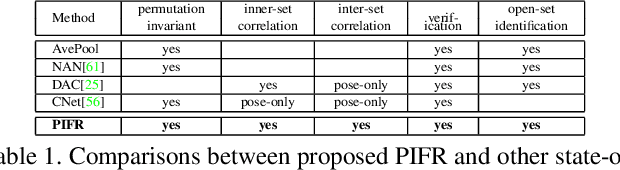


We consider the problem of comparing the similarity of image sets with variable-quantity, quality and un-ordered heterogeneous images. We use feature restructuring to exploit the correlations of both inner$\&$inter-set images. Specifically, the residual self-attention can effectively restructure the features using the other features within a set to emphasize the discriminative images and eliminate the redundancy. Then, a sparse/collaborative learning-based dependency-guided representation scheme reconstructs the probe features conditional to the gallery features in order to adaptively align the two sets. This enables our framework to be compatible with both verification and open-set identification. We show that the parametric self-attention network and non-parametric dictionary learning can be trained end-to-end by a unified alternative optimization scheme, and that the full framework is permutation-invariant. In the numerical experiments we conducted, our method achieves top performance on competitive image set/video-based face recognition and person re-identification benchmarks.
A Parallel Optical Image Security System with Cascaded Phase-only Masks
Feb 21, 2019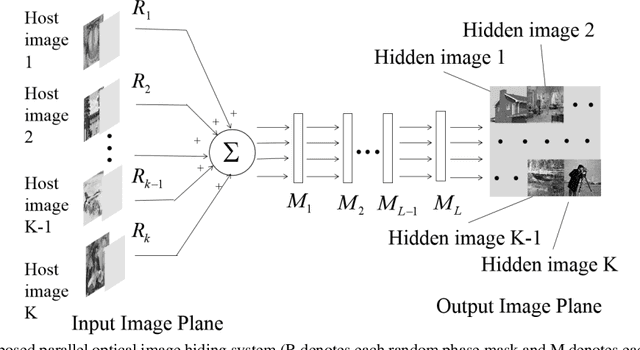

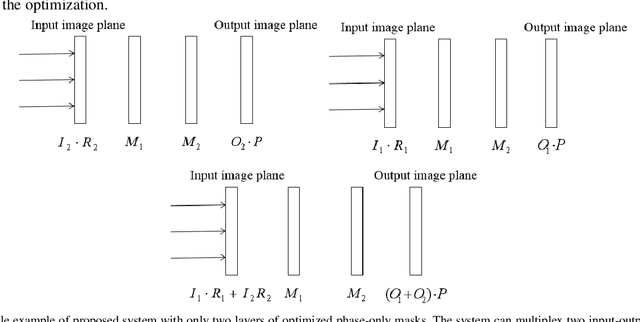
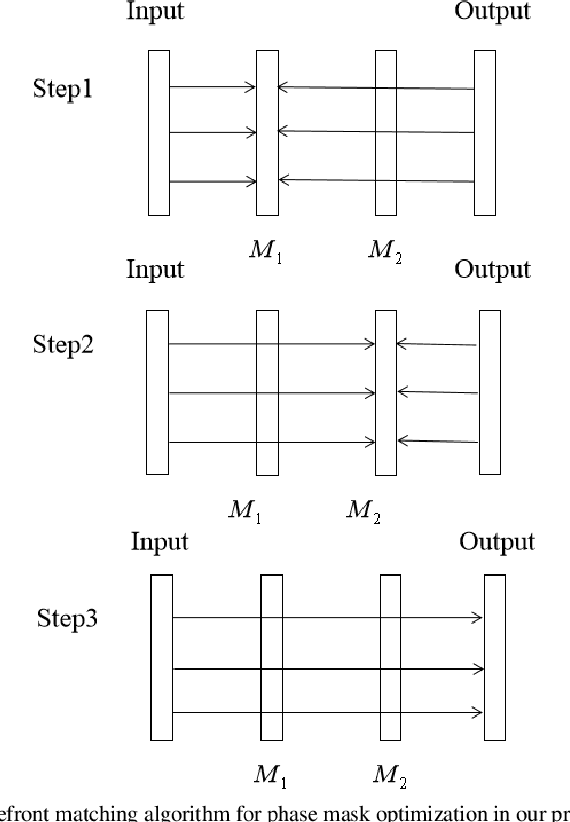
In many previous works, a cascaded phase-only mask (or phase-only hologram) architecture is designed for optical image encryption and watermarking. However, one such system usually cannot process multiple pairs of host images and hidden images in parallel. In our proposed scheme, multiple host images can be simultaneously input to the system and each corresponding output hidden image will be displayed in a non-overlap sub-region in the output imaging plane. Each input host image undergoes a different optical transform in an independent channel within the same system. The multiple cascaded phase masks (up to 25 layers or even more) in the system can be effectively optimized by a wavefront matching algorithm.
'CADSketchNet' -- An Annotated Sketch dataset for 3D CAD Model Retrieval with Deep Neural Networks
Jul 20, 2021

Ongoing advancements in the fields of 3D modelling and digital archiving have led to an outburst in the amount of data stored digitally. Consequently, several retrieval systems have been developed depending on the type of data stored in these databases. However, unlike text data or images, performing a search for 3D models is non-trivial. Among 3D models, retrieving 3D Engineering/CAD models or mechanical components is even more challenging due to the presence of holes, volumetric features, presence of sharp edges etc., which make CAD a domain unto itself. The research work presented in this paper aims at developing a dataset suitable for building a retrieval system for 3D CAD models based on deep learning. 3D CAD models from the available CAD databases are collected, and a dataset of computer-generated sketch data, termed 'CADSketchNet', has been prepared. Additionally, hand-drawn sketches of the components are also added to CADSketchNet. Using the sketch images from this dataset, the paper also aims at evaluating the performance of various retrieval system or a search engine for 3D CAD models that accepts a sketch image as the input query. Many experimental models are constructed and tested on CADSketchNet. These experiments, along with the model architecture, choice of similarity metrics are reported along with the search results.
* Computers & Graphics Journal, Special Section on 3DOR 2021
Instance Localization for Self-supervised Detection Pretraining
Feb 16, 2021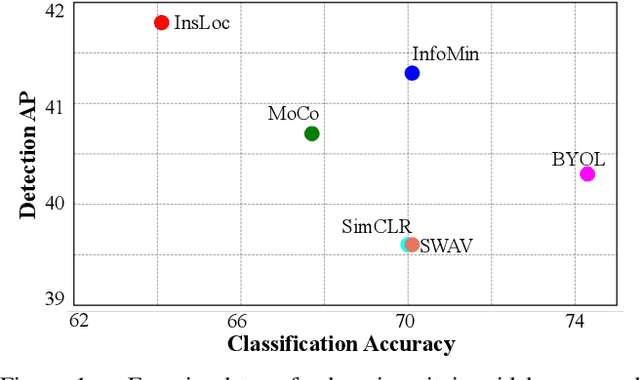
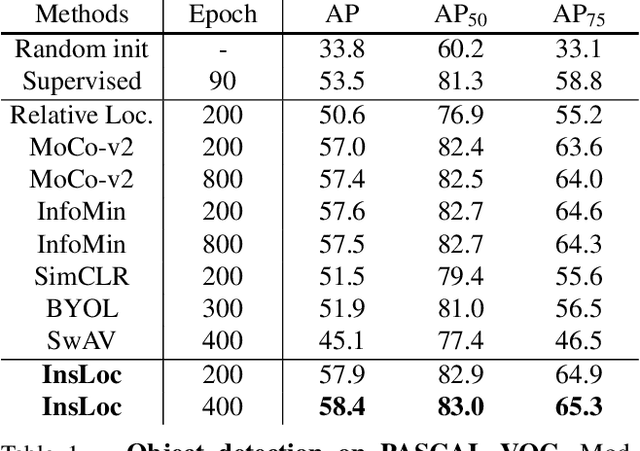
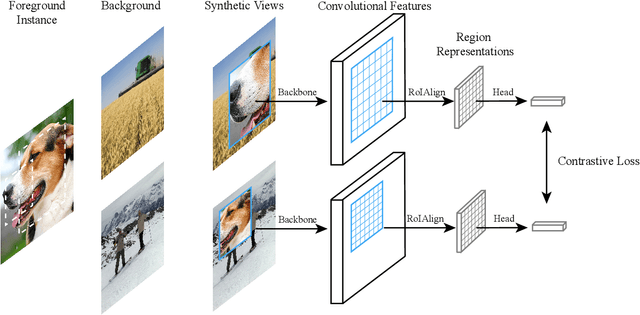
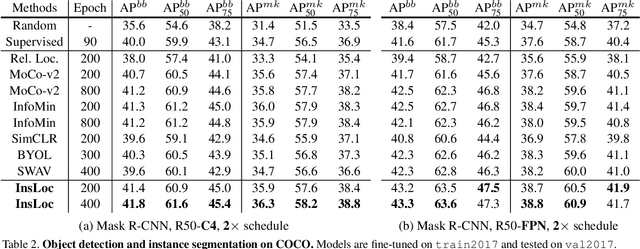
Prior research on self-supervised learning has led to considerable progress on image classification, but often with degraded transfer performance on object detection. The objective of this paper is to advance self-supervised pretrained models specifically for object detection. Based on the inherent difference between classification and detection, we propose a new self-supervised pretext task, called instance localization. Image instances are pasted at various locations and scales onto background images. The pretext task is to predict the instance category given the composited images as well as the foreground bounding boxes. We show that integration of bounding boxes into pretraining promotes better task alignment and architecture alignment for transfer learning. In addition, we propose an augmentation method on the bounding boxes to further enhance the feature alignment. As a result, our model becomes weaker at Imagenet semantic classification but stronger at image patch localization, with an overall stronger pretrained model for object detection. Experimental results demonstrate that our approach yields state-of-the-art transfer learning results for object detection on PASCAL VOC and MSCOCO.
BridgeNet: A Joint Learning Network of Depth Map Super-Resolution and Monocular Depth Estimation
Jul 27, 2021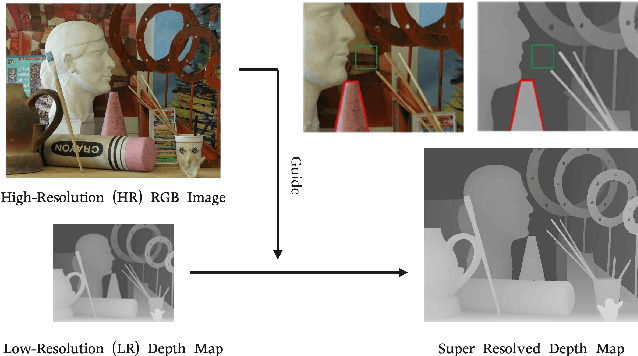
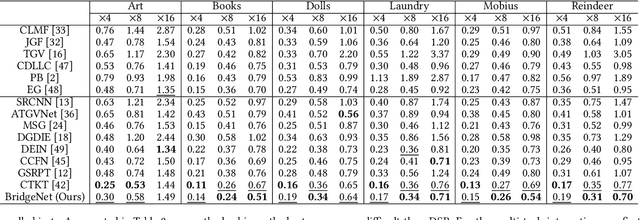
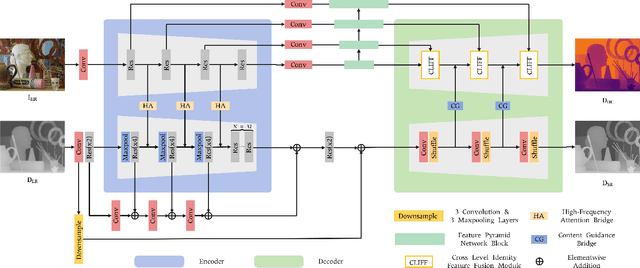

Depth map super-resolution is a task with high practical application requirements in the industry. Existing color-guided depth map super-resolution methods usually necessitate an extra branch to extract high-frequency detail information from RGB image to guide the low-resolution depth map reconstruction. However, because there are still some differences between the two modalities, direct information transmission in the feature dimension or edge map dimension cannot achieve satisfactory result, and may even trigger texture copying in areas where the structures of the RGB-D pair are inconsistent. Inspired by the multi-task learning, we propose a joint learning network of depth map super-resolution (DSR) and monocular depth estimation (MDE) without introducing additional supervision labels. For the interaction of two subnetworks, we adopt a differentiated guidance strategy and design two bridges correspondingly. One is the high-frequency attention bridge (HABdg) designed for the feature encoding process, which learns the high-frequency information of the MDE task to guide the DSR task. The other is the content guidance bridge (CGBdg) designed for the depth map reconstruction process, which provides the content guidance learned from DSR task for MDE task. The entire network architecture is highly portable and can provide a paradigm for associating the DSR and MDE tasks. Extensive experiments on benchmark datasets demonstrate that our method achieves competitive performance. Our code and models are available at https://rmcong.github.io/proj_BridgeNet.html.
EA-Net: Edge-Aware Network for Flow-based Video Frame Interpolation
May 17, 2021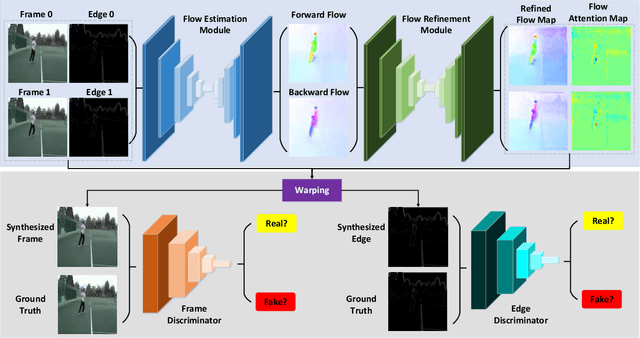



Video frame interpolation can up-convert the frame rate and enhance the video quality. In recent years, although the interpolation performance has achieved great success, image blur usually occurs at the object boundaries owing to the large motion. It has been a long-standing problem, and has not been addressed yet. In this paper, we propose to reduce the image blur and get the clear shape of objects by preserving the edges in the interpolated frames. To this end, the proposed Edge-Aware Network (EA-Net) integrates the edge information into the frame interpolation task. It follows an end-to-end architecture and can be separated into two stages, \emph{i.e.}, edge-guided flow estimation and edge-protected frame synthesis. Specifically, in the flow estimation stage, three edge-aware mechanisms are developed to emphasize the frame edges in estimating flow maps, so that the edge-maps are taken as the auxiliary information to provide more guidance to boost the flow accuracy. In the frame synthesis stage, the flow refinement module is designed to refine the flow map, and the attention module is carried out to adaptively focus on the bidirectional flow maps when synthesizing the intermediate frames. Furthermore, the frame and edge discriminators are adopted to conduct the adversarial training strategy, so as to enhance the reality and clarity of synthesized frames. Experiments on three benchmarks, including Vimeo90k, UCF101 for single-frame interpolation and Adobe240-fps for multi-frame interpolation, have demonstrated the superiority of the proposed EA-Net for the video frame interpolation task.
An Empirical Method to Quantify the Peripheral Performance Degradation in Deep Networks
Dec 04, 2020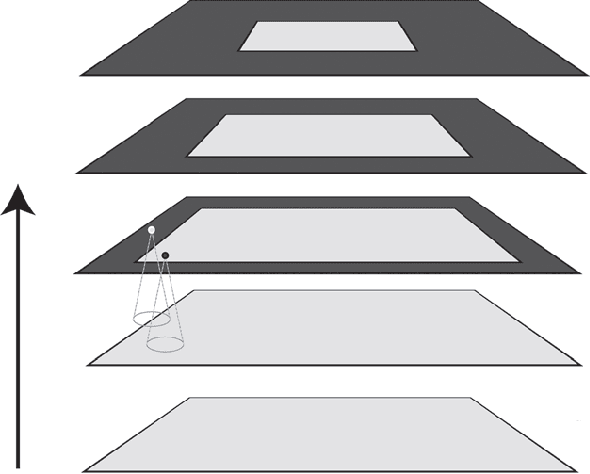
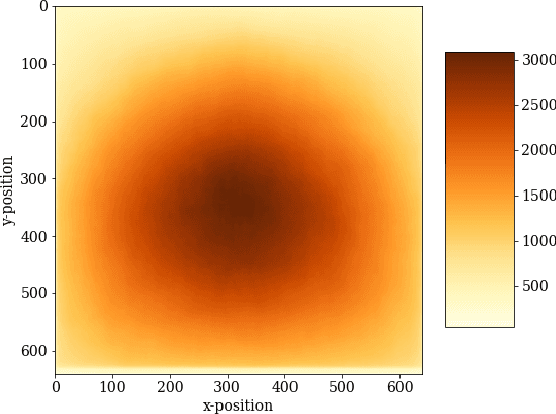


When applying a convolutional kernel to an image, if the output is to remain the same size as the input then some form of padding is required around the image boundary, meaning that for each layer of convolution in a convolutional neural network (CNN), a strip of pixels equal to the half-width of the kernel size is produced with a non-veridical representation. Although most CNN kernels are small to reduce the parameter load of a network, this non-veridical area compounds with each convolutional layer. The tendency toward deeper and deeper networks combined with stride-based down-sampling means that the propagation of this region can end up covering a non-negligable portion of the image. Although this issue with convolutions has been well acknowledged over the years, the impact of this degraded peripheral representation on modern network behavior has not been fully quantified. What are the limits of translation invariance? Does image padding successfully mitigate the issue, or is performance affected as an object moves between the image border and center? Using Mask R-CNN as an experimental model, we design a dataset and methodology to quantify the spatial dependency of network performance. Our dataset is constructed by inserting objects into high resolution backgrounds, thereby allowing us to crop sub-images which place target objects at specific locations relative to the image border. By probing the behaviour of Mask R-CNN across a selection of target locations, we see clear patterns of performance degredation near the image boundary, and in particular in the image corners. Quantifying both the extent and magnitude of this spatial anisotropy in network performance is important for the deployment of deep networks into unconstrained and realistic environments in which the location of objects or regions of interest are not guaranteed to be well localized within a given image.
Learning High Fidelity Depths of Dressed Humans by Watching Social Media Dance Videos
Mar 04, 2021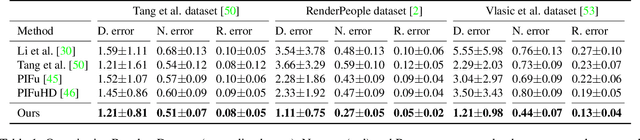
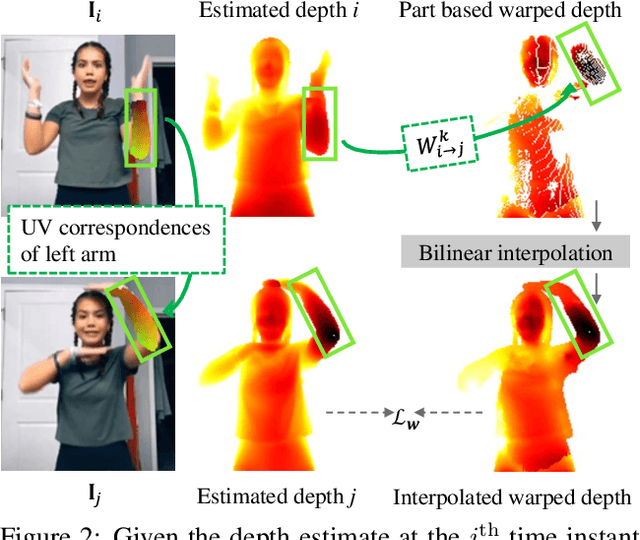

A key challenge of learning the geometry of dressed humans lies in the limited availability of the ground truth data (e.g., 3D scanned models), which results in the performance degradation of 3D human reconstruction when applying to real-world imagery. We address this challenge by leveraging a new data resource: a number of social media dance videos that span diverse appearance, clothing styles, performances, and identities. Each video depicts dynamic movements of the body and clothes of a single person while lacking the 3D ground truth geometry. To utilize these videos, we present a new method to use the local transformation that warps the predicted local geometry of the person from an image to that of another image at a different time instant. This allows self-supervision as enforcing a temporal coherence over the predictions. In addition, we jointly learn the depth along with the surface normals that are highly responsive to local texture, wrinkle, and shade by maximizing their geometric consistency. Our method is end-to-end trainable, resulting in high fidelity depth estimation that predicts fine geometry faithful to the input real image. We demonstrate that our method outperforms the state-of-the-art human depth estimation and human shape recovery approaches on both real and rendered images.
AOSLO-net: A deep learning-based method for automatic segmentation of retinal microaneurysms from adaptive optics scanning laser ophthalmoscope images
Jun 25, 2021

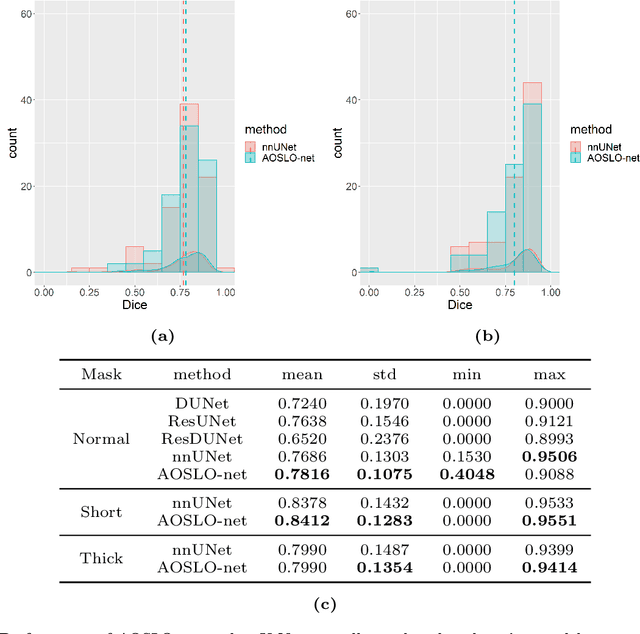
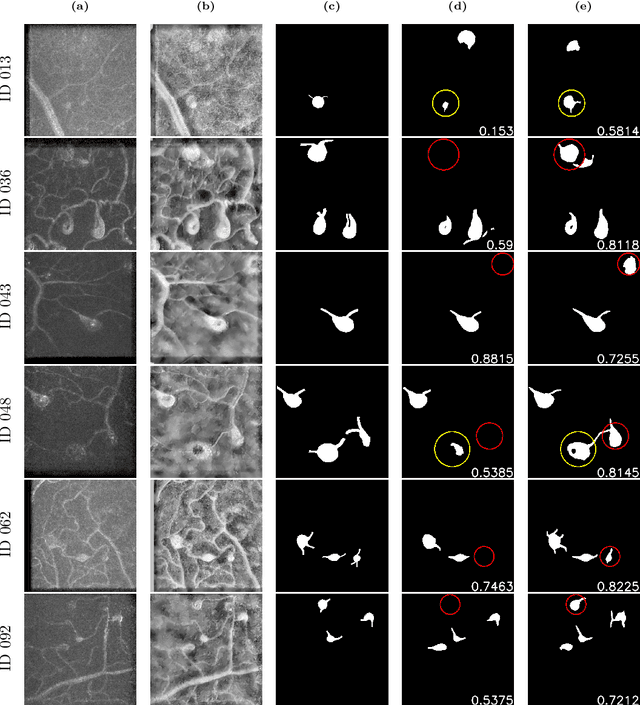
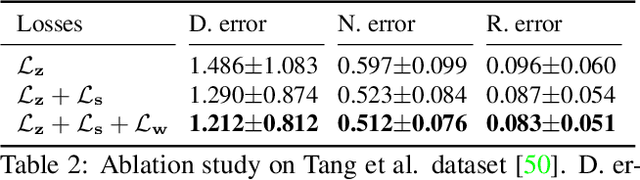
Microaneurysms (MAs) are one of the earliest signs of diabetic retinopathy (DR), a frequent complication of diabetes that can lead to visual impairment and blindness. Adaptive optics scanning laser ophthalmoscopy (AOSLO) provides real-time retinal images with resolution down to 2 $\mu m$ and thus allows detection of the morphologies of individual MAs, a potential marker that might dictate MA pathology and affect the progression of DR. In contrast to the numerous automatic models developed for assessing the number of MAs on fundus photographs, currently there is no high throughput image protocol available for automatic analysis of AOSLO photographs. To address this urgency, we introduce AOSLO-net, a deep neural network framework with customized training policies to automatically segment MAs from AOSLO images. We evaluate the performance of AOSLO-net using 87 DR AOSLO images and our results demonstrate that the proposed model outperforms the state-of-the-art segmentation model both in accuracy and cost and enables correct MA morphological classification.
End-to-end Hand Mesh Recovery from a Monocular RGB Image
Mar 09, 2019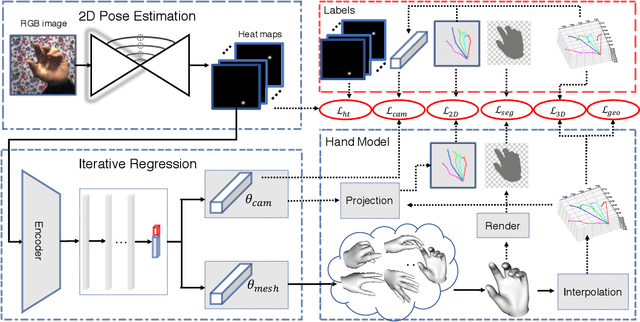
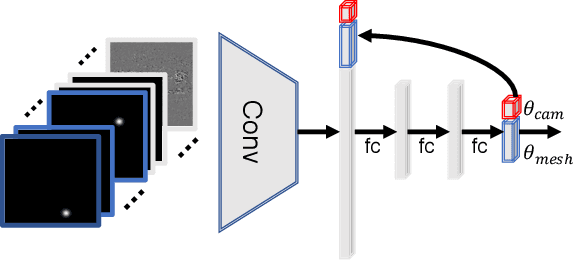
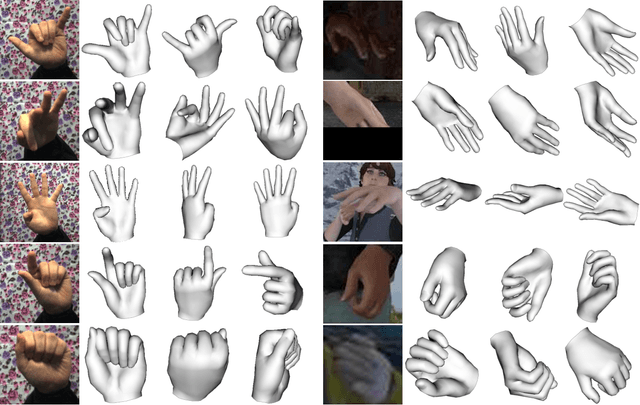

In this paper, we present a HAnd Mesh Recovery (HAMR) framework to tackle the problem of reconstructing the full 3D mesh of a human hand from a single RGB image. In contrast to existing research on 2D or 3D hand pose estimation from RGB or/and depth image data, HAMR can provide a more expressive and useful mesh representation for monocular hand image understanding. In particular, the mesh representation is achieved by parameterizing a generic 3D hand model with shape and relative 3D joint angles. By utilizing this mesh representation, we can easily compute the 3D joint locations via linear interpolations between the vertexes of the mesh, while obtain the 2D joint locations with a projection of the 3D joints.To this end, a differentiable re-projection loss can be defined in terms of the derived representations and the ground-truth labels, thus making our framework end-to-end trainable.Qualitative experiments show that our framework is capable of recovering appealing 3D hand mesh even in the presence of severe occlusions.Quantitatively, our approach also outperforms the state-of-the-art methods for both 2D and 3D hand pose estimation from a monocular RGB image on several benchmark datasets.